 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning for Real Time Crime Forecasting
Jul 09, 2017
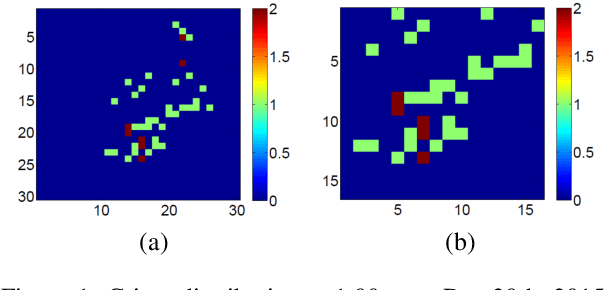
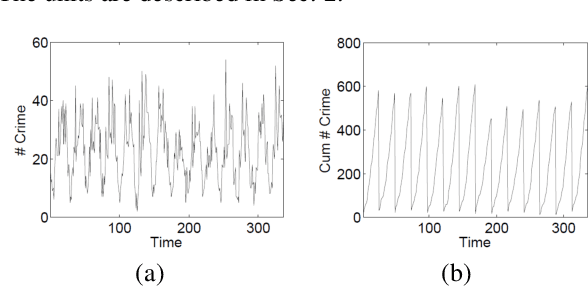
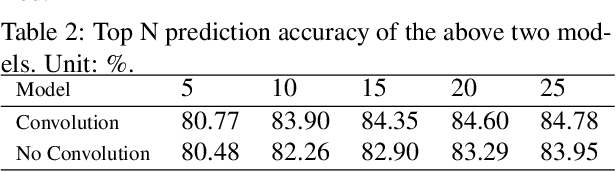
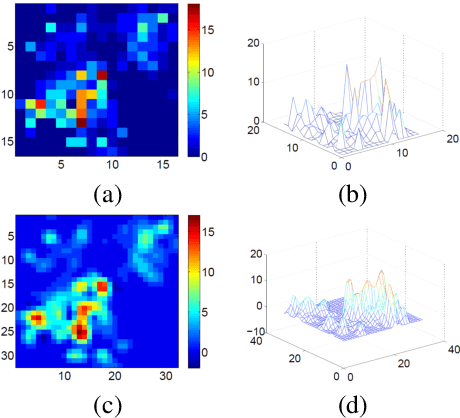
Accurate real time crime prediction is a fundamental issue for public safety, but remains a challenging problem for the scientific community. Crime occurrences depend on many complex factors. Compared to many predictable events, crime is sparse. At different spatio-temporal scales, crime distributions display dramatically different patterns. These distributions are of very low regularity in both space and time. In this work, we adapt the state-of-the-art deep learning spatio-temporal predictor, ST-ResNet [Zhang et al, AAAI, 2017], to collectively predict crime distribution over the Los Angeles area. Our models are two staged. First, we preprocess the raw crime data. This includes regularization in both space and time to enhance predictable signals. Second, we adapt hierarchical structures of residual convolutional units to train multi-factor crime prediction models. Experiments over a half year period in Los Angeles reveal highly accurate predictive power of our models.
