 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalization Error Bound for Hyperbolic Ordinal Embedding
May 21, 2021
Hyperbolic ordinal embedding (HOE) represents entities as points in hyperbolic space so that they agree as well as possible with given constraints in the form of entity i is more similar to entity j than to entity k. It has been experimentally shown that HOE can obtain representations of hierarchical data such as a knowledge base and a citation network effectively, owing to hyperbolic space's exponential growth property. However, its theoretical analysis has been limited to ideal noiseless settings, and its generalization error in compensation for hyperbolic space's exponential representation ability has not been guaranteed. The difficulty is that existing generalization error bound derivations for ordinal embedding based on the Gramian matrix do not work in HOE, since hyperbolic space is not inner-product space. In this paper, through our novel characterization of HOE with decomposed Lorentz Gramian matrices, we provide a generalization error bound of HOE for the first time, which is at most exponential with respect to the embedding space's radius. Our comparison between the bounds of HOE and Euclidean ordinal embedding shows that HOE's generalization error is reasonable as a cost for its exponential representation ability.
Siam-ReID: Confuser Aware Siamese Tracker with Re-identification Feature
Apr 11, 2021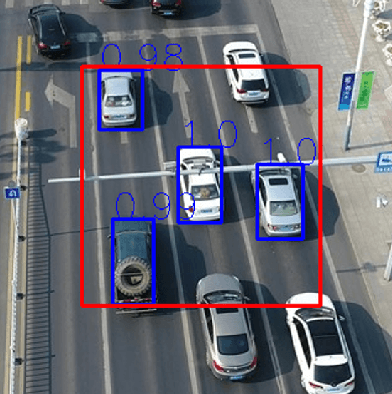
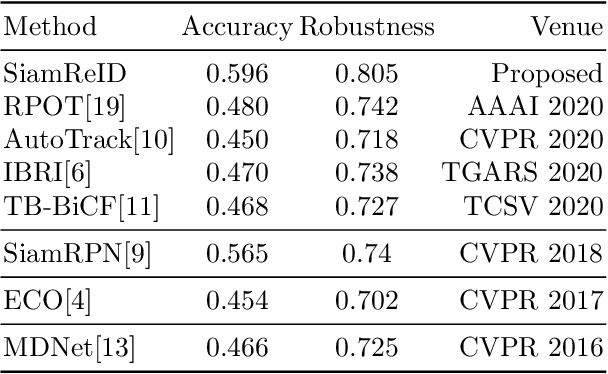
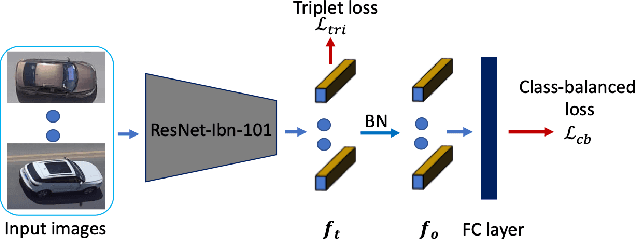
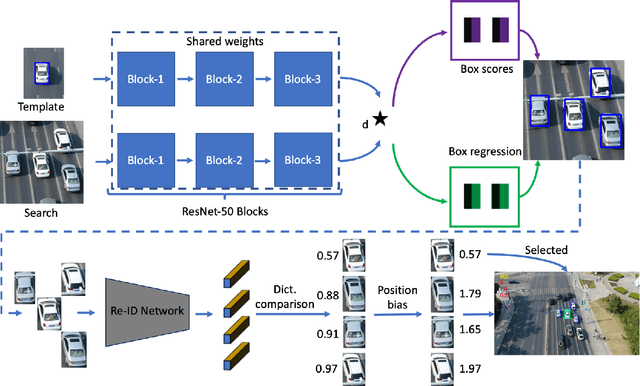
Siamese deep-network trackers have received significant attention in recent years due to their real-time speed and state-of-the-art performance. However, Siamese trackers suffer from similar looking confusers, that are prevalent in aerial imagery and create challenging conditions due to prolonged occlusions where the tracker object re-appears under different pose and illumination. Our work proposes SiamReID, a novel re-identification framework for Siamese trackers, that incorporates confuser rejection during prolonged occlusions and is well-suited for aerial tracking. The re-identification feature is trained using both triplet loss and a class balanced loss. Our approach achieves state-of-the-art performance in the UAVDT single object tracking benchmark.
