 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coherent Integration for Targets with Constant Cartesian Velocities Based on Accurate Range Model
Feb 19, 2021
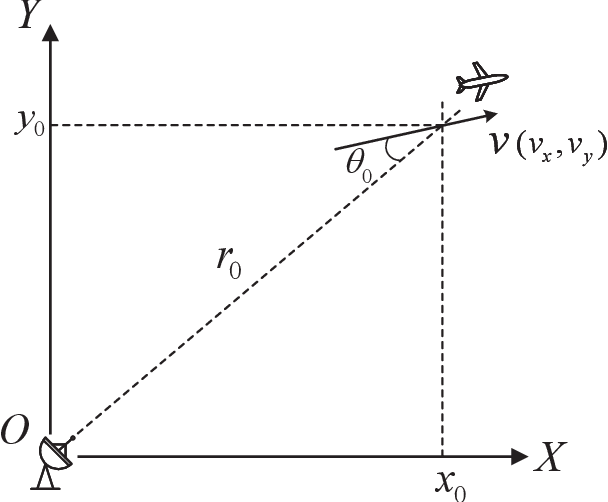

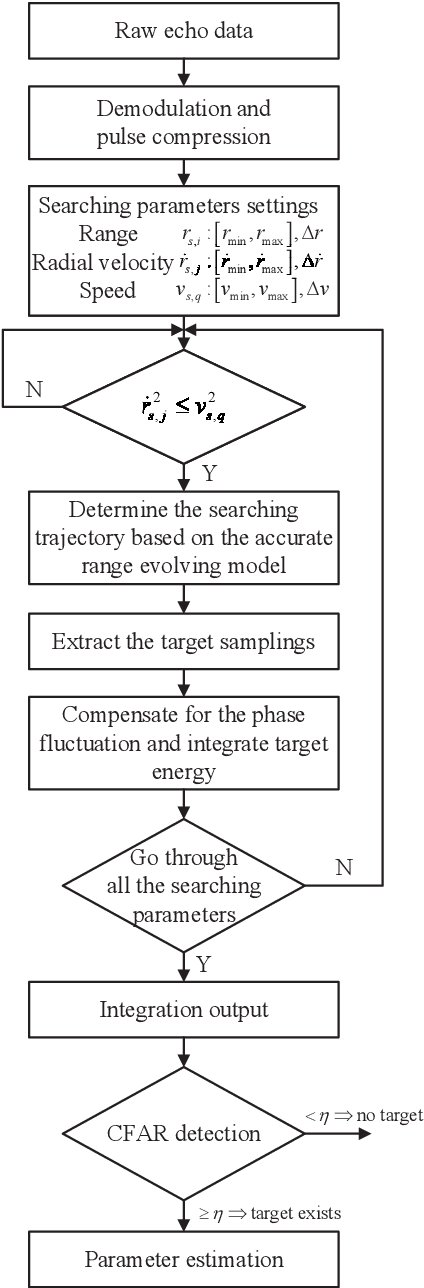

Long-time coherent integration (LTCI) is one of the most important techniques to improve radar detection performance of weak targets. However, for the targets moving with constant Cartesian velocities (CCV), the existing LTCI methods based on polynomial motion models suffer from limited integration time and coverage of target speed due to model mismatch. Here, a novel generalized Radon Fourier transform method for CCV targets is presented, based on the accurate range evolving model, which is a square root of a polynomial with terms up to the second order with target speed as the factor. The accurate model instead of approximate polynomial models used in the proposed method enables effective energy integration on characteristic invariant with feasible computational complexity. The target samplings are collected and the phase fluctuation among pulses is compensated according to the accurate range model. The high order range migration and complex Doppler frequency migration caused by the highly nonlinear signal are eliminated simultaneously. Integration results demonstrate that the proposed method can not only achieve effective coherent integration of CCV targets regardless of target speed and coherent processing interval, but also provide additional observation and resolution in speed domain.
