 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Exploration into why Output Regularization Mitigates Label Noise
Apr 26, 2021
Label noise presents a real challenge for supervised learning algorithms. Consequently, mitigating label noise has attracted immense research in recent years. Noise robust losses is one of the more promising approaches for dealing with label noise, as these methods only require changing the loss function and do not require changing the design of the classifier itself, which can be expensive in terms of development time. In this work we focus on losses that use output regularization (such as label smoothing and entropy). Although these losses perform well in practice, their ability to mitigate label noise lack mathematical rigor. In this work we aim at closing this gap by showing that losses, which incorporate an output regularization term, become symmetric as the regularization coefficient goes to infinity. We argue that the regularization coefficient can be seen as a hyper-parameter controlling the symmetricity, and thus, the noise robustness of the loss function.
Approximately Solving Mean Field Games via Entropy-Regularized Deep Reinforcement Learning
Feb 02, 2021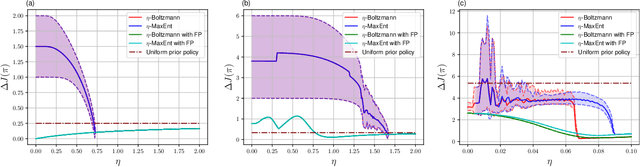

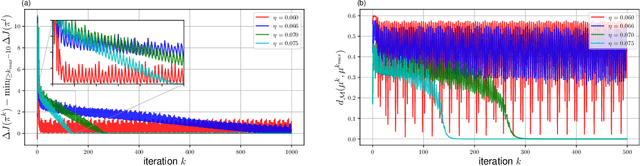
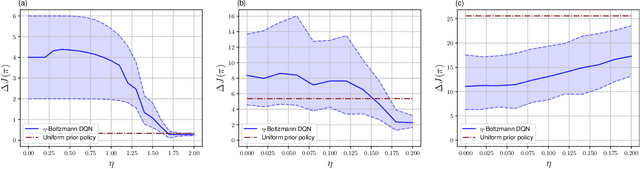
The recent mean field game (MFG) formalism facilitates otherwise intractable computation of approximate Nash equilibria in many-agent settings. In this paper, we consider discrete-time finite MFGs subject to finite-horizon objectives. We show that all discrete-time finite MFGs with non-constant fixed point operators fail to be contractive as typically assumed in existing MFG literature, barring convergence via fixed point iteration. Instead, we incorporate entropy-regularization and Boltzmann policies into the fixed point iteration. As a result, we obtain provable convergence to approximate fixed points where existing methods fail, and reach the original goal of approximate Nash equilibria. All proposed methods are evaluated with respect to their exploitability, on both instructive examples with tractable exact solutions and high-dimensional problems where exact methods become intractable. In high-dimensional scenarios, we apply established deep reinforcement learning methods and empirically combine fictitious play with our approximations.
Dynamic Pooling Improves Nanopore Base Calling Accuracy
May 16, 2021

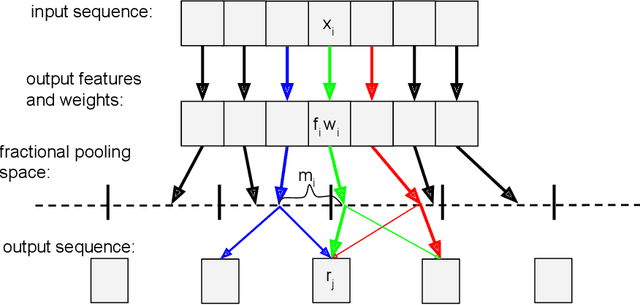
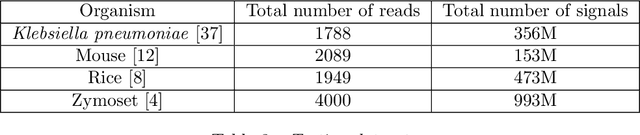
