 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Joint State Inference and Learning of Partially Unknown State-Space Models
Feb 15, 2021
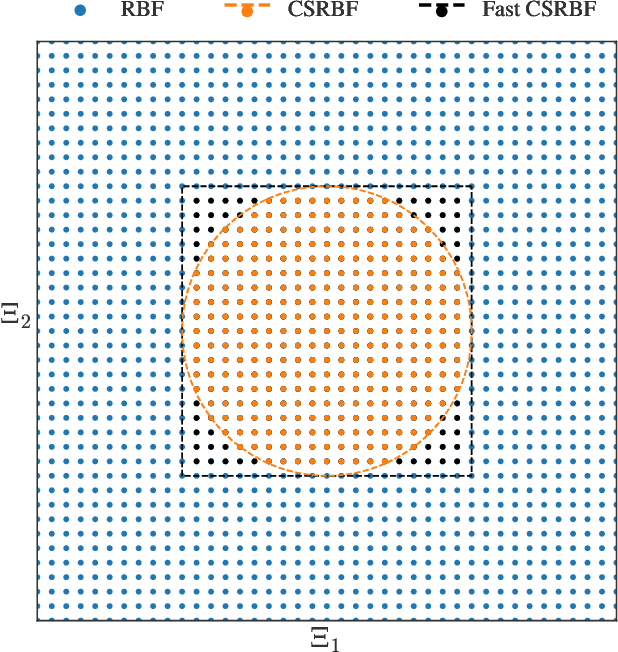
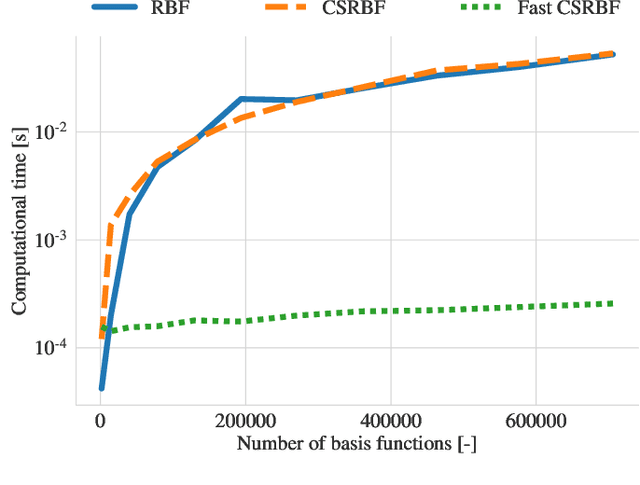
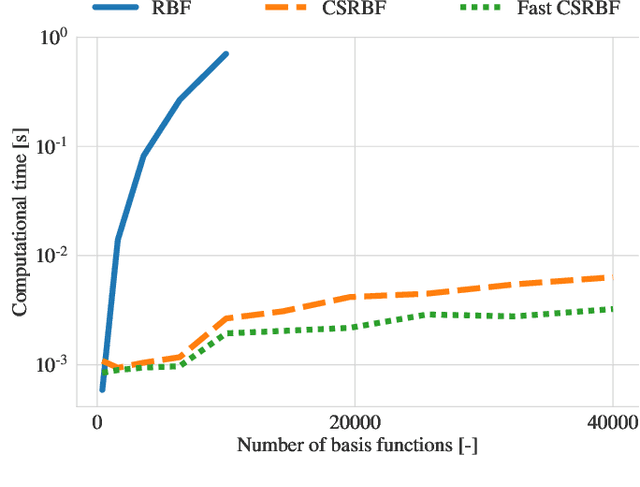

A computationally efficient method for online joint state inference and dynamical model learning is presented. The dynamical model combines an a priori known state-space model with a radial basis function expansion representing unknown system dynamics. Thus, the model is inherently adaptive and can learn unknown and changing system dynamics on-the-fly. Still, by including prior knowledge in the model description, a minimum of estimation performance can be guaranteed already from the start, which is of utmost importance in, e.g., safety-critical applications. The method uses an extended Kalman filter approach to jointly estimate the state of the system and learn the system properties, via the parameters of the basis function expansion. By using compact radial basis functions and an approximate Kalman gain, the computational complexity is considerably reduced compared to similar approaches. The approximation works well when the system dynamics exhibit limited correlation between points well separated in the state-space domain. The method is exemplified via two intelligent vehicle applications where it is shown to: (i) have essentially identical system dynamics estimation performance compared to similar non-real-time algorithms, and (ii) be real-time applicable to large-scale problems.
Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction
May 16, 2021
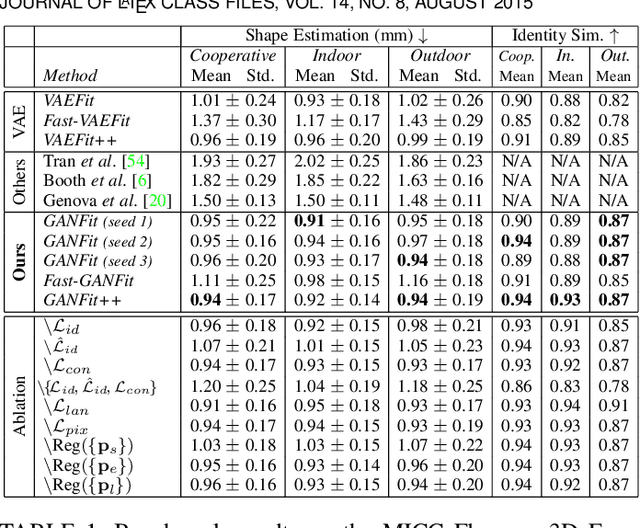
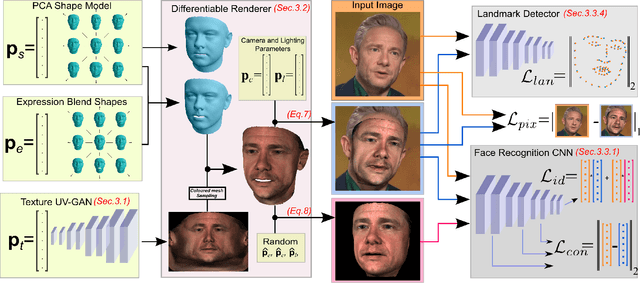
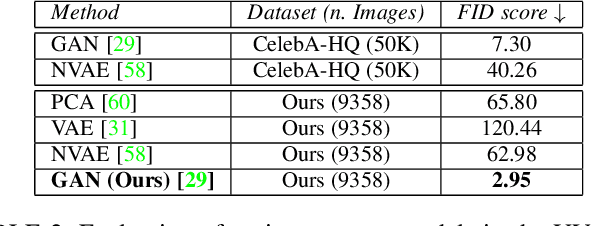
A lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the recent works, the texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction is still not capable of modeling facial texture with high-frequency details. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful facial texture prior \edit{from a large-scale 3D texture dataset}. Then, we revisit the original 3D Morphable Models (3DMMs) fitting making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. In order to be robust towards initialisation and expedite the fitting process, we propose a novel self-supervised regression based approach. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
Conservative Contextual Combinatorial Cascading Bandit
Apr 23, 2021
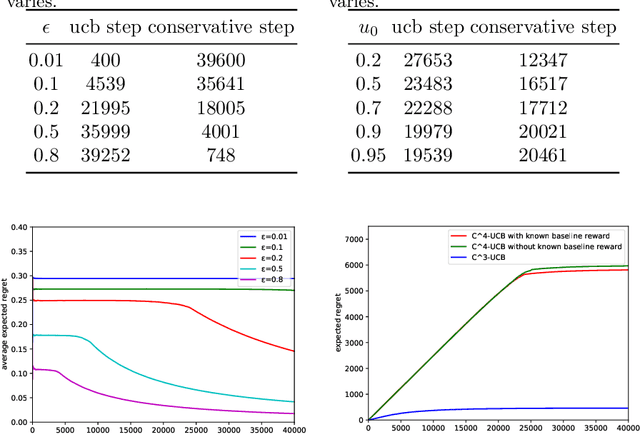
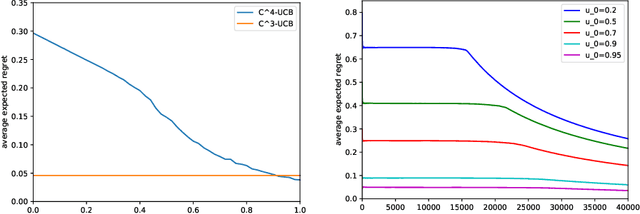
Conservative mechanism is a desirable property in decision-making problems which balance the tradeoff between the exploration and exploitation. We propose the novel \emph{conservative contextual combinatorial cascading bandit ($C^4$-bandit)}, a cascading online learning game which incorporates the conservative mechanism. At each time step, the learning agent is given some contexts and has to recommend a list of items but not worse than the base strategy and then observes the reward by some stopping rules. We design the $C^4$-UCB algorithm to solve the problem and prove its n-step upper regret bound for two situations: known