 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Learning on Monocular Videos for 3D Human Pose Estimation
Dec 02, 2020
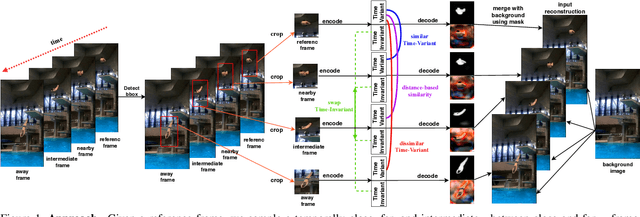
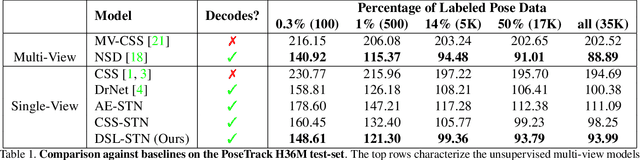
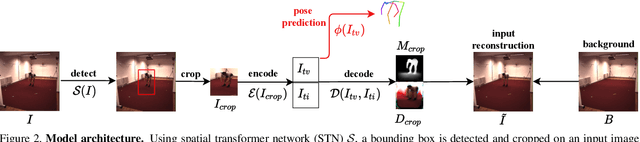
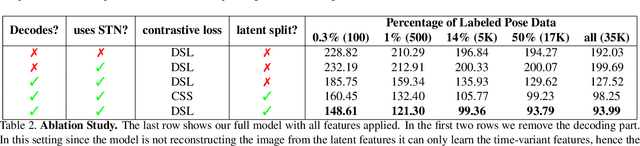
In this paper, we introduce an unsupervised feature extraction method that exploits contrastive self-supervised (CSS) learning to extract rich latent vectors from single-view videos. Instead of simply treating the latent features of nearby frames as positive pairs and those of temporally-distant ones as negative pairs as in other CSS approaches, we explicitly separate each latent vector into a time-variant component and a time-invariant one. We then show that applying CSS only to the time-variant features, while also reconstructing the input and encouraging a gradual transition between nearby and away features yields a rich latent space, well-suited for human pose estimation. Our approach outperforms other unsupervised single-view methods and match the performance of multi-view techniques.
Discovering an Aid Policy to Minimize Student Evasion Using Offline Reinforcement Learning
Apr 20, 2021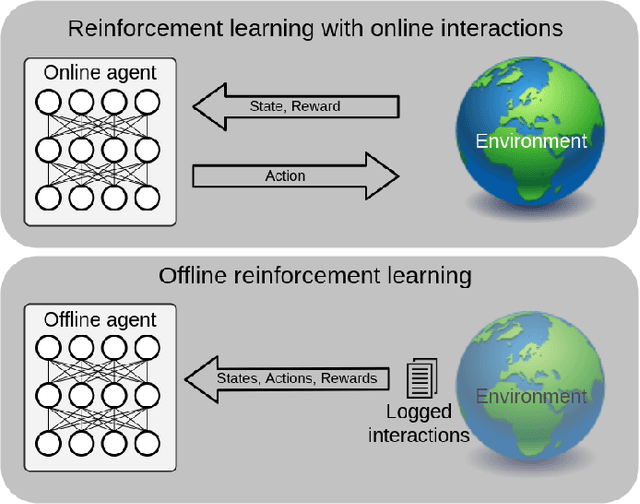
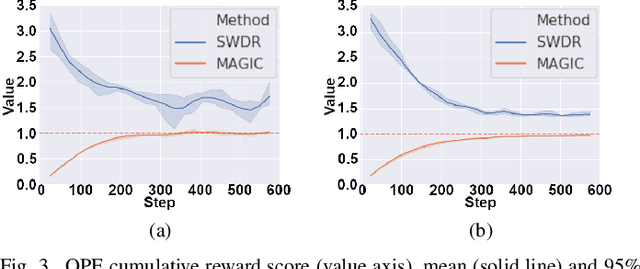
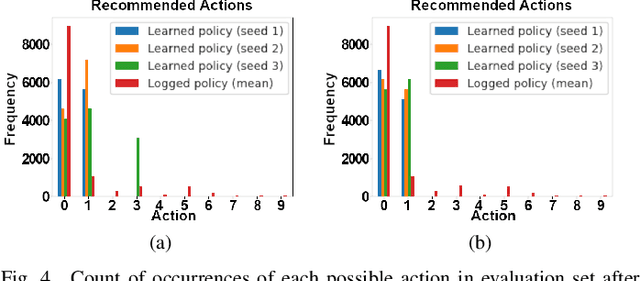
High dropout rates in tertiary education expose a lack of efficiency that causes frustration of expectations and financial waste. Predicting students at risk is not enough to avoid student dropout. Usually, an appropriate aid action must be discovered and applied in the proper time for each student. To tackle this sequential decision-making problem, we propose a decision support method to the selection of aid actions for students using offline reinforcement learning to support decision-makers effectively avoid student dropout. Additionally, a discretization of student's state space applying two different clustering methods is evaluated. Our experiments using logged data of real students shows, through off-policy evaluation, that the method should achieve roughly 1.0 to 1.5 times as much cumulative reward as the logged policy. So, it is feasible to help decision-makers apply appropriate aid actions and, possibly, reduce student dropout.
