 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A New Channel Estimation Strategy in Intelligent Reflecting Surface Assisted Networks
Jun 22, 2021
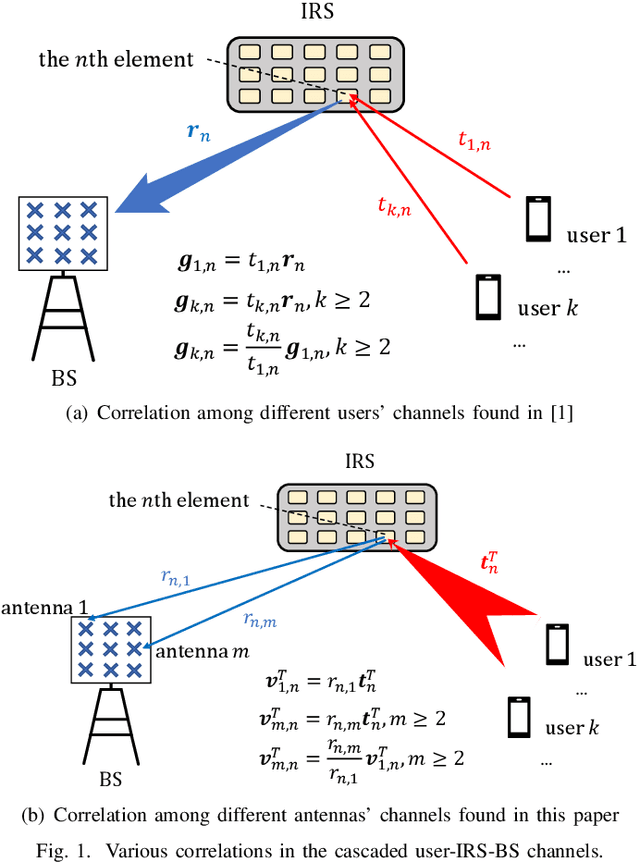
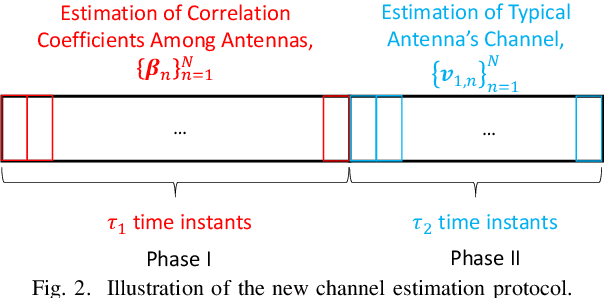
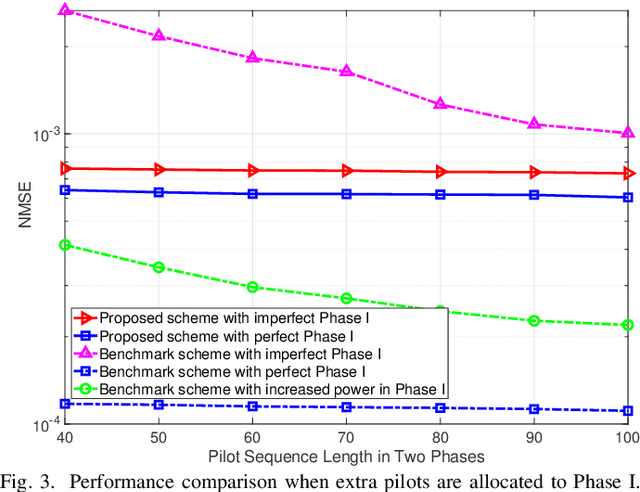
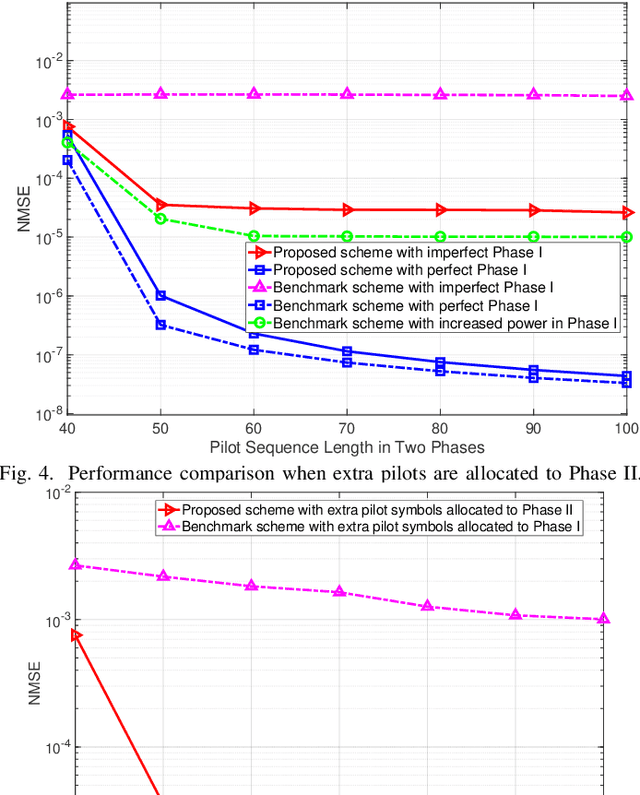
Channel estimation is the main hurdle to reaping the benefits promised by the intelligent reflecting surface (IRS), due to its absence of ability to transmit/receive pilot signals as well as the huge number of channel coefficients associated with its reflecting elements. Recently, a breakthrough was made in reducing the channel estimation overhead by revealing that the IRS-BS (base station) channels are common in the cascaded user-IRS-BS channels of all the users, and if the cascaded channel of one typical user is estimated, the other users' cascaded channels can be estimated very quickly based on their correlation with the typical user's channel \cite{b5}. One limitation of this strategy, however, is the waste of user energy, because many users need to keep silent when the typical user's channel is estimated. In this paper, we reveal another correlation hidden in the cascaded user-IRS-BS channels by observing that the user-IRS channel is common in all the cascaded channels from users to each BS antenna as well. Building upon this finding, we propose a novel two-phase channel estimation protocol in the uplink communication. Specifically, in Phase I, the correlation coefficients between the channels of a typical BS antenna and those of the other antennas are estimated; while in Phase II, the cascaded channel of the typical antenna is estimated. In particular, all the users can transmit throughput Phase I and Phase II. Under this strategy, it is theoretically shown that the minimum number of time instants required for perfect channel estimation is the same as that of the aforementioned strategy in the ideal case without BS noise. Then, in the case with BS noise, we show by simulation that the channel estimation error of our proposed scheme is significantly reduced thanks to the full exploitation of the user energy.
