 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Polynomial time Constructions of Minimum Height Decision Tree
Feb 01, 2018
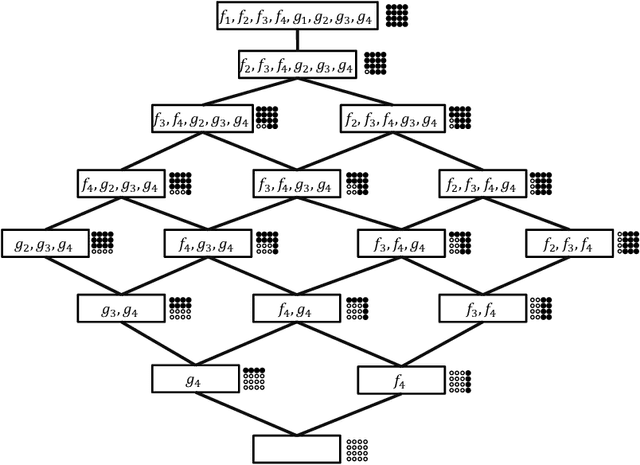
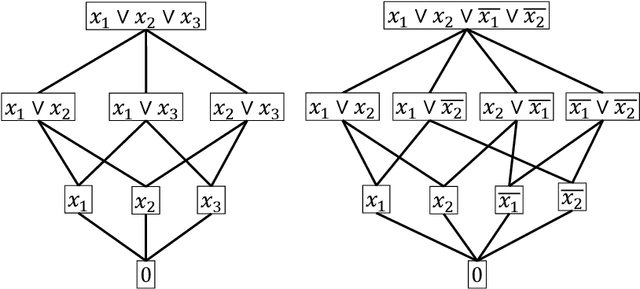
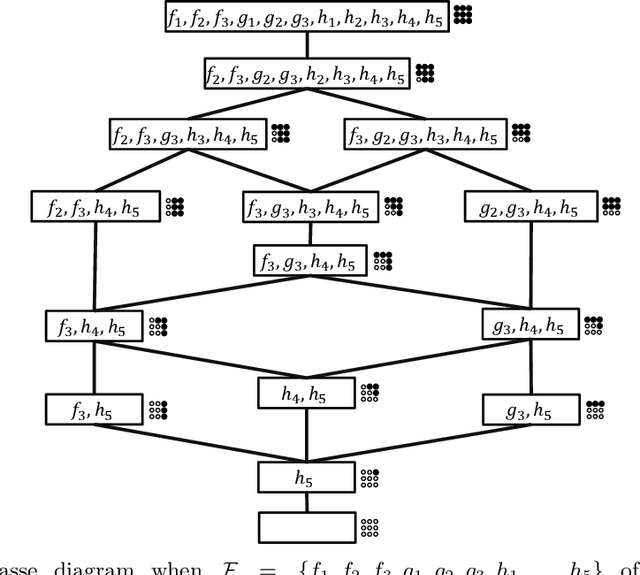
In this paper we study a polynomial time algorithms that for an input $A\subseteq {B_m}$ outputs a decision tree for $A$ of minimum depth. This problem has many applications that include, to name a few, computer vision, group testing, exact learning from membership queries and game theory. Arkin et al. and Moshkov gave a polynomial time $(\ln |A|)$- approximation algorithm (for the depth). The result of Dinur and Steurer for set cover implies that this problem cannot be approximated with ratio $(1-o(1))\cdot \ln |A|$, unless P=NP. Moskov the combinatorial measure of extended teaching dimension of $A$, $ETD(A)$. He showed that $ETD(A)$ is a lower bound for the depth of the decision tree for $A$ and then gave an {\it exponential time} $ETD(A)/\log(ETD(A))$-approximation algorithm. In this paper we further study the $ETD(A)$ measure and a new combinatorial measure, $DEN(A)$, that we call the density of the set $A$. We show that $DEN(A)\le ETD(A)+1$. We then give two results. The first result is that the lower bound $ETD(A)$ of Moshkov for the depth of the decision tree for $A$ is greater than the bounds that are obtained by the classical technique used in the literature. The second result is a polynomial time $(\ln 2) DEN(A)$-approximation (and therefore $(\ln 2) ETD(A)$-approximation) algorithm for the depth of the decision tree of $A$. We also show that a better approximation ratio implies P=NP. We then apply the above results to learning the class of disjunctions of predicates from membership queries. We show that the $ETD$ of this class is bounded from above by the degree $d$ of its Hasse diagram. We then show that Moshkov algorithm can be run in polynomial time and is $(d/\log d)$-approximation algorithm. This gives optimal algorithms when the degree is constant. For example, learning axis parallel rays over constant dimension space.