Variational Bayes Estimation of Discrete-Margined Copula Models with Application to Time Series
Jul 20, 2018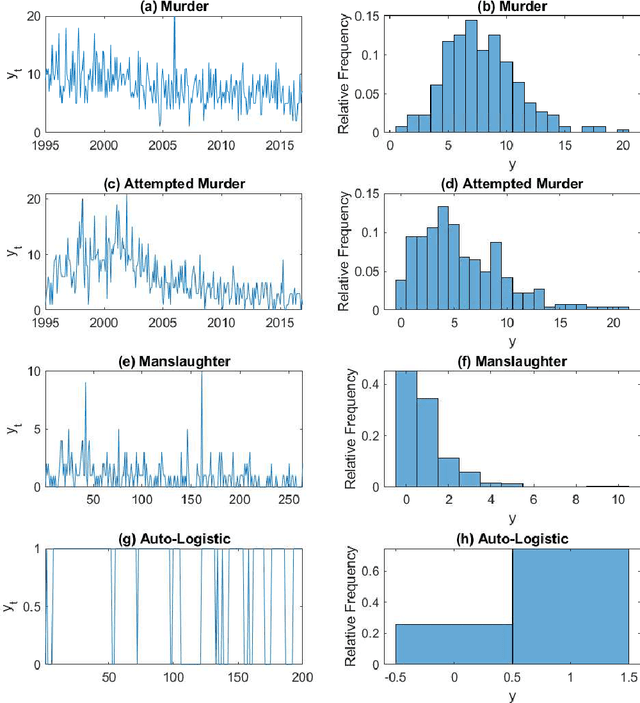
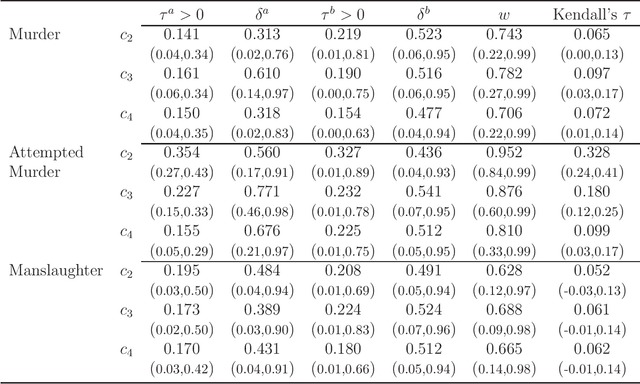
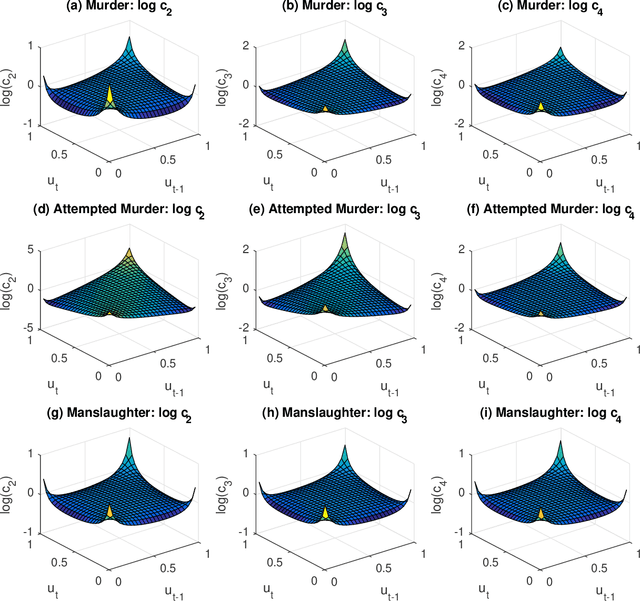
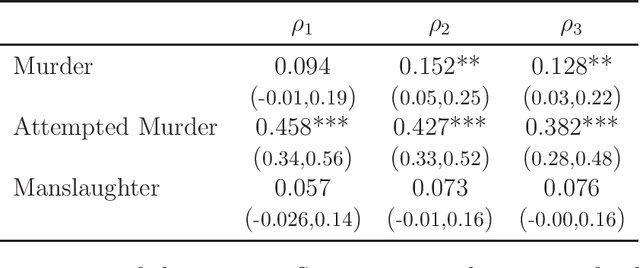
We propose a new variational Bayes estimator for high-dimensional copulas with discrete, or a combination of discrete and continuous, margins. The method is based on a variational approximation to a tractable augmented posterior, and is faster than previous likelihood-based approaches. We use it to estimate drawable vine copulas for univariate and multivariate Markov ordinal and mixed time series. These have dimension $rT$, where $T$ is the number of observations and $r$ is the number of series, and are difficult to estimate using previous methods. The vine pair-copulas are carefully selected to allow for heteroskedasticity, which is a feature of most ordinal time series data. When combined with flexible margins, the resulting time series models also allow for other common features of ordinal data, such as zero inflation, multiple modes and under- or over-dispersion. Using six example series, we illustrate both the flexibility of the time series copula models, and the efficacy of the variational Bayes estimator for copulas of up to 792 dimensions and 60 parameters. This far exceeds the size and complexity of copula models for discrete data that can be estimated using previous methods.
Hybrid Evolutionary Optimization Approach for Oilfield Well Control Optimization
Mar 29, 2021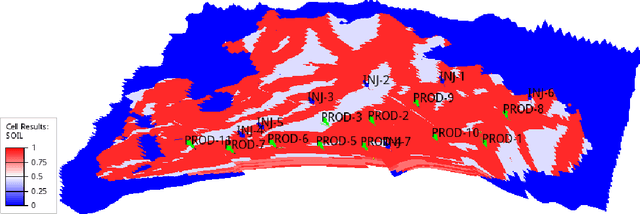

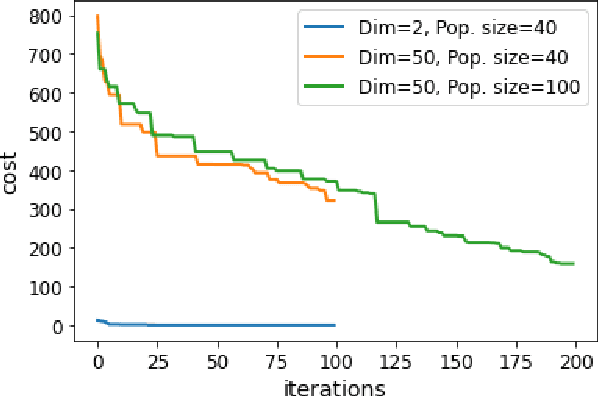

