 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explaining Credit Risk Scoring through Feature Contribution Alignment with Expert Risk Analysts
Mar 15, 2021
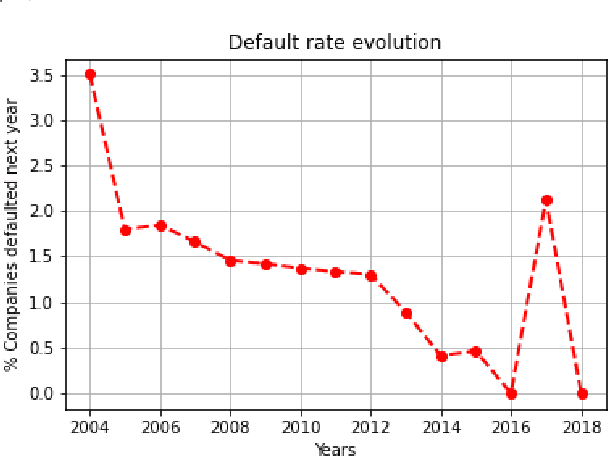
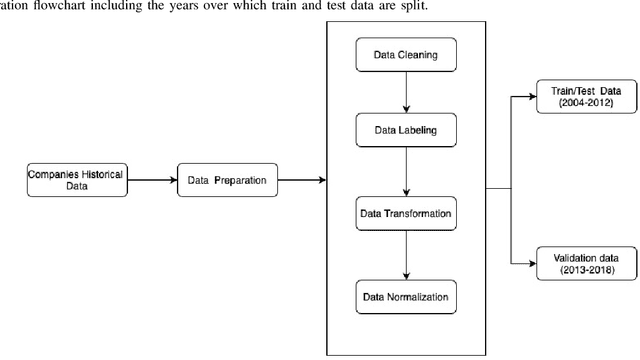
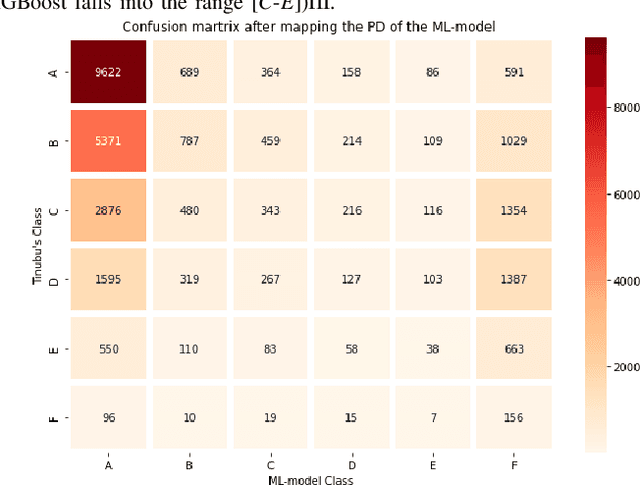
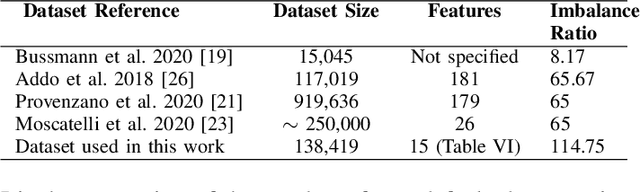
Credit assessments activities are essential for financial institutions and allow the global economy to grow. Building robust, solid and accurate models that estimate the probability of a default of a company is mandatory for credit insurance companies, moreover when it comes to bridging the trade finance gap. Automating the risk assessment process will allow credit risk experts to reduce their workload and focus on the critical and complex cases, as well as to improve the loan approval process by reducing the time to process the application. The recent developments in Artificial Intelligence are offering new powerful opportunities. However, most AI techniques are labelled as blackbox models due to their lack of explainability. For both users and regulators, in order to deploy such technologies at scale, being able to understand the model logic is a must to grant accurate and ethical decision making. In this study, we focus on companies credit scoring and we benchmark different machine learning models. The aim is to build a model to predict whether a company will experience financial problems in a given time horizon. We address the black box problem using eXplainable Artificial Techniques in particular, post-hoc explanations using SHapley Additive exPlanations. We bring light by providing an expert-aligned feature relevance score highlighting the disagreement between a credit risk expert and a model feature attribution explanation in order to better quantify the convergence towards a better human-aligned decision making.
