 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-Supervised Learning of Classifiers from a Statistical Perspective: A Brief Review
Apr 13, 2021
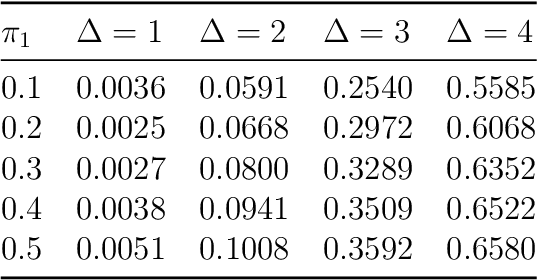
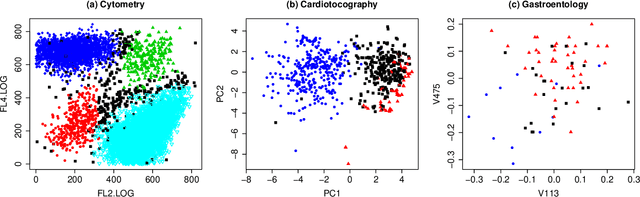
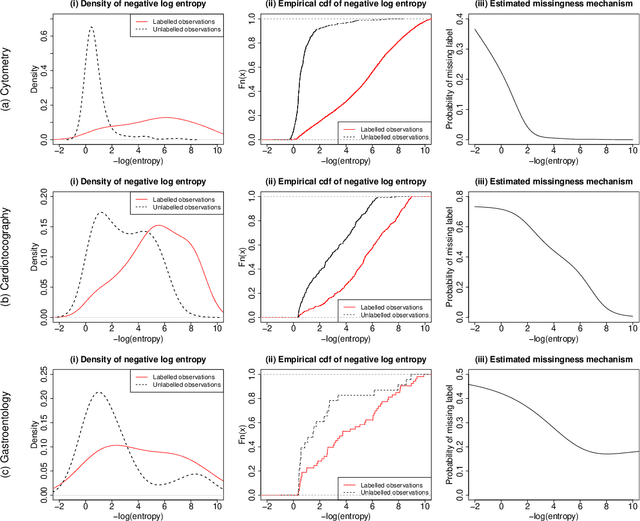
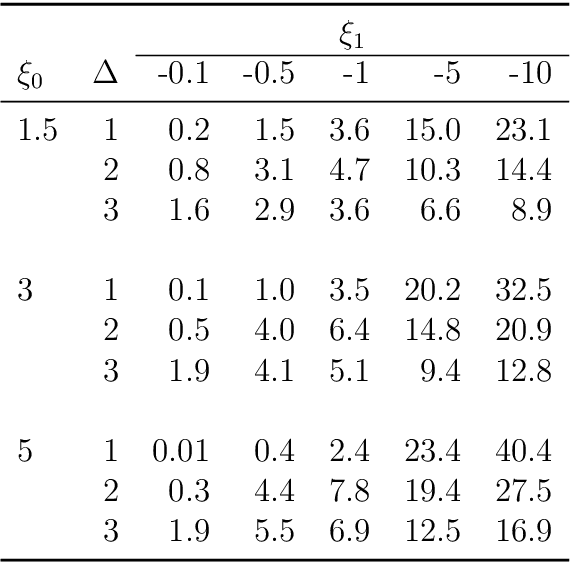
There has been increasing attention to semi-supervised learning (SSL) approaches in machine learning to forming a classifier in situations where the training data for a classifier consists of a limited number of classified observations but a much larger number of unclassified observations. This is because the procurement of classified data can be quite costly due to high acquisition costs and subsequent financial, time, and ethical issues that can arise in attempts to provide the true class labels for the unclassified data that have been acquired. We provide here a review of statistical SSL approaches to this problem, focussing on the recent result that a classifier formed from a partially classified sample can actually have smaller expected error rate than that if the sample were completely classified.