Oilfield production optimization is challenging due to subsurface model complexity and associated non-linearity, large number of control parameters, large number of production scenarios, and subsurface uncertainties. Optimization involves time-consuming reservoir simulation studies to compare different production scenarios and settings. This paper presents efficacy of two hybrid evolutionary optimization approaches for well control optimization of a waterflooding operation, and demonstrates their application using Olympus benchmark. A simpler, weighted sum of cumulative fluid (WCF) is used as objective function first, which is then replaced by net present value (NPV) of discounted cash-flow for comparison. Two popular evolutionary optimization algorithms, genetic algorithm (GA) and particle swarm optimization (PSO), are first used in standalone mode to solve well control optimization problem. Next, both GA and PSO methods are used with another popular optimization algorithm, covariance matrix adaptation-evolution strategy (CMA-ES), in hybrid mode. Hybrid optimization run is made by transferring the resulting population from one algorithm to the next as its starting population for further improvement. Approximately four thousand simulation runs are needed for standalone GA and PSO methods to converge, while six thousand runs are needed in case of two hybrid optimization modes (GA-CMA-ES and PSO-CMA-ES). To reduce turn-around time, commercial cloud computing is used and simulation workload is distributed using parallel programming. GA and PSO algorithms have a good balance between exploratory and exploitative properties, thus are able identify regions of interest. CMA-ES algorithm is able to further refine the solution using its excellent exploitative properties. Thus, GA or PSO with CMA-ES in hybrid mode yields better optimization result as compared to standalone GA or PSO algorithms.
