 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High precision control and deep learning-based corn stand counting algorithms for agricultural robot
Mar 21, 2021

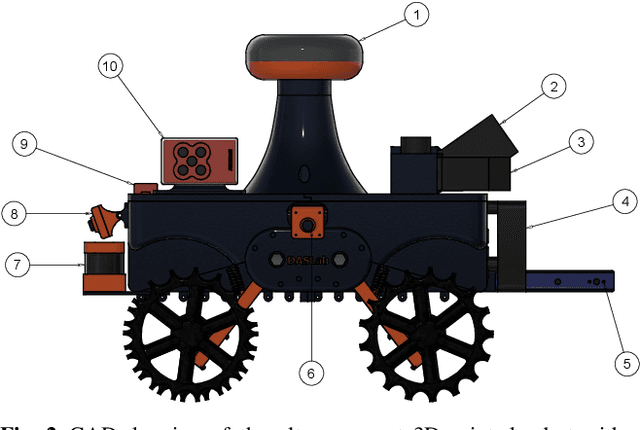
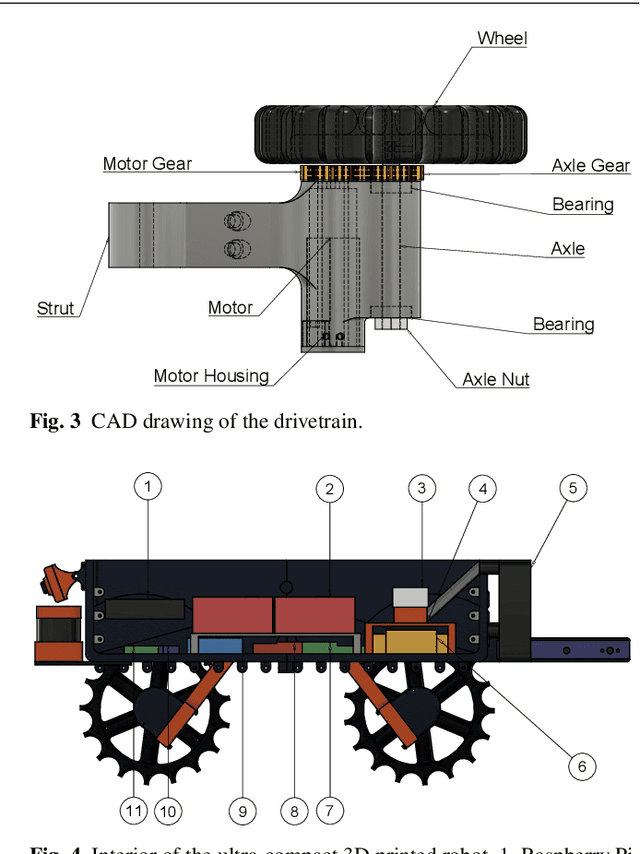
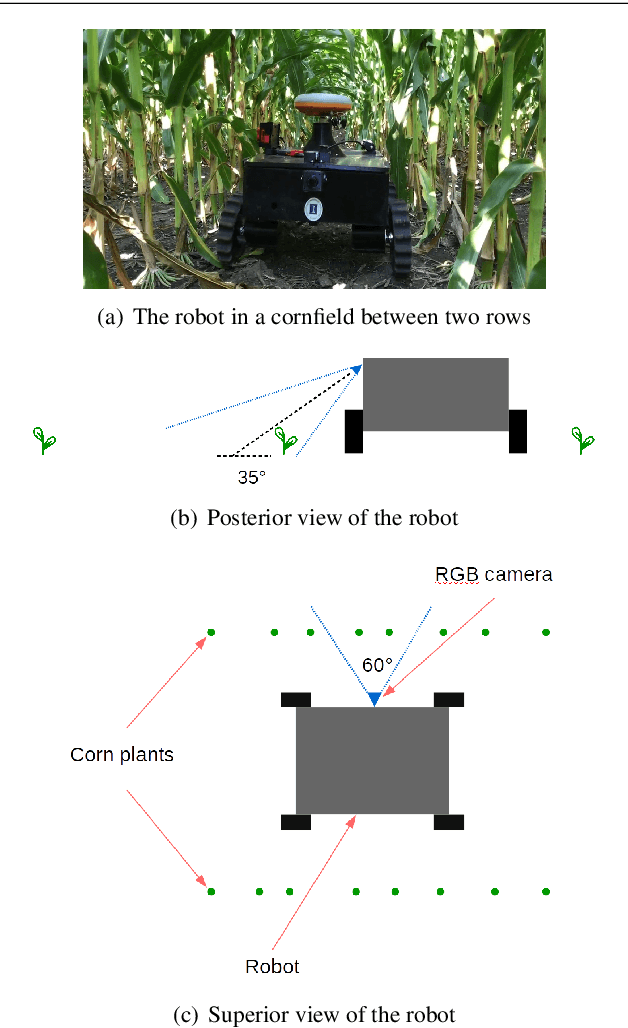
This paper presents high precision control and deep learning-based corn stand counting algorithms for a low-cost, ultra-compact 3D printed and autonomous field robot for agricultural operations. Currently, plant traits, such as emergence rate, biomass, vigor, and stand counting, are measured manually. This is highly labor-intensive and prone to errors. The robot, termed TerraSentia, is designed to automate the measurement of plant traits for efficient phenotyping as an alternative to manual measurements. In this paper, we formulate a Nonlinear Moving Horizon Estimator (NMHE) that identifies key terrain parameters using onboard robot sensors and a learning-based Nonlinear Model Predictive Control (NMPC) that ensures high precision path tracking in the presence of unknown wheel-terrain interaction. Moreover, we develop a machine vision algorithm designed to enable an ultra-compact ground robot to count corn stands by driving through the fields autonomously. The algorithm leverages a deep network to detect corn plants in images, and a visual tracking model to re-identify detected objects at different time steps. We collected data from 53 corn plots in various fields for corn plants around 14 days after emergence (stage V3 - V4). The robot predictions have agreed well with the ground truth with $C_{robot}=1.02 \times C_{human}-0.86$ and a correlation coefficient $R=0.96$. The mean relative error given by the algorithm is $-3.78\%$, and the standard deviation is $6.76\%$. These results indicate a first and significant step towards autonomous robot-based real-time phenotyping using low-cost, ultra-compact ground robots for corn and potentially other crops.