In nanopore sequencing, electrical signal is measured as DNA molecules pass through the sequencing pores. Translating these signals into DNA bases (base calling) is a highly non-trivial task, and its quality has a large impact on the sequencing accuracy. The most successful nanopore base callers to date use convolutional neural networks (CNN) to accomplish the task. Convolutional layers in CNNs are typically composed of filters with constant window size, performing best in analysis of signals with uniform speed. However, the speed of nanopore sequencing varies greatly both within reads and between sequencing runs. Here, we present dynamic pooling, a novel neural network component, which addresses this problem by adaptively adjusting the pooling ratio. To demonstrate the usefulness of dynamic pooling, we developed two base callers: Heron and Osprey. Heron improves the accuracy beyond the experimental high-accuracy base caller Bonito developed by Oxford Nanopore. Osprey is a fast base caller that can compete in accuracy with Guppy high-accuracy mode, but does not require GPU acceleration and achieves a near real-time speed on common desktop CPUs. Availability: https://github.com/fmfi-compbio/osprey, https://github.com/fmfi-compbio/heron Keywords: nanopore sequencing, base calling, convolutional neural networks, pooling
Robust High-speed Running for Quadruped Robots via Deep Reinforcement Learning
Mar 11, 2021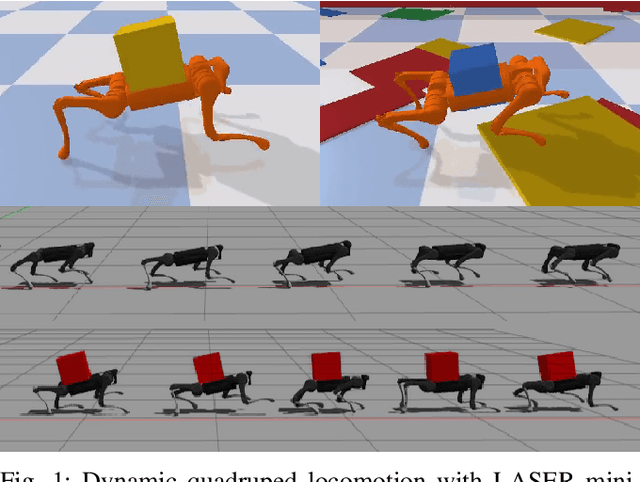
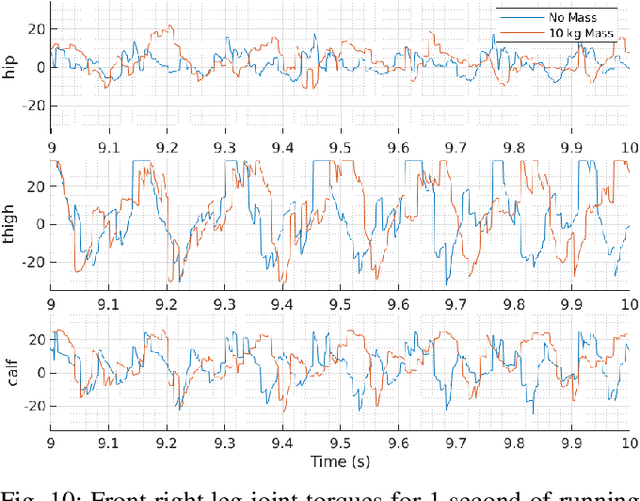
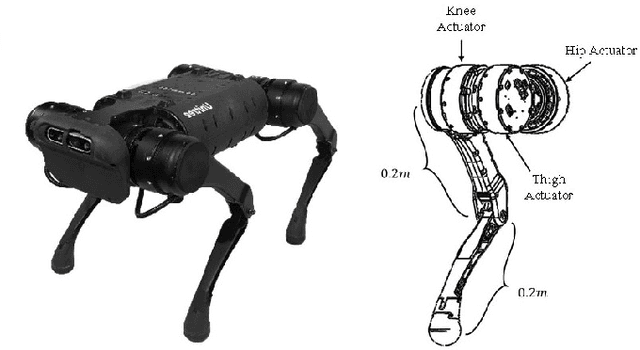

Deep reinforcement learning has emerged as a popular and powerful way to develop locomotion controllers for quadruped robots. Common approaches have largely focused on learning actions directly in joint space, or learning to modify and offset foot positions produced by trajectory generators. Both approaches typically require careful reward shaping and training for millions of time steps, and with trajectory generators introduce human bias into the resulting control policies. In this paper, we instead explore learning foot positions in Cartesian space, which we track with impedance control, for a task of running as fast as possible subject to environmental disturbances. Compared with other action spaces, we observe less needed reward shaping, much improved sample efficiency, the emergence of natural gaits such as galloping and bounding, and ease of sim-to-sim transfer. Policies can be learned in only a few million time steps, even for challenging tasks of running over rough terrain with loads of over 100% of the nominal quadruped mass. Training occurs in PyBullet, and we perform a sim-to-sim transfer to Gazebo, where our quadruped is able to run at over 4 m/s without a load, and 3.5 m/s with a 10 kg load, which is over 83% of the nominal quadruped mass. Video results can be found at https://youtu.be/roE1vxpEWfw.
