 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Oversampling Tecniques for 1-Bit ADCs in Large-Scale MIMO Systems
Feb 27, 2021
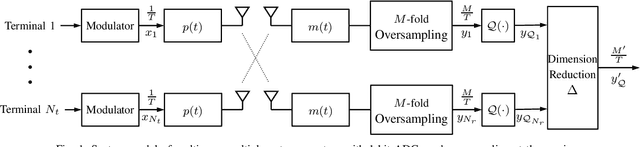
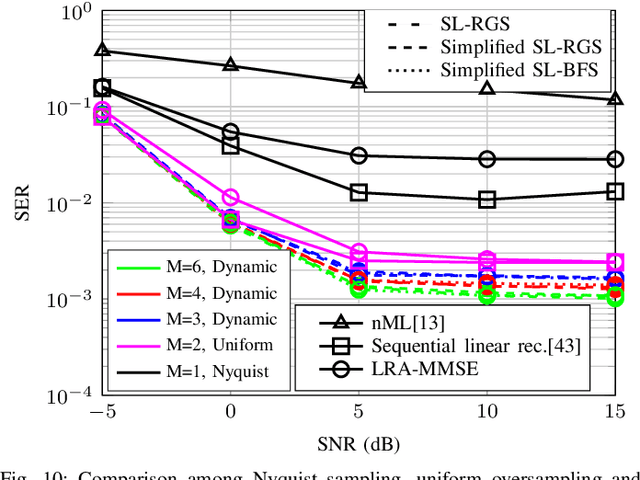
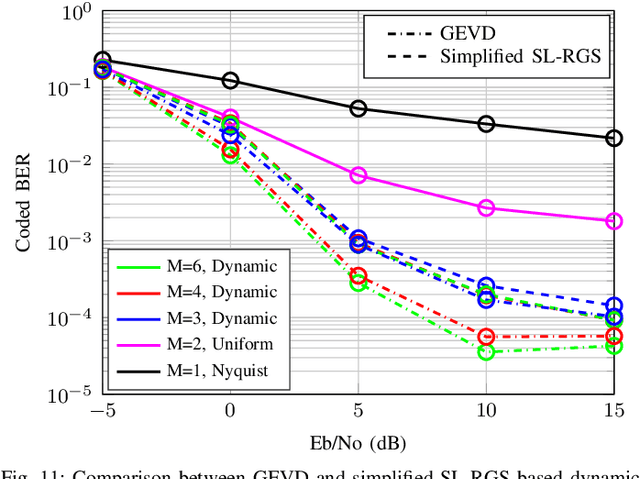
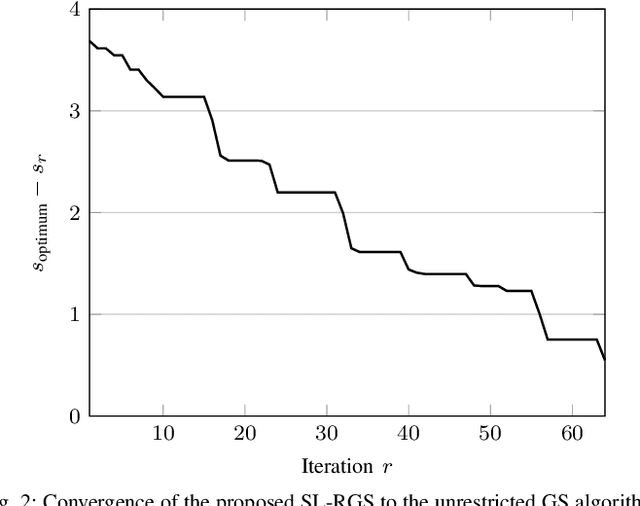
In this work, we investigate dynamic oversampling techniques for large-scale multiple-antenna systems equipped with low-cost and low-power 1-bit analog-to-digital converters at the base stations. To compensate for the performance loss caused by the coarse quantization, oversampling is applied at the receiver. Unlike existing works that use uniform oversampling, which samples the signal at a constant rate, a novel dynamic oversampling scheme is proposed. The basic idea is to perform time-varying nonuniform oversampling, which selects samples with nonuniform patterns that vary over time. We consider two system design criteria: a design that maximizes the achievable sum rate and another design that minimizes the mean square error of detected symbols. Dynamic oversampling is carried out using a dimension reduction matrix $\mathbf{\Delta}$, which can be computed by the generalized eigenvalue decomposition or by novel submatrix-level feature selection algorithms. Moreover, the proposed scheme is analyzed in terms of convergence, computational complexity and power consumption at the receiver. Simulations show that systems with the proposed dynamic oversampling outperform those with uniform oversampling in terms of computational cost, achievable sum rate and symbol error rate performance.