Automated Detection of Abnormal EEGs in Epilepsy With a Compact and Efficient CNN Model
May 21, 2021

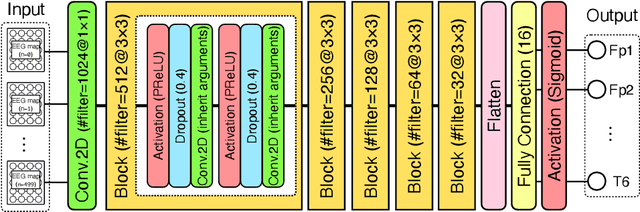
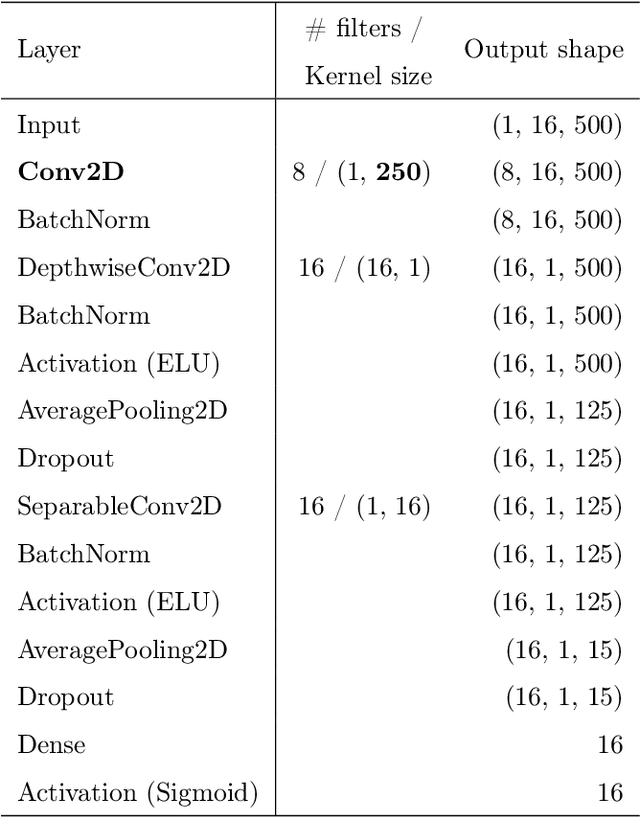
Electroencephalography (EEG) is essential for the diagnosis of epilepsy, but it requires expertise and experience to identify abnormalities. It is thus crucial to develop automated models for the detection of abnormal EEGs related to epilepsy. This paper describes the development of a novel class of compact and efficient convolutional neural networks (CNNs) for detecting abnormal time intervals and electrodes in EEGs for epilepsy. The designed model is inspired by a CNN developed for brain-computer interfacing called multichannel EEGNet (mEEGNet). Unlike the EEGNet, the proposed model, mEEGNet, has the same number of electrode inputs and outputs to detect abnormalities. The mEEGNet was evaluated with a clinical dataset consisting of 29 cases of juvenile and childhood absence epilepsy labeled by a clinical expert. The labels were given to paroxysmal discharges visually observed in both ictal (seizure) and interictal (nonseizure) intervals. Results showed that the mEEGNet detected abnormal EEGs with the area under the curve, F1-values, and sensitivity equivalent to or higher than those of existing CNNs. Moreover, the number of parameters is much smaller than other CNN models. To our knowledge, the dataset of absence epilepsy validated with machine learning through this research is the largest in the literature.
