 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
THP: Topological Hawkes Processes for Learning Granger Causality on Event Sequences
May 23, 2021
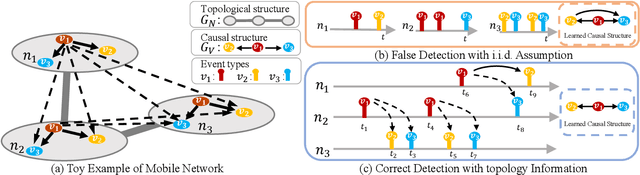
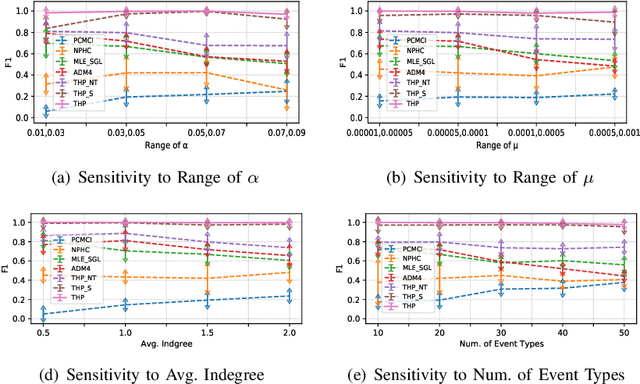
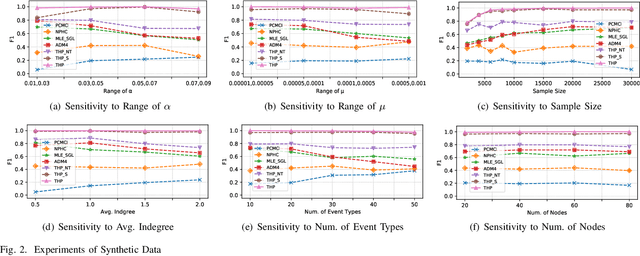
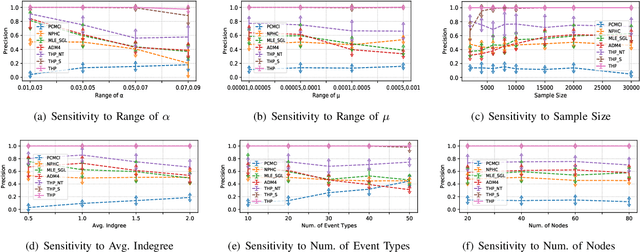
Learning Granger causality among event types on multi-type event sequences is an important but challenging task. Existing methods, such as the Multivariate Hawkes processes, mostly assumed that each sequence is independent and identically distributed. However, in many real-world applications, it is commonplace to encounter a topological network behind the event sequences such that an event is excited or inhibited not only by its history but also by its topological neighbors. Consequently, the failure in describing the topological dependency among the event sequences leads to the error detection of the causal structure. By considering the Hawkes processes from the view of temporal convolution, we propose a Topological Hawkes processes (THP) to draw a connection between the graph convolution in topology domain and the temporal convolution in time domains. We further propose a Granger causality learning method on THP in a likelihood framework. The proposed method is featured with the graph convolution-based likelihood function of THP and a sparse optimization scheme with an Expectation-Maximization of the likelihood function. Theoretical analysis and experiments on both synthetic and real-world data demonstrate the effectiveness of the proposed method.
Multiple Antenna Selection and Successive Signal Detection for SM-based IRS-aided Communication
Apr 28, 2021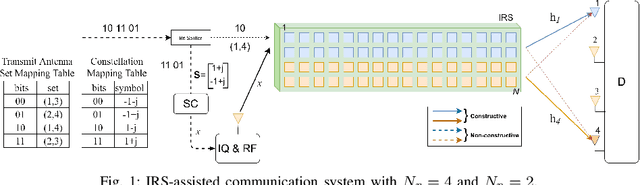
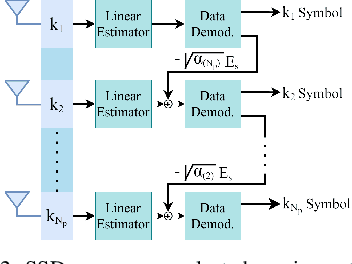
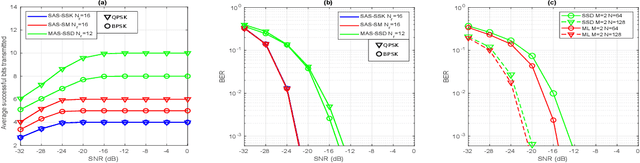

Intelligent reflecting surface (IRS) is being considered as a prospective candidate for next-generation wireless communication due to its ability to significantly improve coverage and spectral efficiency by controlling the propagation environment. One of the ways IRS increases spectral efficiency is by adjusting phase shifts to perform passive beamforming. In this letter, we integrate the concept of IRS-aided communication to the domain of multi-direction beamforming, whereby multiple receive antennas are selected to convey more information bits than existing spatial modulation (SM) techniques at any specific time. To complement this system, we also propose a successive signal detection (SSD) technique at the receiver. Numerical results show that the proposed design is able to improve the average successful bits transmitted (ASBT) by the system, which outperforms other state-of-the-art methods proposed in the literature.
