 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How do Voices from Past Speech Synthesis Challenges Compare Today?
May 05, 2021
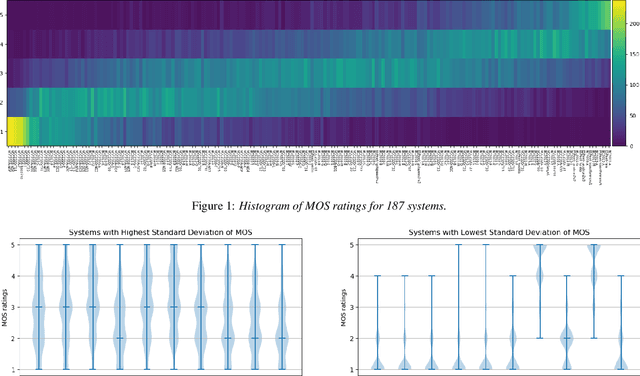
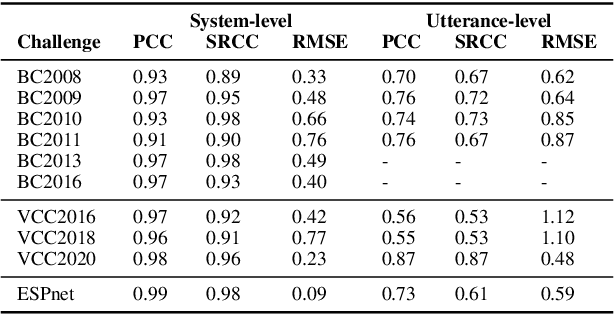

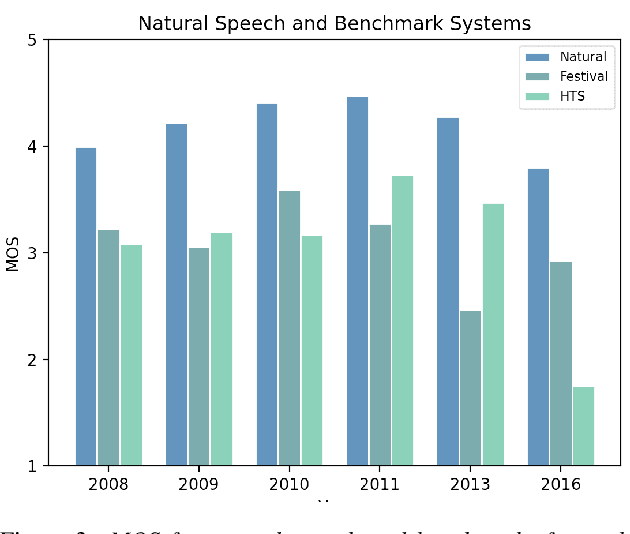
Shared challenges provide a venue for comparing systems trained on common data using a standardized evaluation, and they also provide an invaluable resource for researchers when the data and evaluation results are publicly released. The Blizzard Challenge and Voice Conversion Challenge are two such challenges for text-to-speech synthesis and for speaker conversion, respectively, and their publicly-available system samples and listening test results comprise a historical record of state-of-the-art synthesis methods over the years. In this paper, we revisit these past challenges and conduct a large-scale listening test with samples from many challenges combined. Our aims are to analyze and compare opinions of a large number of systems together, to determine whether and how opinions change over time, and to collect a large-scale dataset of a diverse variety of synthetic samples and their ratings for further research. We found strong correlations challenge by challenge at the system level between the original results and our new listening test. We also observed the importance of the choice of speaker on synthesis quality.
