 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Size-Performance Tradeoffs: Weighing PoS Tagger Models
Apr 16, 2021
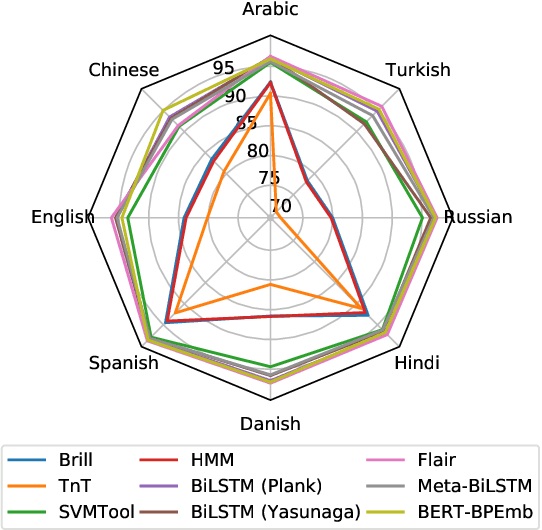
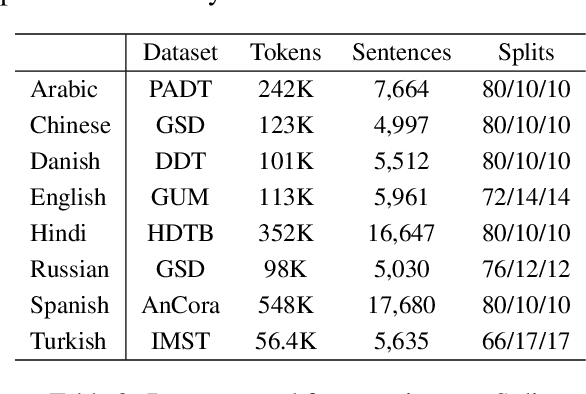
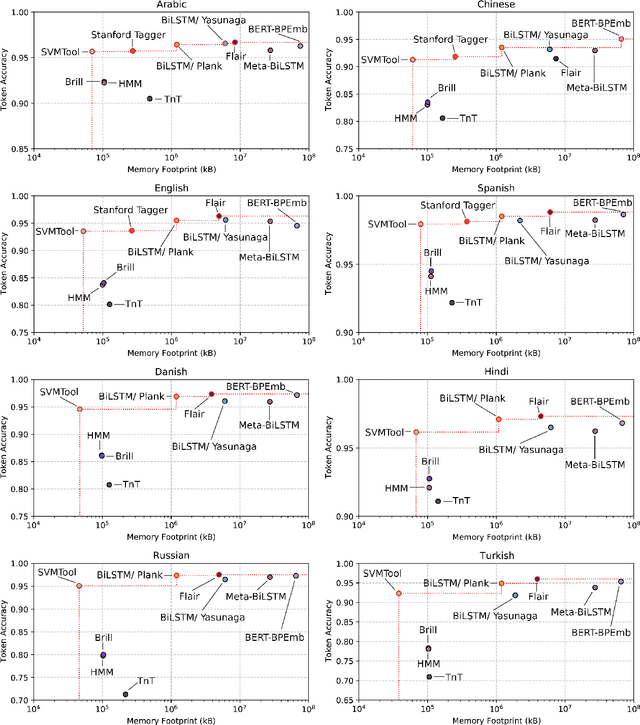
Improvement in machine learning-based NLP performance are often presented with bigger models and more complex code. This presents a trade-off: better scores come at the cost of larger tools; bigger models tend to require more during training and inference time. We present multiple methods for measuring the size of a model, and for comparing this with the model's performance. In a case study over part-of-speech tagging, we then apply these techniques to taggers for eight languages and present a novel analysis identifying which taggers are size-performance optimal. Results indicate that some classical taggers place on the size-performance skyline across languages. Further, although the deep models have highest performance for multiple scores, it is often not the most complex of these that reach peak performance.
MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects
Oct 22, 2018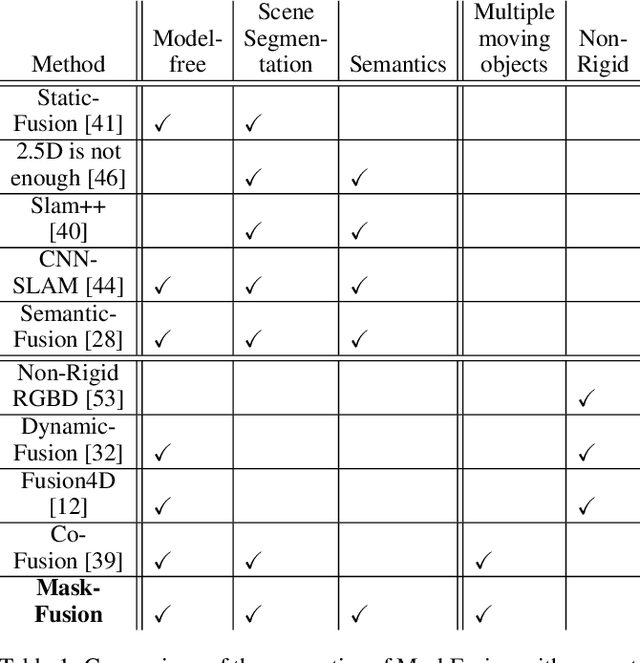
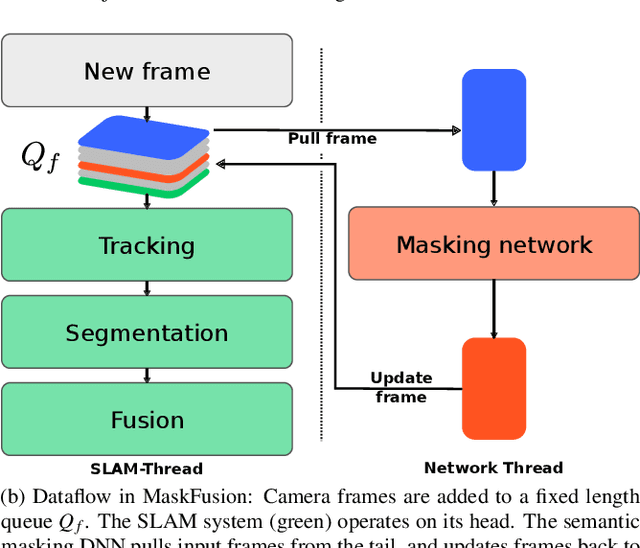