A Detector-oblivious Multi-arm Network for Keypoint Matching
Apr 05, 2021
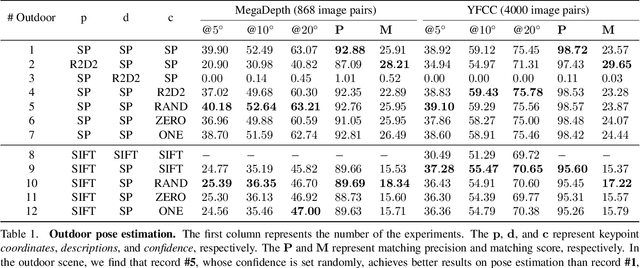
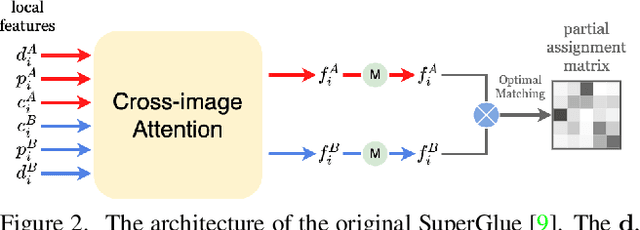
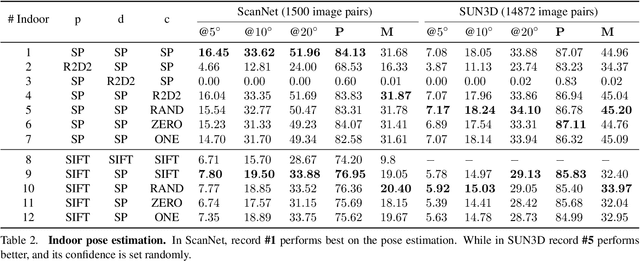
This paper presents a matching network to establish point correspondence between images. We propose a Multi-Arm Network (MAN) to learn region overlap and depth, which can greatly improve the keypoint matching robustness while bringing little computational cost during the inference stage. Another design that makes this framework different from many existing learning based pipelines that require re-training when a different keypoint detector is adopted, our network can directly work with different keypoint detectors without such a time-consuming re-training process. Comprehensive experiments conducted on outdoor and indoor datasets demonstrated that our proposed MAN outperforms state-of-the-art methods. Code will be made publicly available.
Real-time cortical simulations - Energy and interconnect scaling on distributed systems
Dec 12, 2018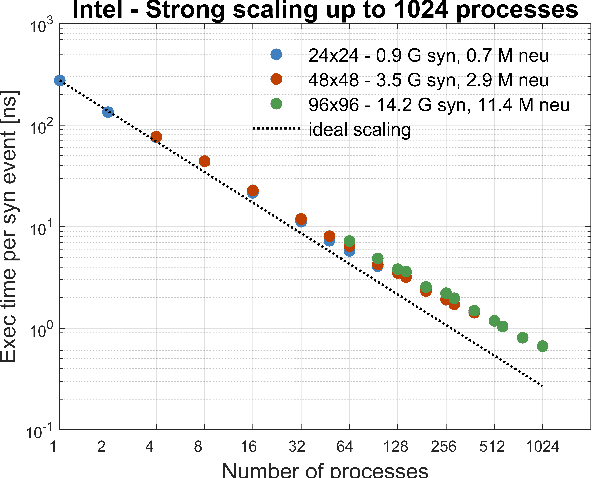
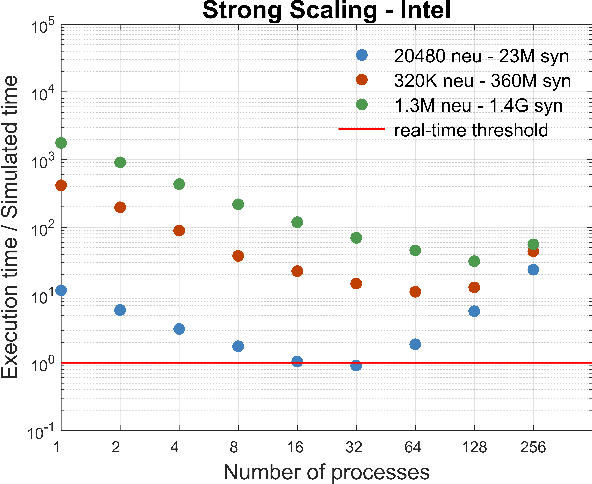
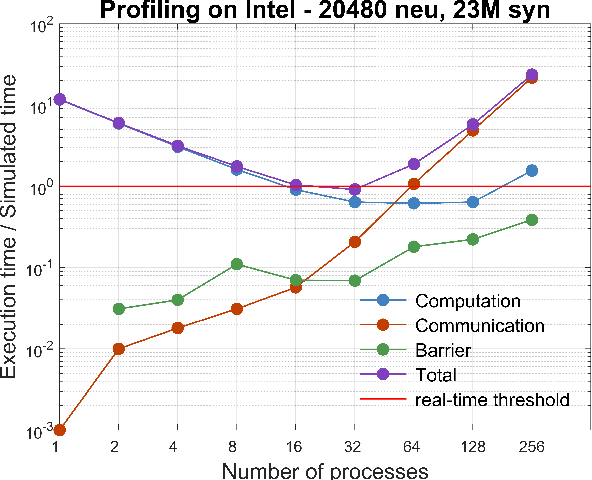
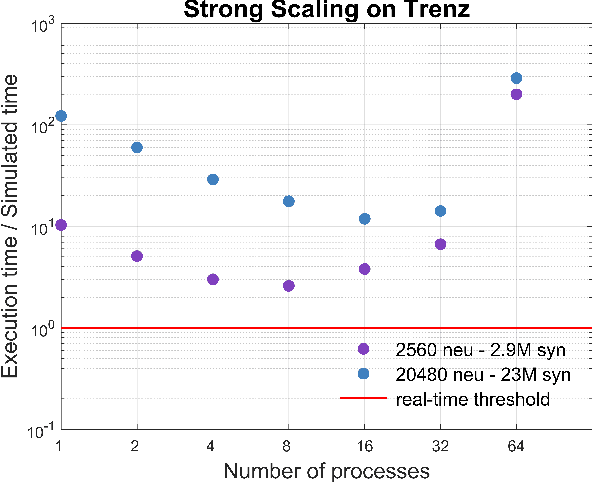
We profile the impact of computation and inter-processor communication on the energy consumption and on the scaling of cortical simulations approaching the real-time regime on distributed computing platforms. Also, the speed and energy consumption of processor architectures typical of standard HPC and embedded platforms are compared. We demonstrate the importance of the design of low-latency interconnect for speed and energy consumption. The cost of cortical simulations is quantified using the Joule per synaptic event metric on both architectures. Reaching efficient real-time on large scale cortical simulations is of increasing relevance for both future bio-inspired artificial intelligence applications and for understanding the cognitive functions of the brain, a scientific quest that will require to embed large scale simulations into highly complex virtual or real worlds. This work stands at the crossroads between the WaveScalES experiment in the Human Brain Project (HBP), which includes the objective of large scale thalamo-cortical simulations of brain states and their transitions, and the ExaNeSt and EuroExa projects, that investigate the design of an ARM-based, low-power High Performance Computing (HPC) architecture with a dedicated interconnect scalable to million of cores; simulation of deep sleep Slow Wave Activity (SWA) and Asynchronous aWake (AW) regimes expressed by thalamo-cortical models are among their benchmarks.
