 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Breaking The Dimension Dependence in Sparse Distribution Estimation under Communication Constraints
Jun 16, 2021
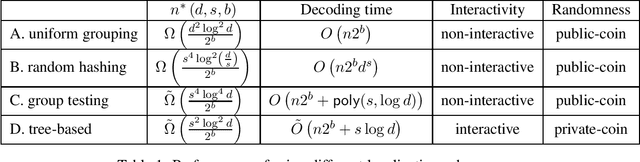
We consider the problem of estimating a $d$-dimensional $s$-sparse discrete distribution from its samples observed under a $b$-bit communication constraint. The best-known previous result on $\ell_2$ estimation error for this problem is $O\left( \frac{s\log\left( {d}/{s}\right)}{n2^b}\right)$. Surprisingly, we show that when sample size $n$ exceeds a minimum threshold $n^*(s, d, b)$, we can achieve an $\ell_2$ estimation error of $O\left( \frac{s}{n2^b}\right)$. This implies that when $n>n^*(s, d, b)$ the convergence rate does not depend on the ambient dimension $d$ and is the same as knowing the support of the distribution beforehand. We next ask the question: ``what is the minimum $n^*(s, d, b)$ that allows dimension-free convergence?''. To upper bound $n^*(s, d, b)$, we develop novel localization schemes to accurately and efficiently localize the unknown support. For the non-interactive setting, we show that $n^*(s, d, b) = O\left( \min \left( {d^2\log^2 d}/{2^b}, {s^4\log^2 d}/{2^b}\right) \right)$. Moreover, we connect the problem with non-adaptive group testing and obtain a polynomial-time estimation scheme when $n = \tilde{\Omega}\left({s^4\log^4 d}/{2^b}\right)$. This group testing based scheme is adaptive to the sparsity parameter $s$, and hence can be applied without knowing it. For the interactive setting, we propose a novel tree-based estimation scheme and show that the minimum sample-size needed to achieve dimension-free convergence can be further reduced to $n^*(s, d, b) = \tilde{O}\left( {s^2\log^2 d}/{2^b} \right)$.
Active Screening for Recurrent Diseases: A Reinforcement Learning Approach
Jan 07, 2021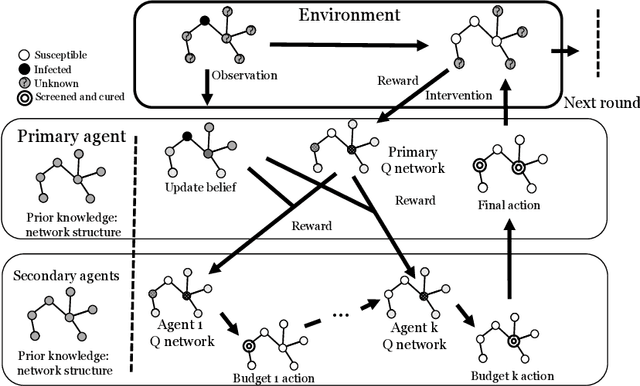
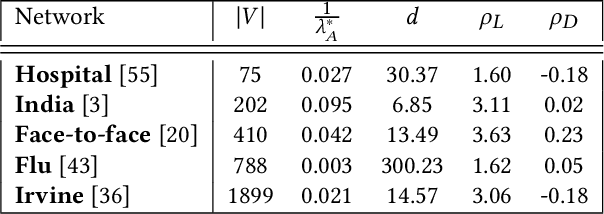
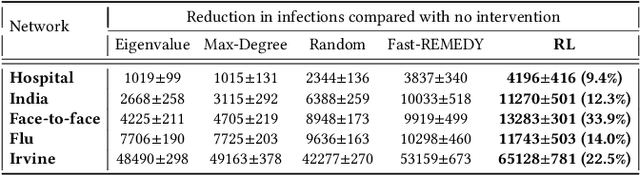
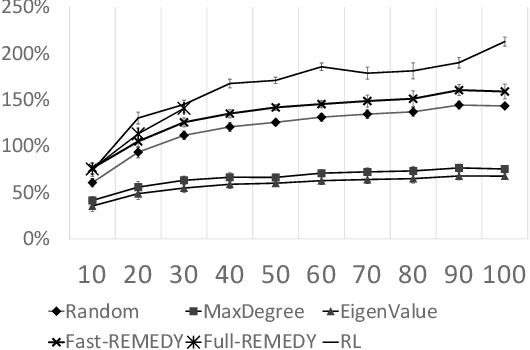
