 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Simulating Continuum Mechanics with Multi-Scale Graph Neural Networks
Jun 09, 2021
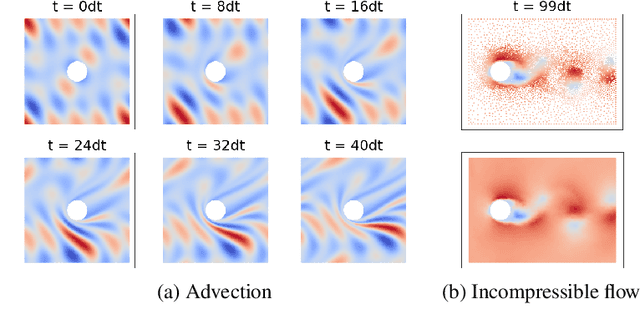
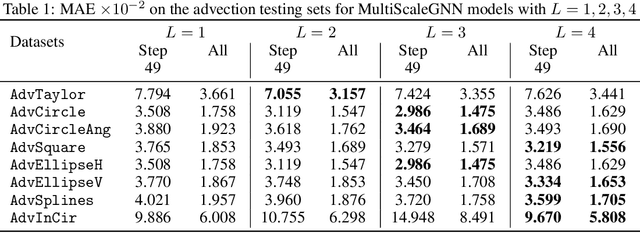
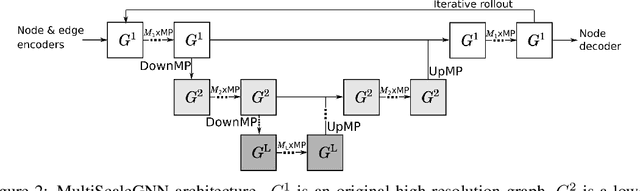

Continuum mechanics simulators, numerically solving one or more partial differential equations, are essential tools in many areas of science and engineering, but their performance often limits application in practice. Recent modern machine learning approaches have demonstrated their ability to accelerate spatio-temporal predictions, although, with only moderate accuracy in comparison. Here we introduce MultiScaleGNN, a novel multi-scale graph neural network model for learning to infer unsteady continuum mechanics. MultiScaleGNN represents the physical domain as an unstructured set of nodes, and it constructs one or more graphs, each of them encoding different scales of spatial resolution. Successive learnt message passing between these graphs improves the ability of GNNs to capture and forecast the system state in problems encompassing a range of length scales. Using graph representations, MultiScaleGNN can impose periodic boundary conditions as an inductive bias on the edges in the graphs, and achieve independence to the nodes' positions. We demonstrate this method on advection problems and incompressible fluid dynamics. Our results show that the proposed model can generalise from uniform advection fields to high-gradient fields on complex domains at test time and infer long-term Navier-Stokes solutions within a range of Reynolds numbers. Simulations obtained with MultiScaleGNN are between two and four orders of magnitude faster than the ones on which it was trained.
Encouraging Intra-Class Diversity Through a Reverse Contrastive Loss for Better Single-Source Domain Generalization
Jun 15, 2021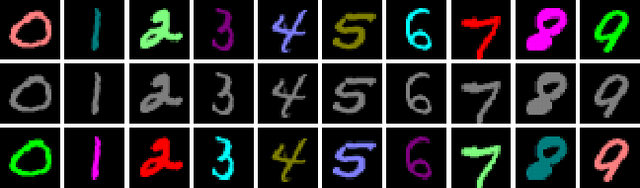
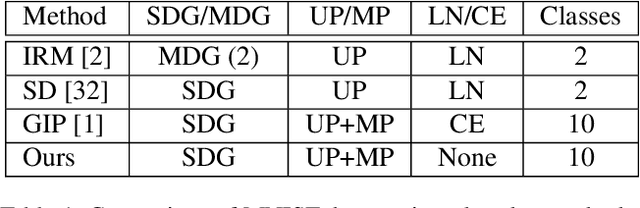
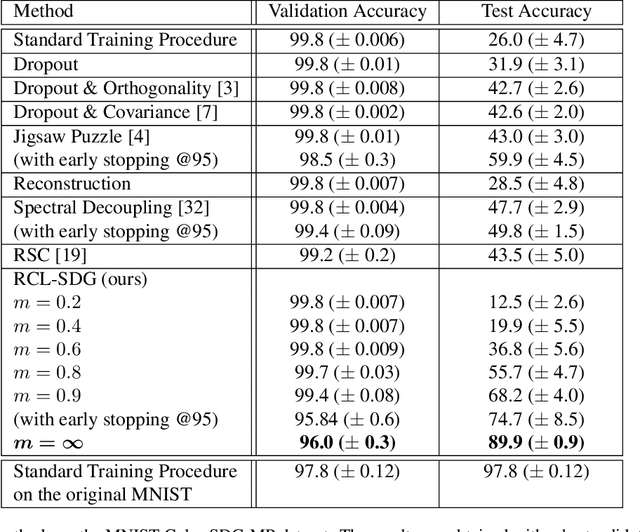
