 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning interpretable continuous-time models of latent stochastic dynamical systems
Feb 12, 2019
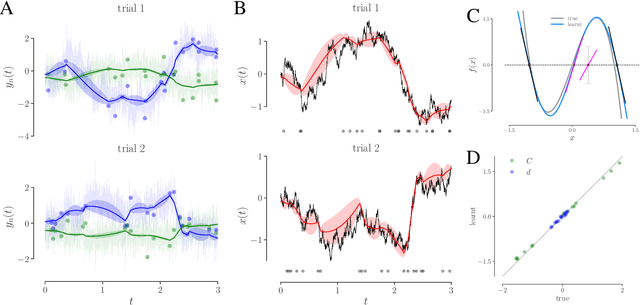
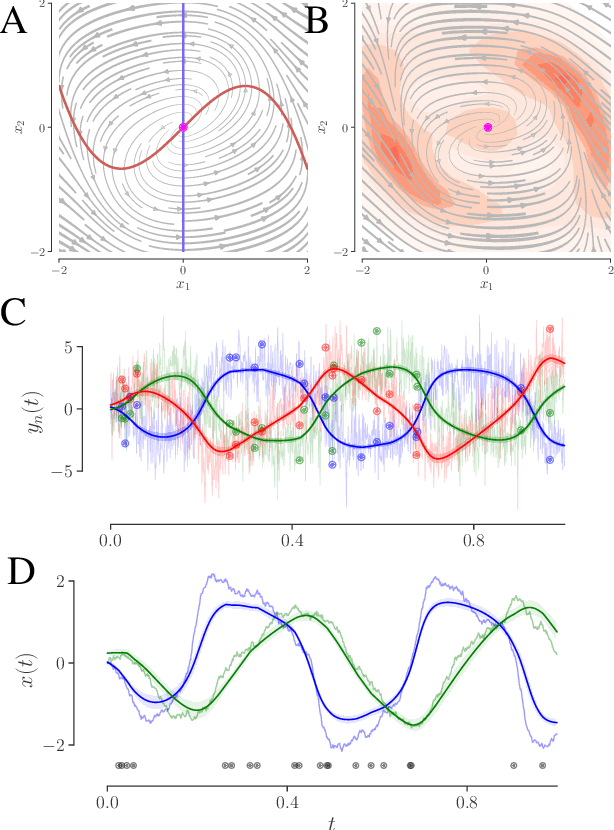
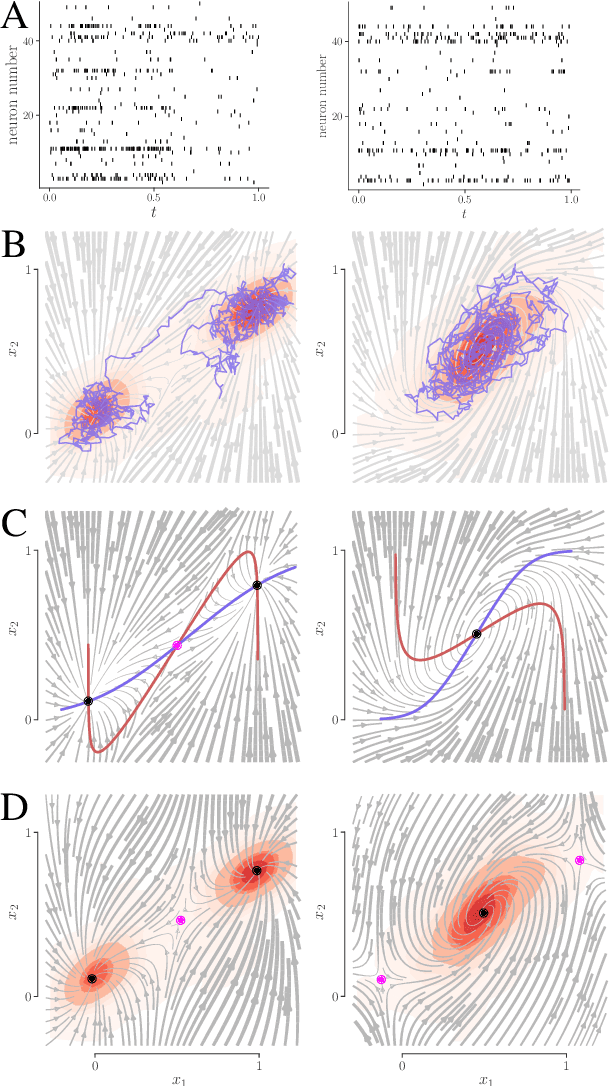
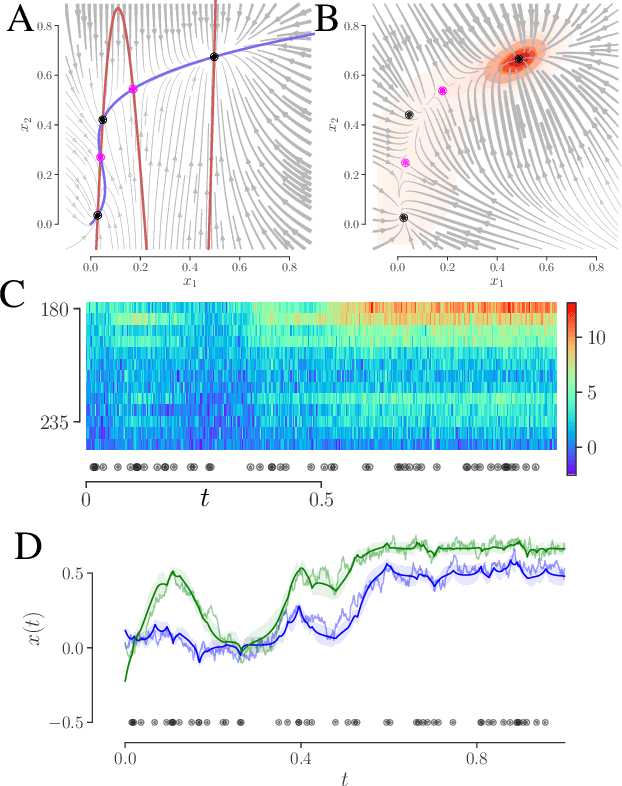
We develop an approach to learn an interpretable semi-parametric model of a latent continuous-time stochastic dynamical system, assuming noisy high-dimensional outputs sampled at uneven times. The dynamics are described by a nonlinear stochastic differential equation (SDE) driven by a Wiener process, with a drift evolution function drawn from a Gaussian process (GP) conditioned on a set of learnt fixed points and corresponding local Jacobian matrices. This form yields a flexible nonparametric model of the dynamics, with a representation corresponding directly to the interpretable portraits routinely employed in the study of nonlinear dynamical systems. The learning algorithm combines inference of continuous latent paths underlying observed data with a sparse variational description of the dynamical process. We demonstrate our approach on simulated data from different nonlinear dynamical systems.
Towards Efficient Compressive Data Collection in the Internet of Things
May 29, 2021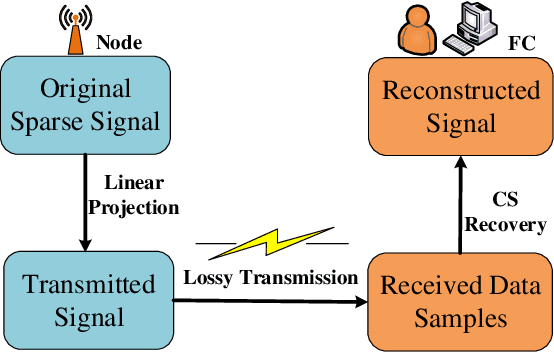
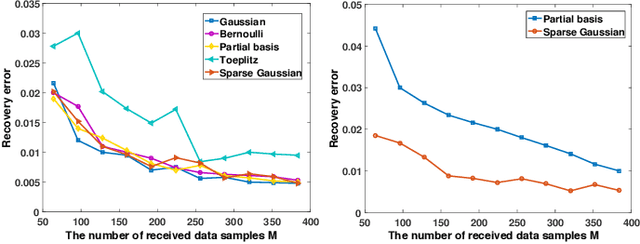
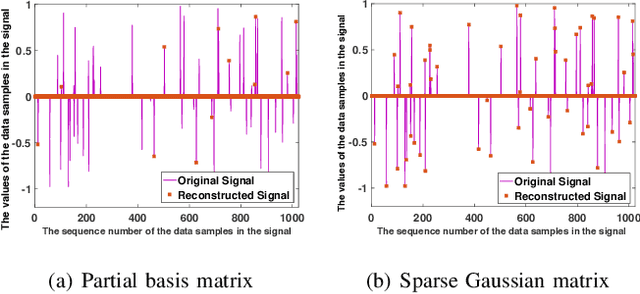
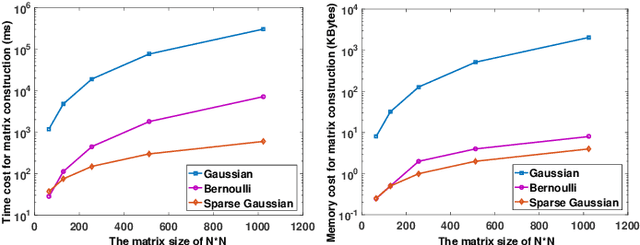