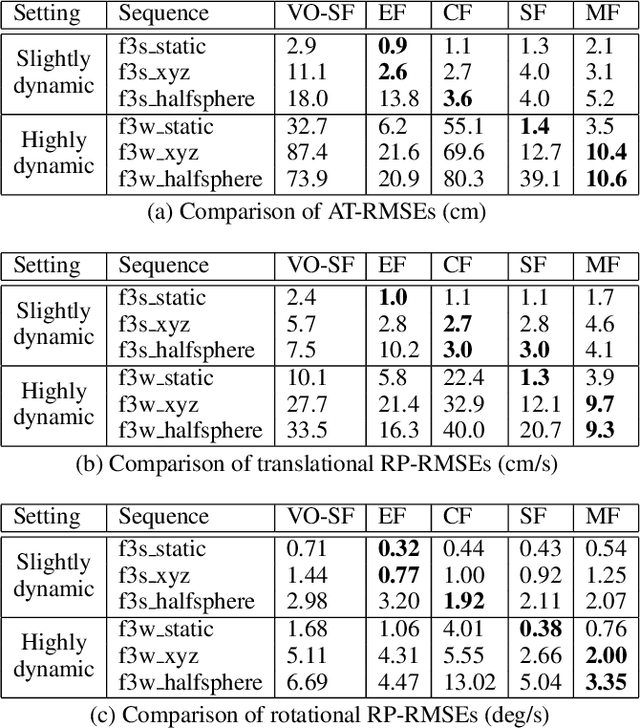
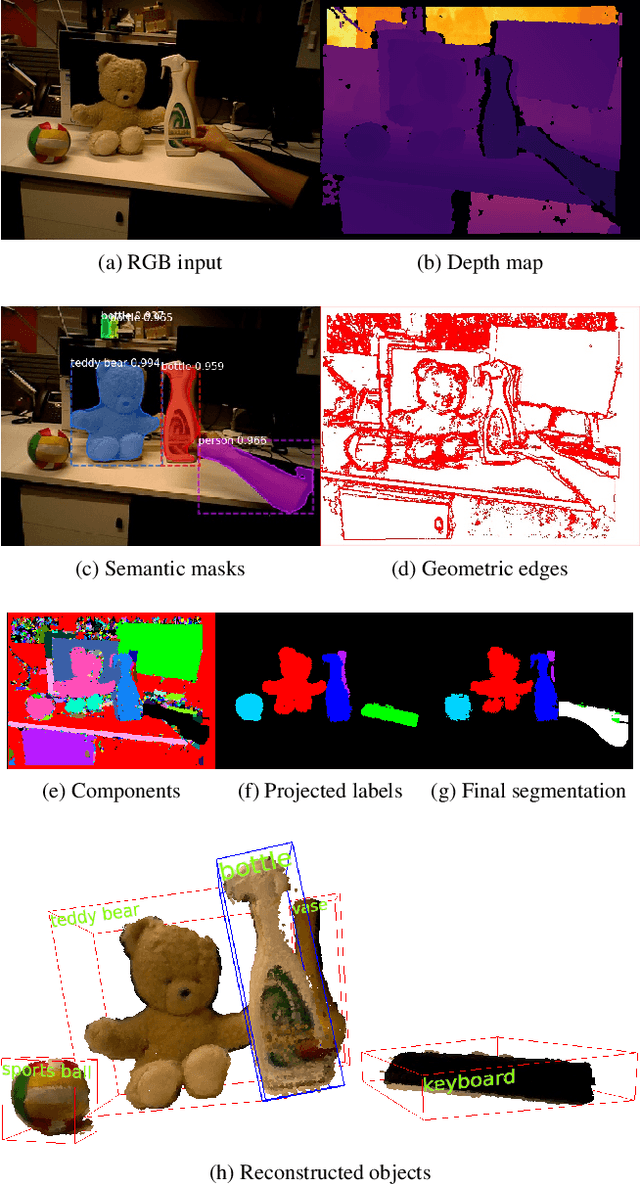
We present MaskFusion, a real-time, object-aware, semantic and dynamic RGB-D SLAM system that goes beyond traditional systems which output a purely geometric map of a static scene. MaskFusion recognizes, segments and assigns semantic class labels to different objects in the scene, while tracking and reconstructing them even when they move independently from the camera. As an RGB-D camera scans a cluttered scene, image-based instance-level semantic segmentation creates semantic object masks that enable real-time object recognition and the creation of an object-level representation for the world map. Unlike previous recognition-based SLAM systems, MaskFusion does not require known models of the objects it can recognize, and can deal with multiple independent motions. MaskFusion takes full advantage of using instance-level semantic segmentation to enable semantic labels to be fused into an object-aware map, unlike recent semantics enabled SLAM systems that perform voxel-level semantic segmentation. We show augmented-reality applications that demonstrate the unique features of the map output by MaskFusion: instance-aware, semantic and dynamic.