Zero-Shot Controlled Generation with Encoder-Decoder Transformers
Jun 11, 2021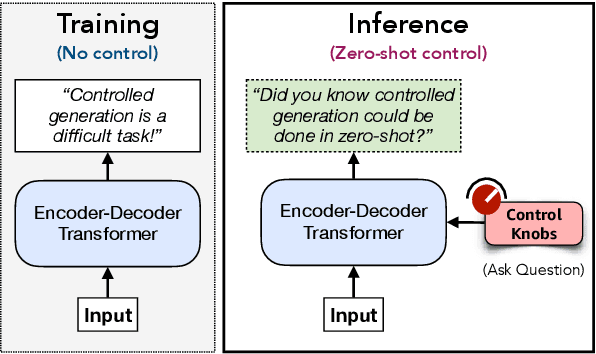

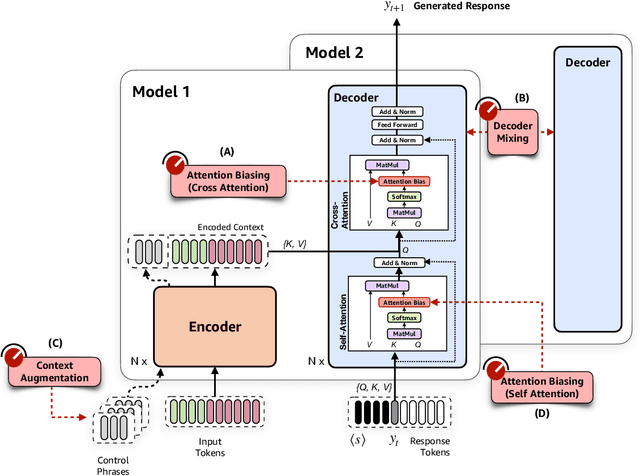

Controlling neural network-based models for natural language generation (NLG) has broad applications in numerous areas such as machine translation, document summarization, and dialog systems. Approaches that enable such control in a zero-shot manner would be of great importance as, among other reasons, they remove the need for additional annotated data and training. In this work, we propose novel approaches for controlling encoder-decoder transformer-based NLG models in a zero-shot manner. This is done by introducing three control knobs; namely, attention biasing, decoder mixing, and context augmentation, that are applied to these models at generation time. These knobs control the generation process by directly manipulating trained NLG models (e.g., biasing cross-attention layers) to realize the desired attributes in the generated outputs. We show that not only are these NLG models robust to such manipulations, but also their behavior could be controlled without an impact on their generation performance. These results, to the best of our knowledge, are the first of their kind. Through these control knobs, we also investigate the role of transformer decoder's self-attention module and show strong evidence that its primary role is maintaining fluency of sentences generated by these models. Based on this hypothesis, we show that alternative architectures for transformer decoders could be viable options. We also study how this hypothesis could lead to more efficient ways for training encoder-decoder transformer models.
The MineRL BASALT Competition on Learning from Human Feedback
Jul 05, 2021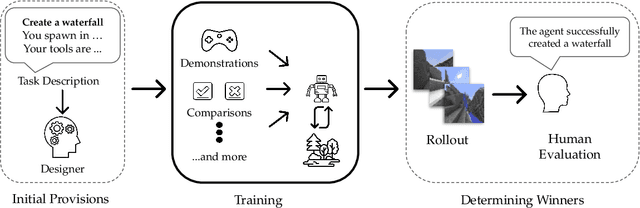

The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. Our hope is that this competition will improve our ability to build AI systems that do what their designers intend them to do, even when the intent cannot be easily formalized. Besides allowing AI to solve more tasks, this can also enable more effective regulation of AI systems, as well as making progress on the value alignment problem.