Active Screening for Recurrent Diseases: A Reinforcement Learning Approach
Jan 07, 2021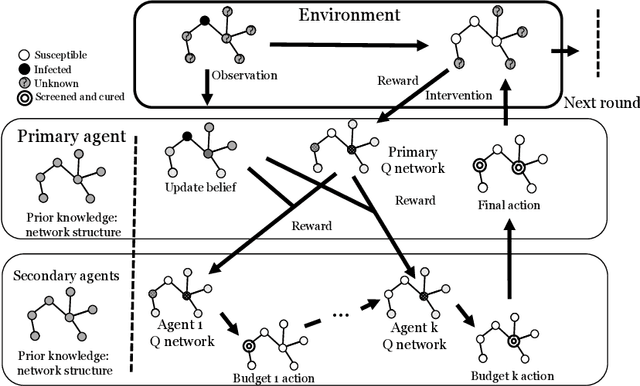
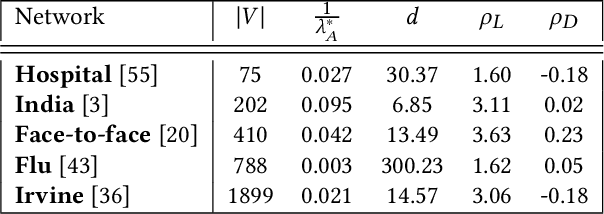
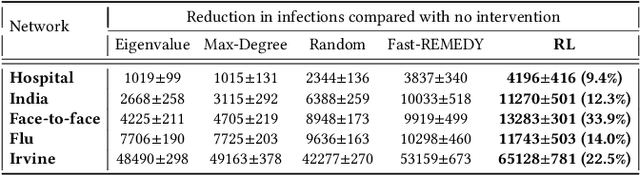
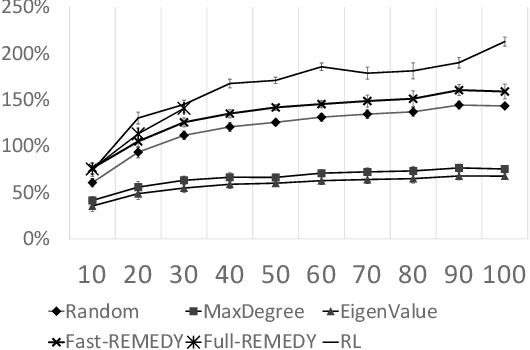
Active screening is a common approach in controlling the spread of recurring infectious diseases such as tuberculosis and influenza. In this approach, health workers periodically select a subset of population for screening. However, given the limited number of health workers, only a small subset of the population can be visited in any given time period. Given the recurrent nature of the disease and rapid spreading, the goal is to minimize the number of infections over a long time horizon. Active screening can be formalized as a sequential combinatorial optimization over the network of people and their connections. The main computational challenges in this formalization arise from i) the combinatorial nature of the problem, ii) the need of sequential planning and iii) the uncertainties in the infectiousness states of the population. Previous works on active screening fail to scale to large time horizon while fully considering the future effect of current interventions. In this paper, we propose a novel reinforcement learning (RL) approach based on Deep Q-Networks (DQN), with several innovative adaptations that are designed to address the above challenges. First, we use graph convolutional networks (GCNs) to represent the Q-function that exploit the node correlations of the underlying contact network. Second, to avoid solving a combinatorial optimization problem in each time period, we decompose the node set selection as a sub-sequence of decisions, and further design a two-level RL framework that solves the problem in a hierarchical way. Finally, to speed-up the slow convergence of RL which arises from reward sparseness, we incorporate ideas from curriculum learning into our hierarchical RL approach. We evaluate our RL algorithm on several real-world networks.