Change Matters: Medication Change Prediction with Recurrent Residual Networks
May 05, 2021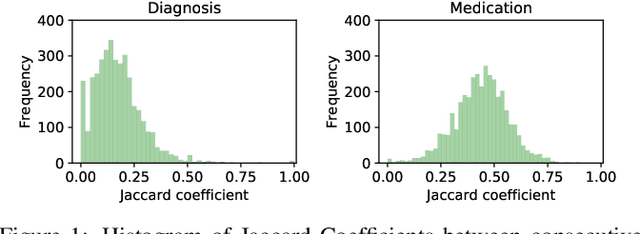
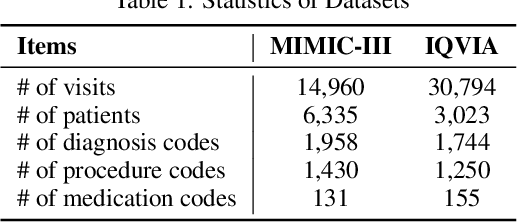
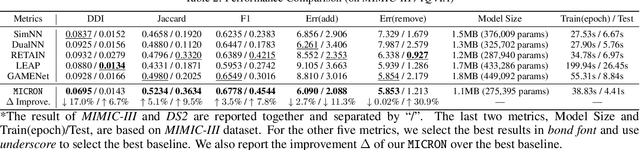
Deep learning is revolutionizing predictive healthcare, including recommending medications to patients with complex health conditions. Existing approaches focus on predicting all medications for the current visit, which often overlaps with medications from previous visits. A more clinically relevant task is to identify medication changes. In this paper, we propose a new recurrent residual network, named MICRON, for medication change prediction. MICRON takes the changes in patient health records as input and learns to update a hidden medication vector and the medication set recurrently with a reconstruction design. The medication vector is like the memory cell that encodes longitudinal information of medications. Unlike traditional methods that require the entire patient history for prediction, MICRON has a residual-based inference that allows for sequential updating based only on new patient features (e.g., new diagnoses in the recent visit) more efficiently. We evaluated MICRON on real inpatient and outpatient datasets. MICRON achieves 3.5% and 7.8% relative improvements over the best baseline in F1 score, respectively. MICRON also requires fewer parameters, which significantly reduces the training time to 38.3s per epoch with 1.5x speed-up.
On the Power of Preconditioning in Sparse Linear Regression
Jun 17, 2021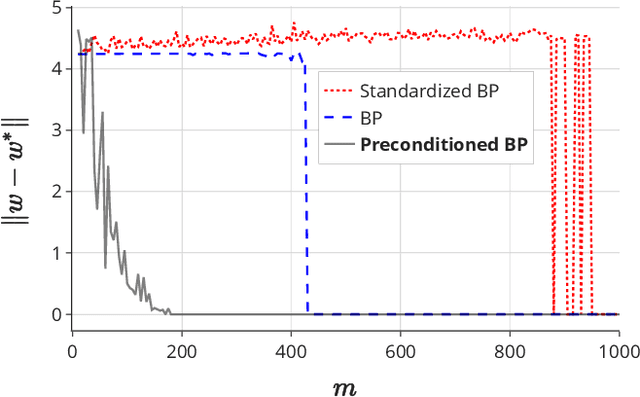
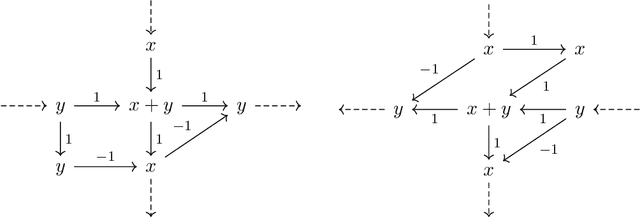
Sparse linear regression is a fundamental problem in high-dimensional statistics, but strikingly little is known about how to efficiently solve it without restrictive conditions on the design matrix. We consider the (correlated) random design setting, where the covariates are independently drawn from a multivariate Gaussian $N(0,\Sigma)$ with $\Sigma : n \times n$, and seek estimators $\hat{w}$ minimizing $(\hat{w}-w^*)^T\Sigma(\hat{w}-w^*)$, where $w^*$ is the $k$-sparse ground truth. Information theoretically, one can achieve strong error bounds with $O(k \log n)$ samples for arbitrary $\Sigma$ and $w^*$; however, no efficient algorithms are known to match these guarantees even with $o(n)$ samples, without further