baseline reward and unknown baseline reward. The regret in both situations can be decomposed into two terms: (a) the upper bound for the general contextual combinatorial cascading bandit; and (b) a constant term for the regret from the conservative mechanism. We also improve the bound of the conservative contextual combinatorial bandit as a by-product. Experiments on synthetic data demonstrate its advantages and validate our theoretical analysis.
Modular Procedural Generation for Voxel Maps
Apr 18, 2021

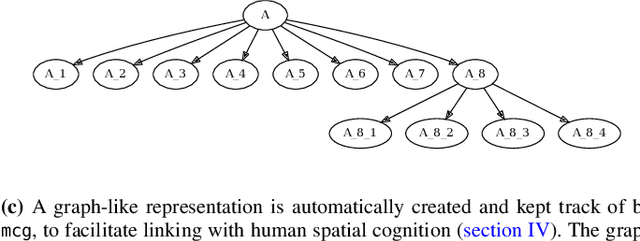
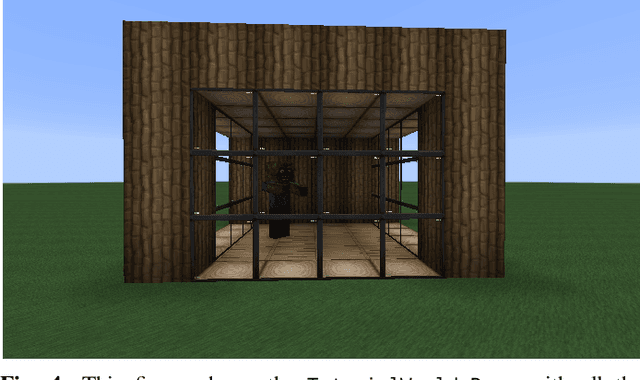
Task environments developed in Minecraft are becoming increasingly popular for artificial intelligence (AI) research. However, most of these are currently constructed manually, thus failing to take advantage of procedural content generation (PCG), a capability unique to virtual task environments. In this paper, we present mcg, an open-source library to facilitate implementing PCG algorithms for voxel-based environments such as Minecraft. The library is designed with human-machine teaming research in mind, and thus takes a 'top-down' approach to generation, simultaneously generating low and high level machine-readable representations that are suitable for empirical research. These can be consumed by downstream AI applications that consider human spatial cognition. The benefits of this approach include rapid, scalable, and efficient development of virtual environments, the ability to control the statistics of the environment at a semantic level, and the ability to generate novel environments in response to player actions in real time.