It is of paramount importance to achieve efficient data collection in the Internet of Things (IoT). Due to the inherent structural properties (e.g., sparsity) existing in many signals of interest, compressive sensing (CS) technology has been extensively used for data collection in IoT to improve both accuracy and energy efficiency. Apart from the existing works which leverage CS as a channel coding scheme to deal with data loss during transmission, some recent results have started to employ CS as a source coding strategy. The frequently used projection matrices in these CS-based source coding schemes include dense random matrices (e.g., Gaussian matrices or Bernoulli matrices) and structured matrices (e.g., Toeplitz matrices). However, these matrices are either difficult to be implemented on resource-constrained IoT sensor nodes or have limited applicability. To address these issues, in this paper, we design a novel simple and efficient projection matrix, named sparse Gaussian matrix, which is easy and resource-saving to be implemented in practical IoT applications. We conduct both theoretical analysis and experimental evaluation of the designed sparse Gaussian matrix. The results demonstrate that employing the designed projection matrix to perform CS-based source coding could significantly save time and memory cost while ensuring satisfactory signal recovery performance.
Decentralized Q-Learning in Zero-sum Markov Games
Jun 04, 2021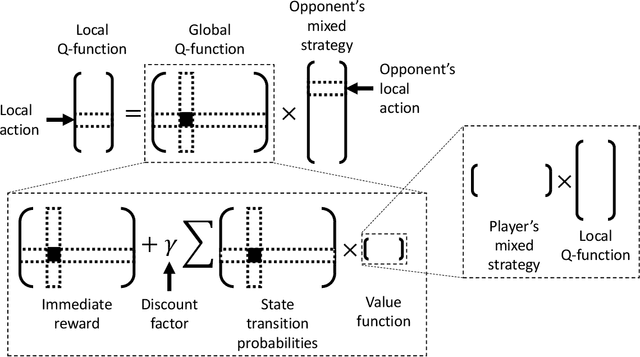
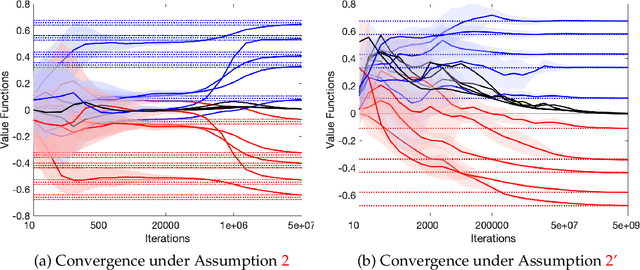
