 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating Pre-Trained Models for User Feedback Analysis in Software Engineering: A Study on Classification of App-Reviews
Apr 12, 2021
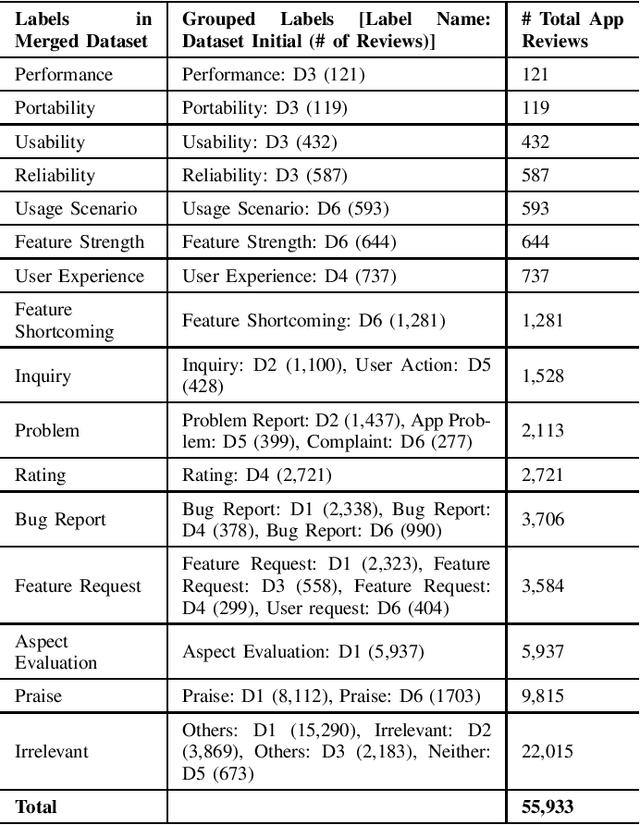
Context: Mobile app reviews written by users on app stores or social media are significant resources for app developers.Analyzing app reviews have proved to be useful for many areas of software engineering (e.g., requirement engineering, testing). Automatic classification of app reviews requires extensive efforts to manually curate a labeled dataset. When the classification purpose changes (e.g. identifying bugs versus usability issues or sentiment), new datasets should be labeled, which prevents the extensibility of the developed models for new desired classes/tasks in practice. Recent pre-trained neural language models (PTM) are trained on large corpora in an unsupervised manner and have found success in solving similar Natural Language Processing problems. However, the applicability of PTMs is not explored for app review classification Objective: We investigate the benefits of PTMs for app review classification compared to the existing models, as well as the transferability of PTMs in multiple settings. Method: We empirically study the accuracy and time efficiency of PTMs compared to prior approaches using six datasets from literature. In addition, we investigate the performance of the PTMs trained on app reviews (i.e. domain-specific PTMs) . We set up different studies to evaluate PTMs in multiple settings: binary vs. multi-class classification, zero-shot classification (when new labels are introduced to the model), multi-task setting, and classification of reviews from different resources. The datasets are manually labeled app review datasets from Google Play Store, Apple App Store, and Twitter data. In all cases, Micro and Macro Precision, Recall, and F1-scores will be used and we will report the time required for training and prediction with the models.
