 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating Reproducible Functional Networks Associated with Task Dynamics using Unsupervised LSTMs
May 06, 2021
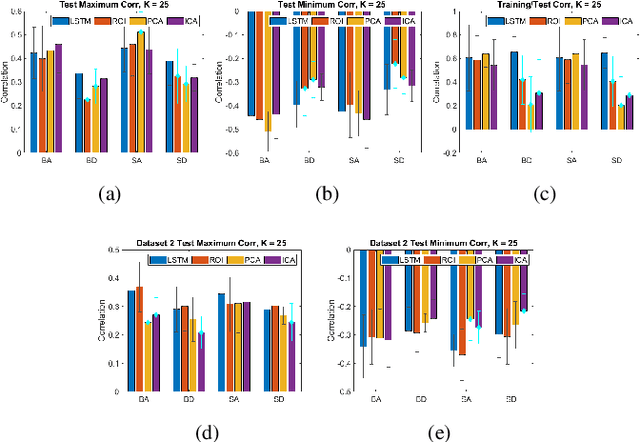
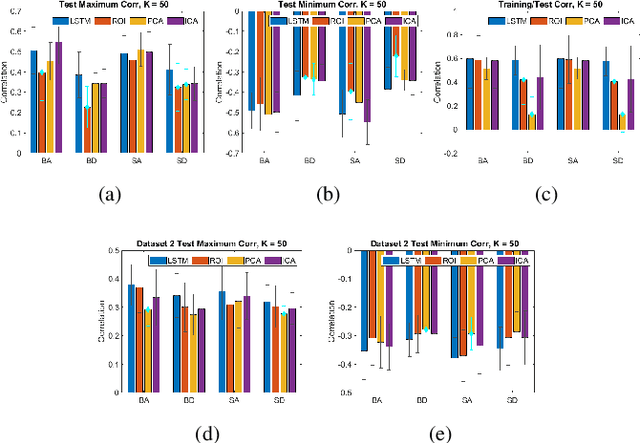
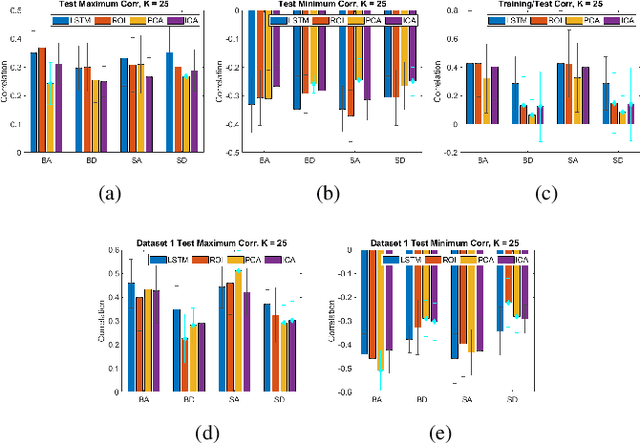
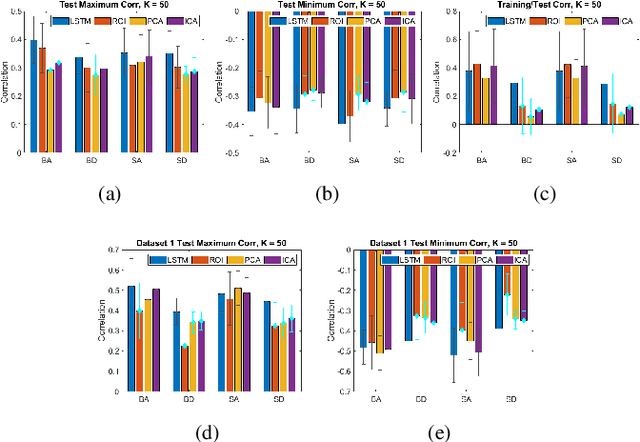
We propose a method for estimating more reproducible functional networks that are more strongly associated with dynamic task activity by using recurrent neural networks with long short term memory (LSTMs). The LSTM model is trained in an unsupervised manner to learn to generate the functional magnetic resonance imaging (fMRI) time-series data in regions of interest. The learned functional networks can then be used for further analysis, e.g., correlation analysis to determine functional networks that are strongly associated with an fMRI task paradigm. We test our approach and compare to other methods for decomposing functional networks from fMRI activity on 2 related but separate datasets that employ a biological motion perception task. We demonstrate that the functional networks learned by the LSTM model are more strongly associated with the task activity and dynamics compared to other approaches. Furthermore, the patterns of network association are more closely replicated across subjects within the same dataset as well as across datasets. More reproducible functional networks are essential for better characterizing the neural correlates of a target task.