Trajectory Optimization of Chance-Constrained Nonlinear Stochastic Systems for Motion Planning and Control
Jun 05, 2021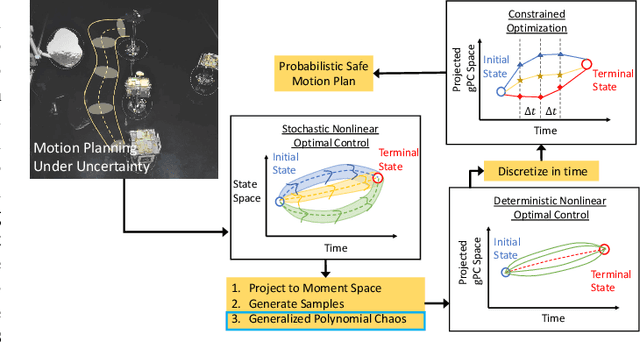
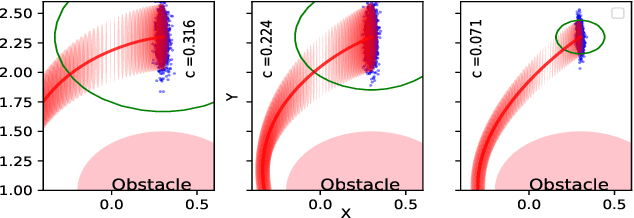
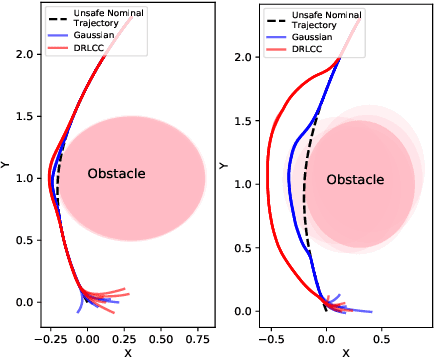
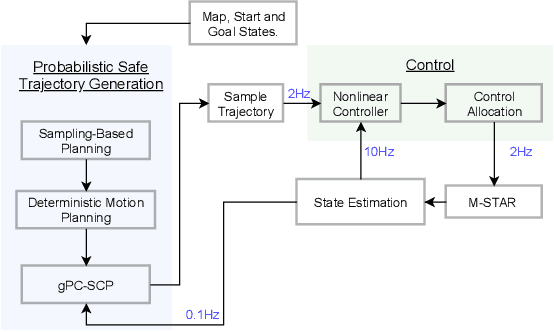
We present gPC-SCP: Generalized Polynomial Chaos-based Sequential Convex Programming method to compute a sub-optimal solution for a continuous-time chance-constrained stochastic nonlinear optimal control problem (SNOC) problem. The approach enables motion planning and control of robotic systems under uncertainty. The proposed method involves two steps. The first step is to derive a deterministic nonlinear optimal control problem (DNOC) with convex constraints that are surrogate to the SNOC by using gPC expansion and the distributionally-robust convex subset of the chance constraints. The second step is to solve the DNOC problem using sequential convex programming (SCP) for trajectory generation and control. We prove that in the unconstrained case, the optimal value of the DNOC converges to that of SNOC asymptotically and that any feasible solution of the constrained DNOC is a feasible solution of the chance-constrained SNOC. We derive a stable stochastic model predictive controller using the gPC-SCP for tracking a trajectory in the presence of uncertainty. We empirically demonstrate the efficacy of the gPC-SCP method for the following three test cases: 1) collision checking under uncertainty in actuation, 2) collision checking with stochastic obstacle model, and 3) safe trajectory tracking under uncertainty in the dynamics and obstacle location by using a receding horizon control approach. We validate the effectiveness of the gPC-SCP method on the robotic spacecraft testbed.