Multi-objective Optimisation of Digital Circuits based on Cell Mapping in an Industrial EDA Flow
May 21, 2021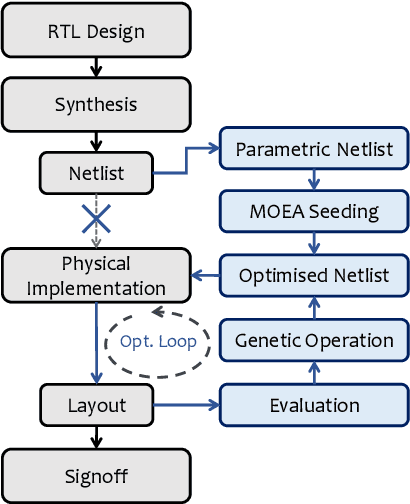
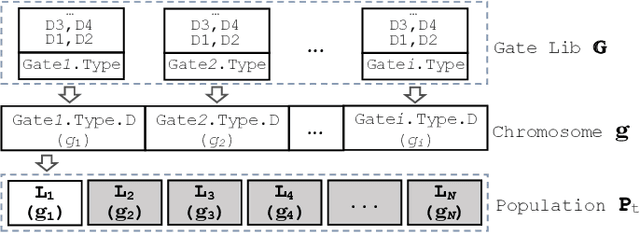
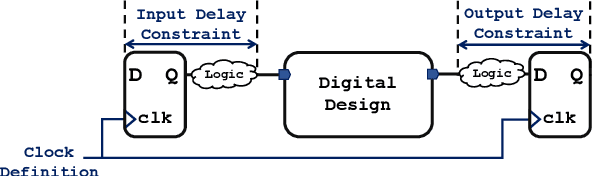
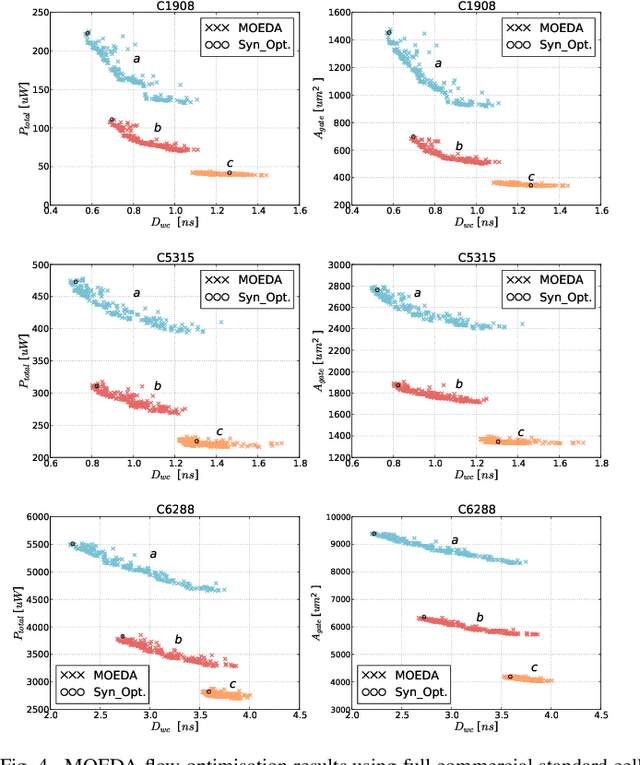
Modern electronic design automation (EDA) tools can handle the complexity of state-of-the-art electronic systems by decomposing them into smaller blocks or cells, introducing different levels of abstraction and staged design flows. However, throughout each independent-optimised design step, overhead and inefficiency can accumulate in the resulting overall design. Performing design-specific optimisation from a more global viewpoint requires more time due to the larger search space, but has the potential to provide solutions with improved performance. In this work, a fully-automated, multi-objective (MO) EDA flow is introduced to address this issue. It specifically tunes drive strength mapping, preceding physical implementation, through multi-objective population-based search algorithms. Designs are evaluated with respect to their power, performance and area (PPA). The proposed approach is capable of expanding the design space, offering a set of Pareto-optimised trade-off solutions for different case-specific utilisation. We have applied the proposed MOEDA framework to ISCAS-85 benchmark circuits using a commercial 65nm standard cell library. The experimental results demonstrate how the MOEDA flow enhances the solutions initially generated by the standard digital flow, and how simultaneously a significant improvement in PPA metrics is achieved.