assumptions on $\Sigma$ or $w^*$. As far as hardness, computational lower bounds are only known with worst-case design matrices. Random-design instances are known which are hard for the Lasso, but these instances can generally be solved by Lasso after a simple change-of-basis (i.e. preconditioning). In this work, we give upper and lower bounds clarifying the power of preconditioning in sparse linear regression. First, we show that the preconditioned Lasso can solve a large class of sparse linear regression problems nearly optimally: it succeeds whenever the dependency structure of the covariates, in the sense of the Markov property, has low treewidth -- even if $\Sigma$ is highly ill-conditioned. Second, we construct (for the first time) random-design instances which are provably hard for an optimally preconditioned Lasso. In fact, we complete our treewidth classification by proving that for any treewidth-$t$ graph, there exists a Gaussian Markov Random Field on this graph such that the preconditioned Lasso, with any choice of preconditioner, requires $\Omega(t^{1/20})$ samples to recover $O(\log n)$-sparse signals when covariates are drawn from this model.
Enabling Content-Centric Device-to-Device Communication in the Millimeter-Wave Band
Apr 12, 2021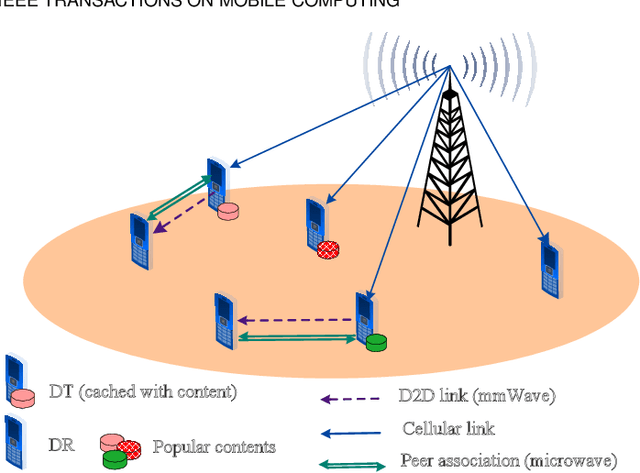

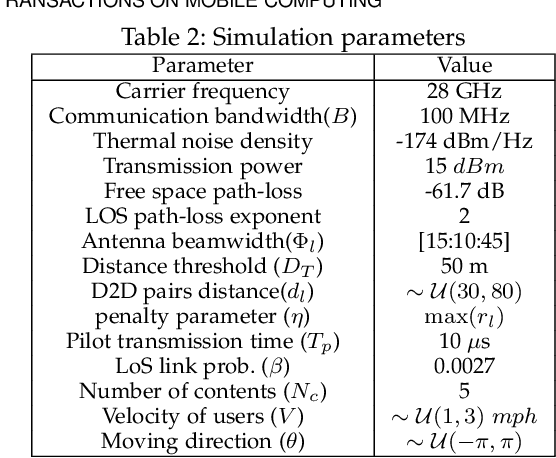
The growth in wireless traffic and mobility of devices have congested the core network significantly. This bottleneck, along with spectrum scarcity, made the conventional cellular networks insufficient for the dissemination of large contents. In this paper, we propose a novel scheme that enables efficient initialization of CCN-based D2D networks in the mmWave band through addressing decentralized D2D peer association and antenna beamwidth selection. The proposed scheme considers mmWave characteristics such as directional communication and blockage susceptibility. We propose a heuristic peer association algorithm to associate D2D users using context information, including link stability time and content availability. The performance of the proposed scheme in terms of data throughput and transmission efficiency is evaluated through extensive simulations. Simulation results show that the proposed scheme improves network performance significantly and outperforms other methods in the literature.
