 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Editorial Workflow and Metadata Quality at Springer Nature
Mar 24, 2021
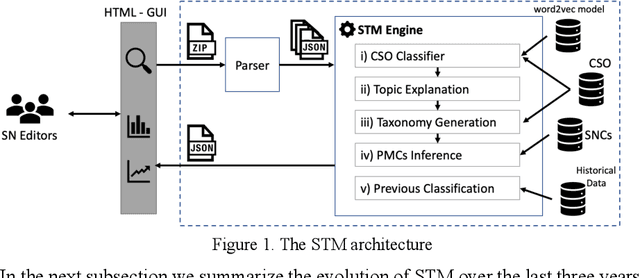

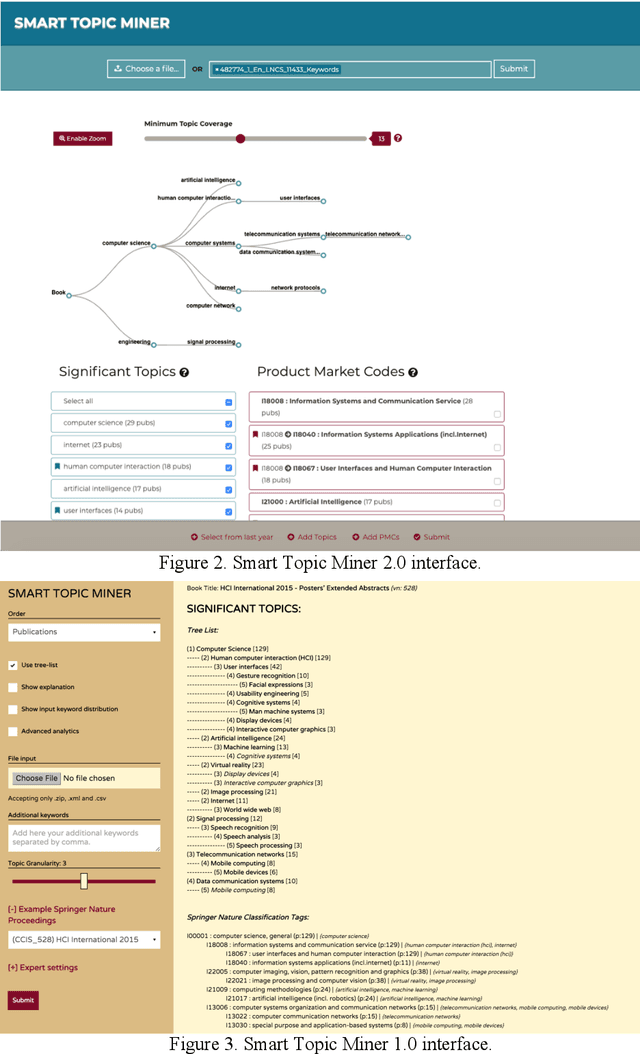
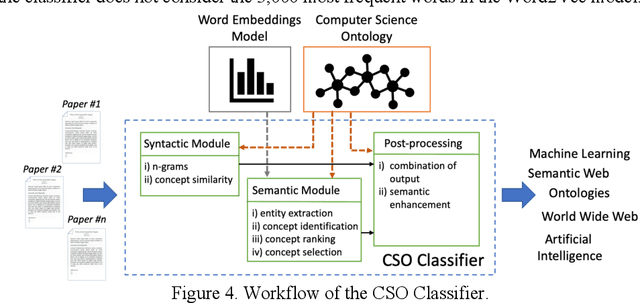
Identifying the research topics that best describe the scope of a scientific publication is a crucial task for editors, in particular because the quality of these annotations determine how effectively users are able to discover the right content in online libraries. For this reason, Springer Nature, the world's largest academic book publisher, has traditionally entrusted this task to their most expert editors. These editors manually analyse all new books, possibly including hundreds of chapters, and produce a list of the most relevant topics. Hence, this process has traditionally been very expensive, time-consuming, and confined to a few senior editors. For these reasons, back in 2016 we developed Smart Topic Miner (STM), an ontology-driven application that assists the Springer Nature editorial team in annotating the volumes of all books covering conference proceedings in Computer Science. Since then STM has been regularly used by editors in Germany, China, Brazil, India, and Japan, for a total of about 800 volumes per year. Over the past three years the initial prototype has iteratively evolved in response to feedback from the users and evolving requirements. In this paper we present the most recent version of the tool and describe the evolution of the system over the years, the key lessons learnt, and the impact on the Springer Nature workflow. In particular, our solution has drastically reduced the time needed to annotate proceedings and significantly improved their discoverability, resulting in 9.3 million additional downloads. We also present a user study involving 9 editors, which yielded excellent results in term of usability, and report an evaluation of the new topic classifier used by STM, which outperforms previous versions in recall and F-measure.