Traditional deep learning algorithms often fail to generalize when they are tested outside of the domain of training data. Because data distributions can change dynamically in real-life applications once a learned model is deployed, in this paper we are interested in single-source domain generalization (SDG) which aims to develop deep learning algorithms able to generalize from a single training domain where no information about the test domain is available at training time. Firstly, we design two simple MNISTbased SDG benchmarks, namely MNIST Color SDG-MP and MNIST Color SDG-UP, which highlight the two different fundamental SDG issues of increasing difficulties: 1) a class-correlated pattern in the training domain is missing (SDG-MP), or 2) uncorrelated with the class (SDG-UP), in the testing data domain. This is in sharp contrast with the current domain generalization (DG) benchmarks which mix up different correlation and variation factors and thereby make hard to disentangle success or failure factors when benchmarking DG algorithms. We further evaluate several state-of-the-art SDG algorithms through our simple benchmark, namely MNIST Color SDG-MP, and show that the issue SDG-MP is largely unsolved despite of a decade of efforts in developing DG algorithms. Finally, we also propose a partially reversed contrastive loss to encourage intra-class diversity and find less strongly correlated patterns, to deal with SDG-MP and show that the proposed approach is very effective on our MNIST Color SDG-MP benchmark.
One Billion Audio Sounds from GPU-enabled Modular Synthesis
Apr 27, 2021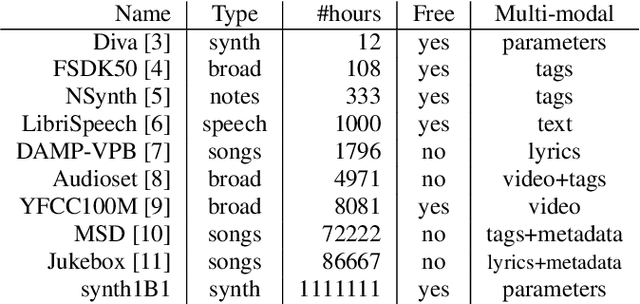
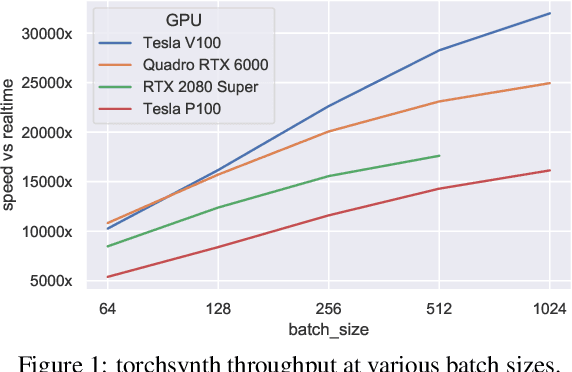
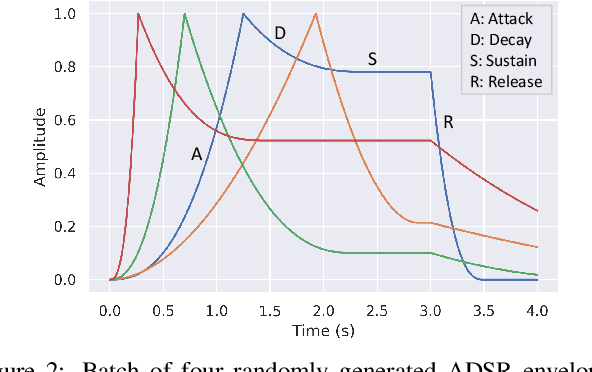
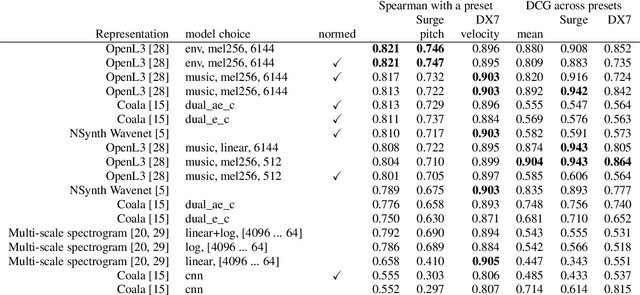
