 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 20, 2021
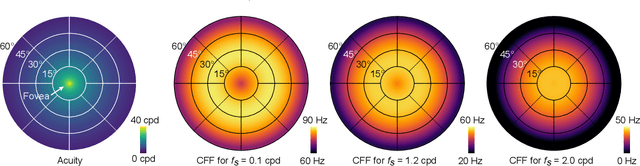
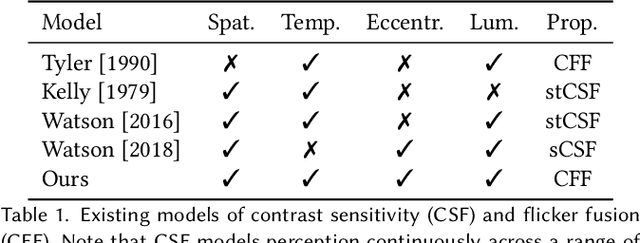

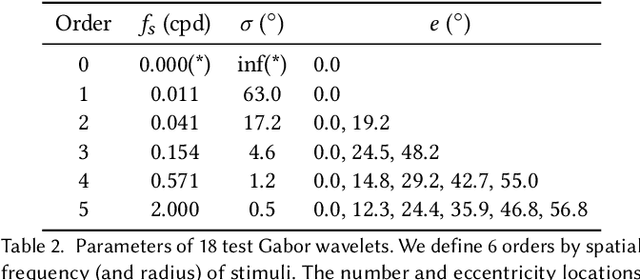
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
3D-FFS: Faster 3D object detection with Focused Frustum Search in sensor fusion based networks
Mar 15, 2021
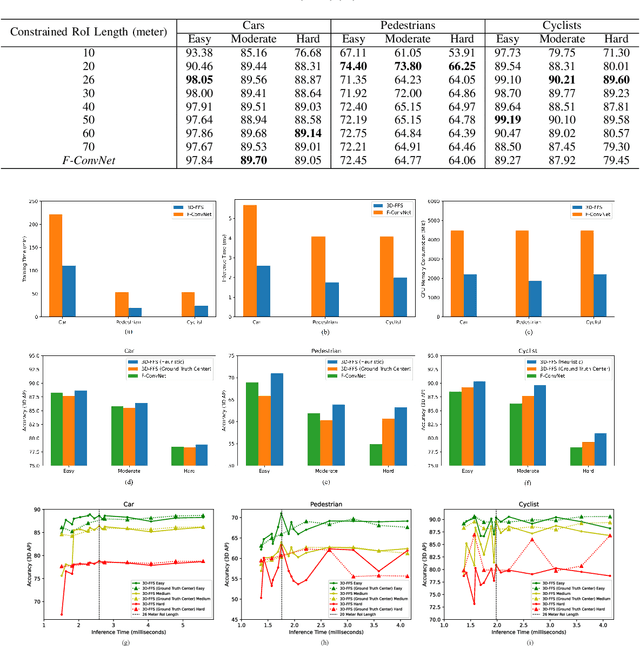
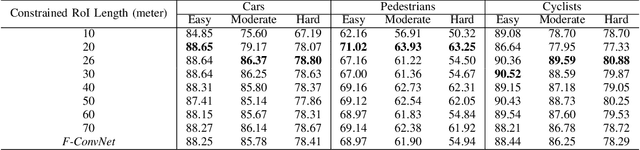
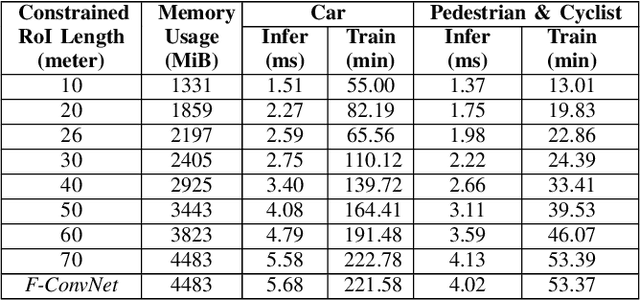
In this work we propose 3D-FFS, a novel approach to make sensor fusion based 3D object detection networks significantly faster using a class of computationally inexpensive heuristics. Existing sensor fusion based networks generate 3D region proposals by leveraging inferences from 2D object detectors. However, as images have no depth information, these networks rely on extracting semantic features of points from the entire scene to locate the object. By leveraging aggregated intrinsic properties (e.g. point density) of the 3D point cloud data, 3D-FFS can substantially constrain the 3D search space and thereby significantly reduce training time, inference time and memory consumption without sacrificing accuracy. To demonstrate the efficacy of 3D-FFS, we have integrated it with Frustum ConvNet (F-ConvNet), a prominent sensor fusion based 3D object detection model. We assess the performance of 3D-FFS on the KITTI dataset. Compared to F-ConvNet, we achieve improvements in training and inference times by up to 62.84% and 56.46%, respectively, while reducing the memory usage by up to 58.53%. Additionally, we achieve 0.59%, 2.03% and 3.34% improvements in accuracy for the Car, Pedestrian and Cyclist classes, respectively. 3D-FFS shows a lot of promise in domains with limited computing power, such as autonomous vehicles, drones and robotics where LiDAR-Camera based sensor fusion perception systems are widely used.