* 14 pages, 9 figures
Encoders and Ensembles for Task-Free Continual Learning
May 27, 2021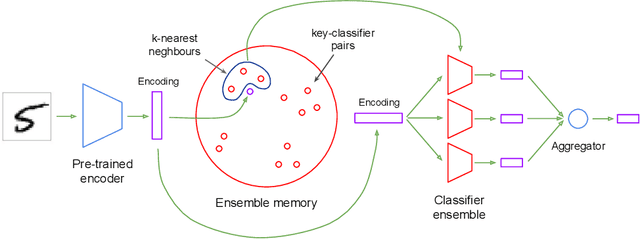
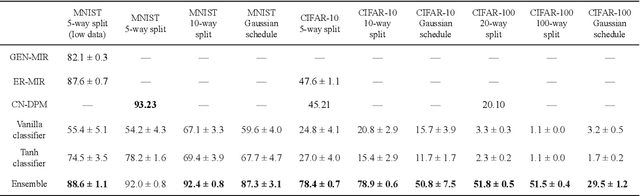
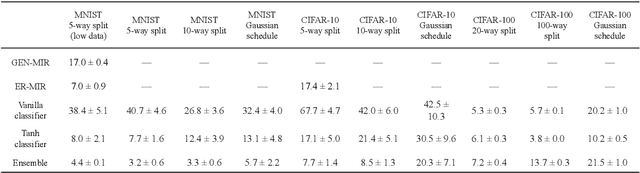
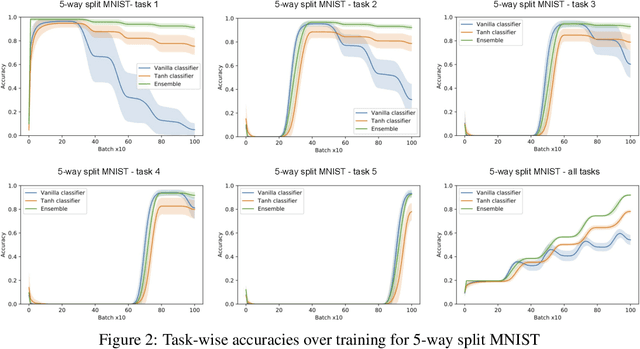
We present an architecture that is effective for continual learning in an especially demanding setting, where task boundaries do not exist or are unknown. Our architecture comprises an encoder, pre-trained on a separate dataset, and an ensemble of simple one-layer classifiers. Two main innovations are required to make this combination work. First, the provision of suitably generic pre-trained encoders has been made possible thanks to recent progress in self-supervised training methods. Second, pairing each classifier in the ensemble with a key, where the key-space is identical to the latent space of the encoder, allows them to be used collectively, yet selectively, via k-nearest neighbour lookup. We show that models trained with the encoders-and-ensembles architecture are state-of-the-art for the task-free setting on standard image classification continual learning benchmarks, and improve on prior state-of-the-art by a large margin in the most challenging cases. We also show that the architecture learns well in a fully incremental setting, where one class is learned at a time, and we demonstrate its effectiveness in this setting with up to 100 classes. Finally, we show that the architecture works in a task-free continual learning context where the data distribution changes gradually, and existing approaches requiring knowledge of task boundaries cannot be applied.
Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
Jun 27, 2020
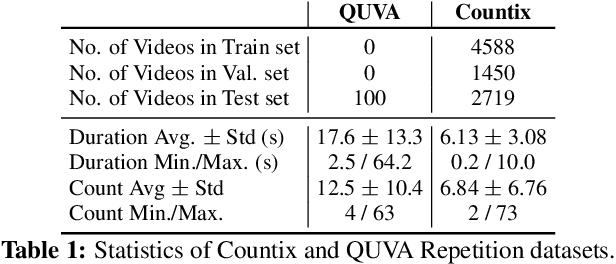


We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google.com/view/repnet .
Point Cloud Audio Processing
May 06, 2021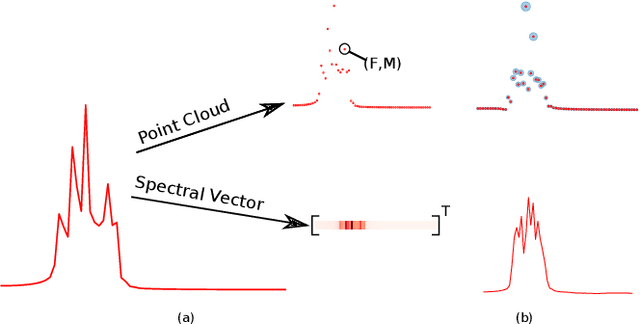
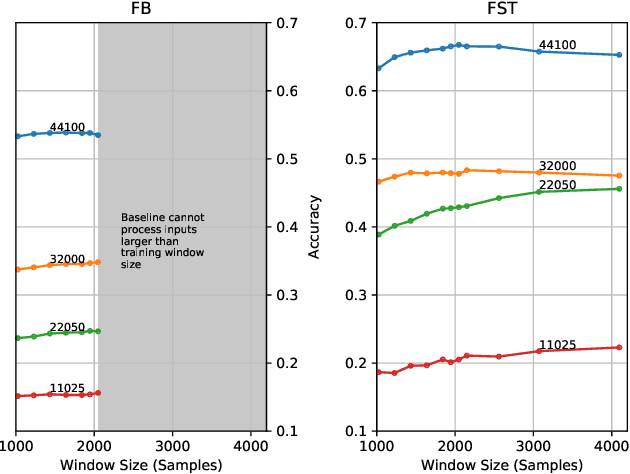
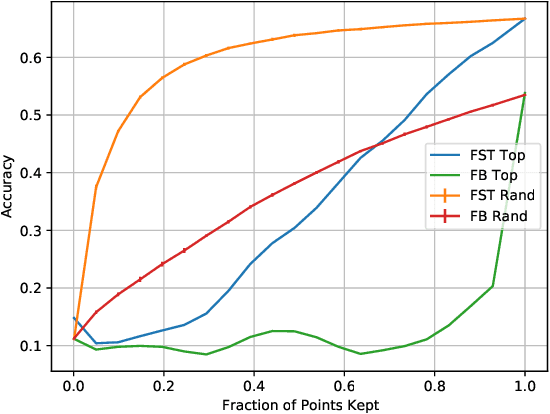
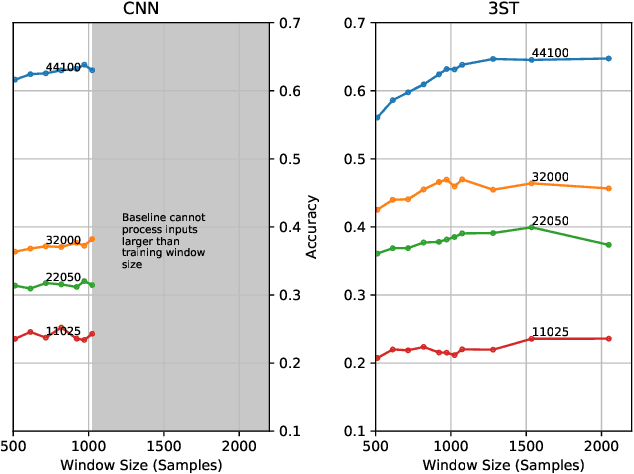
Most audio processing pipelines involve transformations that act on fixed-dimensional input representations of audio. For example, when using the Short Time Fourier Transform (STFT) the DFT size specifies a fixed dimension for the input representation. As a consequence, most audio machine learning models are designed to process fixed-size vector inputs which often prohibits the repurposing of learned models on audio with different sampling rates or alternative representations. We note, however, that the intrinsic spectral information in the audio signal is invariant to the choice of the input representation or the sampling rate. Motivated by this, we introduce a novel way of processing audio signals by treating them as a collection of points in feature space, and we use point cloud machine learning models that give us invariance to