Contrastive Explanations for Explaining Model Adaptations
Apr 07, 2021Many decision making systems deployed in the real world are not static - a phenomenon known as model adaptation takes place over time. The need for transparency and interpretability of AI-based decision models is widely accepted and thus have been worked on extensively. Usually, explanation methods assume a static system that has to be explained. Explaining non-static systems is still an open research question, which poses the challenge how to explain model adaptations. In this contribution, we propose and (empirically) evaluate a framework for explaining model adaptations by contrastive explanations. We also propose a method for automatically finding regions in data space that are affected by a given model adaptation and thus should be explained.
Impact of Sound Duration and Inactive Frames on Sound Event Detection Performance
Feb 03, 2021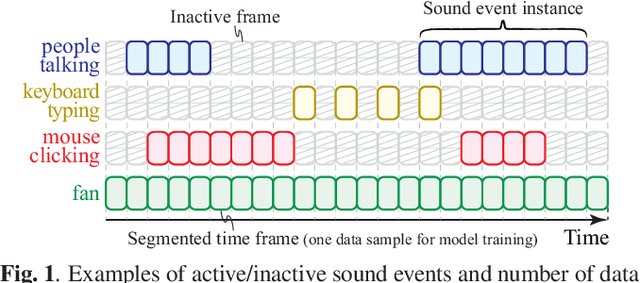
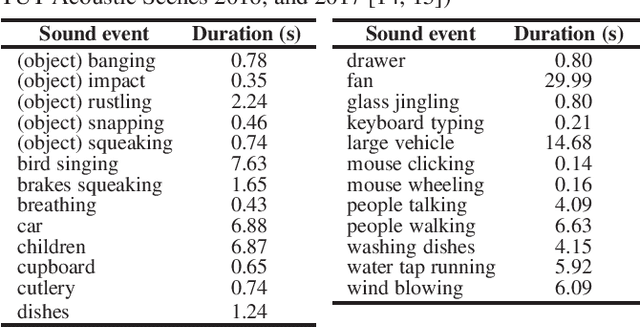
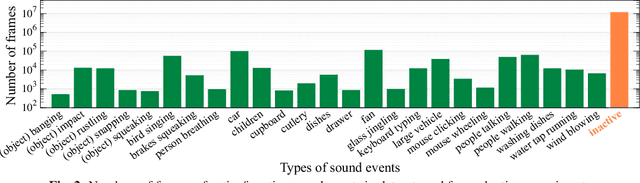

In many methods of sound event detection (SED), a segmented time frame is regarded as one data sample to model training. The durations of sound events greatly depend on the sound event class, e.g., the sound event "fan" has a long duration, whereas the sound event "mouse clicking" is instantaneous. Thus, the difference in the duration between sound event classes results in a serious data imbalance in SED. Moreover, most sound events tend to occur occasionally; therefore, there are many more inactive time frames of sound events than active frames. This also causes a severe data imbalance between active and inactive frames. In this paper, we investigate the impact of sound duration and inactive frames on SED performance by introducing four loss functions, such as simple reweighting loss, inverse frequency loss, asymmetric focal loss, and focal batch Tversky loss. Then, we provide insights into how we tackle this imbalance problem.