Deformable TDNN with adaptive receptive fields for speech recognition
Apr 30, 2021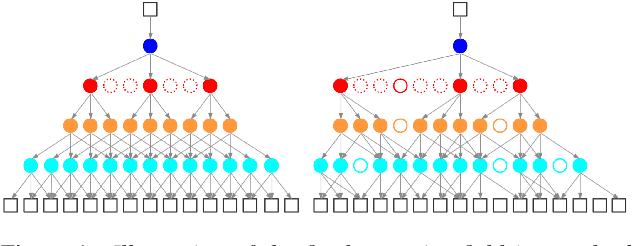
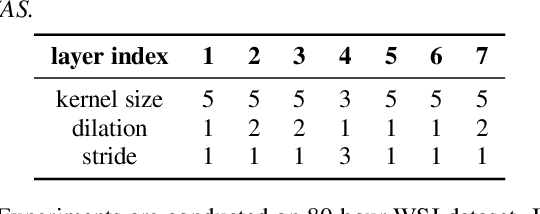
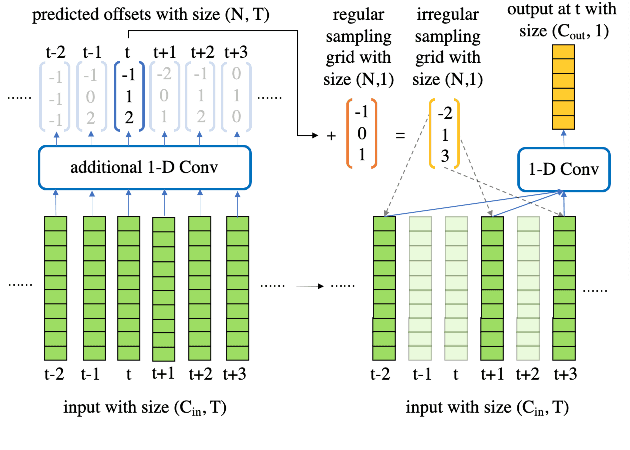
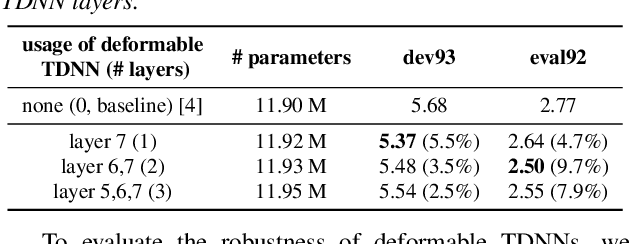
Time Delay Neural Networks (TDNNs) are widely used in both DNN-HMM based hybrid speech recognition systems and recent end-to-end systems. Nevertheless, the receptive fields of TDNNs are limited and fixed, which is not desirable for tasks like speech recognition, where the temporal dynamics of speech are varied and affected by many factors. This paper proposes to use deformable TDNNs for adaptive temporal dynamics modeling in end-to-end speech recognition. Inspired by deformable ConvNets, deformable TDNNs augment the temporal sampling locations with additional offsets and learn the offsets automatically based on the ASR criterion, without additional supervision. Experiments show that deformable TDNNs obtain state-of-the-art results on WSJ benchmarks (1.42\%/3.45\% WER on WSJ eval92/dev93 respectively), outperforming standard TDNNs significantly. Furthermore, we propose the latency control mechanism for deformable TDNNs, which enables deformable TDNNs to do streaming ASR without accuracy degradation.