Learning to Fairly Classify the Quality of Wireless Links
Feb 24, 2021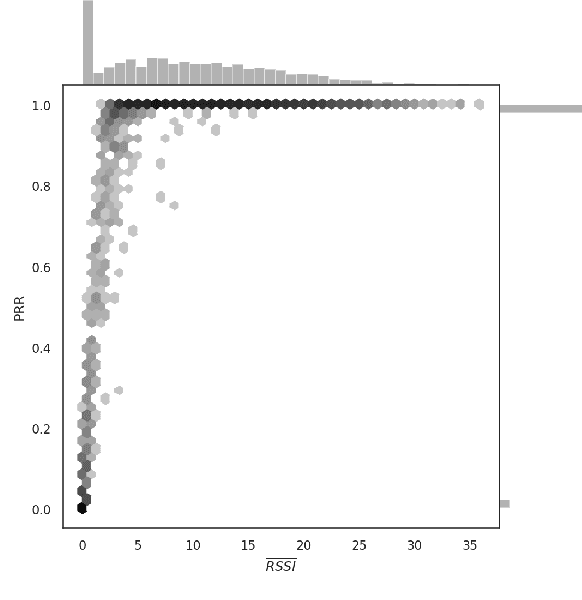
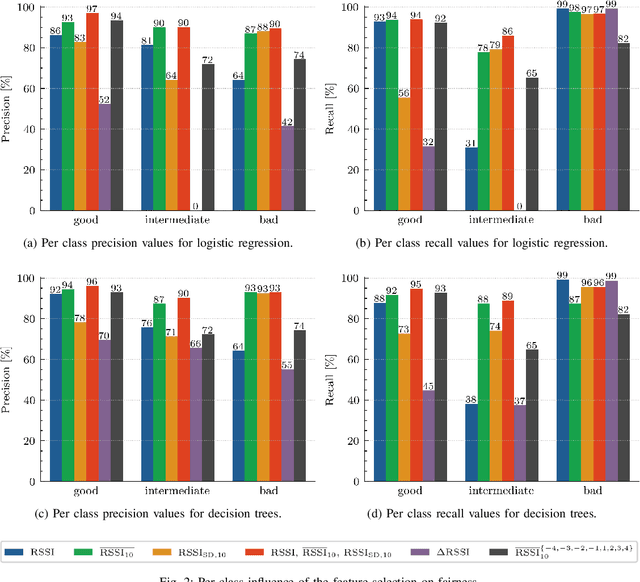
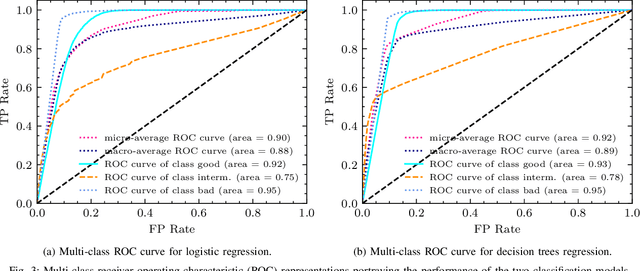

Machine learning (ML) has been used to develop increasingly accurate link quality estimators for wireless networks. However, more in-depth questions regarding the most suitable class of models, most suitable metrics and model performance on imbalanced datasets remain open. In this paper, we propose a new tree-based link quality classifier that meets high performance and fairly classifies the minority class and, at the same time, incurs low training cost. We compare the tree-based model, to a multilayer perceptron (MLP) non-linear model and two linear models, namely logistic regression (LR) and SVM, on a selected imbalanced dataset and evaluate their results using five different performance metrics. Our study shows that 1) non-linear models perform slightly better than linear models in general, 2) the proposed non-linear tree-based model yields the best performance trade-off considering F1, training time and fairness, 3) single metric aggregated evaluations based only on accuracy can hide poor, unfair performance especially on minority classes, and 4) it is possible to improve the performance on minority classes, by over 40% through feature selection and by over 20% through resampling, therefore leading to fairer classification results.