Towards General Purpose Vision Systems
Apr 01, 2021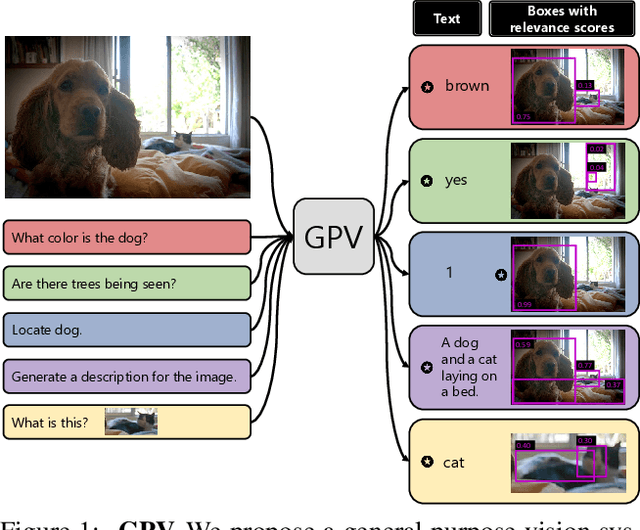
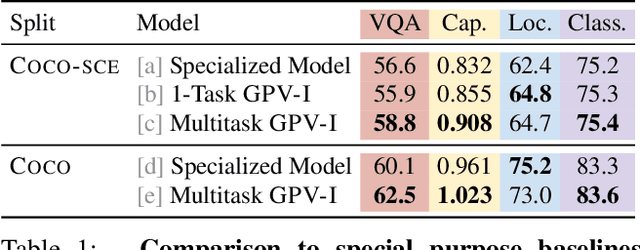
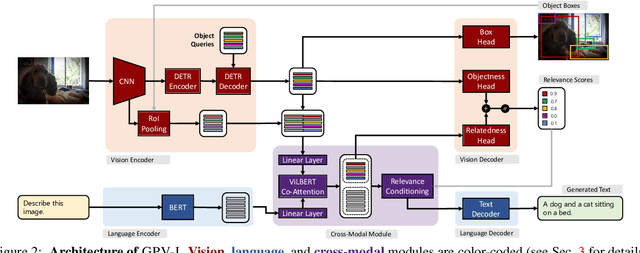

A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system's ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
Human-robot collaborative object transfer using human motion prediction based on Cartesian pose Dynamic Movement Primitives
Apr 07, 2021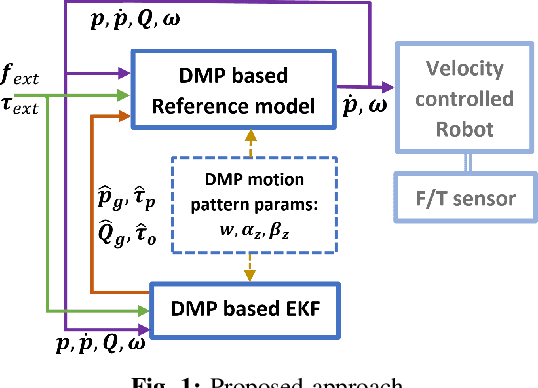

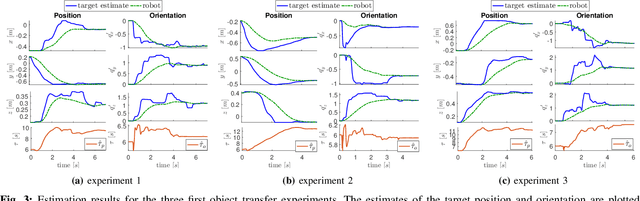
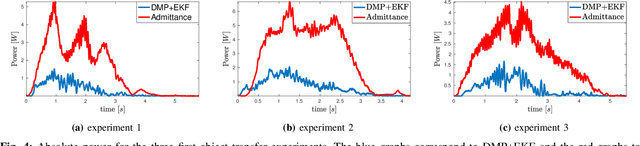
In this work, the problem of human-robot collaborative object transfer to unknown target poses is addressed. The desired pattern of the end-effector pose trajectory to a known target pose is encoded using DMPs (Dynamic Movement Primitives). During transportation of the object to new unknown targets, a DMP-based reference model and an EKF (Extended Kalman Filter) for estimating the target pose and time duration of the human's intended motion is proposed. A stability analysis of the overall scheme is provided. Experiments using a Kuka LWR4+ robot equipped with an ATI sensor at its end-effector validate its efficacy with respect to the required human effort and compare it with an admittance control scheme.
