 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wearable Sensors for Spatio-Temporal Grip Force Profiling
Jan 16, 2021
Wearable biosensor technology enables real-time, convenient, and continuous monitoring of users behavioral signals. Such include signals relative to body motion, body temperature, biological or biochemical markers, and individual grip forces, which are studied in this paper. A four step pick and drop image guided and robot assisted precision task has been designed for exploiting a wearable wireless sensor glove system. Individual spatio temporal grip forces are analyzed on the basis of thousands of individual sensor data, collected from different locations on the dominant and non-dominant hands of each of three users in ten successive task sessions. Statistical comparisons reveal specific differences between grip force profiles of the individual users as a function of task skill level (expertise) and time.
Federated Word2Vec: Leveraging Federated Learning to Encourage Collaborative Representation Learning
Apr 19, 2021
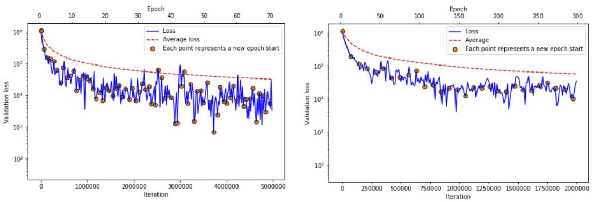
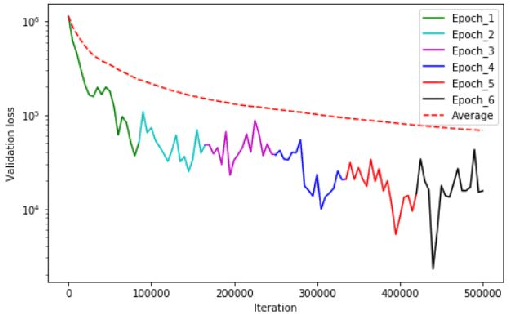
Large scale contextual representation models have significantly advanced NLP in recent years, understanding the semantics of text to a degree never seen before. However, they need to process large amounts of data to achieve high-quality results. Joining and accessing all these data from multiple sources can be extremely challenging due to privacy and regulatory reasons. Federated