A Comparison of CNN-based Face and Head Detectors for Real-Time Video Surveillance Applications
Sep 10, 2018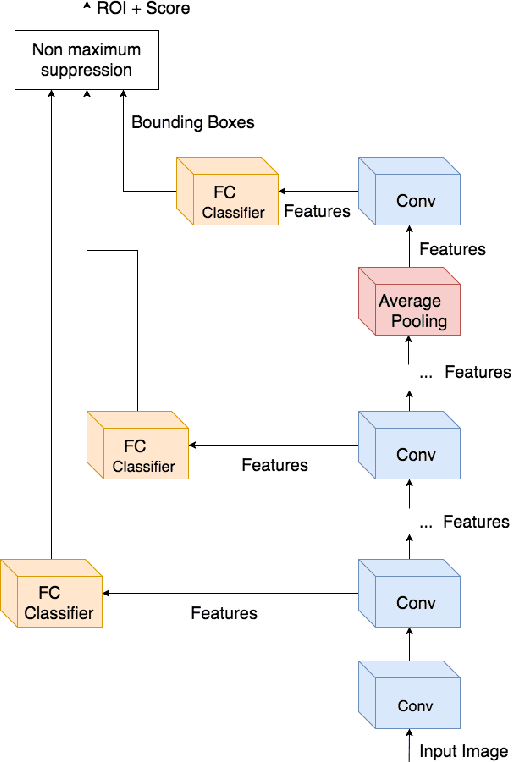
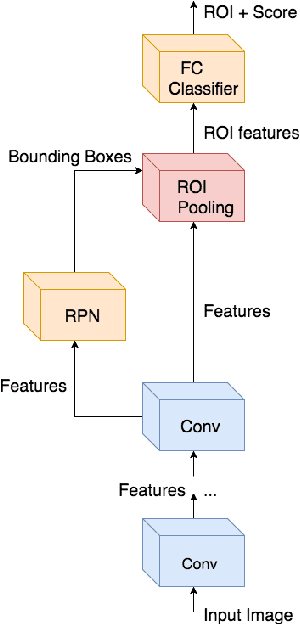
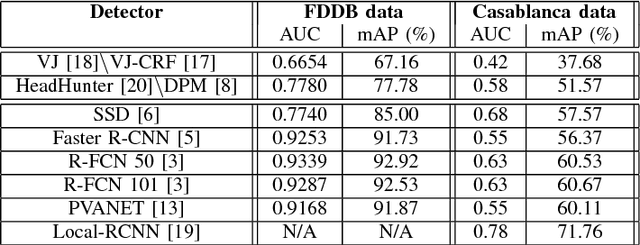
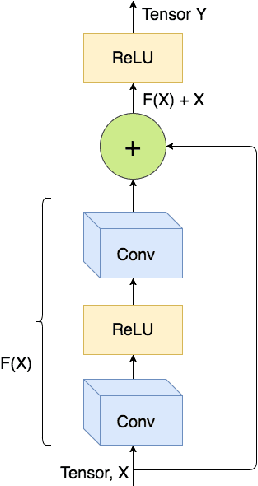
Detecting faces and heads appearing in video feeds are challenging tasks in real-world video surveillance applications due to variations in appearance, occlusions and complex backgrounds. Recently, several CNN architectures have been proposed to increase the accuracy of detectors, although their computational complexity can be an issue, especially for real-time applications, where faces and heads must be detected live using high-resolution cameras. This paper compares the accuracy and complexity of state-of-the-art CNN architectures that are suitable for face and head detection. Single pass and region-based architectures are reviewed and compared empirically to baseline techniques according to accuracy and to time and memory complexity on images from several challenging datasets. The viability of these architectures is analyzed with real-time video surveillance applications in mind. Results suggest that, although CNN architectures can achieve a very high level of accuracy compared to traditional detectors, their computational cost can represent a limitation for many practical real-time applications.