Neural Clinical Event Sequence Prediction through Personalized Online Adaptive Learning
Apr 06, 2021
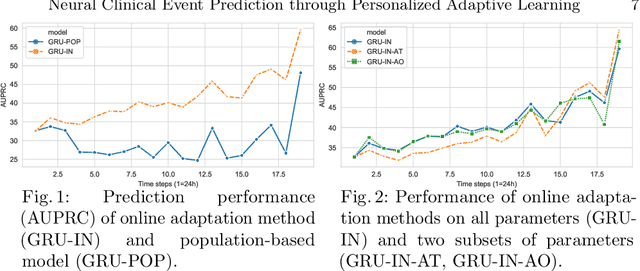
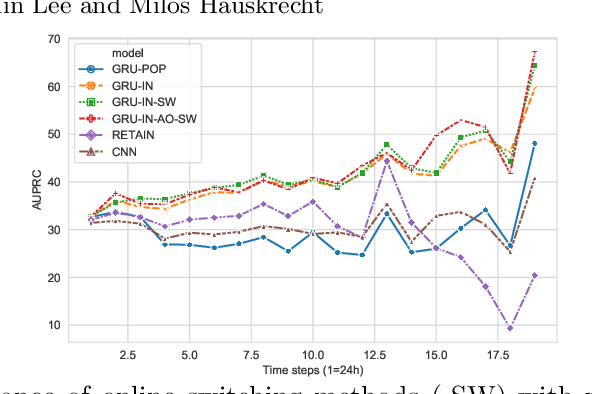
Clinical event sequences consist of thousands of clinical events that represent records of patient care in time. Developing accurate prediction models for such sequences is of a great importance for defining representations of a patient state and for improving patient care. One important challenge of learning a good predictive model of clinical sequences is patient-specific variability. Based on underlying clinical complications, each patient's sequence may consist of different sets of clinical events. However, population-based models learned from such sequences may not accurately predict patient-specific dynamics of event sequences. To address the problem, we develop a new adaptive event sequence prediction framework that learns to adjust its prediction for individual patients through an online model update.
Gaussian Experts Selection using Graphical Models
Feb 02, 2021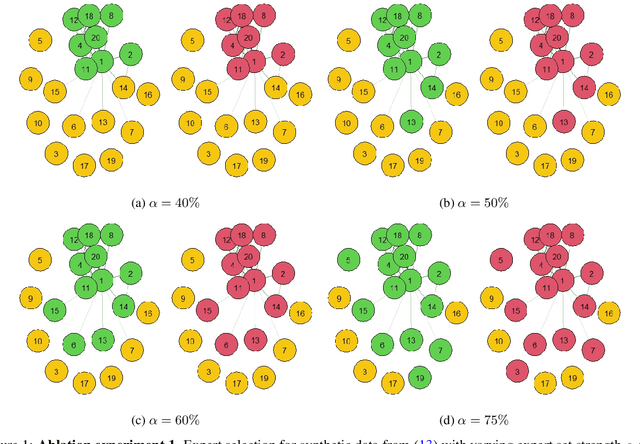
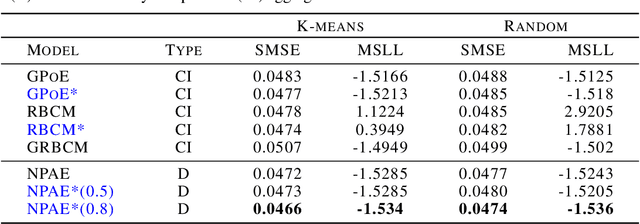
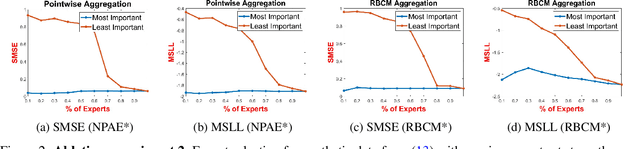
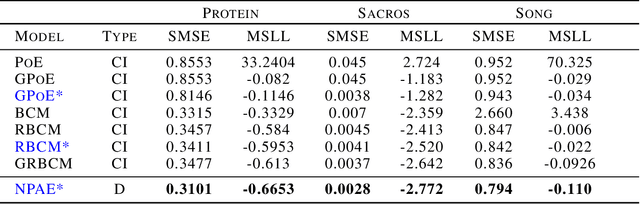
Local approximations are popular methods to scale Gaussian processes (GPs) to big data. Local approximations reduce time complexity by dividing the original dataset into subsets and training a local expert on each subset. Aggregating the experts' prediction is done assuming either conditional dependence or independence between the experts. Imposing the \emph{conditional independence assumption} (CI) between the experts renders the aggregation of different expert predictions time efficient at the cost of poor uncertainty quantification. On the other hand, modeling dependent experts can provide precise predictions and uncertainty quantification at the expense of impractically high computational costs. By eliminating weak experts via a theory-guided expert selection step, we substantially reduce the computational cost of aggregating dependent experts while ensuring calibrated uncertainty quantification. We leverage techniques from the literature on undirected graphical models, using sparse precision matrices that encode conditional dependencies between experts to select the most important experts. Moreov