Drift Estimation with Graphical Models
Feb 02, 2021
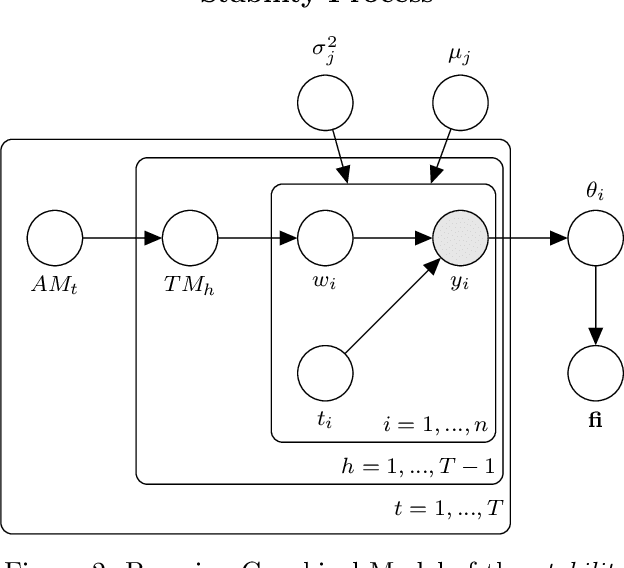

This paper deals with the issue of concept drift in supervised machine learn-ing. We make use of graphical models to elicit the visible structure of the dataand we infer from there changes in the hidden context. Differently from previous concept-drift detection methods, this application does not depend on the supervised machine learning model in use for a specific target variable, but it tries to assess the concept drift as independent characteristic of the evolution of a dataset. Specifically, we investigate how a graphical model evolves by looking at the creation of new links and the disappearing of existing ones in different time periods. The paper suggests a method that highlights the changes and eventually produce a metric to evaluate the stability over time. The paper evaluate the method with real world data on the Australian Electric market.
An Improved Measure of Musical Noise Based on Spectral Kurtosis
May 27, 2021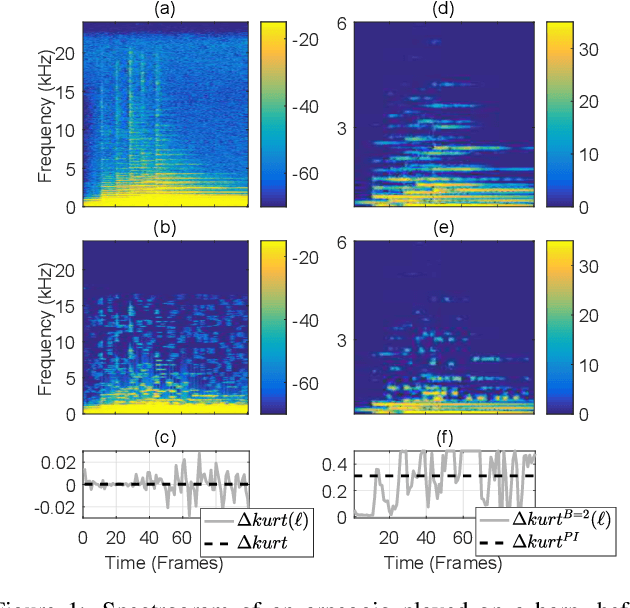
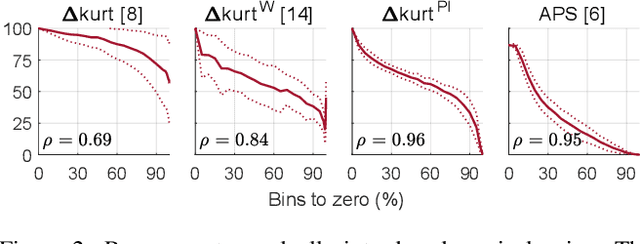
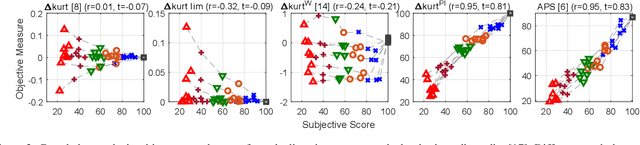
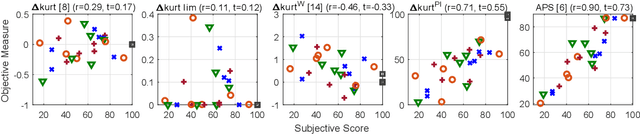
Audio processing methods operating on a time-frequency representation of the signal can introduce unpleasant sounding artifacts known as musical noise. These artifacts are observed in the context of audio coding, speech enhancement, and source separation. The change in kurtosis of the power spectrum introduced during the processing was shown to correlate with the human perception of musical noise in the context of speech enhancement, leading to the proposal of measures based on it. These baseline measures are here shown to correlate with human perception only in a limited manner. As ground truth for the human perception, the results from two listening tests are considered: one involving audio coding and one involving source separation. Simple but effective