We release synth1B1, a multi-modal audio corpus consisting of 1 billion 4-second synthesized sounds, which is 100x larger than any audio dataset in the literature. Each sound is paired with the corresponding latent parameters used to generate it. synth1B1 samples are deterministically generated on-the-fly 16200x faster than real-time (714MHz) on a single GPU using torchsynth (https://github.com/torchsynth/torchsynth), an open-source modular synthesizer we release. Additionally, we release two new audio datasets: FM synth timbre (https://zenodo.org/record/4677102) and subtractive synth pitch (https://zenodo.org/record/4677097). Using these datasets, we demonstrate new rank-based synthesizer-motivated evaluation criteria for existing audio representations. Finally, we propose novel approaches to synthesizer hyperparameter optimization, and demonstrate how perceptually-correlated auditory distances could enable new applications in synthesizer design.
DSNet for Real-Time Driving Scene Semantic Segmentation
Dec 06, 2018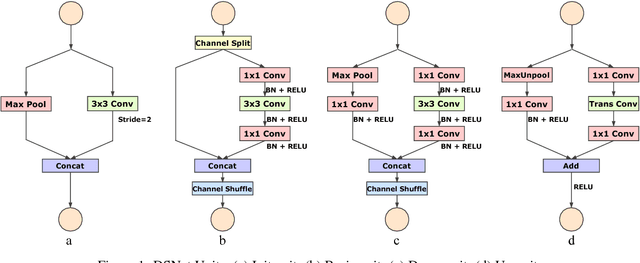
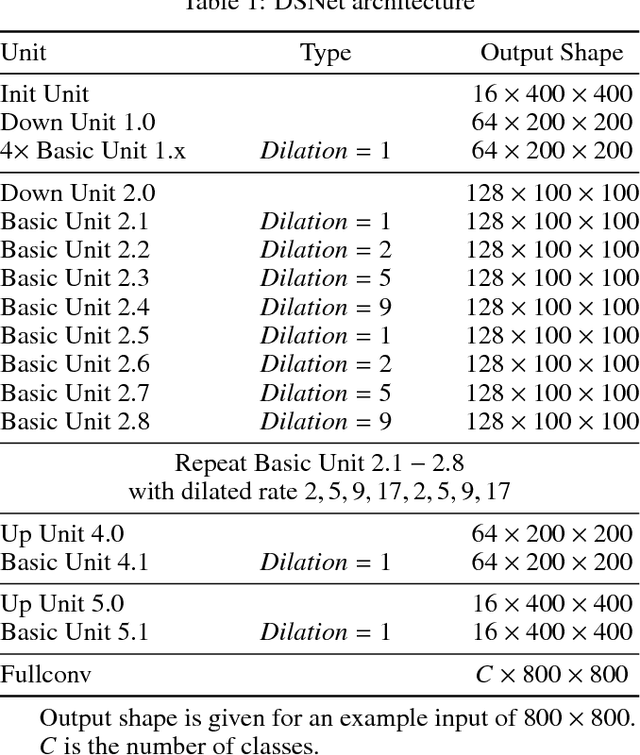
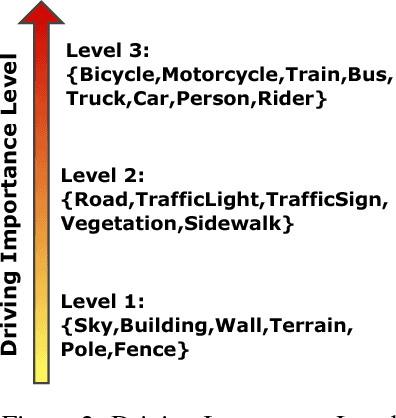
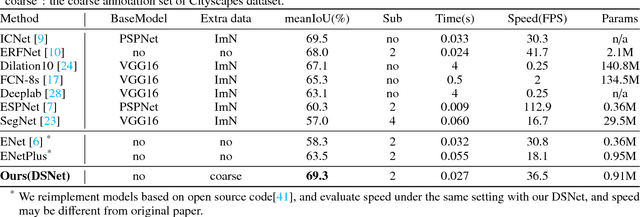
We focus on the very challenging task of semantic segmentation for autonomous driving system. It must deliver decent semantic segmentation result for traffic critical objects real-time. In this paper, we propose a very efficient yet powerful deep neural network for driving scene semantic segmentation termed as Driving Segmentation Network (DSNet). DSNet achieves state-of-the-art balance between accuracy and inference speed through efficient units and architecture design inspired by ShuffleNet V2 and ENet. More importantly, DSNet highlights classes most critical with driving decision making through our novel Driving Importance-weighted Loss. We evaluate DSNet on Cityscapes dataset, our DSNet achieves 71.8% mean Intersection-over-Union (IoU) on validation set and 69.3% on test set. Class-wise IoU scores show that Driving Importance-weighted Loss could improve most driving critical classes by a large margin. Compared with ENet, DSNet is 18.9% more accurate and 1.1+ times faster which implies great potential for autonomous driving application.
