 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Localize Using a LiDAR Intensity Map
Dec 20, 2020

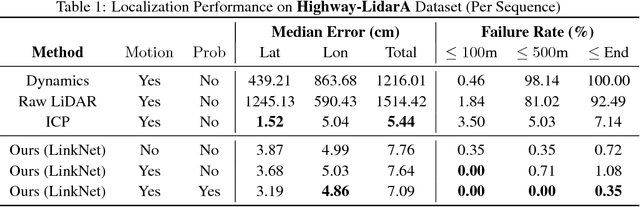
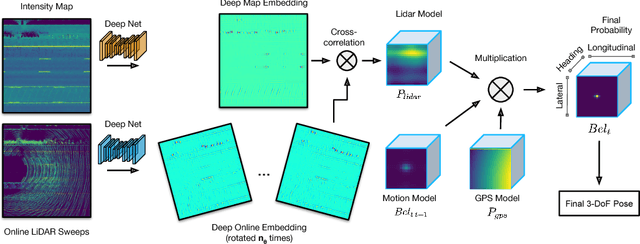

In this paper we propose a real-time, calibration-agnostic and effective localization system for self-driving cars. Our method learns to embed the online LiDAR sweeps and intensity map into a joint deep embedding space. Localization is then conducted through an efficient convolutional matching between the embeddings. Our full system can operate in real-time at 15Hz while achieving centimeter level accuracy across different LiDAR sensors and environments. Our experiments illustrate the performance of the proposed approach over a large-scale dataset consisting of over 4000km of driving.
* 12 pages, 7 figures, 5 tables; Presented at the 2nd Conference on Robot Learning (CoRL), 2018
Benchmarking down-scaled (not so large) pre-trained language models
May 11, 2021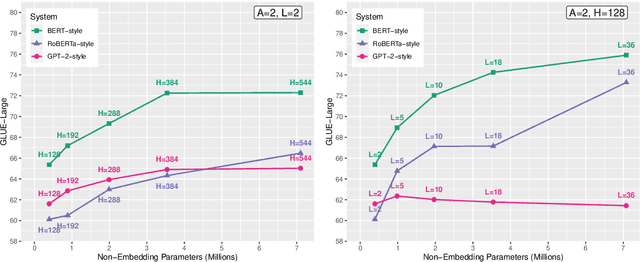
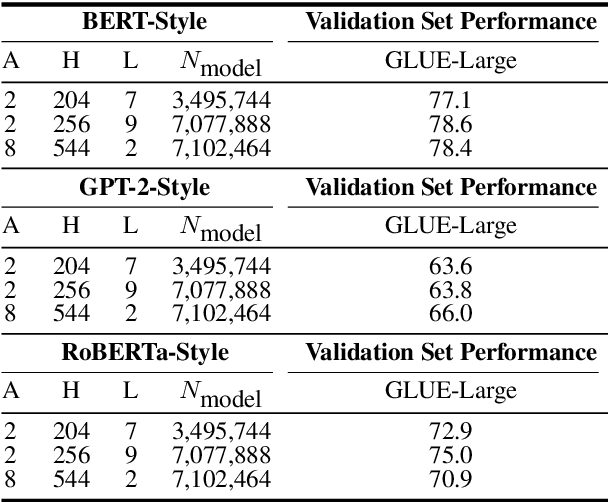
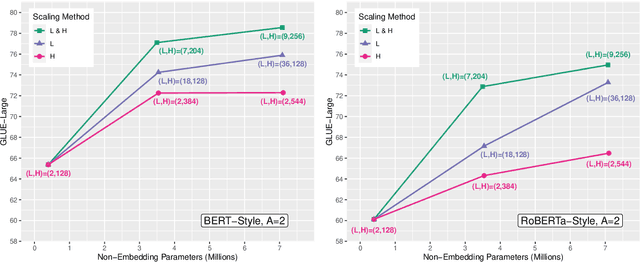
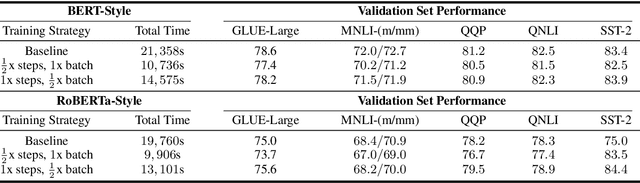
Large Transformer-based language models are pre-trained on corpora of varying sizes, for a different number of steps and with different batch sizes. At the same time, more fundamental components, such as the pre-training objective or architectural hyperparameters, are modified. In total, it is therefore difficult to ascribe changes in performance to specific factors. Since searching the hyperparameter space over the full systems is too costly, we pre-train down-scaled versions of several popular Transformer-based architectures on a common pre-training corpus and benchmark them on a subset of the GLUE tasks (Wang et al., 2018). Specifically, we systematically compare three pre-training objectives for different shape parameters and model sizes, while also varying the number of pre-training steps and the batch size. In our experiments MLM + NSP (BERT-style) consistently outperforms MLM (RoBERTa-style) as well as the standard LM objective. Furthermore, we find that additional compute should be mainly allocated to an increased model size, while training for more steps is inefficient. Based on these observations, as a final step we attempt to scale up several systems using compound scaling (Tan and Le, 2019) adapted to Transformer-based language models.