The Age of Correlated Features in Supervised Learning based Forecasting
Feb 27, 2021
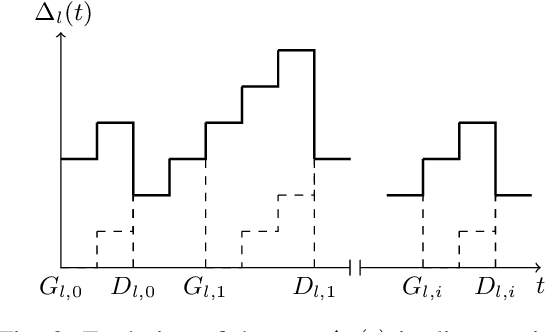
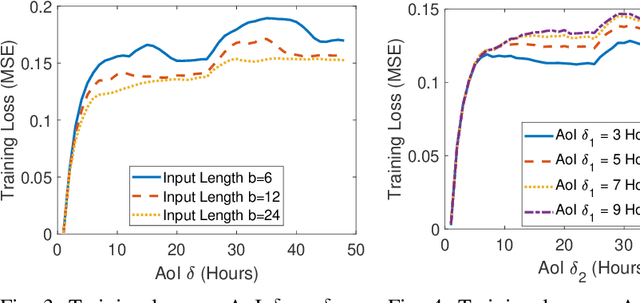
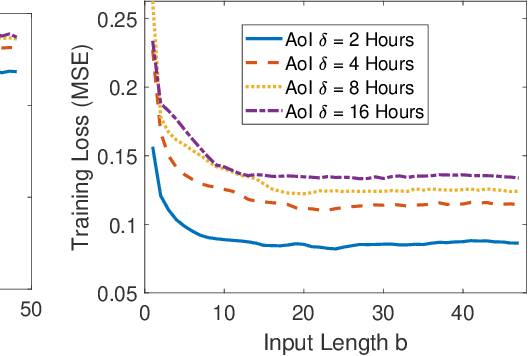
In this paper, we analyze the impact of information freshness on supervised learning based forecasting. In these applications, a neural network is trained to predict a time-varying target (e.g., solar power), based on multiple correlated features (e.g., temperature, humidity, and cloud coverage). The features are collected from different data sources and are subject to heterogeneous and time-varying ages. By using an information-theoretic approach, we prove that the minimum training loss is a function of the ages of the features, where the function is not always monotonic. However, if the empirical distribution of the training data is close to the distribution of a Markov chain, then the training loss is approximately a non-decreasing age function. Both the training loss and testing loss depict similar growth patterns as the age increases. An experiment on solar power prediction is conducted to validate our theory. Our theoretical and experimental results suggest that it is beneficial to (i) combine the training data with different age values into a large training dataset and jointly train the forecasting decisions for these age values, and (ii) feed the age value as a part of the input feature to the neural network.
Target-Following Double Deep Q-Networks for UAVs
May 12, 2021
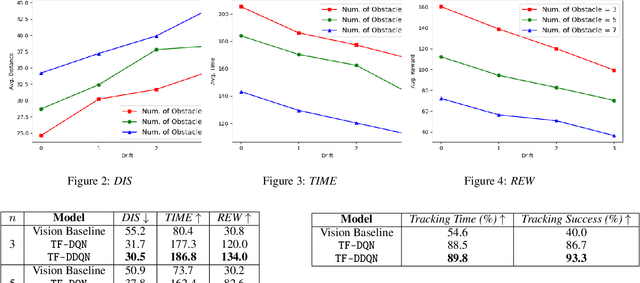


Target tracking in unknown real-world environments in the presence of obstacles and target motion uncertainty demand agents to develop an intrinsic understanding of the environment in order to predict the suitable actions to be taken at each time step. This task requires the agents to maximize the visibility of the mobile target maneuvering randomly in a network of roads by learning a policy that takes into consideration the various aspects of a real-world environment. In this paper, we propose a DDQN-based extension to the state-of-the-art in target tracking using a UAV TF-DQN, that we call TF-DDQN, that isolates the value estimation and evaluation steps. Additionally, in order to carefully benchmark the performance of any given target tracking algorithm, we introduce a novel target tracking evaluation scheme that quantifies its efficacy in terms of a wide set of diverse parameters. To replicate the real-world setting, we test our approach against standard baselines for the task of target tracking in complex environments with varying drift conditions and changes in environmental configuration.
