 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Trade-off Analysis of Replacing Proprietary LLMs with Open Source SLMs in Production
Jan 15, 2024
Many companies rely on APIs of managed AI models such as OpenAI's GPT-4 to create AI-enabled experiences in their products. Along with the benefits of ease of use and shortened time to production, this reliance on proprietary APIs has downsides in terms of model control, performance reliability, up-time predictability, and cost. At the same time, there has been a flurry of open source small language models (SLMs) that have been made available for commercial use. However, their readiness to replace existing capabilities remains unclear, and a systematic approach to test these models is not readily available. In this paper, we present a systematic evaluation methodology for, and characterization of, modern open source SLMs and their trade-offs when replacing a proprietary LLM APIs for a real-world product feature. We have designed SLaM, an automated analysis tool that enables the quantitative and qualitative testing of product features utilizing arbitrary SLMs. Using SLaM, we examine both the quality and the performance characteristics of modern SLMs relative to an existing customer-facing OpenAI-based implementation. We find that across 9 SLMs and 29 variants, we observe competitive quality-of-results for our use case, significant performance consistency improvement, and a cost reduction of 5x-29x when compared to OpenAI GPT-4.
The Cadaver in the Machine: The Social Practices of Measurement and Validation in Motion Capture Technology
Jan 19, 2024Motion capture systems, used across various domains, make body representations concrete through technical processes. We argue that the measurement of bodies and the validation of measurements for motion capture systems can be understood as social practices. By analyzing the findings of a systematic literature review (N=278) through the lens of social practice theory, we show how these practices, and their varying attention to errors, become ingrained in motion capture design and innovation over time. Moreover, we show how contemporary motion capture systems perpetuate assumptions about human bodies and their movements. We suggest that social practices of measurement and validation are ubiquitous in the development of data- and sensor-driven systems more broadly, and provide this work as a basis for investigating hidden design assumptions and their potential negative consequences in human-computer interaction.
Input Convex Lipschitz RNN: A Fast and Robust Approach for Engineering Tasks
Jan 19, 2024Computational efficiency and adversarial robustness are critical factors in real-world engineering applications. Yet, conventional neural networks often fall short in addressing both simultaneously, or even separately. Drawing insights from natural physical systems and existing literature, it is known that an input convex architecture enhances computational efficiency, while a Lipschitz-constrained architecture bolsters adversarial robustness. By leveraging the strengths of convexity and Lipschitz continuity, we develop a novel network architecture, termed Input Convex Lipschitz Recurrent Neural Networks. This model outperforms existing recurrent units across a spectrum of engineering tasks in terms of computational efficiency and adversarial robustness. These tasks encompass a benchmark MNIST image classification, real-world solar irradiance prediction for Solar PV system planning at LHT Holdings in Singapore, and real-time Model Predictive Control optimization for a chemical reactor.
Super-resolution of THz time-domain images based on low-rank representation
Dec 21, 2023Terahertz time-domain spectroscopy (THz-TDS) employs sub-picosecond pulses to probe dielectric properties of materials giving as a result a 3-dimensional hyperspectral data cube. The spatial resolution of THz images is primarily limited by two sources: a non-zero THz beam waist and the acquisition step size. Acquisition with a small step size allows for the visualisation of smaller details in images at the expense of acquisition time, but the frequency-dependent point-spread function remains the biggest bottleneck for THz imaging. This work presents a super-resolution approach to restore THz time-domain images acquired with medium-to-big step sizes. The results show the optimized and robust performance for different frequency bands (from 0.5 to 3.5 THz) obtaining higher resolution and additionally removing effects of blur at lower frequencies and noise at higher frequencies.