An FPGA Implementation of a Time Delay Reservoir Using Stochastic Logic
Sep 12, 2018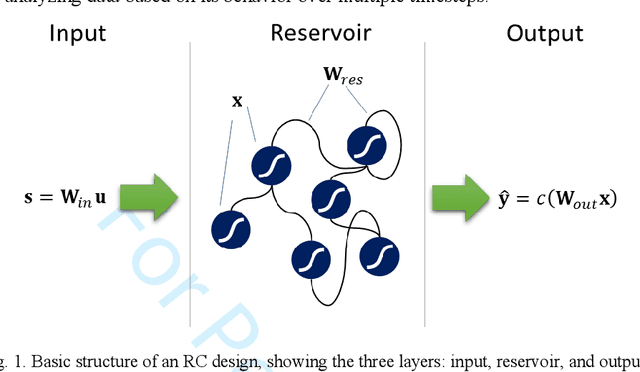
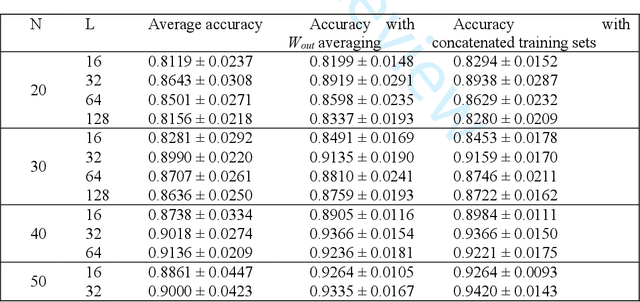
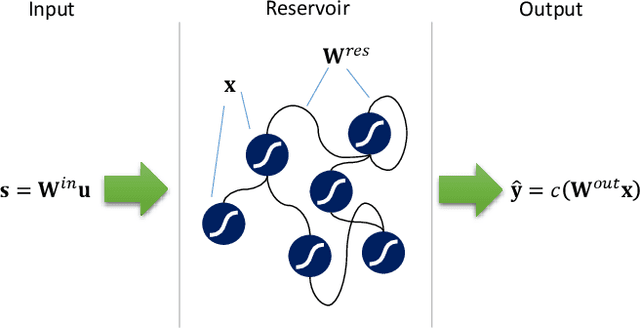
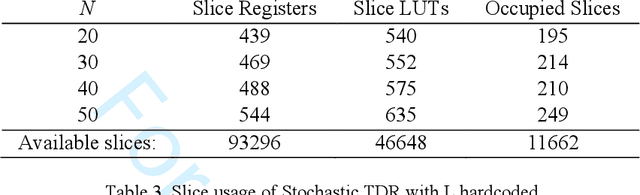
This paper presents and demonstrates a stochastic logic time delay reservoir design in FPGA hardware. The reservoir network approach is analyzed using a number of metrics, such as kernel quality, generalization rank, performance on simple benchmarks, and is also compared to a deterministic design. A novel re-seeding method is introduced to reduce the adverse effects of stochastic noise, which may also be implemented in other stochastic logic reservoir computing designs, such as echo state networks. Benchmark results indicate that the proposed design performs well on noise-tolerant classification problems, but more work needs to be done to improve the stochastic logic time delay reservoirs robustness for regression problems. In addition, we show that the stochastic design can significantly reduce area cost if the conversion between binary and stochastic representations implemented efficiently.
Applying VertexShuffle Toward 360-Degree Video Super-Resolution on Focused-Icosahedral-Mesh
Jun 21, 2021

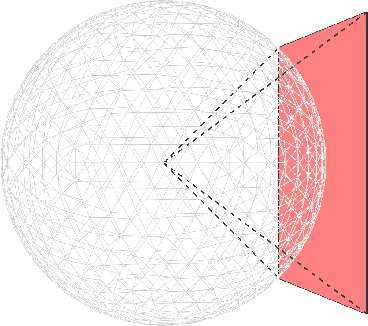
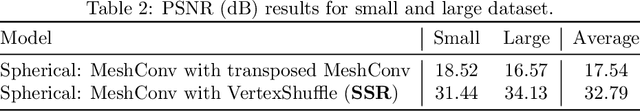
With the emerging of 360-degree image/video, augmented reality (AR) and virtual reality (VR), the demand for analysing and processing spherical signals get tremendous increase. However, plenty of effort paid on planar signals that projected from spherical signals, which leading to some problems, e.g. waste of pixels, distortion. Recent advances in spherical CNN have opened up the possibility of directly analysing spherical signals. However, they pay attention to the full mesh which makes it infeasible to deal with situations in real-world application due to the extremely large bandwidth requirement. To address the bandwidth waste problem associated with 360-degree video streaming and save computation, we exploit Focused Icosahedral Mesh to represent a small area and construct matrices to rotate spherical content to the focused mesh area. We also proposed a novel VertexShuffle operation that can significantly improve both the performance and the efficiency compared to the original MeshConv Transpose operation introduced in UGSCNN. We further apply our proposed methods on super resolution model, which is the first to propose a spherical super-resolution model that directly operates on a mesh representation of spherical pixels of 360-degree data. To evaluate our model, we also collect a set of high-resolution 360-degree videos to generate a spherical image dataset. Our experiments indicate that our proposed spherical super-resolution model achieves significant benefits in terms of both performance and inference time compared to the baseline spherical super-resolution model that uses the simple MeshConv Transpose operation. In summary, our model achieves great super-resolution performance on 360-degree inputs, achieving 32.79 dB PSNR on average when super-resoluting 16x vertices on the mesh.