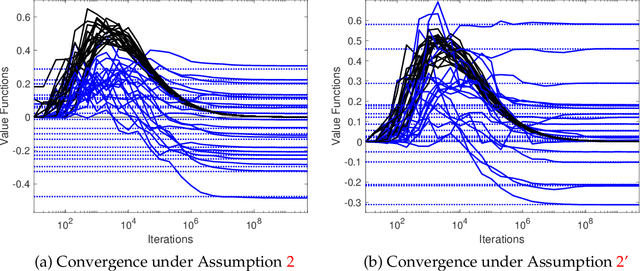
We study multi-agent reinforcement learning (MARL) in infinite-horizon discounted zero-sum Markov games. We focus on the practical but challenging setting of decentralized MARL, where agents make decisions without coordination by a centralized controller, but only based on their own payoffs and local actions executed. The agents need not observe the opponent's actions or payoffs, possibly being even oblivious to the presence of the opponent, nor be aware of the zero-sum structure of the underlying game, a setting also referred to as radically uncoupled in the literature of learning in games. In this paper, we develop for the first time a radically uncoupled Q-learning dynamics that is both rational and convergent: the learning dynamics converges to the best response to the opponent's strategy when the opponent follows an asymptotically stationary strategy; the value function estimates converge to the payoffs at a Nash equilibrium when both agents adopt the dynamics. The key challenge in this decentralized setting is the non-stationarity of the learning environment from an agent's perspective, since both her own payoffs and the system evolution depend on the actions of other agents, and each agent adapts their policies simultaneously and independently. To address this issue, we develop a two-timescale learning dynamics where each agent updates her local Q-function and value function estimates concurrently, with the latter happening at a slower timescale.