Computer-aided Interpretable Features for Leaf Image Classification
Jun 15, 2021

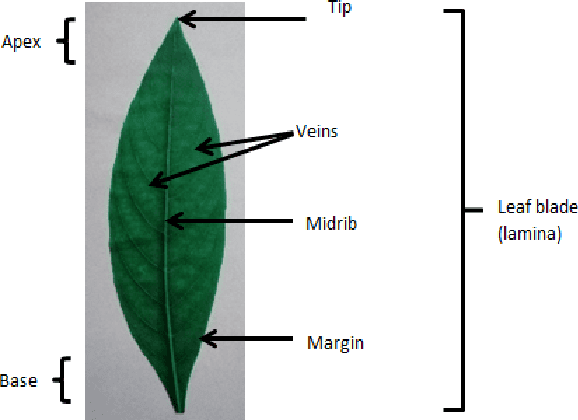
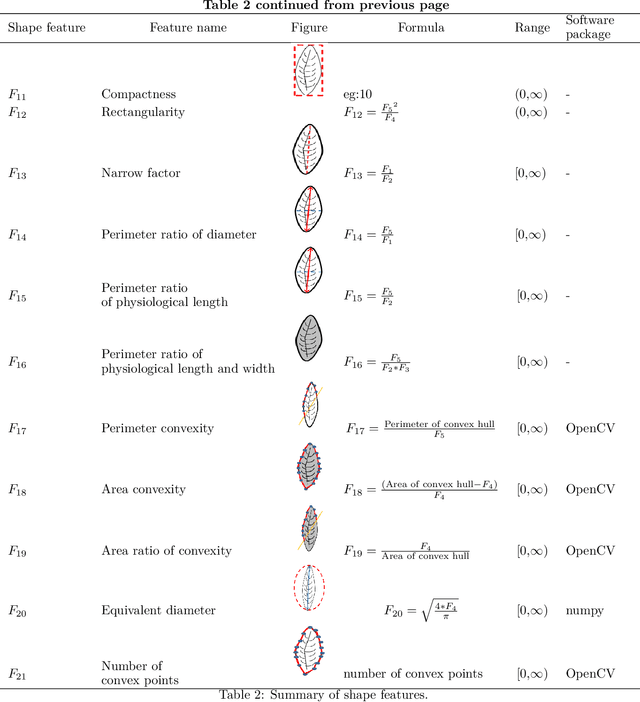
Plant species identification is time consuming, costly, and requires lots of efforts, and expertise knowledge. In recent, many researchers use deep learning methods to classify plants directly using plant images. While deep learning models have achieved a great success, the lack of interpretability limit their widespread application. To overcome this, we explore the use of interpretable, measurable and computer-aided features extracted from plant leaf images. Image processing is one of the most challenging, and crucial steps in feature-extraction. The purpose of image processing is to improve the leaf image by removing undesired distortion. The main image processing steps of our algorithm involves: i) Convert original image to RGB (Red-Green-Blue) image, ii) Gray scaling, iii) Gaussian smoothing, iv) Binary thresholding, v) Remove stalk, vi) Closing holes, and vii) Resize image. The next step after image processing is to extract features from plant leaf images. We introduced 52 computationally efficient features to classify plant species. These features are mainly classified into four groups as: i) shape-based features, ii) color-based features, iii) texture-based features, and iv) scagnostic features. Length, width, area, texture correlation, monotonicity and scagnostics are to name few of them. We explore the ability of features to discriminate the classes of interest under supervised learning and unsupervised learning settings. For that, supervised dimensionality reduction technique, Linear Discriminant Analysis (LDA), and unsupervised dimensionality reduction technique, Principal Component Analysis (PCA) are used to convert and visualize the images from digital-image space to feature space. The results show that the features are sufficient to discriminate the classes of interest under both supervised and unsupervised learning settings.
Short- and long-term prediction of a chaotic flow: A physics-constrained reservoir computing approach
Feb 15, 2021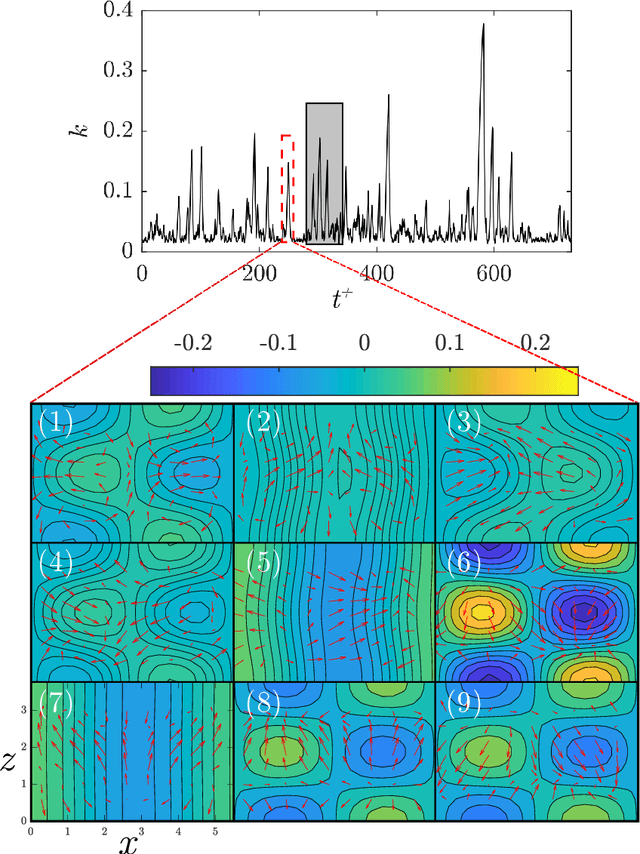
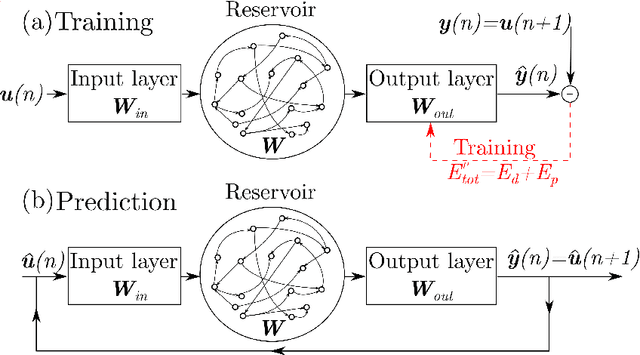
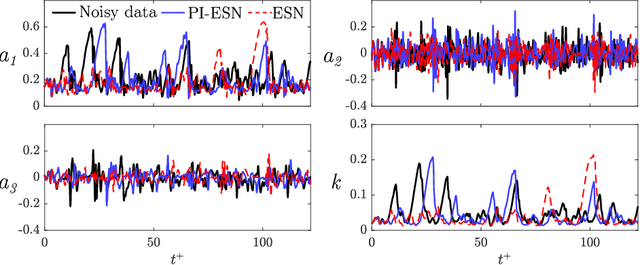
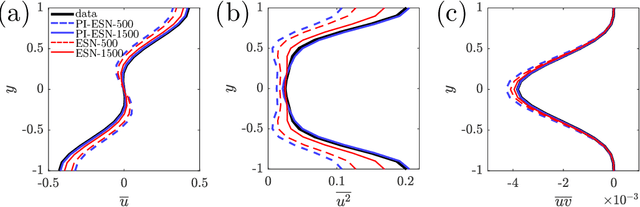
