 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Slow Momentum with Fast Reversion: A Trading Strategy Using Deep Learning and Changepoint Detection
Jun 18, 2021
Momentum strategies are an important part of alternative investments and are at the heart of commodity trading advisors (CTAs). These strategies have however been found to have difficulties adjusting to rapid changes in market conditions, such as during the 2020 market crash. In particular, immediately after momentum turning points, where a trend reverses from an uptrend (downtrend) to a downtrend (uptrend), time-series momentum (TSMOM) strategies are prone to making bad bets. To improve the response to regime change, we introduce a novel approach, where we insert an online change-point detection (CPD) module into a Deep Momentum Network (DMN) [1904.04912] pipeline, which uses an LSTM deep-learning architecture to simultaneously learn both trend estimation and position sizing. Furthermore, our model is able to optimise the way in which it balances 1) a slow momentum strategy which exploits persisting trends, but does not overreact to localised price moves, and 2) a fast mean-reversion strategy regime by quickly flipping its position, then swapping it back again to exploit localised price moves. Our CPD module outputs a changepoint location and severity score, allowing our model to learn to respond to varying degrees of disequilibrium, or smaller and more localised changepoints, in a data driven manner. Using a portfolio of 50, liquid, continuous futures contracts over the period 1990-2020, the addition of the CPD module leads to an improvement in Sharpe ratio of one-third. Even more notably, this module is especially beneficial in periods of significant nonstationarity, and in particular, over the most recent years tested (2015-2020) the performance boost is approximately two-thirds. This is especially interesting as traditional momentum strategies have been underperforming in this period.
User Grouping and Reflective Beamforming for IRS-Aided URLLC
May 26, 2021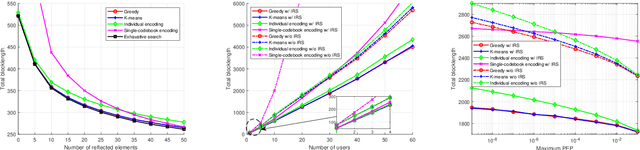
This paper studies an intelligent reflecting surface (IRS)-aided downlink ultra-reliable and low-latency communication (URLLC) system, in which an IRS is dedicatedly deployed to assist a base station (BS) to send individual short-packet messages to multiple users. To enhance the URLLC performance, the users are divided into different groups and the messages for users in each group are encoded into a single codeword. By considering the time division multiple access (TDMA) protocol among different groups, our objective is to minimize the total latency for all users subject to their individual reliability requirements, via jointly optimizing the user grouping and block-length allocation at the BS together with the reflective beamforming at the IRS. We solve the latency minimization problem via the alternating optimization, in which the blocklengths and the reflective beamforming are optimized by using the techniques of successive convex approximation (SCA) and semi-definite relaxation (SDR), while the user grouping is updated by K-means and greedy-based methods. Numerical results show that the proposed designs can significantly reduce the communication latency, as compared to various benchmark schemes, which unveil the importance of user grouping and reflective beamforming optimization for exploiting the joint encoding gain and enhancing the worst-case user performance.
Instance-aware Remote Sensing Image Captioning with Cross-hierarchy Attention
May 11, 2021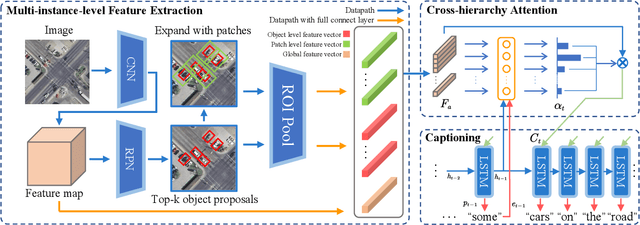


The spatial attention is a straightforward approach to enhance the performance for remote sensing image captioning. However, conventional spatial attention approaches consider only the attention distribution on one fixed coarse grid, resulting in the semantics of tiny objects can be easily ignored or disturbed during the visual feature extraction. Worse still, the fixed semantic level of conventional spatial attention limits the image understanding in different levels and perspectives, which is critical for tackling the huge diversity in remote sensing images. To address these issues, we propose a remote sensing image caption generator with instance-awareness and cross-hierarchy attention. 1) The instances awareness is achieved by introducing a multi-level feature architecture that contains the visual information of multi-level instance-possible regions and their surroundings. 2) Moreover, based on this multi-level feature extraction, a cross-hierarchy attention mechanism is proposed to prompt the decoder to dynamically focus on different semantic hierarchies and instances at each time step. The experimental results on public datasets demonstrate the superiority of proposed approach over existing methods.