Cross-SEAN: A Cross-Stitch Semi-Supervised Neural Attention Model for COVID-19 Fake News Detection
Feb 18, 2021
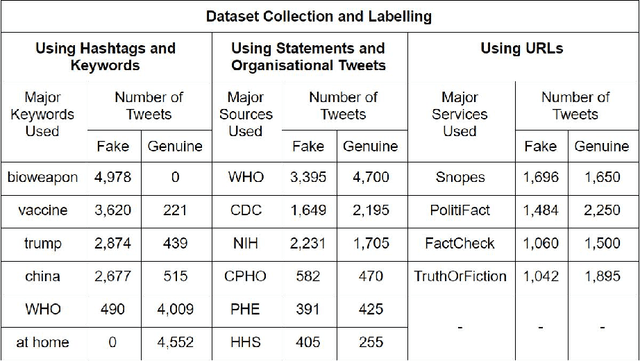
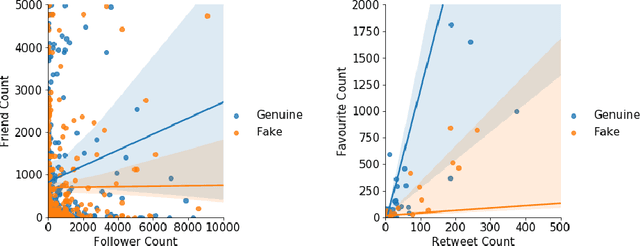

As the COVID-19 pandemic sweeps across the world, it has been accompanied by a tsunami of fake news and misinformation on social media. At the time when reliable information is vital for public health and safety, COVID-19 related fake news has been spreading even faster than the facts. During times such as the COVID-19 pandemic, fake news can not only cause intellectual confusion but can also place lives of people at risk. This calls for an immediate need to contain the spread of such misinformation on social media. We introduce CTF, the first COVID-19 Twitter fake news dataset with labeled genuine and fake tweets. Additionally, we propose Cross-SEAN, a cross-stitch based semi-supervised end-to-end neural attention model, which leverages the large amount of unlabelled data. Cross-SEAN partially generalises to emerging fake news as it learns from relevant external knowledge. We compare Cross-SEAN with seven state-of-the-art fake news detection methods. We observe that it achieves $0.95$ F1 Score on CTF, outperforming the best baseline by $9\%$. We also develop Chrome-SEAN, a Cross-SEAN based chrome extension for real-time detection of fake tweets.
Safe Model-based Off-policy Reinforcement Learning for Eco-Driving in Connected and Automated Hybrid Electric Vehicles
May 25, 2021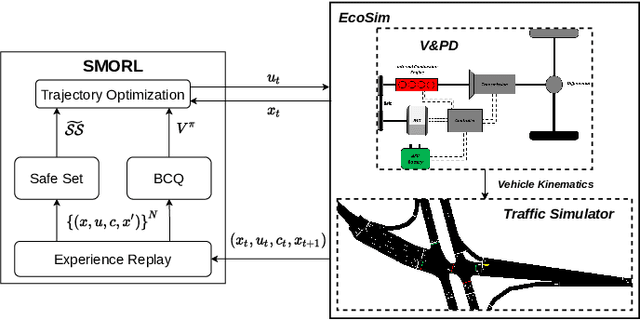