perceptually motivated improvements are proposed and the resulting new measure is shown to clearly outperform the baselines in terms of correlation with the results of both listening tests. Moreover, with respect to the listening test on musical noise in audio coding, the exhibited correlation is nearly as good as the one exhibited by the Artifact-related Perceptual Score (APS), which was found to be the best objective measure for this task. The APS is however computationally very expensive. The proposed measure is easily computed, requiring only a fraction of the computational cost of the APS.
* Manuscript accepted for the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics
Leveraging Third-Order Features in Skeleton-Based Action Recognition
May 04, 2021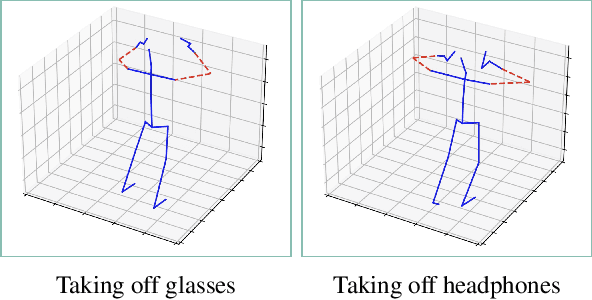
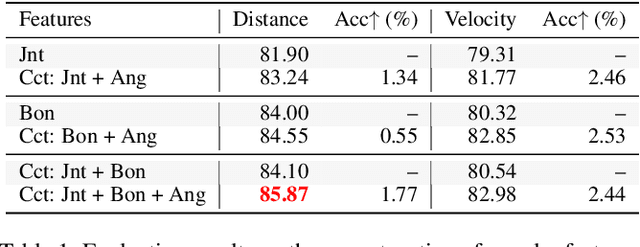
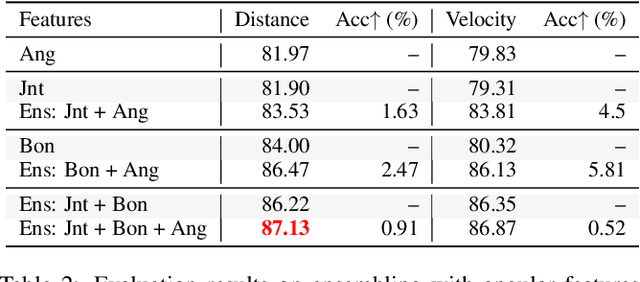
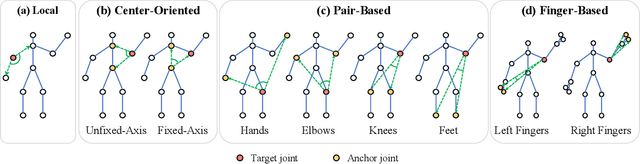
Skeleton sequences are light-weight and compact, and thus ideal candidates for action recognition on edge devices. Recent skeleton-based action recognition methods extract features from 3D joint coordinates as spatial-temporal cues, using these representations in a graph neural network for feature fusion, to boost recognition performance. The use of first- and second-order features, i.e., joint and bone representations has led to high accuracy, but many models are still confused by actions that have similar motion trajectories. To address these issues, we propose fusing third-order features in the form of angles into modern architectures, to robustly capture the relationships between joints and body parts. This simple fusion with popular spatial-temporal graph neural networks achieves new state-of-the-art accuracy in two large benchmarks, including NTU60 and NTU120, while employing fewer parameters and reduced run time. Our sourcecode is publicly available at: https://github.com/ZhenyueQin/Angular-Skeleton-Encoding.