Conditional Generative Models for Counterfactual Explanations
Jan 25, 2021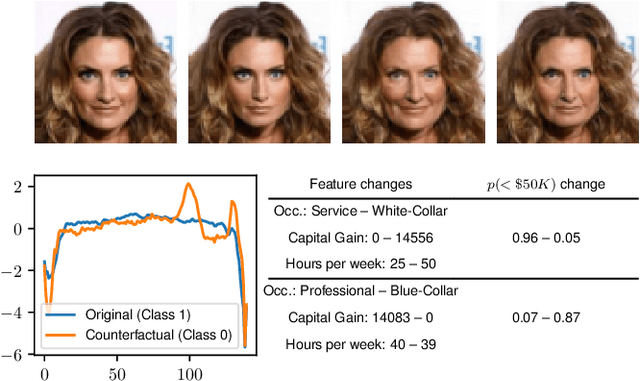



Counterfactual instances offer human-interpretable insight into the local behaviour of machine learning models. We propose a general framework to generate sparse, in-distribution counterfactual model explanations which match a desired target prediction with a conditional generative model, allowing batches of counterfactual instances to be generated with a single forward pass. The method is flexible with respect to the type of generative model used as well as the task of the underlying predictive model. This allows straightforward application of the framework to different modalities such as images, time series or tabular data as well as generative model paradigms such as GANs or autoencoders and predictive tasks like classification or regression. We illustrate the effectiveness of our method on image (CelebA), time series (ECG) and mixed-type tabular (Adult Census) data.
Highly Fast Text Segmentation With Pairwise Markov Chains
Feb 17, 2021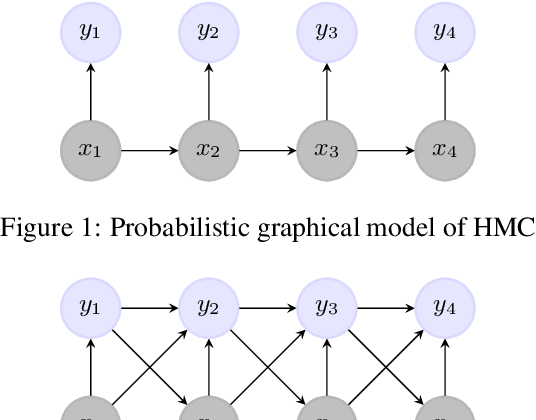
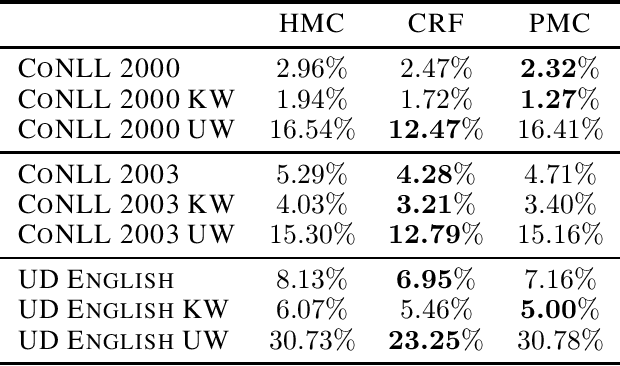
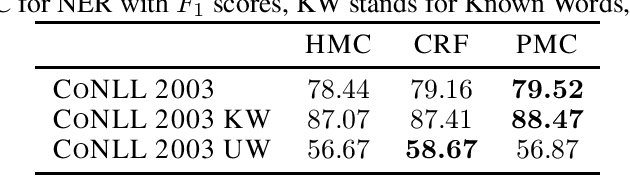
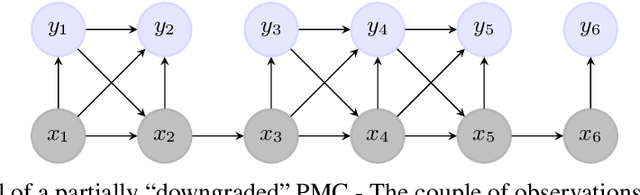
Natural Language Processing (NLP) models' current trend consists of using increasingly more extra-data to build the best models as possible. It implies more expensive computational costs and training time, difficulties for deployment, and worries about these models' carbon footprint reveal a critical problem in the future. Against this trend, our goal is to develop NLP models requiring no extra-data and minimizing training time. To do so, in this paper, we explore Markov chain models, Hidden Markov Chain (HMC) and Pairwise Markov Chain (PMC), for NLP segmentation tasks. We apply these models for three classic applications: POS Tagging, Named-Entity-Recognition, and Chunking. We develop an original method to adapt these models for text segmentation's specific challenges to obtain relevant performances with very short training and execution times. PMC achieves equivalent results to those obtained by Conditional Random Fields (CRF), one of the most applied models for these tasks when no extra-data are used. Moreover, PMC has training times 30 times shorter than the CRF ones, which validates this model given our objectives.