CDSM -- Casual Inference using Deep Bayesian Dynamic Survival Models
Jan 26, 2021
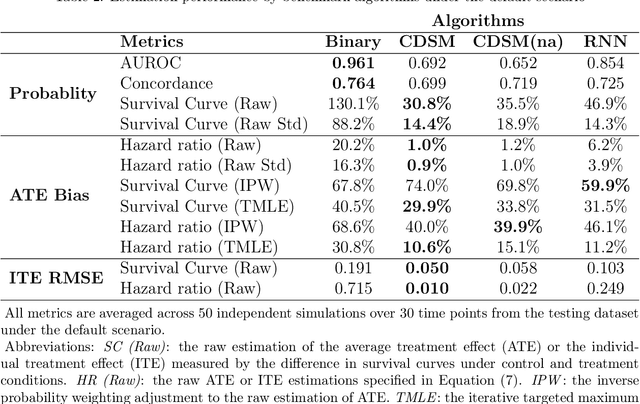
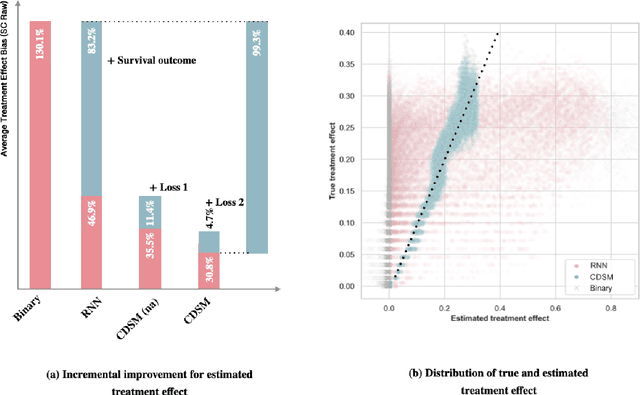
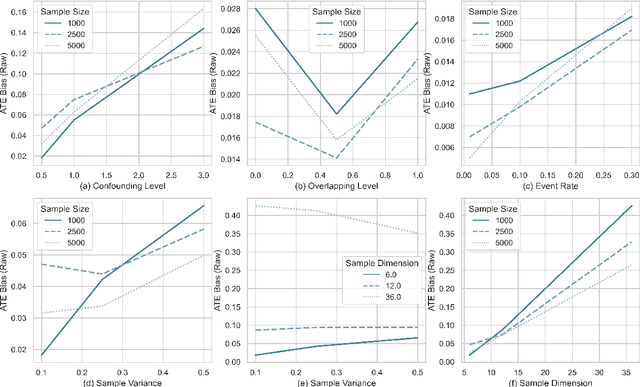
A smart healthcare system that supports clinicians for risk-calibrated treatment assessment typically requires the accurate modeling of time-to-event outcomes. To tackle this sequential treatment effect estimation problem, we developed causal dynamic survival model (CDSM) for causal inference with survival outcomes using longitudinal electronic health record (EHR). CDSM has impressive explanatory performance while maintaining the prediction capability of conventional binary neural network predictors. It borrows the strength from explanatory framework including the survival analysis and counterfactual framework and integrates them with the prediction power from a deep Bayesian recurrent neural network to extract implicit knowledge from EHR data. In two large clinical cohort studies, our model identified the conditional average treatment effect in accordance with previous literature yet detected individual effect heterogeneity over time and patient subgroups. The model provides individualized and clinically interpretable treatment effect estimations to improve patient outcomes.