We propose a physics-constrained machine learning method-based on reservoir computing- to time-accurately predict extreme events and long-term velocity statistics in a model of turbulent shear flow. The method leverages the strengths of two different approaches: empirical modelling based on reservoir computing, which it learns the chaotic dynamics from data only, and physical modelling based on conservation laws, which extrapolates the dynamics when training data becomes unavailable. We show that the combination of the two approaches is able to accurately reproduce the velocity statistics and to predict the occurrence and amplitude of extreme events in a model of self-sustaining process in turbulence. In this flow, the extreme events are abrupt transitions from turbulent to quasi-laminar states, which are deterministic phenomena that cannot be traditionally predicted because of chaos. Furthermore, the physics-constrained machine learning method is shown to be robust with respect to noise. This work opens up new possibilities for synergistically enhancing data-driven methods with physical knowledge for the time-accurate prediction of chaotic flows.
A Novel Solution of Using Mixed Reality in Bowel and Oral and Maxillofacial Surgical Telepresence: 3D Mean Value Cloning algorithm
Mar 17, 2021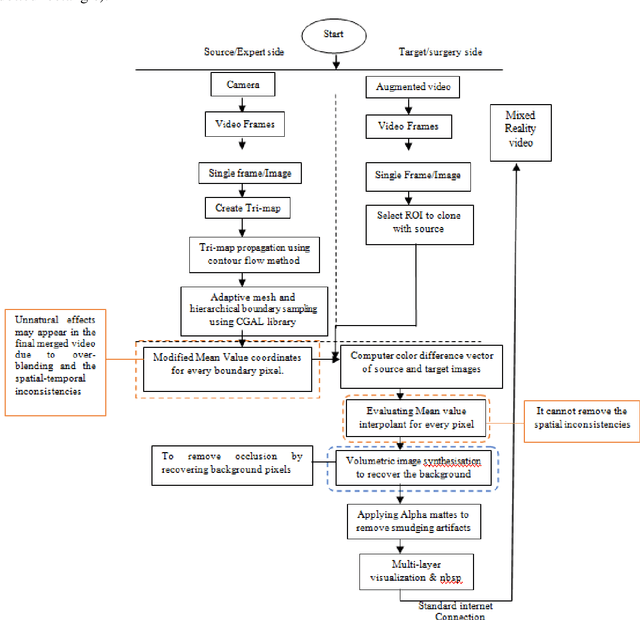
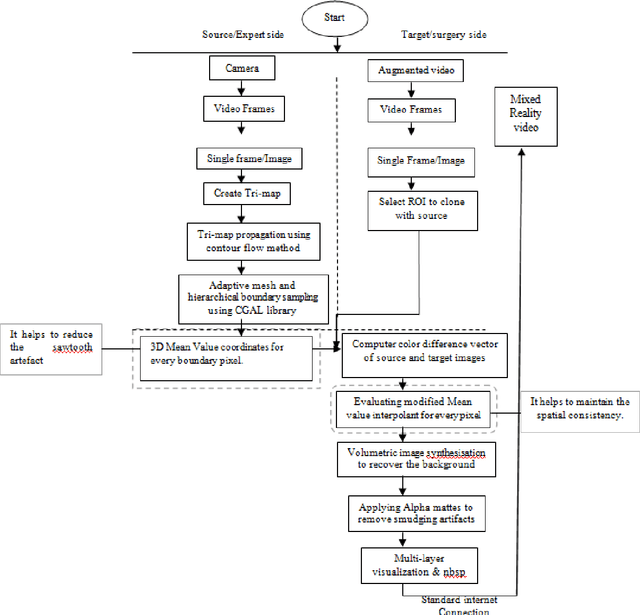

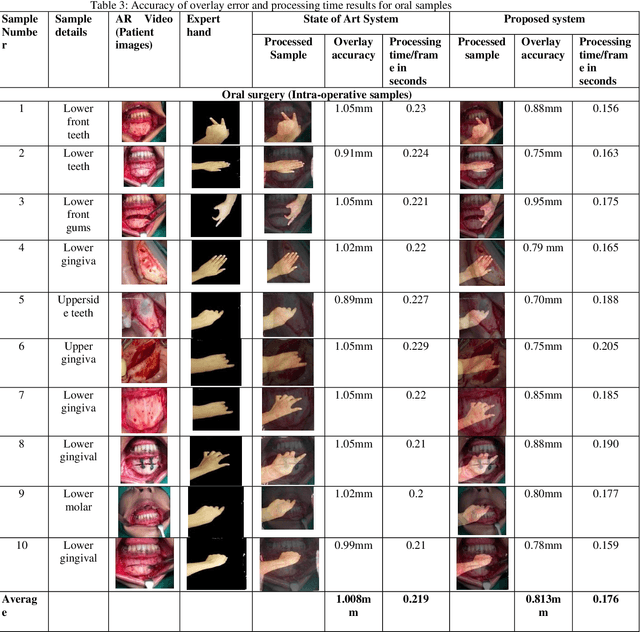
Background and aim: Most of the Mixed Reality models used in the surgical telepresence are suffering from discrepancies in the boundary area and spatial-temporal inconsistency due to the illumination variation in the video frames. The aim behind this work is to propose a new solution that helps produce the composite video by merging the augmented video of the surgery site and the virtual hand of the remote expertise surgeon. The purpose of the proposed solution is to decrease the processing time and enhance the accuracy of merged video by decreasing the overlay and visualization error and removing occlusion and artefacts. Methodology: The proposed system enhanced the mean value cloning algorithm that helps to maintain the spatial-temporal consistency of the final composite video. The enhanced algorithm includes the 3D mean value coordinates and improvised mean value interpolant in the image cloning process, which helps to reduce the sawtooth, smudging and discolouration artefacts around the blending region. Results: As compared to the state of the art solution, the accuracy in terms of overlay error of the proposed solution is improved from 1.01mm to 0.80mm whereas the accuracy in terms of visualization error is improved from 98.8% to 99.4%. The processing time is reduced to 0.173 seconds from 0.211 seconds. Conclusion: Our solution helps make the object of interest consistent with the light intensity of the target image by adding the space distance that helps maintain the spatial consistency in the final merged video.