Learning from Łukasiewicz and Meredith: Investigations into Proof Structures (Extended Version)
Apr 28, 2021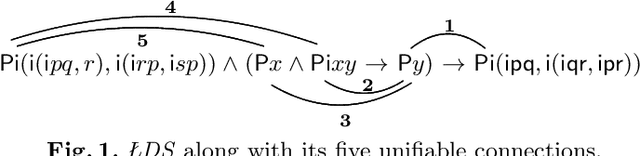
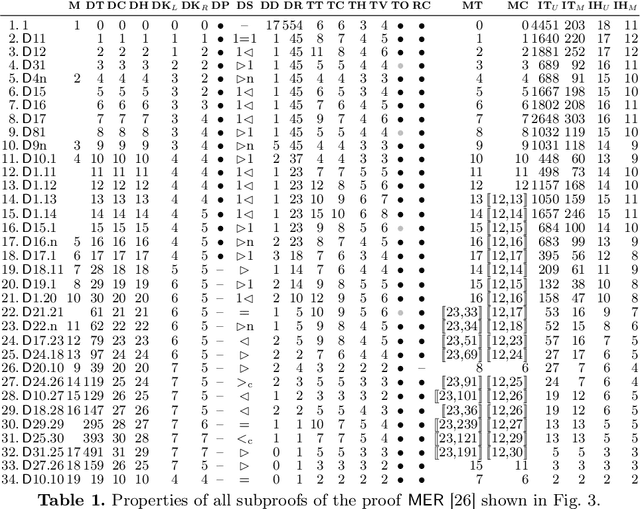
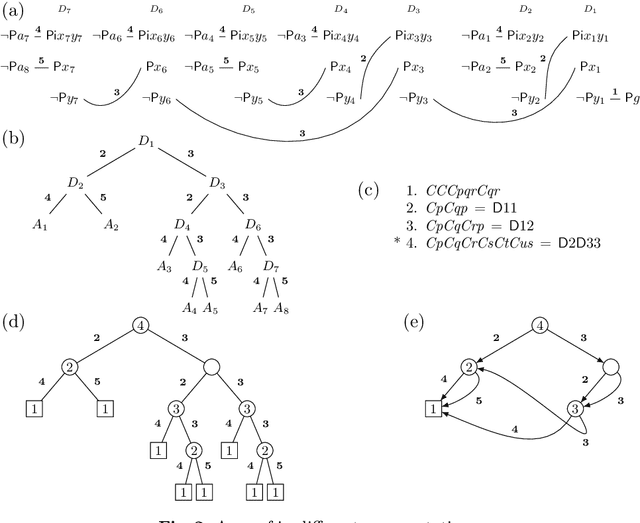

The material presented in this paper contributes to establishing a basis deemed essential for substantial progress in Automated Deduction. It identifies and studies global features in selected problems and their proofs which offer the potential of guiding proof search in a more direct way. The studied problems are of the wide-spread form of "axiom(s) and rule(s) imply goal(s)". The features include the well-known concept of lemmas. For their elaboration both human and automated proofs of selected theorems are taken into a close comparative consideration. The study at the same time accounts for a coherent and comprehensive formal reconstruction of historical work by {\L}ukasiewicz, Meredith and others. First experiments resulting from the study indicate novel ways of lemma generation to supplement automated first-order provers of various families, strengthening in particular their ability to find short proofs.