Emergence of Structural Bias in Differential Evolution
May 10, 2021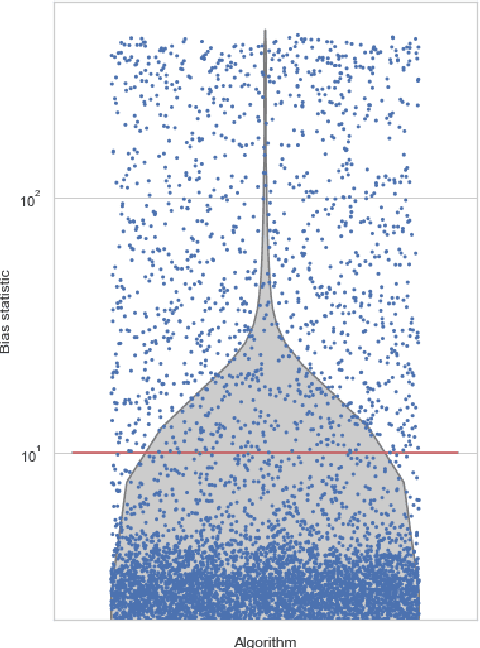
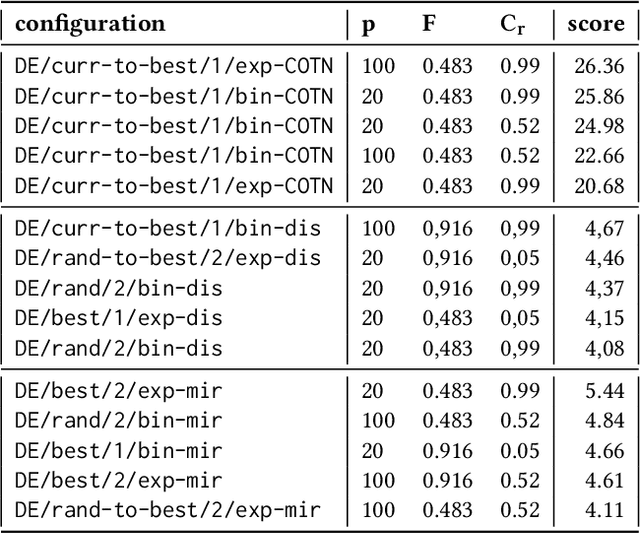
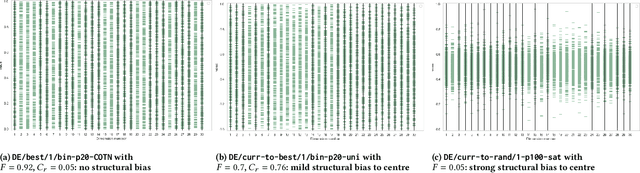
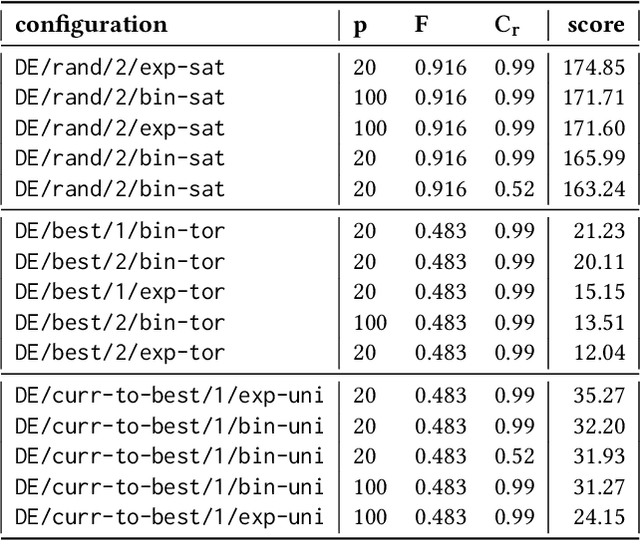
Heuristic optimisation algorithms are in high demand due to the overwhelming amount of complex optimisation problems that need to be solved. The complexity of these problems is well beyond the boundaries of applicability of exact optimisation algorithms and therefore require modern heuristics to find feasible solutions quickly. These heuristics and their effects are almost always evaluated and explained by particular problem instances. In previous works, it has been shown that many such algorithms show structural bias, by either being attracted to a certain region of the search space or by consistently avoiding regions of the search space, on a special test function designed to ensure uniform 'exploration' of the domain. In this paper, we analyse the emergence of such structural bias for Differential Evolution (DE) configurations and, specifically, the effect of different mutation, crossover and correction strategies. We also analyse the emergence of the structural bias during the run-time of each algorithm. We conclude with recommendations of which configurations should be avoided in order to run DE unbiased.