EEG-Inception: An Accurate and Robust End-to-End Neural Network for EEG-based Motor Imagery Classification
Feb 01, 2021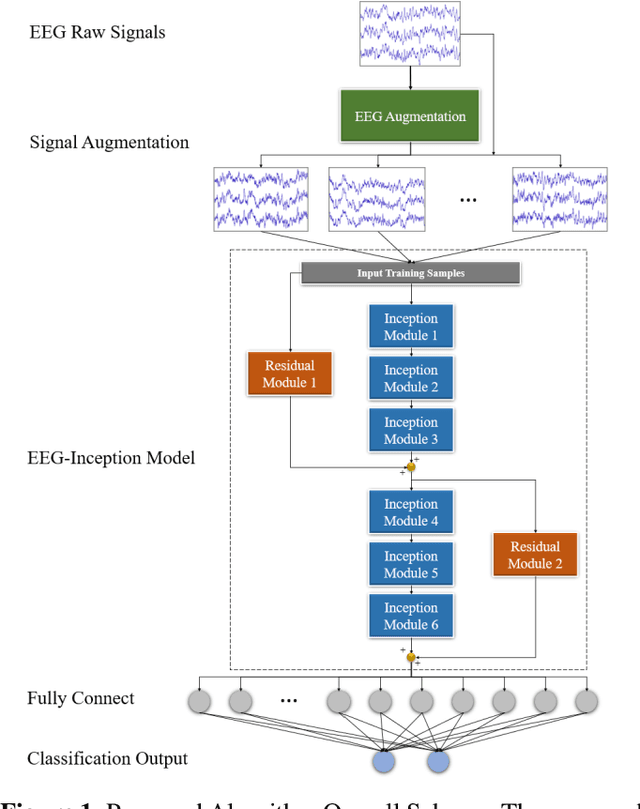

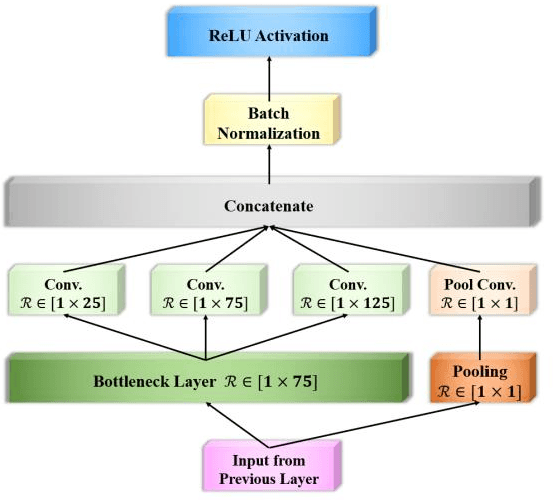
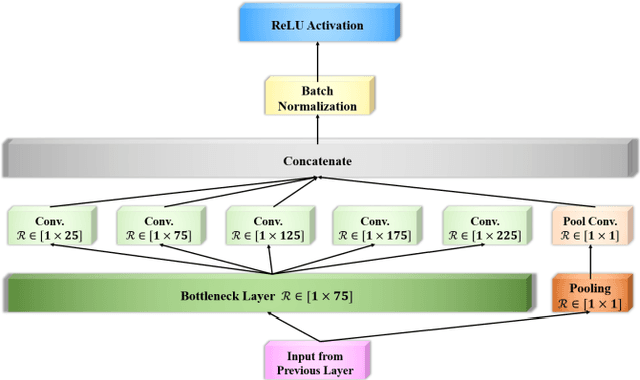
Classification of EEG-based motor imagery (MI) is a crucial non-invasive application in brain-computer interface (BCI) research. This paper proposes a novel convolutional neural network (CNN) architecture for accurate and robust EEG-based MI classification that outperforms the state-of-the-art methods. The proposed CNN model, namely EEG-Inception, is built on the backbone of the Inception-Time network, which showed to be highly efficient and accurate for time-series classification. Also, the proposed network is an end-to-end classification, as it takes the raw EEG signals as the input and does not require complex EEG signal-preprocessing. Furthermore, this paper proposes a novel data augmentation method for EEG signals to enhance the accuracy, at least by 3%, and reduce overfitting with limited BCI datasets. The proposed model outperforms all the state-of-the-art methods by achieving the average accuracy of 88.4% and 88.6% on the 2008 BCI Competition IV 2a (four-classes) and 2b datasets (binary-classes), respectively. Furthermore, it takes less than 0.025 seconds to test a sample suitable for real-time processing. Moreover, the classification standard deviation for nine different subjects achieves the lowest value of 5.5 for the 2b dataset and 7.1 for the 2a dataset, which validates that the proposed method is highly robust. From the experiment results, it can be inferred that the EEG-Inception network exhibits a strong potential as a subject-independent classifier for EEG-based MI tasks.