* IEEE International Symposium on Biomedical Imaging (ISBI) 2020
Neural Networks and Continuous Time
Jun 14, 2016

The fields of neural computation and artificial neural networks have developed much in the last decades. Most of the works in these fields focus on implementing and/or learning discrete functions or behavior. However, technical, physical, and also cognitive processes evolve continuously in time. This cannot be described directly with standard architectures of artificial neural networks such as multi-layer feed-forward perceptrons. Therefore, in this paper, we will argue that neural networks modeling continuous time are needed explicitly for this purpose, because with them the synthesis and analysis of continuous and possibly periodic processes in time are possible (e.g. for robot behavior) besides computing discrete classification functions (e.g. for logical reasoning). We will relate possible neural network architectures with (hybrid) automata models that allow to express continuous processes.
Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
Jun 27, 2020
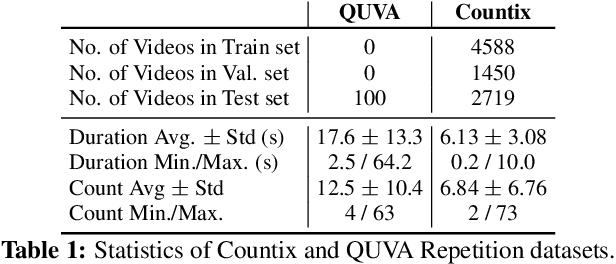


We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google.com/view/repnet .
Multi-Scale Cost Volumes Cascade Network for Stereo Matching
Feb 03, 2021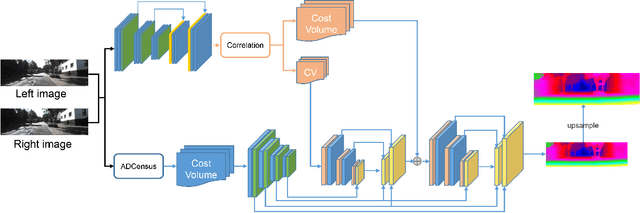
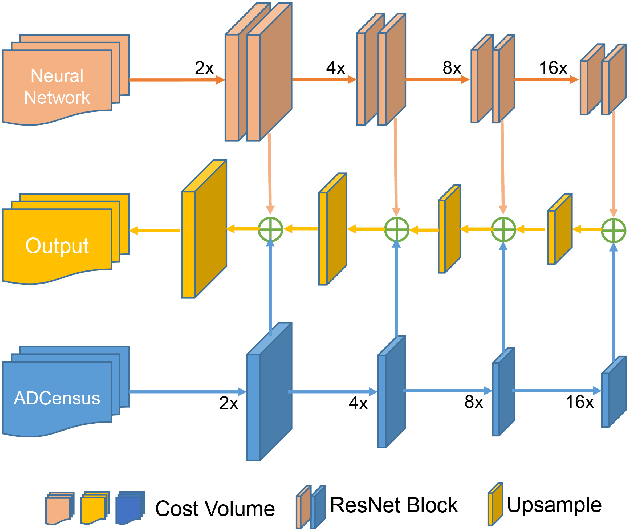

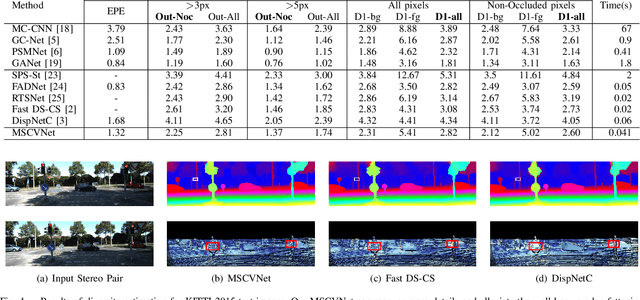
Stereo matching is essential for robot navigation. However, the accuracy of current widely used traditional methods is low, while methods based on CNN need expensive computational cost and running time. This is because different cost volumes play a crucial role in balancing speed and accuracy. Thus we propose MSCVNet, which combines traditional methods and CNN to improve the quality of cost volume. Concretely, our network first generates multiple 3D cost volumes with different resolutions and then uses 2D convolutions to construct a novel cascade hourglass network for cost aggregation. Meanwhile, we design an algorithm to distinguish and calculate the loss for discontinuous areas of disparity result. According to the KITTI official website, our network is much faster than most top-performing methods(24*than CSPN, 44*than GANet, etc.). Meanwhile, compared to traditional methods(SPS-St, SGM) and other real-time stereo matching networks(Fast DS-CS, DispNetC, and RTSNet, etc.), our network achieves a big improvement in accuracy, demonstrating the effectiveness of our proposed method.