DSNet for Real-Time Driving Scene Semantic Segmentation
Dec 06, 2018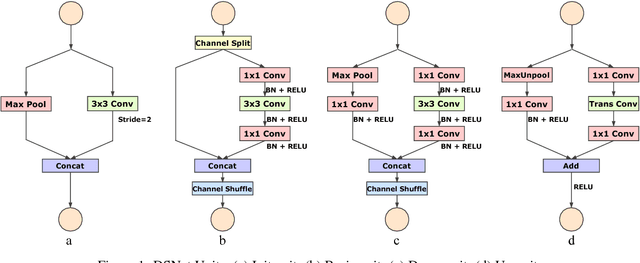
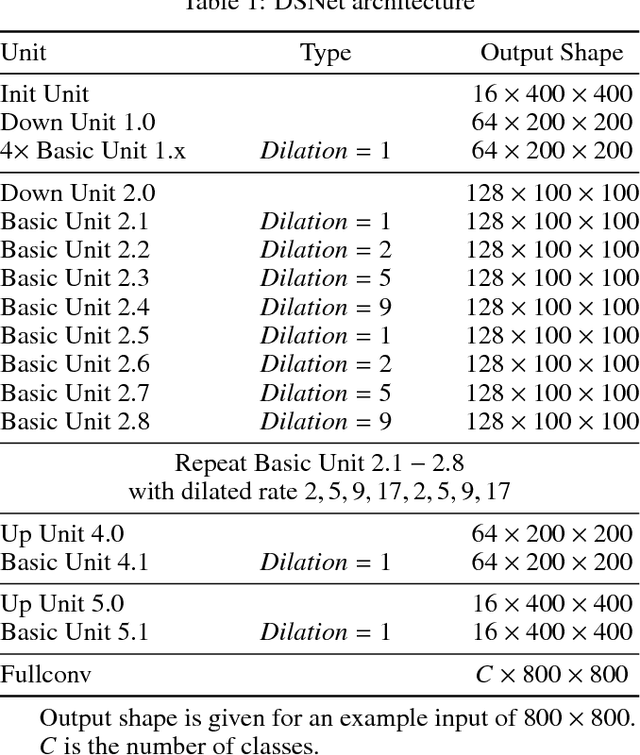
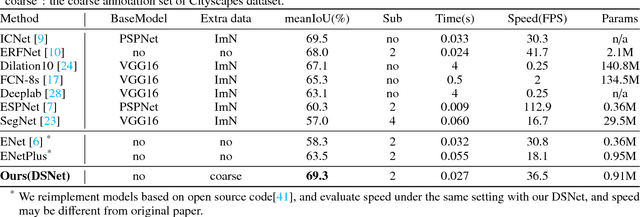
We focus on the very challenging task of semantic segmentation for autonomous driving system. It must deliver decent semantic segmentation result for traffic critical objects real-time. In this paper, we propose a very efficient yet powerful deep neural network for driving scene semantic segmentation termed as Driving Segmentation Network (DSNet). DSNet achieves state-of-the-art balance between accuracy and inference speed through efficient units and architecture design inspired by ShuffleNet V2 and ENet. More importantly, DSNet highlights classes most critical with driving decision making through our novel Driving Importance-weighted Loss. We evaluate DSNet on Cityscapes dataset, our DSNet achieves 71.8% mean Intersection-over-Union (IoU) on validation set and 69.3% on test set. Class-wise IoU scores show that Driving Importance-weighted Loss could improve most driving critical classes by a large margin. Compared with ENet, DSNet is 18.9% more accurate and 1.1+ times faster which implies great potential for autonomous driving application.