* This work was presented at the Sixth International Workshop on Mobile Terahertz Systems (IWMTS)
Modulating Retroreflector-based Satellite-to-Ground Optical Communications: Sensing and Positioning
Jan 17, 2024This paper focuses on the optimal design of a modulated retroreflector (MRR) laser link to establish a high-speed downlink for cube satellites (CubeSats), taking into account the weight and power limitations commonly encountered by these tiny satellites. To this end, first, a comprehensive channel modeling is conducted considering key real channel parameters including mechanical gimbal error, fast steering mirror angle error, laser beamwidth, MRR area, atmospheric turbulence, and channel coherence time. Accordingly, a closed-form expression for the distribution of the received signal is derived and utilized to propose a maximum likelihood based method to sense and estimate the initial position of the satellite. Subsequently, the distribution of the distance estimation error during the sensing phase is formulated as a function of the laser beamwidth and the gimbal error, which enables us to fine-tune the optimal laser beamwidth to minimize sensing time. Moreover, using the sensing and initial satellite distance estimation, two positioning algorithms are proposed. To compare the performance of the proposed positioning method, we obtain the lower bound of the positioning error as a benchmark. Finally, by providing comprehensive simulations, we evaluate the effect of different parameters on the performance of the considered MRR-based system in both the sensing and positioning phases.
CLAN: A Contrastive Learning based Novelty Detection Framework for Human Activity Recognition
Jan 17, 2024In ambient assisted living, human activity recognition from time series sensor data mainly focuses on predefined activities, often overlooking new activity patterns. We propose CLAN, a two-tower contrastive learning-based novelty detection framework with diverse types of negative pairs for human activity recognition. It is tailored to challenges with human activity characteristics, including the significance of temporal and frequency features, complex activity dynamics, shared features across activities, and sensor modality variations. The framework aims to construct invariant representations of known activity robust to the challenges. To generate suitable negative pairs, it selects data augmentation methods according to the temporal and frequency characteristics of each dataset. It derives the key representations against meaningless dynamics by contrastive and classification losses-based representation learning and score function-based novelty detection that accommodate dynamic numbers of the different types of augmented samples. The proposed two-tower model extracts the representations in terms of time and frequency, mutually enhancing expressiveness for distinguishing between new and known activities, even when they share common features. Experiments on four real-world human activity datasets show that CLAN surpasses the best performance of existing novelty detection methods, improving by 8.3%, 13.7%, and 53.3% in AUROC, balanced accuracy, and FPR@TPR0.95 metrics respectively.
VeriBug: An Attention-based Framework for Bug-Localization in Hardware Designs
Jan 17, 2024In recent years, there has been an exponential growth in the size and complexity of System-on-Chip designs targeting different specialized applications. The cost of an undetected bug in these systems is much higher than in traditional processor systems as it may imply the loss of property or life. The problem is further exacerbated by the ever-shrinking time-to-market and ever-increasing demand to churn out billions of devices. Despite decades of research in simulation and formal methods for debugging and verification, it is still one of the most time-consuming and resource intensive processes in contemporary hardware design cycle. In this work, we propose VeriBug, which leverages recent advances in deep learning to accelerate debugging at the Register-Transfer Level and generates explanations of likely root causes. First, VeriBug uses control-data flow graph of a hardware design and learns to execute design statements by analyzing the context of operands and their assignments. Then, it assigns an importance score to each operand in a design statement and uses that score for generating explanations for failures. Finally, VeriBug produces a heatmap highlighting potential buggy source code portions. Our experiments show that VeriBug can achieve an average bug localization coverage of 82.5% on open-source designs and different types of injected bugs.
Tempo estimation as fully self-supervised binary classification
Jan 17, 2024This paper addresses the problem of global tempo estimation in musical audio. Given that annotating tempo is time-consuming and requires certain musical expertise, few publicly available data sources exist to train machine learning models for this task. Towards alleviating this issue, we propose a fully self-supervised approach that does not rely on any human labeled data. Our method builds on the fact that generic (music) audio embeddings already encode a variety of properties, including information about tempo, making them easily adaptable for downstream tasks. While recent work in self-supervised tempo estimation aimed to learn a tempo specific representation that was subsequently used to train a supervised classifier, we reformulate the task into the binary classification problem of predicting whether a target track has the same or a different tempo compared to a reference. While the former still requires labeled training data for the final classification model, our approach uses arbitrary unlabeled music data in combination with time-stretching for model training as well as a small set of synthetically created reference samples for predicting the final tempo. Evaluation of our approach in comparison with the state-of-the-art reveals highly competitive performance when the constraint of finding the precise tempo octave is relaxed.