Controlling earthquake-like instabilities using artificial intelligence
Apr 27, 2021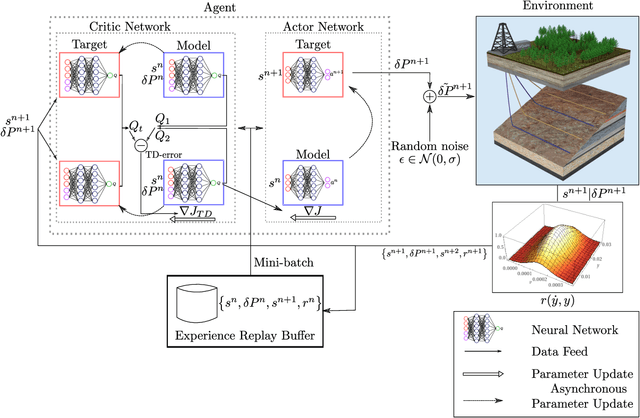
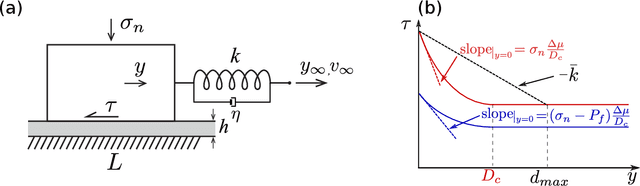
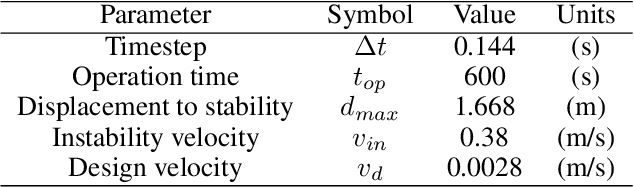
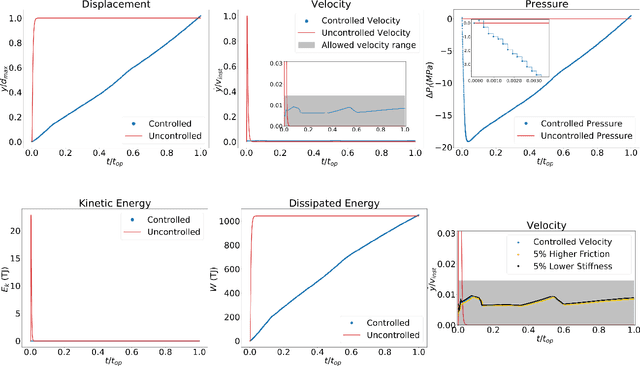
Earthquakes are lethal and costly. This study aims at avoiding these catastrophic events by the application of injection policies retrieved through reinforcement learning. With the rapid growth of artificial intelligence, prediction-control problems are all the more tackled by function approximation models that learn how to control a specific task, even for systems with unmodeled/unknown dynamics and important uncertainties. Here, we show for the first time the possibility of controlling earthquake-like instabilities using state-of-the-art deep reinforcement learning techniques. The controller is trained using a reduced model of the physical system, i.e, the spring-slider model, which embodies the main dynamics of the physical problem for a given earthquake magnitude. Its robustness to unmodeled dynamics is explored through a parametric study. Our study is a first step towards minimizing seismicity in industrial projects (geothermal energy, hydrocarbons production, CO2 sequestration) while, in a second step for inspiring techniques for natural earthquakes control and prevention.