MAVFI: An End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles
May 27, 2021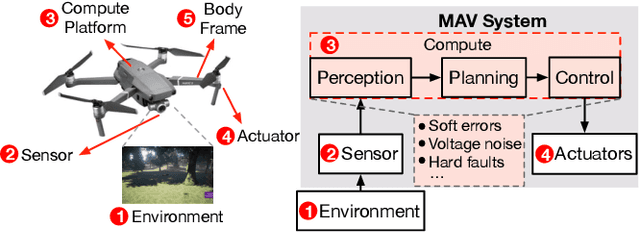

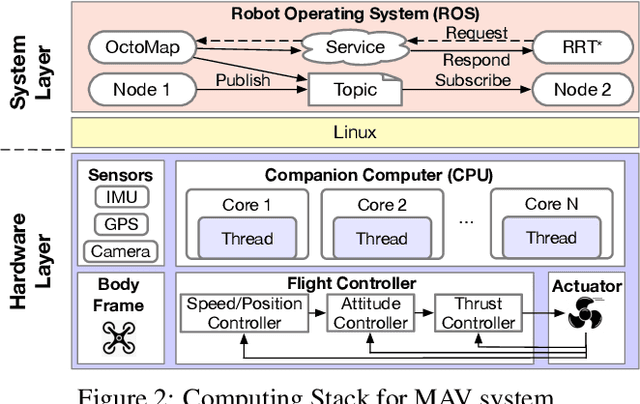
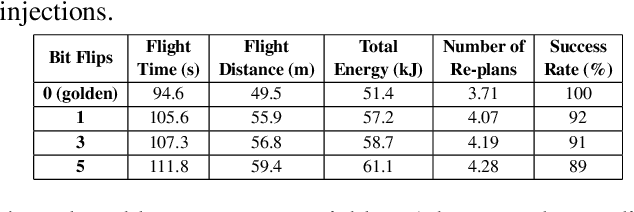
Reliability and safety are critical in autonomous machine services, such as autonomous vehicles and aerial drones. In this paper, we first present an open-source Micro Aerial Vehicles (MAVs) reliability analysis framework, MAVFI, to characterize transient fault's impacts on the end-to-end flight metrics, e.g., flight time, success rate. Based on our framework, it is observed that the end-to-end fault tolerance analysis is essential for characterizing system reliability. We demonstrate the planning and control stages are more vulnerable to transient faults than the visual perception stage in the common "Perception-Planning-Control (PPC)" compute pipeline. Furthermore, to improve the reliability of the MAV system, we propose two low overhead anomaly-based transient fault detection and recovery schemes based on Gaussian statistical models and autoencoder neural networks. We validate our anomaly fault protection schemes with a variety of simulated photo-realistic environments on both Intel i9 CPU and ARM Cortex-A57 on Nvidia TX2 platform. It is demonstrated that the autoencoder-based scheme can improve the system reliability by 100% recovering failure cases with less than 0.0062% computational overhead in best-case scenarios. In addition, MAVFI framework can be used for other ROS-based cyber-physical applications and is open-sourced at https://github.com/harvard-edge/MAVBench/tree/mavfi