Efficient Algorithms for Estimating the Parameters of Mixed Linear Regression Models
May 12, 2021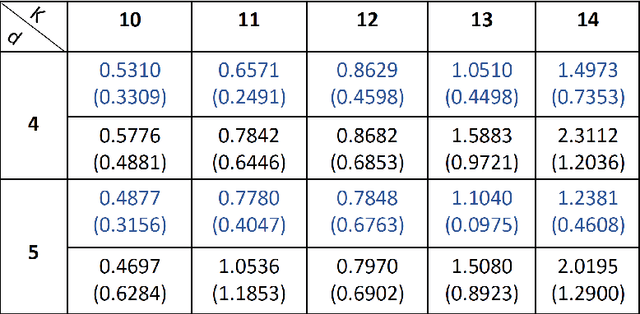
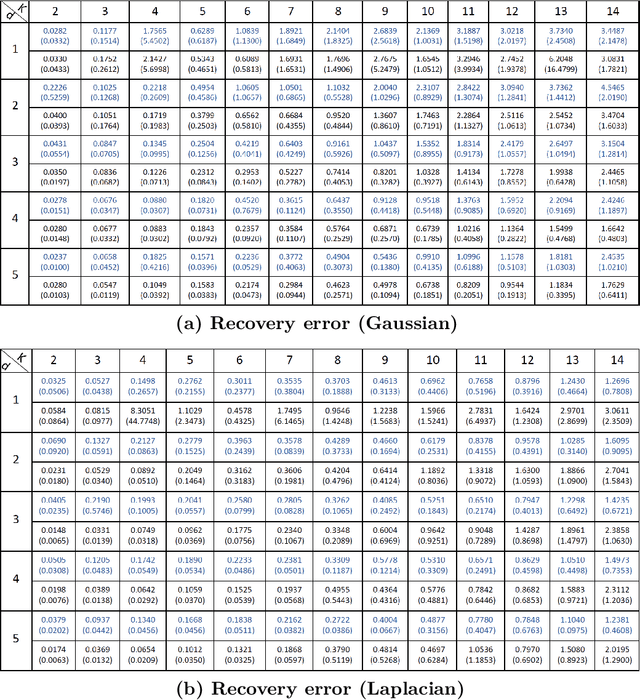
Mixed linear regression (MLR) model is among the most exemplary statistical tools for modeling non-linear distributions using a mixture of linear models. When the additive noise in MLR model is Gaussian, Expectation-Maximization (EM) algorithm is a widely-used algorithm for maximum likelihood estimation of MLR parameters. However, when noise is non-Gaussian, the steps of EM algorithm may not have closed-form update rules, which makes EM algorithm impractical. In this work, we study the maximum likelihood estimation of the parameters of MLR model when the additive noise has non-Gaussian distribution. In particular, we consider the case that noise has Laplacian distribution and we first show that unlike the the Gaussian case, the resulting sub-problems of EM algorithm in this case does not have closed-form update rule, thus preventing us from using EM in this case. To overcome this issue, we propose a new algorithm based on combining the alternating direction method of multipliers (ADMM) with EM algorithm idea. Our numerical experiments show that our method outperforms the EM algorithm in statistical accuracy and computational time in non-Gaussian noise case.