Entropy Causal Graphs for Multivariate Time Series Anomaly Detection
Dec 15, 2023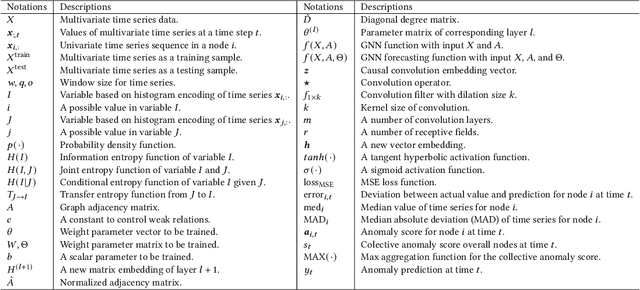
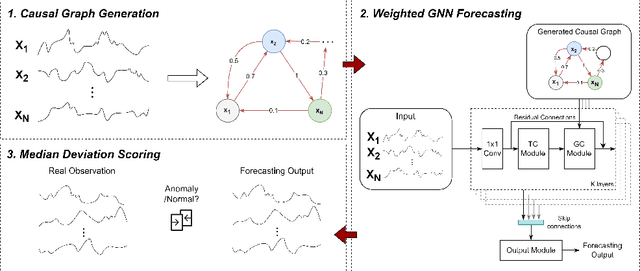
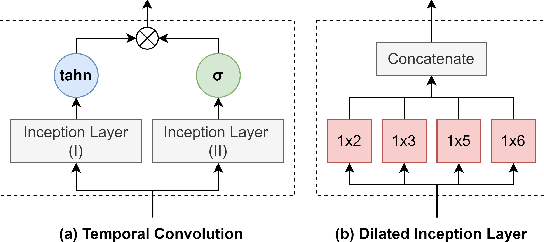
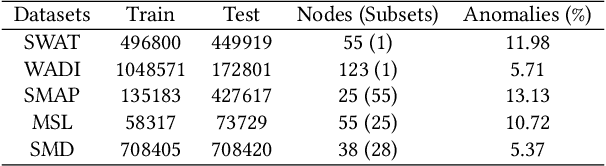
Many multivariate time series anomaly detection frameworks have been proposed and widely applied. However, most of these frameworks do not consider intrinsic relationships between variables in multivariate time series data, thus ignoring the causal relationship among variables and degrading anomaly detection performance. This work proposes a novel framework called CGAD, an entropy Causal Graph for multivariate time series Anomaly Detection. CGAD utilizes transfer entropy to construct graph structures that unveil the underlying causal relationships among time series data. Weighted graph convolutional networks combined with causal convolutions are employed to model both the causal graph structures and the temporal patterns within multivariate time series data. Furthermore, CGAD applies anomaly scoring, leveraging median absolute deviation-based normalization to improve the robustness of the anomaly identification process. Extensive experiments demonstrate that CGAD outperforms state-of-the-art methods on real-world datasets with a 15% average improvement based on three different multivariate time series anomaly detection metrics.
Agent Alignment in Evolving Social Norms
Jan 20, 2024Agents based on Large Language Models (LLMs) are increasingly permeating various domains of human production and life, highlighting the importance of aligning them with human values. The current alignment of AI systems primarily focuses on passively aligning LLMs through human intervention. However, agents possess characteristics like receiving environmental feedback and self-evolution, rendering the LLM alignment methods inadequate. In response, we propose an evolutionary framework for agent evolution and alignment, named EvolutionaryAgent, which transforms agent alignment into a process of evolution and selection under the principle of survival of the fittest. In an environment where social norms continuously evolve, agents better adapted to the current social norms will have a higher probability of survival and proliferation, while those inadequately aligned dwindle over time. Experimental results assessing the agents from multiple perspectives in aligning with social norms demonstrate that EvolutionaryAgent can align progressively better with the evolving social norms while maintaining its proficiency in general tasks. Effectiveness tests conducted on various open and closed-source LLMs as the foundation for agents also prove the applicability of our approach.