Active screening is a common approach in controlling the spread of recurring infectious diseases such as tuberculosis and influenza. In this approach, health workers periodically select a subset of population for screening. However, given the limited number of health workers, only a small subset of the population can be visited in any given time period. Given the recurrent nature of the disease and rapid spreading, the goal is to minimize the number of infections over a long time horizon. Active screening can be formalized as a sequential combinatorial optimization over the network of people and their connections. The main computational challenges in this formalization arise from i) the combinatorial nature of the problem, ii) the need of sequential planning and iii) the uncertainties in the infectiousness states of the population. Previous works on active screening fail to scale to large time horizon while fully considering the future effect of current interventions. In this paper, we propose a novel reinforcement learning (RL) approach based on Deep Q-Networks (DQN), with several innovative adaptations that are designed to address the above challenges. First, we use graph convolutional networks (GCNs) to represent the Q-function that exploit the node correlations of the underlying contact network. Second, to avoid solving a combinatorial optimization problem in each time period, we decompose the node set selection as a sub-sequence of decisions, and further design a two-level RL framework that solves the problem in a hierarchical way. Finally, to speed-up the slow convergence of RL which arises from reward sparseness, we incorporate ideas from curriculum learning into our hierarchical RL approach. We evaluate our RL algorithm on several real-world networks.
Robust Dynamic Network Embedding via Ensembles
May 30, 2021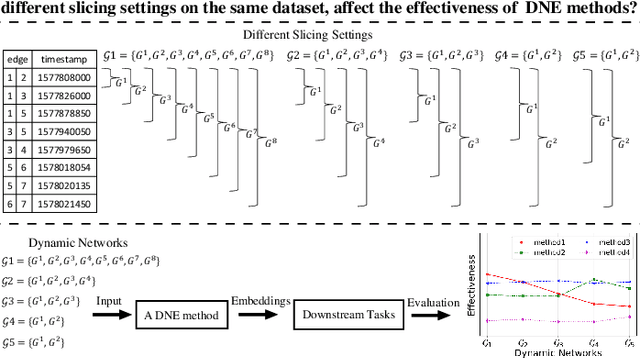
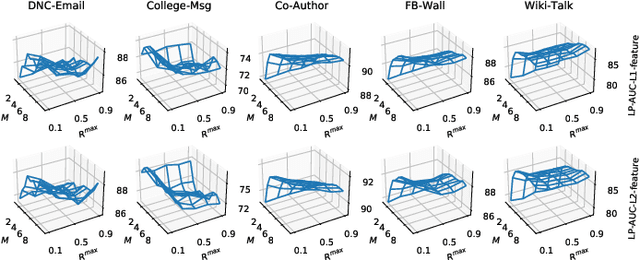
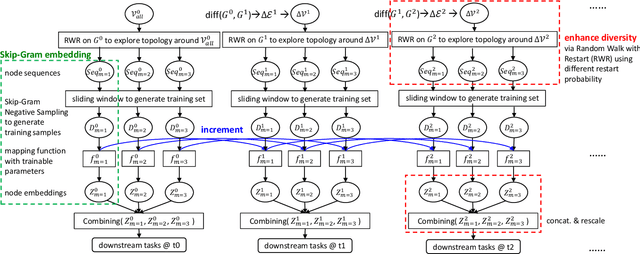
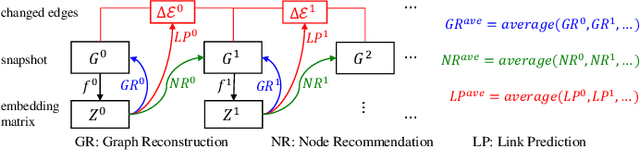
Dynamic Network Embedding (DNE) has recently attracted considerable attention due to the advantage of network embedding in various applications and the dynamic nature of many real-world networks. For dynamic networks, the degree of changes, i.e., defined as the averaged number of changed edges between consecutive snapshots spanning a dynamic network, could be very different in real-world scenarios. Although quite a few DNE methods have been proposed, it still remains unclear that whether