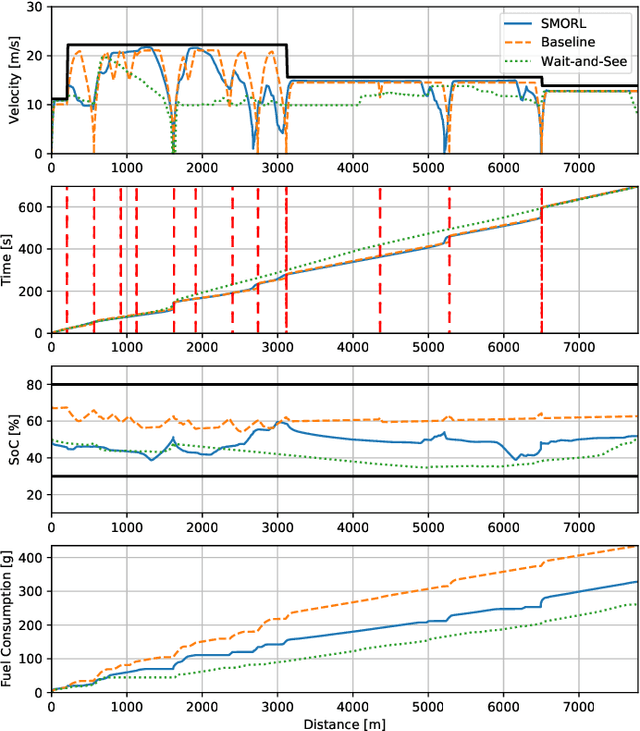
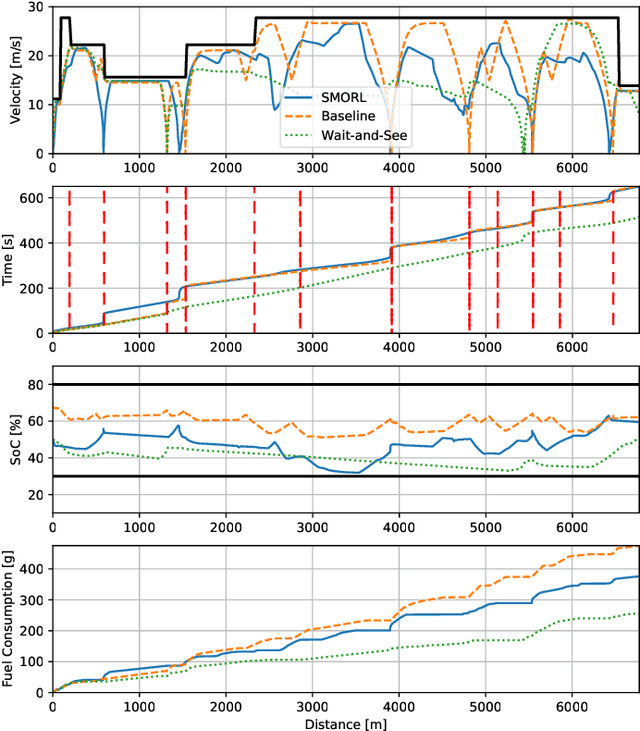
Connected and Automated Hybrid Electric Vehicles have the potential to reduce fuel consumption and travel time in real-world driving conditions. The eco-driving problem seeks to design optimal speed and power usage profiles based upon look-ahead information from connectivity and advanced mapping features. Recently, Deep Reinforcement Learning (DRL) has been applied to the eco-driving problem. While the previous studies synthesize simulators and model-free DRL to reduce online computation, this work proposes a Safe Off-policy Model-Based Reinforcement Learning algorithm for the eco-driving problem. The advantages over the existing literature are three-fold. First, the combination of off-policy learning and the use of a physics-based model improves the sample efficiency. Second, the training does not require any extrinsic rewarding mechanism for constraint satisfaction. Third, the feasibility of trajectory is guaranteed by using a safe set approximated by deep generative models. The performance of the proposed method is benchmarked against a baseline controller representing human drivers, a previously designed model-free DRL strategy, and the wait-and-see optimal solution. In simulation, the proposed algorithm leads to a policy with a higher average speed and a better fuel economy compared to the model-free agent. Compared to the baseline controller, the learned strategy reduces the fuel consumption by more than 21\% while keeping the average speed comparable.
