 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Networked Federated Multi-Task Learning
May 26, 2021

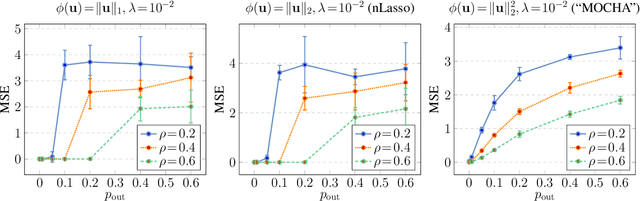
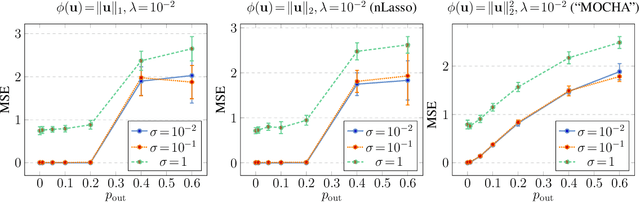
Many important application domains generate distributed collections of heterogeneous local datasets. These local datasets are often related via an intrinsic network structure that arises from domain-specific notions of similarity between local datasets. Different notions of similarity are induced by spatiotemporal proximity, statistical dependencies, or functional relations. We use this network structure to adaptively pool similar local datasets into nearly homogenous training sets for learning tailored models. Our main conceptual contribution is to formulate networked federated learning using the concept of generalized total variation (GTV) minimization as a regularizer. This formulation is highly flexible and can be combined with almost any parametric model including Lasso or deep neural networks. We unify and considerably extend some well-known approaches to federated multi-task learning. Our main algorithmic contribution is a novel federated learning algorithm that is well suited for distributed computing environments such as edge computing over wireless networks. This algorithm is robust against model misspecification and numerical errors arising from limited computational resources including processing time or wireless channel bandwidth. As our main technical contribution, we offer precise conditions on the local models as well on their network structure such that our algorithm learns nearly optimal local models. Our analysis reveals an interesting interplay between the (information-) geometry of local models and the (cluster-) geometry of their network.
Pre-treatment of outliers and anomalies in plant data: Methodology and case study of a Vacuum Distillation Unit
Jun 17, 2021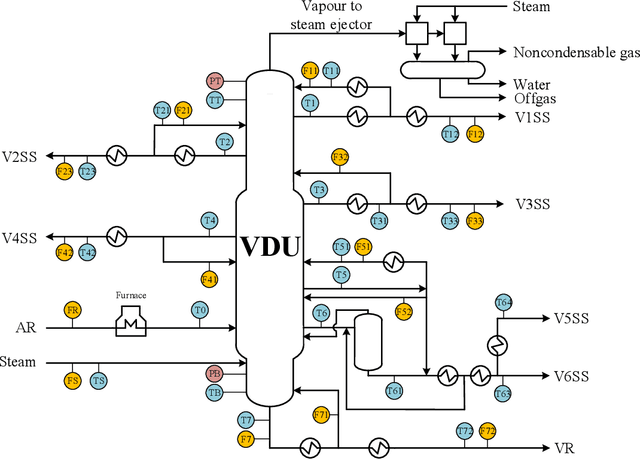
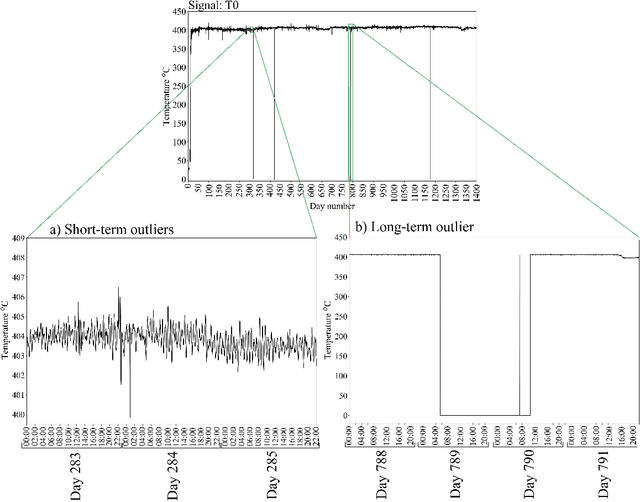