* 27 pages
The Future of Intelligent Wavefront Shaping for Smart Radio Environments
Mar 30, 2021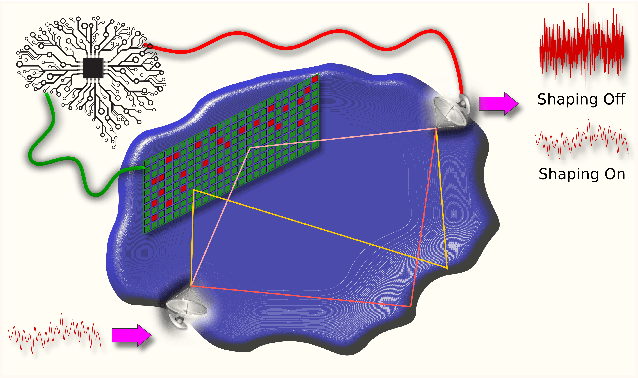
As the electromagnetic spectrum becomes more congested and the environments in which we need to operate become more complicated, control over the environment itself becomes necessary to ensure the integrity of wireless communication channels. Wavefront shaping with programmable metasurfaces allows wave fields to be manipulated in both time and space, providing a method to interact with the environment. When coupled with deep learning, intelligent wavefront shaping serves as a catalyst, enabling smart radio environments and unlocking applications beyond traditional wireless communication networks. In this paper, we discuss the outlook of intelligent wavefront shaping for wave propagation in complex environments and highlight its transformative potential.
FVNet: 3D Front-View Proposal Generation for Real-Time Object Detection from Point Clouds
Mar 26, 2019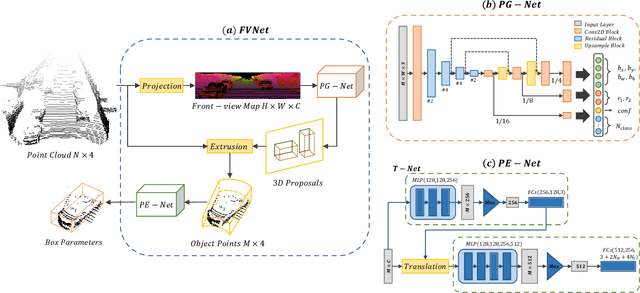
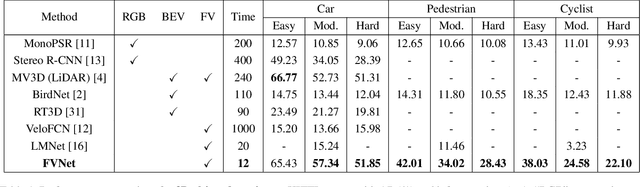
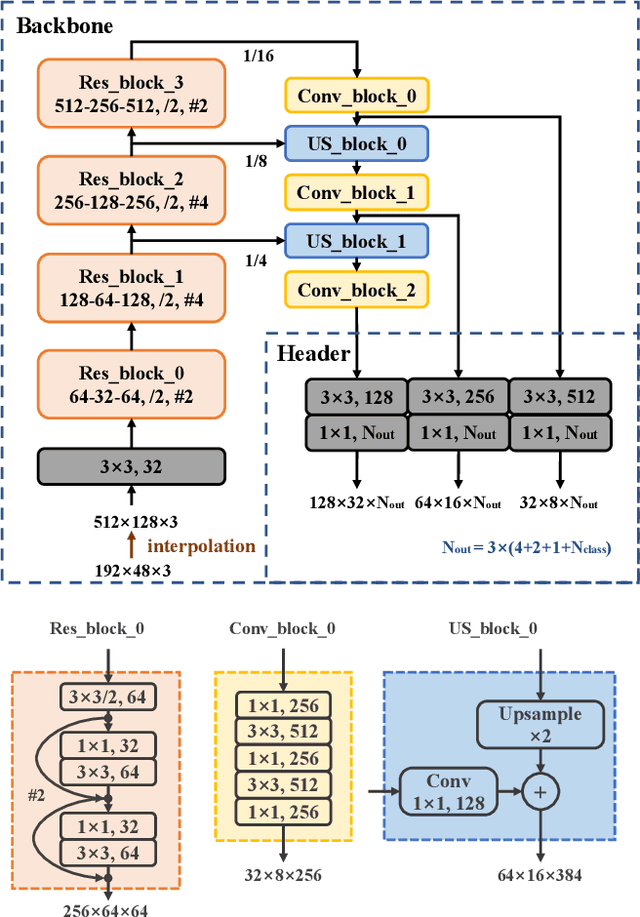
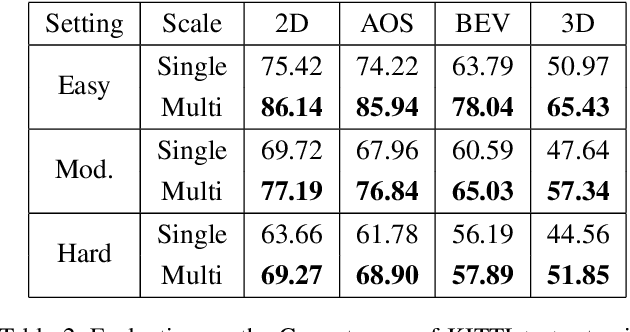
3D object detection from raw and sparse point clouds has been far less treated to date, compared with its 2D counterpart. In this paper, we propose a novel framework called FVNet for 3D front-view proposal generation and object detection from point clouds. It consists of two stages: generation of front-view proposals and estimation of 3D bounding box parameters. Instead of generating proposals from camera images or bird's-eye-view maps, we first project point clouds onto a cylindrical surface to generate front-view feature maps which retains rich information. We then introduce a proposal generation network to predict 3D region proposals from the generated maps and further extrude objects of interest from the whole point cloud. Finally, we present another network to extract the point-wise features from the extruded object points and regress the final 3D bounding box parameters in the canonical coordinates. Our framework achieves real-time performance with 12ms per point cloud sample. Extensive experiments on the 3D detection benchmark KITTI show that the proposed architecture outperforms state-of-the-art techniques which take either camera images or point clouds as input, in terms of accuracy and inference time.