Entity-Based Query Interpretation
May 18, 2021
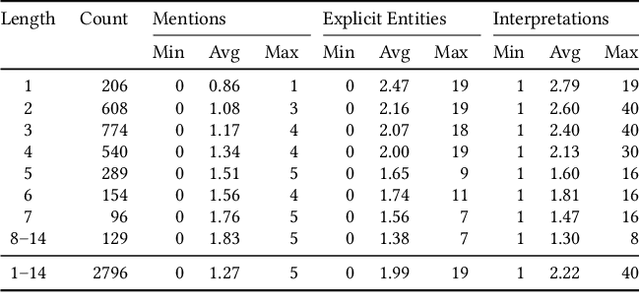
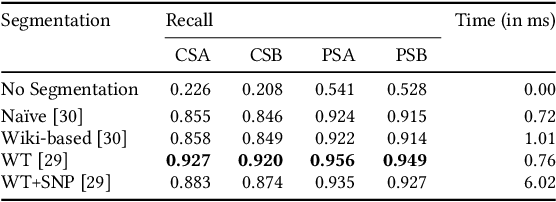
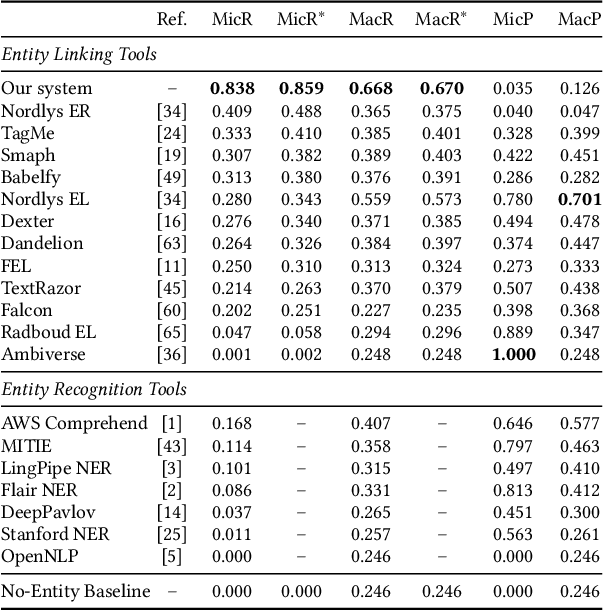
Web search queries can be rather ambiguous: Is "paris hilton" meant to find the latest news on the celebrity or to find a specific hotel in Paris? And in which of the worldwide more than 20 "Parises"? We propose to solve this ambiguity problem by deriving entity-based query interpretations: given some query, the task is to link suitable parts of the query to semantically compatible entities in a background knowledge base. Our suggested approach to identify the most reasonable interpretations of a query based on the contained entities focuses on effectiveness but also on efficiency since web search response times should not exceed some hundreds of milliseconds. In our approach, we propose to use query segmentation as a pre-processing step that finds promising segment-based "skeletons". These skeletons are then enhanced to "interpretations" by linking the contained segments to entities from a knowledge base and then ranking the interpretations in a final step. An experimental comparison on a corpus of 2,800 queries shows our approach to have a better interpretation accuracy at a better run time than the previously most effective query entity linking methods.