On Interaction Between Augmentations and Corruptions in Natural Corruption Robustness
Feb 22, 2021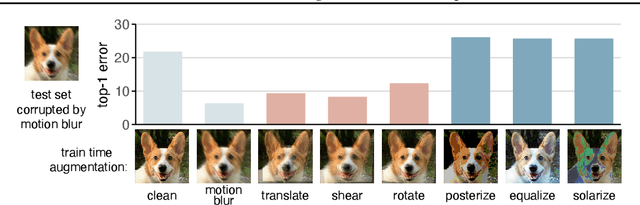
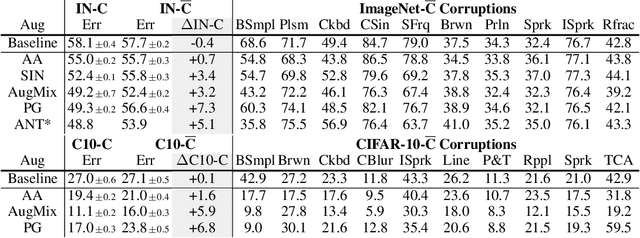
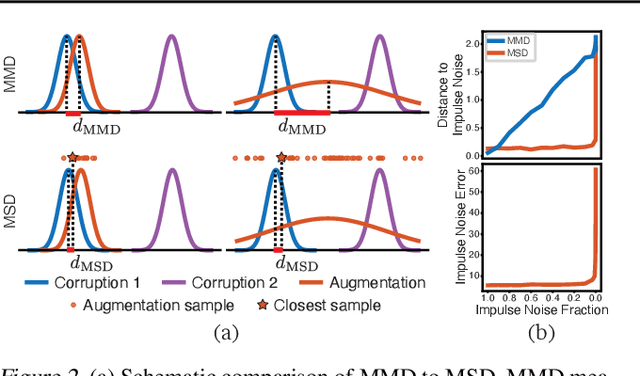
Invariance to a broad array of image corruptions, such as warping, noise, or color shifts, is an important aspect of building robust models in computer vision. Recently, several new data augmentations have been proposed that significantly improve performance on ImageNet-C, a benchmark of such corruptions. However, there is still a lack of basic understanding on the relationship between data augmentations and test-time corruptions. To this end, we develop a feature space for image transforms, and then use a new measure in this space between augmentations and corruptions called the Minimal Sample Distance to demonstrate there is a strong correlation between similarity and performance. We then investigate recent data augmentations and observe a significant degradation in corruption robustness when the test-time corruptions are sampled to be perceptually dissimilar from ImageNet-C in this feature space. Our results suggest that test error can be improved by training on perceptually similar augmentations, and data augmentations may not generalize well beyond the existing benchmark. We hope our results and tools will allow for more robust progress towards improving robustness to image corruptions.