Multilingual Language Models Predict Human Reading Behavior
Apr 12, 2021

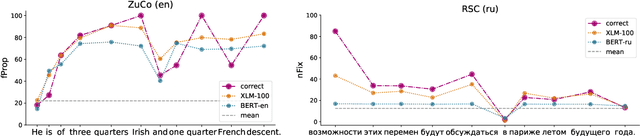
We analyze if large language models are able to predict patterns of human reading behavior. We compare the performance of language-specific and multilingual pretrained transformer models to predict reading time measures reflecting natural human sentence processing on Dutch, English, German, and Russian texts. This results in accurate models of human reading behavior, which indicates that transformer models implicitly encode relative importance in language in a way that is comparable to human processing mechanisms. We find that BERT and XLM models successfully predict a range of eye tracking features. In a series of experiments, we analyze the cross-domain and cross-language abilities of these models and show how they reflect human sentence processing.
TabAug: Data Driven Augmentation for Enhanced Table Structure Recognition
May 15, 2021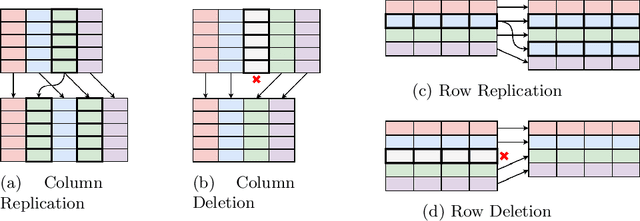
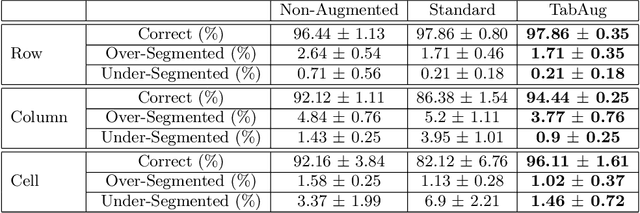
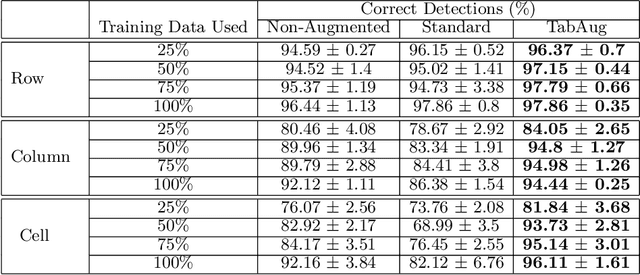
Table Structure Recognition is an essential part of end-to-end tabular data extraction in document images. The recent success of deep learning model architectures in computer vision remains to be non-reflective in table structure recognition, largely because extensive datasets for this domain are still unavailable while labeling new data is expensive and time-consuming. Traditionally, in computer vision, these challenges are addressed by standard augmentation techniques that are based on image transformations like color jittering and random cropping. As demonstrated by our experiments, these techniques are not effective for the task of table structure recognition. In this paper, we propose TabAug, a re-imagined Data Augmentation technique that produces structural changes in table images through replication and deletion of rows and columns. It also consists of a data-driven probabilistic model that allows control over the augmentation process. To demonstrate the efficacy of our approach, we perform experimentation on ICDAR 2013 dataset where our approach shows consistent improvements in all aspects of the evaluation metrics, with cell-level correct detections improving from 92.16% to 96.11% over the baseline.