Approximating Real-Time Recurrent Learning with Random Kronecker Factors
May 28, 2018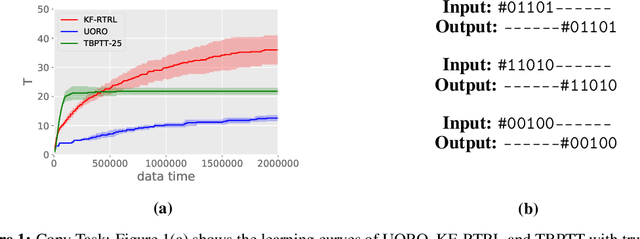
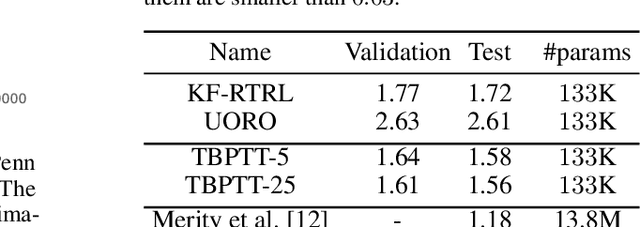
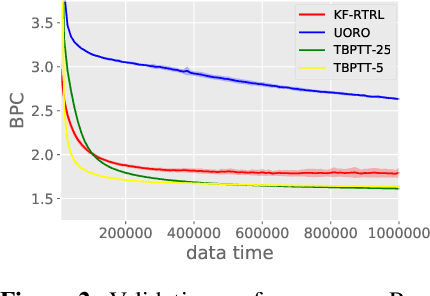
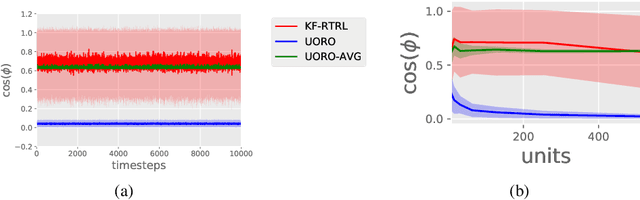
Despite all the impressive advances of recurrent neural networks, sequential data is still in need of better modelling. Truncated backpropagation through time (TBPTT), the learning algorithm most widely used in practice, suffers from the truncation bias, which drastically limits its ability to learn long-term dependencies.The Real-Time Recurrent Learning algorithm (RTRL) addresses this issue, but its high computational requirements make it infeasible in practice. The Unbiased Online Recurrent Optimization algorithm (UORO) approximates RTRL with a smaller runtime and memory cost, but with the disadvantage of obtaining noisy gradients that also limit its practical applicability. In this paper we propose the Kronecker Factored RTRL (KF-RTRL) algorithm that uses a Kronecker product decomposition to approximate the gradients for a large class of RNNs. We show that KF-RTRL is an unbiased and memory efficient online learning algorithm. Our theoretical analysis shows that, under reasonable assumptions, the noise introduced by our algorithm is not only stable over time but also asymptotically much smaller than the one of the UORO algorithm. We also confirm these theoretical results experimentally. Further, we show empirically