 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Width Transfer: On the (In)variance of Width Optimization
Apr 24, 2021
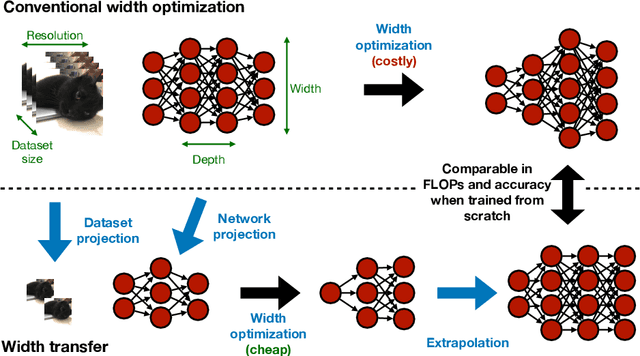

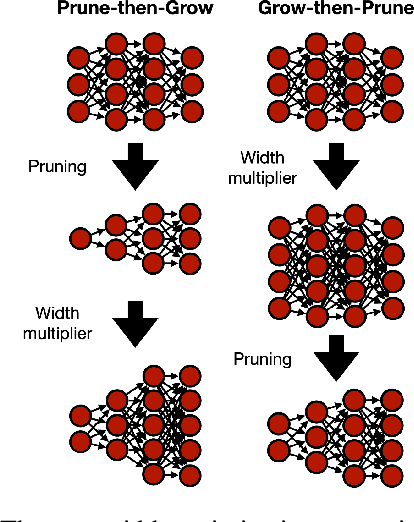
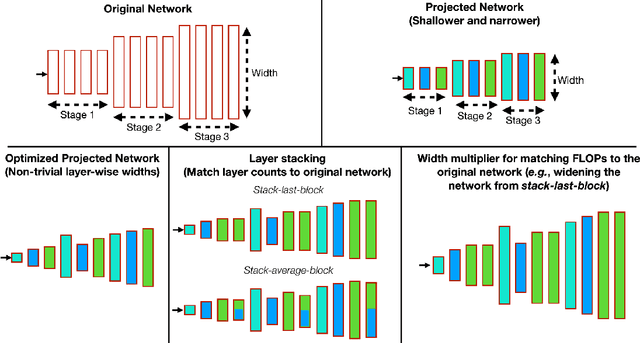
Optimizing the channel counts for different layers of a CNN has shown great promise in improving the efficiency of CNNs at test-time. However, these methods often introduce large computational overhead (e.g., an additional 2x FLOPs of standard training). Minimizing this overhead could therefore significantly speed up training. In this work, we propose width transfer, a technique that harnesses the assumptions that the optimized widths (or channel counts) are regular across sizes and depths. We show that width transfer works well across various width optimization algorithms and networks. Specifically, we can achieve up to 320x reduction in width optimization overhead without compromising the top-1 accuracy on ImageNet, making the additional cost of width optimization negligible relative to initial training. Our findings not only suggest an efficient way to conduct width optimization but also highlight that the widths that lead to better accuracy are invariant to various aspects of network architectures and training data.
