 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Algorithms for Differentially Private Stochastic Monotone Variational Inequalities and Saddle-Point Problems
Apr 07, 2021

In this work, we conduct the first systematic study of stochastic variational inequality (SVI) and stochastic saddle point (SSP) problems under the constraint of differential privacy-(DP). We propose two algorithms: Noisy Stochastic Extragradient (NSEG) and Noisy Inexact Stochastic Proximal Point (NISPP). We show that sampling with replacement variants of these algorithms attain the optimal risk for DP-SVI and DP-SSP. Key to our analysis is the investigation of algorithmic stability bounds, both of which are new even in the nonprivate case, together with a novel "stability implies generalization" result for the gap functions for SVI and SSP problems. The dependence of the running time of these algorithms, with respect to the dataset size $n$, is $n^2$ for NSEG and $\widetilde{O}(n^{3/2})$ for NISPP.
Deriving the Traveler Behavior Information from Social Media: A Case Study in Manhattan with Twitter
Jan 27, 2021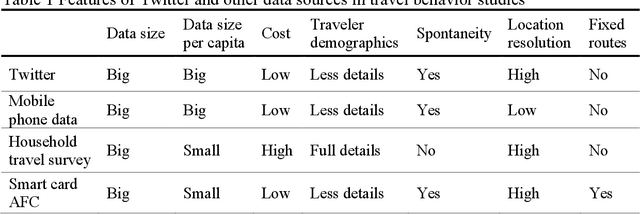
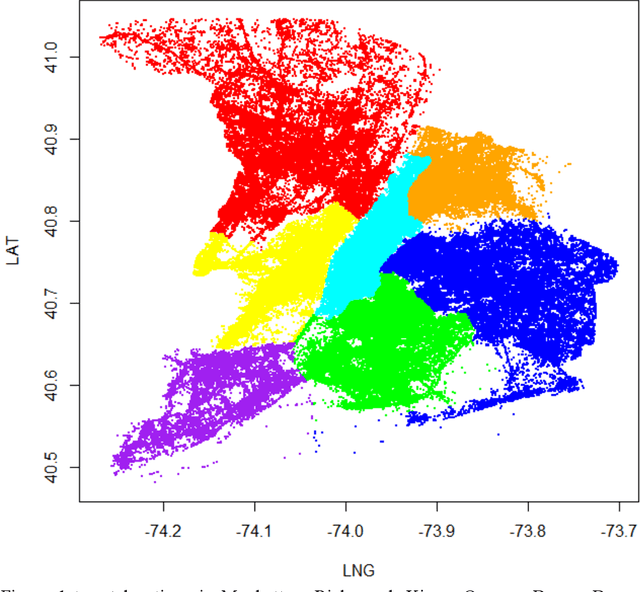

Social media platforms, such as Twitter, provide a totally new perspective in dealing with the traffic problems and is anticipated to complement the traditional methods. The geo-tagged tweets can provide the Twitter users' location information and is being applied in traveler behavior analysis. This paper explores the full potentials of Twitter in deriving travel behavior information and conducts a case study in Manhattan Area. A systematic method is proposed to extract displacement information from Twitter locations. Our study shows that Twitter has a unique demographics which combine not only local residents but also the tourists or passengers. For individual user, Twitter can uncover his/her travel behavior features including the time-of-day and location distributions on both weekdays and weekends. For all Twitter users, the aggregated travel behavior results also show that the time-of-day travel patterns in Manhattan Island resemble that of the traffic flow; the identification of OD pattern is also promising by comparing with the results of travel survey.