Good Practices and A Strong Baseline for Traffic Anomaly Detection
May 09, 2021
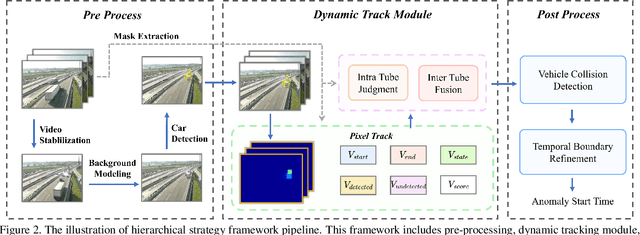
The detection of traffic anomalies is a critical component of the intelligent city transportation management system. Previous works have proposed a variety of notable insights and taken a step forward in this field, however, dealing with the complex traffic environment remains a challenge. Moreover, the lack of high-quality data and the complexity of the traffic scene, motivate us to study this problem from a hand-crafted perspective. In this paper, we propose a straightforward and efficient framework that includes pre-processing, a dynamic track module, and post-processing. With video stabilization, background modeling, and vehicle detection, the pro-processing phase aims to generate candidate anomalies. The dynamic tracking module seeks and locates the start time of anomalies by utilizing vehicle motion patterns and spatiotemporal status. Finally, we use post-processing to fine-tune the temporal boundary of anomalies. Not surprisingly, our proposed framework was ranked $1^{st}$ in the NVIDIA AI CITY 2021 leaderboard for traffic anomaly detection. The code is available at: https://github.com/Endeavour10020/AICity2021-Anomaly-Detection .
The DKU System Description for The Interspeech 2021 Auto-KWS Challenge
Apr 11, 2021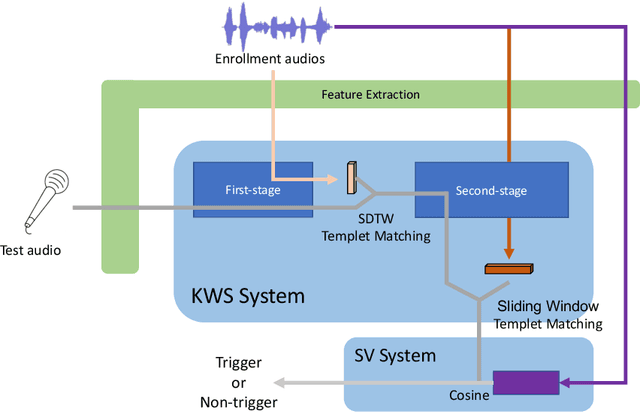
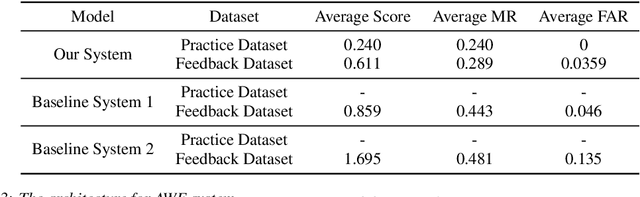
This paper introduces the system submitted by the DKU-SMIIP team for the Auto-KWS 2021 Challenge. Our implementation consists of a two-stage keyword spotting system based on query-by-example spoken term detection and a speaker verification system. We employ two different detection algorithms in our proposed keyword spotting system. The first stage adopts subsequence dynamic time warping for template matching based on frame-level language-independent bottleneck feature and phoneme posterior probability. We use a sliding window template matching algorithm based on acoustic word embeddings to further verify the detection from the first stage. As a result, our KWS system achieves an average score of 0.61 on the feedback dataset, which outperforms the baseline1 system by 0.25.