the choice of representation parameters, such as DFT size or the sampling rate. Additionally, we observe that these methods result in smaller models, and allow us to significantly subsample the input representation with minimal effects to a trained model performance.
2D Linear Time-Variant Controller for Human's Intention Detection for Reach-to-Grasp Trajectories in Novel Scenes
Jun 19, 2019
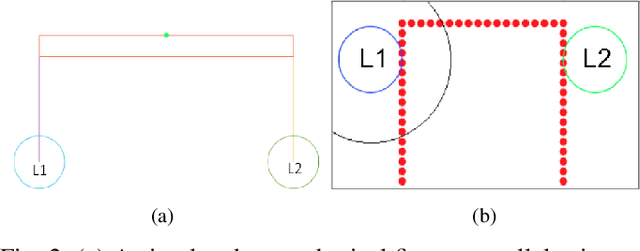
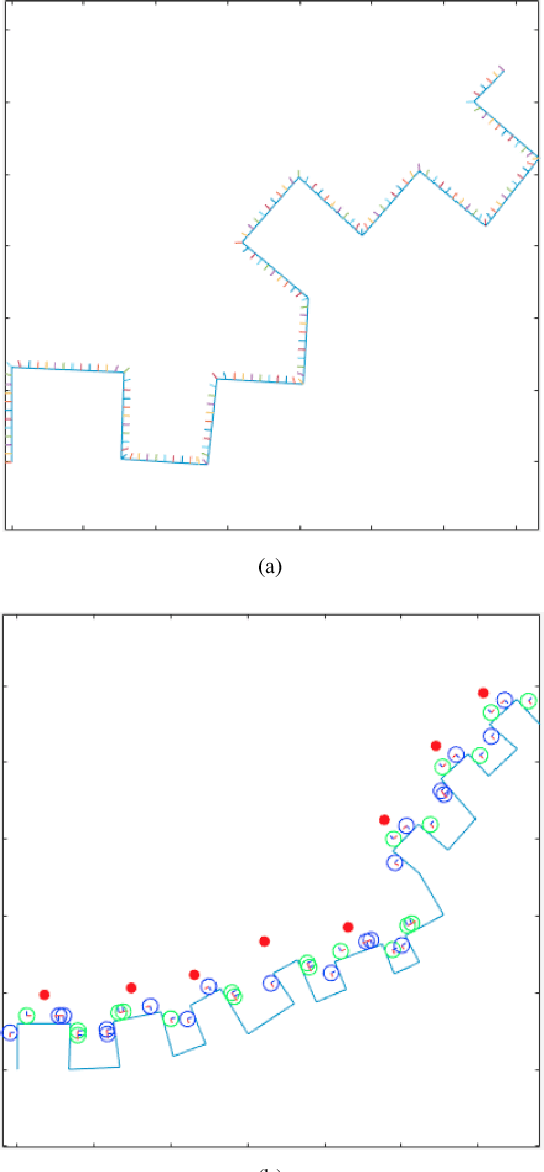
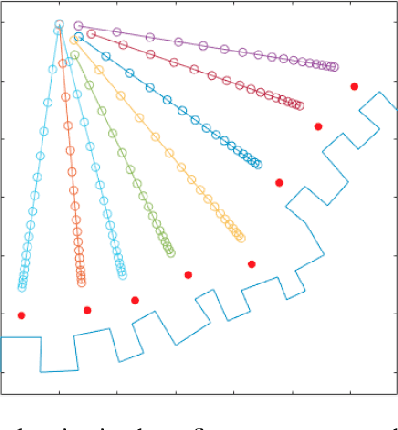
Designing robotic assistance devices for manipulation tasks is challenging. This work is concerned with improving accuracy and usability of semi-autonomous robots, such as human operated manipulators or exoskeletons. The key insight is to develop a system that takes into account context- and user-awareness to take better decisions in how to assist the user. The context-awareness is implemented by enabling the system to automatically generate a set of candidate grasps and reach-to-grasp trajectories in novel, cluttered scenes. The user-awareness is implemented as a linear time-variant feedback controller to facilitate the motion towards the most promising grasp. Our approach is demonstrated in a simple 2D example