Dynamic Sample Complexity for Exact Sparse Recovery using Sequential Iterative Hard Thresholding
Feb 28, 2021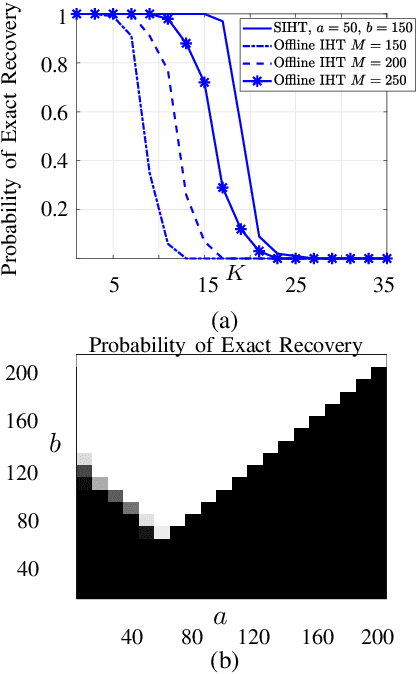
In this paper we consider the problem of exact recovery of a fixed sparse vector with the measurement matrices sequentially arriving along with corresponding measurements. We propose an extension of the iterative hard thresholding (IHT) algorithm, termed as sequential IHT (SIHT) which breaks the total time horizon into several phases such that IHT is executed in each of these phases using a fixed measurement matrix obtained at the beginning of that phase. We consider a stochastic setting where the measurement matrices obtained at each phase are independent samples of a sub Gaussian random matrix. We prove that if a certain dynamic sample complexity that depends on the sizes of the measurement matrices at each phase, along with their duration and the number of phases, satisfy certain lower bound, the estimation error of SIHT over a fixed time horizon decays rapidly. Interestingly, this bound reveals that the probability of decay of estimation error is hardly affected even if very small number measurements are sporadically used in different phases. This theoretical observation is also corroborated using numerical experiments demonstrating that SIHT enjoys improved probability of recovery compared to offline IHT.
BackEISNN: A Deep Spiking Neural Network with Adaptive Self-Feedback and Balanced Excitatory-Inhibitory Neurons
May 27, 2021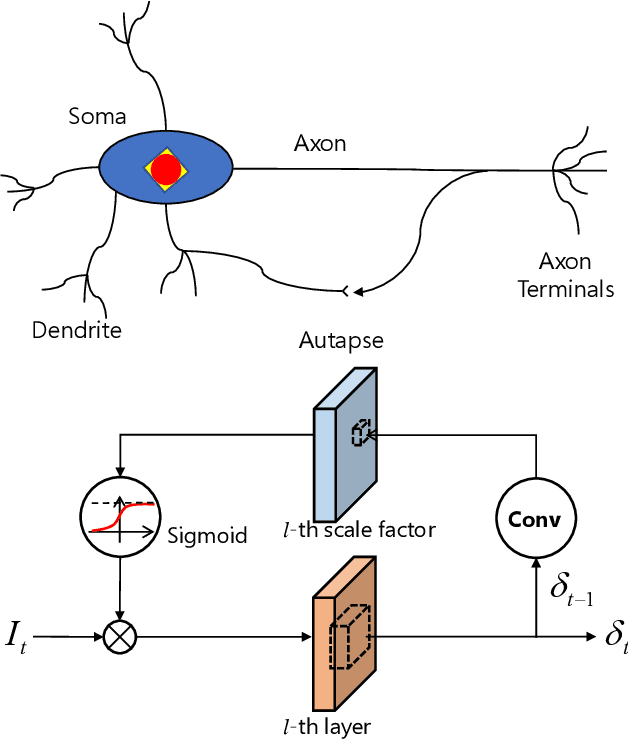