Policy Fusion for Adaptive and Customizable Reinforcement Learning Agents
Apr 21, 2021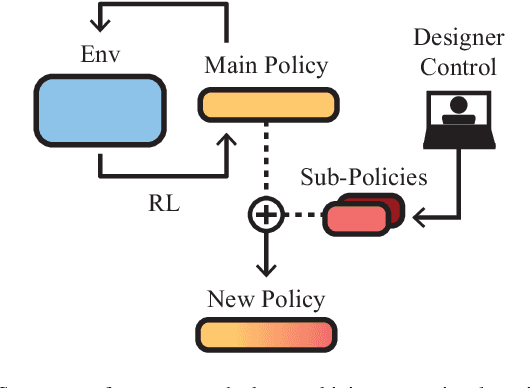
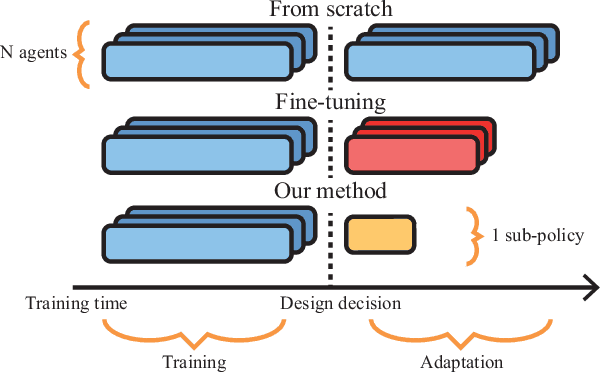
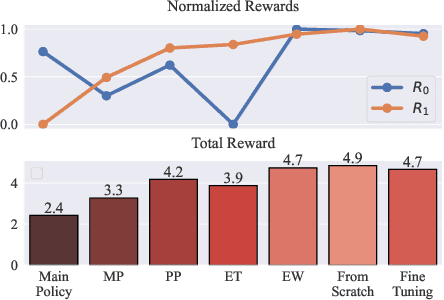
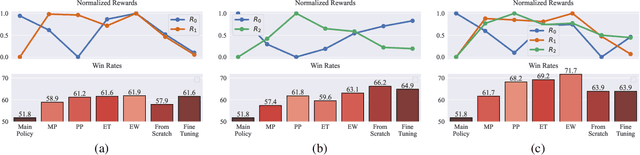
In this article we study the problem of training intelligent agents using Reinforcement Learning for the purpose of game development. Unlike systems built to replace human players and to achieve super-human performance, our agents aim to produce meaningful interactions with the player, and at the same time demonstrate behavioral traits as desired by game designers. We show how to combine distinct behavioral policies to obtain a meaningful "fusion" policy which comprises all these behaviors. To this end, we propose four different policy fusion methods for combining pre-trained policies. We further demonstrate how these methods can be used in combination with Inverse Reinforcement Learning in order to create intelligent agents with specific behavioral styles as chosen by game designers, without having to define many and possibly poorly-designed reward functions. Experiments on two different environments indicate that entropy-weighted policy fusion significantly outperforms all others. We provide several practical examples and use-cases for how these methods are indeed useful for video game production and designers.
AdvantageNAS: Efficient Neural Architecture Search with Credit Assignment
Dec 11, 2020



Neural architecture search (NAS) is an approach for automatically designing a neural network architecture without human effort or expert knowledge. However, the high computational cost of NAS limits its use in commercial applications. Two recent NAS paradigms, namely one-shot and sparse propagation, which reduce the time and space complexities, respectively, provide clues for solving this problem. In this paper, we propose a novel search strategy for one-shot and sparse propagation NAS, namely AdvantageNAS, which further reduces the time complexity of NAS by reducing the number of search iterations. AdvantageNAS is a gradient-based approach that improves the search efficiency by introducing credit assignment in gradient estimation for architecture updates. Experiments on the NAS-Bench-201 and PTB dataset show that AdvantageNAS discovers an architecture with higher performance under a limited time budget compared to existing sparse propagation NAS. To further reveal the reliabilities of AdvantageNAS, we investigate it theoretically and find that it monotonically improves the expected loss and thus converges.