SpreadGNN: Serverless Multi-task Federated Learning for Graph Neural Networks
Jun 04, 2021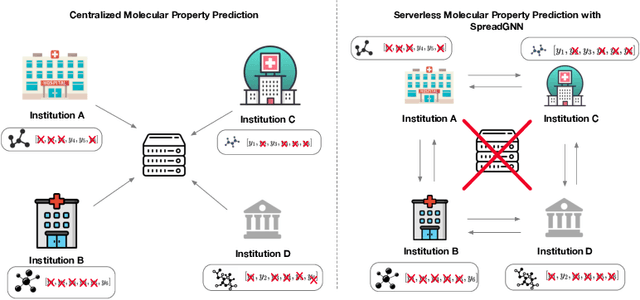
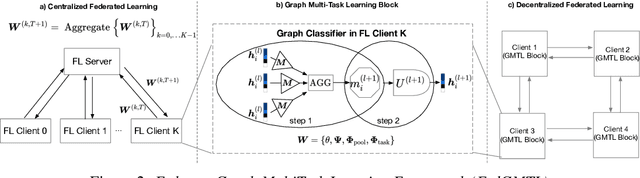
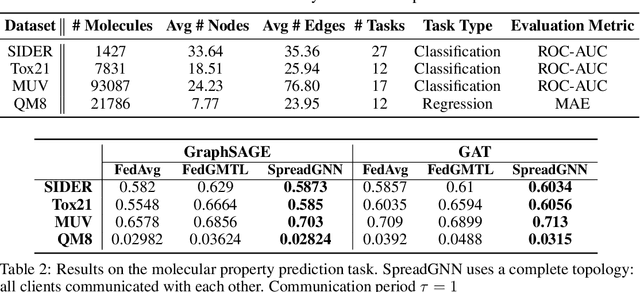
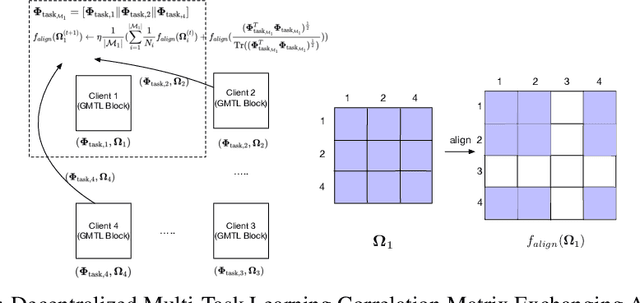
Graph Neural Networks (GNNs) are the first choice methods for graph machine learning problems thanks to their ability to learn state-of-the-art level representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated Learning is the de-facto standard for collaborative training of machine learning models over many distributed edge devices without the need for centralization. Nevertheless, training graph neural networks in a federated setting is vaguely defined and brings statistical and systems challenges. This work proposes SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. SpreadGNN extends federated multi-task learning to realistic serverless settings for GNNs, and utilizes a novel optimization algorithm with a convergence guarantee, Decentralized Periodic Averaging SGD (DPA-SGD), to solve decentralized multi-task learning problems. We empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. Our results show that SpreadGNN outperforms GNN models trained over a central server-dependent federated learning system, even in constrained topologies. The source code is publicly available at https://github.com/FedML-AI/SpreadGNN
Converting ADMM to a Proximal Gradient for Convex Optimization Problems
Apr 22, 2021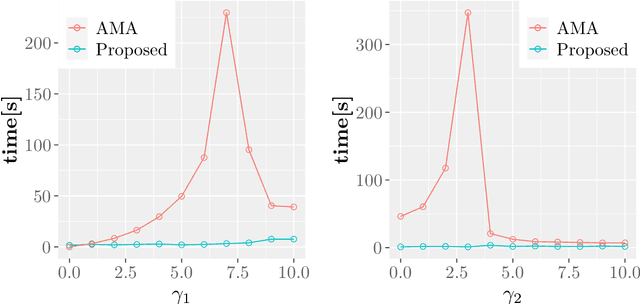
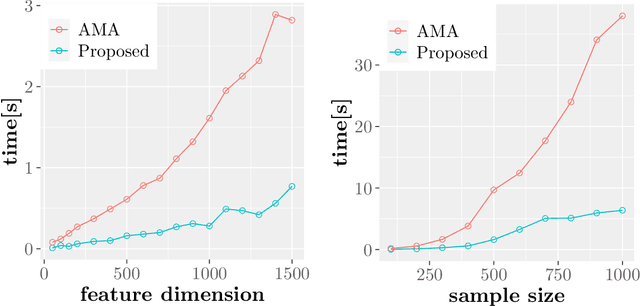
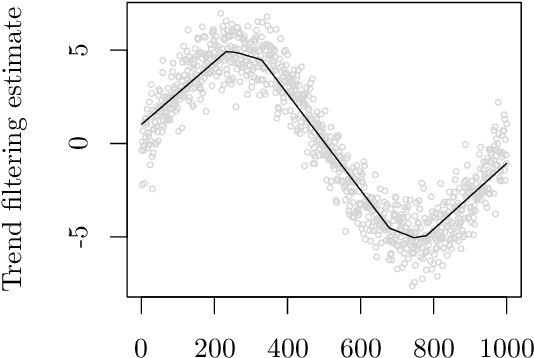
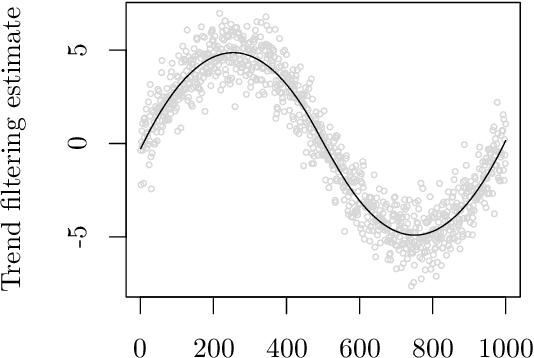