Learning can solve these limitations by training models in a distributed fashion, taking advantage of the hardware of the devices that generate the data. We show the viability of training NLP models, specifically Word2Vec, with the Federated Learning protocol. In particular, we focus on a scenario in which a small number of organizations each hold a relatively large corpus. The results show that neither the quality of the results nor the convergence time in Federated Word2Vec deteriorates as compared to centralised Word2Vec.
A deep network approach to multitemporal cloud detection
Dec 09, 2020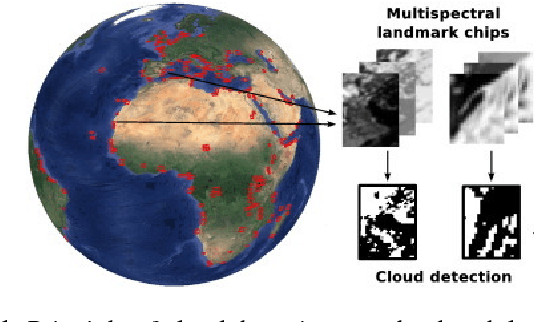
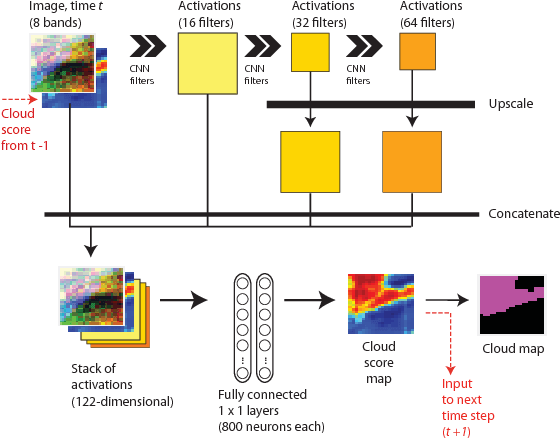
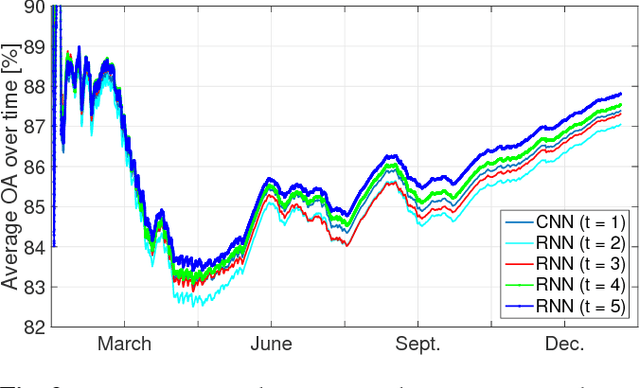
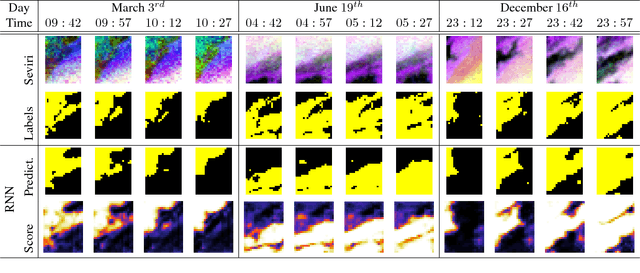
We present a deep learning model with temporal memory to detect clouds in image time series acquired by the Seviri imager mounted on the Meteosat Second Generation (MSG) satellite. The model provides pixel-level cloud maps with related confidence and propagates information in time via a recurrent neural network structure. With a single model, we are able to outline clouds along all year and during day and night with high accuracy.
Domain Adaptation and Multi-Domain Adaptation for Neural Machine Translation: A Survey
Apr 14, 2021