Strengthening the Training of Convolutional Neural Networks By Using Walsh Matrix
Mar 31, 2021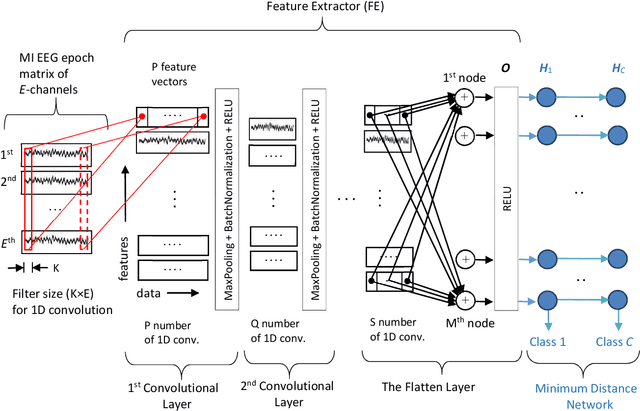
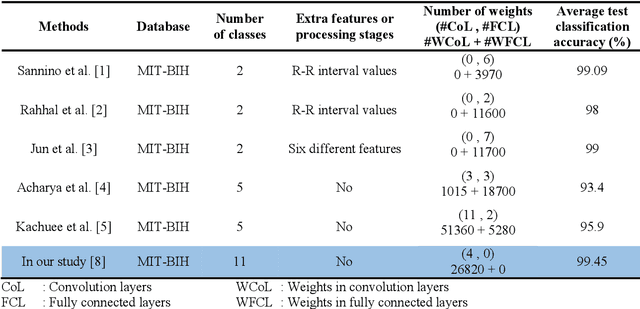
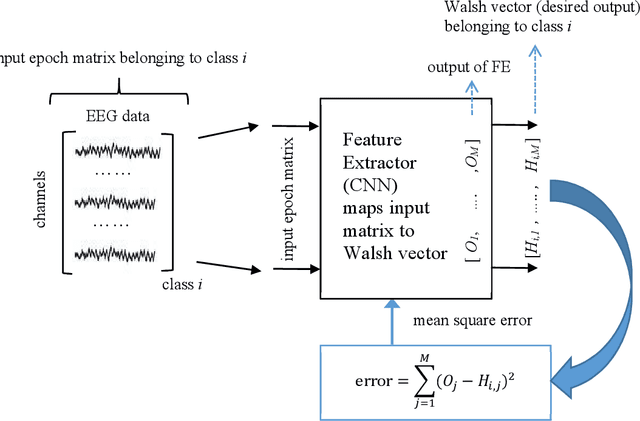
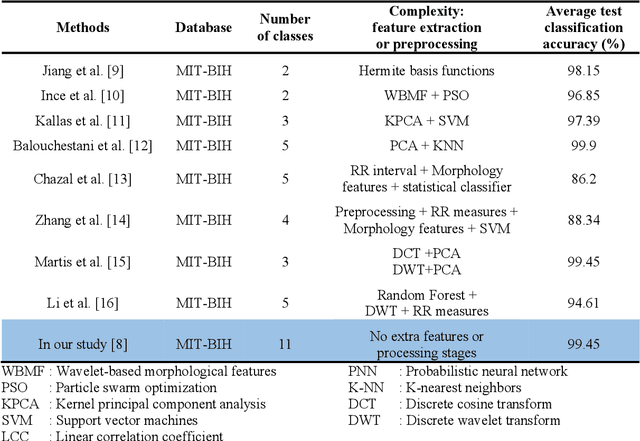
DNN structures are continuously developing and achieving high performances in classification problems. Also, it is observed that success rates obtained with DNNs are higher than those obtained with traditional neural networks. In addition, one of the advantages of DNNs is that there is no need to spend an extra effort to determine the features; the CNN automatically extracts the features from the dataset during the training. Besides their benefits, the DNNs have the following three major drawbacks among the others: (i) Researchers have struggled with over-fitting and under-fitting issues in the training of DNNs, (ii) determination of even a coarse structure for the DNN may take days, and (iii) most of the time, the proposed network structure is too large to be too bulky to be used in real time applications. We have modified the training and structure of DNN to increase the classification performance, to decrease the number of nodes in the structure, and to be used with less number of hyper parameters. A minimum distance network (MDN) following the last layer of the convolutional neural network (CNN) is used as the classifier instead of a fully connected neural network (FCNN). In order to strengthen the training of the CNN, we suggest employing Walsh function. We tested the performances of the proposed DNN (named as DivFE) on the classification of ECG, EEG, heart sound, detection pneumonia in X-ray chest images, detection of BGA solder defects, and patterns of benchmark datasets (MNIST, IRIS, CIFAR10 and CIFAR20). In different areas, it has been observed that a higher classification performance was obtained by using the DivFE with less number of nodes.