High precision control and deep learning-based corn stand counting algorithms for agricultural robot
Mar 21, 2021
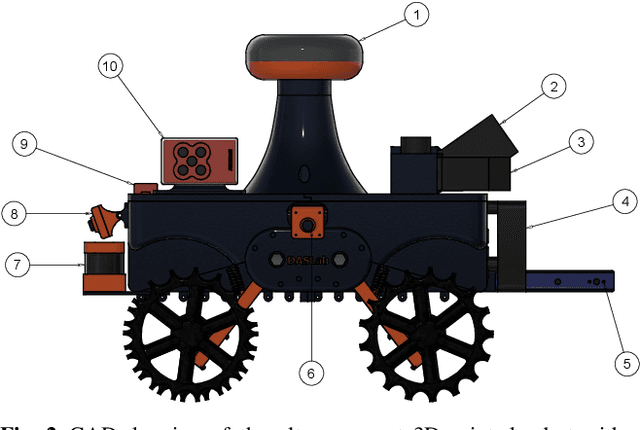
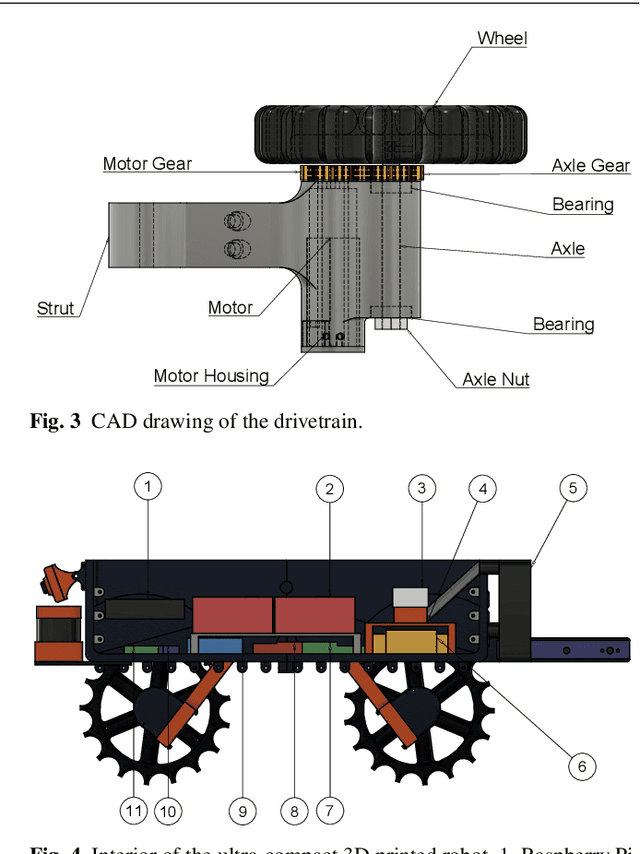
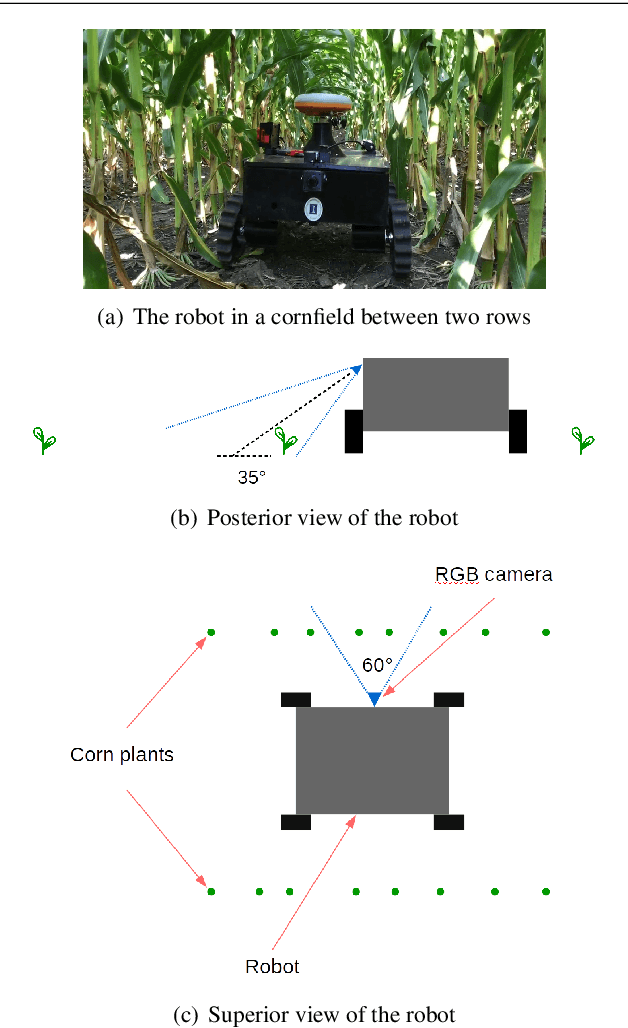
This paper presents high precision control and deep learning-based corn stand counting algorithms for a low-cost, ultra-compact 3D printed and autonomous field robot for agricultural operations. Currently, plant traits, such as emergence rate, biomass, vigor, and stand counting, are measured manually. This is highly labor-intensive and prone to errors. The robot, termed TerraSentia, is designed to automate the measurement of plant traits for efficient phenotyping as an alternative to manual measurements. In this paper, we formulate a Nonlinear Moving Horizon Estimator (NMHE) that identifies key terrain parameters using onboard robot sensors and a learning-based Nonlinear Model Predictive Control (NMPC) that ensures high precision path tracking in the presence of unknown wheel-terrain interaction. Moreover, we develop a machine vision algorithm designed to enable an ultra-compact ground robot to count corn stands by driving through the fields autonomously. The algorithm leverages a deep network to detect corn plants in images, and a visual tracking model to re-identify detected objects at different time steps. We collected data from 53 corn plots in various fields for corn plants around 14 days after emergence (stage V3 - V4). The robot predictions have agreed well with the ground truth with $C_{robot}=1.02 \times C_{human}-0.86$ and a correlation coefficient $R=0.96$. The mean relative error given by the algorithm is $-3.78\%$, and the standard deviation is $6.76\%$. These results indicate a first and significant step towards autonomous robot-based real-time phenotyping using low-cost, ultra-compact ground robots for corn and potentially other crops.