that the KF-RTRL algorithm captures long-term dependencies and almost matches the performance of TBPTT on real world tasks by training Recurrent Highway Networks on a synthetic string memorization task and on the Penn TreeBank task, respectively. These results indicate that RTRL based approaches might be a promising future alternative to TBPTT.
Trajectory Prediction for Autonomous Driving with Topometric Map
May 09, 2021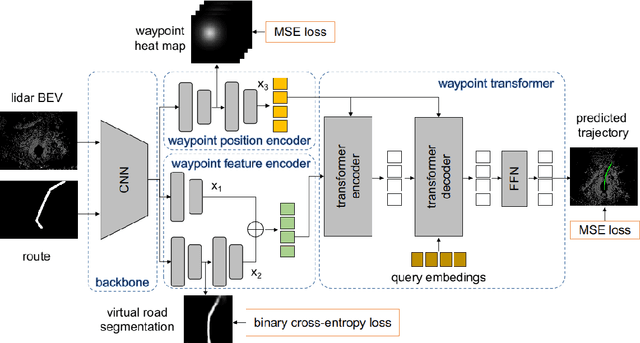
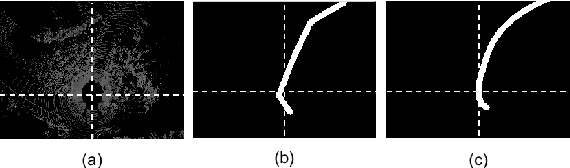
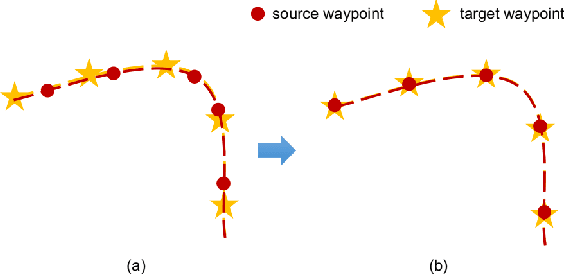
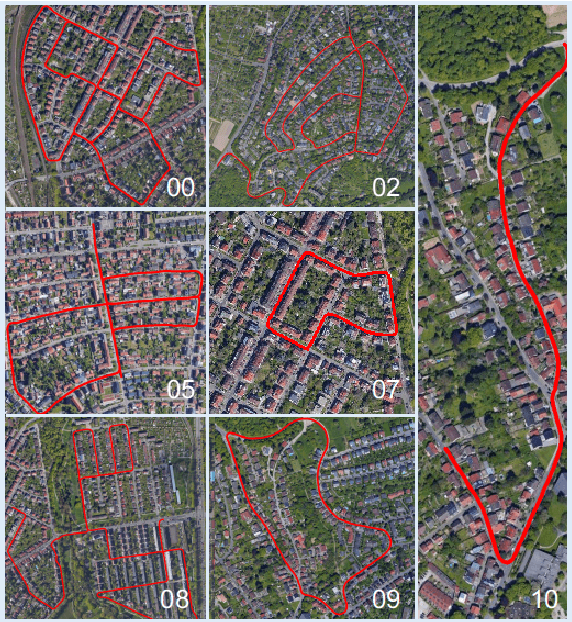
State-of-the-art autonomous driving systems rely on high definition (HD) maps for localization and navigation. However, building and maintaining HD maps is time-consuming and expensive. Furthermore, the HD maps assume structured environment such as the existence of major road and lanes, which are not present in rural areas. In this work, we propose an end-to-end transformer networks based approach for map-less autonomous driving. The proposed model takes raw LiDAR data and noisy topometric map as input and produces precise local trajectory for navigation. We demonstrate the effectiveness of our method in real-world driving data, including both urban and rural areas. The experimental results show that the proposed method outperforms state-of-the-art multimodal methods and is robust to the perturbations of the topometric map. The code of the proposed method is publicly available at \url{https://github.com/Jiaolong/trajectory-prediction}.