2.5-dimensional distributed model training
May 30, 2021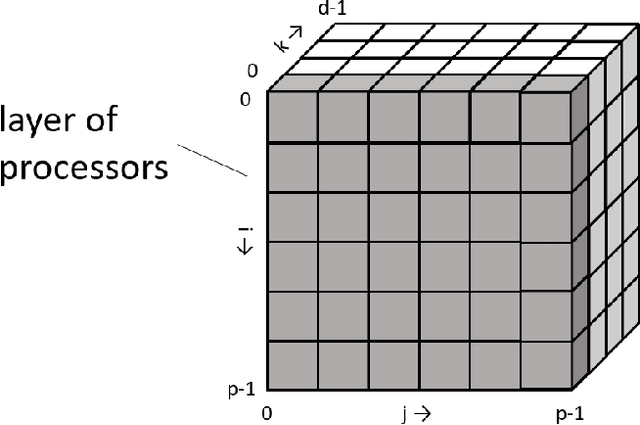
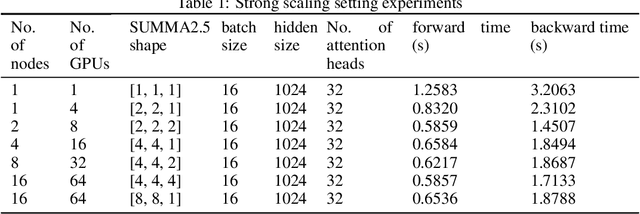
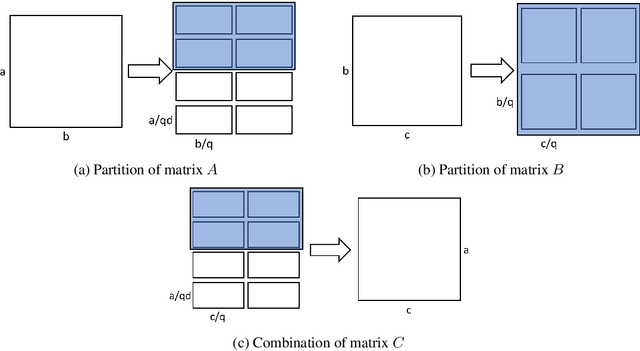
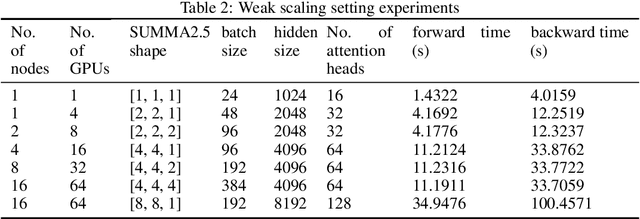
Data parallelism does a good job in speeding up the training. However, when it comes to the case when the memory of a single device can not host a whole model, data parallelism would not have the chance to do anything. Another option is to split the model by operator, or horizontally. Megatron-LM introduced a 1-Dimensional distributed method to use GPUs to speed up the training process. Optimus is a 2D solution for distributed tensor parallelism. However, these methods have a high communication overhead and a low scaling efficiency on large-scale computing clusters. To solve this problem, we investigate the 2.5-Dimensional distributed tensor parallelism.Introduced by Solomonik et al., 2.5-Dimensional Matrix Multiplication developed an effective method to perform multiple Cannon's algorithm at the same time to increase the efficiency. With many restrictions of Cannon's Algorithm and a huge amount of shift operation, we need to invent a new method of 2.5-dimensional matrix multiplication to enhance the performance. Absorbing the essence from both SUMMA and 2.5-Dimensional Matrix Multiplication, we introduced SUMMA2.5-LM for language models to overcome the abundance of unnecessary transmission loss result from the increasing size of language model parallelism. Compared to previous 1D and 2D model parallelization of language models, our SUMMA2.5-LM managed to reduce the transmission cost on each layer, which could get a 1.45X efficiency according to our weak scaling result between 2.5-D [4,4,4] arrangement and 2-D [8,8,1] arrangement.