* 14 pages, 9 figures
EiGLasso for Scalable Sparse Kronecker-Sum Inverse Covariance Estimation
May 20, 2021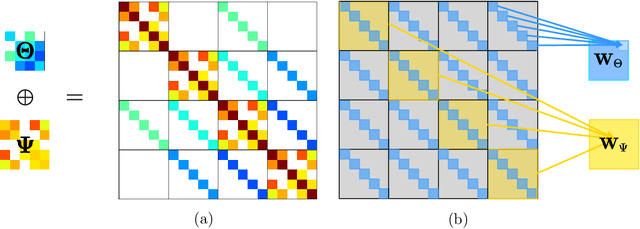
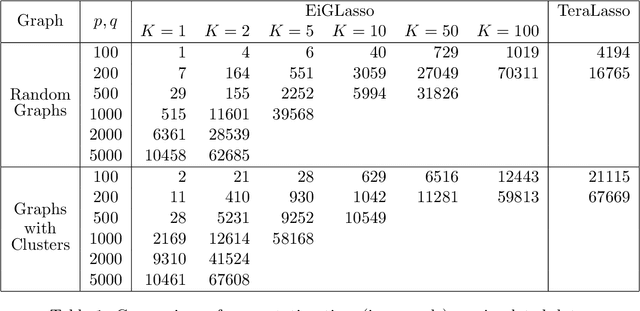
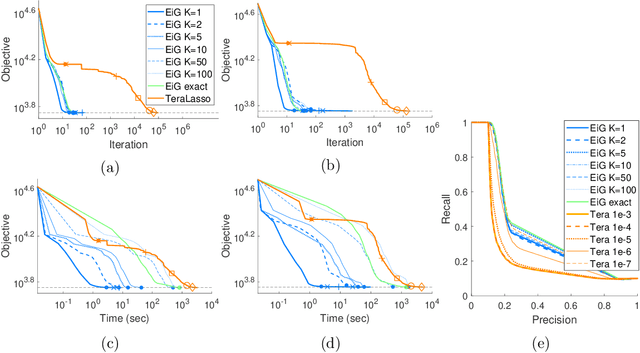
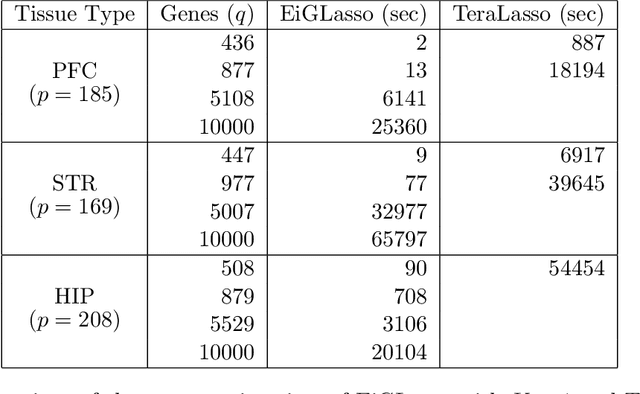
In many real-world problems, complex dependencies are present both among samples and among features. The Kronecker sum or the Cartesian product of two graphs, each modeling dependencies across features and across samples, has been used as an inverse covariance matrix for a matrix-variate Gaussian distribution, as an alternative to a Kronecker-product inverse covariance matrix, due to its more intuitive sparse structure. However, the existing methods for sparse Kronecker-sum inverse covariance estimation are limited in that they do not scale to more than a few hundred features and samples and that the unidentifiable parameters pose challenges in estimation. In this paper, we introduce EiGLasso, a highly scalable method for sparse Kronecker-sum inverse covariance estimation, based on Newton's method combined with eigendecomposition of the two graphs for exploiting the structure of Kronecker sum. EiGLasso further reduces computation time by approximating the