 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conditional Generative Models for Counterfactual Explanations
Jan 25, 2021
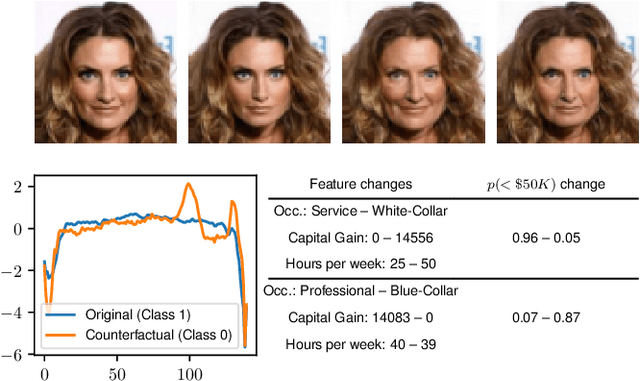



Counterfactual instances offer human-interpretable insight into the local behaviour of machine learning models. We propose a general framework to generate sparse, in-distribution counterfactual model explanations which match a desired target prediction with a conditional generative model, allowing batches of counterfactual instances to be generated with a single forward pass. The method is flexible with respect to the type of generative model used as well as the task of the underlying predictive model. This allows straightforward application of the framework to different modalities such as images, time series or tabular data as well as generative model paradigms such as GANs or autoencoders and predictive tasks like classification or regression. We illustrate the effectiveness of our method on image (CelebA), time series (ECG) and mixed-type tabular (Adult Census) data.
Towards General Purpose Vision Systems
Apr 01, 2021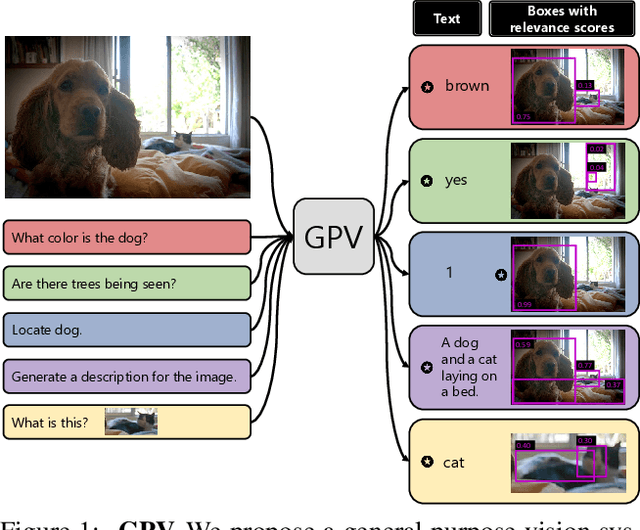
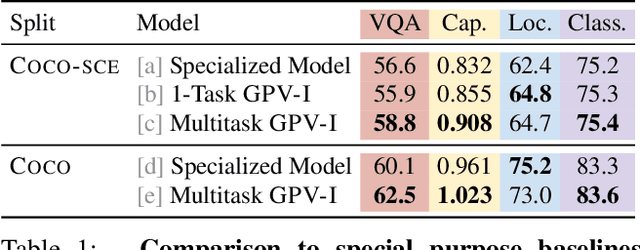
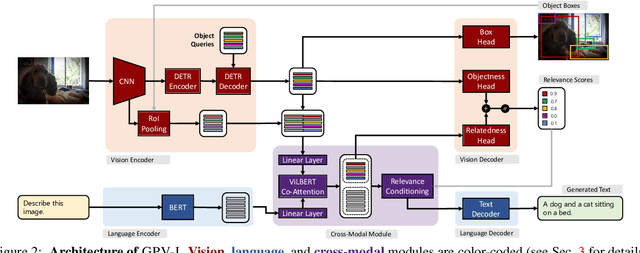

A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system's ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
Resource Allocation for Massive MIMO HetNets with Quantize-Forward Relaying