RFID-based Article-to-Fixture Predictions in Real-World Fashion Stores
May 21, 2021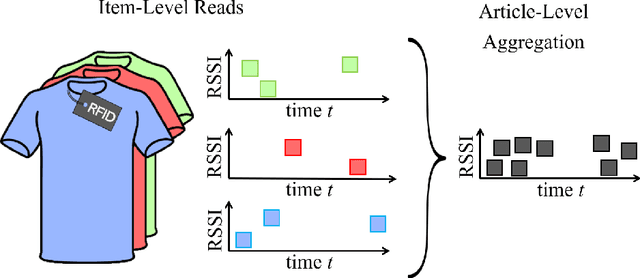

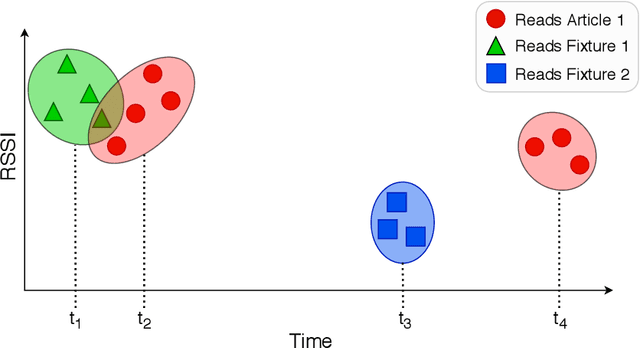

In recent years, Radio Frequency Identification (RFID) technology has been applied to improve numerous processes, such as inventory management in retail stores. However, automatic localization of RFID-tagged goods in stores is still a challenging problem. To address this issue, we equip fixtures (e.g., shelves) with reference tags and use data we collect during RFID-based stocktakes to map articles to fixtures. Knowing the location of goods enables the implementation of several practical applications, such as automated Money Mapping (i.e., a heat map of sales across fixtures). Specifically, we conduct controlled lab experiments and a case-study in two fashion retail stores to evaluate our article-to-fixture prediction approaches. The approaches are based on calculating distances between read event time series using DTW, and clustering of read events using DBSCAN. We find that, read events collected during RFID-based stocktakes can be used to assign articles to fixtures with an accuracy of more than 90%. Additionally, we conduct a pilot to investigate the challenges related to the integration of such a localization system in the day-to-day business of retail stores. Hence, in this paper we present an exploratory venture into novel and practical RFID-based applications in fashion retails stores, beyond the scope of stock management.
Modeling the dynamics of language change: logistic regression, Piotrowski's law, and a handful of examples in Polish
Apr 28, 2021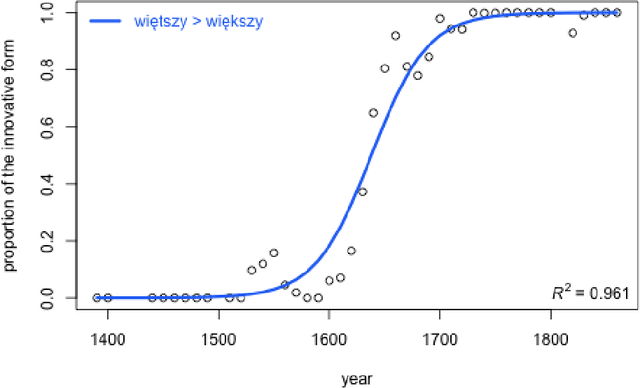

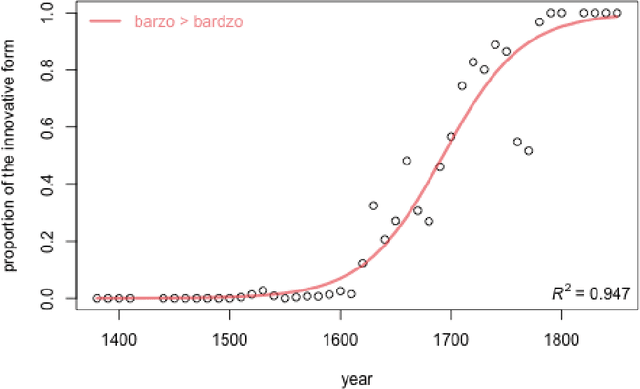
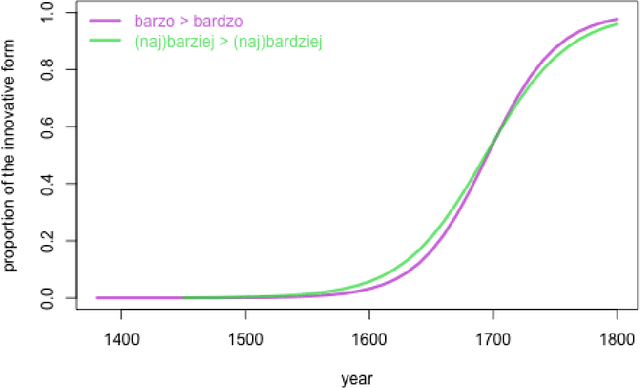