Modelling Segmented Cardiotocography Time-Series Signals Using One-Dimensional Convolutional Neural Networks for the Early Detection of Abnormal Birth Outcomes
Aug 06, 2019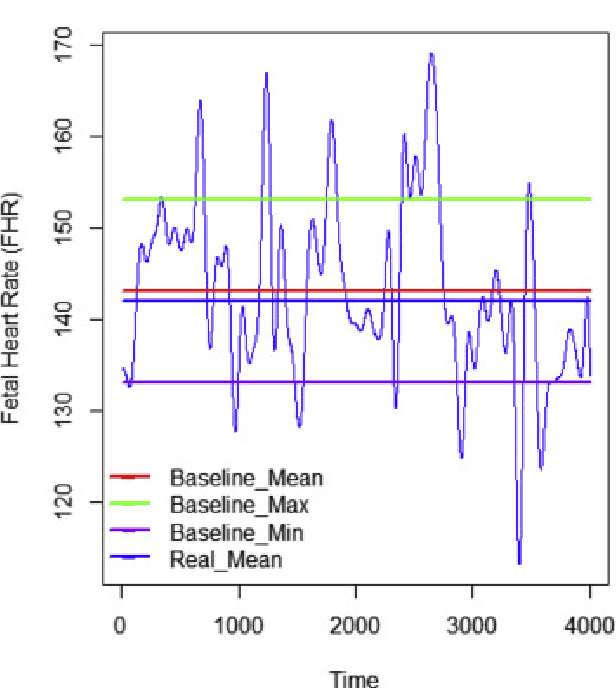
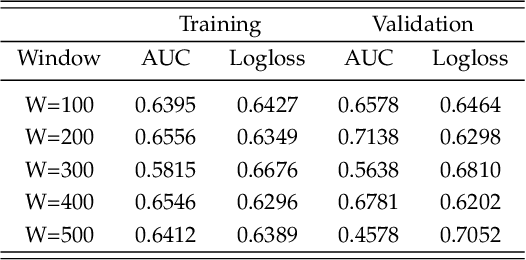
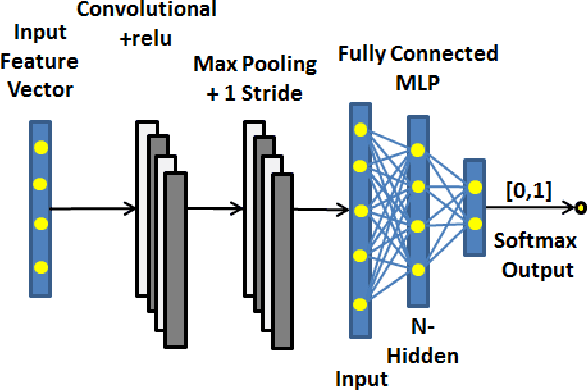
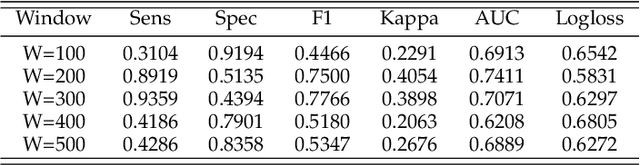
Gynaecologists and obstetricians visually interpret cardiotocography (CTG) traces using the International Federation of Gynaecology and Obstetrics (FIGO) guidelines to assess the wellbeing of the foetus during antenatal care. This approach has raised concerns among professionals concerning inter- and intra-variability where clinical diagnosis only has a 30% positive predictive value when classifying pathological outcomes. Machine learning models, trained with FIGO and other user derived features extracted from CTG traces, have been shown to increase positive predictive capacity and minimise variability. This is only possible however when class distributions are equal which is rarely the case in clinical trials where case-control observations are heavily skewed. Classes can be balanced using either synthetic data derived from resampled case training data or by decreasing the number of control instances. However, this introduces bias and removes valuable information. Concerns have also been raised regarding machine learning studies and their reliance on manually handcrafted features. While this has led to some interesting results, deriving an optimal set of features is considered to be an art as well as a science and is often an empirical and time consuming process. In this paper, we address both of these issues and propose a novel CTG analysis methodology that a) splits CTG time series signals into n-size windows with equal class distributions, and b) automatically extracts features from time-series windows using a one dimensional convolutional neural network (1DCNN) and multilayer perceptron (MLP) ensemble. Our proposed method achieved good results using a window size of 200 with (Sens=0.7981, Spec=0.7881, F1=0.7830, Kappa=0.5849, AUC=0.8599, and Logloss=0.4791).