May 24, 2021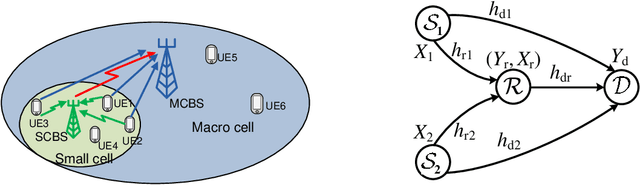
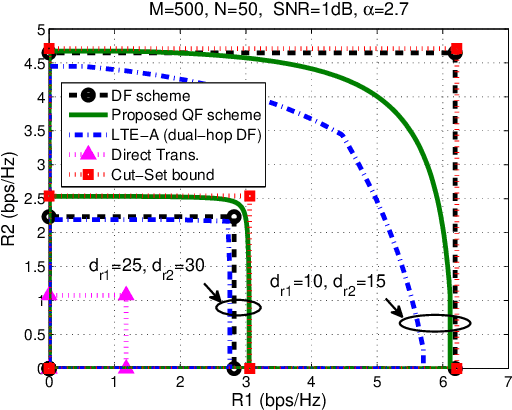
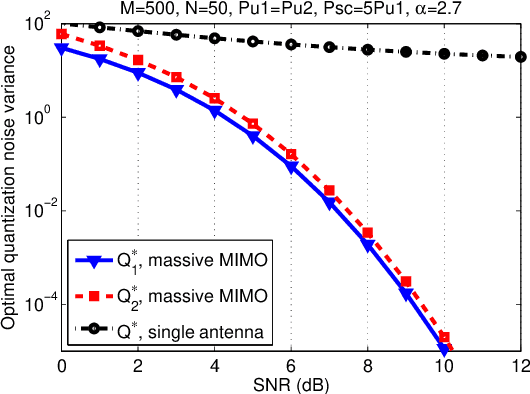
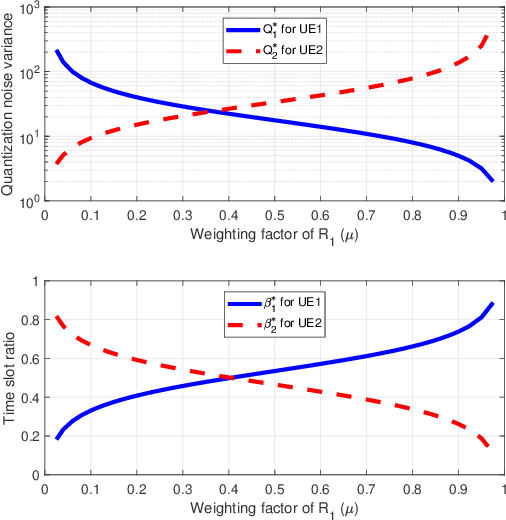
We investigate how massive MIMO impacts the uplink transmission design in a heterogeneous network (HetNet) where multiple users communicate with a macro-cell base station (MCBS) with the help of a small-cell BS (SCBS) with zero-forcing (ZF) detection at each BS. We first analyze the quantize-forward (QF) relaying scheme with joint decoding (JD) at the MCBS. To maximize the rate region, we optimize the quantization of all user data streams at the SCBS by developing a novel water-filling algorithm that is based on the Descartes' rule of signs. Our result shows that as a user link to the SCBS becomes stronger than that to the MCBS, the SCBS deploys finer quantization to that user data stream. We further propose a new simplified scheme through Wyner-Ziv (WZ) binning and time-division (TD) transmission at the SCBS, which allows not only sequential but also separate decoding of each user message at the MCBS. For this new QF-WZTD scheme, the optimal quantization parameters are identical to that of the QF-JD scheme while the phase durations are conveniently optimized as functions of the quantization parameters. Despite its simplicity, the QF-WZTD scheme achieves the same rate performance of the QF-JD scheme, making it an attractive option for future HetNets.