Finite-Horizon, Energy-Optimal Trajectories in Unsteady Flows
Mar 18, 2021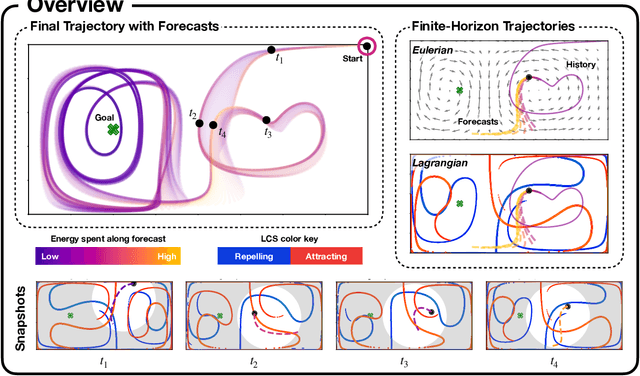
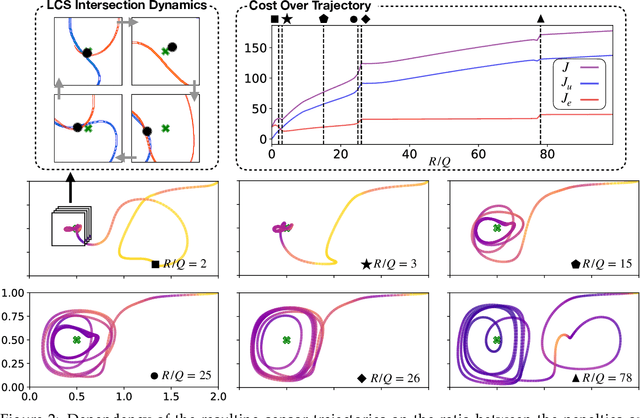
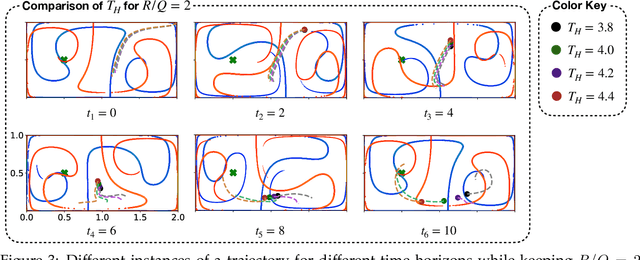
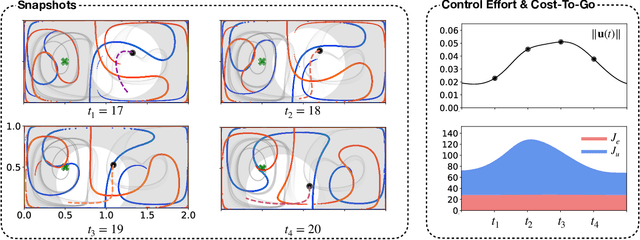
Intelligent mobile sensors, such as uninhabited aerial or underwater vehicles, are becoming prevalent in environmental sensing and monitoring applications. These active sensing platforms operate in unsteady fluid flows, including windy urban environments, hurricanes, and ocean currents. Often constrained in their actuation capabilities, the dynamics of these mobile sensors depend strongly on the background flow, making their deployment and control particularly challenging. Therefore, efficient trajectory planning with partial knowledge about the background flow is essential for teams of mobile sensors to adaptively sense and monitor their environments. In this work, we investigate the use of finite-horizon model predictive control (MPC) for the energy-efficient trajectory planning of an active mobile sensor in an unsteady fluid flow field. We uncover connections between the finite-time optimal trajectories and finite-time Lyapunov exponents (FTLE) of the background flow, confirming that energy-efficient trajectories exploit invariant coherent structures in the flow. We demonstrate our findings on the unsteady double gyre vector field, which is a canonical model for chaotic mixing in the ocean. We present an exhaustive search through critical MPC parameters including the prediction horizon, maximum sensor actuation, and relative penalty on the accumulated state error and actuation effort. We find that even relatively short prediction horizons can often yield nearly energy-optimal trajectories. These results are promising for the adaptive planning of energy-efficient trajectories for swarms of mobile sensors in distributed sensing and monitoring.