Partially-Connected Differentiable Architecture Search for Deepfake and Spoofing Detection
Apr 07, 2021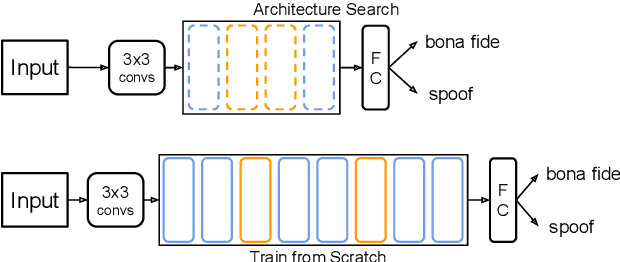
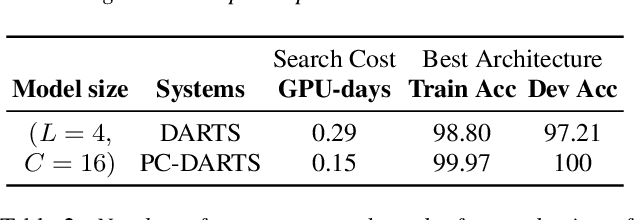
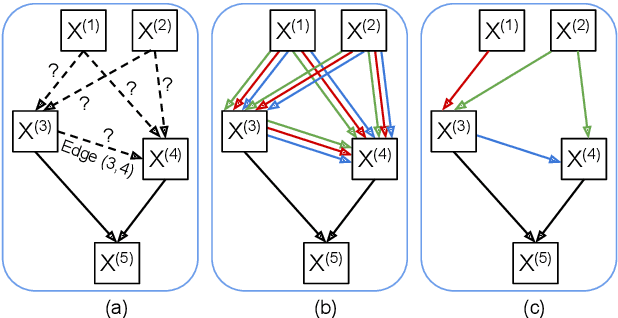
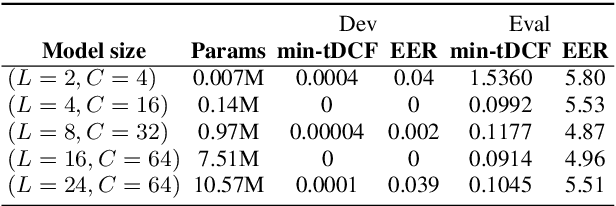
This paper reports the first successful application of a differentiable architecture search (DARTS) approach to the deepfake and spoofing detection problems. An example of neural architecture search, DARTS operates upon a continuous, differentiable search space which enables both the architecture and parameters to be optimised via gradient descent. Solutions based on partially-connected DARTS use random channel masking in the search space to reduce GPU time and automatically learn and optimise complex neural architectures composed of convolutional operations and residual blocks. Despite being learned quickly with little human effort, the resulting networks are competitive with the best performing systems reported in the literature. Some are also far less complex, containing 85% fewer parameters than a Res2Net competitor.