On the Computational Intelligibility of Boolean Classifiers
Apr 13, 2021
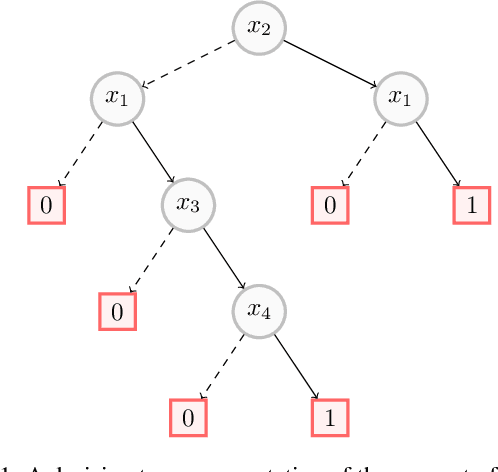


In this paper, we investigate the computational intelligibility of Boolean classifiers, characterized by their ability to answer XAI queries in polynomial time. The classifiers under consideration are decision trees, DNF formulae, decision lists, decision rules, tree ensembles, and Boolean neural nets. Using 9 XAI queries, including both explanation queries and verification queries, we show the existence of large intelligibility gap between the families of classifiers. On the one hand, all the 9 XAI queries are tractable for decision trees. On the other hand, none of them is tractable for DNF formulae, decision lists, random forests, boosted decision trees, Boolean multilayer perceptrons, and binarized neural networks.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
May 13, 2021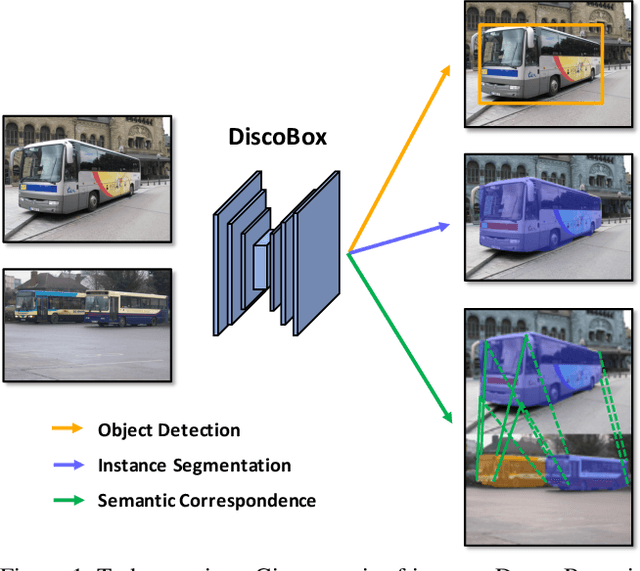
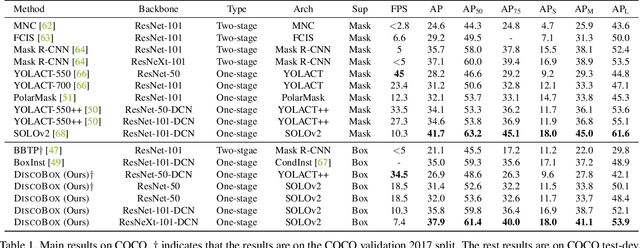
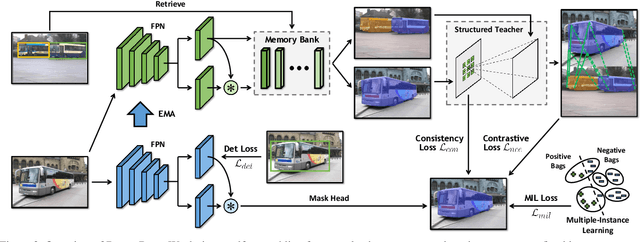
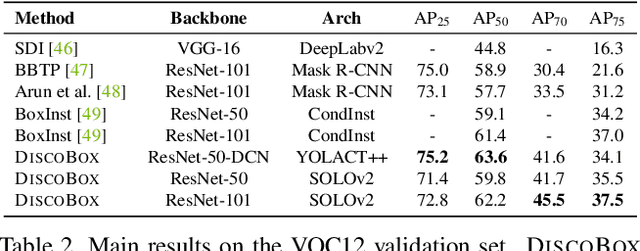
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
Onoma-to-wave: Environmental sound synthesis from onomatopoeic words
Feb 11, 2021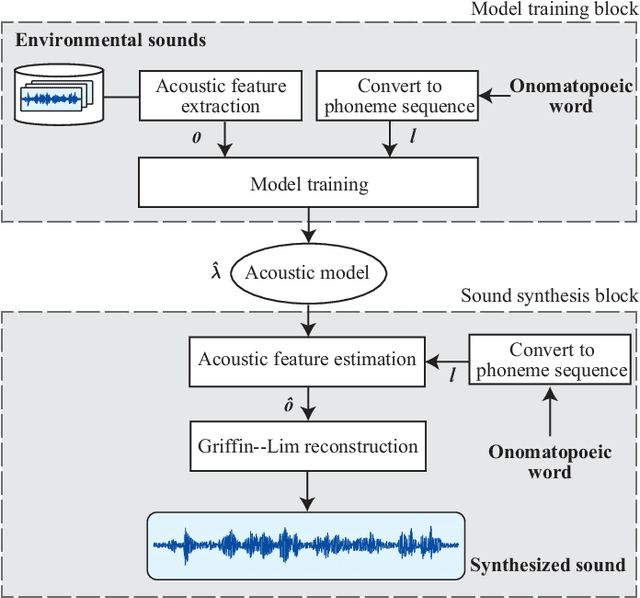
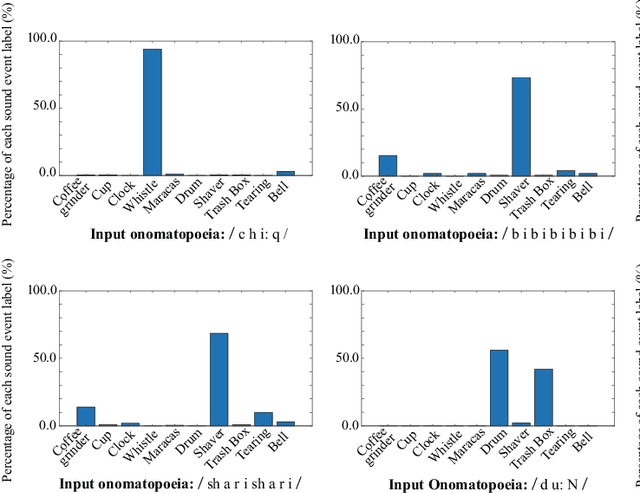
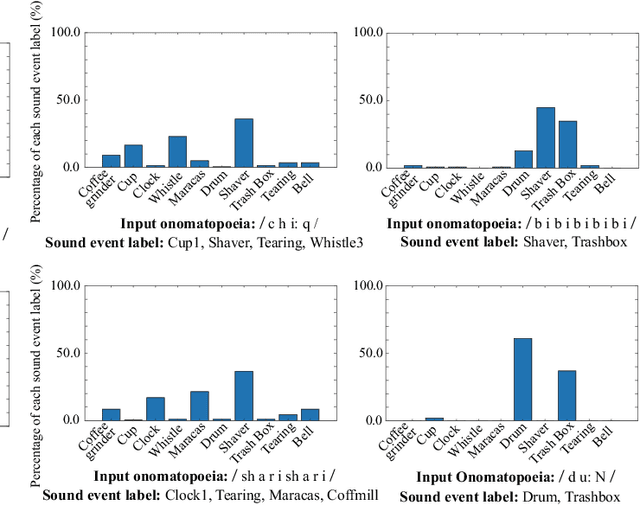
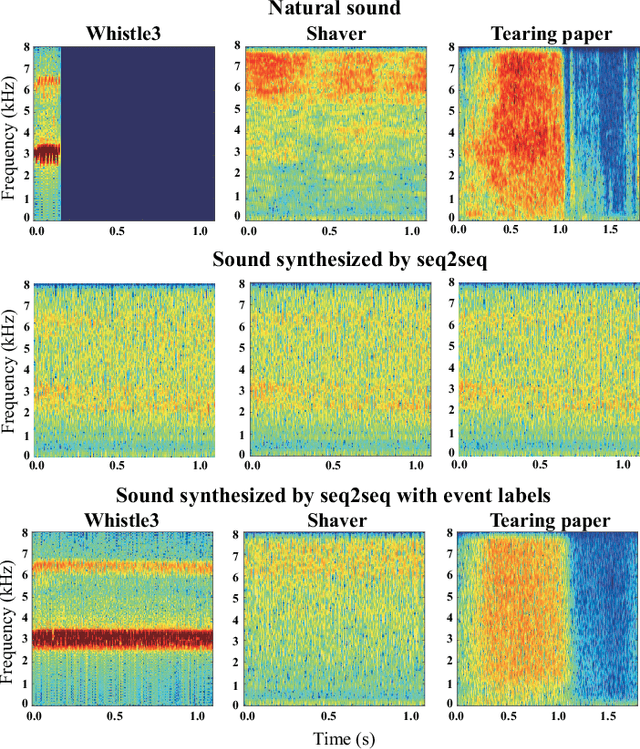
In this paper, we propose a new framework for environmental sound synthesis using onomatopoeic words and sound event labels. The conventional method of environmental sound synthesis, in which only sound event labels are used, cannot finely control the time-frequency structural features of synthesized sounds, such as sound duration, timbre, and pitch. There are various ways to express environmental sound other than sound event labels, such as the use of onomatopoeic words. An onomatopoeic word, which is a character sequence for phonetically imitating a sound, has been shown to be effective for describing the phonetic feature of sounds. We believe that environmental sound synthesis using onomatopoeic words will enable us to control the fine time-frequency structural features of synthesized sounds, such as sound duration, timbre, and pitch. In this paper, we thus propose environmental sound synthesis from onomatopoeic words on the basis of a sequence-to-sequence framework. To convert onomatopoeic words to environmental sound, we use a sequence-to-sequence framework. We also propose a method of environmental sound synthesis using onomatopoeic words and sound event labels to control the fine time-frequency structure and frequency property of synthesized sounds. Our subjective experiments show that the proposed method achieves the same level of sound quality as the conventional method using WaveNet. Moreover, our methods are better than the conventional method in terms of the expressiveness of synthesized sounds to onomatopoeic words.