Efficient Evolutionary Models with Digraphons
Apr 26, 2021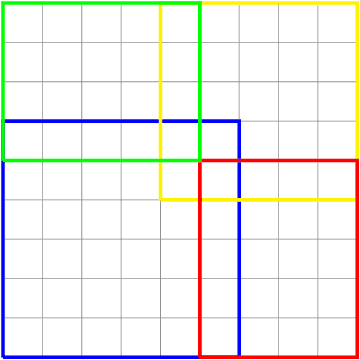
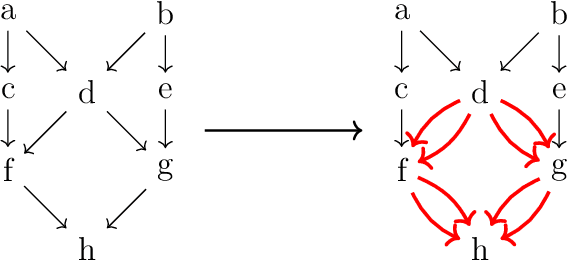
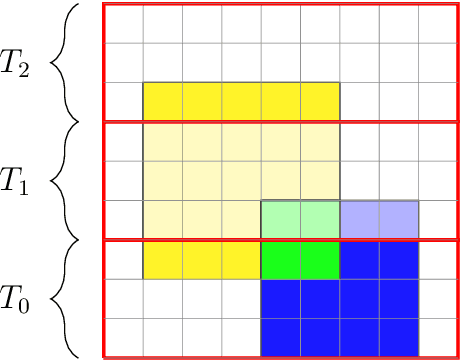
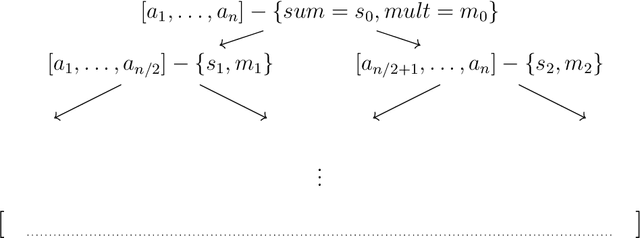
We present two main contributions which help us in leveraging the theory of graphons for modeling evolutionary processes. We show a generative model for digraphons using a finite basis of subgraphs, which is representative of biological networks with evolution by duplication. We show a simple MAP estimate on the Bayesian non parametric model using the Dirichlet Chinese restaurant process representation, with the help of a Gibbs sampling algorithm to infer the prior. Next we show an efficient implementation to do simulations on finite basis segmentations of digraphons. This implementation is used for developing fast evolutionary simulations with the help of an efficient 2-D representation of the digraphon using dynamic segment-trees with the square-root decomposition representation. We further show how this representation is flexible enough to handle changing graph nodes and can be used to also model dynamic digraphons with the help of an amortized update representation to achieve an efficient time complexity of the update at $O(\sqrt{|V|}\log{|V|})$.