"Grip-that-there": An Investigation of Explicit and Implicit Task Allocation Techniques for Human-Robot Collaboration
Feb 03, 2021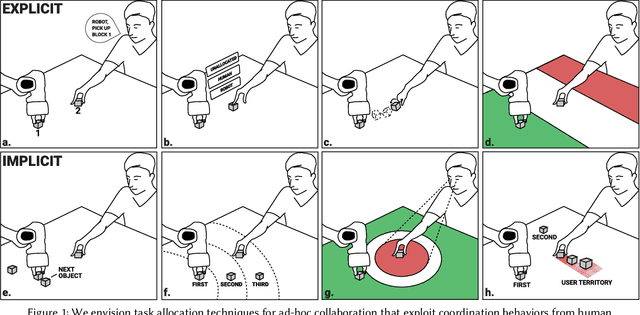

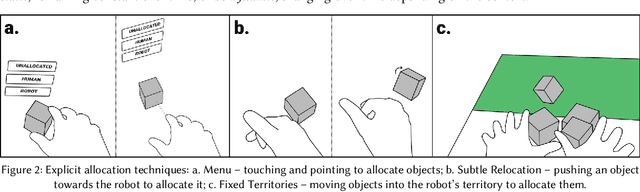
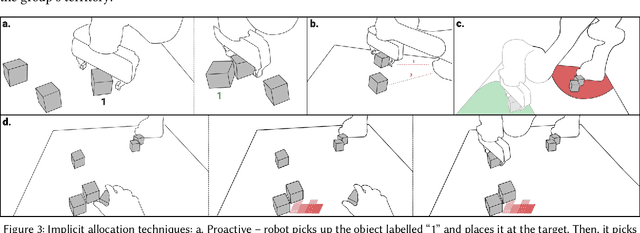
In ad-hoc human-robot collaboration (HRC), humans and robots work on a task without pre-planning the robot's actions prior to execution; instead, task allocation occurs in real-time. However, prior research has largely focused on task allocations that are pre-planned - there has not been a comprehensive exploration or evaluation of techniques where task allocation is adjusted in real-time. Inspired by HCI research on territoriality and proxemics, we propose a design space of novel task allocation techniques including both explicit techniques, where the user maintains agency, and implicit techniques, where the efficiency of automation can be leveraged. The techniques were implemented and evaluated using a tabletop HRC simulation in VR. A 16-participant study, which presented variations of a collaborative block stacking task, showed that implicit techniques enable efficient task completion and task parallelization, and should be augmented with explicit mechanisms to provide users with fine-grained control.