Word-level Text Highlighting of Medical Texts forTelehealth Services
May 21, 2021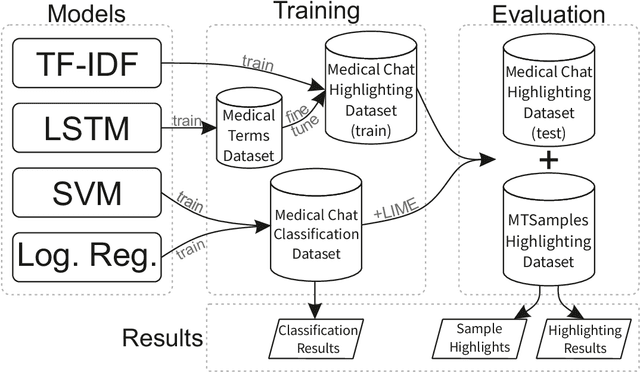
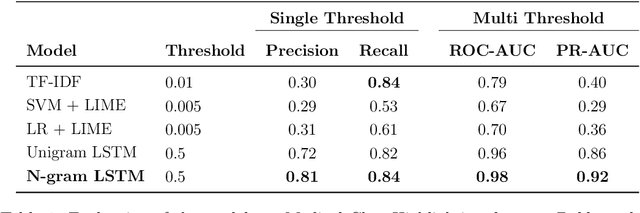

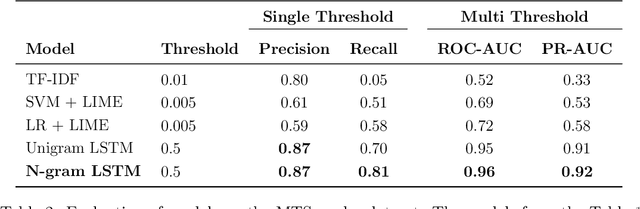
The medical domain is often subject to information overload. The digitization of healthcare, constant updates to online medical repositories, and increasing availability of biomedical datasets make it challenging to effectively analyze the data. This creates additional work for medical professionals who are heavily dependent on medical data to complete their research and consult their patients. This paper aims to show how different text highlighting techniques can capture relevant medical context. This would reduce the doctors' cognitive load and response time to patients by facilitating them in making faster decisions, thus improving the overall quality of online medical services. Three different word-level text highlighting methodologies are implemented and evaluated. The first method uses TF-IDF scores directly to highlight important parts of the text. The second method is a combination of TF-IDF scores and the application of Local Interpretable Model-Agnostic Explanations to classification models. The third method uses neural networks directly to make predictions