Towards 3D Metric GPR Imaging Based on DNN Noise Removal and Dielectric Estimation
May 15, 2021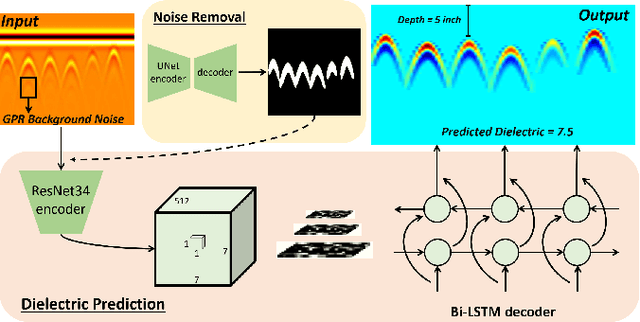

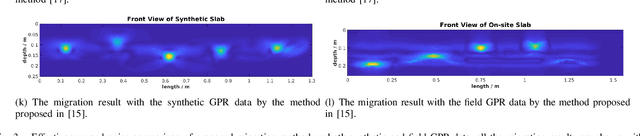
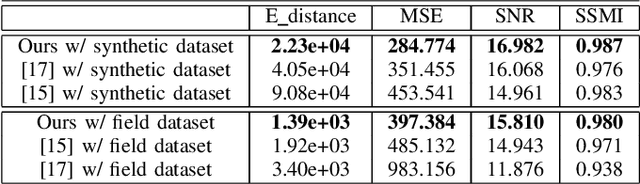
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) devices to detect subsurface objects (i.e., rebars, utility pipes) and reveal the underground scene. The two biggest challenges in GPR-based inspection are the GPR data collection and subsurface target imaging. To address these challenges, we propose a robotic solution that automates the GPR data collection process with a free motion pattern. It facilitates the 3D metric GPR imaging by tagging the pose information with GPR measurement in real-time. We also introduce a deep neural network (DNN) based GPR data analysis method which includes a noise removal segmentation module to clear the noise in GPR raw data and a DielectricNet to estimate the dielectric value of subsurface media in each GPR B-scan data. We use both the field and synthetic data to verify the proposed method. Experimental results demonstrate that our proposed method can achieve better performance and faster processing speed in GPR data collection and 3D GPR imaging than other methods.
* under review
Structured Citation Trend Prediction Using Graph Neural Networks
Apr 06, 2021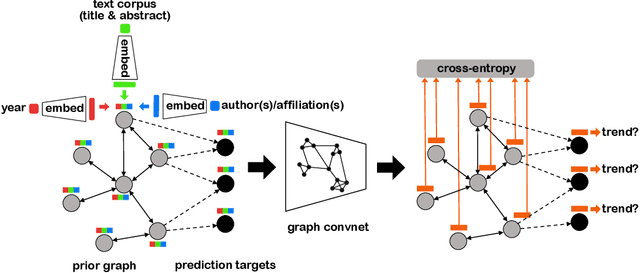
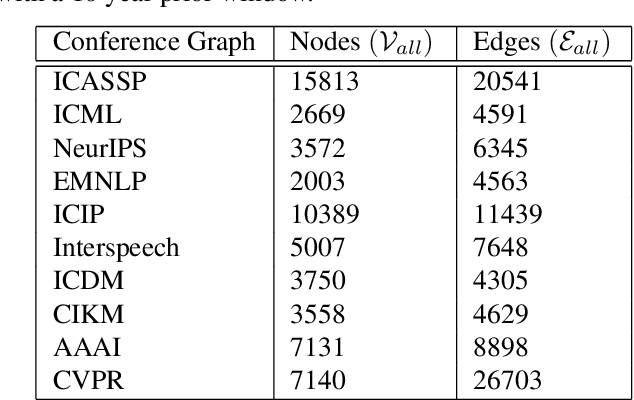
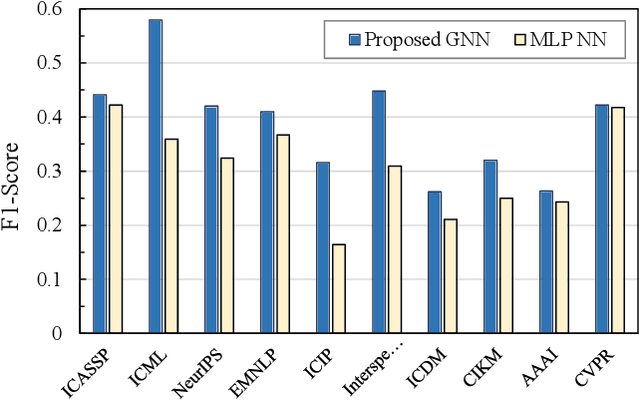
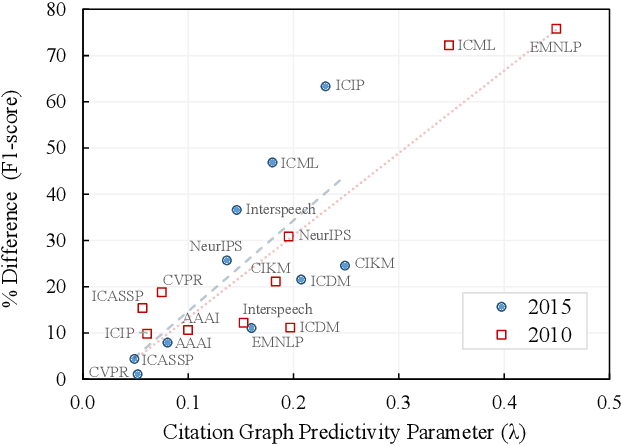
Academic citation graphs represent citation relationships between publications across the full range of academic fields. Top cited papers typically reveal future trends in their corresponding domains which is of importance to both researchers and practitioners. Prior citation prediction methods often require initial citation trends to be established and do not take advantage of the recent advancements in graph neural networks (GNNs). We present GNN-based architecture that predicts the top set of papers at the time of publication. For experiments, we curate a set of academic citation graphs for a variety of conferences and show that the proposed model outperforms other classic machine learning models in terms of the F1-score.