In machine learning and data science, we often consider efficiency for solving problems. In sparse estimation, such as fused lasso and convex clustering, we apply either the proximal gradient method or the alternating direction method of multipliers (ADMM) to solve the problem. It takes time to include matrix division in the former case, while an efficient method such as FISTA (fast iterative shrinkage-thresholding algorithm) has been developed in the latter case. This paper proposes a general method for converting the ADMM solution to the proximal gradient method, assuming that the constraints and objectives are strongly convex. Then, we apply it to sparse estimation problems, such as sparse convex clustering and trend filtering, and we show by numerical experiments that we can obtain a significant improvement in terms of efficiency.
Chord Recognition- Music and Audio Information Retrieval
May 14, 2021
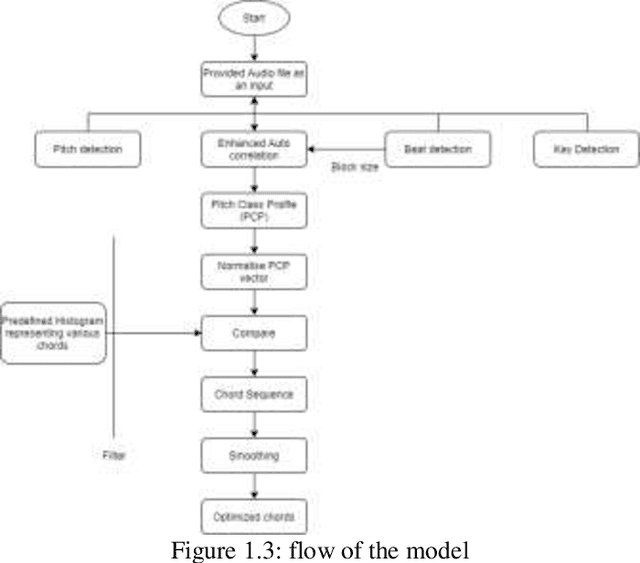
Music Information Retrieval (MIR) is a collaborative scientific study that help to build innovative information research themes, novel frameworks, and developing connected delivery mechanisms in addition to making the world's massive collection of music open for everyone. Modern rock music proved to be difficult to estimate tempo and chord recognition did not work. All of the findings indicate that modern rock and metal music can be analysed, despite its complexity, but that further research is needed in this area to make it useful. Using a neural network has been one of the simplest ways of dealing with it. The pitch class profile vector is used in the neural network method. Because the vector only contains 12 elements of semi-tone values, it is enough for chord recognition. Of course, there are other ways of achieving this work, most of them depend on pitch class profiling to transform the chord into a type that can be recognised, but the recognition process is time-consuming centred on extremely complicated and memory-intensive methods.