TweetCOVID: A System for Analyzing Public Sentiments and Discussions about COVID-19 via Twitter Activities
Mar 02, 2021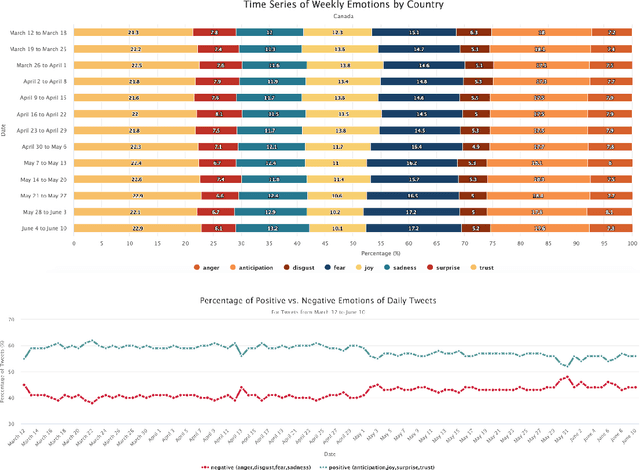
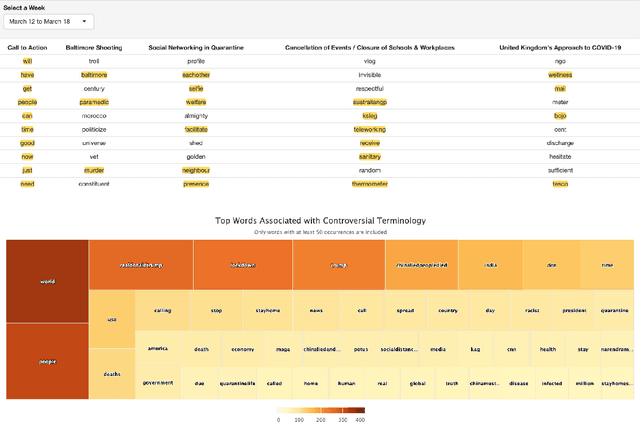
The COVID-19 pandemic has created widespread health and economical impacts, affecting millions around the world. To better understand these impacts, we present the TweetCOVID system that offers the capability to understand the public reactions to the COVID-19 pandemic in terms of their sentiments, emotions, topics of interest and controversial discussions, over a range of time periods and locations, using public tweets. We also present three example use cases that illustrates the usefulness of our proposed TweetCOVID system.
CSCAD: Correlation Structure-based Collective Anomaly Detection in Complex System
May 30, 2021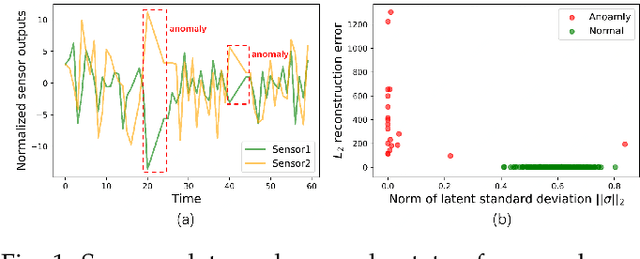
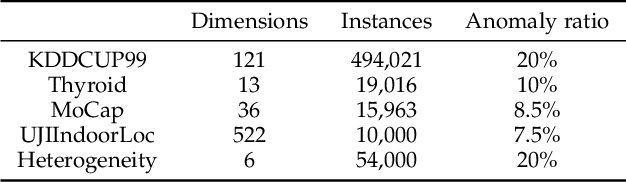
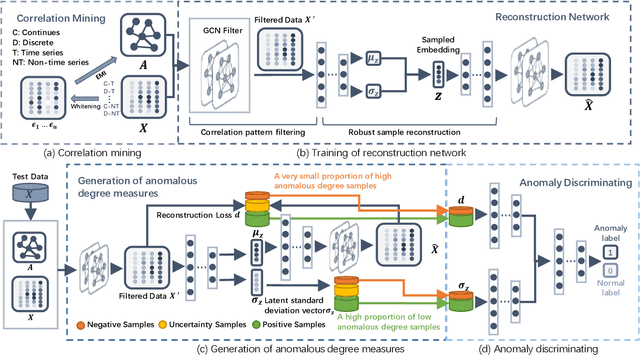
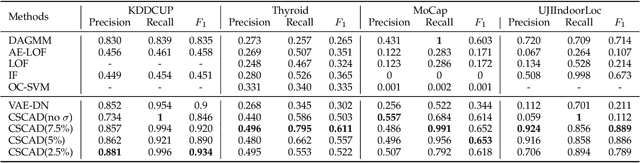
Detecting anomalies in large complex systems is a critical and challenging task. The difficulties arise from several aspects. First, collecting ground truth labels or prior knowledge for anomalies is hard in real-world systems, which often lead to limited or no anomaly labels in the dataset. Second, anomalies in large systems usually occur in a collective manner due to the underlying dependency structure among devices or sensors. Lastly, real-time anomaly detection for high-dimensional data requires efficient algorithms that are capable of handling different types of data (i.e. continuous and discrete). We propose a correlation structure-based collective anomaly detection (CSCAD) model for high-dimensional anomaly detection problem in large systems, which is also generalizable to semi-supervised or supervised settings. Our framework utilize graph convolutional network combining a variational autoencoder to jointly exploit the feature space correlation and reconstruction deficiency of samples to perform anomaly detection. We propose an extended mutual information (EMI) metric to mine the internal correlation structure among different data features, which enhances the data reconstruction capability of CSCAD. The reconstruction loss and latent standard deviation vector of a sample obtained from reconstruction network can be perceived as two natural anomalous degree measures. An anomaly discriminating network can then be trained using low anomalous degree samples as positive samples, and high anomalous degree samples as negative samples. Experimental results on five public datasets demonstrate that our approach consistently outperforms all the competing baselines.