E-commerce warehousing: learning a storage policy
Jan 21, 2021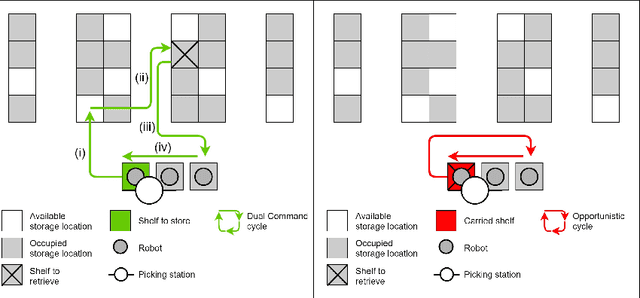
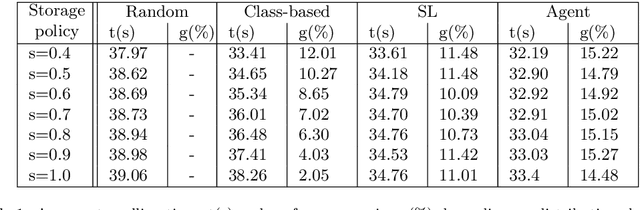
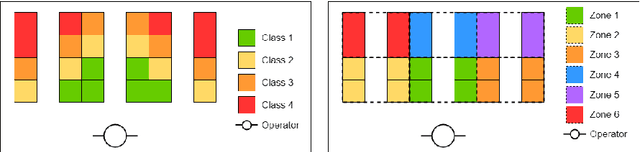
E-commerce with major online retailers is changing the way people consume. The goal of increasing delivery speed while remaining cost-effective poses significant new challenges for supply chains as they race to satisfy the growing and fast-changing demand. In this paper, we consider a warehouse with a Robotic Mobile Fulfillment System (RMFS), in which a fleet of robots stores and retrieves shelves of items and brings them to human pickers. To adapt to changing demand, uncertainty, and differentiated service (e.g., prime vs. regular), one can dynamically modify the storage allocation of a shelf. The objective is to define a dynamic storage policy to minimise the average cycle time used by the robots to fulfil requests. We propose formulating this system as a Partially Observable Markov Decision Process, and using a Deep Q-learning agent from Reinforcement Learning, to learn an efficient real-time storage policy that leverages repeated experiences and insightful forecasts using simulations. Additionally, we develop a rollout strategy to enhance our method by leveraging more information available at a given time step. Using simulations to compare our method to traditional storage rules used in the industry showed preliminary results up to 14\% better in terms of travelling times.