The study discusses modeling diachronic processes by logistic regression. Such an approach was suggested by Raimund Piotrowski (hence labelled as Piotrowski's law), even if actual linguistic evidence usually speaks against using the notion of a "law" in this context. In our study, we apply logistic regression models to 9 changes which occurred between 15th and 18th century in the Polish language. The attested course of the majority of these changes closely follow the expected values, which proves that the language change might indeed resemble a nonlinear phase change scenario. We also extend the original Piotrowski's approach by proposing polynomial logistic regression for these cases which can hardly be described by its standard version. Also, we propose to consider individual language change cases jointly, in order to inspect their possible collinearity or, more likely, their different dynamics in the function of time. Last but not least, we evaluate our results by testing the influence of the subcorpus size on the model's goodness-of-fit.
Distilling Knowledge via Knowledge Review
Apr 19, 2021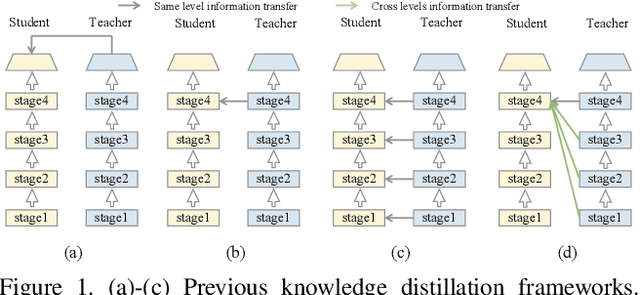
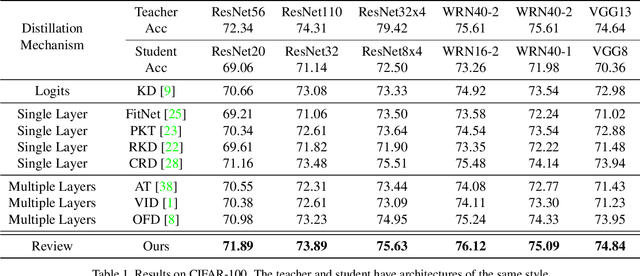
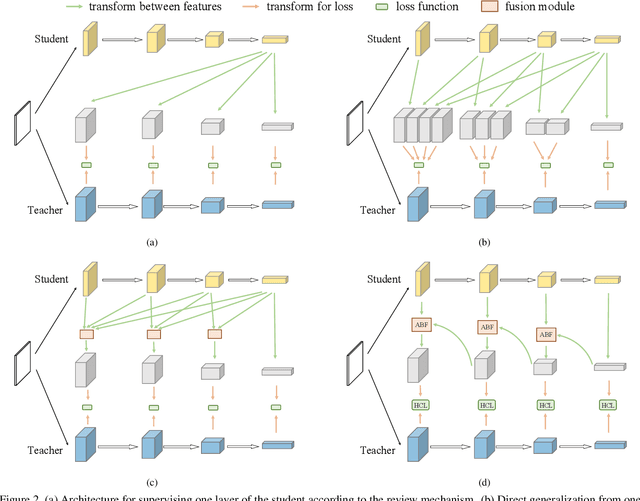
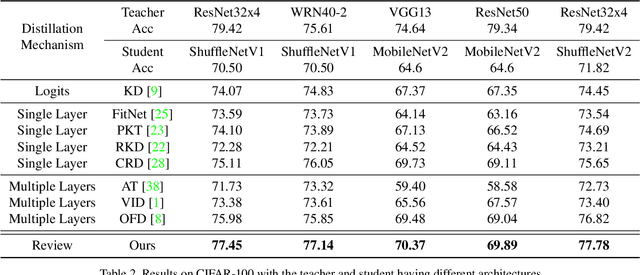
Knowledge distillation transfers knowledge from the teacher network to the student one, with the goal of greatly improving the performance of the student network. Previous methods mostly focus on proposing feature transformation and loss functions between the same level's features to improve the effectiveness. We differently study the factor of connection path cross levels between teacher and student networks, and reveal its great importance. For the first time in knowledge distillation, cross-stage connection paths are proposed. Our new review mechanism is effective and structurally simple. Our finally designed nested and compact framework requires negligible computation overhead, and outperforms other methods on a variety of tasks. We apply our method to classification, object detection, and instance segmentation tasks. All of them witness significant student network performance improvement. Code is available at https://github.com/Jia-Research-Lab/ReviewKD