Estimation and Quantization of Expected Persistence Diagrams
May 11, 2021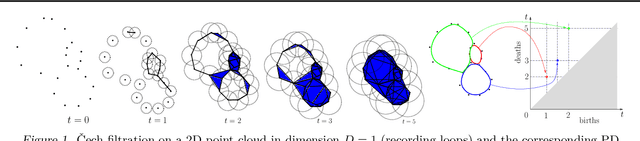
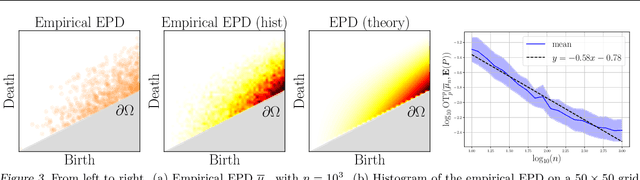
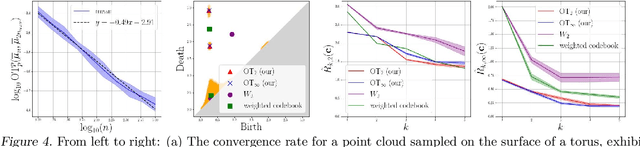
Persistence diagrams (PDs) are the most common descriptors used to encode the topology of structured data appearing in challenging learning tasks; think e.g. of graphs, time series or point clouds sampled close to a manifold. Given random objects and the corresponding distribution of PDs, one may want to build a statistical summary-such as a mean-of these random PDs, which is however not a trivial task as the natural geometry of the space of PDs is not linear. In this article, we study two such summaries, the Expected Persistence Diagram (EPD), and its quantization. The EPD is a measure supported on R 2 , which may be approximated by its empirical counterpart. We prove that this estimator is optimal from a minimax standpoint on a large class of models with a parametric rate of convergence. The empirical EPD is simple and efficient to compute, but possibly has a very large support, hindering its use in practice. To overcome this issue, we propose an algorithm to compute a quantization of the empirical EPD, a measure with small support which is shown to approximate with near-optimal rates a quantization of the theoretical EPD.