Moment-Based Exact Uncertainty Propagation Through Nonlinear Stochastic Autonomous Systems
Jan 29, 2021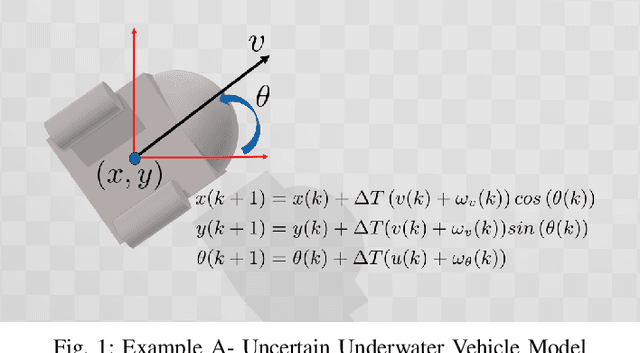
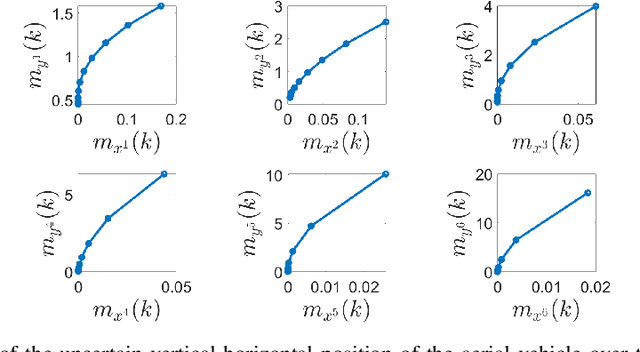

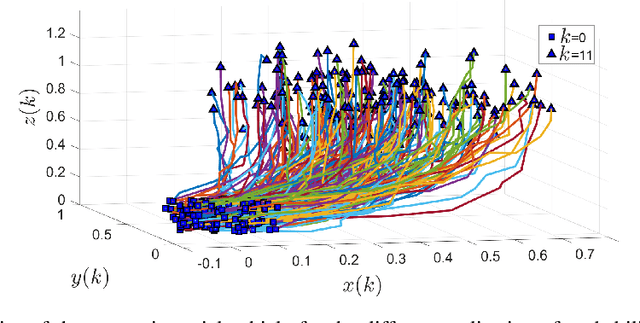
In this paper, we address the problem of uncertainty propagation through nonlinear stochastic dynamical systems. More precisely, given a discrete-time continuous-state probabilistic nonlinear dynamical system, we aim at finding the sequence of the moments of the probability distributions of the system states up to any desired order over the given planning horizon. Moments of uncertain states can be used in estimation, planning, control, and safety analysis of stochastic dynamical systems. Existing approaches to address moment propagation problems provide approximate descriptions of the moments and are mainly limited to particular set of uncertainties, e.g., Gaussian disturbances. In this paper, to describe the moments of uncertain states, we introduce trigonometric and also mixed-trigonometric-polynomial moments. Such moments allow us to obtain closed deterministic dynamical systems that describe the exact time evolution of the moments of uncertain states of an important class of autonomous and robotic systems including underwater, ground, and aerial vehicles, robotic arms and walking robots. Such obtained deterministic dynamical systems can be used, in a receding horizon fashion, to propagate the uncertainties over the planning horizon in real-time. To illustrate the performance of the proposed method, we benchmark our method against existing approaches including linear, unscented transformation, and sampling based uncertainty propagation methods that are widely used in estimation, prediction, planning, and control problems.