Density-Ratio Based Personalised Ranking from Implicit Feedback
Jan 19, 2021
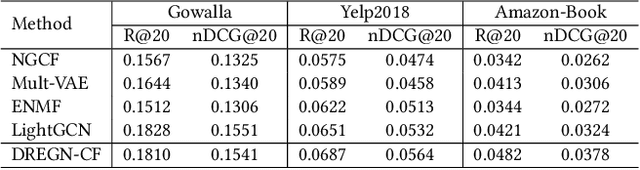
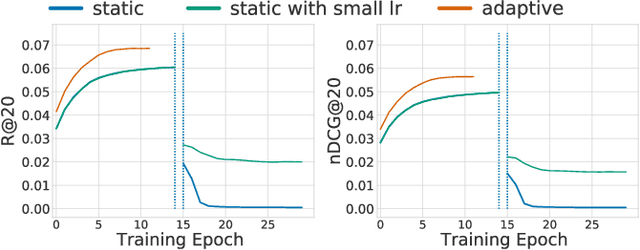
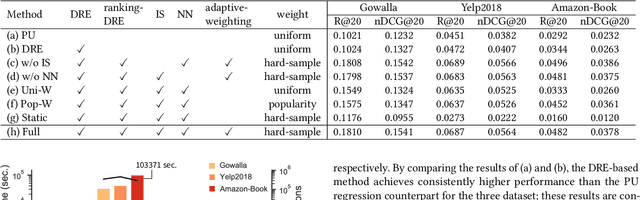
Learning from implicit user feedback is challenging as we can only observe positive samples but never access negative ones. Most conventional methods cope with this issue by adopting a pairwise ranking approach with negative sampling. However, the pairwise ranking approach has a severe disadvantage in the convergence time owing to the quadratically increasing computational cost with respect to the sample size; it is problematic, particularly for large-scale datasets and complex models such as neural networks. By contrast, a pointwise approach does not directly solve a ranking problem, and is therefore inferior to a pairwise counterpart in top-K ranking tasks; however, it is generally advantageous in regards to the convergence time. This study aims to establish an approach to learn personalised ranking from implicit feedback, which reconciles the training efficiency of the pointwise approach and ranking effectiveness of the pairwise counterpart. The key idea is to estimate the ranking of items in a pointwise manner; we first reformulate the conventional pointwise approach based on density ratio estimation and then incorporate the essence of ranking-oriented approaches (e.g. the pairwise approach) into our formulation. Through experiments on three real-world datasets, we demonstrate that our approach not only dramatically reduces the convergence time (one to two orders of magnitude faster) but also significantly improving the ranking performance.