Anchor Distance for 3D Multi-Object Distance Estimation from 2D Single Shot
Feb 16, 2021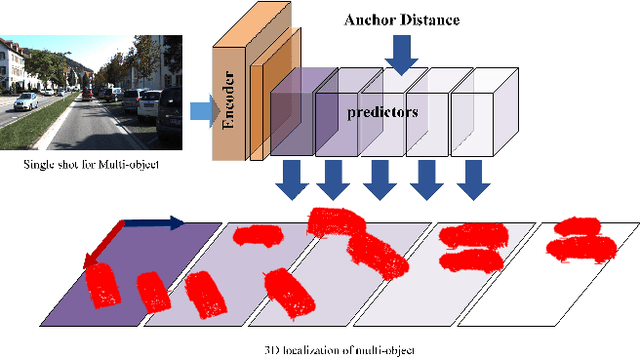
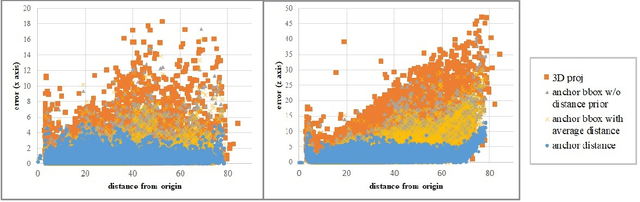
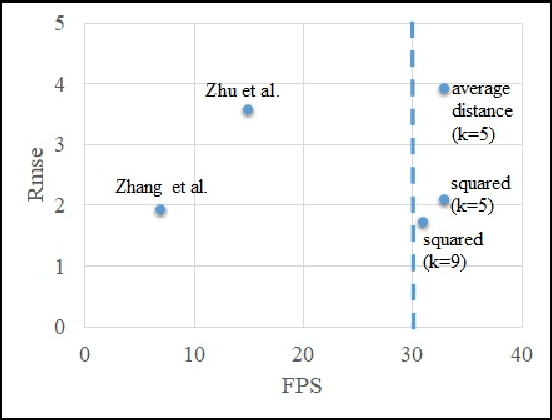
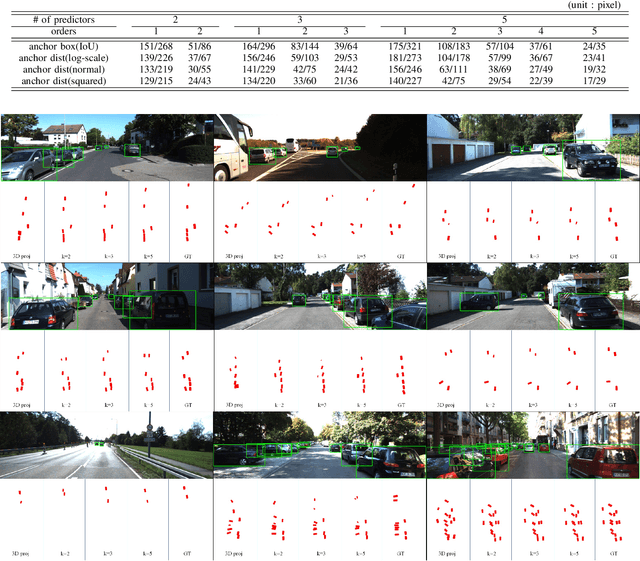
Visual perception of the objects in a 3D environment is a key to successful performance in autonomous driving and simultaneous localization and mapping (SLAM). In this paper, we present a real time approach for estimating the distances to multiple objects in a scene using only a single-shot image. Given a 2D Bounding Box (BBox) and object parameters, a 3D distance to the object can be calculated directly using 3D reprojection; however, such methods are prone to significant errors because an error from the 2D detection can be amplified in 3D. In addition, it is also challenging to apply such methods to a real-time system due to the computational burden. In the case of the traditional multi-object detection methods, %they mostly pay attention to existing works have been developed for specific tasks such as object segmentation or 2D BBox regression. These methods introduce the concept of anchor BBox for elaborate 2D BBox estimation, and predictors are specialized and trained for specific 2D BBoxes. In order to estimate the distances to the 3D objects from a single 2D image, we introduce the notion of \textit{anchor distance} based on an object's location and propose a method that applies the anchor distance to the multi-object detector structure. We let the predictors catch the distance prior using anchor distance and train the network based on the distance. The predictors can be characterized to the objects located in a specific distance range. By propagating the distance prior using a distance anchor to the predictors, it is feasible to perform the precise distance estimation and real-time execution simultaneously. The proposed method achieves about 30 FPS speed, and shows the lowest RMSE compared to the existing methods.