Forecasting Significant Wave Heights in Oceanic Waters
May 18, 2021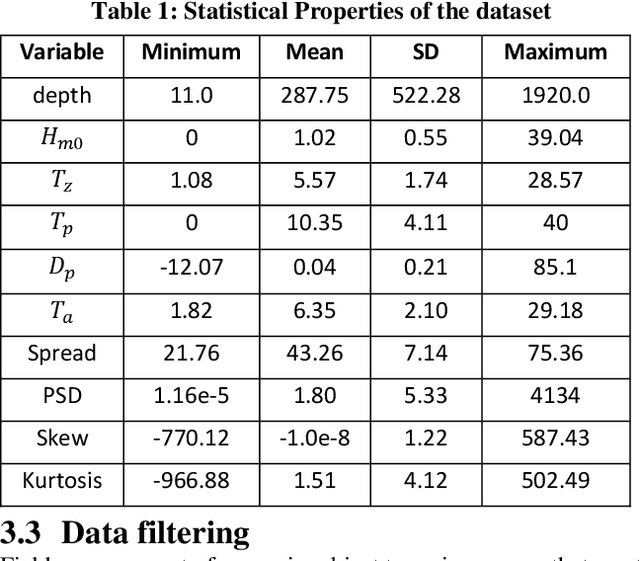
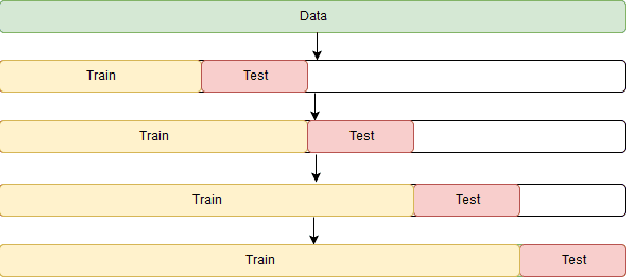

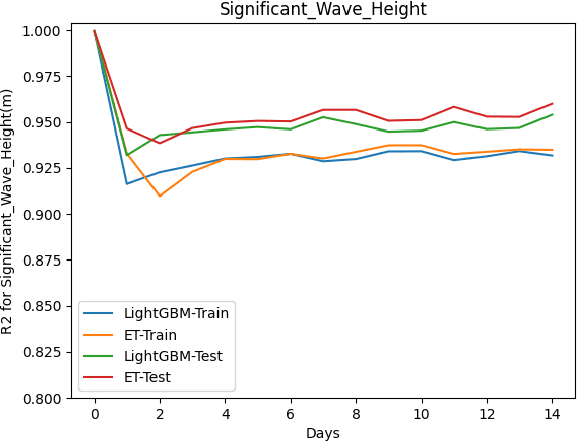
This paper proposes a machine learning method based on the Extra Trees (ET) algorithm for forecasting Significant Wave Heights in oceanic waters. To derive multiple features from the CDIP buoys, which make point measurements, we first nowcast various parameters and then forecast them at 30-min intervals. The proposed algorithm has Scatter Index (SI), Bias, Correlation Coefficient, Root Mean Squared Error (RMSE) of 0.130, -0.002, 0.97, and 0.14, respectively, for one day ahead prediction and 0.110, -0.001, 0.98, and 0.122, respectively, for 14-day ahead prediction on the testing dataset. While other state-of-the-art methods can only forecast up to 120 hours ahead, we extend it further to 14 days. This 14-day limit is not the forecasting limit, but it arises due to our experiment's setup. Our proposed setup includes spectral features, hv-block cross-validation, and stringent QC criteria. The proposed algorithm performs significantly better than the state-of-the-art methods commonly used for significant wave height forecasting for one-day ahead prediction. Moreover, the improved performance of the proposed machine learning method compared to the numerical methods, shows that this performance can be extended to even longer time periods allowing for early prediction of significant wave heights in oceanic waters.