Exploring Deep Learning for Joint Audio-Visual Lip Biometrics
Apr 17, 2021
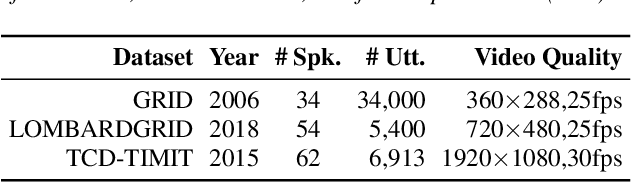
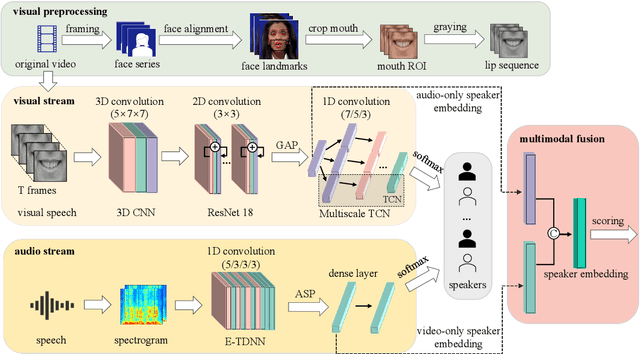

Audio-visual (AV) lip biometrics is a promising authentication technique that leverages the benefits of both the audio and visual modalities in speech communication. Previous works have demonstrated the usefulness of AV lip biometrics. However, the lack of a sizeable AV database hinders the exploration of deep-learning-based audio-visual lip biometrics. To address this problem, we compile a moderate-size database using existing public databases. Meanwhile, we establish the DeepLip AV lip biometrics system realized with a convolutional neural network (CNN) based video module, a time-delay neural network (TDNN) based audio module, and a multimodal fusion module. Our experiments show that DeepLip outperforms traditional speaker recognition models in context modeling and achieves over 50% relative improvements compared with our best single modality baseline, with an equal error rate of 0.75% and 1.11% on the test datasets, respectively.
Kernel Thinning
May 12, 2021
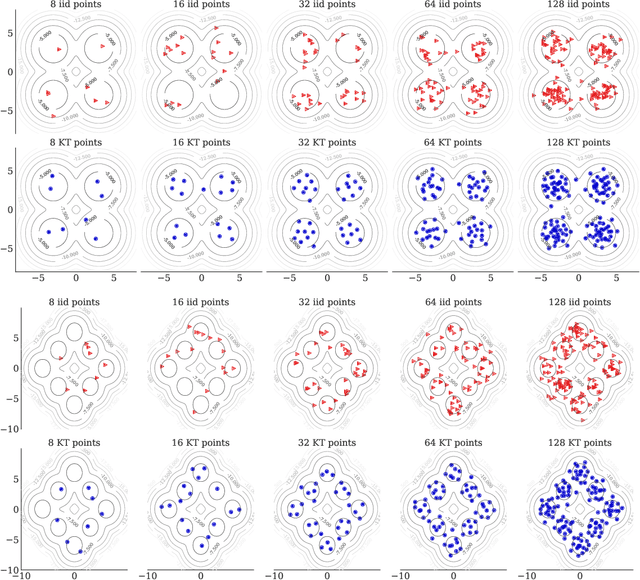
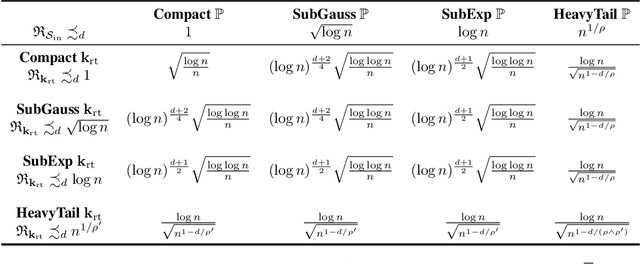
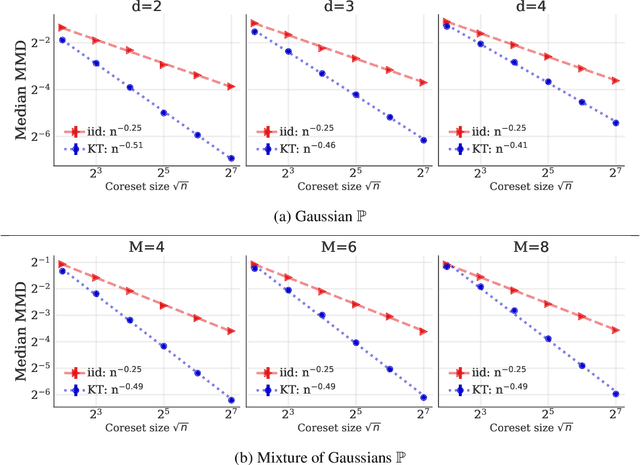
We introduce kernel thinning, a simple algorithm for generating better-than-Monte-Carlo approximations to distributions $\mathbb{P}$ on $\mathbb{R}^d$. Given $n$ input points, a suitable reproducing kernel $\mathbf{k}$, and $\mathcal{O}(n^2)$ time, kernel thinning returns $\sqrt{n}$ points with comparable integration error for every function in the associated reproducing kernel Hilbert space. With high probability, the maximum discrepancy in integration error is $\mathcal{O}_d(n^{-\frac{1}{2}}\sqrt{\log n})$ for compactly