Hessian based on the eigendecomposition of the sample and feature graphs. EiGLasso achieves quadratic convergence with the exact Hessian and linear convergence with the approximate Hessian. We describe a simple new approach to estimating the unidentifiable parameters that generalizes the existing methods. On simulated and real-world data, we demonstrate that EiGLasso achieves two to three orders-of-magnitude speed-up compared to the existing methods.
Deep Learning in Multiple Multistep Time Series Prediction
Oct 12, 2017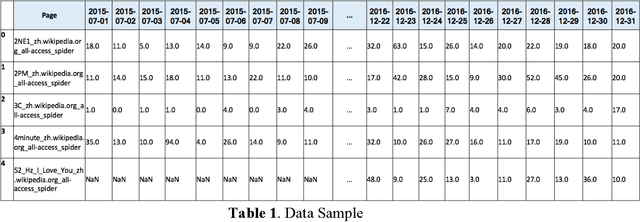
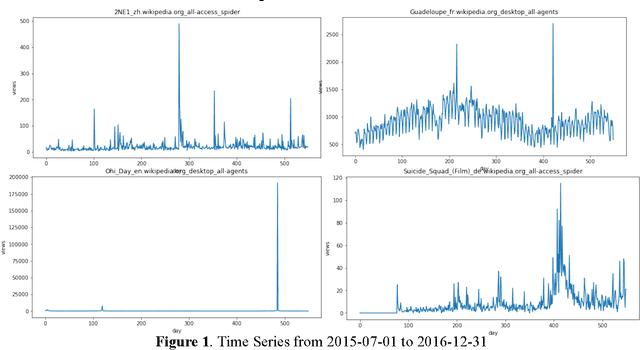
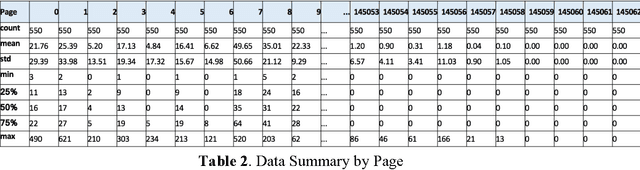
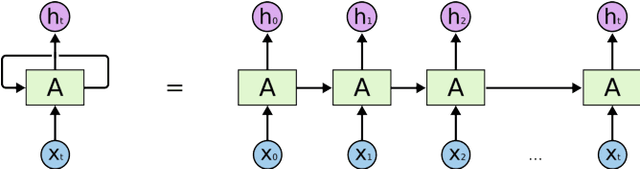
The project aims to research on combining deep learning specifically Long-Short Memory (LSTM) and basic statistics in multiple multistep time series prediction. LSTM can dive into all the pages and learn the general trends of variation in a large scope, while the well selected medians for each page can keep the special seasonality of different pages so that the future trend will not fluctuate too much from the reality. A recent Kaggle competition on 145K Web Traffic Time Series Forecasting [1] is used to thoroughly illustrate and test this idea.