Modelling of LIDAR sensor disturbances by solid airborne particles
May 10, 2021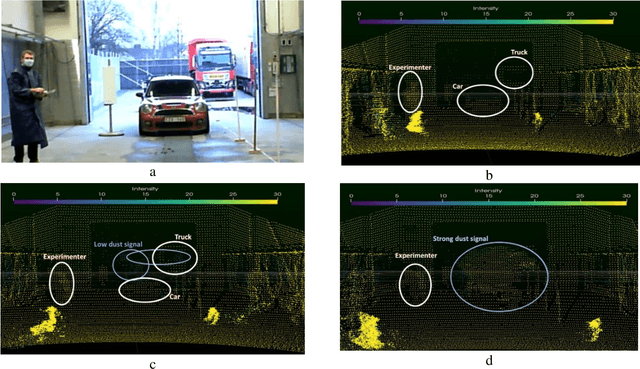
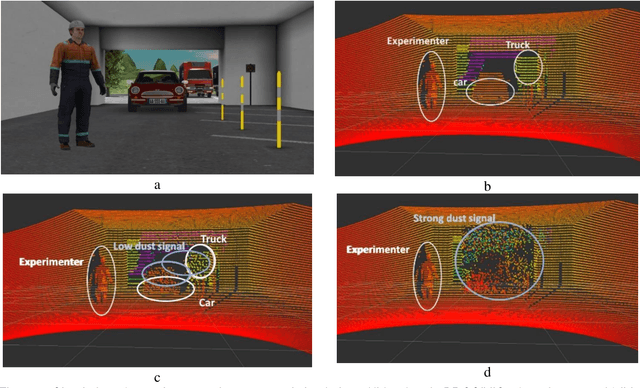
This paper aims to introduce a method for simulating with a real time performance the automotive LIDAR disturbance by dust clouds caused by natural phenomena, mechanical or man-made processes like a traveling vehicle. In this study, we are interested to study the interaction of an automotive LIDAR sensor with a dust cloud composed of solid particles. The main objective of this study is to provide a simulation model to industry and research laboratories that help to study LIDAR performance in a dust-sand environment with the capability to reproduce the encountered problems in degraded conditions and the ability to parameterize the degradation model. Based on industrial projects with a passenger's vehicles and truck manufacturers, we present LIDAR sensor and functionalities to perceive objects in a scene (pedestrian, car, truck, ...) in clear or extreme weather conditions. Simulated and experimental data are compared and analyzed in this article. The features presented are evaluated according to their quality for object detection. This study can be applied to sensors post-processing algorithms (object recognition, tracking, data fusion...) and even to the design of cleaning systems.
Multi-Level Graph Encoding with Structural-Collaborative Relation Learning for Skeleton-Based Person Re-Identification
Jun 06, 2021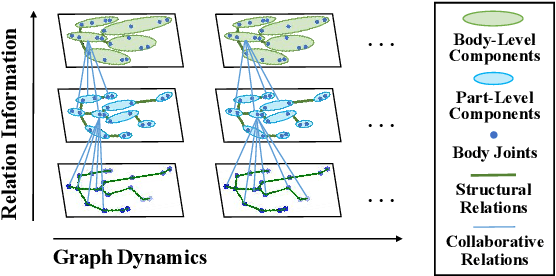
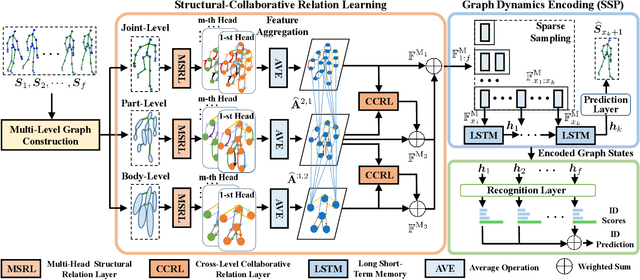
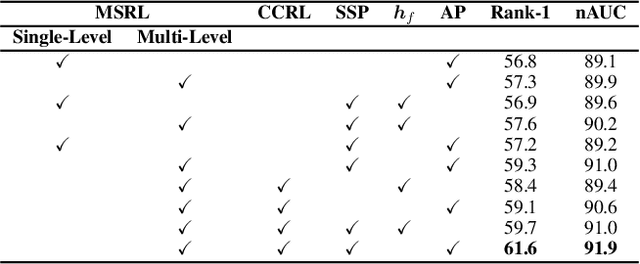
Skeleton-based person re-identification (Re-ID) is an emerging open topic providing great value for safety-critical applications. Existing methods typically extract hand-crafted features or model skeleton dynamics from the trajectory of body joints, while they rarely explore valuable relation information contained in body structure or motion. To fully explore body relations, we construct graphs to model human skeletons from different levels, and for the first time propose a Multi-level Graph encoding approach with Structural-Collaborative Relation learning (MG-SCR) to encode discriminative graph features for person Re-ID. Specifically, considering that structurally-connected body components are highly correlated in a skeleton, we first propose a multi-head structural relation layer to learn different relations of neighbor body-component nodes in graphs, which helps aggregate key correlative