in which participants are asked to grasp a specific object in a clutter scene. Our approach also reduce the number of controllable dimensions for the user by providing only control on x- and y-axis, while orientation of the end-effector and the pose of its fingers are inferred by the system. The experimental results show the benefits of our approach in terms of accuracy and execution time with respect to a pure manual control.
BlitzNet: A Real-Time Deep Network for Scene Understanding
Aug 09, 2017
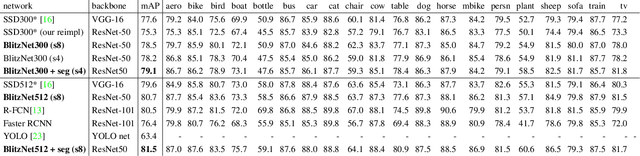
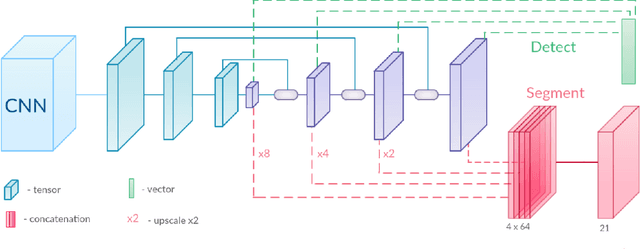
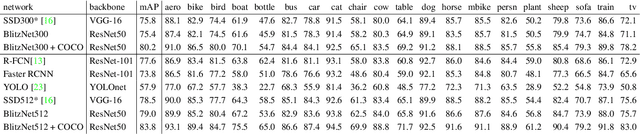
Real-time scene understanding has become crucial in many applications such as autonomous driving. In this paper, we propose a deep architecture, called BlitzNet, that jointly performs object detection and semantic segmentation in one forward pass, allowing real-time computations. Besides the computational gain of having a single network to perform several tasks, we show that object detection and semantic segmentation benefit from each other in terms of accuracy. Experimental results for VOC and COCO datasets show state-of-the-art performance for object detection and segmentation among real time systems.