supported $\mathbb{P}$ and $\mathcal{O}_d(n^{-\frac{1}{2}} \sqrt{(\log n)^{d+1}\log\log n})$ for sub-exponential $\mathbb{P}$. In contrast, an equal-sized i.i.d. sample from $\mathbb{P}$ suffers $\Omega(n^{-\frac14})$ integration error. Our sub-exponential guarantees resemble the classical quasi-Monte Carlo error rates for uniform $\mathbb{P}$ on $[0,1]^d$ but apply to general distributions on $\mathbb{R}^d$ and a wide range of common kernels. We use our results to derive explicit non-asymptotic maximum mean discrepancy bounds for Gaussian, Mat\'ern, and B-spline kernels and present two vignettes illustrating the practical benefits of kernel thinning over i.i.d. sampling and standard Markov chain Monte Carlo thinning.
Swarm Herding: A Leader-Follower Framework For Multi-Robot Navigation
Jan 19, 2021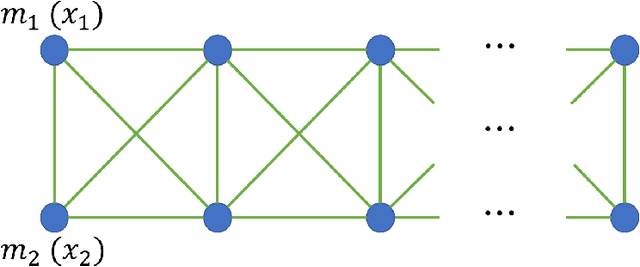
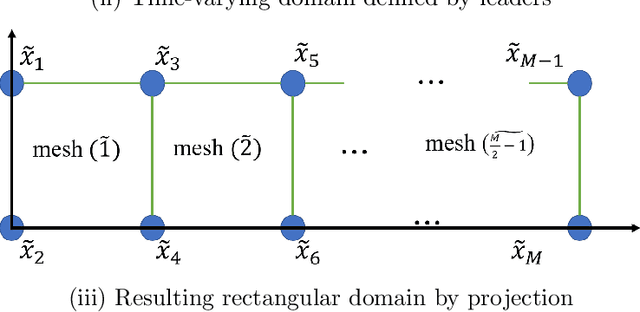

A leader-follower framework is proposed for multi-robot navigation of large scale teams where the leader agents corral the follower agents. A group of leaders is modeled as a 2D deformable object where discrete masses (i.e., leader robots) are interconnected by springs and dampers. A time-varying domain is defined by the positions of leaders while the external forces induce deformations of the domain from its nominal configuration. The team of followers is performing coverage over the time-varying domain by employing a perspective transformation that maps between the nominal and deformed configurations. A decentralized control strategy is proposed where a leader only takes local sensing information and information about its neighbors (connected by virtual springs and dampers), and a follower only needs partial information about leaders and information about its Delaunay neighbors.