Cross-Corpora Language Recognition: A Preliminary Investigation with Indian Languages
May 12, 2021
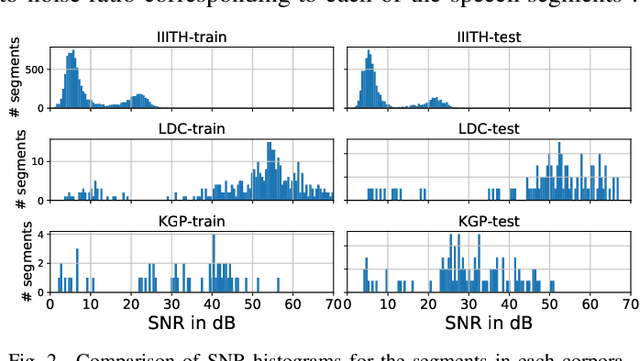
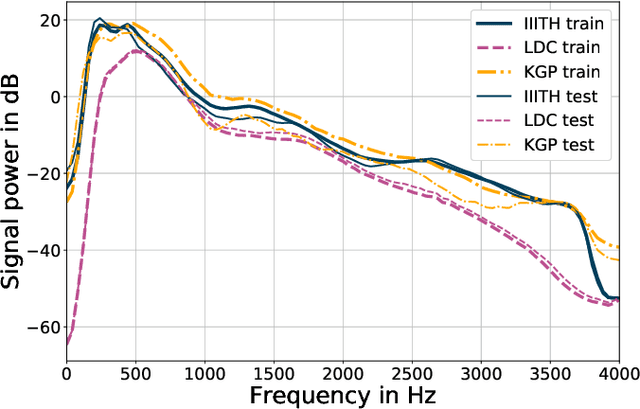
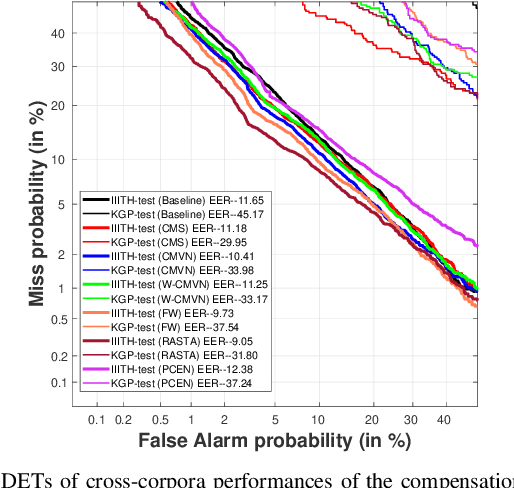
In this paper, we conduct one of the very first studies for cross-corpora performance evaluation in the spoken language identification (LID) problem. Cross-corpora evaluation was not explored much in LID research, especially for the Indian languages. We have selected three Indian spoken language corpora: IIITH-ILSC, LDC South Asian, and IITKGP-MLILSC. For each of the corpus, LID systems are trained on the state-of-the-art time-delay neural network (TDNN) based architecture with MFCC features. We observe that the LID performance degrades drastically for cross-corpora evaluation. For example, the system trained on the IIITH-ILSC corpus shows an average EER of 11.80 % and 43.34 % when evaluated with the same corpora and LDC South Asian corpora, respectively. Our preliminary analysis shows the significant differences among these corpora in terms of mismatch in the long-term average spectrum (LTAS) and signal-to-noise ratio (SNR). Subsequently, we apply different feature level compensation methods to reduce the cross-corpora acoustic mismatch. Our results indicate that these feature normalization schemes can help to achieve promising LID performance on cross-corpora experiments.
On the role of feedback in visual processing: a predictive coding perspective