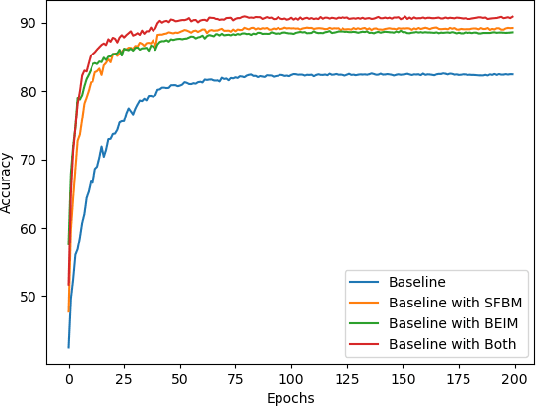
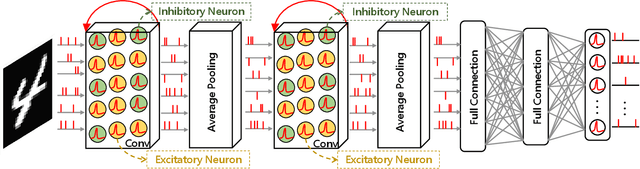
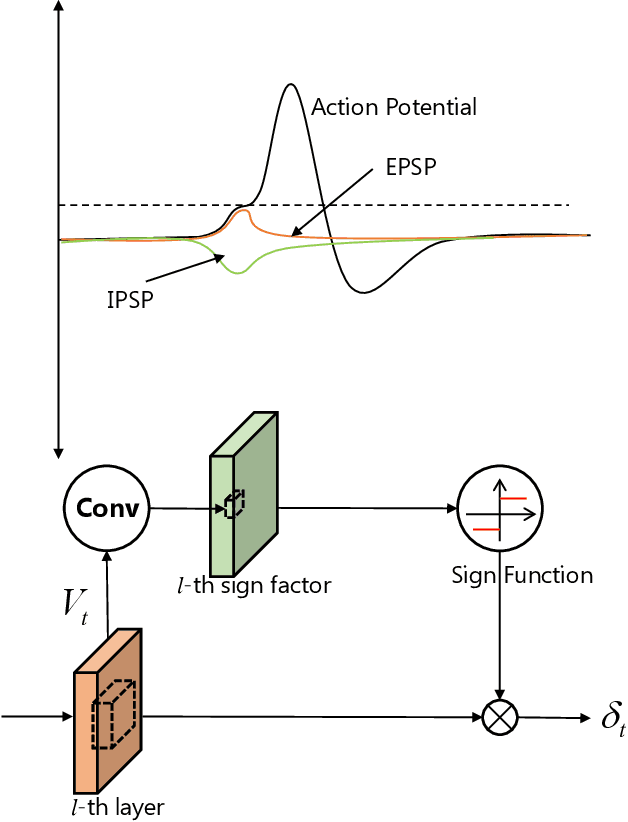
Spiking neural networks (SNNs) transmit information through discrete spikes, which performs well in processing spatial-temporal information. Due to the non-differentiable characteristic, there still exist difficulties in designing well-performed SNNs. Recently, SNNs trained with backpropagation have shown superior performance due to the proposal of the gradient approximation. However, the performance on complex tasks is still far away from the deep neural networks. Taking inspiration from the autapse in the brain which connects the spiking neurons with a self-feedback connection, we apply an adaptive time-delayed self-feedback on the membrane potential to regulate the spike precisions. As well as, we apply the balanced excitatory and inhibitory neurons mechanism to control the spiking neurons' output dynamically. With the combination of the two mechanisms, we propose a deep spiking neural network with adaptive self-feedback and balanced excitatory and inhibitory neurons (BackEISNN). The experimental results on several standard datasets have shown that the two modules not only accelerate the convergence of the network but also improve the accuracy. For the MNIST, FashionMNIST, and N-MNIST datasets, our model has achieved state-of-the-art performance. For the CIFAR10 dataset, our BackEISNN also gets remarkable performance on a relatively light structure that competes against state-of-the-art SNNs.