EnMcGAN: Adversarial Ensemble Learning for 3D Complete Renal Structures Segmentation
Jun 08, 2021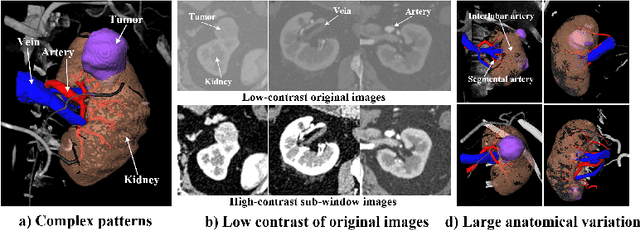

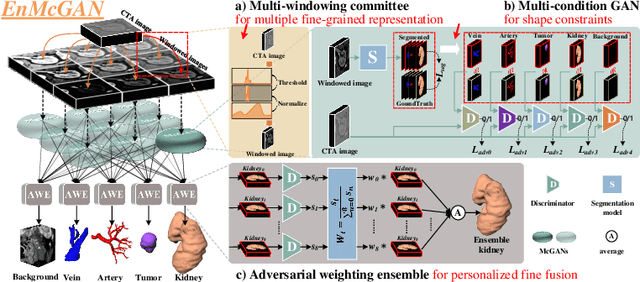
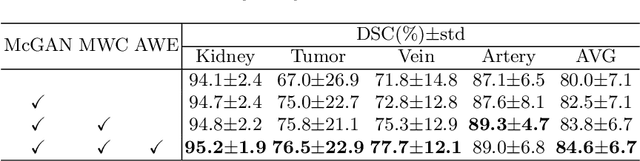
3D complete renal structures(CRS) segmentation targets on segmenting the kidneys, tumors, renal arteries and veins in one inference. Once successful, it will provide preoperative plans and intraoperative guidance for laparoscopic partial nephrectomy(LPN), playing a key role in the renal cancer treatment. However, no success has been reported in 3D CRS segmentation due to the complex shapes of renal structures, low contrast and large anatomical variation. In this study, we utilize the adversarial ensemble learning and propose Ensemble Multi-condition GAN(EnMcGAN) for 3D CRS segmentation for the first time. Its contribution is three-fold. 1)Inspired by windowing, we propose the multi-windowing committee which divides CTA image into multiple narrow windows with different window centers and widths enhancing the contrast for salient boundaries and soft tissues. And then, it builds an ensemble segmentation model on these narrow windows to fuse the segmentation superiorities and improve whole segmentation quality. 2)We propose the multi-condition GAN which equips the segmentation model with multiple discriminators to encourage the segmented structures meeting their real shape conditions, thus improving the shape feature extraction ability. 3)We propose the adversarial weighted ensemble module which uses the trained discriminators to evaluate the quality of segmented structures, and normalizes these evaluation scores for the ensemble weights directed at the input image, thus enhancing the ensemble results. 122 patients are enrolled in this study and the mean Dice coefficient of the renal structures achieves 84.6%. Extensive experiments with promising results on renal structures reveal powerful segmentation accuracy and great clinical significance in renal cancer treatment.
Left Ventricle Contouring in Cardiac Images Based on Deep Reinforcement Learning
Jun 08, 2021
Medical image segmentation is one of the important tasks of computer-aided diagnosis in medical image analysis. Since most medical images have the characteristics of blurred boundaries and uneven intensity distribution, through existing segmentation methods, the discontinuity within the target area and the discontinuity of the target boundary are likely to lead to rough or even erroneous boundary delineation. In this paper, we propose a new iterative refined interactive segmentation method for medical images based on agent reinforcement learning, which focuses on the problem of target segmentation boundaries. We model the dynamic process of drawing the target contour in a certain order as a Markov Decision Process (MDP) based on a deep reinforcement learning method. In the dynamic process of continuous interaction between the agent and the image, the agent tracks the boundary point by point in order within a limited length range until the contour of the target is completely drawn. In this process, the agent can quickly improve the segmentation performance by exploring an interactive policy in the image. The method we proposed is simple and effective. At the same time, we evaluate our method on the cardiac MRI scan data set. Experimental results show that our method has a better segmentation effect on the left ventricle in a small number of medical image data sets, especially in terms of segmentation boundaries, this method is better than existing methods. Based on our proposed method, the dynamic generation process of the predicted contour trajectory of the left ventricle will be displayed online at https://github.com/H1997ym/LV-contour-trajectory.