Convergence Analysis and System Design for Federated Learning over Wireless Networks
Apr 30, 2021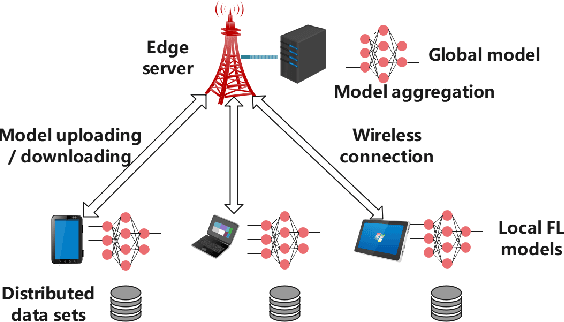
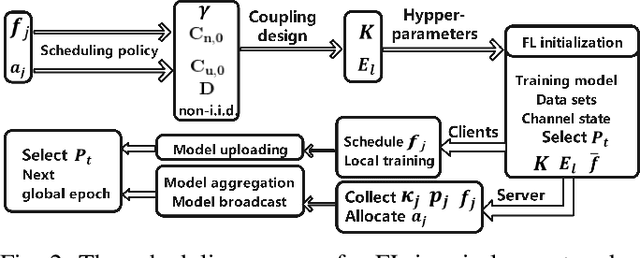
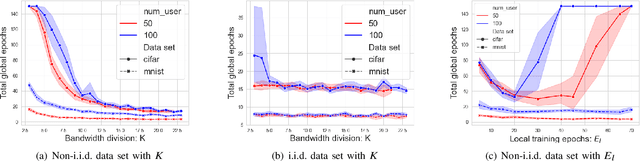
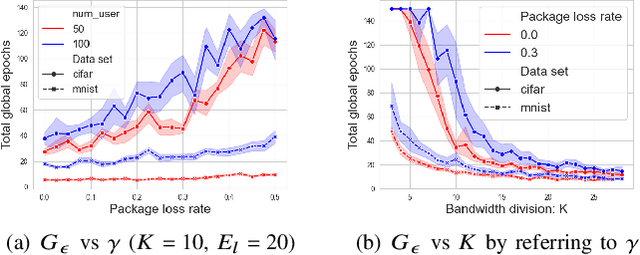
Federated learning (FL) has recently emerged as an important and promising learning scheme in IoT, enabling devices to jointly learn a model without sharing their raw data sets. However, as the training data in FL is not collected and stored centrally, FL training requires frequent model exchange, which is largely affected by the wireless communication network. Therein, limited bandwidth and random package loss restrict interactions in training. Meanwhile, the insufficient message synchronization among distributed clients could also affect FL convergence. In this paper, we analyze the convergence rate of FL training considering the joint impact of communication network and training settings. Further by considering the training costs in terms of time and power, the optimal scheduling problems for communication networks are formulated. The developed theoretical results can be used to assist the system parameter selections and explain the principle of how the wireless communication system could influence the distributed training process and network scheduling.
Recognition of handwritten MNIST digits on low-memory 2 Kb RAM Arduino board using LogNNet reservoir neural network
Apr 20, 2021The presented compact algorithm for recognizing handwritten digits of the MNIST database, created on the LogNNet reservoir neural network, reaches the recognition accuracy of 82%. The algorithm was tested on a low-memory Arduino board with 2 Kb static RAM low-power microcontroller. The dependences of the accuracy and time of image recognition on the number of neurons in the reservoir have been investigated. The memory allocation demonstrates that the algorithm stores all the necessary information in RAM without using additional data storage, and operates with original images without preliminary processing. The simple structure of the algorithm, with appropriate training, can be adapted for wide practical application, for example, for creating mobile biosensors for early diagnosis of adverse events in medicine. The study results are important for the implementation of artificial intelligence on peripheral constrained IoT devices and for edge computing.