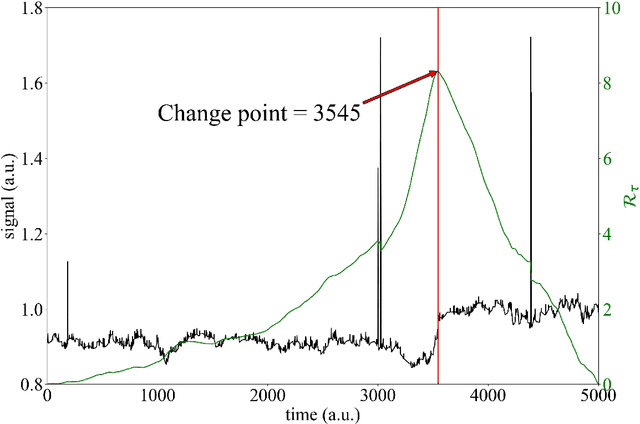

Data pre-treatment plays a significant role in improving data quality, thus allowing extraction of accurate information from raw data. One of the data pre-treatment techniques commonly used is outliers detection. The so-called 3${\sigma}$ method is a common practice to identify the outliers. As shown in the manuscript, it does not identify all outliers, resulting in possible distortion of the overall statistics of the data. This problem can have a significant impact on further data analysis and can lead to reduction in the accuracy of predictive models. There is a plethora of various techniques for outliers detection, however, aside from theoretical work, they all require case study work. Two types of outliers were considered: short-term (erroneous data, noise) and long-term outliers (e.g. malfunctioning for longer periods). The data used were taken from the vacuum distillation unit (VDU) of an Asian refinery and included 40 physical sensors (temperature, pressure and flow rate). We used a modified method for 3${\sigma}$ thresholds to identify the short-term outliers, i.e. ensors data are divided into chunks determined by change points and 3${\sigma}$ thresholds are calculated within each chunk representing near-normal distribution. We have shown that piecewise 3${\sigma}$ method offers a better approach to short-term outliers detection than 3${\sigma}$ method applied to the entire time series. Nevertheless, this does not perform well for long-term outliers (which can represent another state in the data). In this case, we used principal component analysis (PCA) with Hotelling's $T^2$ statistics to identify the long-term outliers. The results obtained with PCA were subject to DBSCAN clustering method. The outliers (which were visually obvious and correctly detected by the PCA method) were also correctly identified by DBSCAN which supported the consistency and accuracy of the PCA method.