Distributed DoS Attack Detection in SDN: Trade offs in Resource Constrained Wireless Networks
Mar 25, 2021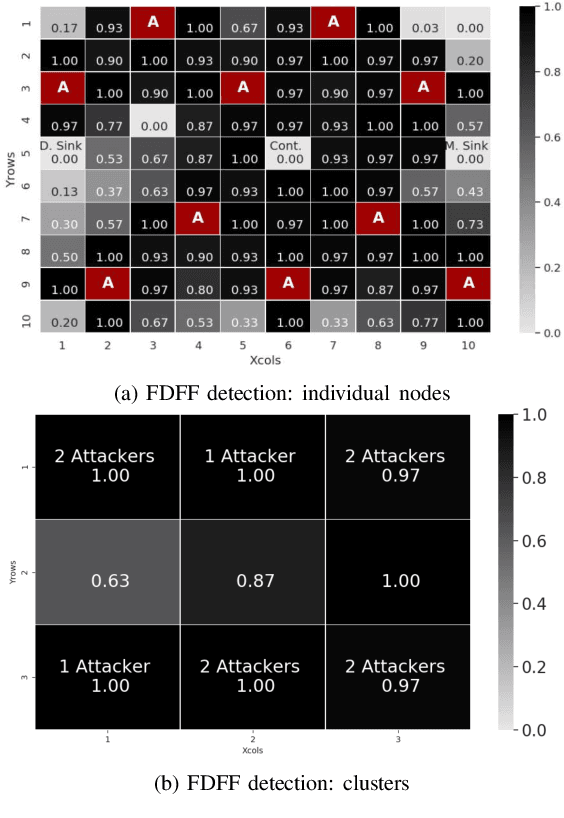
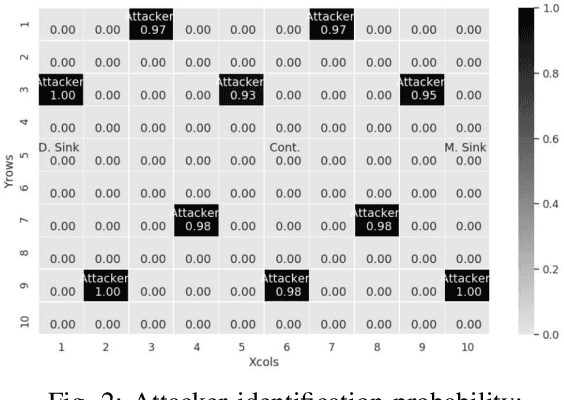
The Software-defined networking(SDN) paradigm centralizes control decisions to improve programmability and simplify network management. However, this centralization turns the network vulnerable to denial of service (DoS) attacks, and in the case of resource constrained networks, the vulnerabilities escalate. The main shortcoming in current security solutions is the trade off between detection rate and complexity. In this work, we propose a DoS attack detection algorithm for SDN resource constrained networks, based on recent results on non-parametric real-time change point detection, and lightweight enough to run on individual resource constrained devices. Our experiment results show detection rates and attacker identification probabilities equal or over 0.93.
Automatic linear measurements of the fetal brain on MRI with deep neural networks
Jun 15, 2021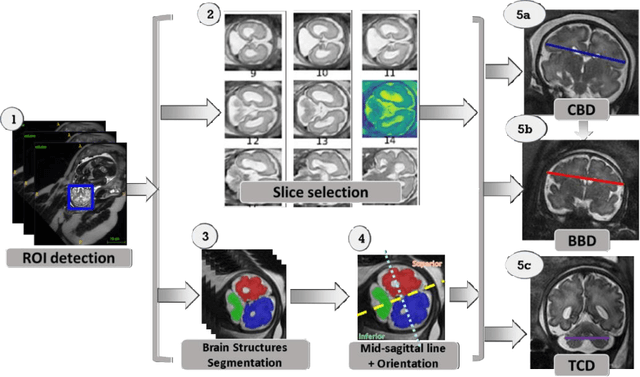
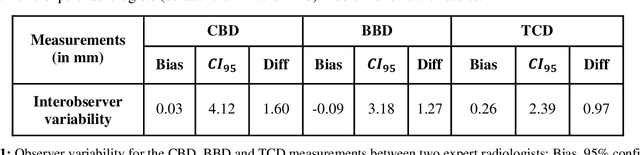
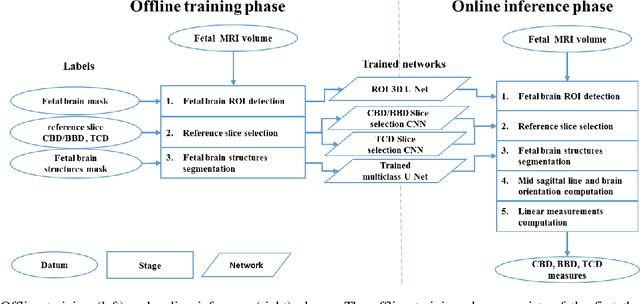
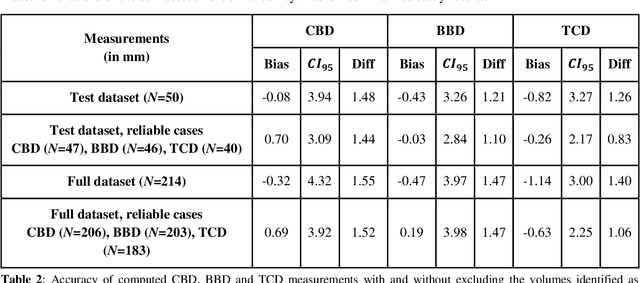
Timely, accurate and reliable assessment of fetal brain development is essential to reduce short and long-term risks to fetus and mother. Fetal MRI is increasingly used for fetal brain assessment. Three key biometric linear measurements important for fetal brain evaluation are Cerebral Biparietal Diameter (CBD), Bone Biparietal Diameter (BBD), and Trans-Cerebellum Diameter (TCD), obtained manually by expert radiologists on reference slices, which is time consuming and prone to human error. The aim of this study was to develop a fully automatic method computing the CBD, BBD and TCD measurements from fetal brain MRI. The input is fetal brain MRI volumes which may include the fetal body and the mother's abdomen. The outputs are the measurement values and reference slices on which the measurements were computed. The method, which follows the manual measurements principle, consists of five stages: 1) computation of a Region Of Interest that includes the fetal brain with an