features for effective node representations. Second, inspired by the fact that body-component collaboration in walking usually carries recognizable patterns, we propose a cross-level collaborative relation layer to infer collaboration between different level components, so as to capture more discriminative skeleton graph features. Finally, to enhance graph dynamics encoding, we propose a novel self-supervised sparse sequential prediction task for model pre-training, which facilitates encoding high-level graph semantics for person Re-ID. MG-SCR outperforms state-of-the-art skeleton-based methods, and it achieves superior performance to many multi-modal methods that utilize extra RGB or depth features. Our codes are available at https://github.com/Kali-Hac/MG-SCR.
* Accepted at IJCAI 2021 Main Track. Sole copyright holder is IJCAI. Codes are available at https://github.com/Kali-Hac/MG-SCR
Multi-modal Sarcasm Detection and Humor Classification in Code-mixed Conversations
May 31, 2021
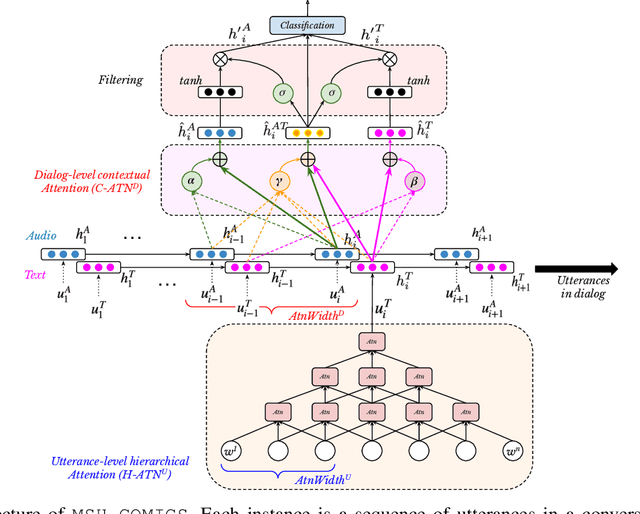


Sarcasm detection and humor classification are inherently subtle problems, primarily due to their dependence on the contextual and non-verbal information. Furthermore, existing studies in these two topics are usually constrained in non-English languages such as Hindi, due to the unavailability of qualitative annotated datasets. In this work, we make two major contributions considering the above limitations: (1) we develop a Hindi-English code-mixed dataset, MaSaC, for the multi-modal sarcasm detection and humor classification in conversational dialog, which to our knowledge is the first dataset of its kind; (2) we propose MSH-COMICS, a novel attention-rich neural architecture for the utterance classification. We learn efficient utterance representation utilizing a hierarchical attention mechanism that attends to a small portion of the input sentence at a time. Further, we incorporate dialog-level contextual attention mechanism to leverage the dialog history for the multi-modal classification. We perform extensive experiments for both the tasks by varying multi-modal inputs and various submodules of MSH-COMICS. We also conduct comparative analysis against existing approaches. We observe that MSH-COMICS attains superior performance over the existing models by > 1 F1-score point for the sarcasm detection and 10 F1-score points in humor classification. We diagnose our model and perform thorough analysis of the results to understand the superiority and pitfalls.