Demographic-Guided Attention in Recurrent Neural Networks for Modeling Neuropathophysiological Heterogeneity
Apr 15, 2021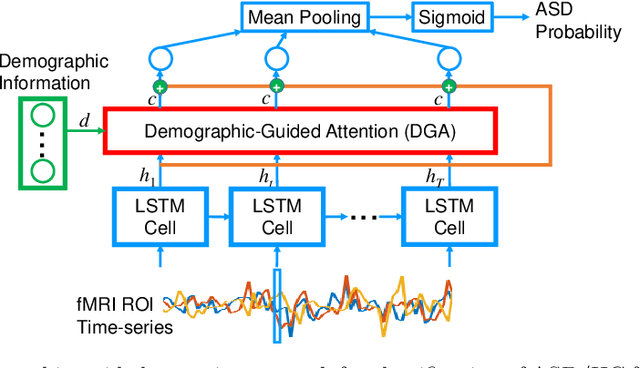
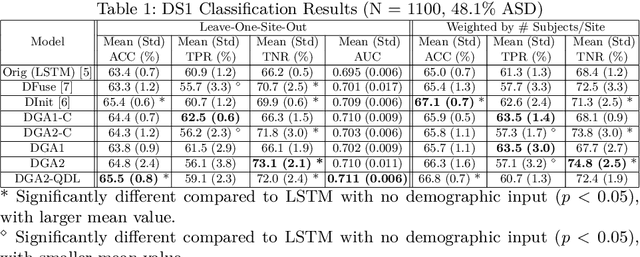
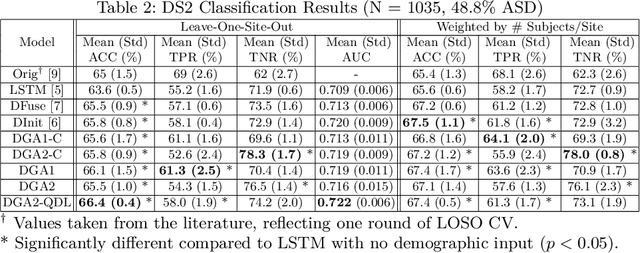
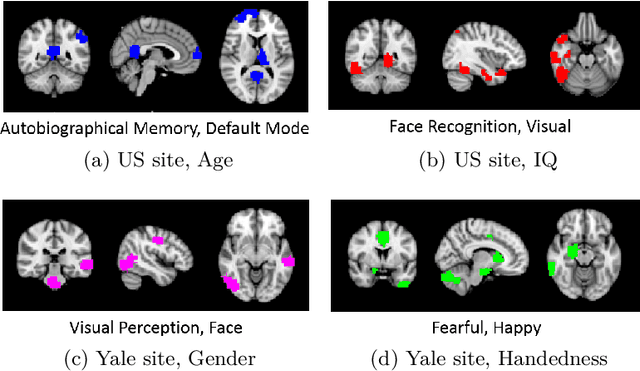
Heterogeneous presentation of a neurological disorder suggests potential differences in the underlying pathophysiological changes that occur in the brain. We propose to model heterogeneous patterns of functional network differences using a demographic-guided attention (DGA) mechanism for recurrent neural network models for prediction from functional magnetic resonance imaging (fMRI) time-series data. The context computed from the DGA head is used to help focus on the appropriate functional networks based on individual demographic information. We demonstrate improved classification on 3 subsets of the ABIDE I dataset used in published studies that have previously produced state-of-the-art results, evaluating performance under a leave-one-site-out cross-validation framework for better generalizeability to new data. Finally, we provide examples of interpreting functional network differences based on individual demographic variables.