Predicting Intraoperative Hypoxemia with Joint Sequence Autoencoder Networks
May 19, 2021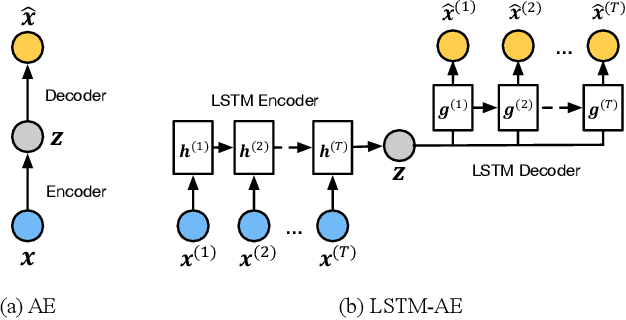
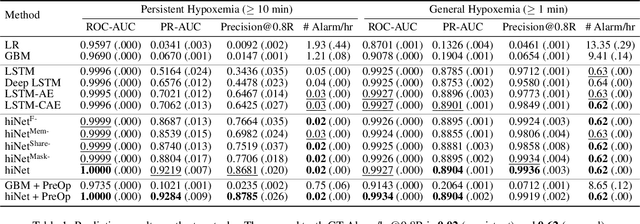
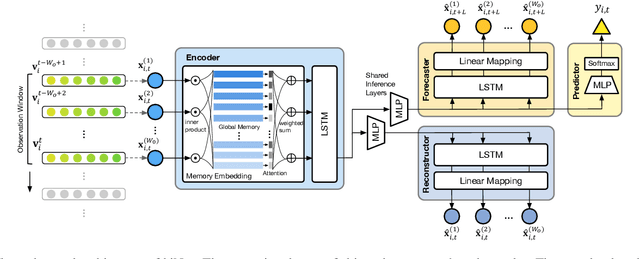
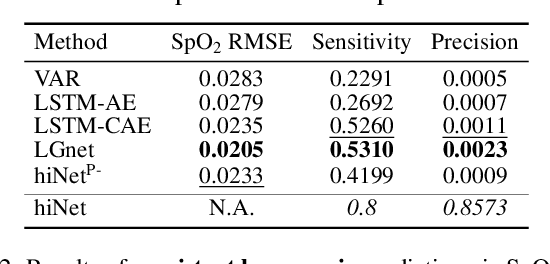
We present an end-to-end model using streaming physiological time series to accurately predict near-term risk for hypoxemia, a rare, but life-threatening condition known to cause serious patient harm during surgery. Our proposed model makes inference on both hypoxemia outcomes and future input sequences, enabled by a joint sequence autoencoder that simultaneously optimizes a discriminative decoder for label prediction, and two auxiliary decoders trained for data reconstruction and forecast, which seamlessly learns future-indicative latent representation. All decoders share a memory-based encoder that helps capture the global dynamics of patient data. In a large surgical cohort of 73,536 surgeries at a major academic medical center, our model outperforms all baselines and gives a large performance gain over the state-of-the-art hypoxemia prediction system. With a high sensitivity cutoff at 80%, it presents 99.36% precision in predicting hypoxemia and 86.81% precision in predicting the much more severe and rare hypoxemic condition, persistent hypoxemia. With exceptionally low rate of false alarms, our proposed model is promising in improving clinical decision making and easing burden on the health system.