The development of deep learning techniques has allowed Neural Machine Translation (NMT) models to become extremely powerful, given sufficient training data and training time. However, systems struggle when translating text from a new domain with a distinct style or vocabulary. Tuning on a representative training corpus allows good in-domain translation, but such data-centric approaches can cause over-fitting to new data and `catastrophic forgetting' of previously learned behaviour. We concentrate on more robust approaches to domain adaptation for NMT, particularly the case where a system may need to translate sentences from multiple domains. We divide techniques into those relating to data selection, model architecture, parameter adaptation procedure, and inference procedure. We finally highlight the benefits of domain adaptation and multi-domain adaptation techniques to other lines of NMT research.
Gradient-augmented Supervised Learning of Optimal Feedback Laws Using State-dependent Riccati Equations
Mar 06, 2021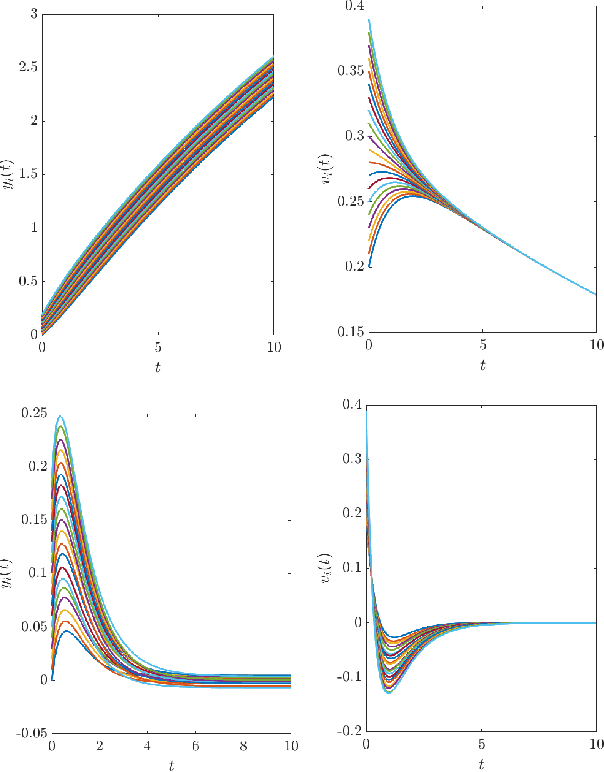
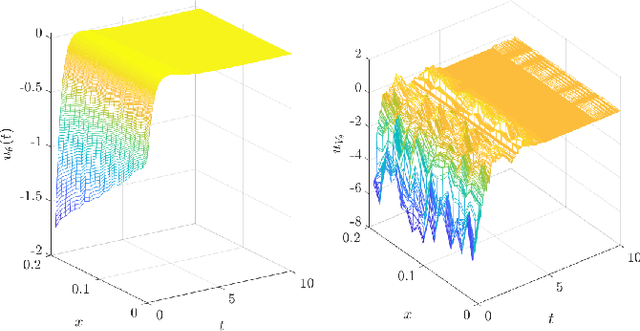
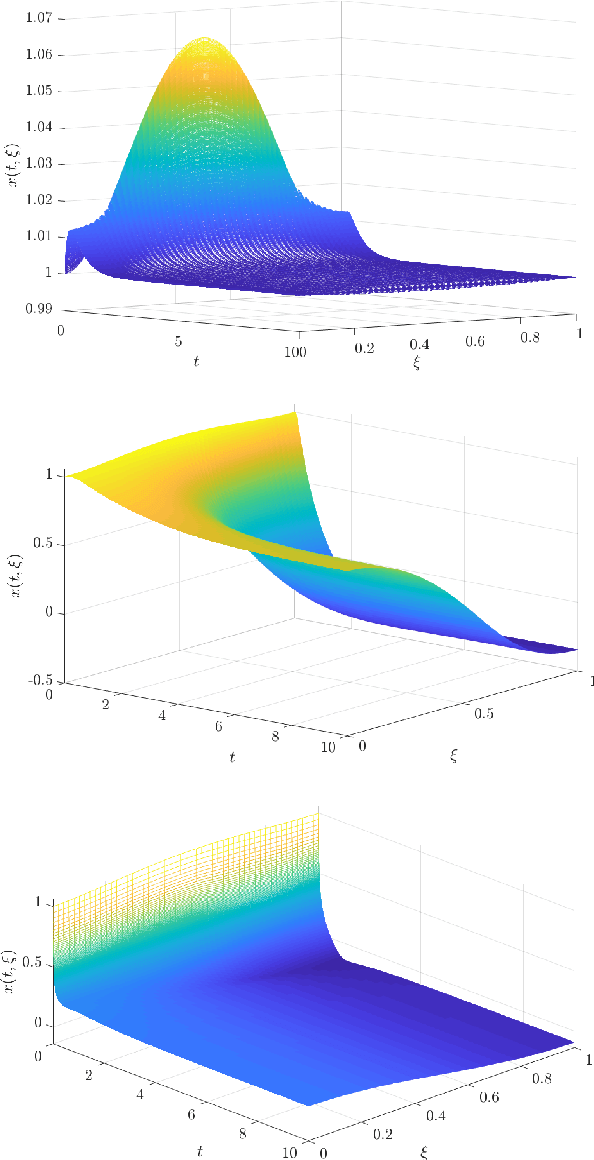
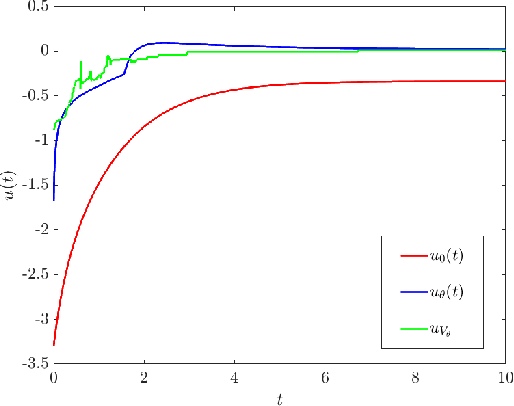
A supervised learning approach for the solution of large-scale nonlinear stabilization problems is presented. A stabilizing feedback law is trained from a dataset generated from State-dependent Riccati Equation solves. The training phase is enriched by the use gradient information in the loss function, which is weighted through the use of hyperparameters. High-dimensional nonlinear stabilization tests demonstrate that real-time sequential large-scale Algebraic Riccati Equation solves can be substituted by a suitably trained feedforward neural network.