ExAD: An Ensemble Approach for Explanation-based Adversarial Detection
Mar 22, 2021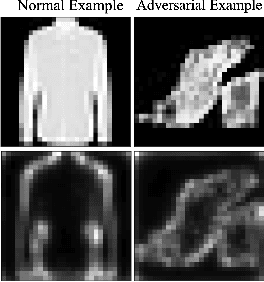
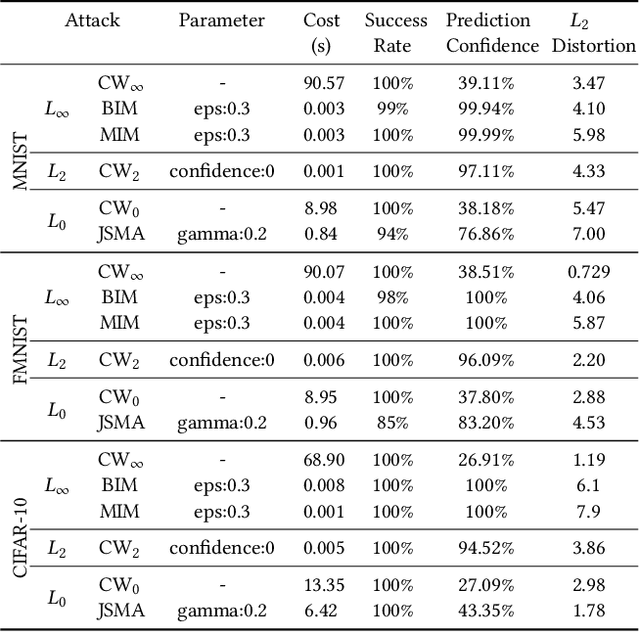
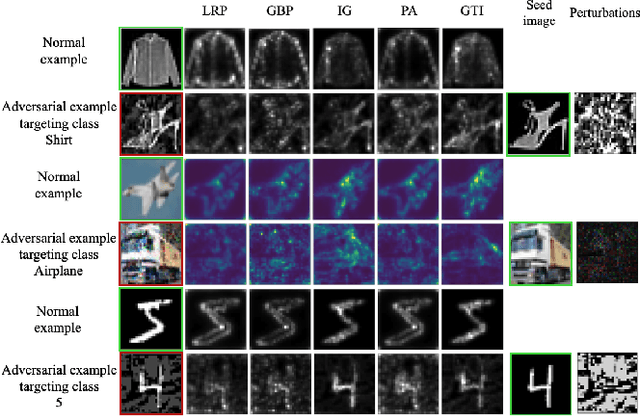
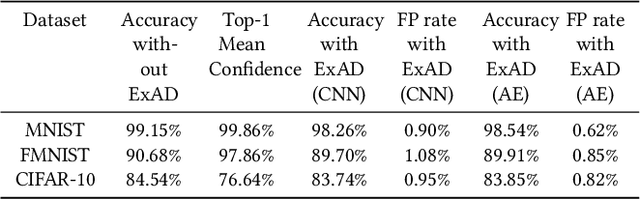
Recent research has shown Deep Neural Networks (DNNs) to be vulnerable to adversarial examples that induce desired misclassifications in the models. Such risks impede the application of machine learning in security-sensitive domains. Several defense methods have been proposed against adversarial attacks to detect adversarial examples at test time or to make machine learning models more robust. However, while existing methods are quite effective under blackbox threat model, where the attacker is not aware of the defense, they are relatively ineffective under whitebox threat model, where the attacker has full knowledge of the defense. In this paper, we propose ExAD, a framework to detect adversarial examples using an ensemble of explanation techniques. Each explanation technique in ExAD produces an explanation map identifying the relevance of input variables for the model's classification. For every class in a dataset, the system includes a detector network, corresponding to each explanation technique, which is trained to distinguish between normal and abnormal explanation maps. At test time, if the explanation map of an input is detected as abnormal by any detector model of the classified class, then we consider the input to be an adversarial example. We evaluate our approach using six state-of-the-art adversarial attacks on three image datasets. Our extensive evaluation shows that our mechanism can effectively detect these attacks under blackbox threat model with limited false-positives. Furthermore, we find that our approach achieves promising results in limiting the success rate of whitebox attacks.