DuctTake: Spatiotemporal Video Compositing
Jan 12, 2021DuctTake is a system designed to enable practical compositing of multiple takes of a scene into a single video. Current industry solutions are based around object segmentation, a hard problem that requires extensive manual input and cleanup, making compositing an expensive part of the film-making process. Our method instead composites shots together by finding optimal spatiotemporal seams using motion-compensated 3D graph cuts through the video volume. We describe in detail the required components, decisions, and new techniques that together make a usable, interactive tool for compositing HD video, paying special attention to running time and performance of each section. We validate our approach by presenting a wide variety of examples and by comparing result quality and creation time to composites made by professional artists using current state-of-the-art tools.
Self-learning Machines based on Hamiltonian Echo Backpropagation
Mar 08, 2021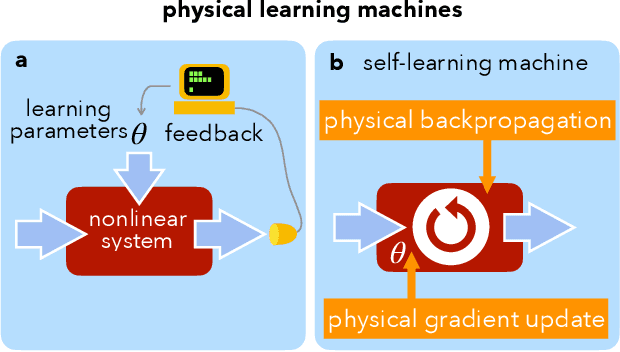
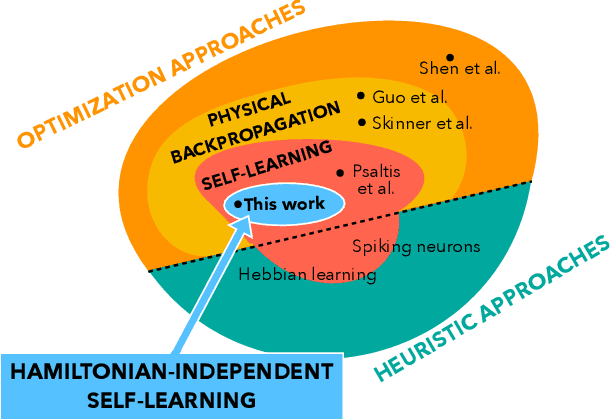
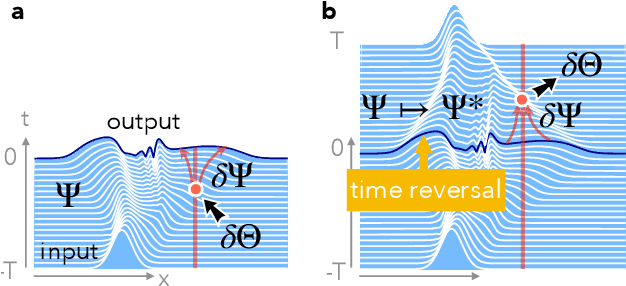
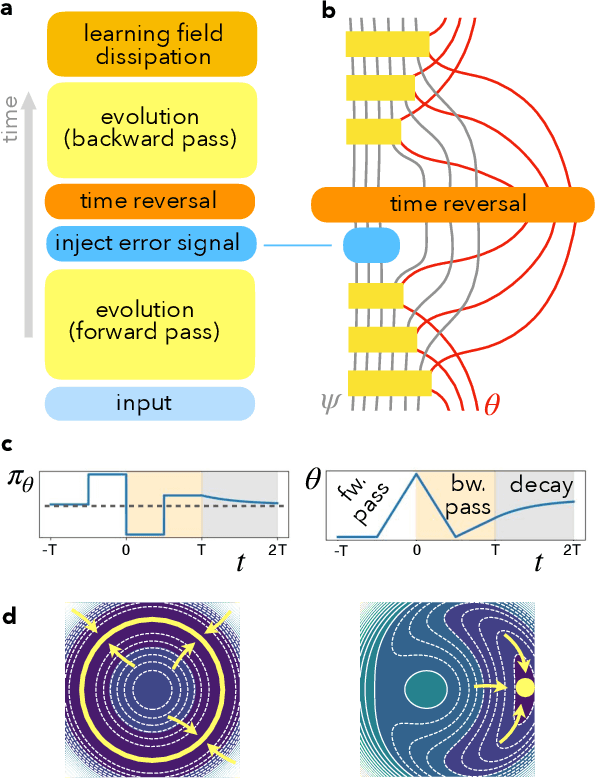
A physical self-learning machine can be defined as a nonlinear dynamical system that can be trained on data (similar to artificial neural networks), but where the update of the internal degrees of freedom that serve as learnable parameters happens autonomously. In this way, neither external processing and feedback nor knowledge of (and control of) these internal degrees of freedom is required. We introduce a general scheme for self-learning in any time-reversible Hamiltonian system. We illustrate the training of such a self-learning machine numerically for the case of coupled nonlinear wave fields.