Full-Sentence Models Perform Better in Simultaneous Translation Using the Information Enhanced Decoding Strategy
May 05, 2021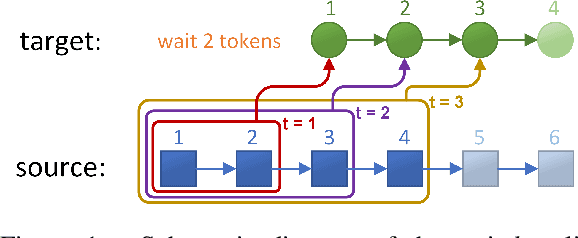
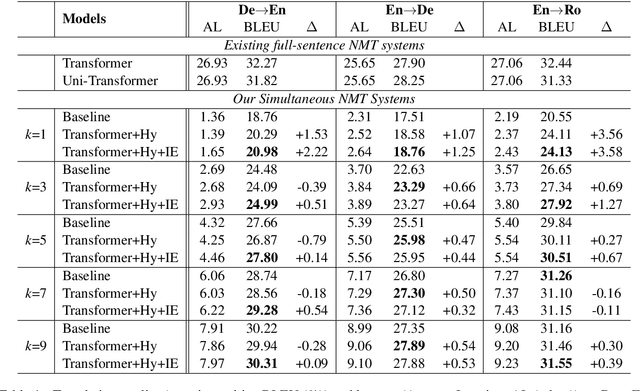
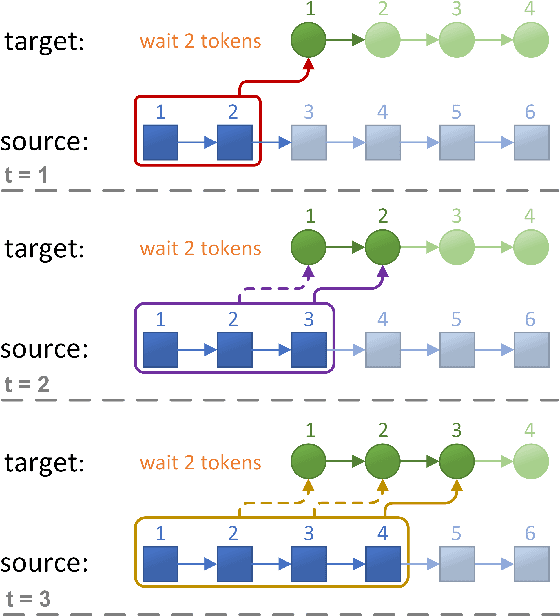
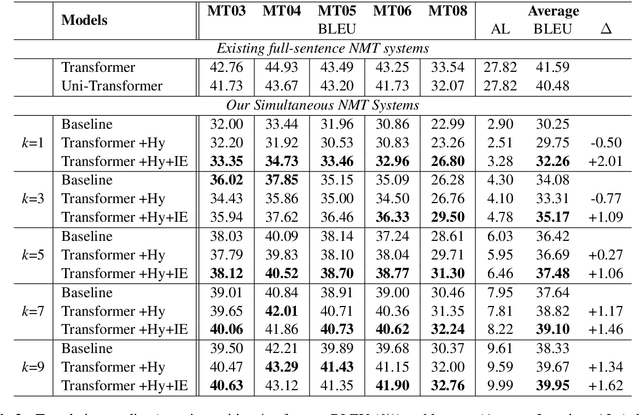
Simultaneous translation, which starts translating each sentence after receiving only a few words in source sentence, has a vital role in many scenarios. Although the previous prefix-to-prefix framework is considered suitable for simultaneous translation and achieves good performance, it still has two inevitable drawbacks: the high computational resource costs caused by the need to train a separate model for each latency $k$ and the insufficient ability to encode information because each target token can only attend to a specific source prefix. We propose a novel framework that adopts a simple but effective decoding strategy which is designed for full-sentence models. Within this framework, training a single full-sentence model can achieve arbitrary given latency and save computational resources. Besides, with the competence of the full-sentence model to encode the whole sentence, our decoding strategy can enhance the information maintained in the decoded states in real time. Experimental results show that our method achieves better translation quality than baselines on 4 directions: Zh$\rightarrow$En, En$\rightarrow$Ro and En$\leftrightarrow$De.
Multiview Pseudo-Labeling for Semi-supervised Learning from Video
Apr 01, 2021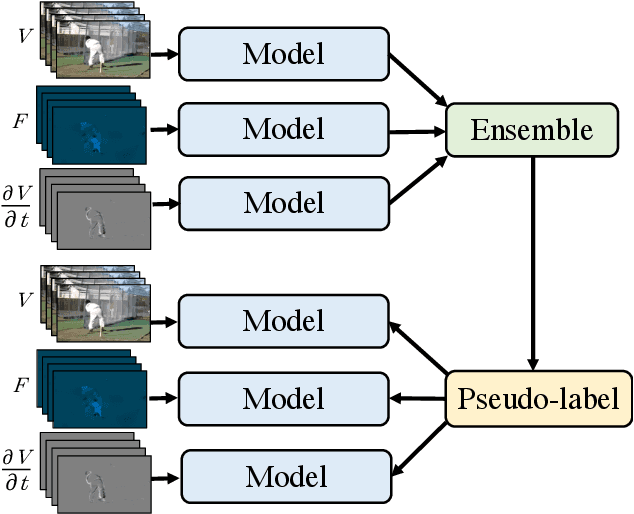
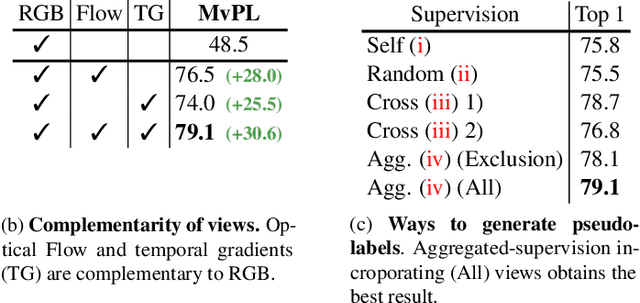
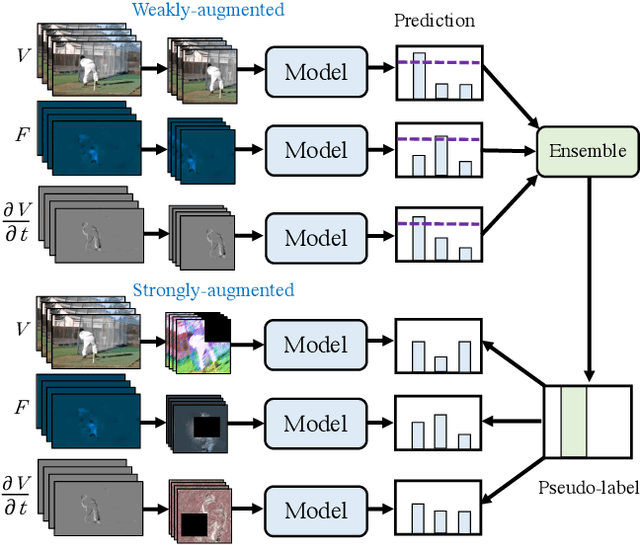

We present a multiview pseudo-labeling approach to video learning, a novel framework that uses complementary views in the form of appearance and motion information for semi-supervised learning in video. The complementary views help obtain more reliable pseudo-labels on unlabeled video, to learn stronger video representations than