anisotropic 3D U-Net classifier; 2) reference slice selection with a Convolutional Neural Network; 3) slice-wise fetal brain structures segmentation with a multiclass U-Net classifier; 4) computation of the fetal brain midsagittal line and fetal brain orientation, and; 5) computation of the measurements. Experimental results on 214 volumes for CBD, BBD and TCD measurements yielded a mean $L_1$ difference of 1.55mm, 1.45mm and 1.23mm respectively, and a Bland-Altman 95% confidence interval ($CI_{95}$) of 3.92mm, 3.98mm and 2.25mm respectively. These results are similar to the manual inter-observer variability. The proposed automatic method for computing biometric linear measurements of the fetal brain from MR imaging achieves human level performance. It has the potential of being a useful method for the assessment of fetal brain biometry in normal and pathological cases, and of improving routine clinical practice.
Inductive Predictions of Extreme Hydrologic Events in The Wabash River Watershed
Apr 25, 2021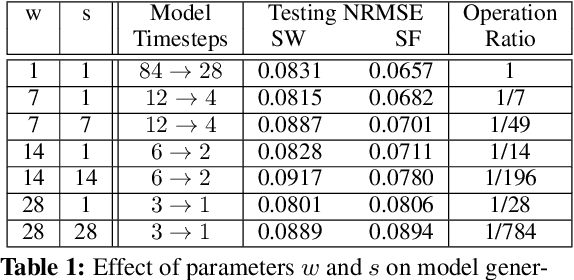
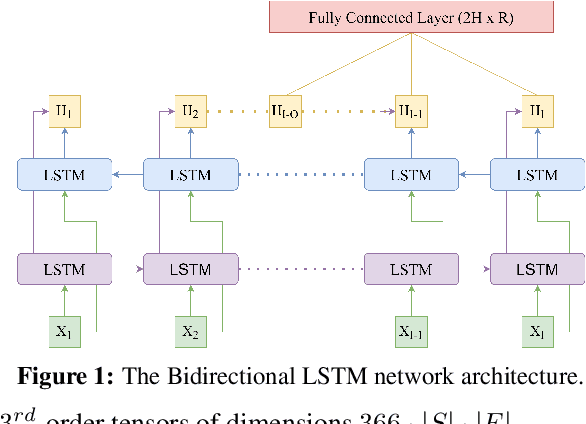
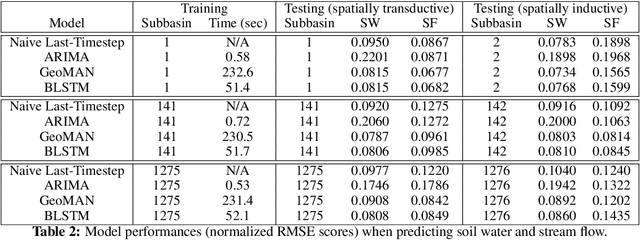
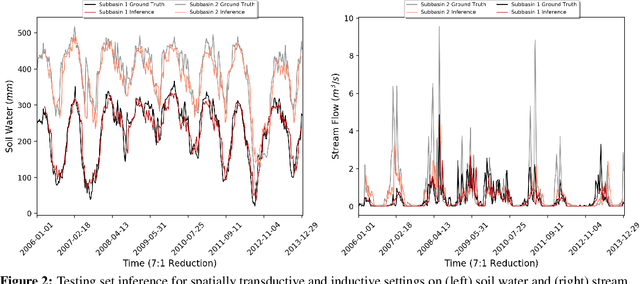
We present a machine learning method to predict extreme hydrologic events from spatially and temporally varying hydrological and meteorological data. We used a timestep reduction technique to reduce the computational and memory requirements and trained a bidirection LSTM network to predict soil water and stream flow from time series data observed and simulated over eighty years in the Wabash River Watershed. We show that our simple model can be trained much faster than complex attention networks such as GeoMAN without sacrificing accuracy. Based on the predicted values of soil water and stream flow, we predict the occurrence and severity of extreme hydrologic events such as droughts. We also demonstrate that extreme events can be predicted in geographical locations separate from locations observed during the training process. This spatially-inductive setting enables us to predict extreme events in other areas in the US and other parts of the world using our model trained with the Wabash Basin data.