Learning to Fairly Classify the Quality of WirelessLinks
Feb 23, 2021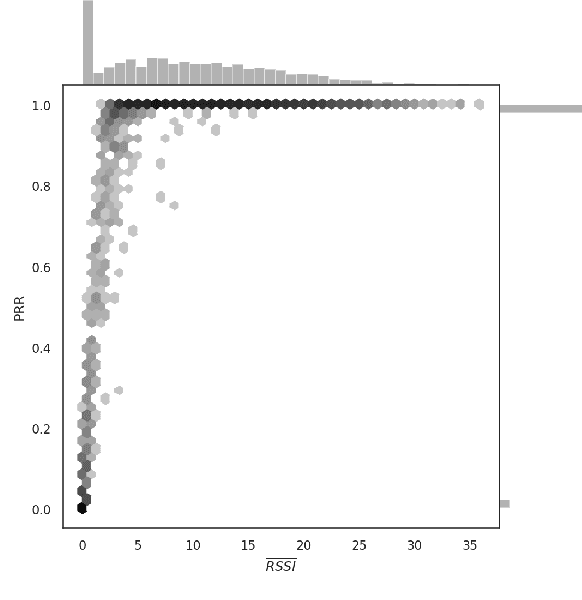
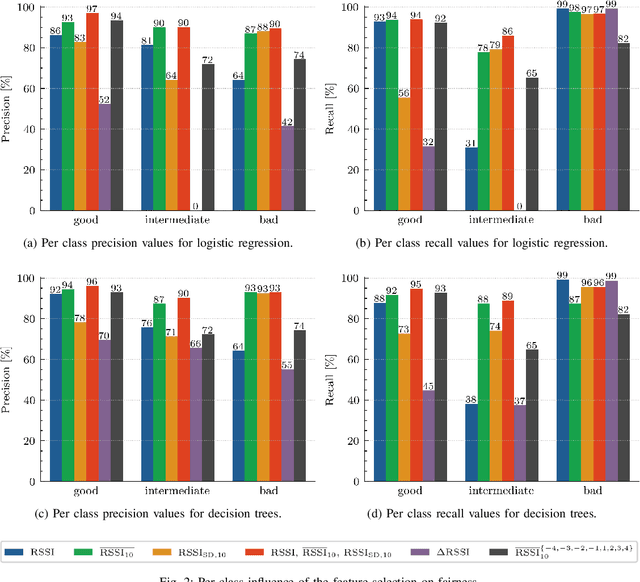
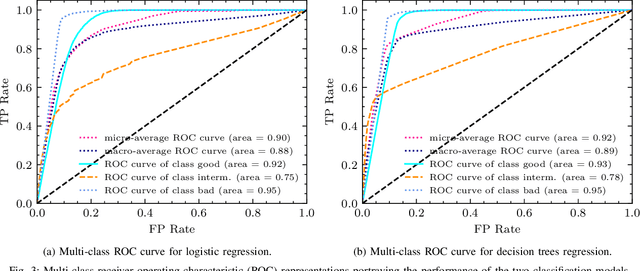

Machine learning (ML) has been used to develop increasingly accurate link quality estimators for wireless networks. However, more in-depth questions regarding the most suitable class of models, most suitable metrics and model performance on imbalanced datasets remain open. In this paper, we propose a new tree-based link quality classifier that meets high performance and fairly classifies the minority class and, at the same time, incurs low training cost. We compare the tree-based model, to a multilayer perceptron (MLP) non-linear model and two linear models, namely logistic regression (LR) and SVM, on a selected imbalanced dataset and evaluate their results using five different performance metrics. Our study shows that 1) non-linear models perform slightly better than linear models in general, 2) the proposed non-linear tree-based model yields the best performance trade-off considering F1, training time and fairness, 3) single metric aggregated evaluations based only on accuracy can hide poor, unfair performance especially on minority classes, and 4) it is possible to improve the performance on minority classes, by over 40% through feature selection and by over 20% through resampling, therefore leading to fairer classification results.