IQDet: Instance-wise Quality Distribution Sampling for Object Detection
Apr 14, 2021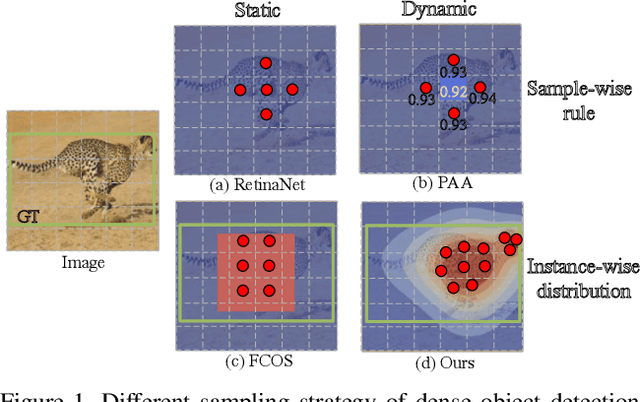
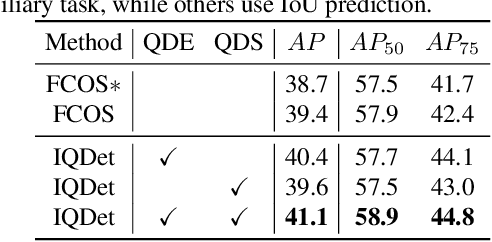
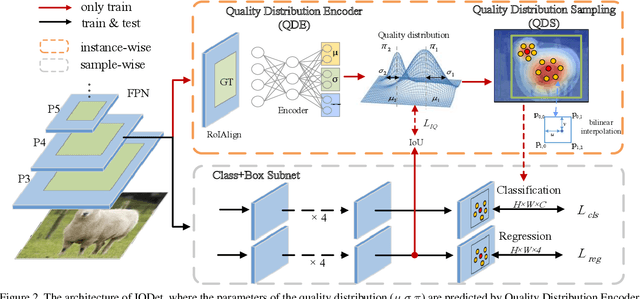
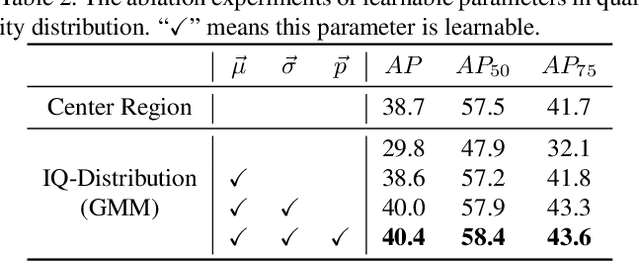
We propose a dense object detector with an instance-wise sampling strategy, named IQDet. Instead of using human prior sampling strategies, we first extract the regional feature of each ground-truth to estimate the instance-wise quality distribution. According to a mixture model in spatial dimensions, the distribution is more noise-robust and adapted to the semantic pattern of each instance. Based on the distribution, we propose a quality sampling strategy, which automatically selects training samples in a probabilistic manner and trains with more high-quality samples. Extensive experiments on MS COCO show that our method steadily improves baseline by nearly 2.4 AP without bells and whistles. Moreover, our best model achieves 51.6 AP, outperforming all existing state-of-the-art one-stage detectors and it is completely cost-free in inference time.
Bi-direction Context Propagation Network for Real-time Semantic Segmentation
Jun 02, 2020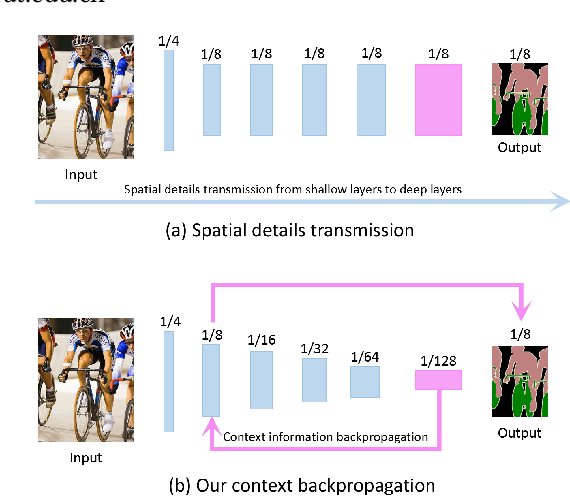
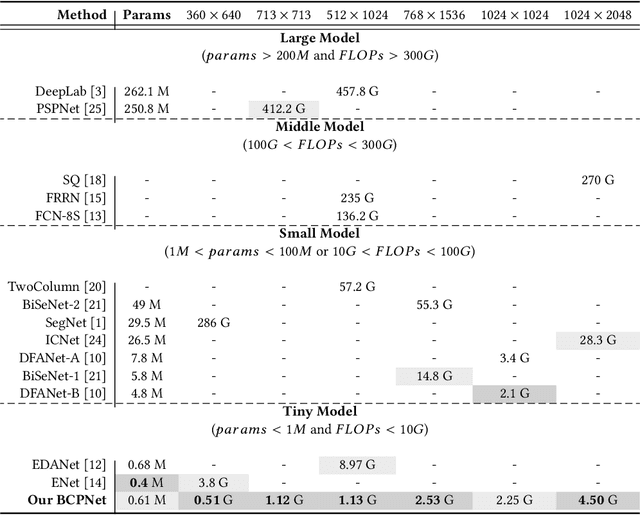
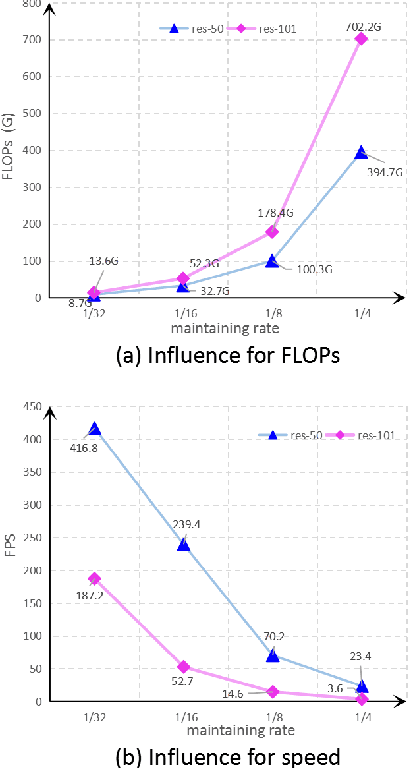

Spatial details and context correlations are two types of important information for semantic segmentation. Generally, shallow layers tend to contain more spatial details, while deep layers are rich in context correlations. Aiming to keep both advantages, most of current methods choose to forward-propagate the spatial details from shallow layers to deep layers, which is computationally expensive and substantially lowers the model's execution speed. To address this problem, we propose the Bi-direction Context Propagation Network (BCPNet) by leveraging both spatial and context information. Different from the previous methods, our BCPNet builds bi-directional paths in its network architecture, allowing the backward context propagation and the forward spatial detail propagation simultaneously. Moreover, all