An Efficient Asynchronous Method for Integrating Evolutionary and Gradient-based Policy Search
Jan 06, 2021
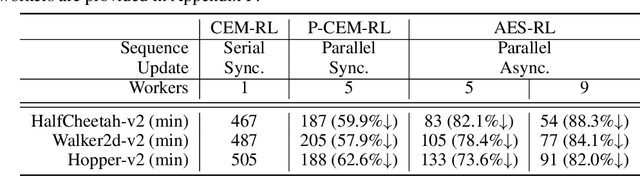
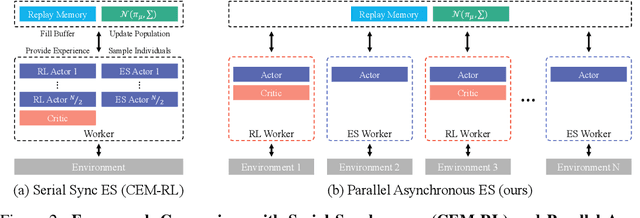

Deep reinforcement learning (DRL) algorithms and evolution strategies (ES) have been applied to various tasks, showing excellent performances. These have the opposite properties, with DRL having good sample efficiency and poor stability, while ES being vice versa. Recently, there have been attempts to combine these algorithms, but these methods fully rely on synchronous update scheme, making it not ideal to maximize the benefits of the parallelism in ES. To solve this challenge, asynchronous update scheme was introduced, which is capable of good time-efficiency and diverse policy exploration. In this paper, we introduce an Asynchronous Evolution Strategy-Reinforcement Learning (AES-RL) that maximizes the parallel efficiency of ES and integrates it with policy gradient methods. Specifically, we propose 1) a novel framework to merge ES and DRL asynchronously and 2) various asynchronous update methods that can take all advantages of asynchronism, ES, and DRL, which are exploration and time efficiency, stability, and sample efficiency, respectively. The proposed framework and update methods are evaluated in continuous control benchmark work, showing superior performance as well as time efficiency compared to the previous methods.
Restoring and Mining the Records of the Joseon Dynasty via Neural Language Modeling and Machine Translation
May 07, 2021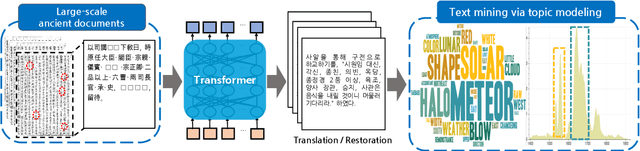
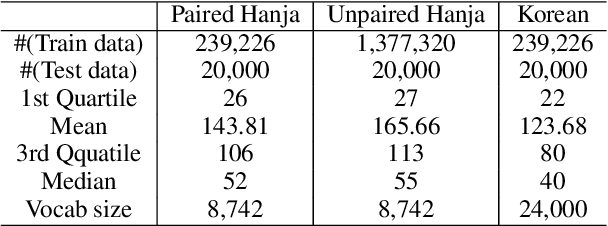


Understanding voluminous historical records provides clues on the past in various aspects, such as social and political issues and even natural science facts. However, it is generally difficult to fully utilize the historical records, since most of the documents are not written in a modern language and part of the contents are damaged over time. As a result, restoring the damaged or unrecognizable parts as well as translating the records into modern languages are crucial tasks. In response, we present a multi-task learning approach to restore and translate historical documents based on a self-attention mechanism, specifically utilizing two Korean historical records, ones of the most voluminous historical records in the world. Experimental results show that our approach significantly improves the accuracy of the translation task than baselines without multi-task learning. In addition, we present an in-depth exploratory analysis on our translated results via topic modeling, uncovering several significant historical events.