RoadMap: A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving
Jun 04, 2021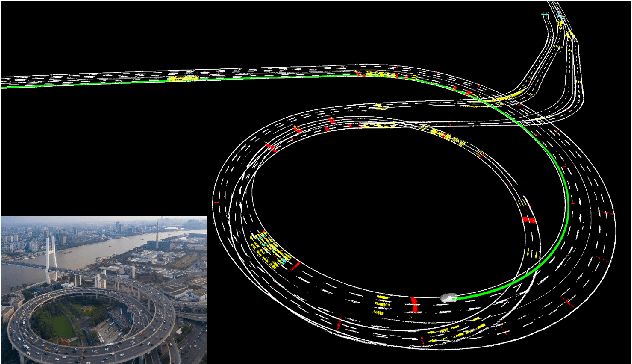
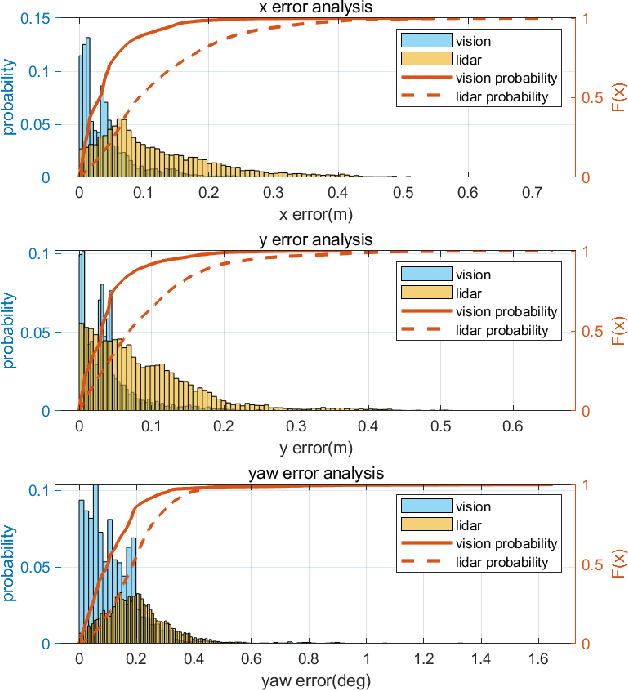

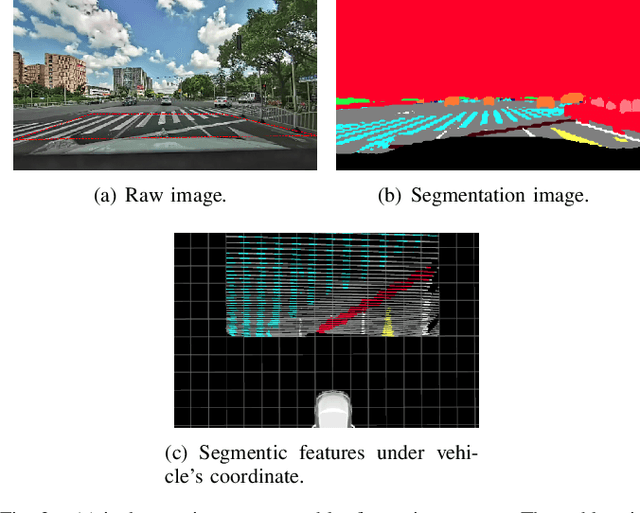
Accurate localization is of crucial importance for autonomous driving tasks. Nowadays, we have seen a lot of sensor-rich vehicles (e.g. Robo-taxi) driving on the street autonomously, which rely on high-accurate sensors (e.g. Lidar and RTK GPS) and high-resolution map. However, low-cost production cars cannot afford such high expenses on sensors and maps. How to reduce costs? How do sensor-rich vehicles benefit low-cost cars? In this paper, we proposed a light-weight localization solution, which relies on low-cost cameras and compact visual semantic maps. The map is easily produced and updated by sensor-rich vehicles in a crowd-sourced way. Specifically, the map consists of several semantic elements, such as lane line, crosswalk, ground sign, and stop line on the road surface. We introduce the whole framework of on-vehicle mapping, on-cloud maintenance, and user-end localization. The map data is collected and preprocessed on vehicles. Then, the crowd-sourced data is uploaded to a cloud server. The mass data from multiple vehicles are merged on the cloud so that the semantic map is updated in time. Finally, the semantic map is compressed and distributed to production cars, which use this map for localization. We validate the performance of the proposed map in real-world experiments and compare it against other algorithms. The average size of the semantic map is $36$ kb/km. We highlight that this framework is a reliable and practical localization solution for autonomous driving.