A modularity comparison of Long Short-Term Memory and Morphognosis neural networks
Apr 23, 2021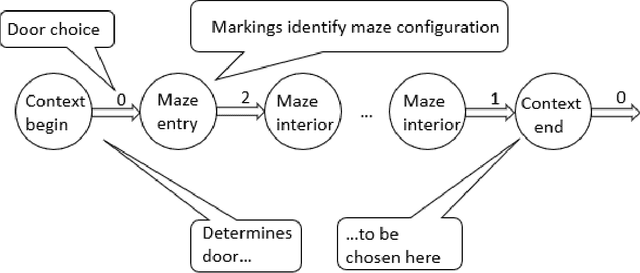
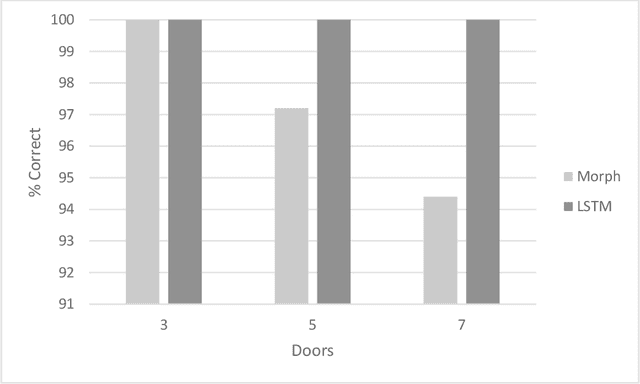
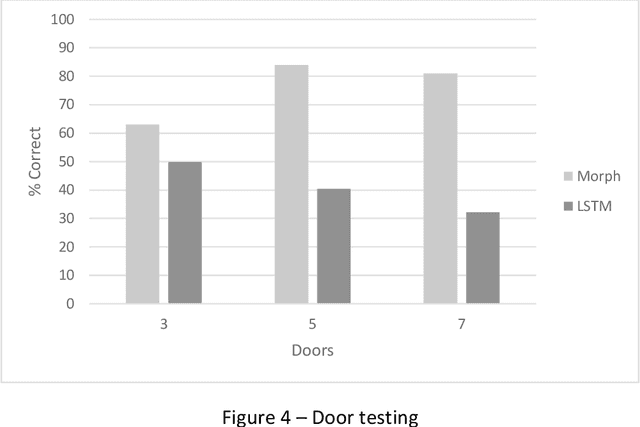
This study compares the modularity performance of two artificial neural network architectures: a Long Short-Term Memory (LSTM) recurrent network, and Morphognosis, a neural network based on a hierarchy of spatial and temporal contexts. Mazes are used to measure performance, defined as the ability to utilize independently learned mazes to solve mazes composed of them. A maze is a sequence of rooms connected by doors. The modular task is implemented as follows: at the beginning of the maze, an initial door choice forms a context that must be retained until the end of an intervening maze, where the same door must be chosen again to reach the goal. For testing, the door-association mazes and separately trained intervening mazes are presented together for the first time. While both neural networks perform well during training, the testing performance of Morphognosis is significantly better than LSTM on this modular task.
The AI Settlement Generation Challenge in Minecraft: First Year Report
Mar 27, 2021

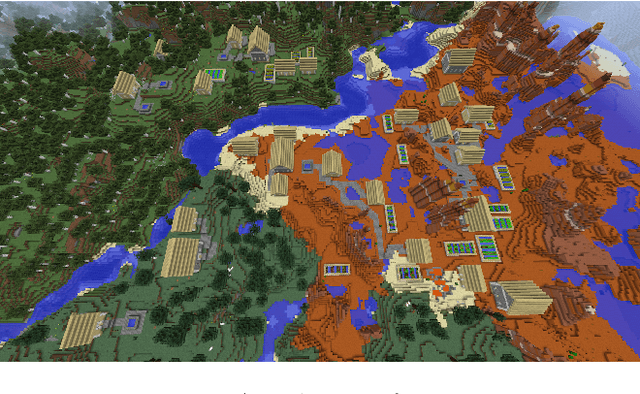

This article outlines what we learned from the first year of the AI Settlement Generation Competition in Minecraft, a competition about producing AI programs that can generate interesting settlements in Minecraft for an unseen map. This challenge seeks to focus research into adaptive and holistic procedural content generation. Generating Minecraft towns and villages given existing maps is a suitable task for this, as it requires the generated content to be adaptive, functional, evocative and aesthetic at the same time. Here, we present the results from the first iteration of the competition. We discuss the evaluation methodology, present the different technical approaches by the competitors, and outline the open problems.
* 14 pages, 9 figures, published in KI-K\"unstliche Intelligenz