Modelling of LIDAR sensor disturbances by solid airborne particles
May 10, 2021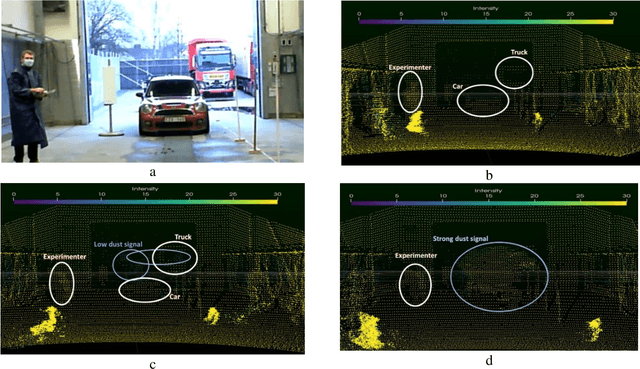
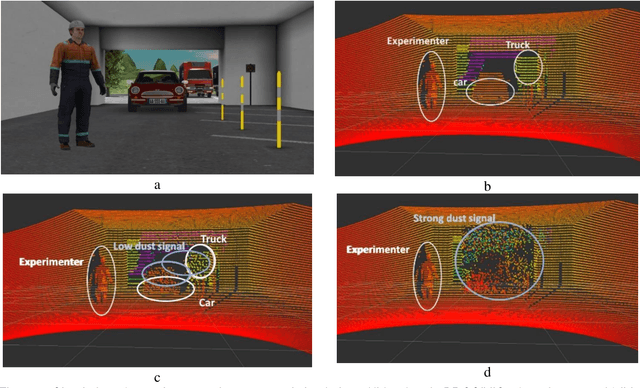
This paper aims to introduce a method for simulating with a real time performance the automotive LIDAR disturbance by dust clouds caused by natural phenomena, mechanical or man-made processes like a traveling vehicle. In this study, we are interested to study the interaction of an automotive LIDAR sensor with a dust cloud composed of solid particles. The main objective of this study is to provide a simulation model to industry and research laboratories that help to study LIDAR performance in a dust-sand environment with the capability to reproduce the encountered problems in degraded conditions and the ability to parameterize the degradation model. Based on industrial projects with a passenger's vehicles and truck manufacturers, we present LIDAR sensor and functionalities to perceive objects in a scene (pedestrian, car, truck, ...) in clear or extreme weather conditions. Simulated and experimental data are compared and analyzed in this article. The features presented are evaluated according to their quality for object detection. This study can be applied to sensors post-processing algorithms (object recognition, tracking, data fusion...) and even to the design of cleaning systems.
Probabilistic Gradient Boosting Machines for Large-Scale Probabilistic Regression
Jun 06, 2021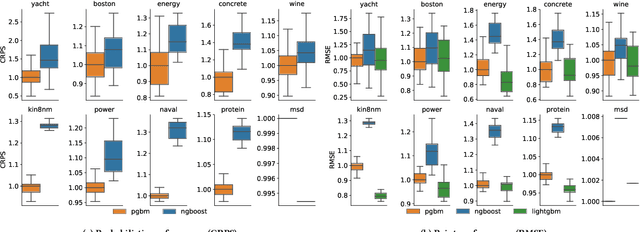
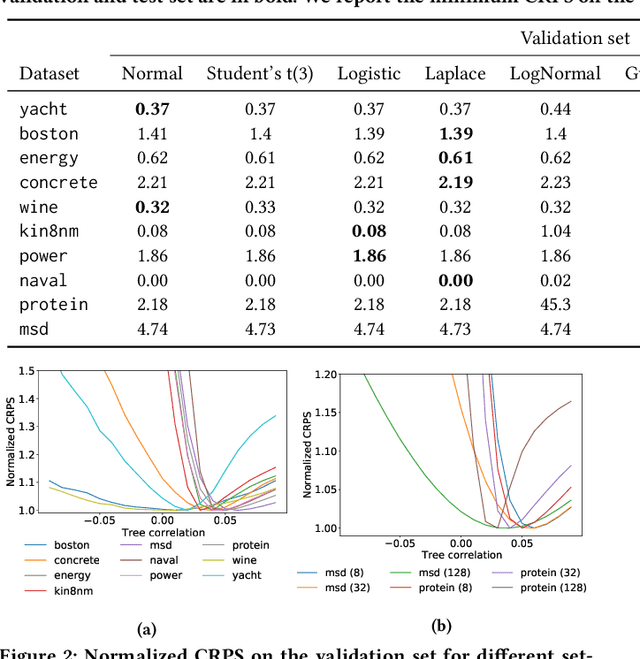
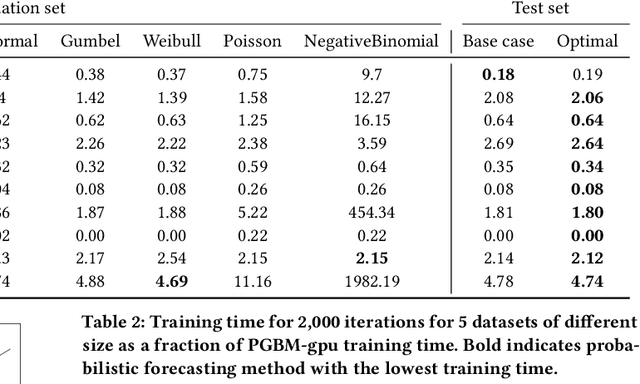
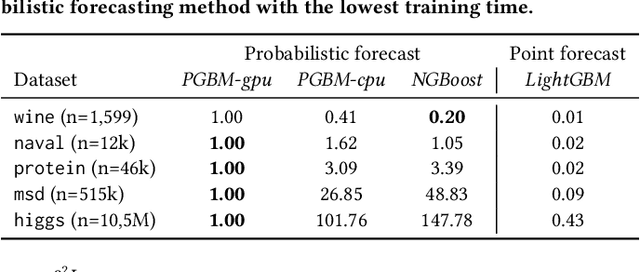
Gradient Boosting Machines (GBM) are hugely popular for solving tabular data problems. However, practitioners are not only interested in point predictions, but also in probabilistic predictions in order to quantify the uncertainty of the predictions. Creating such probabilistic predictions is difficult with existing GBM-based solutions: they either require training multiple models or they become too computationally expensive to be useful for large-scale settings. We propose Probabilistic Gradient Boosting Machines (PGBM), a method to create probabilistic predictions with a single ensemble of decision trees in a computationally efficient manner. PGBM approximates the leaf weights in a decision tree as a random variable, and approximates the mean and variance of each sample in a dataset via stochastic tree ensemble