Bi-direction Context Propagation Network for Real-time Semantic Segmentation
Jun 02, 2020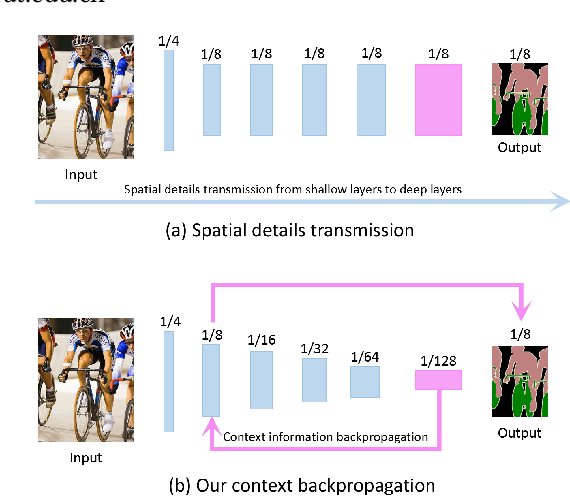
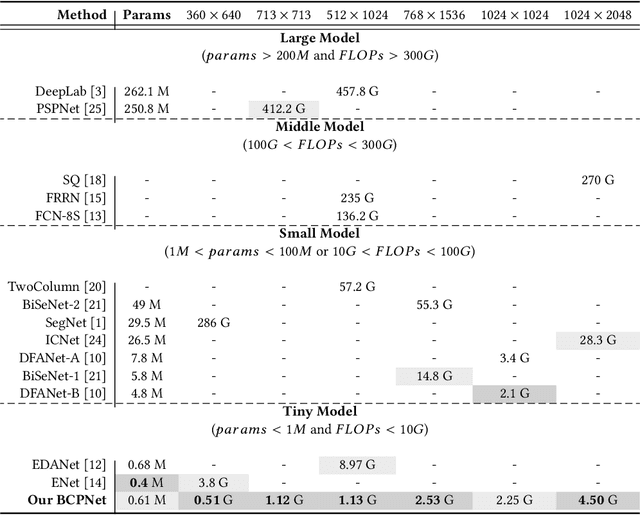
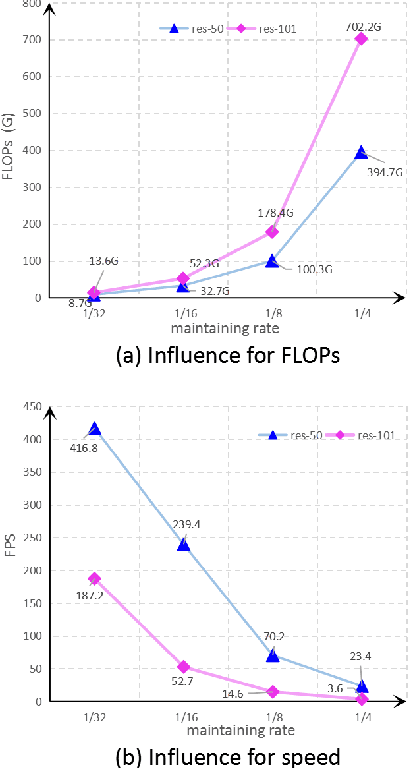

Spatial details and context correlations are two types of important information for semantic segmentation. Generally, shallow layers tend to contain more spatial details, while deep layers are rich in context correlations. Aiming to keep both advantages, most of current methods choose to forward-propagate the spatial details from shallow layers to deep layers, which is computationally expensive and substantially lowers the model's execution speed. To address this problem, we propose the Bi-direction Context Propagation Network (BCPNet) by leveraging both spatial and context information. Different from the previous methods, our BCPNet builds bi-directional paths in its network architecture, allowing the backward context propagation and the forward spatial detail propagation simultaneously. Moreover, all the components in the network are kept lightweight. Extensive experiments show that our BCPNet has achieved a good balance between accuracy and speed. For accuracy, our BCPNet has achieved 68.4 \% mIoU on the Cityscapes test set and 67.8 \% mIoU on the CamVid test set. For speed, our BCPNet can achieve 585.9 FPS (or 1.7 ms runtime per image) at $360 \times 640$ size based on a GeForce GTX TITAN X GPU card.