Sub-Linear Memory: How to Make Performers SLiM
Dec 21, 2020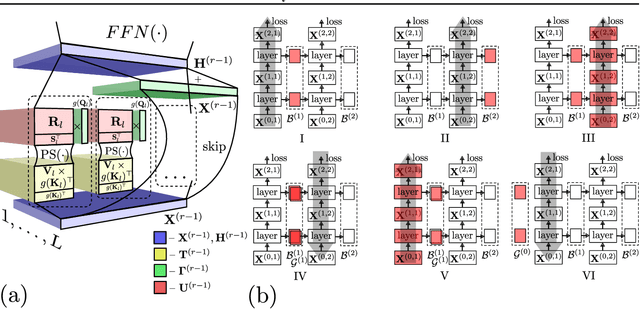

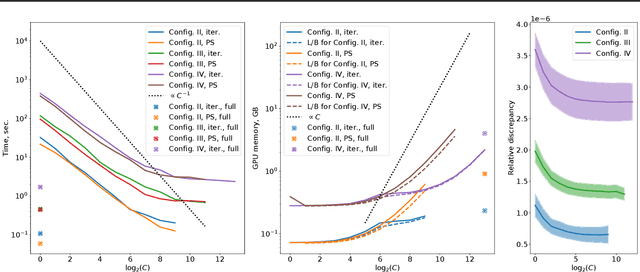
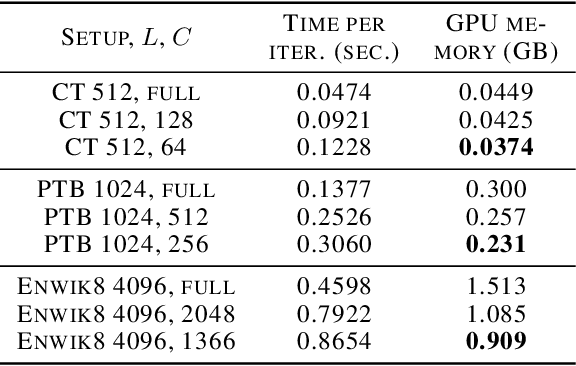
The Transformer architecture has revolutionized deep learning on sequential data, becoming ubiquitous in state-of-the-art solutions for a wide variety of applications. Yet vanilla Transformers are notoriously resource-expensive, requiring $O(L^2)$ in serial time and memory as functions of input length $L$. Recent works proposed various linear self-attention mechanisms, scaling only as $O(L)$ for serial computation. We perform a thorough analysis of recent Transformer mechanisms with linear self-attention, Performers, in terms of overall computational complexity. We observe a remarkable computational flexibility: forward and backward propagation can be performed with no approximations using sublinear memory as a function of $L$ (in addition to negligible storage for the input sequence), at a cost of greater time complexity in the parallel setting. In the extreme case, a Performer consumes only $O(1)$ memory during training, and still requires $O(L)$ time. This discovered time-memory tradeoff can be used for training or, due to complete backward-compatibility, for fine-tuning on a low-memory device, e.g. a smartphone or an earlier-generation GPU, thus contributing towards decentralized and democratized deep learning.