A Control Architecture for Provably-Correct Autonomous Driving
May 06, 2021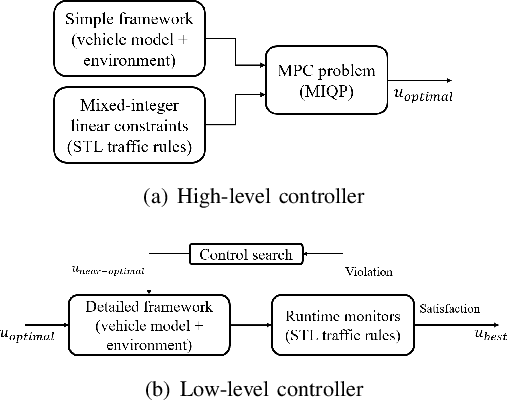
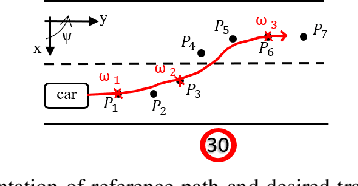
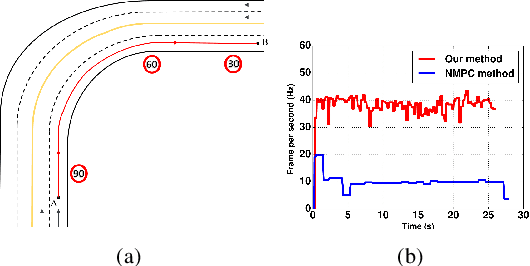
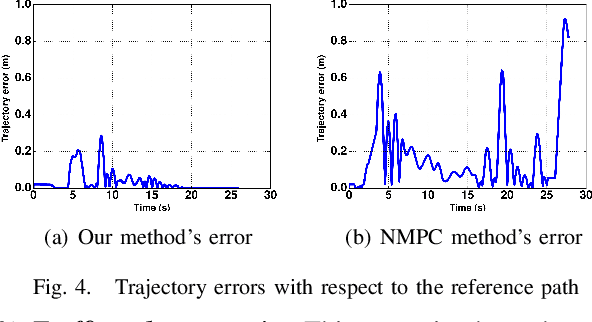
This paper presents a novel two-level control architecture for a fully autonomous vehicle in a deterministic environment, which can handle traffic rules as specifications and low-level vehicle control with real-time performance. At the top level, we use a simple representation of the environment and vehicle dynamics to formulate a linear Model Predictive Control (MPC) problem. We describe the traffic rules and safety constraints using Signal Temporal Logic (STL) formulas, which are mapped to mixed integer-linear constraints in the optimization problem. The solution obtained at the top level is used at the bottom-level to determine the best control command for satisfying the constraints in a more detailed framework. At the bottom-level, specification-based runtime monitoring techniques, together with detailed representations of the environment and vehicle dynamics, are used to compensate for the mismatch between the simple models used in the MPC and the real complex models. We obtain substantial improvements over existing approaches in the literature in the sense of runtime performance and we validate the effectiveness of our proposed control approach in the simulator CARLA.