Times Series Forecasting for Urban Building Energy Consumption Based on Graph Convolutional Network
May 27, 2021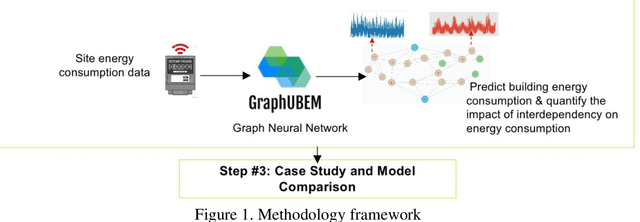

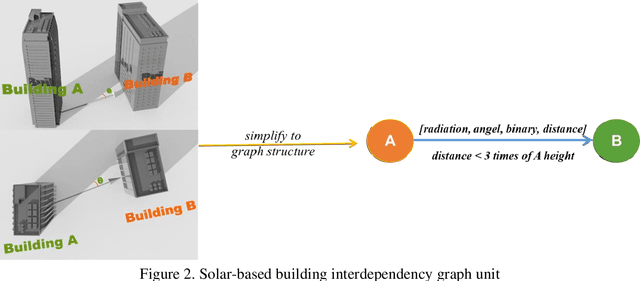
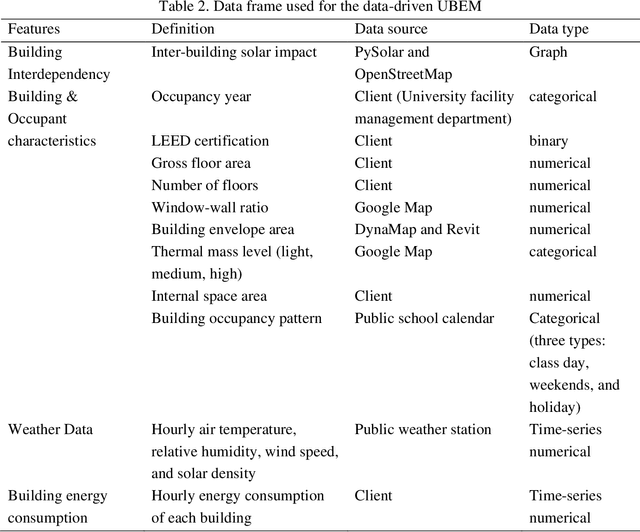
The world is increasingly urbanizing and the building industry accounts for more than 40% of energy consumption in the United States. To improve urban sustainability, many cities adopt ambitious energy-saving strategies through retrofitting existing buildings and constructing new communities. In this situation, an accurate urban building energy model (UBEM) is the foundation to support the design of energy-efficient communities. However, current UBEM are limited in their abilities to capture the inter-building interdependency due to their dynamic and non-linear characteristics. Those models either ignored or oversimplified these building interdependencies, which can substantially affect the accuracy of urban energy modeling. To fill the research gap, this study proposes a novel data-driven UBEM synthesizing the solar-based building interdependency and spatial-temporal graph convolutional network (ST-GCN) algorithm. Especially, we took a university campus located in downtown Atlanta as an example to predict the hourly energy consumption. Furthermore, we tested the feasibility of the proposed model by comparing the performance of the ST-GCN model with other common time-series machine learning models. The results indicate that the ST-GCN model overall outperforms all others. In addition, the physical knowledge embedded in the model is well interpreted. After discussion, it is found that data-driven models integrated engineering or physical knowledge can significantly improve the urban building energy simulation.