NorDial: A Preliminary Corpus of Written Norwegian Dialect Use
Apr 11, 2021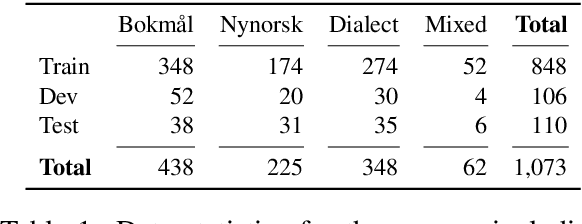
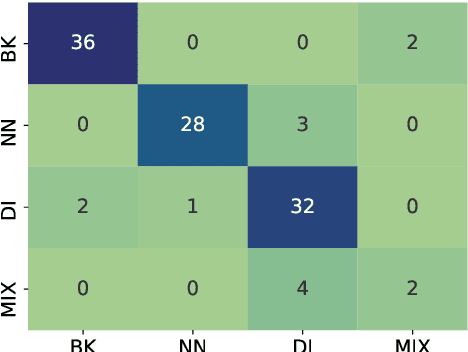
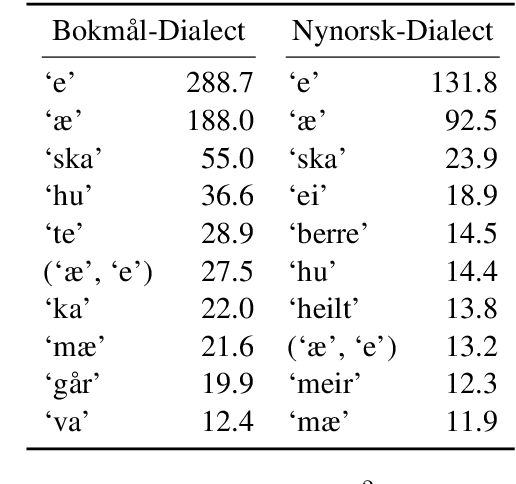
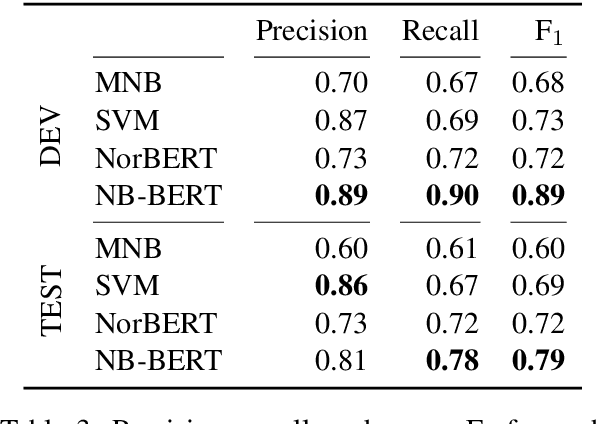
Norway has a large amount of dialectal variation, as well as a general tolerance to its use in the public sphere. There are, however, few available resources to study this variation and its change over time and in more informal areas, \eg on social media. In this paper, we propose a first step to creating a corpus of dialectal variation of written Norwegian. We collect a small corpus of tweets and manually annotate them as Bokm{\aa}l, Nynorsk, any dialect, or a mix. We further perform preliminary experiments with state-of-the-art models, as well as an analysis of the data to expand this corpus in the future. Finally, we make the annotations and models available for future work.