Polynomial Graph Parsing with Non-Structural Reentrancies
May 06, 2021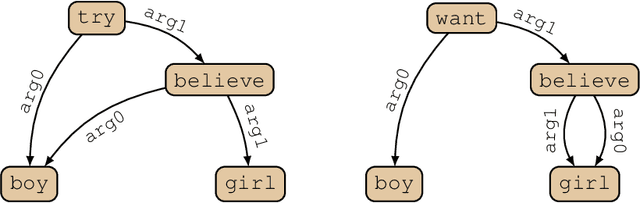

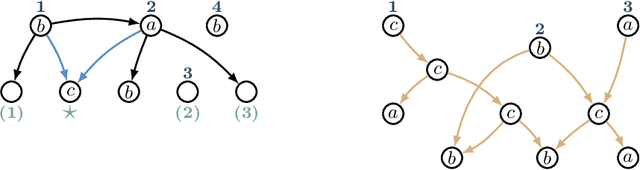
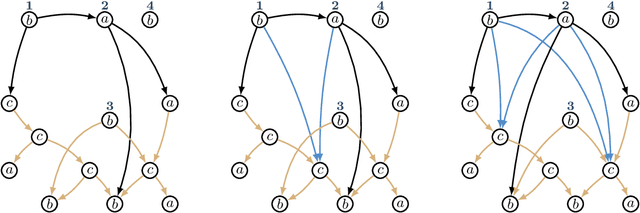
Graph-based semantic representations are valuable in natural language processing, where it is often simple and effective to represent linguistic concepts as nodes, and relations as edges between them. Several attempts has been made to find a generative device that is sufficiently powerful to represent languages of semantic graphs, while at the same allowing efficient parsing. We add to this line of work by introducing graph extension grammar, which consists of an algebra over graphs together with a regular tree grammar that generates expressions over the operations of the algebra. Due to the design of the operations, these grammars can generate graphs with non-structural reentrancies; a type of node-sharing that is excessively common in formalisms such as abstract meaning representation, but for which existing devices offer little support. We provide a parsing algorithm for graph extension grammars, which is proved to be correct and run in polynomial time.
Dual Script E2E framework for Multilingual and Code-Switching ASR
Jun 02, 2021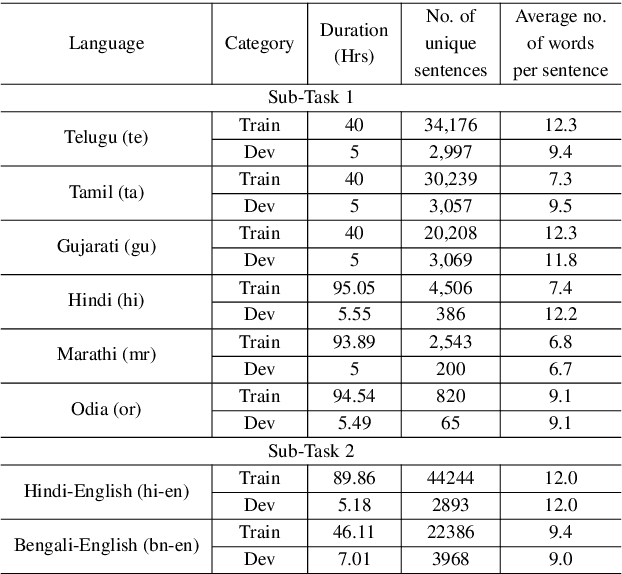
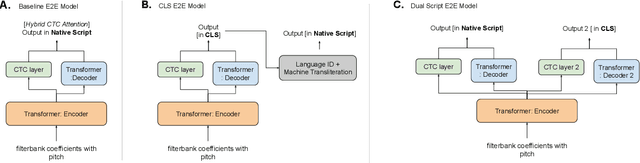
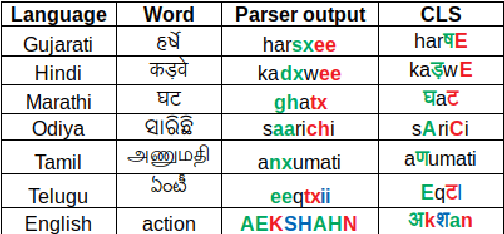
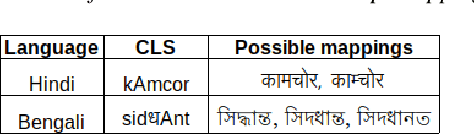
India is home to multiple languages, and training automatic speech recognition (ASR) systems for languages is challenging. Over time, each language has adopted words from other languages, such as English, leading to code-mixing. Most Indian languages also have their own unique scripts, which poses a major limitation in training multilingual and code-switching ASR systems. Inspired by results in