Safely Probabilistically Complete Real-Time Planning and Exploration in Unknown Environments
Mar 07, 2019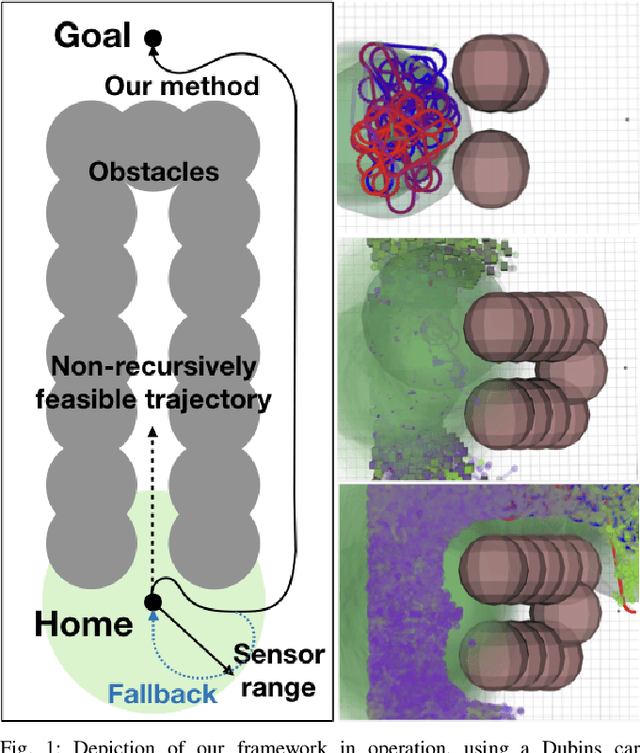
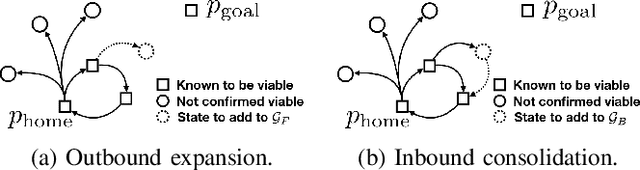
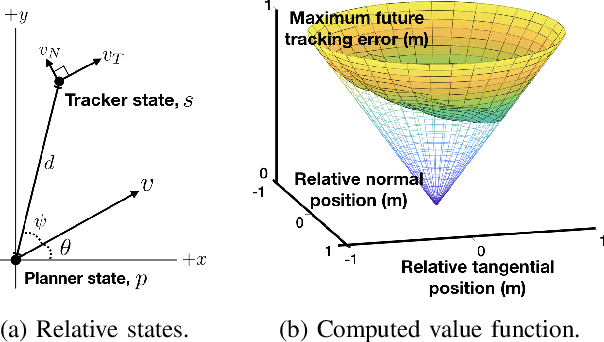
We present a new framework for motion planning that wraps around existing kinodynamic planners and guarantees recursive feasibility when operating in a priori unknown, static environments. Our approach makes strong guarantees about overall safety and collision avoidance by utilizing a robust controller derived from reachability analysis. We ensure that motion plans never exit the safe backward reachable set of the initial state, while safely exploring the space. This preserves the safety of the initial state, and guarantees that that we will eventually find the goal if it is possible to do so while exploring safely. We implement our framework in the Robot Operating System (ROS) software environment and demonstrate it in a real-time simulation.