the components in the network are kept lightweight. Extensive experiments show that our BCPNet has achieved a good balance between accuracy and speed. For accuracy, our BCPNet has achieved 68.4 \% mIoU on the Cityscapes test set and 67.8 \% mIoU on the CamVid test set. For speed, our BCPNet can achieve 585.9 FPS (or 1.7 ms runtime per image) at $360 \times 640$ size based on a GeForce GTX TITAN X GPU card.
A Monotone Approximate Dynamic Programming Approach for the Stochastic Scheduling, Allocation, and Inventory Replenishment Problem: Applications to Drone and Electric Vehicle Battery Swap Stations
May 14, 2021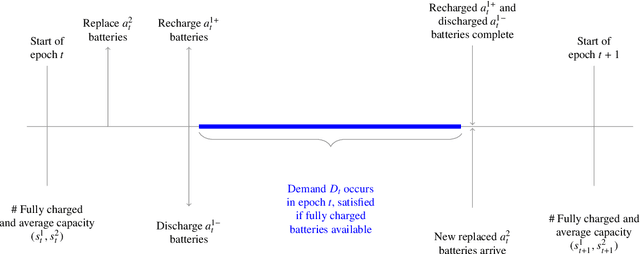

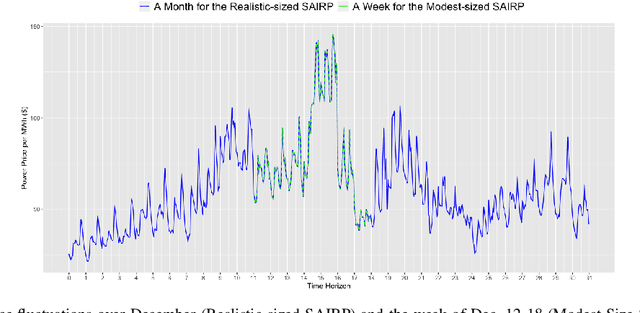
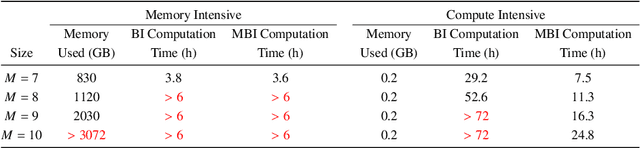
There is a growing interest in using electric vehicles (EVs) and drones for many applications. However, battery-oriented issues, including range anxiety and battery degradation, impede adoption. Battery swap stations are one alternative to reduce these concerns that allow the swap of depleted for full batteries in minutes. We consider the problem of deriving actions at a battery swap station when explicitly considering the uncertain arrival of swap demand, battery degradation, and replacement. We model the operations at a battery swap station using a finite horizon Markov Decision Process model for the stochastic scheduling, allocation, and inventory replenishment problem (SAIRP), which determines when and how many batteries are charged, discharged, and replaced over time. We present theoretical proofs for the monotonicity of the value function and monotone structure of an optimal policy for special SAIRP cases. Due to the curses of dimensionality, we develop a new monotone approximate dynamic programming (ADP) method, which intelligently initializes a value function approximation using regression. In computational tests, we demonstrate the superior performance of the new regression-based monotone ADP method as compared to exact methods and other monotone ADP methods. Further, with the tests, we deduce policy insights for drone swap stations.