Providing Meaningful Data Summarizations Using Examplar-based Clustering in Industry 4.0
May 25, 2021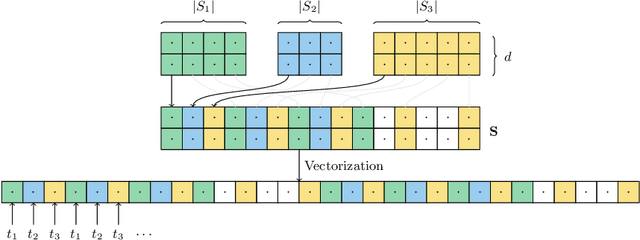
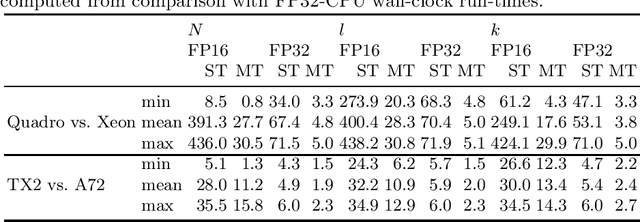
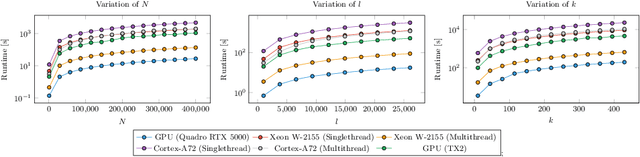
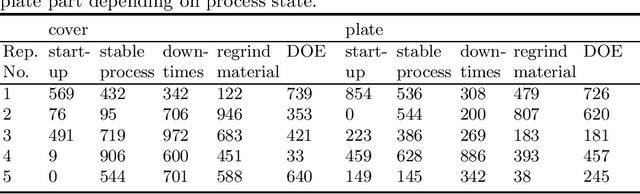
Data summarizations are a valuable tool to derive knowledge from large data streams and have proven their usefulness in a great number of applications. Summaries can be found by optimizing submodular functions. These functions map subsets of data to real values, which indicate their "representativeness" and which should be maximized to find a diverse summary of the underlying data. In this paper, we studied Exemplar-based clustering as a submodular function and provide a GPU algorithm to cope with its high computational complexity. We show, that our GPU implementation provides speedups of up to 72x using single-precision and up to 452x using half-precision computation compared to conventional CPU algorithms. We also show, that the GPU algorithm not only provides remarkable runtime benefits with workstation-grade GPUs but also with low-power embedded computation units for which speedups of up to 35x are possible. Furthermore, we apply our algorithm to real-world data from injection molding manufacturing processes and discuss how found summaries help with steering this specific process to cut costs and reduce the manufacturing of bad parts. Beyond pure speedup considerations, we show, that our approach can provide summaries within reasonable time frames for this kind of industrial, real-world data.