TEA-DNN: the Quest for Time-Energy-Accuracy Co-optimized Deep Neural Networks
Nov 29, 2018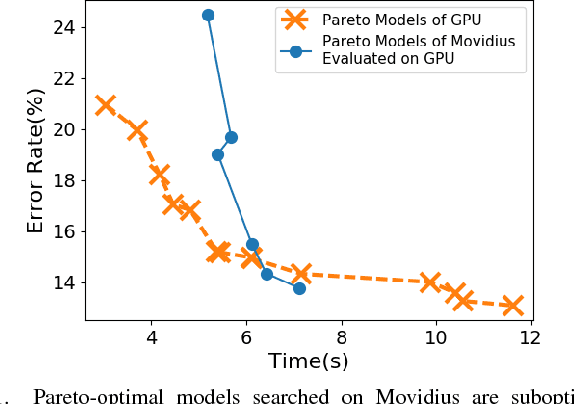
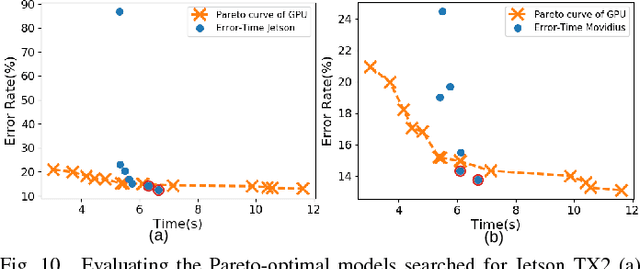
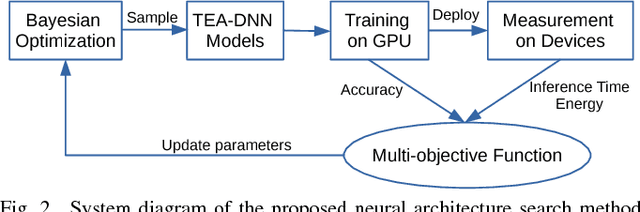
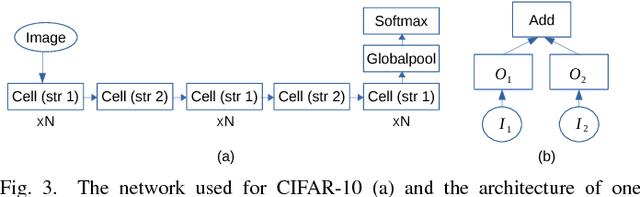
Embedded deep learning platforms have witnessed two simultaneous improvements. First, the accuracy of convolutional neural networks (CNNs) has been significantly improved through the use of automated neural-architecture search (NAS) algorithms to determine CNN structure. Second, there has been increasing interest in developing application-specific platforms for CNNs that provide improved inference performance and energy consumption as compared to GPUs. Embedded deep learning platforms differ in the amount of compute resources and memory-access bandwidth, which would affect performance and energy consumption of CNNs. It is therefore critical to consider the available hardware resources in the network architecture search. To this end, we introduce TEA-DNN, a NAS algorithm targeting multi-objective optimization of execution time, energy consumption, and classification accuracy of CNN workloads on embedded architectures. TEA-DNN leverages energy and execution time measurements on embedded hardware when exploring the Pareto-optimal curves across accuracy, execution time, and energy consumption and does not require additional effort to model the underlying hardware. We apply TEA-DNN for image classification on actual embedded platforms (NVIDIA Jetson TX2 and Intel Movidius Neural Compute Stick). We highlight the Pareto-optimal operating points that emphasize the necessity to explicitly consider hardware characteristics in the search process. To the best of our knowledge, this is the most comprehensive study of Pareto-optimal models across a range of hardware platforms using actual measurements on hardware to obtain objective values.