Knowledge Transfer across Imaging Modalities Via Simultaneous Learning of Adaptive Autoencoders for High-Fidelity Mobile Robot Vision
May 11, 2021
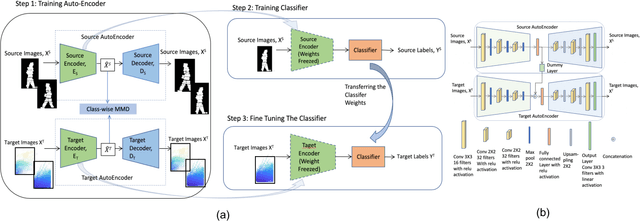

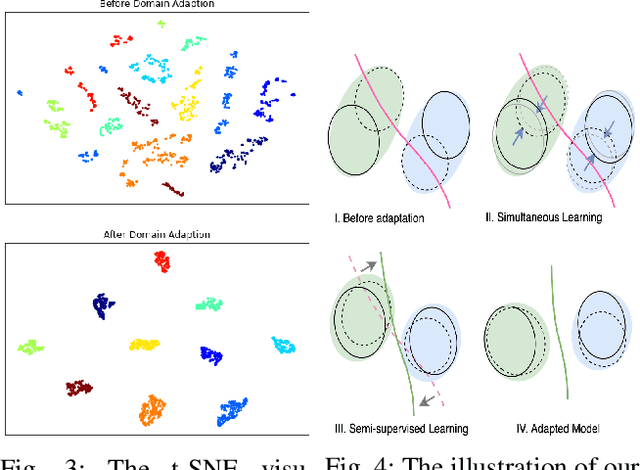
Enabling mobile robots for solving challenging and diverse shape, texture, and motion related tasks with high fidelity vision requires the integration of novel multimodal imaging sensors and advanced fusion techniques. However, it is associated with high cost, power, hardware modification, and computing requirements which limit its scalability. In this paper, we propose a novel Simultaneously Learned Auto Encoder Domain Adaptation (SAEDA)-based transfer learning technique to empower noisy sensing with advanced sensor suite capabilities. In this regard, SAEDA trains both source and target auto-encoders together on a single graph to obtain the domain invariant feature space between the source and target domains on simultaneously collected data. Then, it uses the domain invariant feature space to transfer knowledge between different signal modalities. The evaluation has been done on two collected datasets (LiDAR and Radar) and one existing dataset (LiDAR, Radar and Video) which provides a significant improvement in quadruped robot-based classification (home floor and human activity recognition) and regression (surface roughness estimation) problems. We also integrate our sensor suite and SAEDA framework on two real-time systems (vacuum cleaning and Mini-Cheetah quadruped robots) for studying the feasibility and usability.
Same State, Different Task: Continual Reinforcement Learning without Interference
Jun 05, 2021



Continual Learning (CL) considers the problem of training an agent sequentially on a set of tasks while seeking to retain performance on all previous tasks. A key challenge in CL is catastrophic forgetting, which arises when performance on a previously mastered task is reduced when learning a new task. While a variety of methods exist to combat forgetting, in some cases tasks are fundamentally incompatible with each other and thus cannot be learnt by a single policy. This can occur, in reinforcement learning (RL) when an agent may be rewarded for achieving different goals from the same observation. In this paper we formalize this ``interference'' as distinct from the problem of forgetting. We show that existing CL methods based on single neural network predictors with shared replay buffers fail in the presence of interference. Instead, we propose a simple method, OWL, to address this challenge. OWL learns a factorized policy, using shared feature extraction layers, but separate heads, each specializing on a new task. The separate heads in OWL are used to prevent interference. At test time, we formulate policy selection as a multi-armed bandit problem, and show it is possible to select the best policy for an unknown task using feedback from the environment. The use of bandit algorithms allows the OWL agent to constructively re-use different continually learnt policies at different times during an episode. We show in multiple RL environments that existing replay based CL methods fail, while OWL is able to achieve close to optimal performance when training sequentially.