Prediction-assistant Frame Super-Resolution for Video Streaming
Mar 17, 2021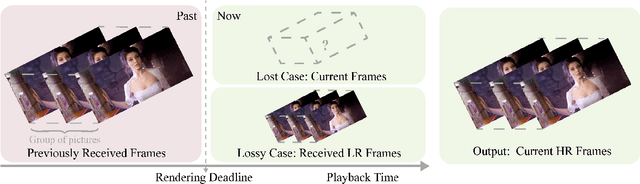
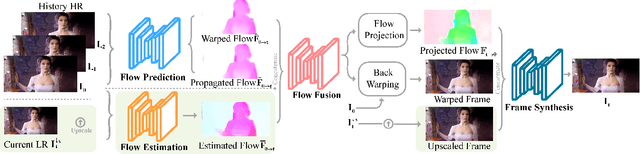

Video frame transmission delay is critical in real-time applications such as online video gaming, live show, etc. The receiving deadline of a new frame must catch up with the frame rendering time. Otherwise, the system will buffer a while, and the user will encounter a frozen screen, resulting in unsatisfactory user experiences. An effective approach is to transmit frames in lower-quality under poor bandwidth conditions, such as using scalable video coding. In this paper, we propose to enhance video quality using lossy frames in two situations. First, when current frames are too late to receive before rendering deadline (i.e., lost), we propose to use previously received high-resolution images to predict the future frames. Second, when the quality of the currently received frames is low~(i.e., lossy), we propose to use previously received high-resolution frames to enhance the low-quality current ones. For the first case, we propose a small yet effective video frame prediction network. For the second case, we improve the video prediction network to a video enhancement network to associate current frames as well as previous frames to restore high-quality images. Extensive experimental results demonstrate that our method performs favorably against state-of-the-art algorithms in the lossy video streaming environment.
Better Algorithms for Individually Fair $k$-Clustering
Jun 23, 2021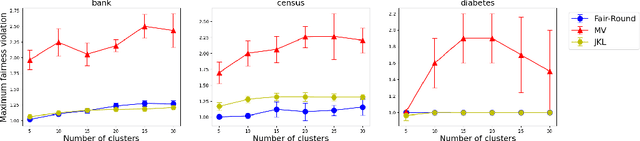
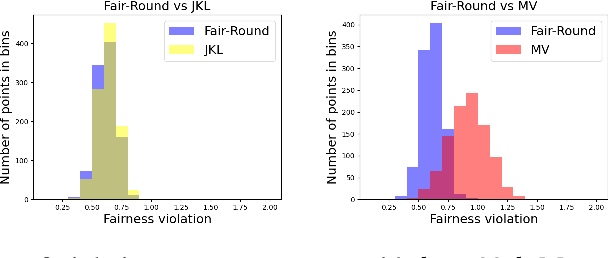
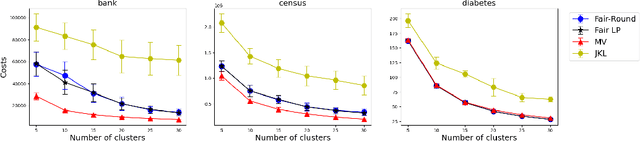
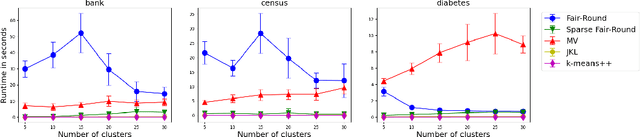
We study data clustering problems with $\ell_p$-norm objectives (e.g. $k$-Median and $k$-Means) in the context of individual fairness. The dataset consists of $n$ points, and we want to find $k$ centers such that (a) the objective is minimized, while (b) respecting the individual fairness constraint that every point $v$ has a center within a distance at most $r(v)$, where $r(v)$ is $v$'s distance to its $(n/k)$th nearest point. Jung, Kannan, and Lutz [FORC 2020] introduced this concept and designed a clustering algorithm with provable (approximate) fairness and objective guarantees for the $\ell_\infty$ or $k$-Center objective. Mahabadi and Vakilian [ICML 2020] revisited this problem to give a local-search algorithm for all $\ell_p$-norms. Empirically, their algorithms outperform Jung et. al.'s by a large margin in terms of cost (for $k$-Median and $k$-Means), but they incur a reasonable loss in fairness. In this paper, our main contribution is to use Linear Programming (LP) techniques to obtain better algorithms for this problem, both in theory and in practice. We prove that by modifying known LP rounding techniques, one gets a worst-case guarantee on the objective which is much better than in MV20, and empirically, this objective is extremely close to the optimal. Furthermore, our theoretical fairness guarantees are comparable with MV20 in theory, and empirically, we obtain noticeably fairer solutions. Although solving the LP {\em exactly} might be prohibitive, we demonstrate that in practice, a simple sparsification technique drastically improves the run-time of our algorithm.