Towards Discovery and Attribution of Open-world GAN Generated Images
May 10, 2021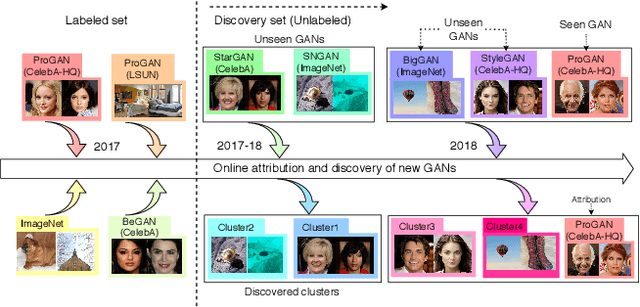

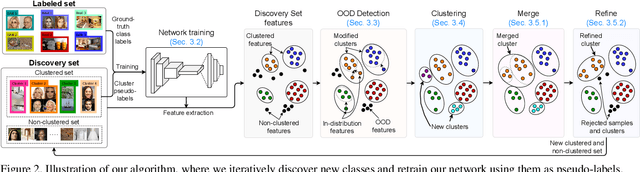
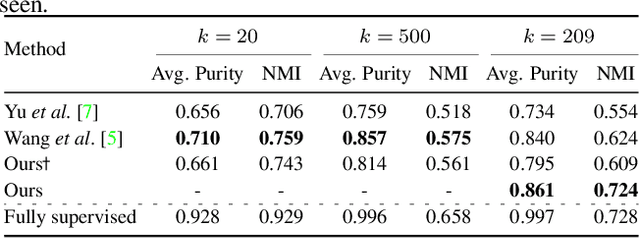
With the recent progress in Generative Adversarial Networks (GANs), it is imperative for media and visual forensics to develop detectors which can identify and attribute images to the model generating them. Existing works have shown to attribute images to their corresponding GAN sources with high accuracy. However, these works are limited to a closed set scenario, failing to generalize to GANs unseen during train time and are therefore, not scalable with a steady influx of new GANs. We present an iterative algorithm for discovering images generated from previously unseen GANs by exploiting the fact that all GANs leave distinct fingerprints on their generated images. Our algorithm consists of multiple components including network training, out-of-distribution detection, clustering, merge and refine steps. Through extensive experiments, we show that our algorithm discovers unseen GANs with high accuracy and also generalizes to GANs trained on unseen real datasets. We additionally apply our algorithm to attribution and discovery of GANs in an online fashion as well as to the more standard task of real/fake detection. Our experiments demonstrate the effectiveness of our approach to discover new GANs and can be used in an open-world setup.
Learning to Localize Using a LiDAR Intensity Map
Dec 20, 2020
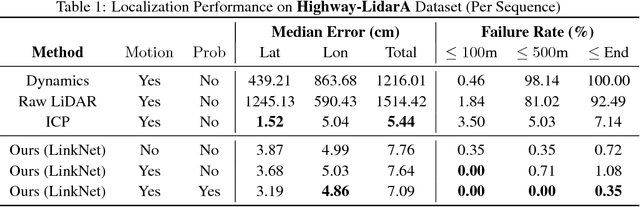
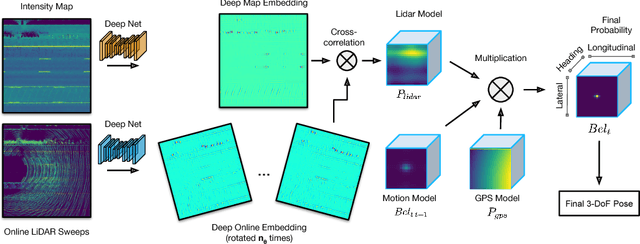

In this paper we propose a real-time, calibration-agnostic and effective localization system for self-driving cars. Our method learns to embed the online LiDAR sweeps and intensity map into a joint deep embedding space. Localization is then conducted through an efficient convolutional matching between the embeddings. Our full system can operate in real-time at 15Hz while achieving centimeter level accuracy across different LiDAR sensors and environments. Our experiments illustrate the performance of the proposed approach over a large-scale dataset consisting of over 4000km of driving.