text-to-speech synthesis, in this work, we use an in-house rule-based phoneme-level common label set (CLS) representation to train multilingual and code-switching ASR for Indian languages. We propose two end-to-end (E2E) ASR systems. In the first system, the E2E model is trained on the CLS representation, and we use a novel data-driven back-end to recover the native language script. In the second system, we propose a modification to the E2E model, wherein the CLS representation and the native language characters are used simultaneously for training. We show our results on the multilingual and code-switching tasks of the Indic ASR Challenge 2021. Our best results achieve 6% and 5% improvement (approx) in word error rate over the baseline system for the multilingual and code-switching tasks, respectively, on the challenge development data.
Constant-Time Predictive Distributions for Gaussian Processes
Jun 20, 2018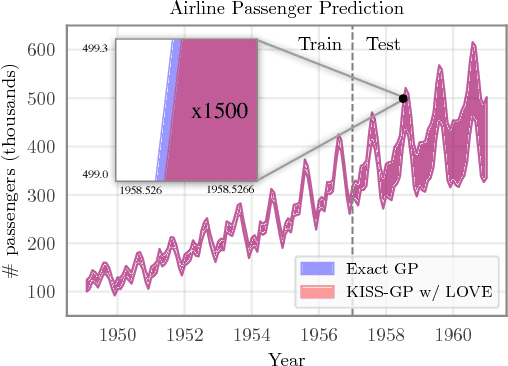

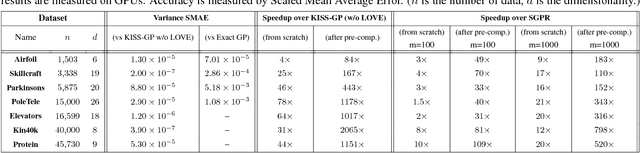
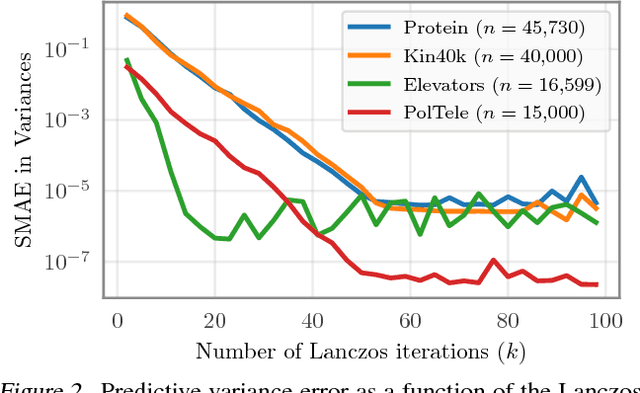
One of the most compelling features of Gaussian process (GP) regression is its ability to provide well-calibrated posterior distributions. Recent advances in inducing point methods have sped up GP marginal likelihood and posterior mean computations, leaving posterior covariance estimation and sampling as the remaining computational bottlenecks. In this paper we address these shortcomings by using the Lanczos algorithm to rapidly approximate the predictive covariance matrix. Our approach, which we refer to as LOVE (LanczOs Variance Estimates), substantially improves time and space complexity. In our experiments, LOVE computes covariances up to 2,000 times faster and draws samples 18,000 times faster than existing methods, all without sacrificing accuracy.