Contrastive Explanations for Explaining Model Adaptations
Apr 07, 2021Many decision making systems deployed in the real world are not static - a phenomenon known as model adaptation takes place over time. The need for transparency and interpretability of AI-based decision models is widely accepted and thus have been worked on extensively. Usually, explanation methods assume a static system that has to be explained. Explaining non-static systems is still an open research question, which poses the challenge how to explain model adaptations. In this contribution, we propose and (empirically) evaluate a framework for explaining model adaptations by contrastive explanations. We also propose a method for automatically finding regions in data space that are affected by a given model adaptation and thus should be explained.
Strengthening the Training of Convolutional Neural Networks By Using Walsh Matrix
Mar 31, 2021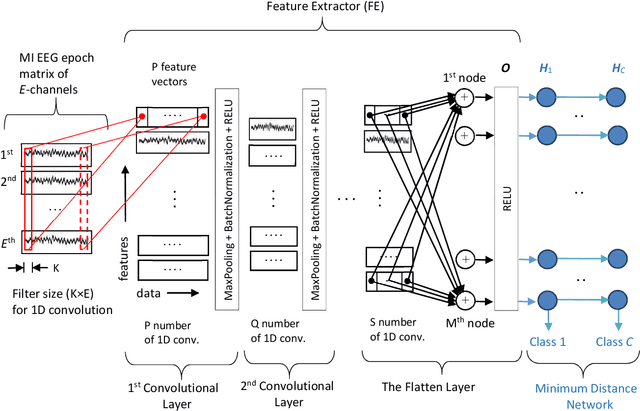
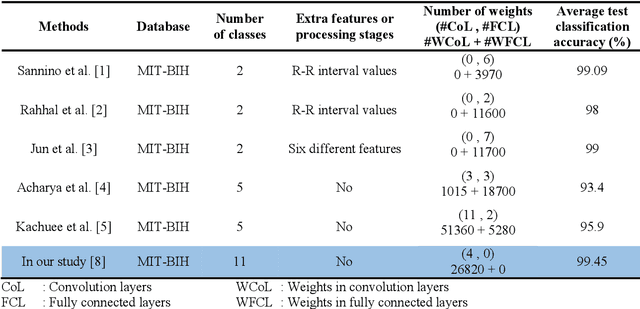
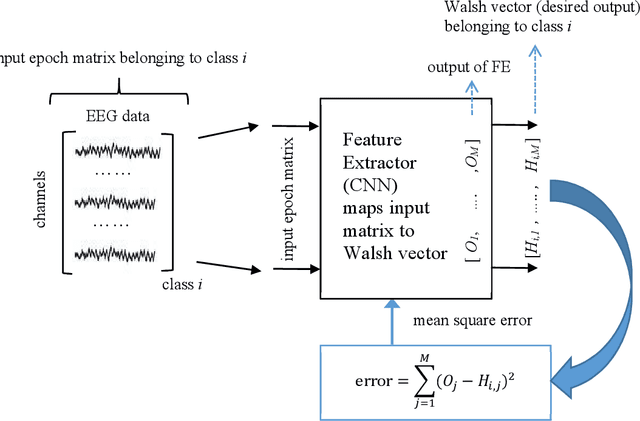
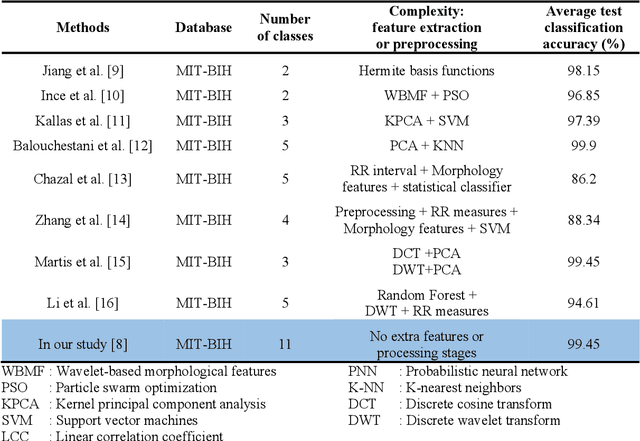
DNN structures are continuously developing and achieving high performances in classification problems. Also, it is observed that success rates obtained with DNNs are higher than those obtained with traditional neural networks. In addition, one of the advantages of DNNs is that there is no need to spend an extra effort to determine the features; the CNN automatically extracts the features from the dataset during the training. Besides their benefits, the DNNs have the following three major drawbacks among the others: (i) Researchers have struggled with over-fitting and under-fitting issues in the training of DNNs, (ii) determination of even a coarse structure for the DNN may take days, and (iii) most of the time, the proposed network structure is too large to be too bulky to be used in real time applications. We have modified the training and structure of DNN to increase the classification performance, to decrease the number of nodes in the structure, and to be used with less number of hyper parameters. A minimum distance network (MDN) following the last layer of the convolutional neural network (CNN) is used as the classifier instead of a fully connected neural network (FCNN). In order to strengthen the training of the CNN, we suggest employing Walsh function. We tested the performances of the proposed DNN (named as DivFE) on the classification of ECG, EEG, heart sound, detection pneumonia in X-ray chest images, detection of BGA solder defects, and patterns of benchmark datasets (MNIST, IRIS, CIFAR10 and CIFAR20). In different areas, it has been observed that a higher classification performance was obtained by using the DivFE with less number of nodes.
Parameter-free Gradient Temporal Difference Learning
May 10, 2021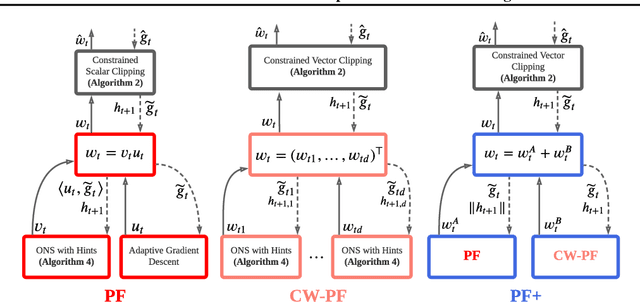
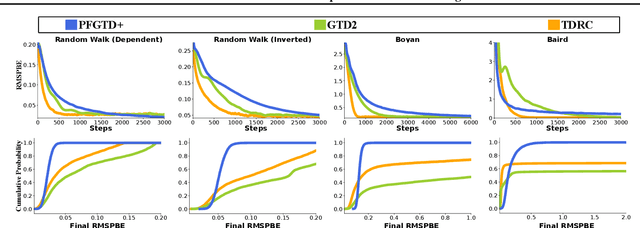
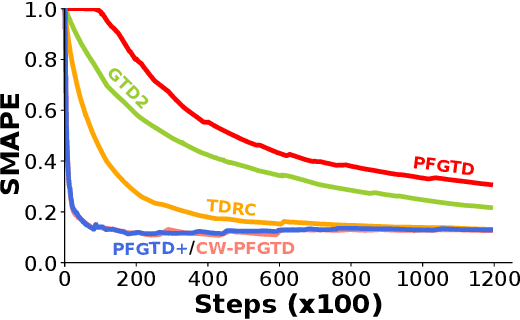
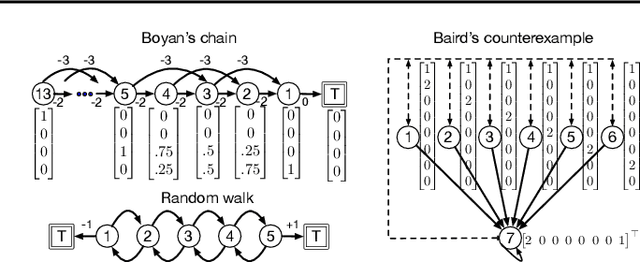
Reinforcement learning lies at the intersection of several challenges. Many applications of interest involve extremely large state spaces, requiring function approximation to enable tractable computation. In addition, the learner has only a single stream of experience with which to evaluate a large number of possible courses of action, necessitating algorithms which can learn off-policy. However, the combination of off-policy learning with function approximation leads to divergence of temporal difference methods. Recent work into gradient-based temporal difference methods has promised a path to stability, but at the cost of expensive hyperparameter tuning. In parallel, progress in online learning has provided parameter-free methods that achieve minimax optimal guarantees up to logarithmic terms, but their application in reinforcement learning has yet to be explored. In this work, we combine these two lines of attack, deriving parameter-free, gradient-based temporal difference algorithms. Our algorithms run in linear time and achieve high-probability convergence guarantees matching those of GTD2 up to $\log$ factors. Our experiments demonstrate that our methods maintain high prediction performance relative to fully-tuned baselines, with no tuning whatsoever.