Discovery of slow variables in a class of multiscale stochastic systems via neural networks
Apr 28, 2021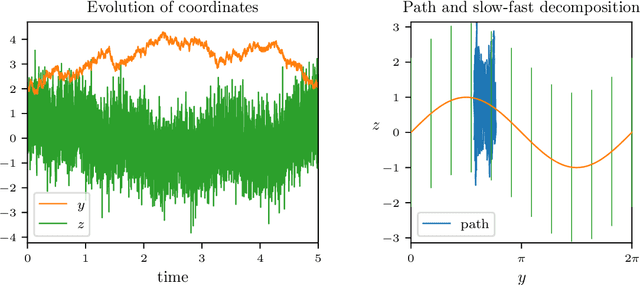
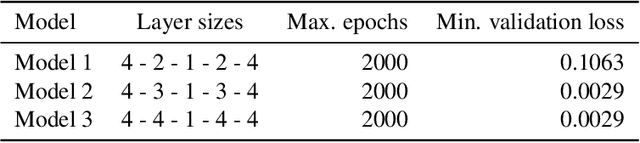
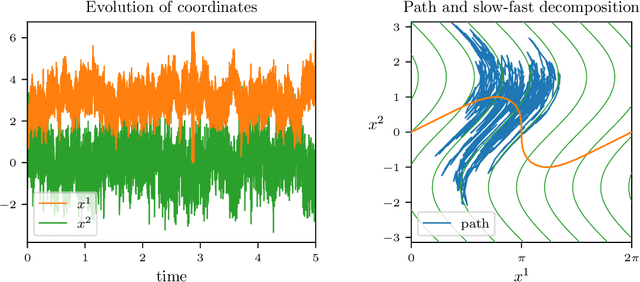
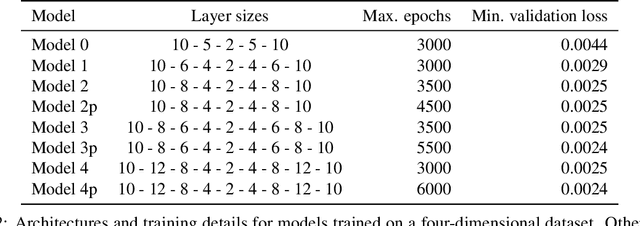
Finding a reduction of complex, high-dimensional dynamics to its essential, low-dimensional "heart" remains a challenging yet necessary prerequisite for designing efficient numerical approaches. Machine learning methods have the potential to provide a general framework to automatically discover such representations. In this paper, we consider multiscale stochastic systems with local slow-fast time scale separation and propose a new method to encode in an artificial neural network a map that extracts the slow representation from the system. The architecture of the network consists of an encoder-decoder pair that we train in a supervised manner to learn the appropriate low-dimensional embedding in the bottleneck layer. We test the method on a number of examples that illustrate the ability to discover a correct slow representation. Moreover, we provide an error measure to assess the quality of the embedding and demonstrate that pruning the network can pinpoint an essential coordinates of the system to build the slow representation.