Phase Space Reconstruction Network for Lane Intrusion Action Recognition
Feb 22, 2021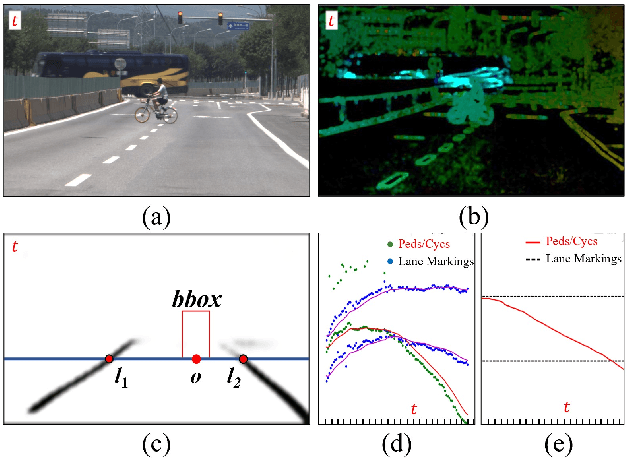
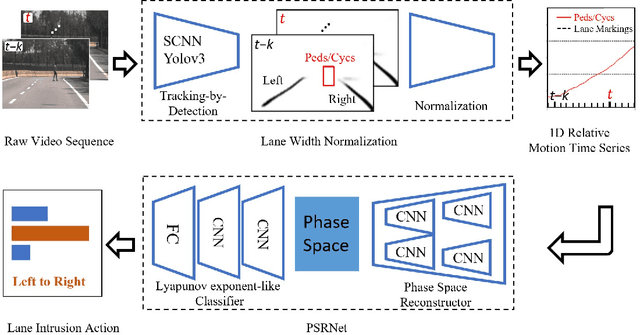
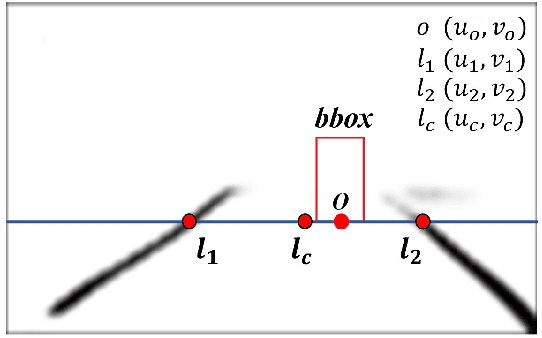
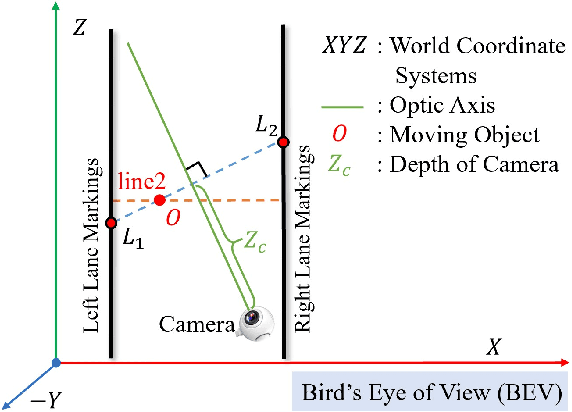
In a complex road traffic scene, illegal lane intrusion of pedestrians or cyclists constitutes one of the main safety challenges in autonomous driving application. In this paper, we propose a novel object-level phase space reconstruction network (PSRNet) for motion time series classification, aiming to recognize lane intrusion actions that occur 150m ahead through a monocular camera fixed on moving vehicle. In the PSRNet, the movement of pedestrians and cyclists, specifically viewed as an observable object-level dynamic process, can be reconstructed as trajectories of state vectors in a latent phase space and further characterized by a learnable Lyapunov exponent-like classifier that indicates discrimination in terms of average exponential divergence of state trajectories. Additionally, in order to first transform video inputs into one-dimensional motion time series of each object, a lane width normalization based on visual object tracking-by-detection is presented. Extensive experiments are conducted on the THU-IntrudBehavior dataset collected from real urban roads. The results show that our PSRNet could reach the best accuracy of 98.0%, which remarkably exceeds existing action recognition approaches by more than 30%.