Eye Know You: Metric Learning for End-to-end Biometric Authentication Using Eye Movements from a Longitudinal Dataset
Apr 21, 2021



While numerous studies have explored eye movement biometrics since the modality's inception in 2004, the permanence of eye movements remains largely unexplored as most studies utilize datasets collected within a short time frame. This paper presents a convolutional neural network for authenticating users using their eye movements. The network is trained with an established metric learning loss function, multi-similarity loss, which seeks to form a well-clustered embedding space and directly enables the enrollment and authentication of out-of-sample users. Performance measures are computed on GazeBase, a task-diverse and publicly-available dataset collected over a 37-month period. This study includes an exhaustive analysis of the effects of training on various tasks and downsampling from 1000 Hz to several lower sampling rates. Our results reveal that reasonable authentication accuracy may be achieved even during a low-cognitive-load task or at low sampling rates. Moreover, we find that eye movements are quite resilient against template aging after 3 years.
Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models
Mar 08, 2021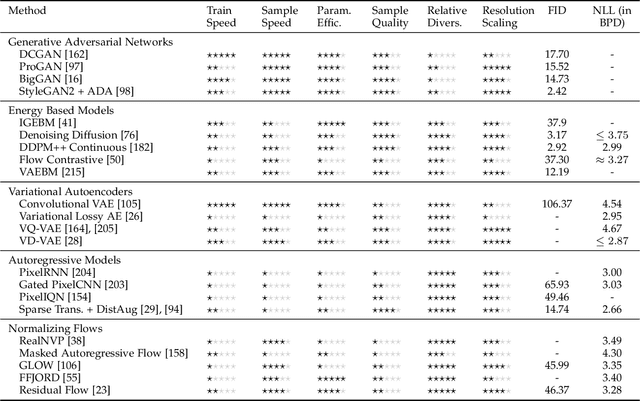
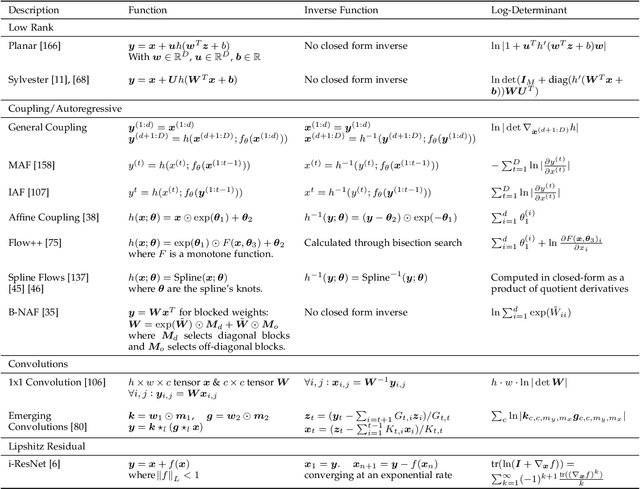
Deep generative modelling is a class of techniques that train deep neural networks to model the distribution of training samples. Research has fragmented into various interconnected approaches, each of which making trade-offs including run-time, diversity, and architectural restrictions. In particular, this compendium covers energy-based models, variational autoencoders, generative adversarial networks, autoregressive models, normalizing flows, in addition to numerous hybrid approaches. These techniques are drawn under a single cohesive framework, comparing and contrasting to explain the premises behind each, while reviewing current state-of-the-art advances and implementations.