Trimming Feature Extraction and Inference for MCU-based Edge NILM: a Systematic Approach
May 21, 2021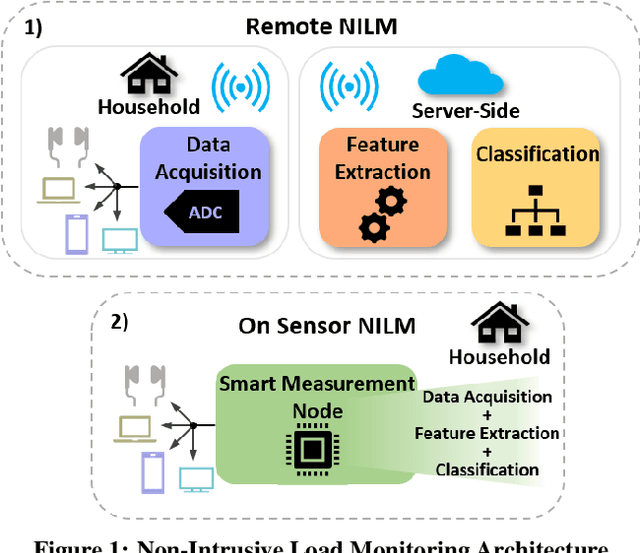
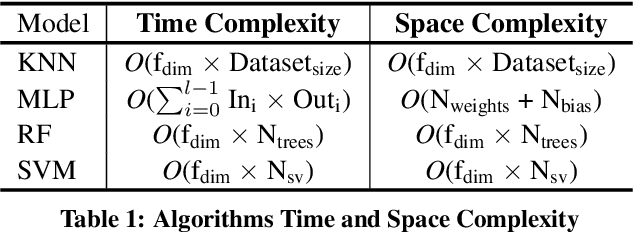

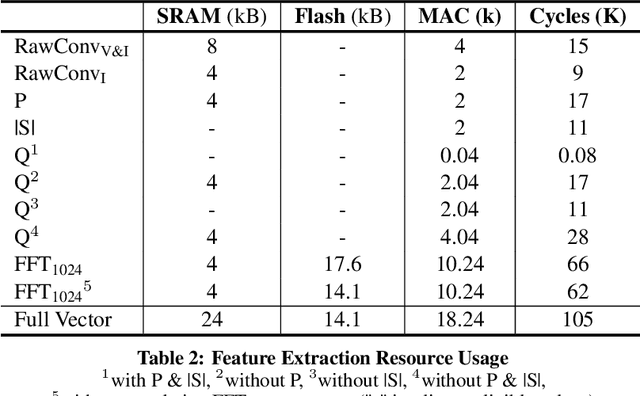
Non-Intrusive Load Monitoring (NILM) enables the disaggregation of the global power consumption of multiple loads, taken from a single smart electrical meter, into appliance-level details. State-of-the-Art approaches are based on Machine Learning methods and exploit the fusion of time- and frequency-domain features from current and voltage sensors. Unfortunately, these methods are compute-demanding and memory-intensive. Therefore, running low-latency NILM on low-cost, resource-constrained MCU-based meters is currently an open challenge. This paper addresses the optimization of the feature spaces as well as the computational and storage cost reduction needed for executing State-of-the-Art (SoA) NILM algorithms on memory- and compute-limited MCUs. We compare four supervised learning techniques on different classification scenarios and characterize the overall NILM pipeline's implementation on a MCU-based Smart Measurement Node. Experimental results demonstrate that optimizing the feature space enables edge MCU-based NILM with 95.15% accuracy, resulting in a small drop compared to the most-accurate feature vector deployment (96.19%) while achieving up to 5.45x speed-up and 80.56% storage reduction. Furthermore, we show that low-latency NILM relying only on current measurements reaches almost 80% accuracy, allowing a major cost reduction by removing voltage sensors from the hardware design.
YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers
Nov 14, 2018

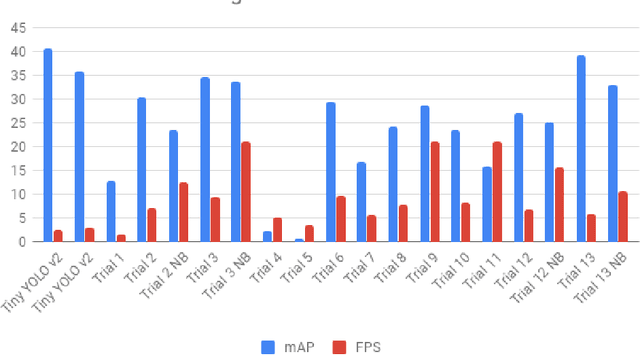
This paper focuses on YOLO-LITE, a real-time object detection model developed to run on portable devices such as a laptop or cellphone lacking a Graphics Processing Unit (GPU). The model was first trained on the PASCAL VOC dataset then on the COCO dataset, achieving a mAP of 33.81% and 12.26% respectively. YOLO-LITE runs at about 21 FPS on a non-GPU computer and 10 FPS after implemented onto a website with only 7 layers and 482 million FLOPS. This speed is 3.8x faster than the fastest state of art model, SSD MobilenetvI. Based on the original object detection algorithm YOLOV2, YOLO- LITE was designed to create a smaller, faster, and more efficient model increasing the accessibility of real-time object detection to a variety of devices.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 03, 2021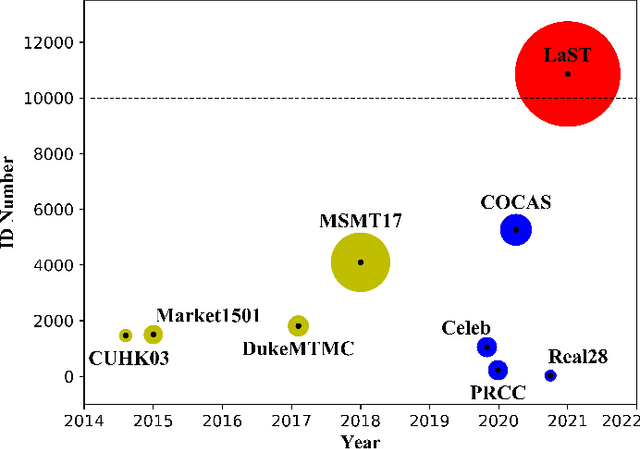
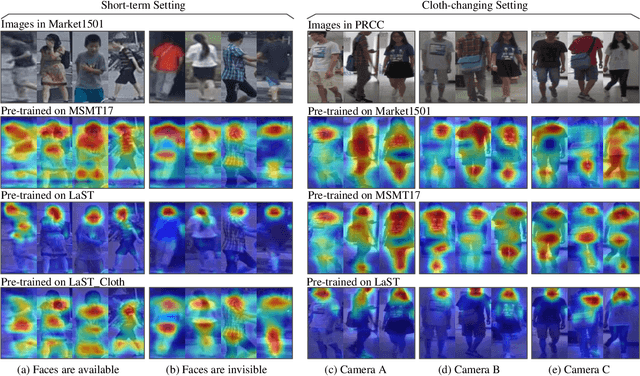
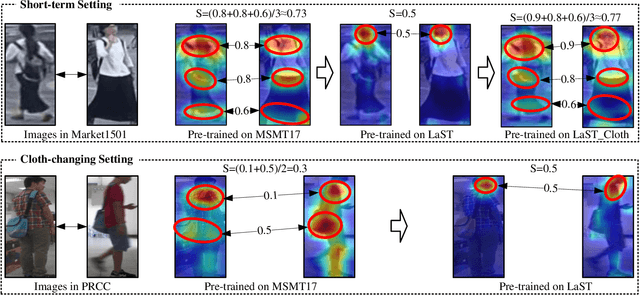

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal (LaST) person re-ID dataset, including 10,860 identities with more than 224k images. Compared with existing datasets, LaST presents more challenging and high-diversity reID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatiotemporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
May 06, 2021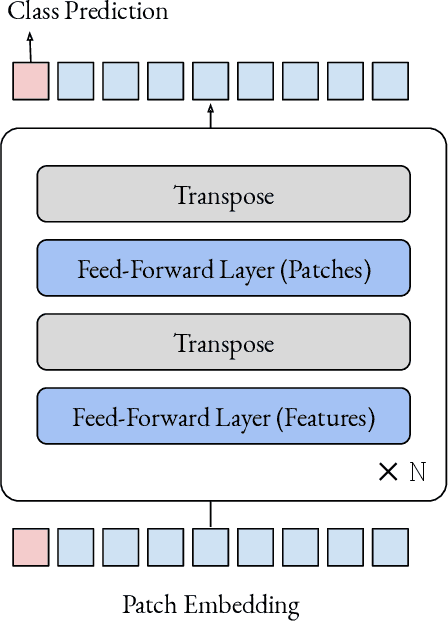
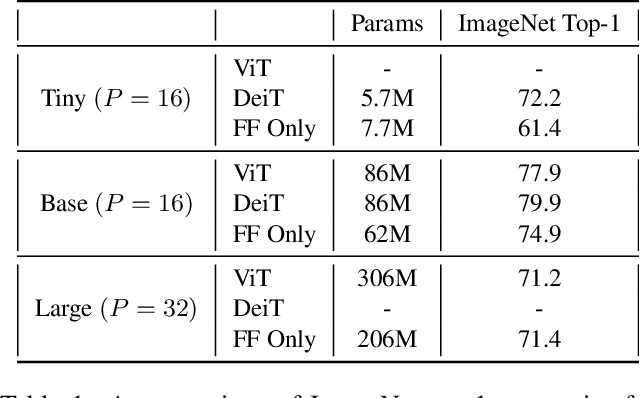

The strong performance of vision transformers on image classification and other vision tasks is often attributed to the design of their multi-head attention layers. However, the extent to which attention is responsible for this strong performance remains unclear. In this short report, we ask: is the attention layer even necessary? Specifically, we replace the attention layer in a vision transformer with a feed-forward layer applied over the patch dimension. The resulting architecture is simply a series of feed-forward layers applied over the patch and feature dimensions in an alternating fashion. In experiments on ImageNet, this architecture performs surprisingly well: a ViT/DeiT-base-sized model obtains 74.9\% top-1 accuracy, compared to 77.9\% and 