from purely supervised data. Though our method capitalizes on multiple views, it nonetheless trains a model that is shared across appearance and motion input and thus, by design, incurs no additional computation overhead at inference time. On multiple video recognition datasets, our method substantially outperforms its supervised counterpart, and compares favorably to previous work on standard benchmarks in self-supervised video representation learning.
Change Matters: Medication Change Prediction with Recurrent Residual Networks
May 05, 2021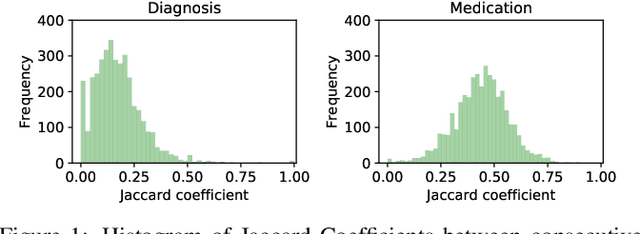
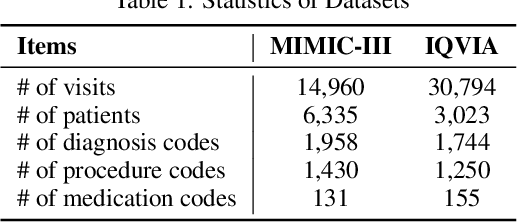
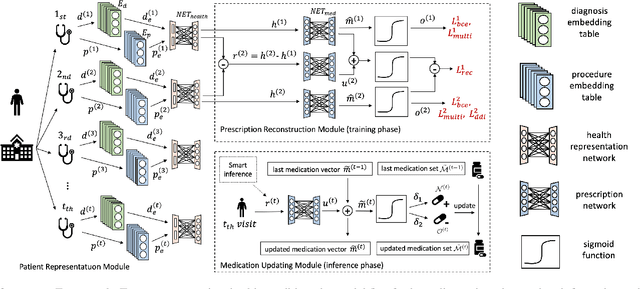
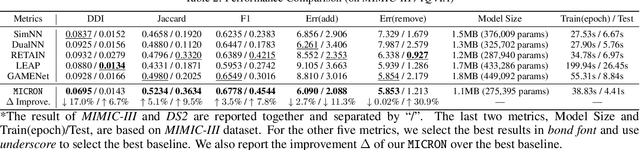
Deep learning is revolutionizing predictive healthcare, including recommending medications to patients with complex health conditions. Existing approaches focus on predicting all medications for the current visit, which often overlaps with medications from previous visits. A more clinically relevant task is to identify medication changes. In this paper, we propose a new recurrent residual network, named MICRON, for medication change prediction. MICRON takes the changes in patient health records as input and learns to update a hidden medication vector and the medication set recurrently with a reconstruction design. The medication vector is like the memory cell that encodes longitudinal information of medications. Unlike traditional methods that require the entire patient history for prediction, MICRON has a residual-based inference that allows for sequential updating based only on new patient features (e.g., new diagnoses in the recent visit) more efficiently. We evaluated MICRON on real inpatient and outpatient datasets. MICRON achieves 3.5% and 7.8% relative improvements over the best baseline in F1 score, respectively. MICRON also requires fewer parameters, which significantly reduces the training time to 38.3s per epoch with 1.5x speed-up.
WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
Mar 06, 2021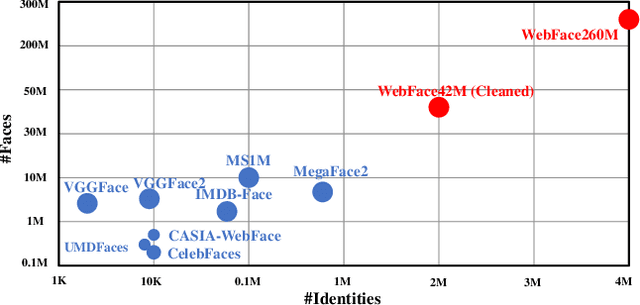
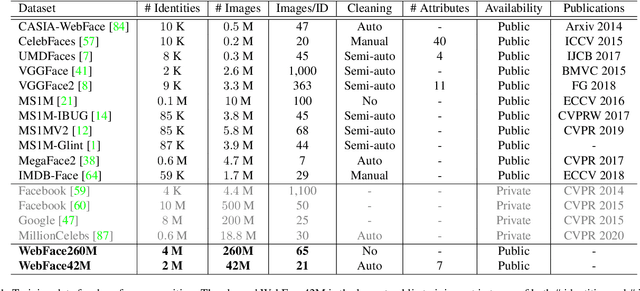
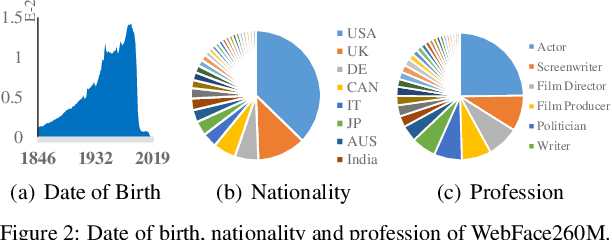
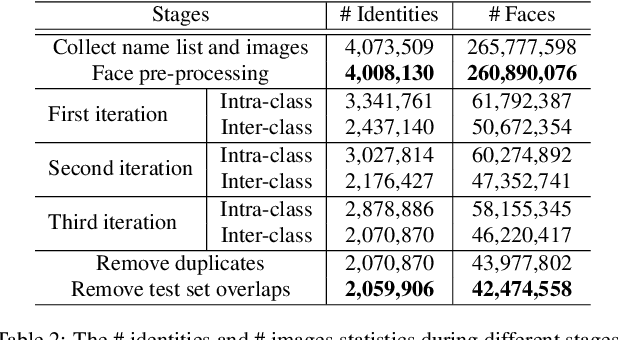
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.