and to what extent the existing DNE methods are robust to the degree of changes, which is however an important factor in both academic research and industrial applications. In this work, we investigate the robustness issue of DNE methods w.r.t. the degree of changes for the first time and accordingly, propose a robust DNE method. Specifically, the proposed method follows the notion of ensembles where the base learner adopts an incremental Skip-Gram neural embedding approach. To further boost the performance, a novel strategy is proposed to enhance the diversity among base learners at each timestep by capturing different levels of local-global topology. Extensive experiments demonstrate the benefits of special designs in the proposed method, and the superior performance of the proposed method compared to state-of-the-art methods. The comparative study also reveals the robustness issue of some DNE methods. The source code is available at https://github.com/houchengbin/SG-EDNE
"Grip-that-there": An Investigation of Explicit and Implicit Task Allocation Techniques for Human-Robot Collaboration
Feb 03, 2021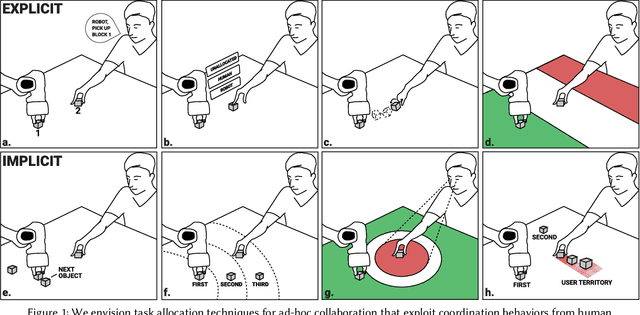

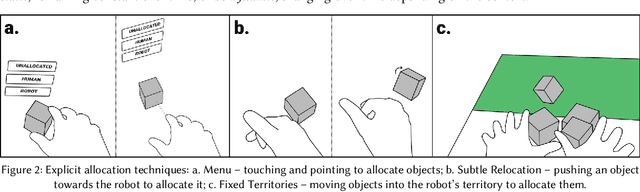
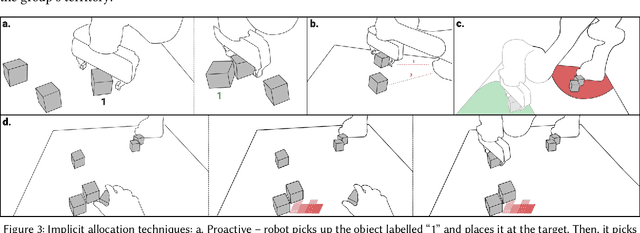
In ad-hoc human-robot collaboration (HRC), humans and robots work on a task without pre-planning the robot's actions prior to execution; instead, task allocation occurs in real-time. However, prior research has largely focused on task allocations that are pre-planned - there has not been a comprehensive exploration or evaluation of techniques where task allocation is adjusted in real-time. Inspired by HCI research on territoriality and proxemics, we propose a design space of novel task allocation techniques including both explicit techniques, where the user maintains agency, and implicit techniques, where the efficiency of automation can be leveraged. The techniques were implemented and evaluated using a tabletop HRC simulation in VR. A 16-participant study, which presented variations of a collaborative block stacking task, showed that implicit techniques enable efficient task completion and task parallelization, and should be augmented with explicit mechanisms to provide users with fine-grained control.