TweetCOVID: A System for Analyzing Public Sentiments and Discussions about COVID-19 via Twitter Activities
Mar 02, 2021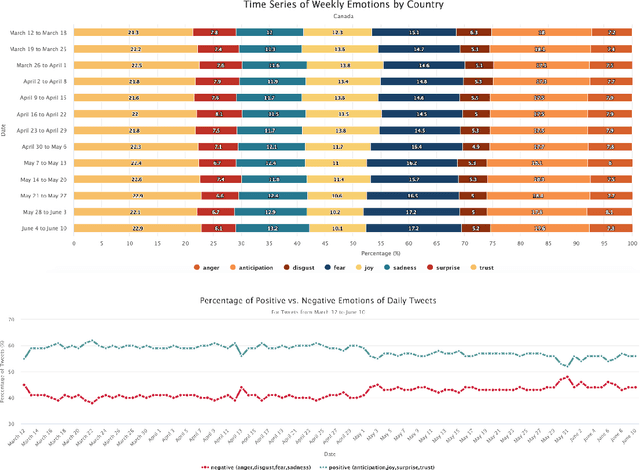
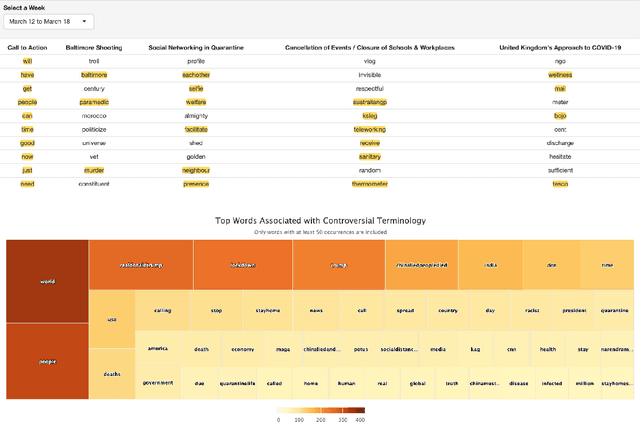
The COVID-19 pandemic has created widespread health and economical impacts, affecting millions around the world. To better understand these impacts, we present the TweetCOVID system that offers the capability to understand the public reactions to the COVID-19 pandemic in terms of their sentiments, emotions, topics of interest and controversial discussions, over a range of time periods and locations, using public tweets. We also present three example use cases that illustrates the usefulness of our proposed TweetCOVID system.