Learning Fast and Slow: PROPEDEUTICA for Real-time Malware Detection
Dec 04, 2017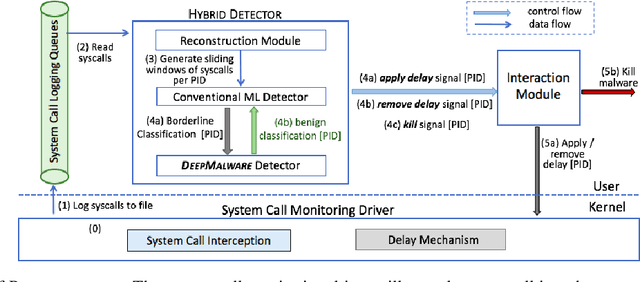
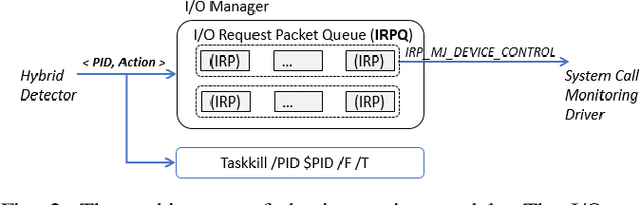
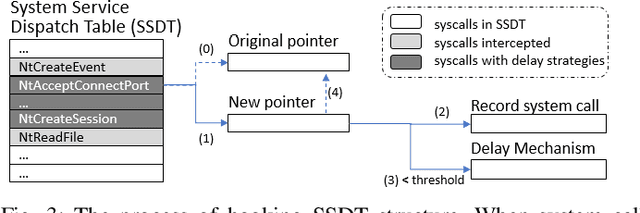
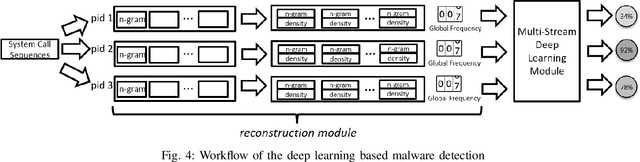
In this paper, we introduce and evaluate PROPEDEUTICA, a novel methodology and framework for efficient and effective real-time malware detection, leveraging the best of conventional machine learning (ML) and deep learning (DL) algorithms. In PROPEDEUTICA, all software processes in the system start execution subjected to a conventional ML detector for fast classification. If a piece of software receives a borderline classification, it is subjected to further analysis via more performance expensive and more accurate DL methods, via our newly proposed DL algorithm DEEPMALWARE. Further, we introduce delays to the execution of software subjected to deep learning analysis as a way to "buy time" for DL analysis and to rate-limit the impact of possible malware in the system. We evaluated PROPEDEUTICA with a set of 9,115 malware samples and 877 commonly used benign software samples from various categories for the Windows OS. Our results show that the false positive rate for conventional ML methods can reach 20%, and for modern DL methods it is usually below 6%. However, the classification time for DL can be 100X longer than conventional ML methods. PROPEDEUTICA improved the detection F1-score from 77.54% (conventional ML method) to 90.25%, and reduced the detection time by 54.86%. Further, the percentage of software subjected to DL analysis was approximately 40% on average. Further, the application of delays in software subjected to ML reduced the detection time by approximately 10%. Finally, we found and discussed a discrepancy between the detection accuracy offline (analysis after all traces are collected) and on-the-fly (analysis in tandem with trace collection). Our insights show that conventional ML and modern DL-based malware detectors in isolation cannot meet the needs of efficient and effective malware detection: high accuracy, low false positive rate, and short classification time.