Semi-Passive 3D Positioning of Multiple RIS-Enabled Users
Apr 25, 2021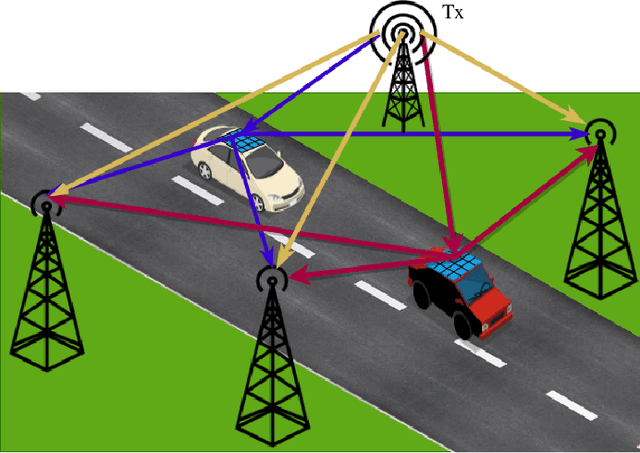
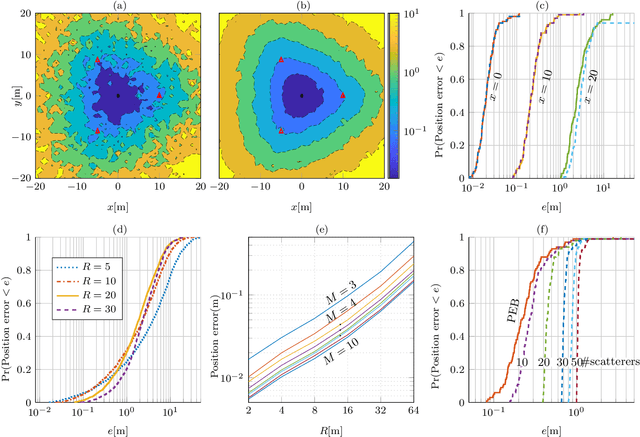
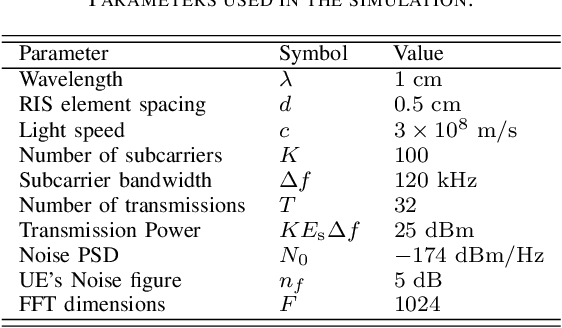
Reconfigurable intelligent surfaces (RISs) are set to be a revolutionary technology in the 6th generation of wireless systems. In this work, we study the application of RIS in a multi-user passive localization scenario, where we have one transmitter (Tx) and multiple asynchronous receivers (Rxs) with known locations. We aim to estimate the locations of multiple users equipped with RISs. The RISs only reflect the signal from the Tx to the Rxs and are not used as active transceivers themselves. Each Rx receives the signal from the Tx (LOS path) and the reflected signal from the RISs (NLOS path). We show that users' 3D position can be estimated with submeter accuracy in a large area around the transmitter, using the LOS and NLOS time-of-arrival measurements at the Rxs. We do so, by developing the signal model, deriving the Cramer-Rao bounds, and devising an estimator that attains these bounds. Furthermore, by orthogonalizing the RIS phase profiles across different users, we circumvent inter-path interference.
Teachers' perspective on fostering computational thinking through educational robotics
May 11, 2021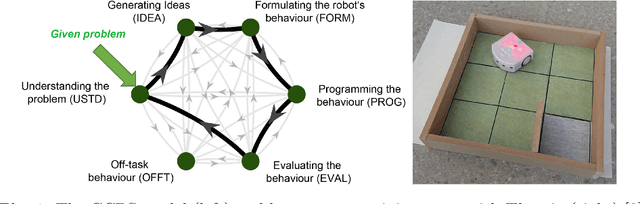
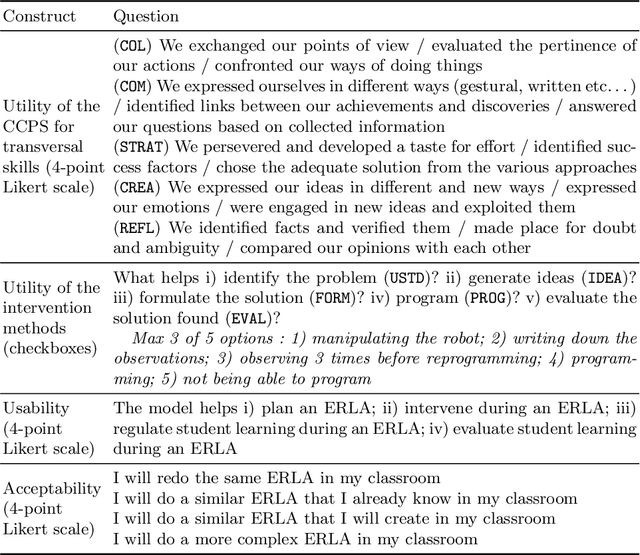
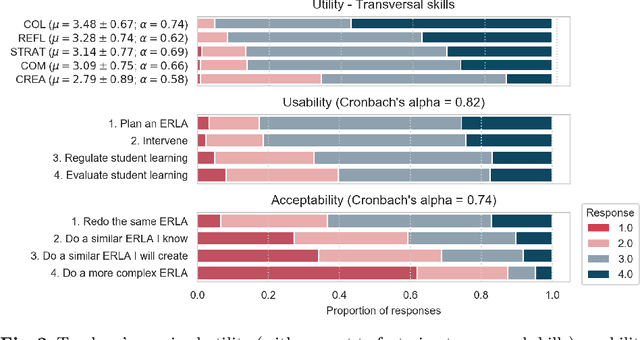
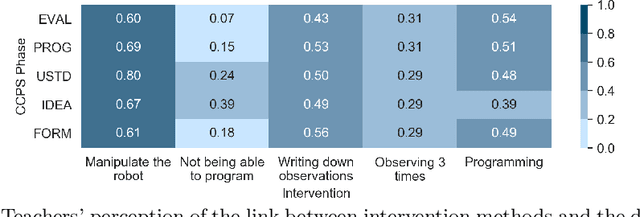
With the introduction of educational robotics (ER) and computational thinking (CT) in classrooms, there is a rising need for operational models that help ensure that CT skills are adequately developed. One such model is the Creative Computational Problem Solving Model (CCPS) which can be employed to improve the design of ER learning activities. Following the first validation with students, the objective of the present study is to validate the model with teachers, specifically considering how they may employ the model in their own practices. The