* 12 pages, 7 figures, 5 tables; Presented at the 2nd Conference on Robot Learning (CoRL), 2018
A Constrained Coupled Matrix-Tensor Factorization for Learning Time-evolving and Emerging Topics
Jun 30, 2018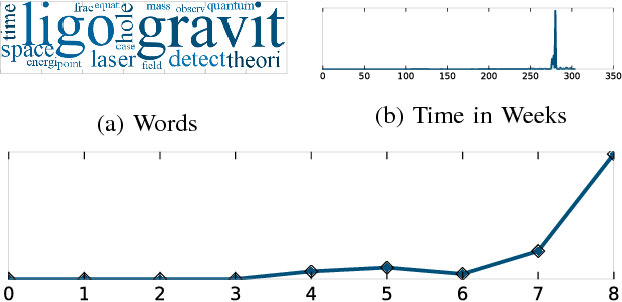
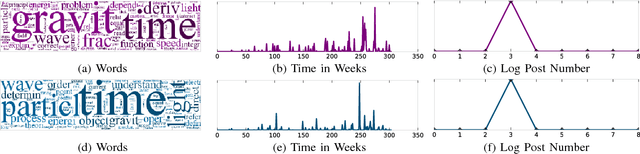
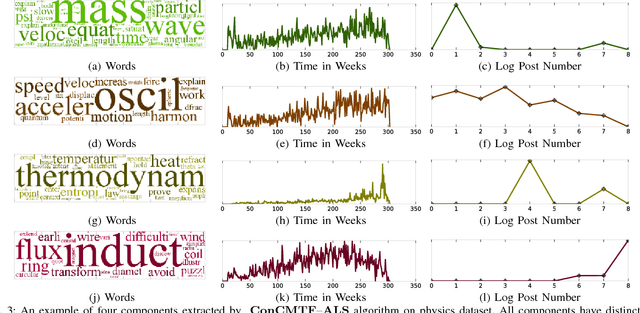
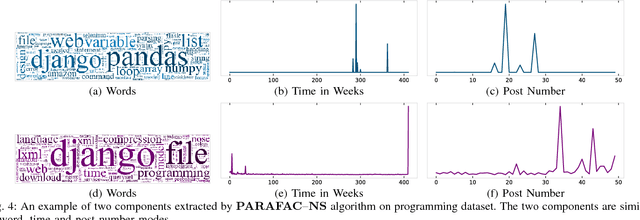
Topic discovery has witnessed a significant growth as a field of data mining at large. In particular, time-evolving topic discovery, where the evolution of a topic is taken into account has been instrumental in understanding the historical context of an emerging topic in a dynamic corpus. Traditionally, time-evolving topic discovery has focused on this notion of time. However, especially in settings where content is contributed by a community or a crowd, an orthogonal notion of time is the one that pertains to the level of expertise of the content creator: the more experienced the creator, the more advanced the topic. In this paper, we propose a novel time-evolving topic discovery method which, in addition to the extracted topics, is able to identify the evolution of that topic over time, as well as the level of difficulty of that topic, as it is inferred by the level of expertise of its main contributors. Our method is based on a novel formulation of Constrained Coupled Matrix-Tensor Factorization, which adopts constraints well-motivated for, and, as we demonstrate, are essential for high-quality topic discovery. We qualitatively evaluate our approach using real data from the Physics and also Programming Stack Exchange forum, and we were able to identify topics of varying levels of difficulty which can be linked to external events, such as the announcement of gravitational waves by the LIGO lab in Physics forum. We provide a quantitative evaluation of our method by conducting a user study where experts were asked to judge the coherence and quality of the extracted topics. Finally, our proposed method has implications for automatic curriculum design using the extracted topics, where the notion of the level of difficulty is necessary for the proper modeling of prerequisites and advanced concepts.