on whether or not a word should be highlighted. The results of our experiments show that the neural network approach is successful in highlighting medically-relevant terms and its performance is improved as the size of the input segment increases.
Interpretation of multi-label classification models using shapley values
Apr 21, 2021
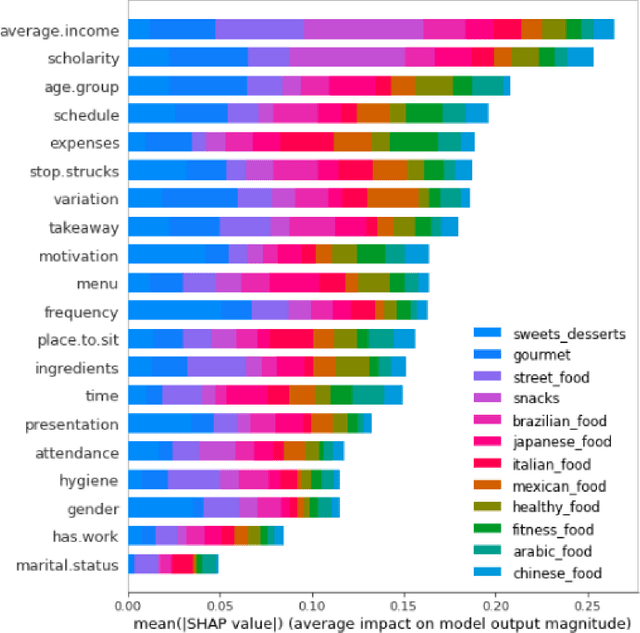
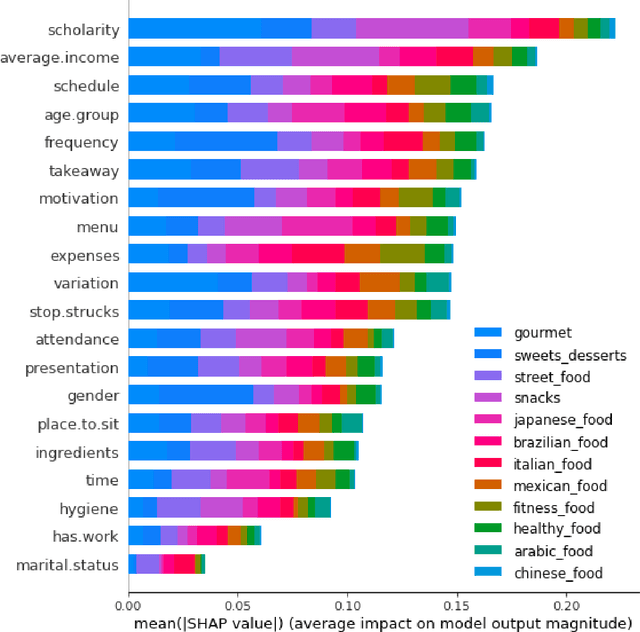
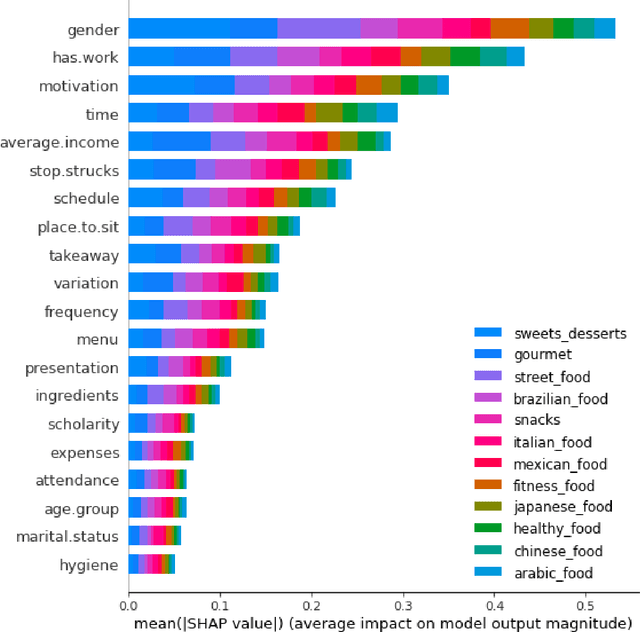
Multi-label classification is a type of classification task, it is used when there are two or more classes, and the data point we want to predict may belong to none of the classes or all of them at the same time. In the real world, many applications are actually multi-label involved, including information retrieval, multimedia content annotation, web mining, and so on. A game theory-based framework known as SHapley Additive exPlanations (SHAP) has been applied to explain various supervised learning models without being aware of the exact model. Herein, this work further extends the explanation of multi-label classification task by using the SHAP methodology. The experiment demonstrates a comprehensive comparision of different algorithms on well known multi-label datasets and shows the usefulness of the interpretation.