Structured Citation Trend Prediction Using Graph Neural Networks
Apr 06, 2021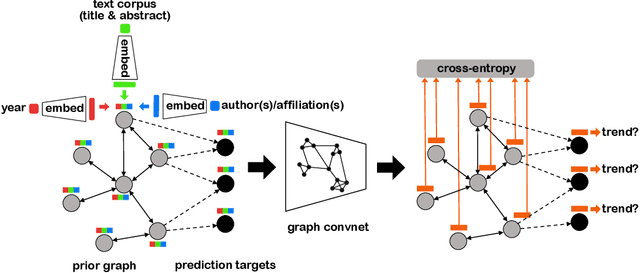
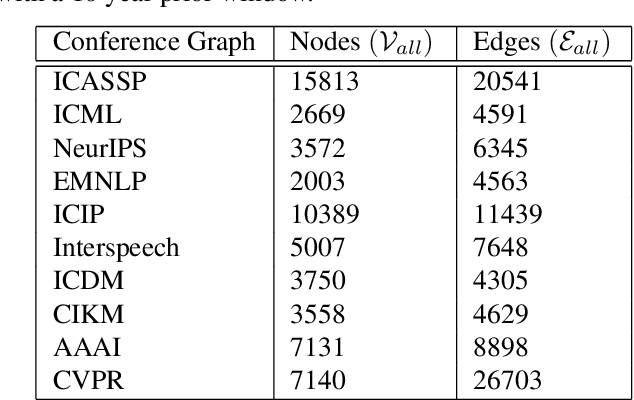
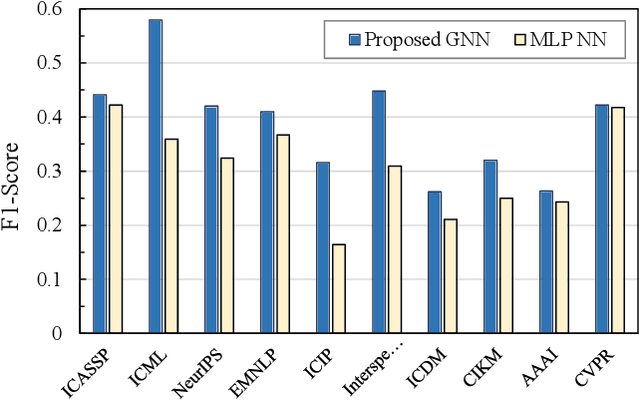
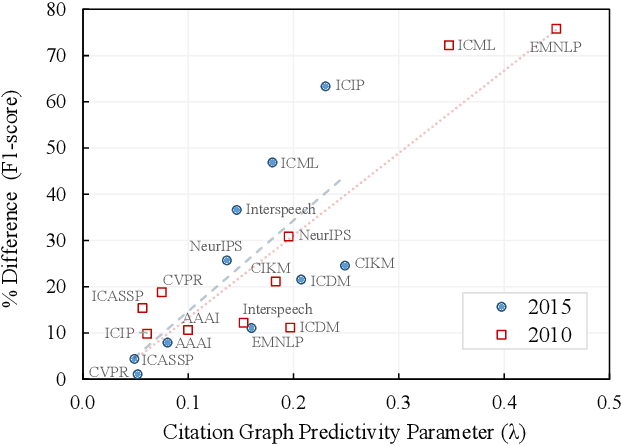
Academic citation graphs represent citation relationships between publications across the full range of academic fields. Top cited papers typically reveal future trends in their corresponding domains which is of importance to both researchers and practitioners. Prior citation prediction methods often require initial citation trends to be established and do not take advantage of the recent advancements in graph neural networks (GNNs). We present GNN-based architecture that predicts the top set of papers at the time of publication. For experiments, we curate a set of academic citation graphs for a variety of conferences and show that the proposed model outperforms other classic machine learning models in terms of the F1-score.
Zero-Shot Controlled Generation with Encoder-Decoder Transformers
Jun 11, 2021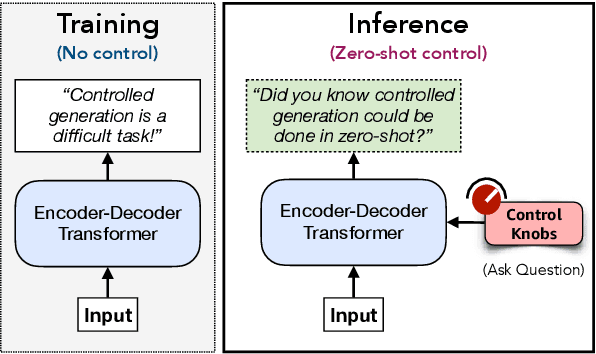

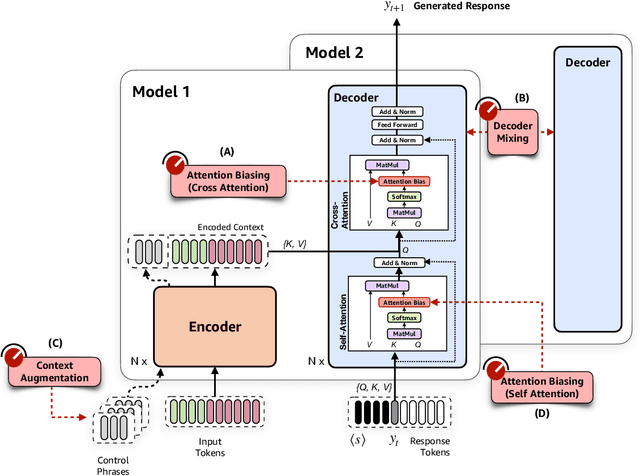

Controlling neural network-based models for natural language generation (NLG) has broad applications in numerous areas such as machine translation, document summarization, and dialog systems. Approaches that enable such control in a zero-shot manner would be of great importance as, among other reasons, they remove the need for additional annotated data and training. In this work, we propose novel approaches for controlling encoder-decoder transformer-based NLG models in a zero-shot manner. This is done by introducing three control knobs; namely, attention biasing, decoder mixing, and context augmentation, that are applied to these models at generation time. These knobs control the generation process by directly manipulating trained NLG models (e.g., biasing cross-attention layers) to realize the desired attributes in the generated outputs. We show that not only are