Raman spectral analysis of mixtures with one-dimensional convolutional neural network
Jun 01, 2021

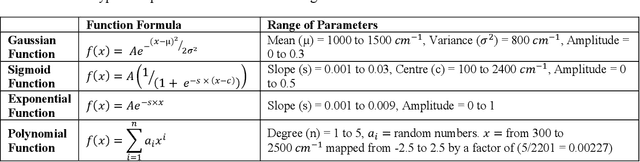
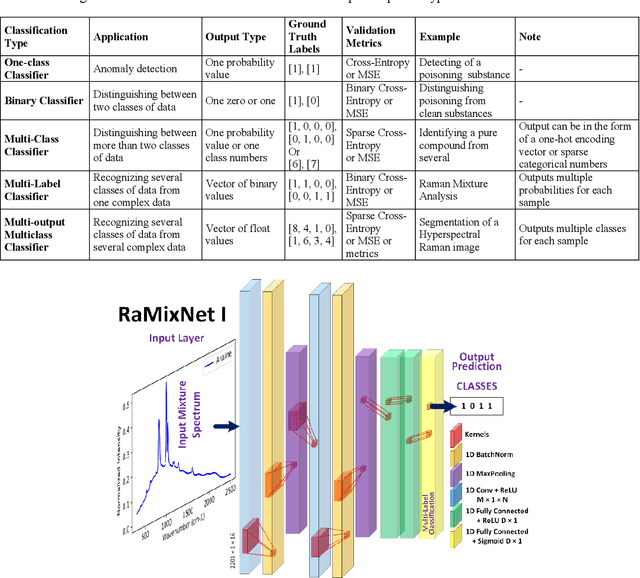
Recently, the combination of robust one-dimensional convolutional neural networks (1-D CNNs) and Raman spectroscopy has shown great promise in rapid identification of unknown substances with good accuracy. Using this technique, researchers can recognize a pure compound and distinguish it from unknown substances in a mixture. The novelty of this approach is that the trained neural network operates automatically without any pre- or post-processing of data. Some studies have attempted to extend this technique to the classification of pure compounds in an unknown mixture. However, the application of 1-D CNNs has typically been restricted to binary classifications of pure compounds. Here we will highlight a new approach in spectral recognition and quantification of chemical components in a multicomponent mixture. Two 1-D CNN models, RaMixNet I and II, have been developed for this purpose. The former is for rapid classification of components in a mixture while the latter is for quantitative determination of those constituents. In the proposed method, there is no limit to the number of compounds in a mixture. A data augmentation method is also introduced by adding random baselines to the Raman spectra. The experimental results revealed that the classification accuracy of RaMixNet I and II is 100% for analysis of unknown test mixtures; at the same time, the RaMixNet II model may achieve a regression accuracy of 88% for the quantification of each component.
InfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021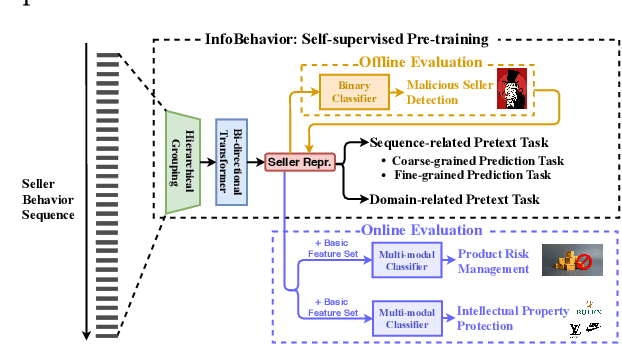
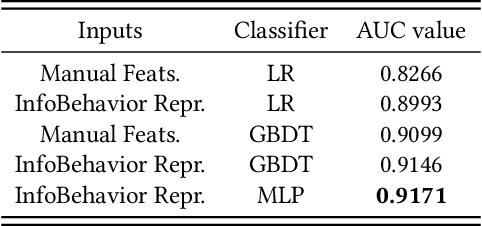
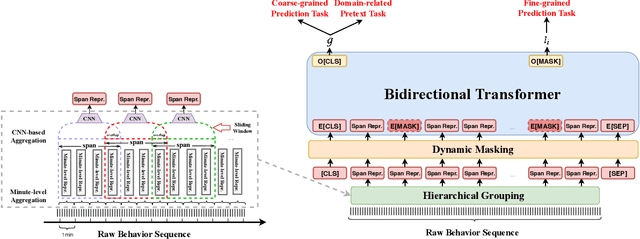
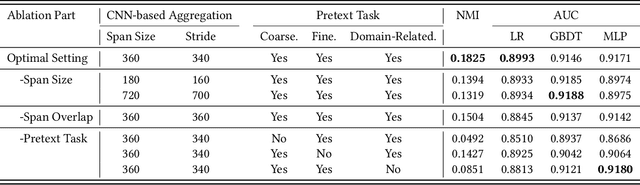
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.
Multi-frame sequence generator of 4D human body motion
Jun 07, 2021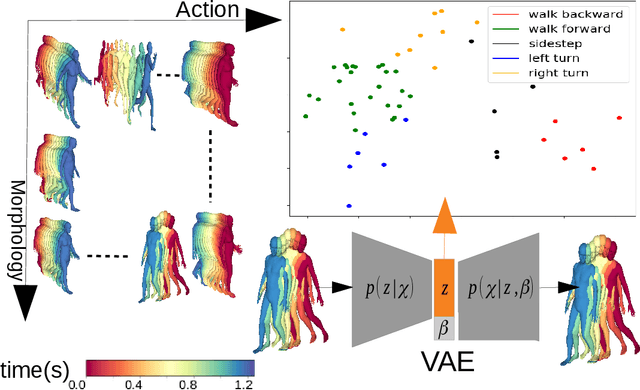
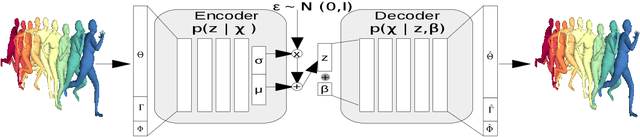
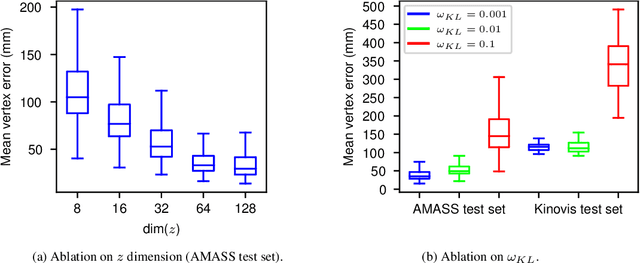
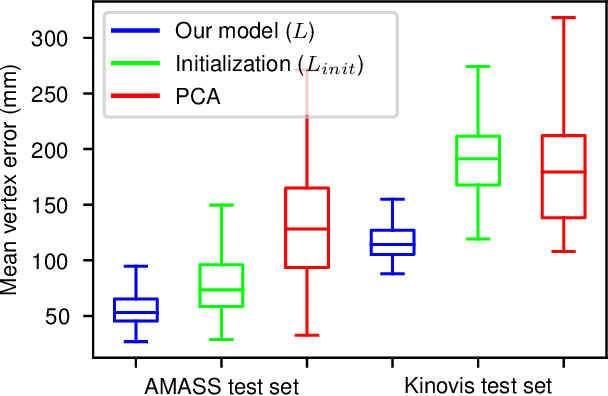
We examine the problem of generating temporally and spatially dense 4D human body motion. On the one hand generative modeling has been extensively studied as a per time-frame static fitting problem for dense 3D models such as mesh representations, where the temporal aspect is left out of the generative model. On the other hand, temporal generative models exist for sparse human models such as marker-based capture representations, but have not to our knowledge been extended to dense 3D shapes. We propose to bridge this gap with a generative auto-encoder-based framework, which encodes morphology, global locomotion including translation and rotation, and multi-frame temporal motion as a single latent space vector. To assess its generalization and factorization abilities, we train our model on a cyclic locomotion subset of AMASS, leveraging the dense surface models it provides for an extensive set of motion captures. Our results validate the ability of the model to reconstruct 4D sequences of human locomotions within a low error bound, and the meaningfulness of latent space interpolation between latent vectors representing different multi-frame sequences and locomotion