Jun 08, 2021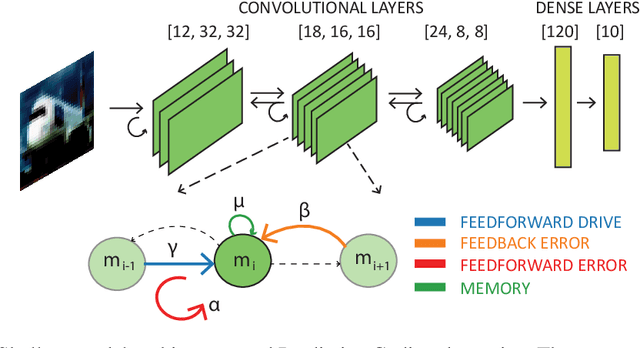
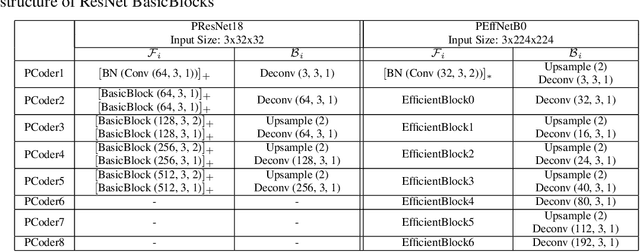
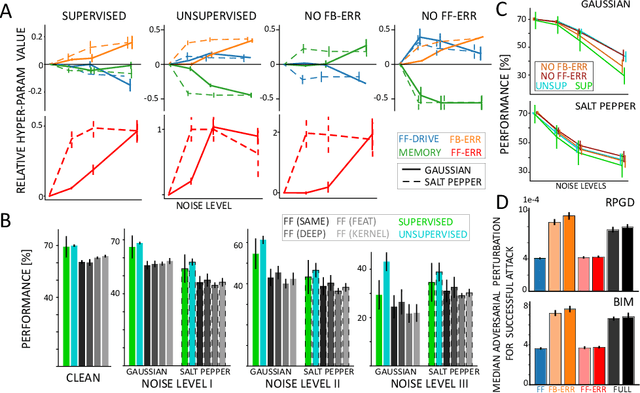
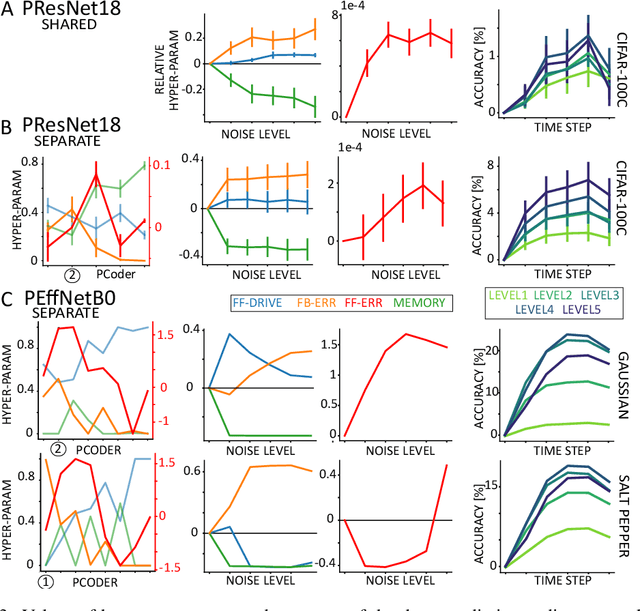
Brain-inspired machine learning is gaining increasing consideration, particularly in computer vision. Several studies investigated the inclusion of top-down feedback connections in convolutional networks; however, it remains unclear how and when these connections are functionally helpful. Here we address this question in the context of object recognition under noisy conditions. We consider deep convolutional networks (CNNs) as models of feed-forward visual processing and implement Predictive Coding (PC) dynamics through feedback connections (predictive feedback) trained for reconstruction or classification of clean images. To directly assess the computational role of predictive feedback in various experimental situations, we optimize and interpret the hyper-parameters controlling the network's recurrent dynamics. That is, we let the optimization process determine whether top-down connections and predictive coding dynamics are functionally beneficial. Across different model depths and architectures (3-layer CNN, ResNet18, and EfficientNetB0) and against various types of noise (CIFAR100-C), we find that the network increasingly relies on top-down predictions as the noise level increases; in deeper networks, this effect is most prominent at lower layers. In addition, the accuracy of the network implementing