SkiffOS: Minimal Cross-compiled Linux for Embedded Containers
Mar 31, 2021Embedded Linux processors are increasingly used for real-time computing tasks such as robotics and Internet of Things (IoT). These applications require robust and reproducible behavior from the host OS, commonly achieved through immutable firmware stored in read-only memory. SkiffOS addresses these requirements with a minimal cross-compiled GNU/Linux system optimized for hosting containerized distributions and applications, and a configuration layering system for the Buildroot embedded cross-compiler tool which automatically re-targets system configurations to any platform or device. This approach cleanly separates the hardware support from the applications. The host system and containers are independently upgraded and backed-up over-the-air (OTA).
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 05, 2021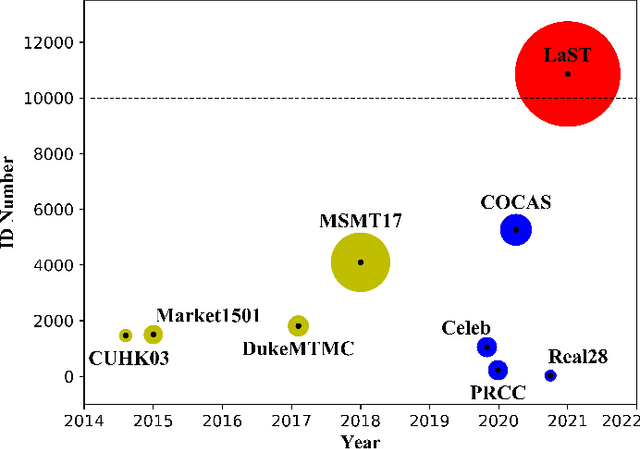
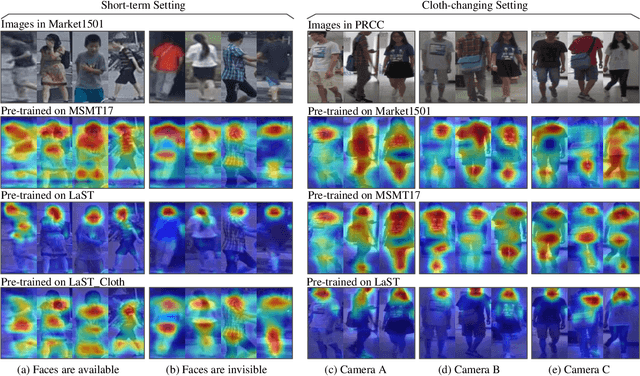
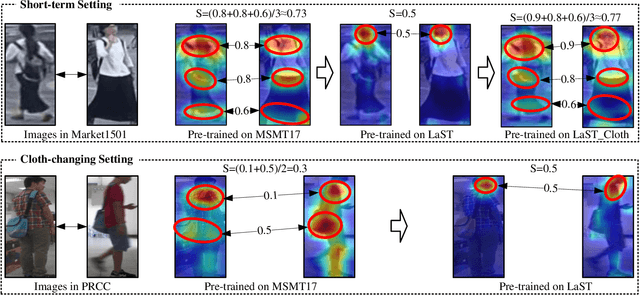

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal (LaST) person re-ID dataset, including 10,860 identities with more than 224k images. Compared with existing datasets, LaST presents more challenging and high-diversity reID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatiotemporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.