Utility, Usability and Acceptability framework was leveraged for the evaluation through a survey analysis with 334 teachers. Teachers found the CCPS model useful to foster transversal skills but could not recognise the impact of specific intervention methods on CT-related cognitive processes. Similarly, teachers perceived the model to be usable for activity design and intervention, although felt unsure about how to use it to assess student learning and adapt their teaching accordingly. Finally, the teachers accepted the model, as shown by their intent to replicate the activity in their classrooms, but were less willing to modify it or create their own activities, suggesting that they need time to appropriate the model and underlying tenets.
A Secure Learning Control Strategy via Dynamic Camouflaging for Unknown Dynamical Systems under Attacks
Feb 01, 2021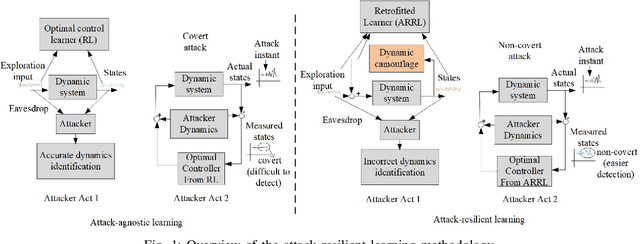
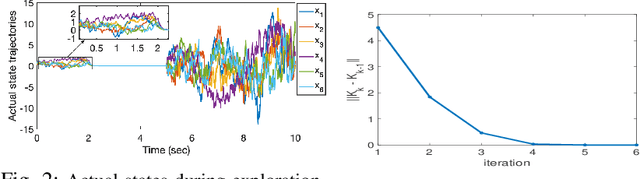
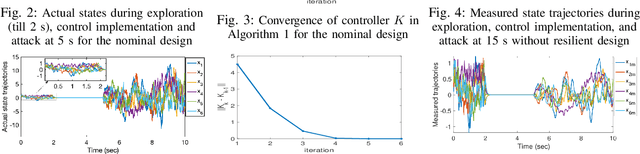
This paper presents a secure reinforcement learning (RL) based control method for unknown linear time-invariant cyber-physical systems (CPSs) that are subjected to compositional attacks such as eavesdropping and covert attack. We consider the attack scenario where the attacker learns about the dynamic model during the exploration phase of the learning conducted by the designer to learn a linear quadratic regulator (LQR), and thereafter, use such information to conduct a covert attack on the dynamic system, which we refer to as doubly learning-based control and attack (DLCA) framework. We propose a dynamic camouflaging based attack-resilient reinforcement learning (ARRL) algorithm which can learn the desired optimal controller for the dynamic system, and at the same time, can inject sufficient misinformation in the estimation of system dynamics by the attacker. The algorithm is accompanied by theoretical guarantees and extensive numerical experiments on a consensus multi-agent system and on a benchmark power grid model.