Forecasting Across Time Series Databases using Recurrent Neural Networks on Groups of Similar Series: A Clustering Approach
Sep 12, 2018
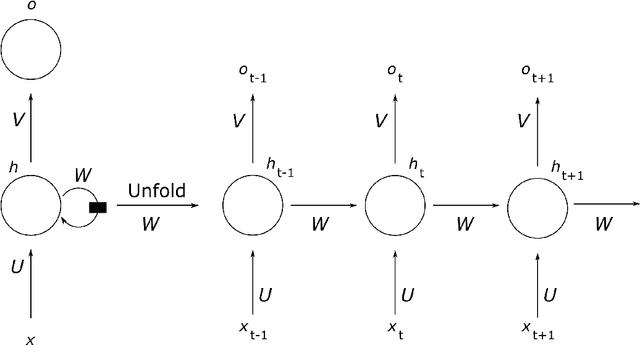
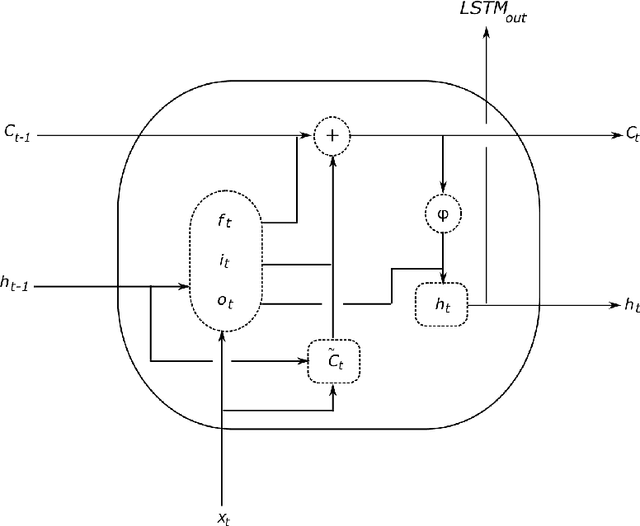
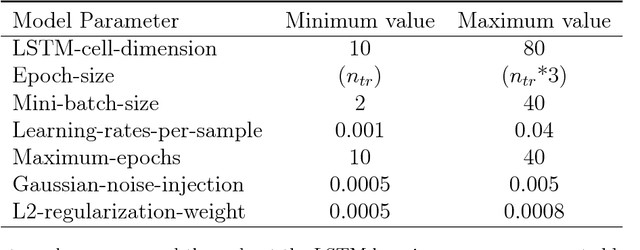
With the advent of Big Data, nowadays in many applications databases containing large quantities of similar time series are available. Forecasting time series in these domains with traditional univariate forecasting procedures leaves great potentials for producing accurate forecasts untapped. Recurrent neural networks (RNNs), and in particular Long Short-Term Memory (LSTM) networks, have proven recently that they are able to outperform state-of-the-art univariate time series forecasting methods in this context when trained across all available time series. However, if the time series database is heterogeneous, accuracy may degenerate, so that on the way towards fully automatic forecasting methods in this space, a notion of similarity between the time series needs to be built into the methods. To this end, we present a prediction model that can be used with different types of RNN models on subgroups of similar time series, which are identified by time series clustering techniques. We assess our proposed methodology using LSTM networks, a widely popular RNN variant. Our method achieves competitive results on benchmarking datasets under competition evaluation procedures. In particular, in terms of mean sMAPE accuracy, it consistently outperforms the baseline LSTM model and outperforms all other methods on the CIF2016 forecasting competition dataset.
Distributed motion coordination for multi-robot systems under LTL specifications
Mar 16, 2021This paper investigates the online motion coordination problem for a group of mobile robots moving in a shared workspace, each of which is assigned a linear temporal logic specification. Based on the realistic assumptions that each robot is subject to both state and input constraints and can have only local view and local information, a fully distributed multi-robot motion coordination strategy is proposed. For each robot, the motion coordination strategy consists of three layers. An offline layer pre-computes the braking area for each region in the workspace, the controlled transition system, and a so-called potential function. An initialization layer outputs an initially safely satisfying trajectory. An online coordination layer resolves conflicts when one occurs. The online coordination layer is further decomposed into three steps. Firstly, a conflict detection algorithm is implemented, which detects conflicts with neighboring robots. Whenever conflicts are detected, a rule is designed to assign dynamically a planning order to each pair of neighboring robots. Finally, a sampling-based algorithm is designed to generate local collision-free trajectories for the robot which at the same time guarantees the feasibility of the specification. Safety is proven to be guaranteed for all robots at any time. The effectiveness and the computational tractability of the resulting solution is verified numerically by two case studies.