AugSplicing: Synchronized Behavior Detection in Streaming Tensors
Jan 05, 2021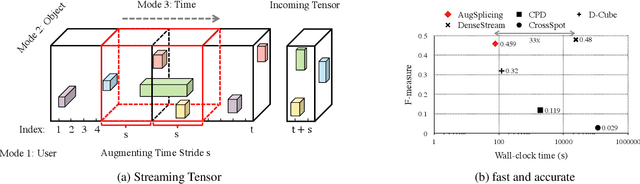
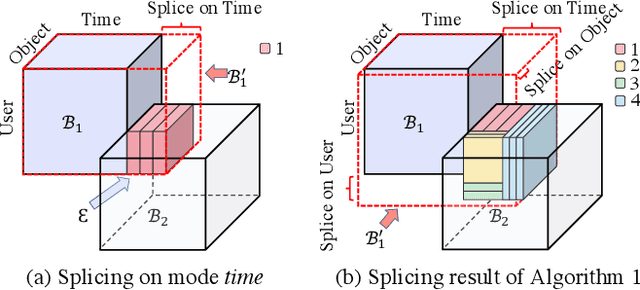
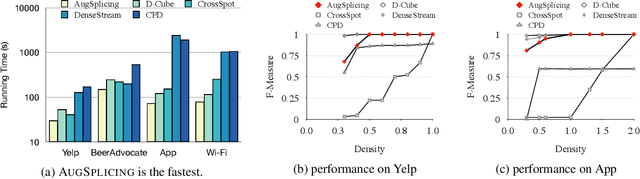
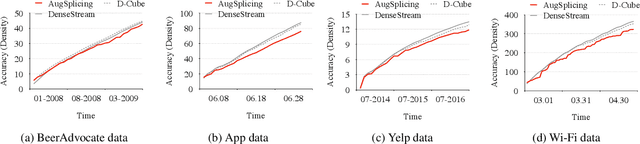
How can we track synchronized behavior in a stream of time-stamped tuples, such as mobile devices installing and uninstalling applications in the lockstep, to boost their ranks in the app store? We model such tuples as entries in a streaming tensor, which augments attribute sizes in its modes over time. Synchronized behavior tends to form dense blocks (i.e. subtensors) in such a tensor, signaling anomalous behavior, or interesting communities. However, existing dense block detection methods are either based on a static tensor, or lack an efficient algorithm in a streaming setting. Therefore, we propose a fast streaming algorithm, AugSplicing, which can detect the top dense blocks by incrementally splicing the previous detection with the incoming ones in new tuples, avoiding re-runs over all the history data at every tracking time step. AugSplicing is based on a splicing condition that guides the algorithm (Section 4). Compared to the state-of-the-art methods, our method is (1) effective to detect fraudulent behavior in installing data of real-world apps and find a synchronized group of students with interesting features in campus Wi-Fi data; (2) robust with splicing theory for dense block detection; (3) streaming and faster than the existing streaming algorithm, with closely comparable accuracy.
Transfer training from smaller language model
Apr 23, 2021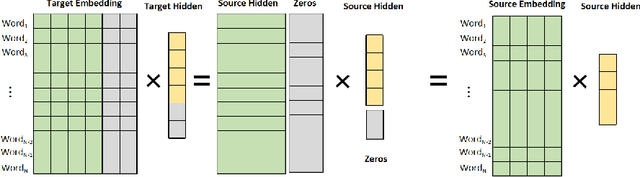

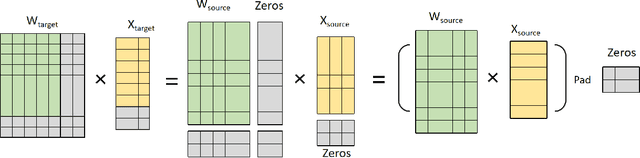
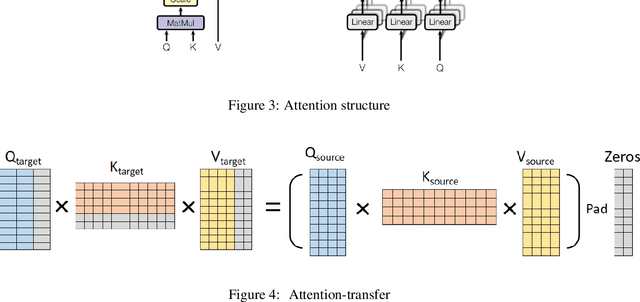
Large language models have led to state-of-the-art accuracies across a range of tasks. However,training large language model needs massive computing resource, as more and more open source pre-training models are available, it is worthy to study how to take full advantage of available model. We find a method to save training time and resource cost by changing the small well-trained model to large model. We initialize a larger target model from a smaller source model by copy weight values from source model and padding with zeros or small initialization values on it to make the source and target model have approximate outputs, which is valid due to block matrix multiplication and residual connection in transformer structure. We test the target model on several data sets and find it is still comparable with the source model. When we continue training the target model, the training loss can start from a smaller value.