79.9\% for ViT and DeiT respectively. These results indicate that aspects of vision transformers other than attention, such as the patch embedding, may be more responsible for their strong performance than previously thought. We hope these results prompt the community to spend more time trying to understand why our current models are as effective as they are.
A critical look at the current train/test split in machine learning
Jun 08, 2021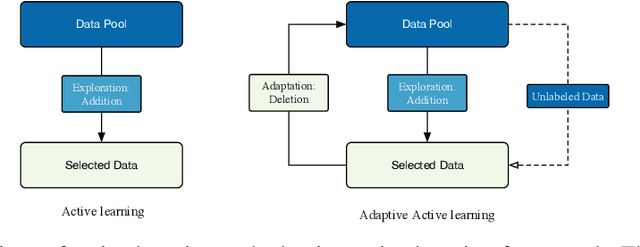

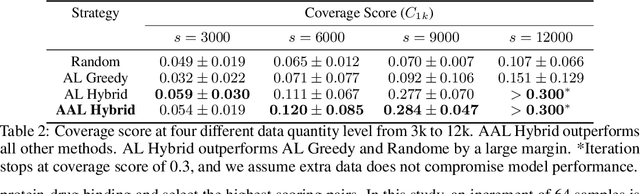
The randomized or cross-validated split of training and testing sets has been adopted as the gold standard of machine learning for decades. The establishment of these split protocols are based on two assumptions: (i)-fixing the dataset to be eternally static so we could evaluate different machine learning algorithms or models; (ii)-there is a complete set of annotated data available to researchers or industrial practitioners. However, in this article, we intend to take a closer and critical look at the split protocol itself and point out its weakness and limitation, especially for industrial applications. In many real-world problems, we must acknowledge that there are numerous situations where assumption (ii) does not hold. For instance, for interdisciplinary applications like drug discovery, it often requires real lab experiments to annotate data which poses huge costs in both time and financial considerations. In other words, it can be very difficult or even impossible to satisfy assumption (ii). In this article, we intend to access this problem and reiterate the paradigm of active learning, and investigate its potential on solving problems under unconventional train/test split protocols. We further propose a new adaptive active learning architecture (AAL) which involves an adaptation policy, in comparison with the traditional active learning that only unidirectionally adds data points to the training pool. We primarily justify our points by extensively investigating an interdisciplinary drug-protein binding problem. We additionally evaluate AAL on more conventional machine learning benchmarking datasets like CIFAR-10 to demonstrate the generalizability and efficacy of the new framework.