Auto-NBA: Efficient and Effective Search Over the Joint Space of Networks, Bitwidths, and Accelerators
Jun 11, 2021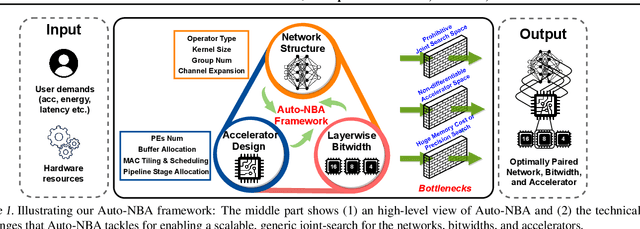
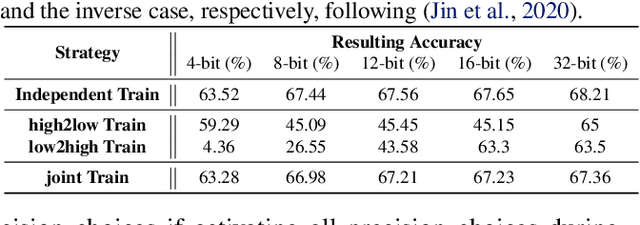
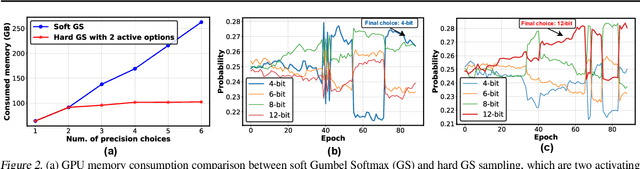
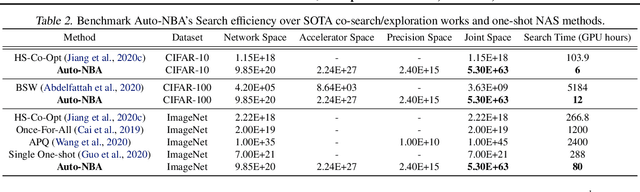
While maximizing deep neural networks' (DNNs') acceleration efficiency requires a joint search/design of three different yet highly coupled aspects, including the networks, bitwidths, and accelerators, the challenges associated with such a joint search have not yet been fully understood and addressed. The key challenges include (1) the dilemma of whether to explode the memory consumption due to the huge joint space or achieve sub-optimal designs, (2) the discrete nature of the accelerator design space that is coupled yet different from that of the networks and bitwidths, and (3) the chicken and egg problem associated with network-accelerator co-search, i.e., co-search requires operation-wise hardware cost, which is lacking during search as the optimal accelerator depending on the whole network is still unknown during search. To tackle these daunting challenges towards optimal and fast development of DNN accelerators, we propose a framework dubbed Auto-NBA to enable jointly searching for the Networks, Bitwidths, and Accelerators, by efficiently localizing the optimal design within the huge joint design space for each target dataset and acceleration specification. Our Auto-NBA integrates a heterogeneous sampling strategy to achieve unbiased search with constant memory consumption, and a novel joint-search pipeline equipped with a generic differentiable accelerator search engine. Extensive experiments and ablation studies validate that both Auto-NBA generated networks and accelerators consistently outperform state-of-the-art designs (including co-search/exploration techniques, hardware-aware NAS methods, and DNN accelerators), in terms of search time, task accuracy, and accelerator efficiency. Our codes are available at: https://github.com/RICE-EIC/Auto-NBA.