Wearable Sensors for Spatio-Temporal Grip Force Profiling
Jan 16, 2021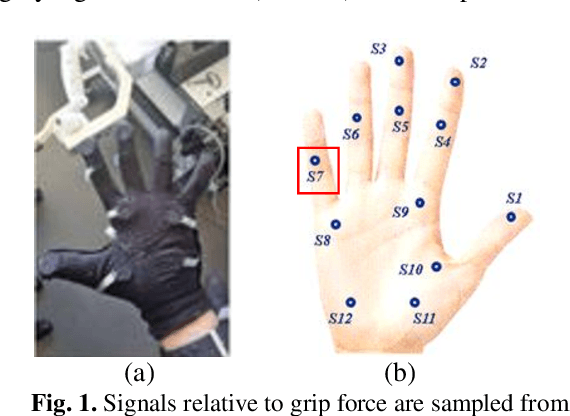
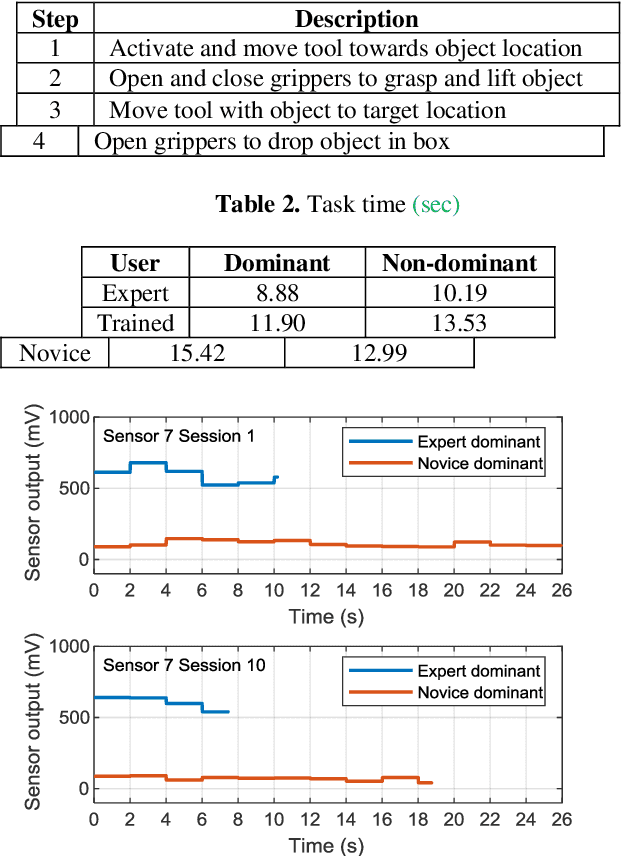
Wearable biosensor technology enables real-time, convenient, and continuous monitoring of users behavioral signals. Such include signals relative to body motion, body temperature, biological or biochemical markers, and individual grip forces, which are studied in this paper. A four step pick and drop image guided and robot assisted precision task has been designed for exploiting a wearable wireless sensor glove system. Individual spatio temporal grip forces are analyzed on the basis of thousands of individual sensor data, collected from different locations on the dominant and non-dominant hands of each of three users in ten successive task sessions. Statistical comparisons reveal specific differences between grip force profiles of the individual users as a function of task skill level (expertise) and time.
Self-supervised on Graphs: Contrastive, Generative,or Predictive
May 16, 2021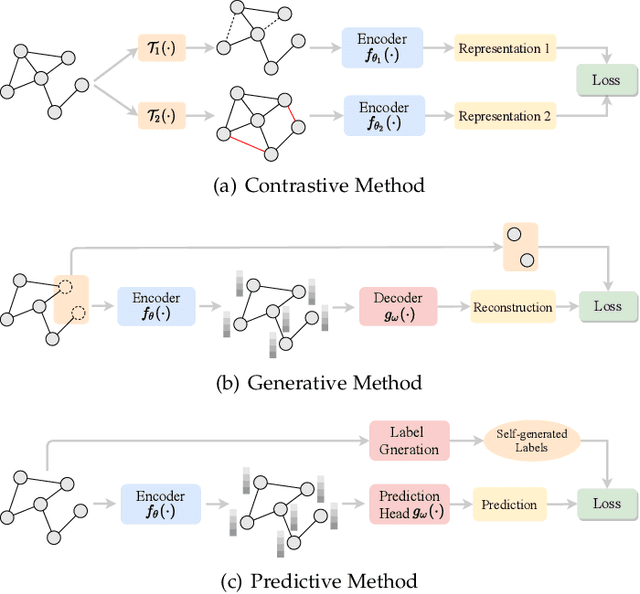
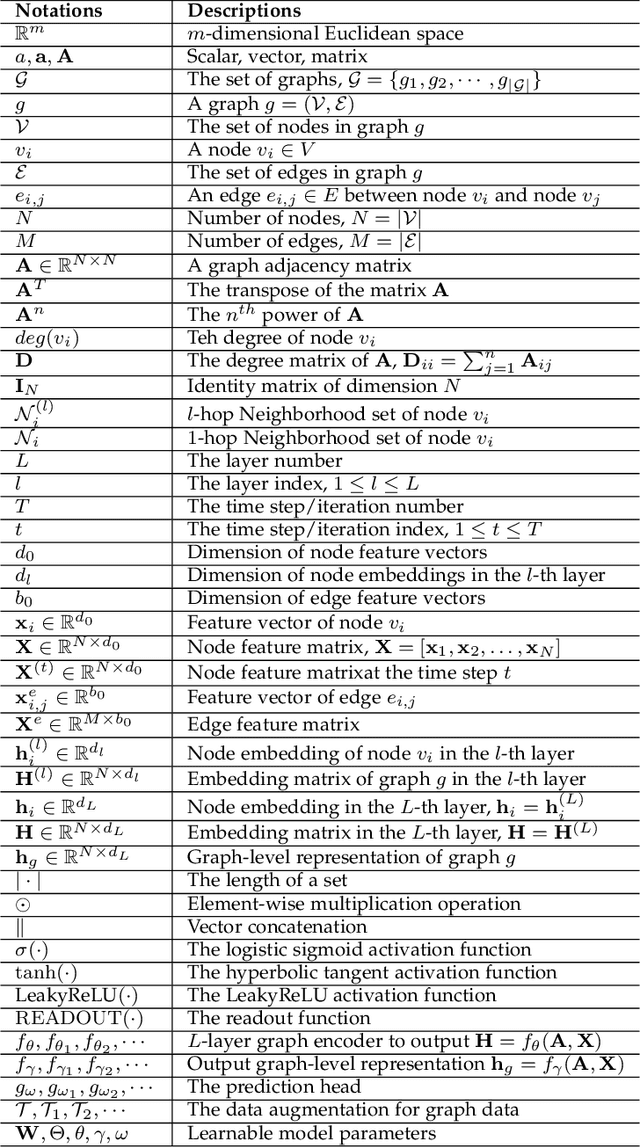
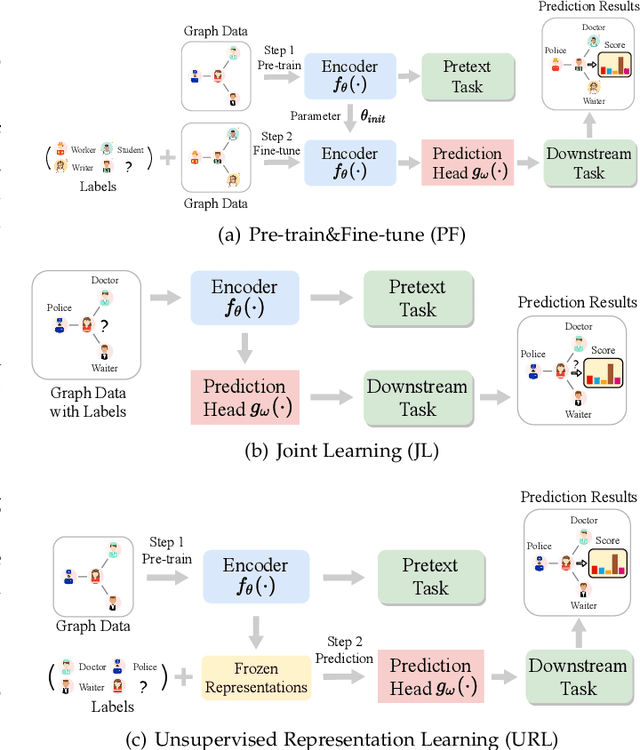
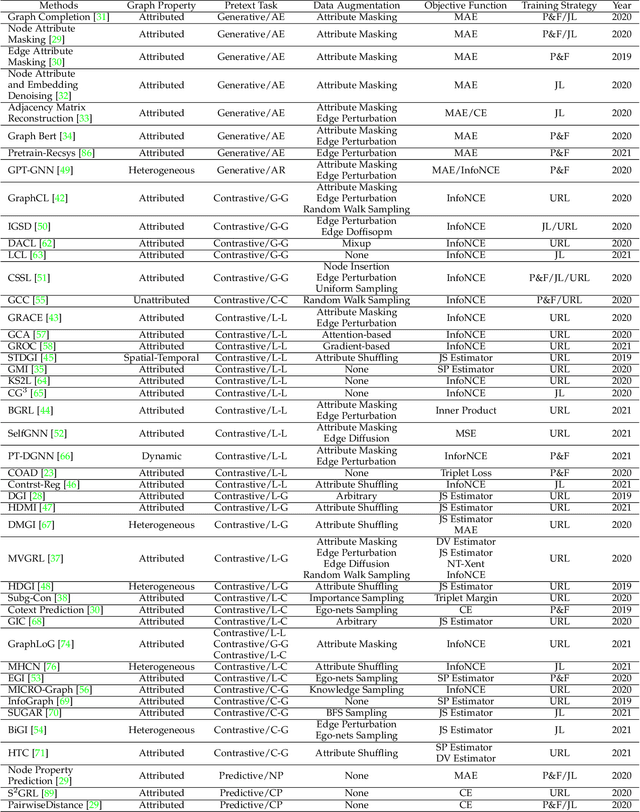
Deep learning on graphs has recently achieved remarkable success on a variety of tasks while such success relies heavily on the massive and carefully labeled data. However, precise annotations are generally very expensive and time-consuming. To address