BlitzNet: A Real-Time Deep Network for Scene Understanding
Aug 09, 2017
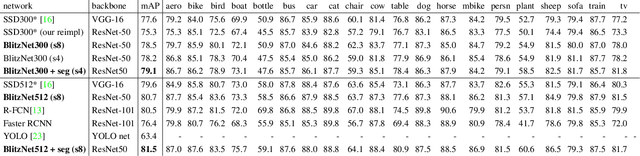
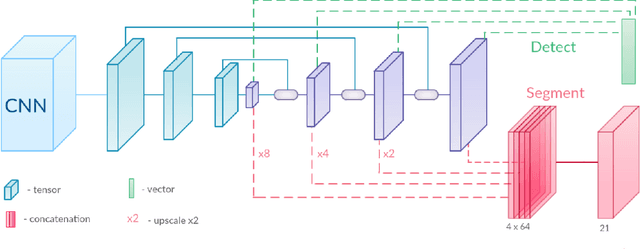
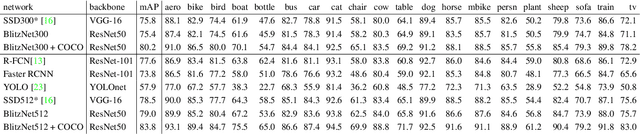
Real-time scene understanding has become crucial in many applications such as autonomous driving. In this paper, we propose a deep architecture, called BlitzNet, that jointly performs object detection and semantic segmentation in one forward pass, allowing real-time computations. Besides the computational gain of having a single network to perform several tasks, we show that object detection and semantic segmentation benefit from each other in terms of accuracy. Experimental results for VOC and COCO datasets show state-of-the-art performance for object detection and segmentation among real time systems.
Almost Surely Stable Deep Dynamics
Mar 26, 2021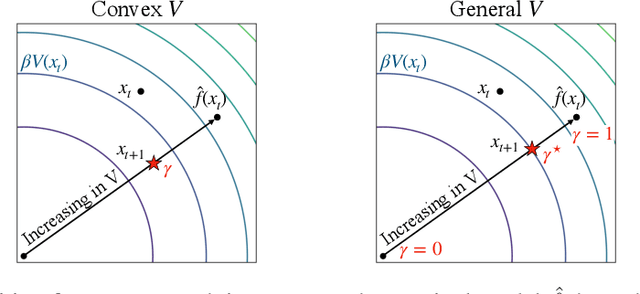
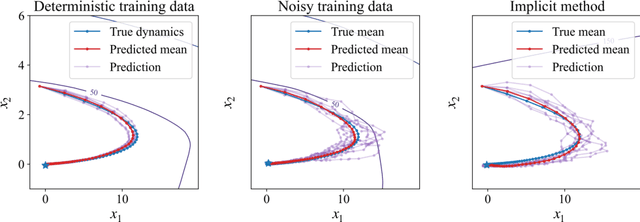
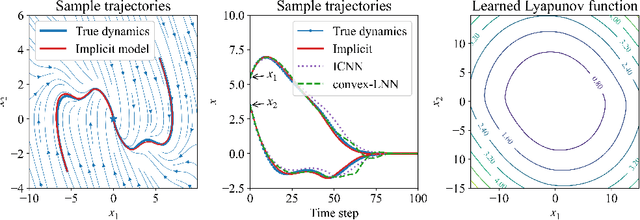
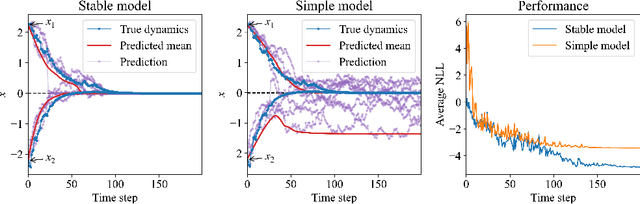
We introduce a method for learning provably stable deep neural network based dynamic models from observed data. Specifically, we consider discrete-time stochastic dynamic models, as they are of particular interest in practical applications such as estimation and control. However, these aspects exacerbate the challenge of guaranteeing stability. Our method works by embedding a Lyapunov neural network into the dynamic model, thereby inherently satisfying the stability criterion. To this end, we propose two approaches and apply them in both the deterministic and stochastic settings: one exploits convexity of the Lyapunov function, while the other enforces stability through an implicit output layer. We demonstrate the utility of each approach through numerical examples.