Brittle Features May Help Anomaly Detection
Apr 21, 2021
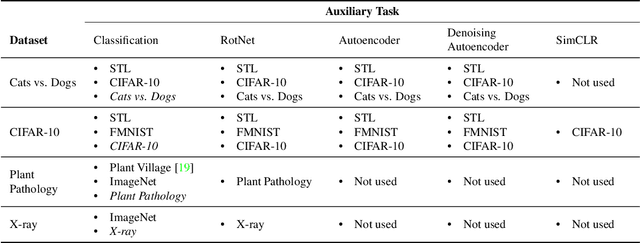
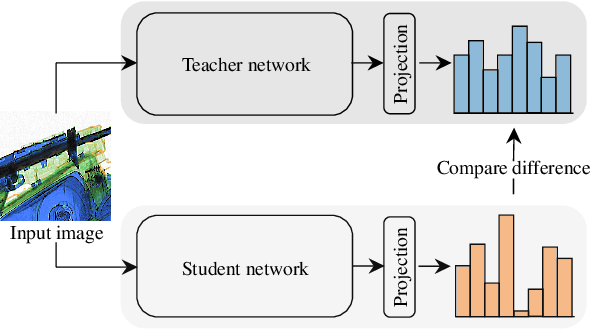
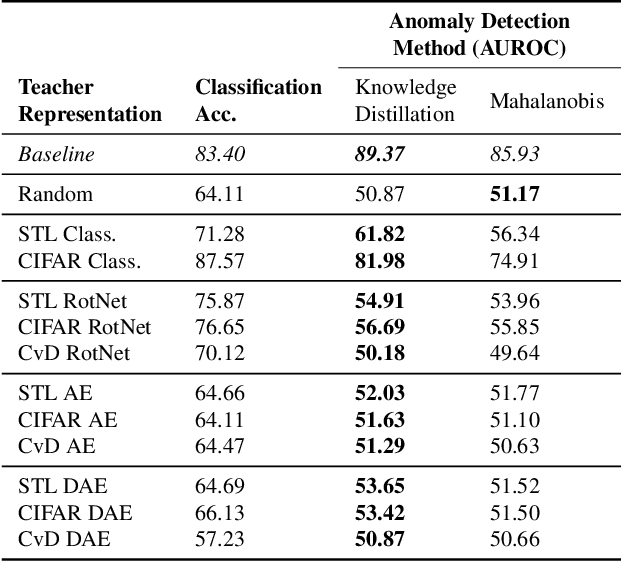
One-class anomaly detection is challenging. A representation that clearly distinguishes anomalies from normal data is ideal, but arriving at this representation is difficult since only normal data is available at training time. We examine the performance of representations, transferred from auxiliary tasks, for anomaly detection. Our results suggest that the choice of representation is more important than the anomaly detector used with these representations, although knowledge distillation can work better than using the representations directly. In addition, separability between anomalies and normal data is important but not the sole factor for a good representation, as anomaly detection performance is also correlated with more adversarially brittle features in the representation space. Finally, we show our configuration can detect 96.4% of anomalies in a genuine X-ray security dataset, outperforming previous results.
Drift Estimation with Graphical Models
Feb 02, 2021
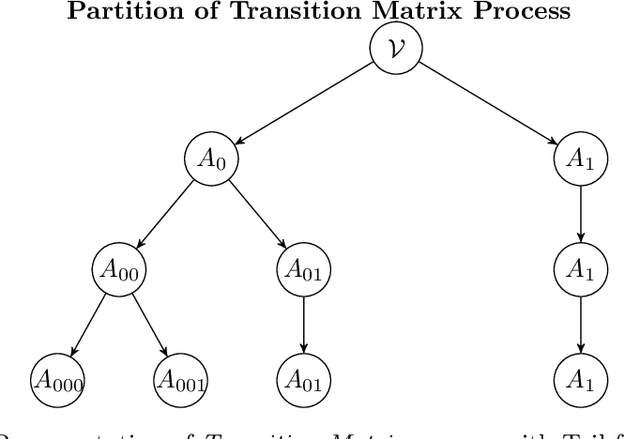

This paper deals with the issue of concept drift in supervised machine learn-ing. We make use of graphical models to elicit the visible structure of the dataand we infer from there changes in the hidden context. Differently from previous concept-drift detection methods, this application does not depend on the supervised machine learning model in use for a specific target variable, but it tries to assess the concept drift as independent characteristic of the evolution of a dataset. Specifically, we investigate how a graphical model evolves by looking at the creation of new links and the disappearing of existing ones in different time periods. The paper suggests a method that highlights the changes and eventually produce a metric to evaluate the stability over time. The paper evaluate the method with real world data on the Australian Electric market.