Pattern Localization in Time Series through Signal-To-Model Alignment in Latent Space
Feb 19, 2018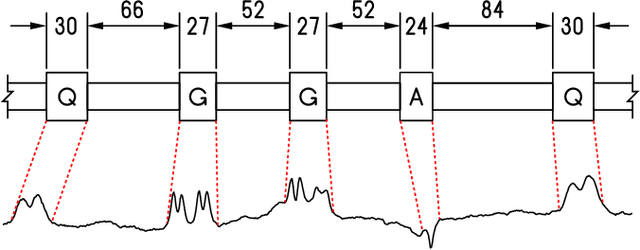
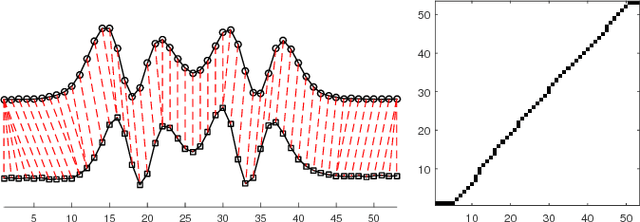

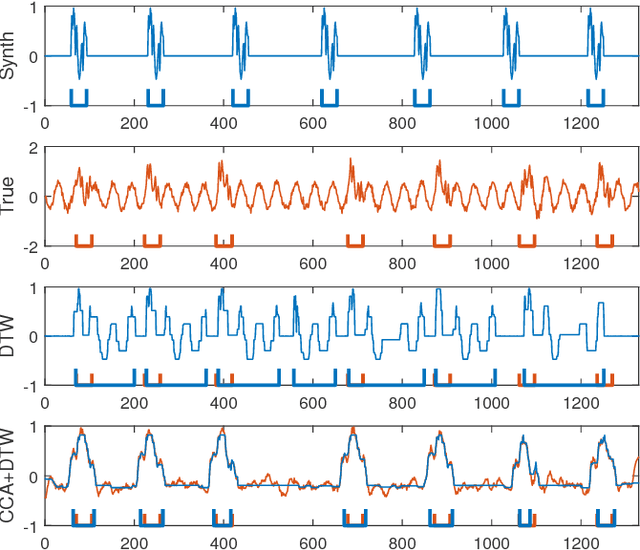
In this paper, we study the problem of locating a predefined sequence of patterns in a time series. In particular, the studied scenario assumes a theoretical model is available that contains the expected locations of the patterns. This problem is found in several contexts, and it is commonly solved by first synthesizing a time series from the model, and then aligning it to the true time series through dynamic time warping. We propose a technique that increases the similarity of both time series before aligning them, by mapping them into a latent correlation space. The mapping is learned from the data through a machine-learning setup. Experiments on data from non-destructive testing demonstrate that the proposed approach shows significant improvements over the state of the art.
Lite-FPN for Keypoint-based Monocular 3D Object Detection
May 01, 2021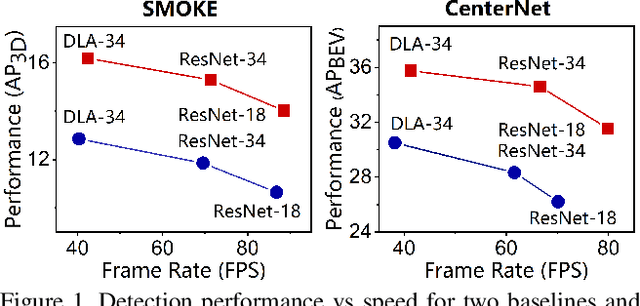
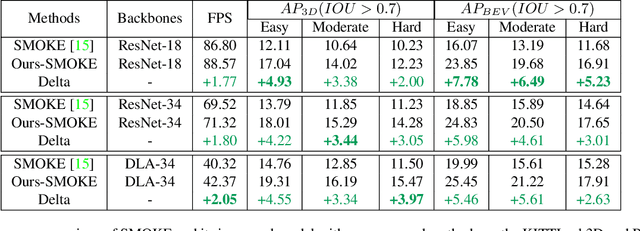
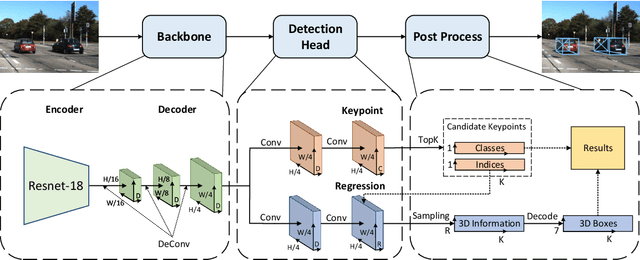
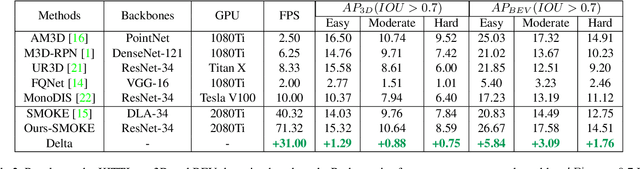
3D object detection with a single image is an essential and challenging task for autonomous driving. Recently, keypoint-based monocular 3D object detection has made tremendous progress and achieved great speed-accuracy trade-off. However, there still exists a huge gap with LIDAR-based methods in terms of accuracy. To improve their performance without sacrificing efficiency, we propose a sort of lightweight feature pyramid network called Lite-FPN to achieve multi-scale feature fusion in an effective and efficient way, which can boost the multi-scale detection capability of keypoint-based detectors. Besides, the misalignment between the classification score and the localization