Pedestrian Collision Avoidance for Autonomous Vehicles at Unsignalized Intersection Using Deep Q-Network
May 01, 2021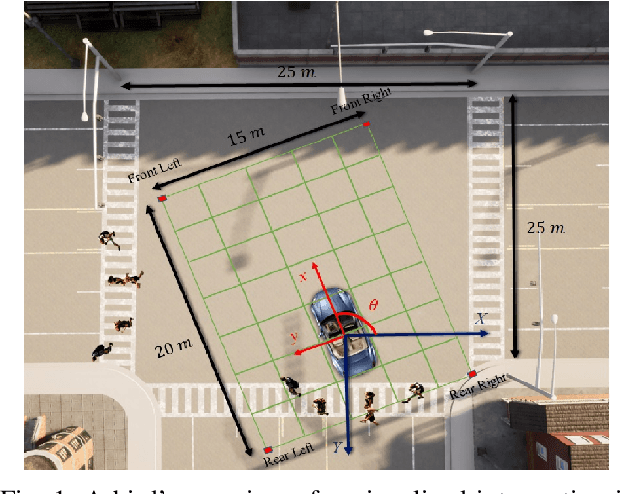
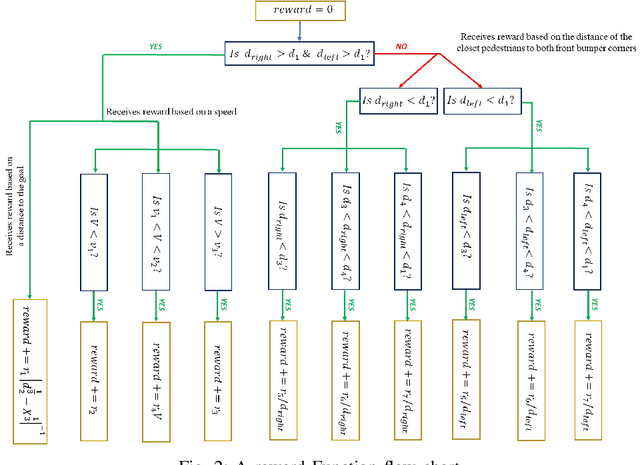
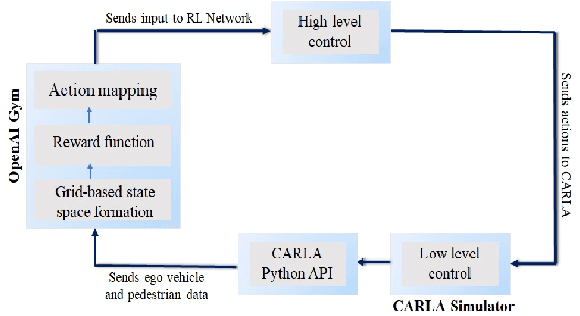
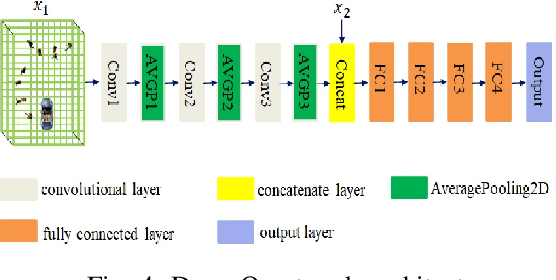
Prior research has extensively explored Autonomous Vehicle (AV) navigation in the presence of other vehicles, however, navigation among pedestrians, who are the most vulnerable element in urban environments, has been less examined. This paper explores AV navigation in crowded, unsignalized intersections. We compare the performance of different deep reinforcement learning methods trained on our reward function and state representation. The performance of these methods and a standard rule-based approach were evaluated in two ways, first at the unsignalized intersection on which the methods were trained, and secondly at an unknown unsignalized intersection with a different topology. For both scenarios, the rule-based method achieves less than 40\% collision-free episodes, whereas our methods result in a performance of approximately 100\%. Of the three methods used, DDQN/PER outperforms the other two methods while it also shows the smallest average intersection crossing time, the greatest average speed, and the greatest distance from the closest pedestrian.