this problem, self-supervised learning (SSL) is emerging as a new paradigm for extracting informative knowledge through well-designed pretext tasks without relying on manual labels. In this survey, we extend the concept of SSL, which first emerged in the fields of computer vision and natural language processing, to present a timely and comprehensive review of the existing SSL techniques for graph data. Specifically, we divide existing graph SSL methods into three categories: contrastive, generative, and predictive. More importantly, unlike many other surveys that only provide a high-level description of published research, we present an additional mathematical summary of the existing works in a unified framework. Furthermore, to facilitate methodological development and empirical comparisons, we also summarize the commonly used datasets, evaluation metrics, downstream tasks, and open-source implementations of various algorithms. Finally, we discuss the technical challenges and potential future directions for improving graph self-supervised learning.
A Spacecraft Dataset for Detection, Segmentation and Parts Recognition
Jun 15, 2021
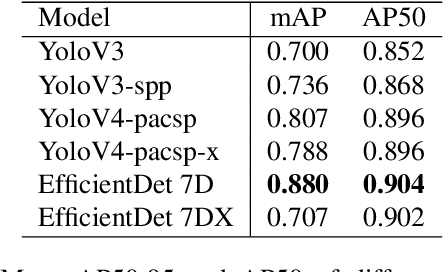

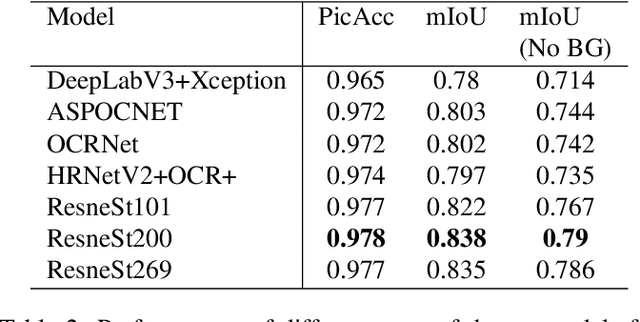
Virtually all aspects of modern life depend on space technology. Thanks to the great advancement of computer vision in general and deep learning-based techniques in particular, over the decades, the world witnessed the growing use of deep learning in solving problems for space applications, such as self-driving robot, tracers, insect-like robot on cosmos and health monitoring of spacecraft. These are just some prominent examples that has advanced space industry with the help of deep learning. However, the success of deep learning models requires a lot of training data in order to have decent performance, while on the other hand, there are very limited amount of publicly available space datasets for the training of deep learning models. Currently, there is no public datasets for space-based object detection or instance segmentation, partly because manually annotating object segmentation masks is very time consuming as they require pixel-level labelling, not to mention the challenge of obtaining images from space. In this paper, we aim to fill this gap by releasing a dataset for spacecraft detection, instance segmentation and part recognition. The main contribution of this work is the development of the dataset using images of space stations and satellites, with rich annotations including bounding boxes of spacecrafts and masks to the level of object parts, which are obtained with a mixture of automatic processes and manual efforts. We also provide evaluations with state-of-the-art methods in object detection and instance segmentation as a benchmark for the dataset. The link for downloading the proposed dataset can be found on https://github.com/Yurushia1998/SatelliteDataset.