ShuffleUNet: Super resolution of diffusion-weighted MRIs using deep learning
Feb 25, 2021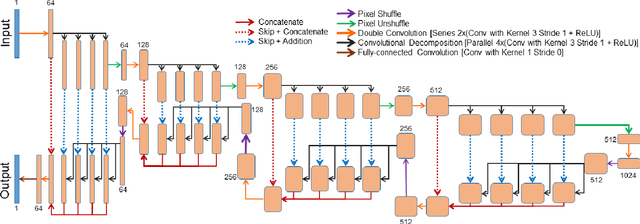
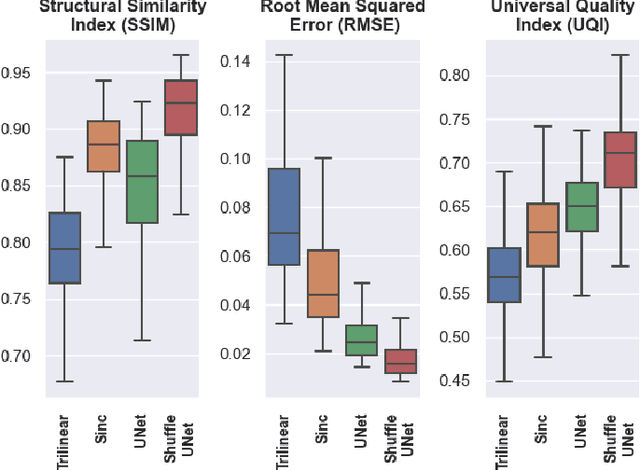
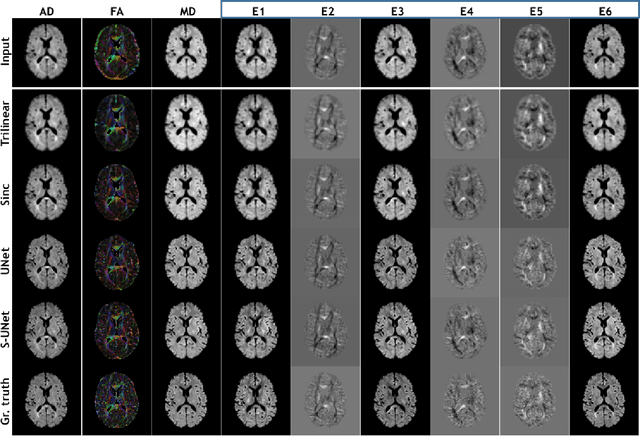
Diffusion-weighted magnetic resonance imaging (DW-MRI) can be used to characterise the microstructure of the nervous tissue, e.g. to delineate brain white matter connections in a non-invasive manner via fibre tracking. Magnetic Resonance Imaging (MRI) in high spatial resolution would play an important role in visualising such fibre tracts in a superior manner. However, obtaining an image of such resolution comes at the expense of longer scan time. Longer scan time can be associated with the increase of motion artefacts, due to the patient's psychological and physical conditions. Single Image Super-Resolution (SISR), a technique aimed to obtain high-resolution (HR) details from one single low-resolution (LR) input image, achieved with Deep Learning, is the focus of this study. Compared to interpolation techniques or sparse-coding algorithms, deep learning extracts prior knowledge from big datasets and produces superior MRI images from the low-resolution counterparts. In this research, a deep learning based super-resolution technique is proposed and has been applied for DW-MRI. Images from the IXI dataset have been used as the ground-truth and were artificially downsampled to simulate the low-resolution images. The proposed method has shown statistically significant improvement over the baselines and achieved an SSIM of $0.913\pm0.045$.