types. We also illustrate the benefits of the approach for 4D human motion prediction of future frames from initial human locomotion frames, showing promising abilities of our model to learn realistic spatio-temporal features of human motion. We show that our model allows for data completion of both spatially and temporally sparse data.
FVNet: 3D Front-View Proposal Generation for Real-Time Object Detection from Point Clouds
Mar 26, 2019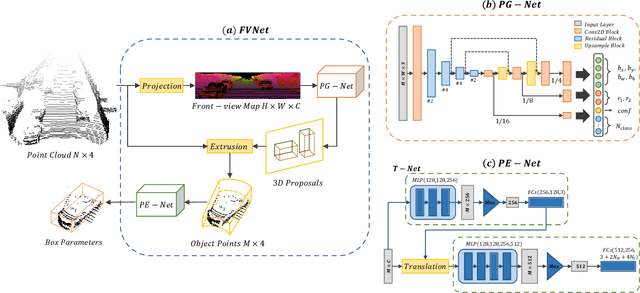
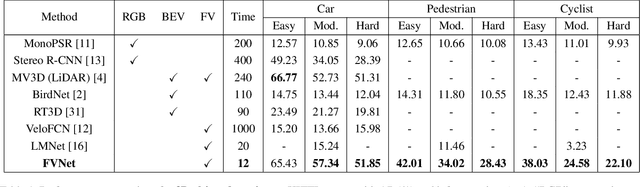
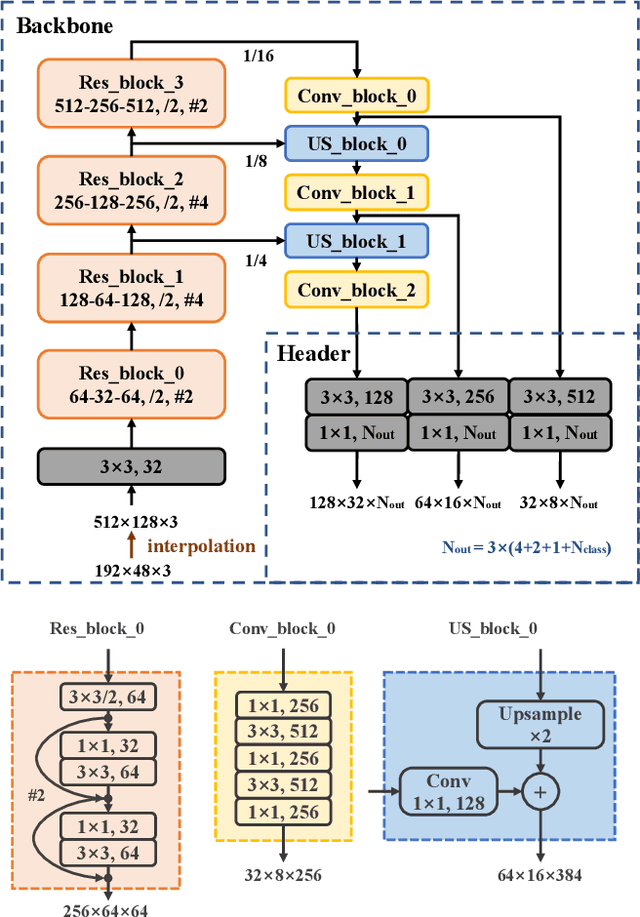
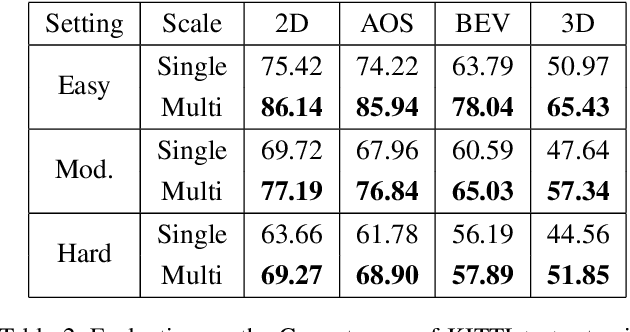
3D object detection from raw and sparse point clouds has been far less treated to date, compared with its 2D counterpart. In this paper, we propose a novel framework called FVNet for 3D front-view proposal generation and object detection from point clouds. It consists of two stages: generation of front-view proposals and estimation of 3D bounding box parameters. Instead of generating proposals from camera images or bird's-eye-view maps, we first project point clouds onto a cylindrical surface to generate front-view feature maps which retains rich information. We then introduce a proposal generation network to predict 3D region proposals from the generated maps and further extrude objects of interest from the whole point cloud. Finally, we present another network to extract the point-wise features from the extruded object points and regress the final 3D bounding box parameters in the canonical coordinates. Our framework achieves real-time performance with 12ms per point cloud sample. Extensive experiments on the 3D detection benchmark KITTI show that the proposed architecture outperforms state-of-the-art techniques which take either camera images or point clouds as input, in terms of accuracy and inference time.