Increasing Energy Efficiency of Massive-MIMO Network via Base Stations Switching using Reinforcement Learning and Radio Environment Maps
Mar 08, 2021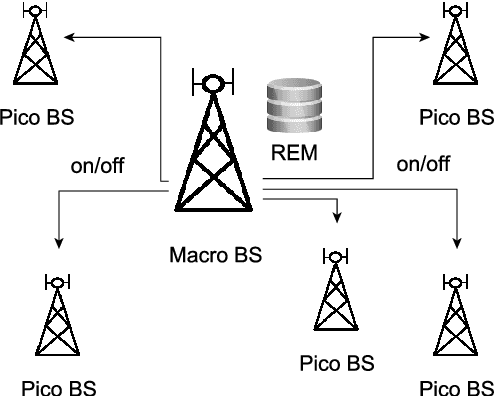
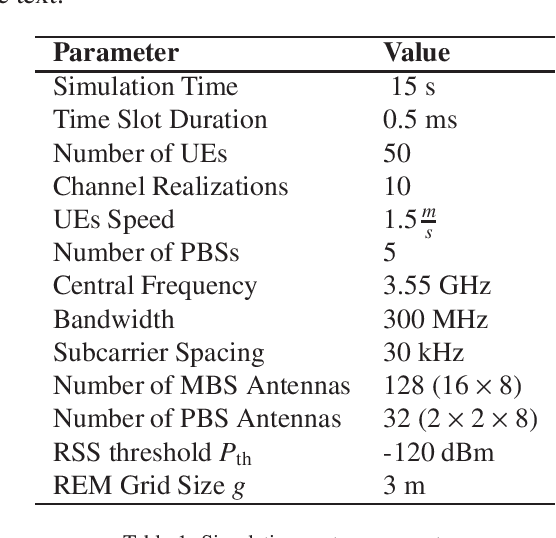
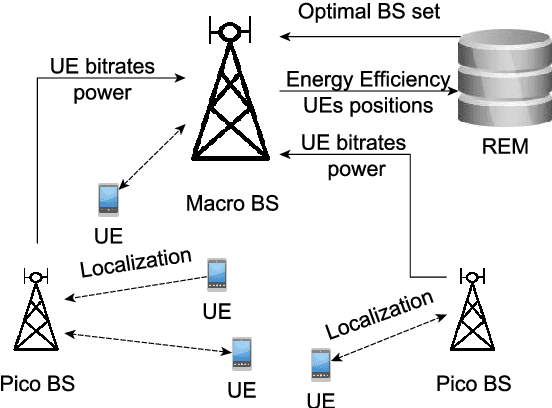
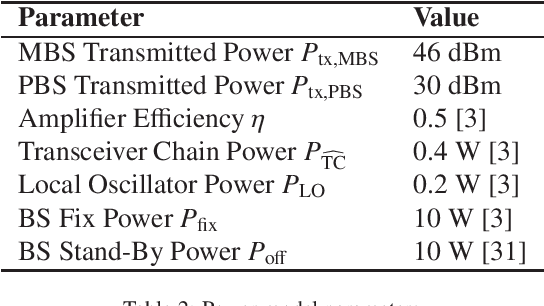
Energy Efficiency (EE) is of high importance while considering Massive Multiple-Input Multiple-Output (M-MIMO) networks where base stations (BSs) are equipped with an antenna array composed of up to hundreds of elements. M-MIMO transmission, although highly spectrally efficient, results in high energy consumption growing with the number of antennas. This paper investigates EE improvement through switching on/off underutilized BSs. It is proposed to use the location-aware approach, where data about an optimal active BSs set is stored in a Radio Environment Map (REM). For efficient acquisition, processing and utilization of the REM data, reinforcement learning (RL) algorithms are used. State-of-the-art exploration/exploitation methods including e-greedy, Upper Confidence Bound (UCB), and Gradient Bandit are evaluated. Then analytical action filtering, and an REM-based Exploration Algorithm (REM-EA) are proposed to improve the RL convergence time. Algorithms are evaluated using an advanced, system-level simulator of an M-MIMO Heterogeneous Network (HetNet) utilizing an accurate 3D-ray-tracing radio channel model. The proposed RL-based BSs switching algorithm is proven to provide 70% gains in EE over a state-of-the-art algorithm using an analytical heuristic. Moreover, the proposed action filtering and REM-EA can reduce RL convergence time in relation to the best-performing state-of-the-art exploration method by 60% and 83%, respectively.