Policy Learning with Adaptively Collected Data
May 05, 2021

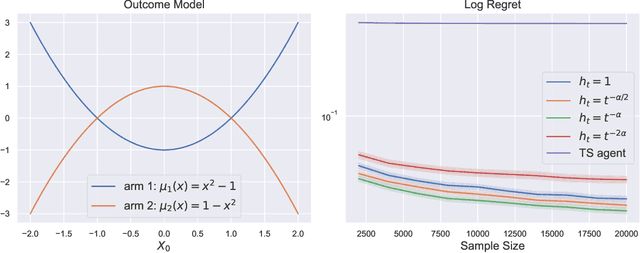

Learning optimal policies from historical data enables the gains from personalization to be realized in a wide variety of applications. The growing policy learning literature focuses on a setting where the treatment assignment policy does not adapt to the data. However, adaptive data collection is becoming more common in practice, from two primary sources: 1) data collected from adaptive experiments that are designed to improve inferential efficiency; 2) data collected from production systems that are adaptively evolving an operational policy to improve performance over time (e.g. contextual bandits). In this paper, we aim to address the challenge of learning the optimal policy with adaptively collected data and provide one of the first theoretical inquiries into this problem. We propose an algorithm based on generalized augmented inverse propensity weighted estimators and establish its finite-sample regret bound. We complement this regret upper bound with a lower bound that characterizes the fundamental difficulty of policy learning with adaptive data. Finally, we demonstrate our algorithm's effectiveness using both synthetic data and public benchmark datasets.
Diversity driven Query Rewriting in Search Advertising
Jun 07, 2021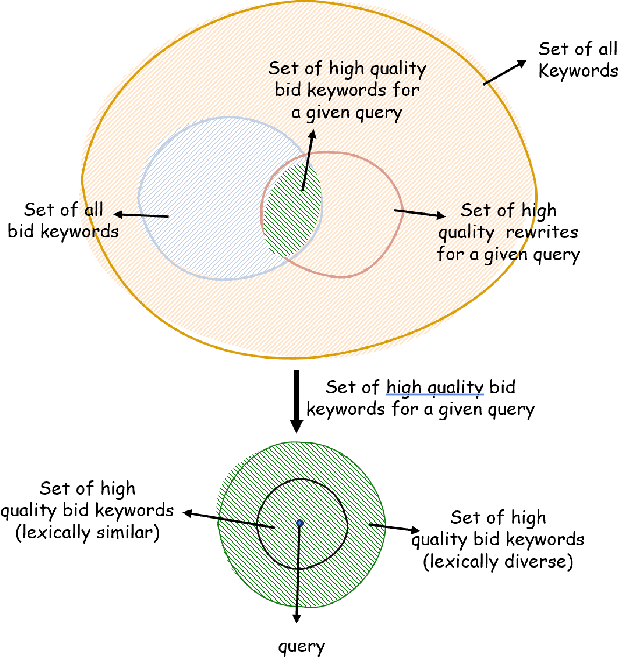

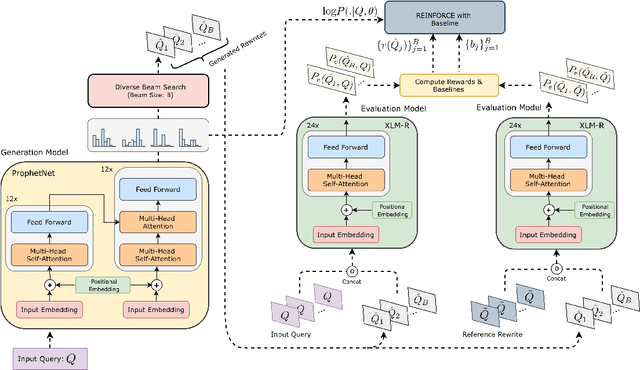
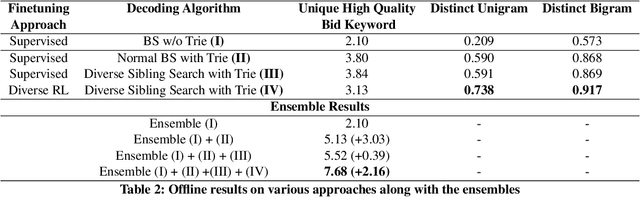
Retrieving keywords (bidwords) with the same intent as query, referred to as close variant keywords, is of prime importance for effective targeted search advertising. For head and torso search queries, sponsored search engines use a huge repository of same intent queries and keywords, mined ahead of time. Online, this repository is used to rewrite the query and then lookup the rewrite in a repository of bid keywords contributing to significant revenue. Recently generative retrieval models have been shown to be effective at the task of generating such query rewrites. We