PC dynamics significantly increases over time-steps, compared to its equivalent forward network. All in all, our results provide novel insights relevant to Neuroscience by confirming the computational role of feedback connections in sensory systems, and to Machine Learning by revealing how these can improve the robustness of current vision models.
MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects
Oct 22, 2018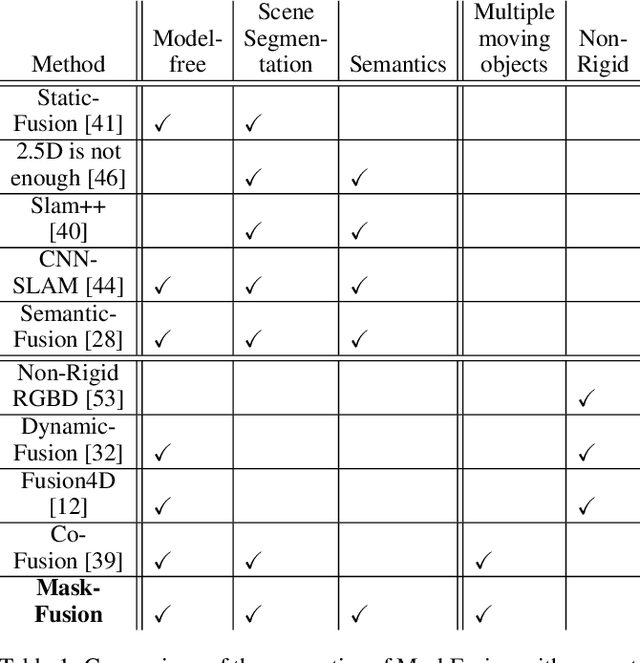
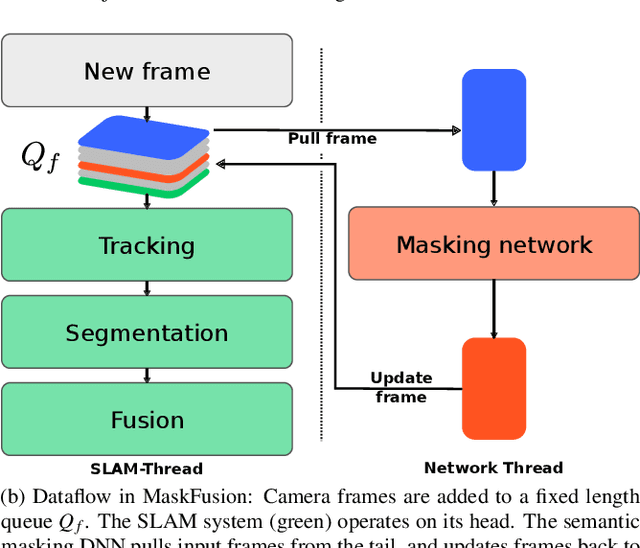
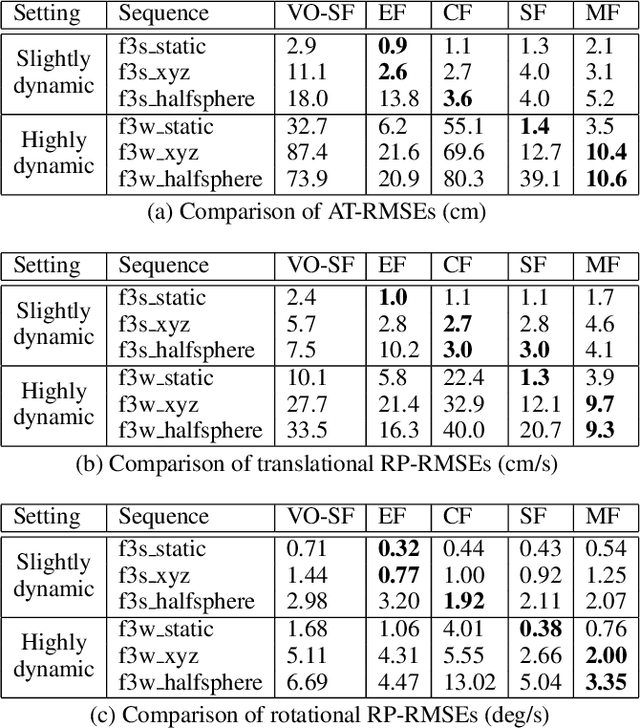
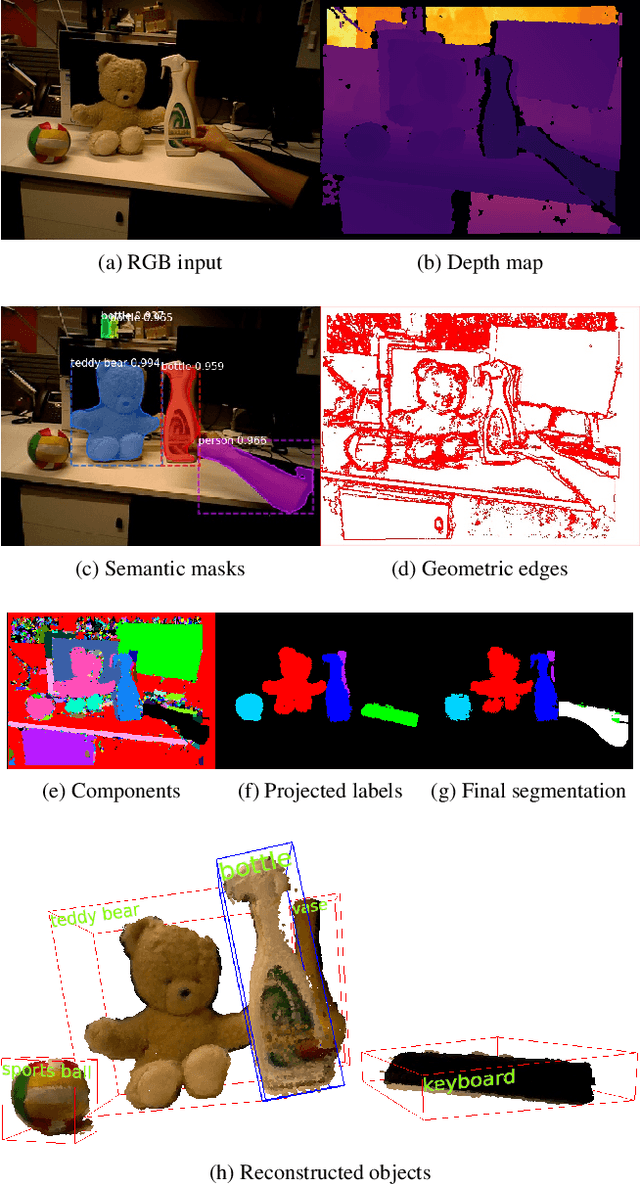
We present MaskFusion, a real-time, object-aware, semantic and dynamic RGB-D SLAM system that goes beyond traditional systems which output a purely geometric map of a static scene. MaskFusion recognizes, segments and assigns semantic class labels to different objects in the scene, while tracking and reconstructing them even when they move independently from the camera. As an RGB-D camera scans a cluttered scene, image-based instance-level semantic segmentation creates semantic object masks that enable real-time object recognition and the creation of an object-level representation for the world map. Unlike previous recognition-based SLAM systems, MaskFusion does not require known models of the objects it can recognize, and can deal with multiple independent motions. MaskFusion takes full advantage of using instance-level semantic segmentation to enable semantic labels to be fused into an object-aware map, unlike recent semantics enabled SLAM systems that perform voxel-level semantic segmentation. We show augmented-reality applications that demonstrate the unique features of the map output by MaskFusion: instance-aware, semantic and dynamic.