LRTuner: A Learning Rate Tuner for Deep Neural Networks
May 30, 2021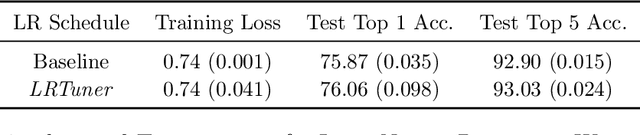
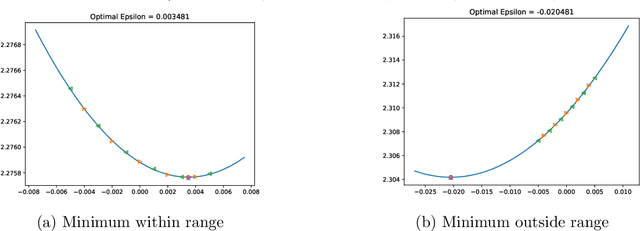
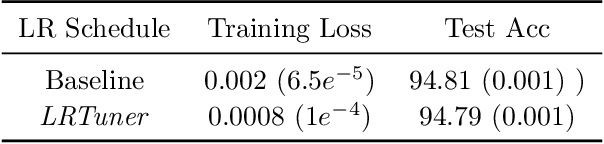
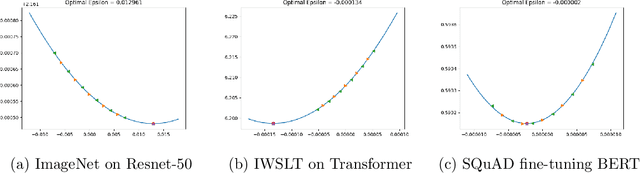
One very important hyperparameter for training deep neural networks is the learning rate schedule of the optimizer. The choice of learning rate schedule determines the computational cost of getting close to a minima, how close you actually get to the minima, and most importantly the kind of local minima (wide/narrow) attained. The kind of minima attained has a significant impact on the generalization accuracy of the network. Current systems employ hand tuned learning rate schedules, which are painstakingly tuned for each network and dataset. Given that the state space of schedules is huge, finding a satisfactory learning rate schedule can be very time consuming. In this paper, we present LRTuner, a method for tuning the learning rate as training proceeds. Our method works with any optimizer, and we demonstrate results on SGD with Momentum, and Adam optimizers. We extensively evaluate LRTuner on multiple datasets, models, and across optimizers. We compare favorably against standard learning rate schedules for the given dataset and models, including ImageNet on Resnet-50, Cifar-10 on Resnet-18, and SQuAD fine-tuning on BERT. For example on ImageNet with Resnet-50, LRTuner shows up to 0.2% absolute gains in test accuracy compared to the hand-tuned baseline schedule. Moreover, LRTuner can achieve the same accuracy as the baseline schedule in 29% less optimization steps.