Self-supervised on Graphs: Contrastive, Generative,or Predictive
May 16, 2021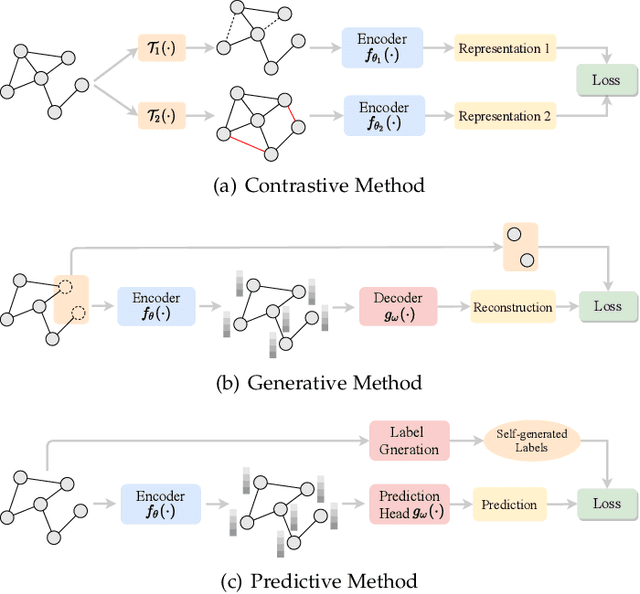
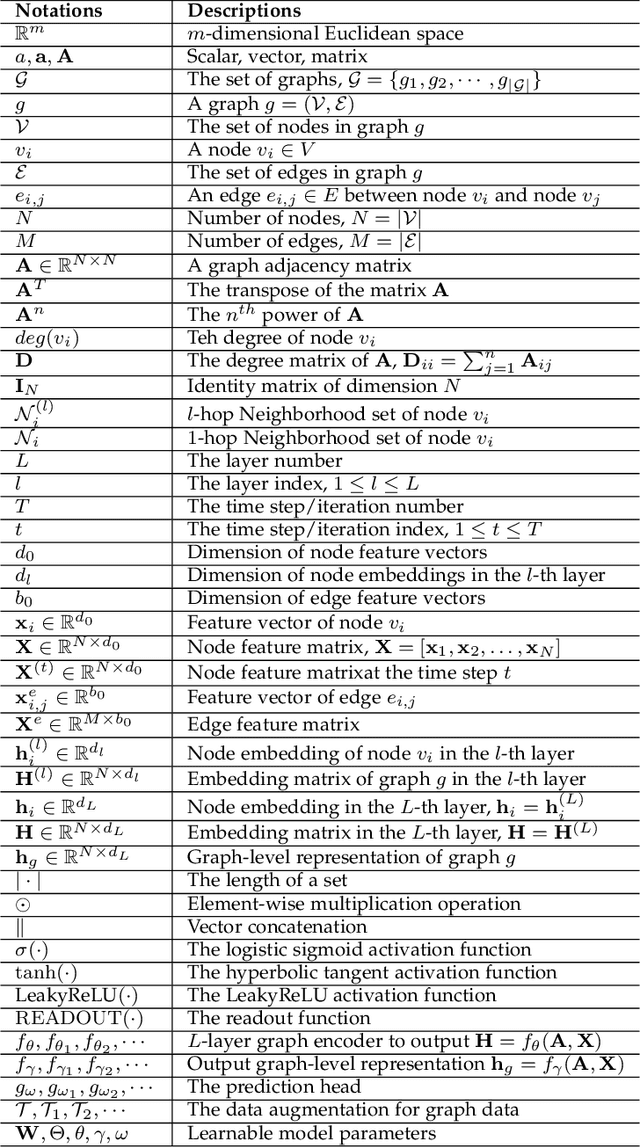
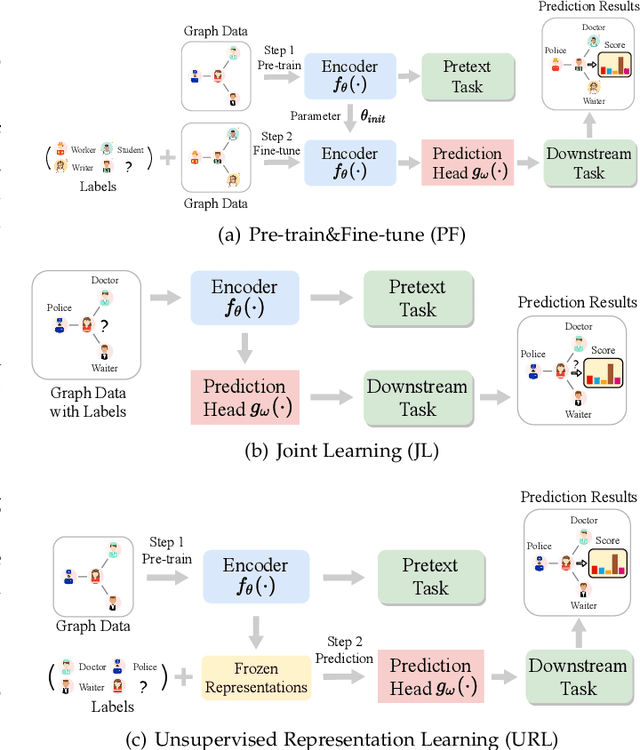
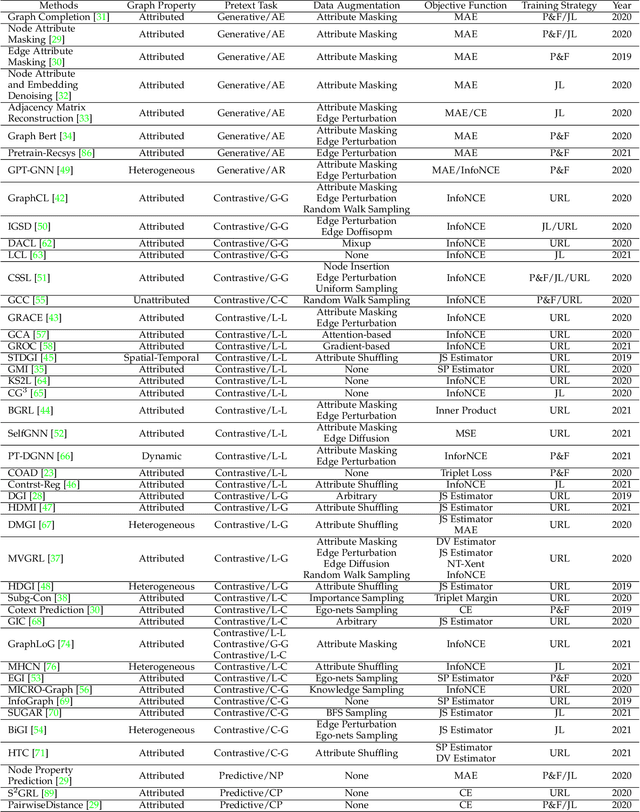
Deep learning on graphs has recently achieved remarkable success on a variety of tasks while such success relies heavily on the massive and carefully labeled data. However, precise annotations are generally very expensive and time-consuming. To address this problem, self-supervised learning (SSL) is emerging as a new paradigm for extracting informative knowledge through well-designed pretext tasks without relying on manual labels. In this survey, we extend the concept of SSL, which first emerged in the fields of computer vision and natural language processing, to present a timely and comprehensive review of the existing SSL techniques for graph data. Specifically, we divide existing graph SSL methods into three categories: contrastive, generative, and predictive. More importantly, unlike many other surveys that only provide a high-level description of published research, we present an additional mathematical summary of the existing works in a unified framework. Furthermore, to facilitate methodological development and empirical comparisons, we also summarize the commonly used datasets, evaluation metrics, downstream tasks, and open-source implementations of various algorithms. Finally, we discuss the technical challenges and potential future directions for improving graph self-supervised learning.