precision is further relieved by introducing a novel regression loss named attention loss. With the proposed loss, predictions with high confidence but poor localization are treated with more attention during the training phase. Comparative experiments based on several state-of-the-art keypoint-based detectors on the KITTI dataset show that our proposed method achieves significantly higher accuracy and frame rate at the same time. The code and pretrained models will be available at https://github.com/yanglei18/Lite-FPN.
DeepMultiCap: Performance Capture of Multiple Characters Using Sparse Multiview Cameras
May 01, 2021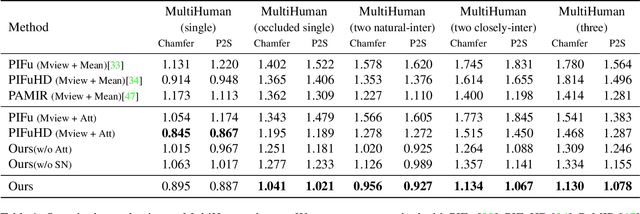
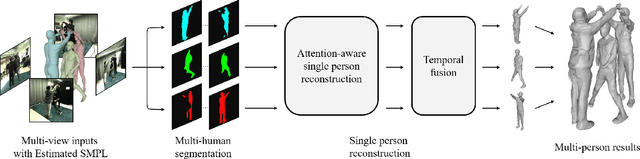
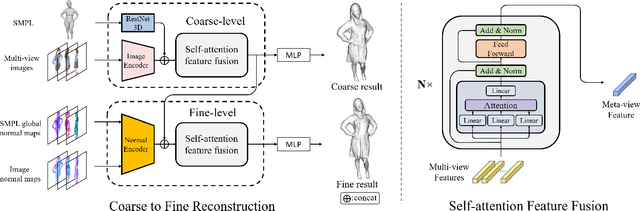

We propose DeepMultiCap, a novel method for multi-person performance capture using sparse multi-view cameras. Our method can capture time varying surface details without the need of using pre-scanned template models. To tackle with the serious occlusion challenge for close interacting scenes, we combine a recently proposed pixel-aligned implicit function with parametric model for robust reconstruction of the invisible surface areas. An effective attention-aware module is designed to obtain the fine-grained geometry details from multi-view images, where high-fidelity results can be generated. In addition to the spatial attention method, for video inputs, we further propose a novel temporal fusion method to alleviate the noise and temporal inconsistencies for moving character reconstruction. For quantitative evaluation, we contribute a high quality multi-person dataset, MultiHuman, which consists of 150 static scenes with different levels of occlusions and ground truth 3D human models. Experimental results demonstrate the state-of-the-art performance of our method and the well generalization to real multiview video data, which outperforms the prior works by a large margin.