Active and sparse methods in smoothed model checking
Apr 20, 2021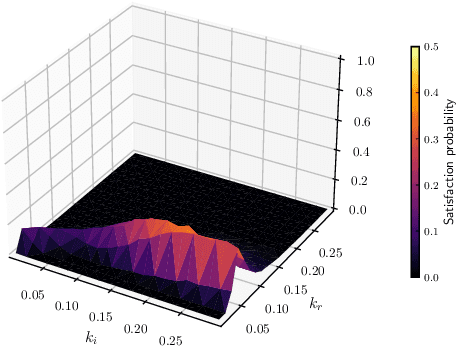
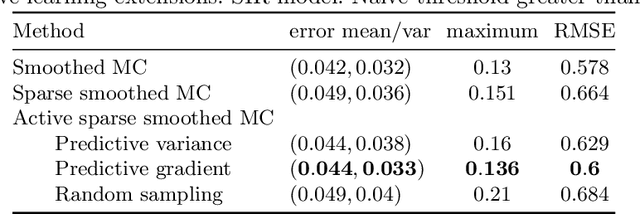
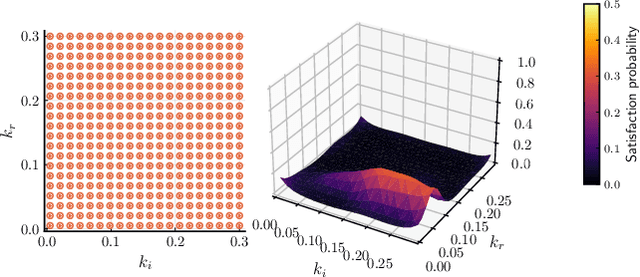
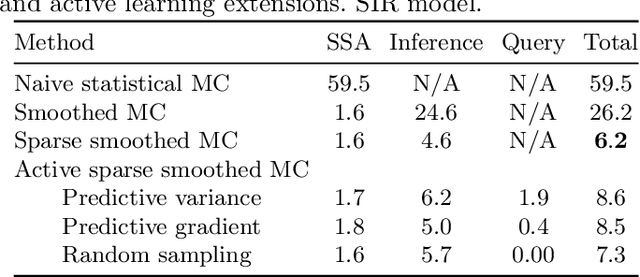
Smoothed model checking based on Gaussian process classification provides a powerful approach for statistical model checking of parametric continuous time Markov chain models. The method constructs a model for the functional dependence of satisfaction probability on the Markov chain parameters. This is done via Gaussian process inference methods from a limited number of observations for different parameter combinations. In this work we consider extensions to smoothed model checking based on sparse variational methods and active learning. Both are used successfully to improve the scalability of smoothed model checking. In particular, we see that active learning-based ideas for iteratively querying the simulation model for observations can be used to steer the model-checking to more informative areas of the parameter space and thus improve sample efficiency. Online extensions of sparse variational Gaussian process inference algorithms are demonstrated to provide a scalable method for implementing active learning approaches for smoothed model checking.
Learning What To Do by Simulating the Past
May 03, 2021
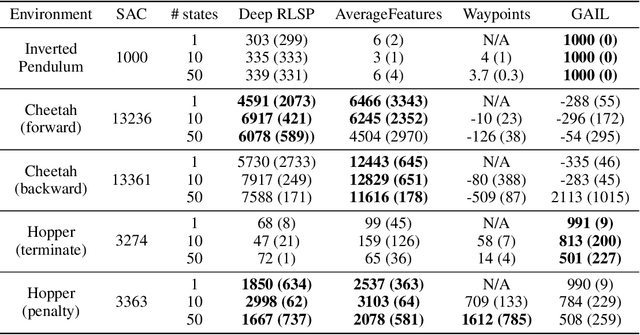

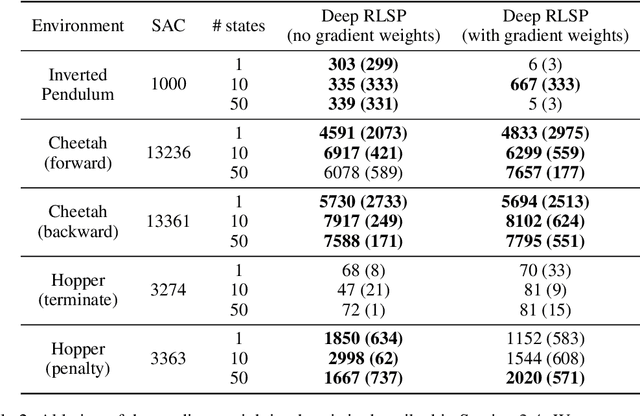
Since reward functions are hard to specify, recent work has focused on learning policies from human feedback. However, such approaches are impeded by the expense of acquiring such feedback. Recent work proposed that agents have access to a source of information that is effectively free: in any environment that humans have acted in, the state will already be optimized for human preferences, and thus an agent can extract information about what humans want from the state. Such learning is possible in principle, but requires simulating all possible past trajectories that could have led to the observed state. This is feasible in gridworlds, but how do we scale it to complex tasks? In this work, we show that by combining a learned feature encoder with learned inverse models, we can enable agents to simulate human actions backwards in time to infer what they must have done. The resulting algorithm is able to reproduce a specific skill in MuJoCo environments given a single state sampled from the optimal policy for that skill.