update equations. These learned moments allow us to subsequently sample from a specified distribution after training. We empirically demonstrate the advantages of PGBM compared to existing state-of-the-art methods: (i) PGBM enables probabilistic estimates without compromising on point performance in a single model, (ii) PGBM learns probabilistic estimates via a single model only (and without requiring multi-parameter boosting), and thereby offers a speedup of up to several orders of magnitude over existing state-of-the-art methods on large datasets, and (iii) PGBM achieves accurate probabilistic estimates in tasks with complex differentiable loss functions, such as hierarchical time series problems, where we observed up to 10% improvement in point forecasting performance and up to 300% improvement in probabilistic forecasting performance.
Modeling Multi-Label Action Dependencies for Temporal Action Localization
Mar 04, 2021

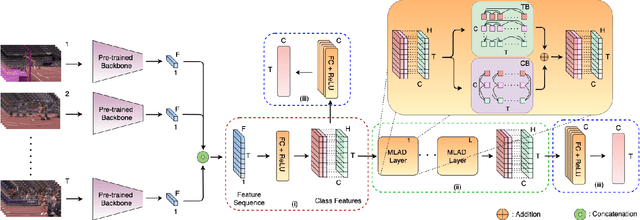
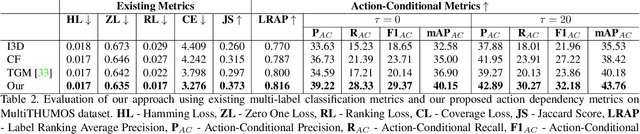
Real-world videos contain many complex actions with inherent relationships between action classes. In this work, we propose an attention-based architecture that models these action relationships for the task of temporal action localization in untrimmed videos. As opposed to previous works that leverage video-level co-occurrence of actions, we distinguish the relationships between actions that occur at the same time-step and actions that occur at different time-steps (i.e. those which precede or follow each other). We define these distinct relationships as action dependencies. We propose to improve action localization performance by modeling these action dependencies in a novel attention-based Multi-Label Action Dependency (MLAD)layer. The MLAD layer consists of two branches: a Co-occurrence Dependency Branch and a Temporal Dependency Branch to model co-occurrence action dependencies and temporal action dependencies, respectively. We observe that existing metrics used for multi-label classification do not explicitly measure how well action dependencies are modeled, therefore, we propose novel metrics that consider both co-occurrence and temporal dependencies between action classes. Through empirical evaluation and extensive analysis, we show improved performance over state-of-the-art methods on multi-label action localization benchmarks(MultiTHUMOS and Charades) in terms of f-mAP and our proposed metric.