* NeurIPS 2020; Spotlight Paper
Exploring Deep Learning for Joint Audio-Visual Lip Biometrics
Apr 17, 2021
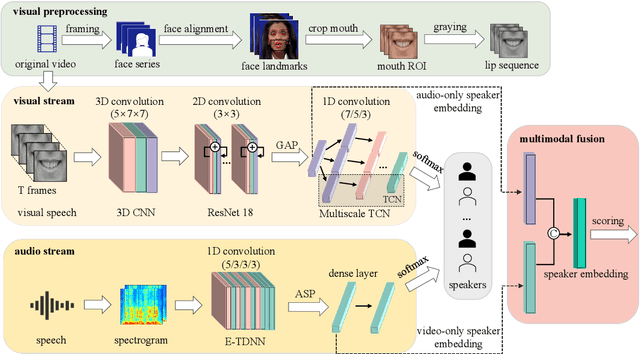

Audio-visual (AV) lip biometrics is a promising authentication technique that leverages the benefits of both the audio and visual modalities in speech communication. Previous works have demonstrated the usefulness of AV lip biometrics. However, the lack of a sizeable AV database hinders the exploration of deep-learning-based audio-visual lip biometrics. To address this problem, we compile a moderate-size database using existing public databases. Meanwhile, we establish the DeepLip AV lip biometrics system realized with a convolutional neural network (CNN) based video module, a time-delay neural network (TDNN) based audio module, and a multimodal fusion module. Our experiments show that DeepLip outperforms traditional speaker recognition models in context modeling and achieves over 50% relative improvements compared with our best single modality baseline, with an equal error rate of 0.75% and 1.11% on the test datasets, respectively.
Efficient Evolutionary Models with Digraphons
Apr 26, 2021
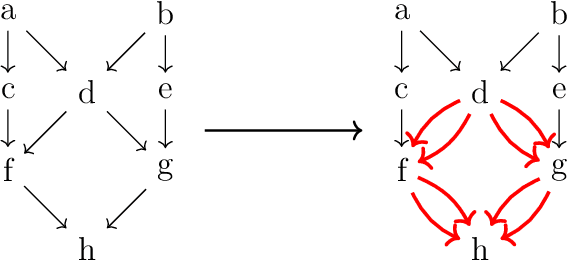
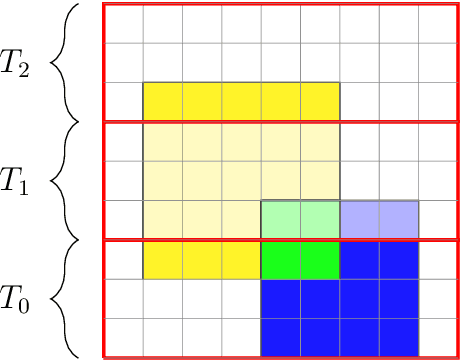
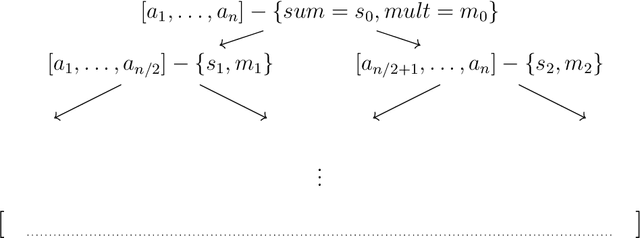
We present two main contributions which help us in leveraging the theory of graphons for modeling evolutionary processes. We show a generative model for digraphons using a finite basis of subgraphs, which is representative of biological networks with evolution by duplication. We show a simple MAP estimate on the Bayesian non parametric model using the Dirichlet Chinese restaurant process representation, with the help of a Gibbs sampling algorithm to infer the prior. Next we show an efficient implementation to do simulations on finite basis segmentations of digraphons. This implementation is used for developing fast evolutionary simulations with the help of an efficient 2-D representation of the digraphon using dynamic segment-trees with the square-root decomposition representation. We further show how this representation is flexible enough to handle changing graph nodes and can be used to also model dynamic digraphons with the help of an amortized update representation to achieve an efficient time complexity of the update at $O(\sqrt{|V|}\log{|V|})$.