Guaranteeing Maximin Shares: Some Agents Left Behind
May 19, 2021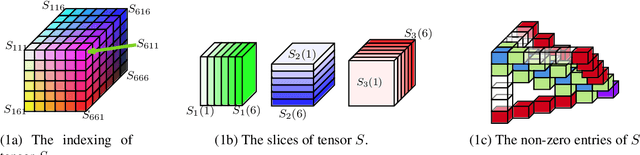
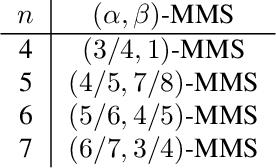
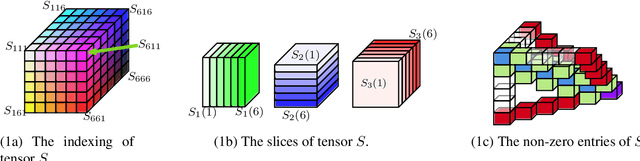
The maximin share (MMS) guarantee is a desirable fairness notion for allocating indivisible goods. While MMS allocations do not always exist, several approximation techniques have been developed to ensure that all agents receive a fraction of their maximin share. We focus on an alternative approximation notion, based on the population of agents, that seeks to guarantee MMS for a fraction of agents. We show that no optimal approximation algorithm can satisfy more than a constant number of agents, and discuss the existence and computation of MMS for all but one agent and its relation to approximate MMS guarantees. We then prove the existence of allocations that guarantee MMS for $\frac{2}{3}$ of agents, and devise a polynomial time algorithm that achieves this bound for up to nine agents. A key implication of our result is the existence of allocations that guarantee $\text{MMS}^{\lceil{3n/2}\rceil}$, i.e., the value that agents receive by partitioning the goods into $\lceil{\frac{3}{2}n}\rceil$ bundles, improving the best known guarantee of $\text{MMS}^{2n-2}$. Finally, we provide empirical experiments using synthetic data.