Kernel Thinning
May 17, 2021
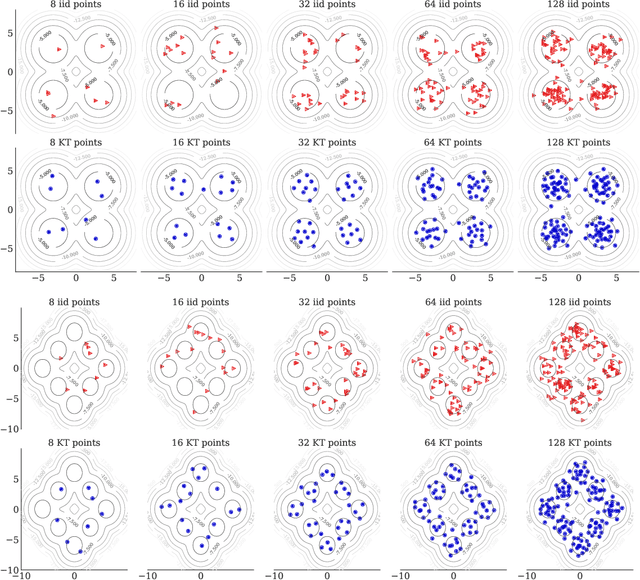
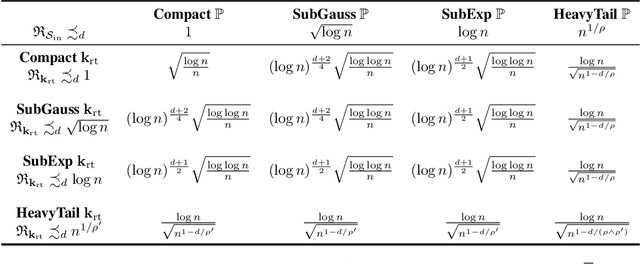
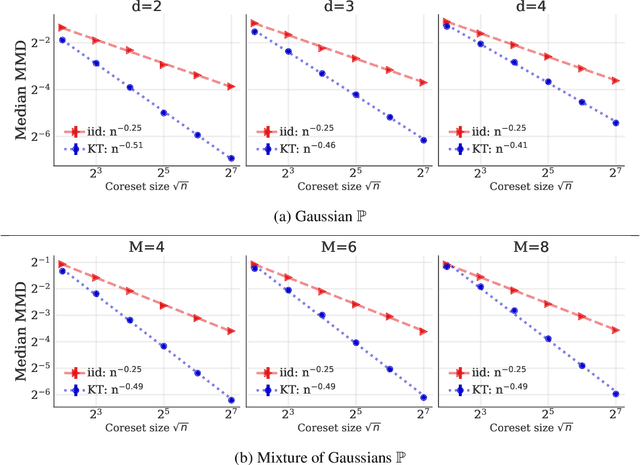
We introduce kernel thinning, a new procedure for compressing a distribution $\mathbb{P}$ more effectively than i.i.d. sampling or standard thinning. Given a suitable reproducing kernel $\mathbf{k}$ and $\mathcal{O}(n^2)$ time, kernel thinning compresses an $n$-point approximation to $\mathbb{P}$ into a $\sqrt{n}$-point approximation with comparable worst-case integration error in the associated reproducing kernel Hilbert space. With high probability, the maximum discrepancy in integration error is $\mathcal{O}_d(n^{-\frac{1}{2}}\sqrt{\log n})$ for compactly supported $\mathbb{P}$ and $\mathcal{O}_d(n^{-\frac{1}{2}} \sqrt{(\log n)^{d+1}\log\log n})$ for sub-exponential $\mathbb{P}$ on $\mathbb{R}^d$. In contrast, an equal-sized i.i.d. sample from $\mathbb{P}$ suffers $\Omega(n^{-\frac14})$ integration error. Our sub-exponential guarantees resemble the classical quasi-Monte Carlo error rates for uniform $\mathbb{P}$ on $[0,1]^d$ but apply to general distributions on $\mathbb{R}^d$ and a wide range of common kernels. We use our results to derive explicit non-asymptotic maximum mean discrepancy bounds for Gaussian, Mat\'ern, and B-spline kernels and present two vignettes illustrating the practical benefits of kernel thinning over i.i.d. sampling and standard Markov chain Monte Carlo thinning.