Neural News Recommendation with Negative Feedback
Jan 12, 2021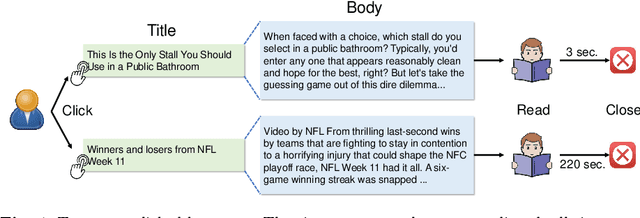

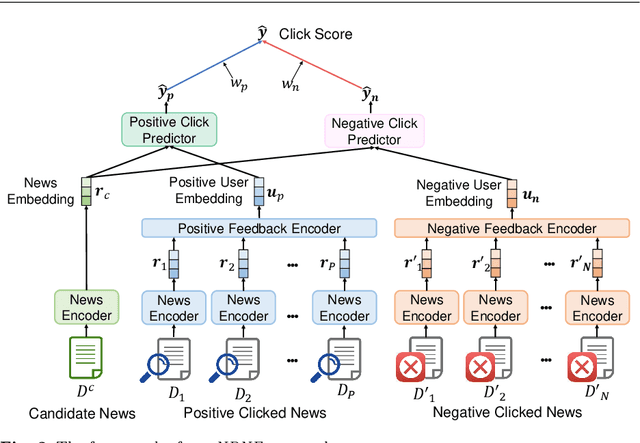
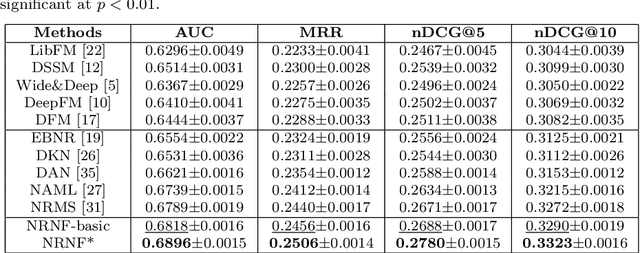
News recommendation is important for online news services. Precise user interest modeling is critical for personalized news recommendation. Existing news recommendation methods usually rely on the implicit feedback of users like news clicks to model user interest. However, news click may not necessarily reflect user interests because users may click a news due to the attraction of its title but feel disappointed at its content. The dwell time of news reading is an important clue for user interest modeling, since short reading dwell time usually indicates low and even negative interest. Thus, incorporating the negative feedback inferred from the dwell time of news reading can improve the quality of user modeling. In this paper, we propose a neural news recommendation approach which can incorporate the implicit negative user feedback. We propose to distinguish positive and negative news clicks according to their reading dwell time, and respectively learn user representations from positive and negative news clicks via a combination of Transformer and additive attention network. In addition, we propose to compute a positive click score and a negative click score based on the relevance between candidate news representations and the user representations learned from the positive and negative news clicks. The final click score is a combination of positive and negative click scores. Besides, we propose an interactive news modeling method to consider the relatedness between title and body in news modeling. Extensive experiments on real-world dataset validate that our approach can achieve more accurate user interest modeling for news recommendation.
Shoulder Implant X-Ray Manufacturer Classification: Exploring with Vision Transformer
Apr 21, 2021
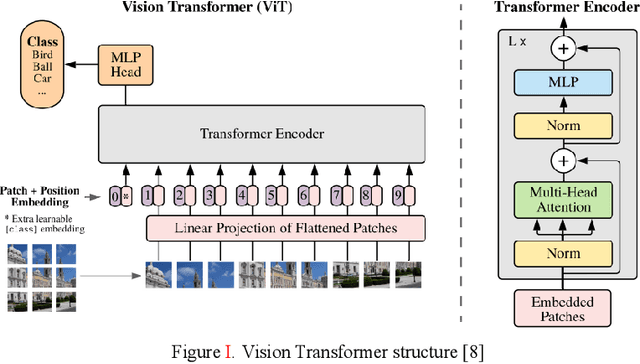
Shoulder replacement surgery, also called total shoulder replacement, is a common and complex surgery in Orthopedics discipline. It involves replacing a dead shoulder joint with an artificial implant. In the market, there are many artificial implant manufacturers and each of them may produce different implants with different structures compares to other providers. The problem arises in the following situation: a patient has some problems with the shoulder implant accessory and the manufacturer of that implant maybe unknown to either the patient or the doctor, therefore, correctly identification of the manufacturer is the key prior to the treatment. In this paper, we will demonstrate different methods for classifying the manufacturer of a shoulder implant. We will use Vision Transformer approach to this task for the first time ever