The Generalized Mean Densest Subgraph Problem
Jun 02, 2021



Finding dense subgraphs of a large graph is a standard problem in graph mining that has been studied extensively both for its theoretical richness and its many practical applications. In this paper we introduce a new family of dense subgraph objectives, parameterized by a single parameter $p$, based on computing generalized means of degree sequences of a subgraph. Our objective captures both the standard densest subgraph problem and the maximum $k$-core as special cases, and provides a way to interpolate between and extrapolate beyond these two objectives when searching for other notions of dense subgraphs. In terms of algorithmic contributions, we first show that our objective can be minimized in polynomial time for all $p \geq 1$ using repeated submodular minimization. A major contribution of our work is analyzing the performance of different types of peeling algorithms for dense subgraphs both in theory and practice. We prove that the standard peeling algorithm can perform arbitrarily poorly on our generalized objective, but we then design a more sophisticated peeling method which for $p \geq 1$ has an approximation guarantee that is always at least $1/2$ and converges to 1 as $p \rightarrow \infty$. In practice, we show that this algorithm obtains extremely good approximations to the optimal solution, scales to large graphs, and highlights a range of different meaningful notions of density on graphs coming from numerous domains. Furthermore, it is typically able to approximate the densest subgraph problem better than the standard peeling algorithm, by better accounting for how the removal of one node affects other nodes in its neighborhood.
Search Algorithms for Automated Hyper-Parameter Tuning
Apr 29, 2021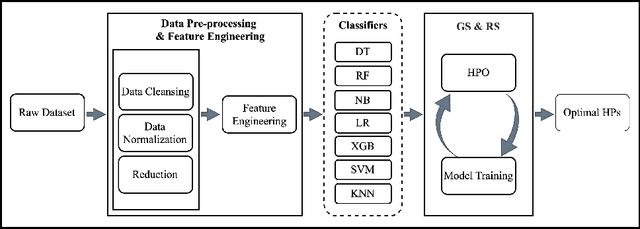
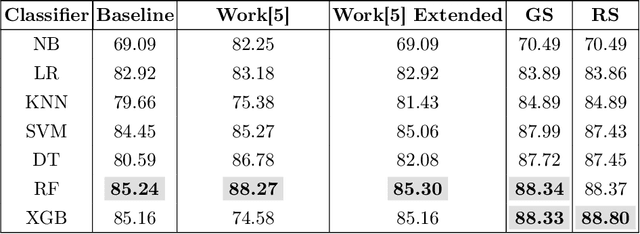
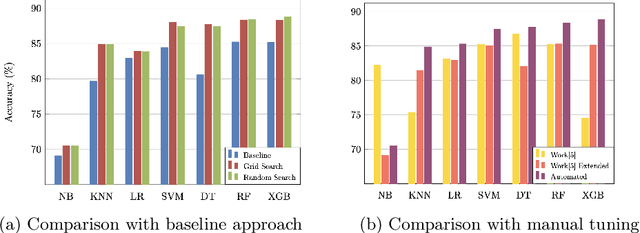
Machine learning is a powerful method for modeling in different fields such as education. Its capability to accurately predict students' success makes it an ideal tool for decision-making tasks related to higher education. The accuracy of machine learning models depends on selecting the proper hyper-parameters. However, it is not an easy task because it requires time and expertise to tune the hyper-parameters to fit the machine learning model. In this paper, we examine the effectiveness of automated hyper-parameter tuning techniques to the realm of students' success. Therefore, we develop two automated Hyper-Parameter Optimization methods, namely grid search and random search, to assess and improve a previous study's performance. The experiment results show that applying random search and grid search on machine learning algorithms improves accuracy. We empirically show automated methods' superiority on real-world educational data (MIDFIELD) for tuning HPs of conventional machine learning classifiers. This work emphasizes the effectiveness of automated hyper-parameter optimization while applying machine learning in the education field to aid faculties, directors', or non-expert users' decisions to improve students' success.