A Control Architecture for Provably-Correct Autonomous Driving
May 06, 2021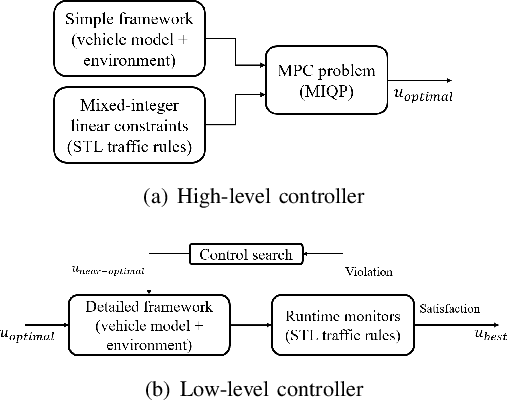
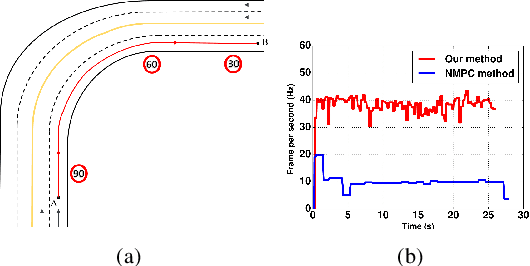
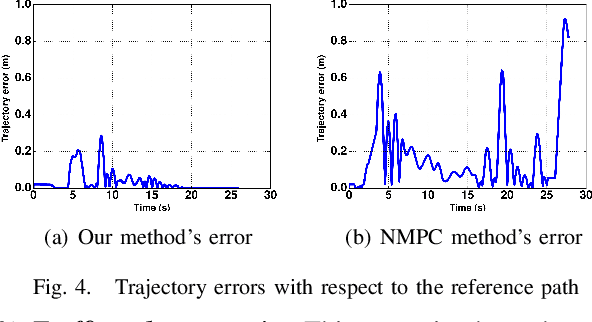
This paper presents a novel two-level control architecture for a fully autonomous vehicle in a deterministic environment, which can handle traffic rules as specifications and low-level vehicle control with real-time performance. At the top level, we use a simple representation of the environment and vehicle dynamics to formulate a linear Model Predictive Control (MPC) problem. We describe the traffic rules and safety constraints using Signal Temporal Logic (STL) formulas, which are mapped to mixed integer-linear constraints in the optimization problem. The solution obtained at the top level is used at the bottom-level to determine the best control command for satisfying the constraints in a more detailed framework. At the bottom-level, specification-based runtime monitoring techniques, together with detailed representations of the environment and vehicle dynamics, are used to compensate for the mismatch between the simple models used in the MPC and the real complex models. We obtain substantial improvements over existing approaches in the literature in the sense of runtime performance and we validate the effectiveness of our proposed control approach in the simulator CARLA.
Self-Weighted Ensemble Method to Adjust the Influence of Individual Models based on Reliability
Apr 09, 2021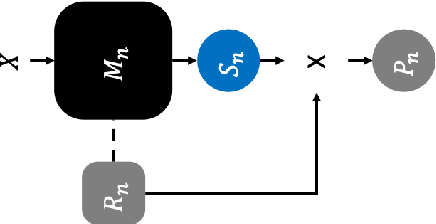

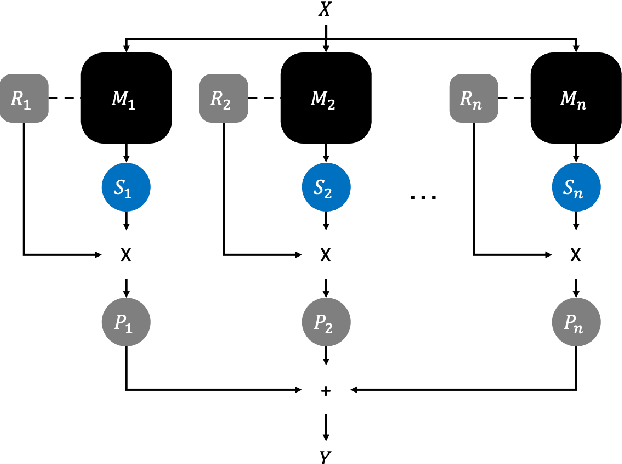
Image classification technology and performance based on Deep Learning have already achieved high standards. Nevertheless, many efforts have conducted to improve the stability of classification via ensembling. However, the existing ensemble method has a limitation in that it requires extra effort including time consumption to find the weight for each model output. In this paper, we propose a simple but improved ensemble method, naming with Self-Weighted Ensemble (SWE), that places the weight of each model via its verification reliability. The proposed ensemble method, SWE, reduces overall efforts for constructing a classification system with varied classifiers. The performance using SWE is 0.033% higher than the conventional ensemble method. Also, the percent of performance superiority to the previous model is up to 73.333% (ratio of 8:22).