Deep Animation Video Interpolation in the Wild
Apr 06, 2021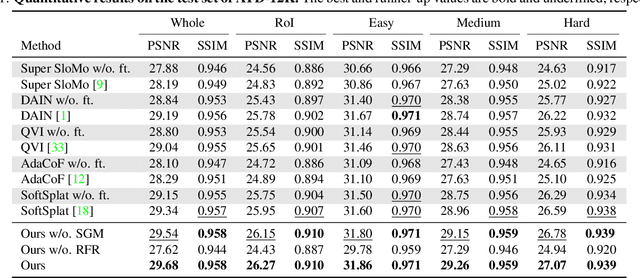

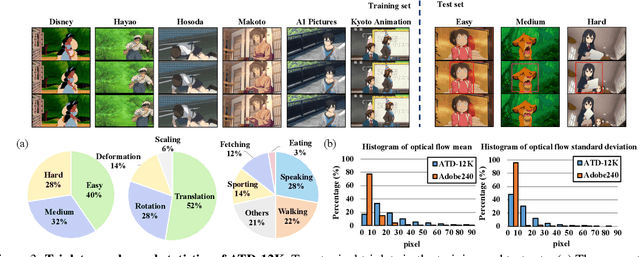
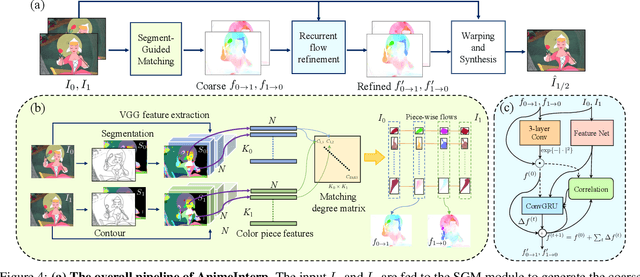
In the animation industry, cartoon videos are usually produced at low frame rate since hand drawing of such frames is costly and time-consuming. Therefore, it is desirable to develop computational models that can automatically interpolate the in-between animation frames. However, existing video interpolation methods fail to produce satisfying results on animation data. Compared to natural videos, animation videos possess two unique characteristics that make frame interpolation difficult: 1) cartoons comprise lines and smooth color pieces. The smooth areas lack textures and make it difficult to estimate accurate motions on animation videos. 2) cartoons express stories via exaggeration. Some of the motions are non-linear and extremely large. In this work, we formally define and study the animation video interpolation problem for the first time. To address the aforementioned challenges, we propose an effective framework, AnimeInterp, with two dedicated modules in a coarse-to-fine manner. Specifically, 1) Segment-Guided Matching resolves the "lack of textures" challenge by exploiting global matching among color pieces that are piece-wise coherent. 2) Recurrent Flow Refinement resolves the "non-linear and extremely large motion" challenge by recurrent predictions using a transformer-like architecture. To facilitate comprehensive training and evaluations, we build a large-scale animation triplet dataset, ATD-12K, which comprises 12,000 triplets with rich annotations. Extensive experiments demonstrate that our approach outperforms existing state-of-the-art interpolation methods for animation videos. Notably, AnimeInterp shows favorable perceptual quality and robustness for animation scenarios in the wild. The proposed dataset and code are available at https://github.com/lisiyao21/AnimeInterp/.