Associating Objects with Transformers for Video Object Segmentation
Jun 04, 2021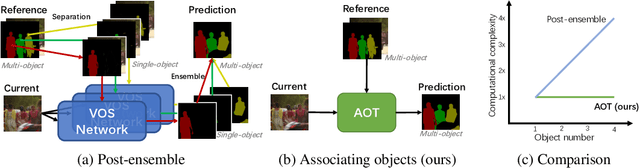
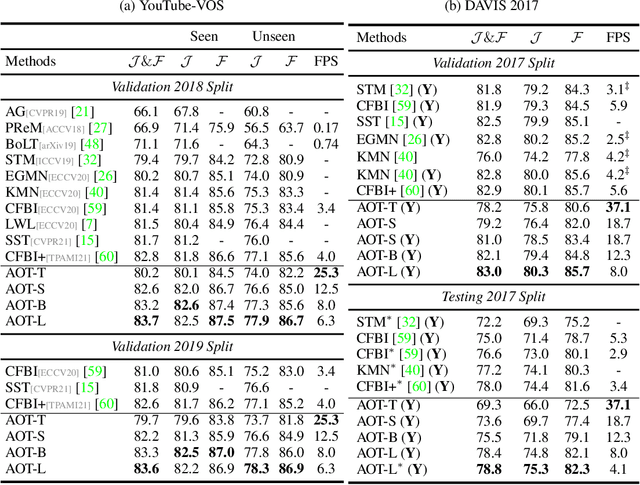
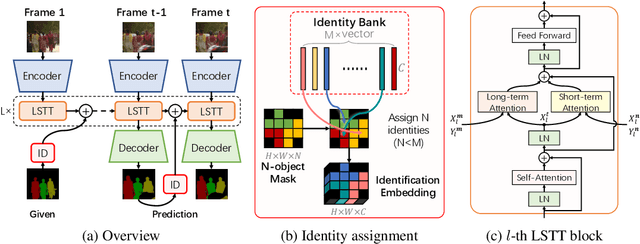
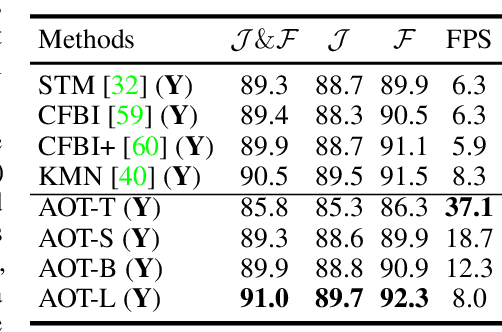
This paper investigates how to realize better and more efficient embedding learning to tackle the semi-supervised video object segmentation under challenging multi-object scenarios. The state-of-the-art methods learn to decode features with a single positive object and thus have to match and segment each target separately under multi-object scenarios, consuming multiple times computing resources. To solve the problem, we propose an Associating Objects with Transformers (AOT) approach to match and decode multiple objects uniformly. In detail, AOT employs an identification mechanism to associate multiple targets into the same high-dimensional embedding space. Thus, we can simultaneously process the matching and segmentation decoding of multiple objects as efficiently as processing a single object. For sufficiently modeling multi-object association, a Long Short-Term Transformer is designed for constructing hierarchical matching and propagation. We conduct extensive experiments on both multi-object and single-object benchmarks to examine AOT variant networks with different complexities. Particularly, our AOT-L outperforms all the state-of-the-art competitors on three popular benchmarks, i.e., YouTube-VOS (83.7% J&F), DAVIS 2017 (83.0%), and DAVIS 2016 (91.0%), while keeping better multi-object efficiency. Meanwhile, our AOT-T can maintain real-time multi-object speed on above benchmarks. We ranked 1st in the 3rd Large-scale Video Object Segmentation Challenge. The code will be publicly available at https://github.com/z-x-yang/AOT.