FiSH: Fair Spatial Hotspots
Jun 01, 2021

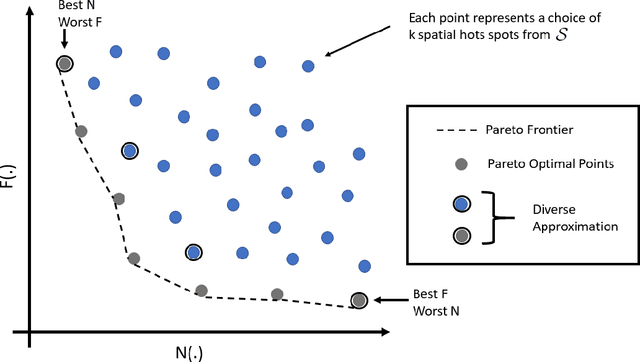
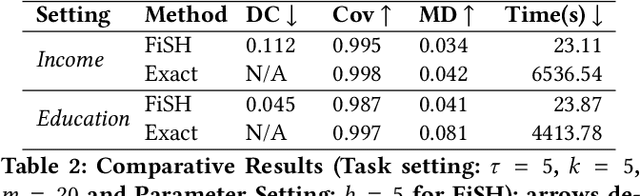
Pervasiveness of tracking devices and enhanced availability of spatially located data has deepened interest in using them for various policy interventions, through computational data analysis tasks such as spatial hot spot detection. In this paper, we consider, for the first time to our best knowledge, fairness in detecting spatial hot spots. We motivate the need for ensuring fairness through statistical parity over the collective population covered across chosen hot spots. We then characterize the task of identifying a diverse set of solutions in the noteworthiness-fairness trade-off spectrum, to empower the user to choose a trade-off justified by the policy domain. Being a novel task formulation, we also develop a suite of evaluation metrics for fair hot spots, motivated by the need to evaluate pertinent aspects of the task. We illustrate the computational infeasibility of identifying fair hot spots using naive and/or direct approaches and devise a method, codenamed {\it FiSH}, for efficiently identifying high-quality, fair and diverse sets of spatial hot spots. FiSH traverses the tree-structured search space using heuristics that guide it towards identifying effective and fair sets of spatial hot spots. Through an extensive empirical analysis over a real-world dataset from the domain of human development, we illustrate that FiSH generates high-quality solutions at fast response times.