observe two main limitations of such generative models. First, rewrites generated by these models exhibit low lexical diversity, and hence the rewrites fail to retrieve relevant keywords that have diverse linguistic variations. Second, there is a misalignment between the training objective - the likelihood of training data, v/s what we desire - improved quality and coverage of rewrites. In this work, we introduce CLOVER, a framework to generate both high-quality and diverse rewrites by optimizing for human assessment of rewrite quality using our diversity-driven reinforcement learning algorithm. We use an evaluation model, trained to predict human judgments, as the reward function to finetune the generation policy. We empirically show the effectiveness of our proposed approach through offline experiments on search queries across geographies spanning three major languages. We also perform online A/B experiments on Bing, a large commercial search engine, which shows (i) better user engagement with an average increase in clicks by 12.83% accompanied with an average defect reduction by 13.97%, and (ii) improved revenue by 21.29%.
Fisheye Lens Camera based Autonomous Valet Parking System
Apr 27, 2021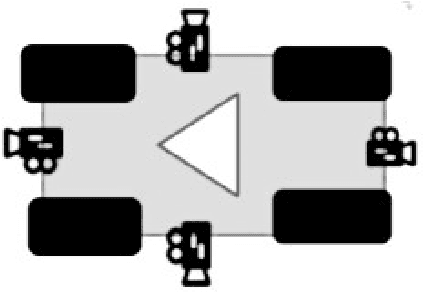



This paper proposes an efficient autonomous valet parking system utilizing only cameras which are the most widely used sensor. To capture more information instantaneously and respond rapidly to changes in the surrounding environment, fisheye cameras which have a wider angle of view compared to pinhole cameras are used. Accordingly, visual simultaneous localization and mapping is used to identify the layout of the parking lot and track the location of the vehicle. In addition, the input image frames are converted into around view monitor images to resolve the distortion of fisheye lens because the algorithm to detect edges are supposed to be applied to images taken with pinhole cameras. The proposed system adopts a look up table for real time operation by minimizing the computational complexity encountered when processing AVM images. The detection rate of each process and the success rate of autonomous parking were measured to evaluate performance. The experimental results confirm that autonomous parking can be achieved using only visual sensors.