these NLG models robust to such manipulations, but also their behavior could be controlled without an impact on their generation performance. These results, to the best of our knowledge, are the first of their kind. Through these control knobs, we also investigate the role of transformer decoder's self-attention module and show strong evidence that its primary role is maintaining fluency of sentences generated by these models. Based on this hypothesis, we show that alternative architectures for transformer decoders could be viable options. We also study how this hypothesis could lead to more efficient ways for training encoder-decoder transformer models.
SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts
May 07, 2021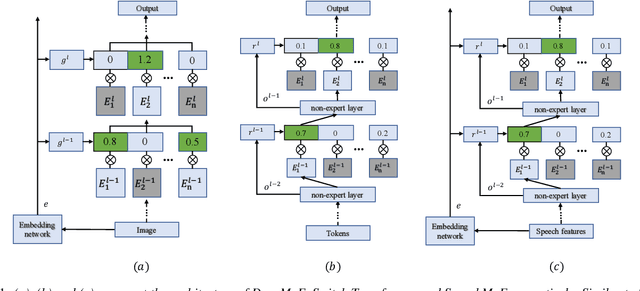
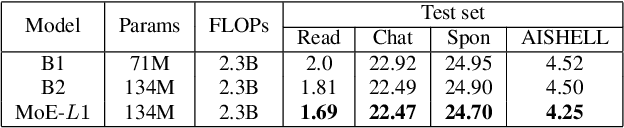
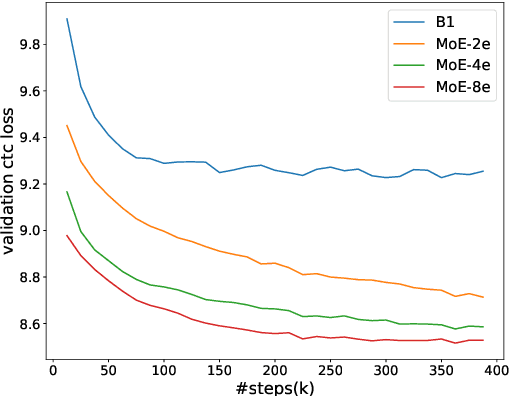
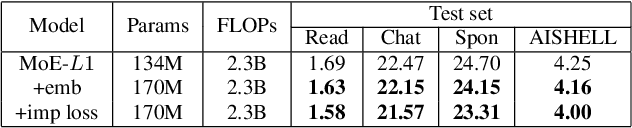
Recently, Mixture of Experts (MoE) based Transformer has shown promising results in many domains. This is largely due to the following advantages of this architecture: firstly, MoE based Transformer can increase model capacity without computational cost increasing both at training and inference time. Besides, MoE based Transformer is a dynamic network which can adapt to the varying complexity of input instances in realworld applications. In this work, we explore the MoE based model for speech recognition, named SpeechMoE. To further control the sparsity of router activation and improve the diversity of gate values, we propose a sparsity L1 loss and a mean importance loss respectively. In addition, a new router architecture is used in SpeechMoE which can simultaneously utilize the information from a shared embedding network and the hierarchical representation of different MoE layers. Experimental results show that SpeechMoE can achieve lower character error rate (CER) with comparable computation cost than traditional static networks, providing 7.0%-23.0% relative CER improvements on four evaluation datasets.