Algorithm-Agnostic Explainability for Unsupervised Clustering
May 17, 2021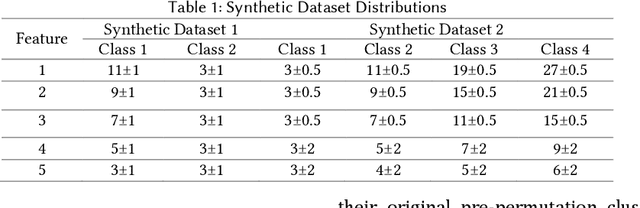
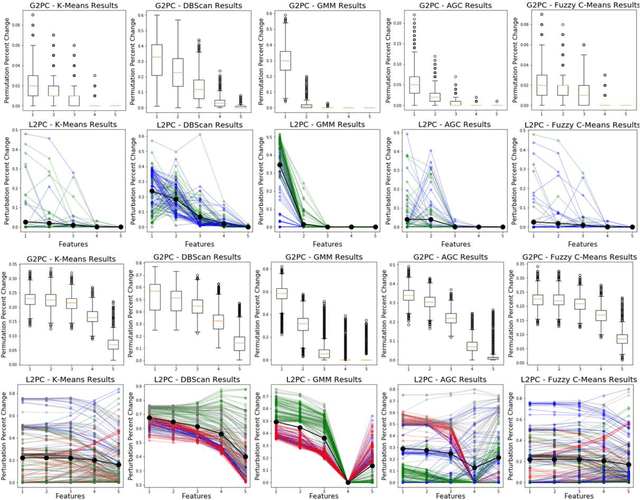
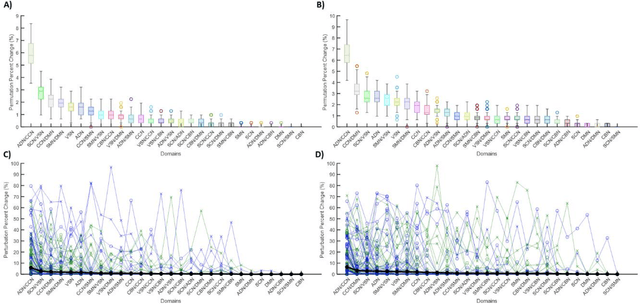
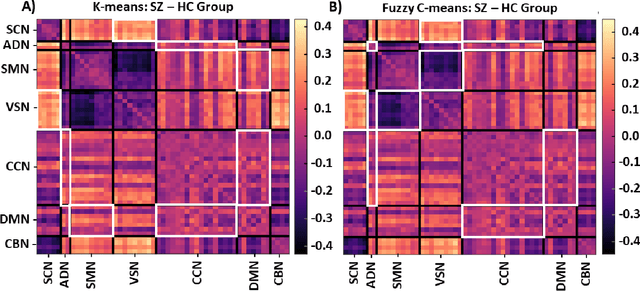
Supervised machine learning explainability has greatly expanded in recent years. However, the field of unsupervised clustering explainability has lagged behind. Here, we, to the best of our knowledge, demonstrate for the first time how model-agnostic methods for supervised machine learning explainability can be adapted to provide algorithm-agnostic unsupervised clustering explainability. We present two novel algorithm-agnostic explainability methods, global permutation percent change (G2PC) feature importance and local perturbation percent change (L2PC) feature importance, that can provide insight into many clustering methods on a global level by identifying the relative importance of features to a clustering algorithm and on a local level by identifying the relative importance of features to the clustering of individual samples. We demonstrate the utility of the methods for explaining five popular clustering algorithms on low-dimensional, ground-truth synthetic datasets and on high-dimensional functional network connectivity (FNC) data extracted from a resting state functional magnetic resonance imaging (rs-fMRI) dataset of 151 subjects with schizophrenia (SZ) and 160 healthy controls (HC). Our proposed explainability methods robustly identify the relative importance of features across multiple clustering methods and could facilitate new insights into many applications. We hope that this study will greatly accelerate the development of the field of clustering explainability.