Sample-efficient Plasma Spray Process Configuration with Constrained Bayesian Optimization
Mar 25, 2021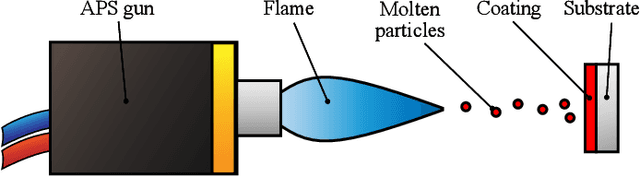
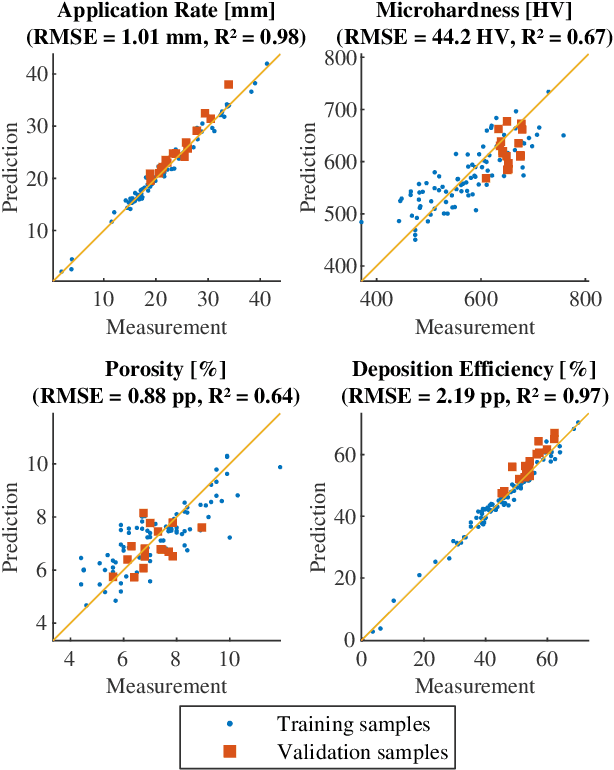

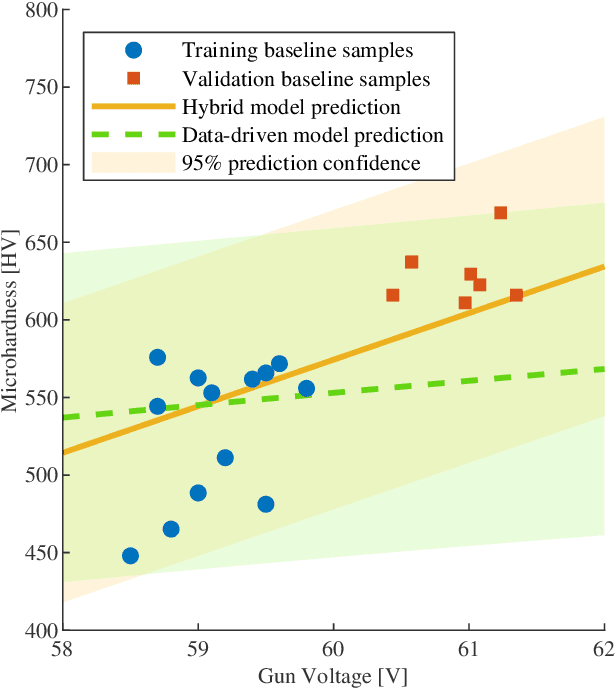
Recent work has shown constrained Bayesian optimization to be a powerful technique for the optimization of industrial processes. We adapt this framework to the set-up and optimization of atmospheric plasma spraying processes. We propose and validate a Gaussian process modeling structure to predict coatings properties. We introduce a parallel acquisition procedure tailored on the process characteristics and propose an algorithm that adapts to real-time process measurements to improve reproducibility. We validate our optimization method numerically and experimentally, and demonstrate that it can efficiently find input parameters that produce the desired coating and minimize the process cost.
Problem-solving benefits of down-sampled lexicase selection
Jun 10, 2021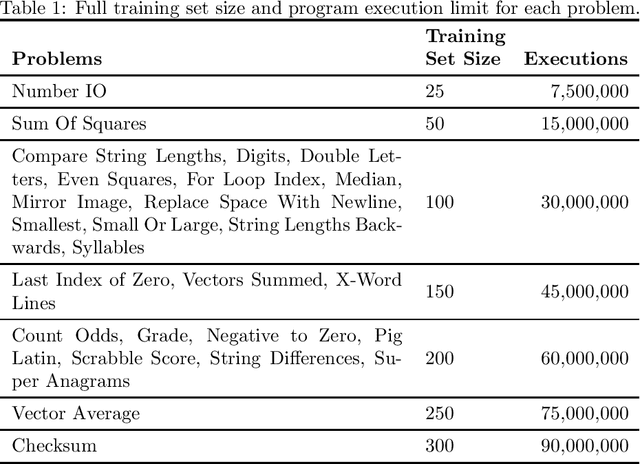

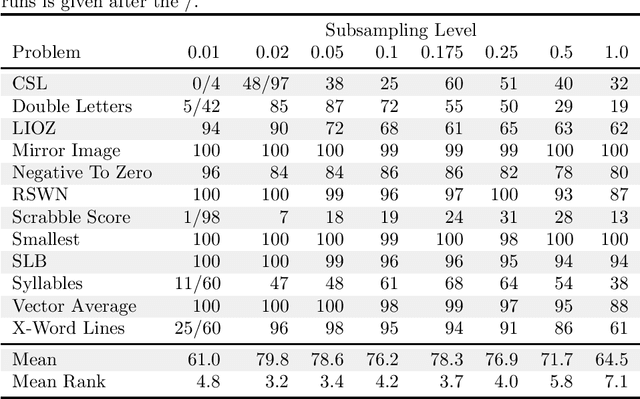
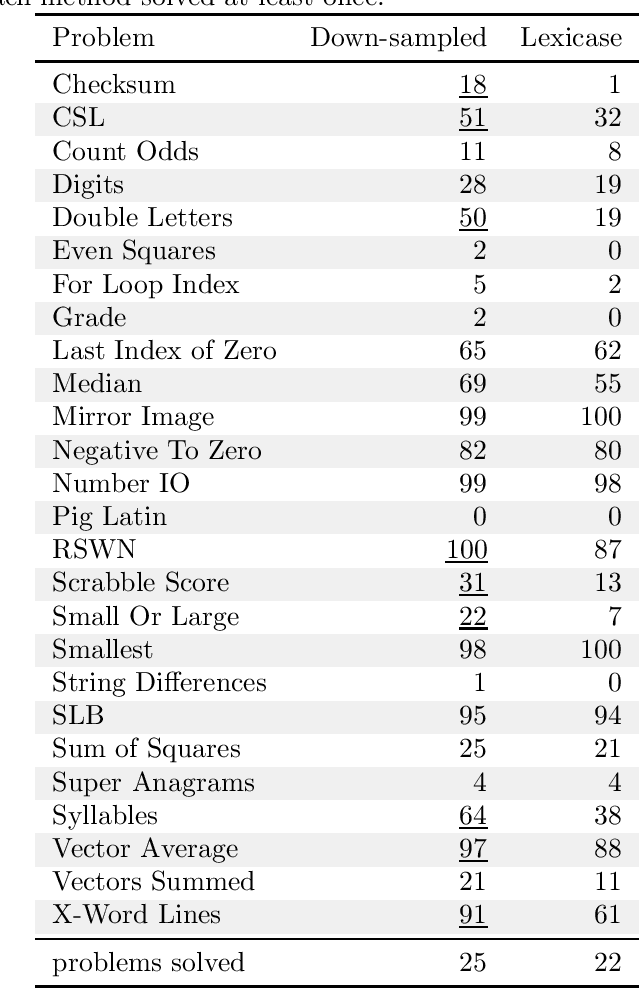
In genetic programming, an evolutionary method for producing computer programs that solve specified computational problems, parent selection is ordinarily based on aggregate measures of performance across an entire training set. Lexicase selection, by contrast, selects on the basis of performance on random sequences of training cases; this has been shown to enhance problem-solving power in many circumstances. Lexicase selection can also be seen as better reflecting biological evolution, by modeling sequences of challenges that organisms face over their lifetimes. Recent work has demonstrated that the advantages of lexicase selection can be amplified by down-sampling, meaning that only a random subsample of the training cases is used each generation. This can be seen as modeling the fact that individual organisms encounter only subsets of the possible environments, and that environments change over time. Here we provide the most extensive benchmarking of down-sampled lexicase selection to date, showing that its benefits hold up to increased scrutiny. The reasons that down-sampling helps, however, are not yet fully understood. Hypotheses include that down-sampling allows for more generations to be processed with the same budget of program evaluations; that the variation of training data across generations acts as a changing environment, encouraging adaptation; or that it reduces overfitting, leading to more general solutions. We systematically evaluate these hypotheses, finding evidence against all three, and instead draw the conclusion that down-sampled lexicase selection's main benefit stems from the fact that it allows the evolutionary process to examine more individuals within the same computational budget, even though each individual is examined less completely.