MoleHD: Automated Drug Discovery using Brain-Inspired Hyperdimensional Computing
Jun 05, 2021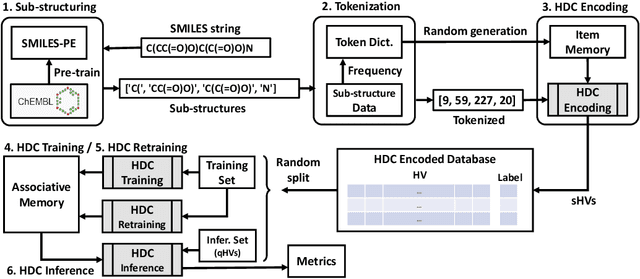
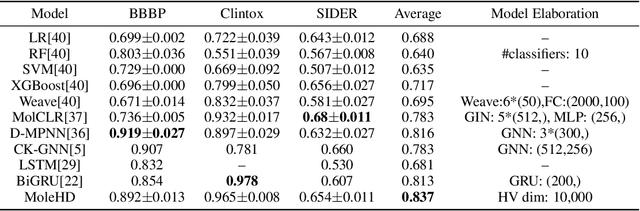
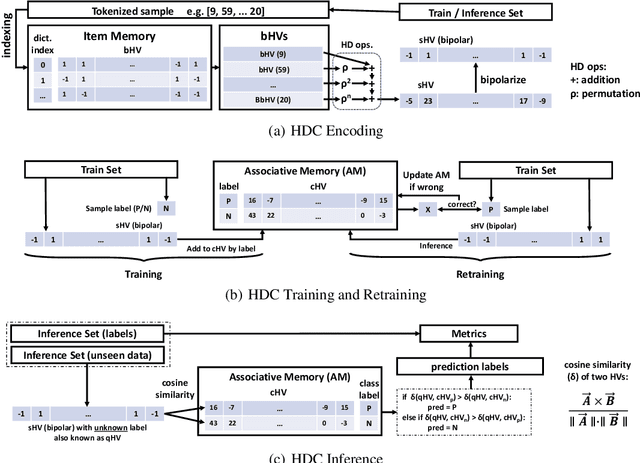
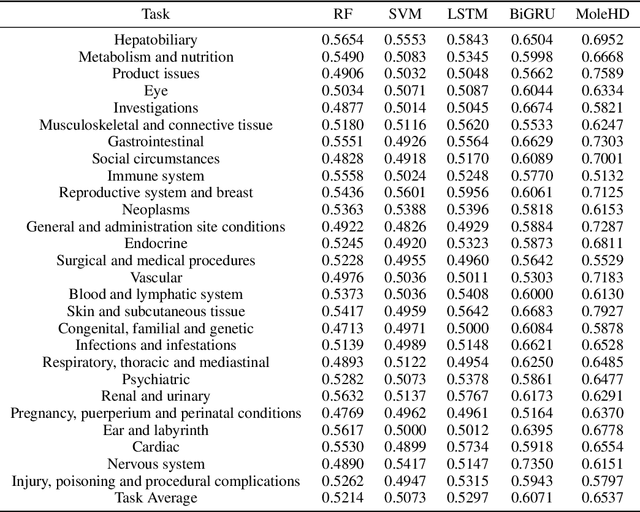
Modern drug discovery is often time-consuming, complex and cost-ineffective due to the large volume of molecular data and complicated molecular properties. Recently, machine learning algorithms have shown promising results in virtual screening of automated drug discovery by predicting molecular properties. While emerging learning methods such as graph neural networks and recurrent neural networks exhibit high accuracy, they are also notoriously computation-intensive and memory-intensive with operations such as feature embeddings or deep convolutions. In this paper, we propose a viable alternative to neural network classifiers. We present MoleHD, a method based on brain-inspired hyperdimensional computing (HDC) for molecular property prediction. We first transform the SMILES presentation of molecules into feature vectors by SMILE-PE tokenizers pretrained on the ChEMBL database. Then, we develop HDC encoders to project such features into high-dimensional vectors that are used for training and inference. We perform an extensive evaluation using 30 classification tasks from 3 widely-used molecule datasets and compare MoleHD with 10 baseline methods including 6 SOTA neural network classifiers. Results show that MoleHD is able to outperform all the baseline methods on average across 30 classification tasks with significantly reduced computing cost. To the best of our knowledge, we develop the first HDC-based method for drug discovery. The promising results presented in this paper can potentially lead to a novel path in drug discovery research.