A Gun Detection Dataset and Searching for Embedded Device Solutions
May 03, 2021

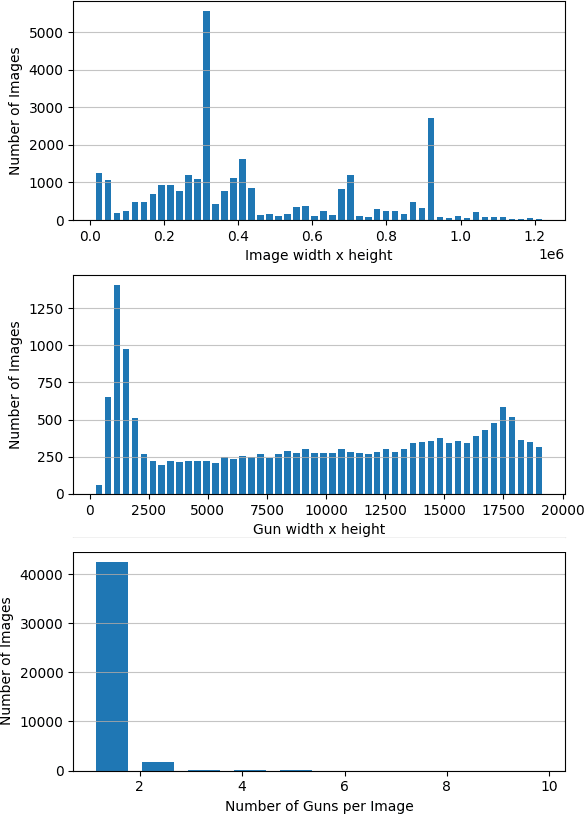
Gun violence is a severe problem in the world, particularly in the United States. Computer vision methods have been studied to detect guns in surveillance video cameras or smart IP cameras and to send a real-time alert to safety personals. However, due to no public datasets, it is hard to benchmark how well such methods work in real applications. In this paper we publish a dataset with 51K annotated gun images for gun detection and other 51K cropped gun chip images for gun classification we collect from a few different sources. To our knowledge, this is the largest dataset for the study of gun detection. This dataset can be downloaded at www.linksprite.com/gun-detection-datasets. We also study to search for solutions for gun detection in embedded edge device (camera) and a gun/non-gun classification on a cloud server. This edge/cloud framework makes possible the deployment of gun detection in the real world.
Auto4D: Learning to Label 4D Objects from Sequential Point Clouds
Jan 17, 2021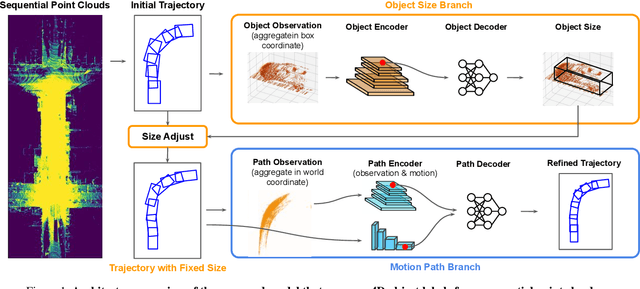
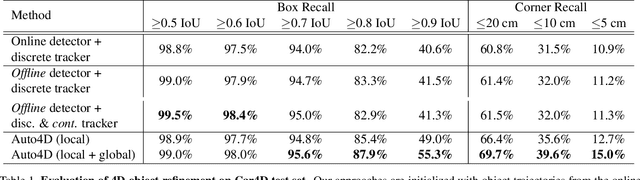
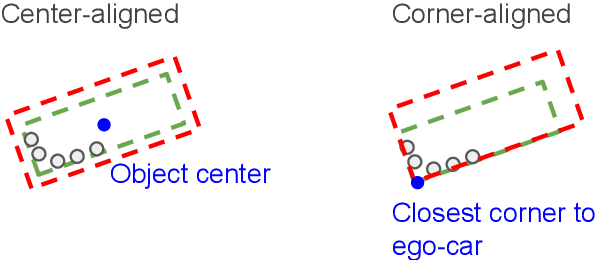
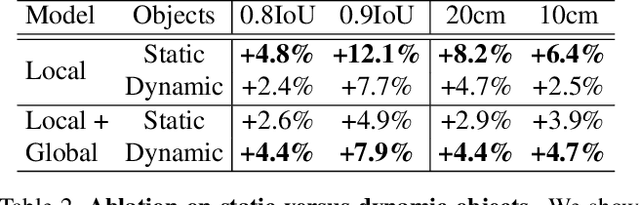
In the past few years we have seen great advances in 3D object detection thanks to deep learning methods. However, they typically rely on large amounts of high-quality labels to achieve good performance, which often require time-consuming and expensive work by human annotators. To address this we propose an automatic annotation pipeline that generates accurate object trajectories in 3D (ie, 4D labels) from LiDAR point clouds. Different from previous works that consider single frames at a time, our approach directly operates on sequential point clouds to combine richer object observations. The key idea is to decompose the 4D label into two parts: the 3D size of the object, and its motion path describing the evolution of the object's pose through time. More specifically, given a noisy but easy-to-get object track as initialization, our model first estimates the object size from temporally aggregated observations, and then refines its motion path by considering both frame-wise observations as well as temporal motion cues. We validate the proposed method on a large-scale driving dataset and show that our approach achieves significant improvements over the baselines. We also showcase the benefits of our approach under the annotator-in-the-loop setting.