The Influence of Memory in Multi-Agent Consensus
May 10, 2021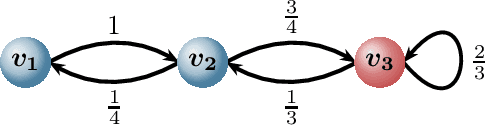
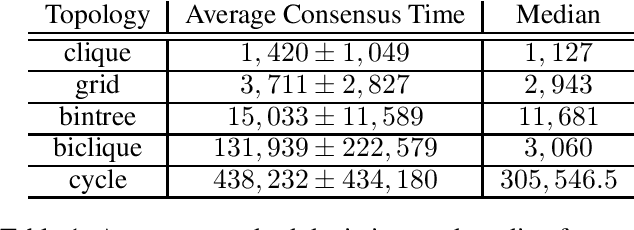
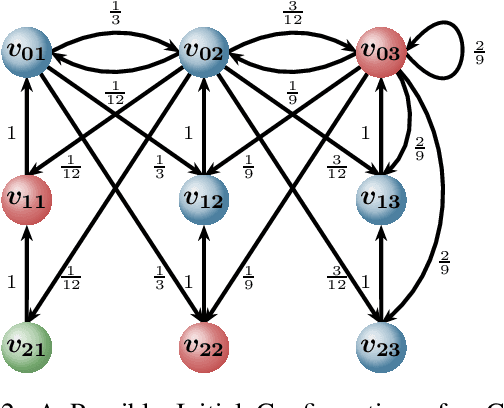
Multi-agent consensus problems can often be seen as a sequence of autonomous and independent local choices between a finite set of decision options, with each local choice undertaken simultaneously, and with a shared goal of achieving a global consensus state. Being able to estimate probabilities for the different outcomes and to predict how long it takes for a consensus to be formed, if ever, are core issues for such protocols. Little attention has been given to protocols in which agents can remember past or outdated states. In this paper, we propose a framework to study what we call \emph{memory consensus protocol}. We show that the employment of memory allows such processes to always converge, as well as, in some scenarios, such as cycles, converge faster. We provide a theoretical analysis of the probability of each option eventually winning such processes based on the initial opinions expressed by agents. Further, we perform experiments to investigate network topologies in which agents benefit from memory on the expected time needed for consensus.
Modeling Multi-Label Action Dependencies for Temporal Action Localization
Mar 05, 2021

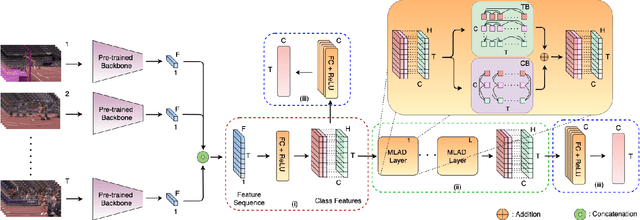
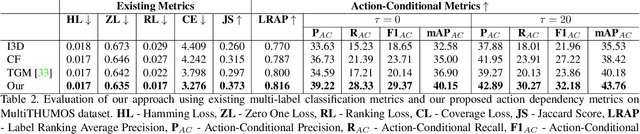
Real-world videos contain many complex actions with inherent relationships between action classes. In this work, we propose an attention-based architecture that models these action relationships for the task of temporal action localization in untrimmed videos. As opposed to previous works that leverage video-level co-occurrence of actions, we distinguish the relationships between actions that occur at the same time-step and actions that occur at different time-steps (i.e. those which precede or follow each other). We define these distinct relationships as action dependencies. We propose to improve action localization performance by modeling these action dependencies in a novel attention-based Multi-Label Action Dependency (MLAD)layer. The MLAD layer consists of two branches: a Co-occurrence Dependency Branch and a Temporal Dependency Branch to model co-occurrence action dependencies and temporal action dependencies, respectively. We observe that existing metrics used for multi-label classification do not explicitly measure how well action dependencies are modeled, therefore, we propose novel metrics that consider both co-occurrence and temporal dependencies between action classes. Through empirical evaluation and extensive analysis, we show improved performance over state-of-the-art methods on multi-label action localization benchmarks(MultiTHUMOS and Charades) in terms of f-mAP and our proposed metric.