Progressive extension of reinforcement learning action dimension for asymmetric assembly tasks
Apr 06, 2021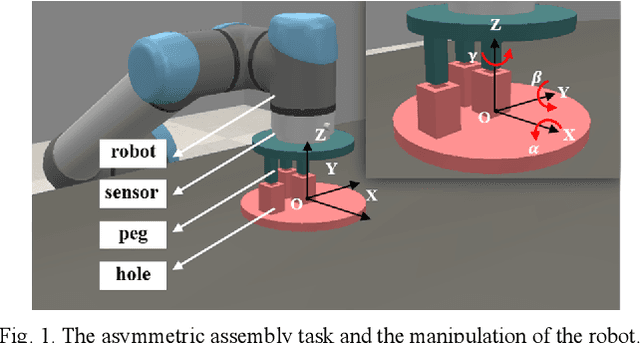
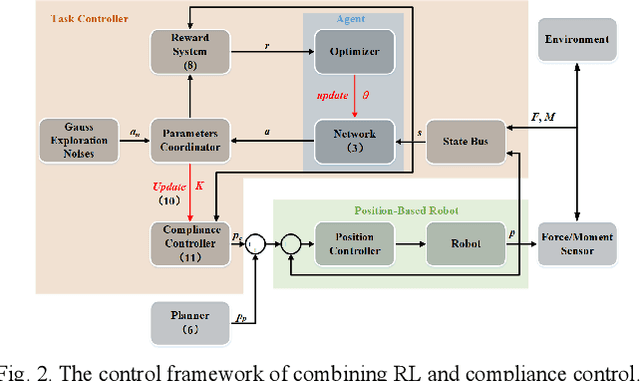
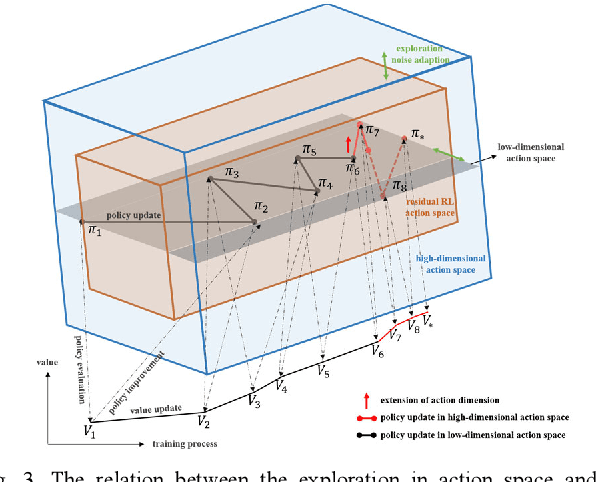
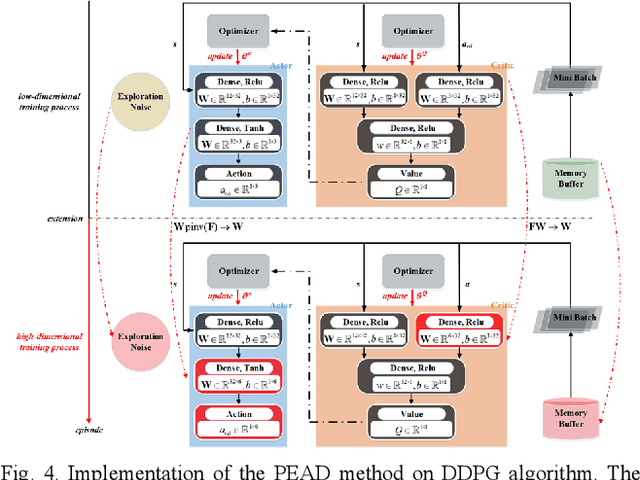
Reinforcement learning (RL) is always the preferred embodiment to construct the control strategy of complex tasks, like asymmetric assembly tasks. However, the convergence speed of reinforcement learning severely restricts its practical application. In this paper, the convergence is first accelerated by combining RL and compliance control. Then a completely innovative progressive extension of action dimension (PEAD) mechanism is proposed to optimize the convergence of RL algorithms. The PEAD method is verified in DDPG and PPO. The results demonstrate the PEAD method will enhance the data-efficiency and time-efficiency of RL algorithms as well as increase the stable reward, which provides more potential for the application of RL.