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
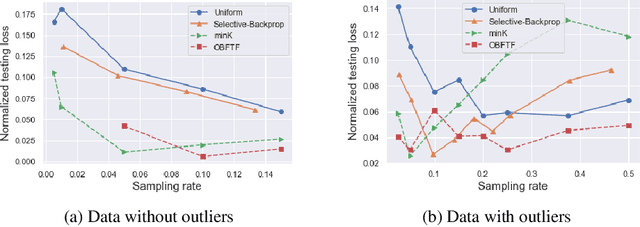

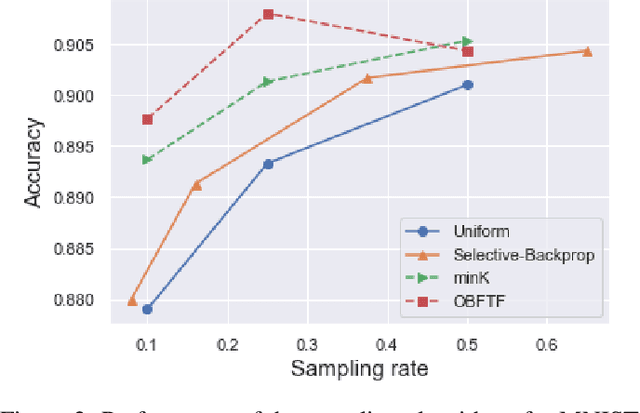
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
Prediction of Dynamical time Series Using Kernel Based Regression and Smooth Splines
Jun 20, 2018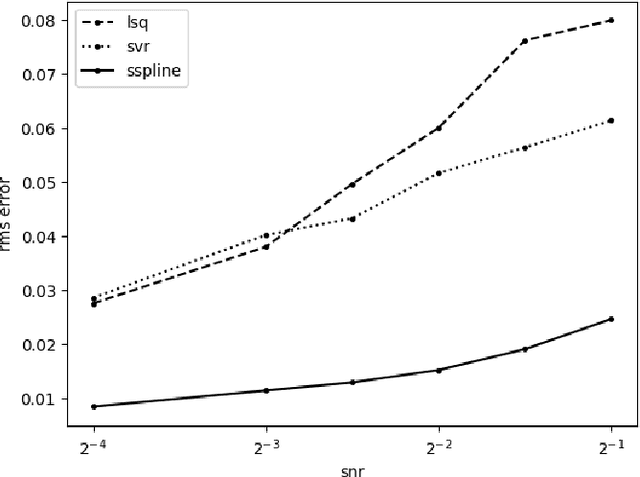
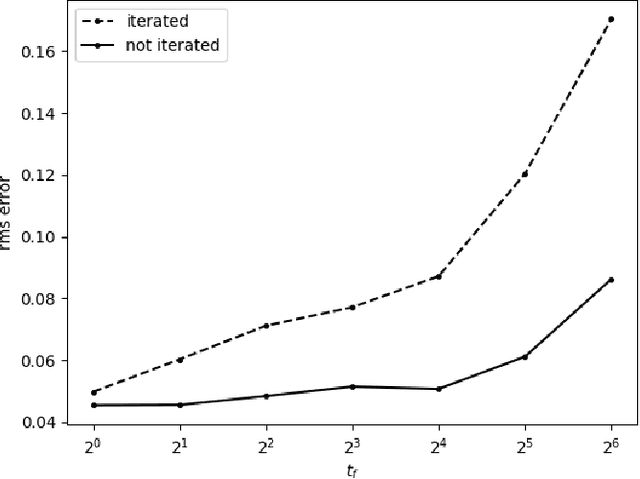
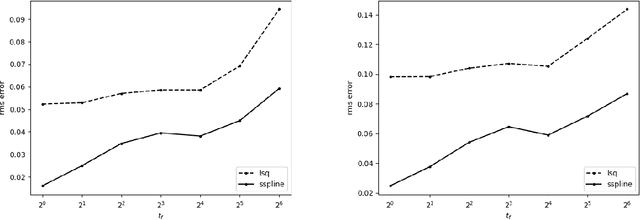
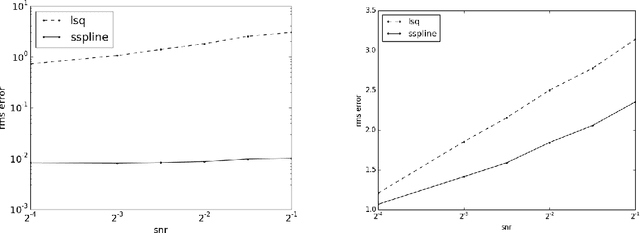
Prediction of dynamical time series with additive noise using support vector machines or kernel based regression has been proved to be consistent for certain classes of discrete dynamical systems. Consistency implies that these methods are effective at computing the expected value of a point at a future time given the present coordinates. However, the present coordinates themselves are noisy, and therefore, these methods are not necessarily effective at removing noise. In this article, we consider denoising and prediction as separate problems for flows, as opposed to discrete time dynamical systems, and show that the use of smooth splines is more effective at removing noise. Combination of smooth splines and kernel based regression yields predictors that are more accurate on benchmarks typically by a factor of 2 or more. We prove that kernel based regression in combination with smooth splines converges to the exact predictor for time series extracted from any compact invariant set of any sufficiently smooth flow. As a consequence of convergence, one can find examples where the combination of kernel based regression with smooth splines is superior by even a factor of $100$. The predictors that we compute operate on delay coordinate data and not the full state vector, which is typically not observable.