Lexical semantic change for Ancient Greek and Latin
Jan 22, 2021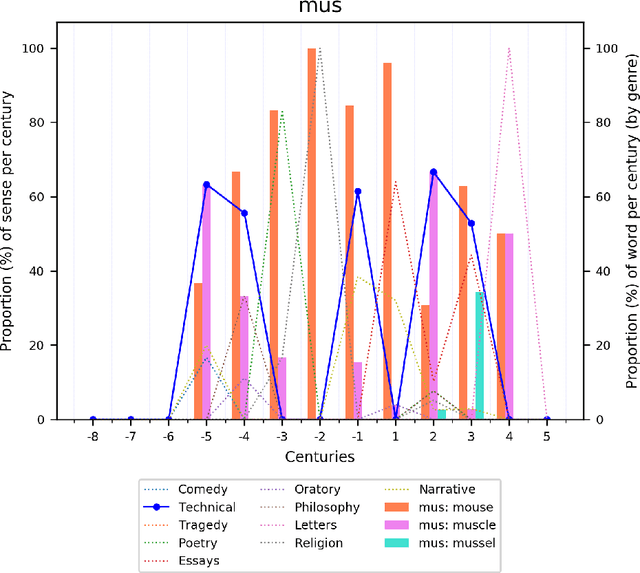
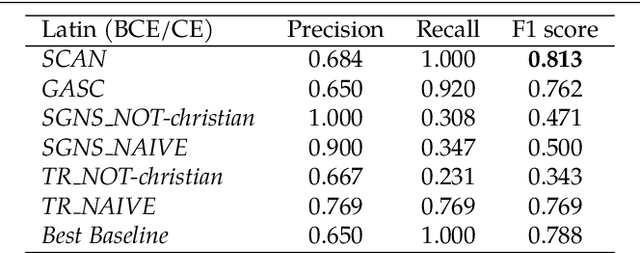
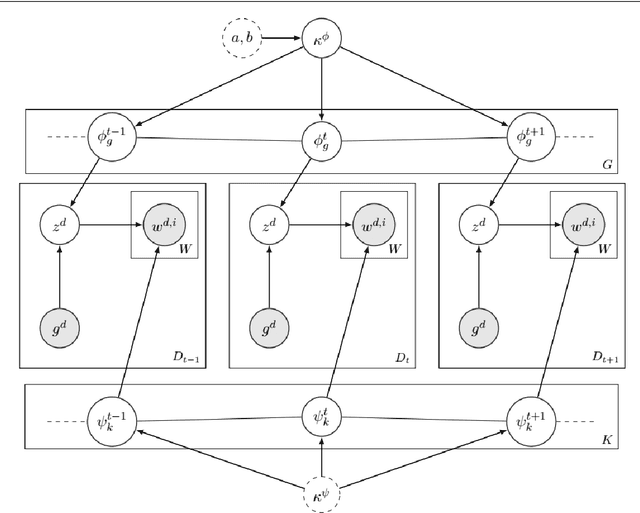
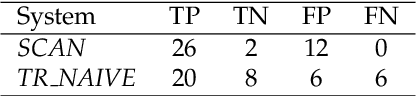
Change and its precondition, variation, are inherent in languages. Over time, new words enter the lexicon, others become obsolete, and existing words acquire new senses. Associating a word's correct meaning in its historical context is a central challenge in diachronic research. Historical corpora of classical languages, such as Ancient Greek and Latin, typically come with rich metadata, and existing models are limited by their inability to exploit contextual information beyond the document timestamp. While embedding-based methods feature among the current state of the art systems, they are lacking in the interpretative power. In contrast, Bayesian models provide explicit and interpretable representations of semantic change phenomena. In this chapter we build on GASC, a recent computational approach to semantic change based on a dynamic Bayesian mixture model. In this model, the evolution of word senses over time is based not only on distributional information of lexical nature, but also on text genres. We provide a systematic comparison of dynamic Bayesian mixture models for semantic change with state-of-the-art embedding-based models. On top of providing a full description of meaning change over time, we show that Bayesian mixture models are highly competitive approaches to detect binary semantic change in both Ancient Greek and Latin.
A Recurrent Neural Network Survival Model: Predicting Web User Return Time
Jul 11, 2018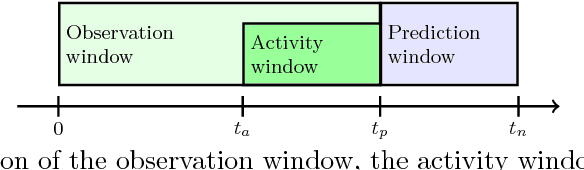
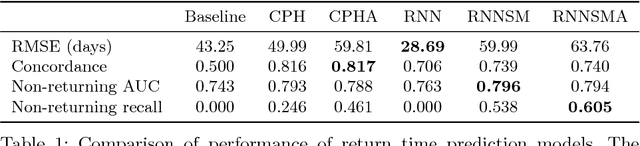
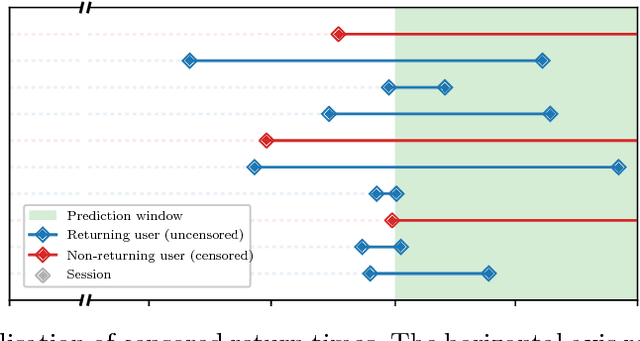
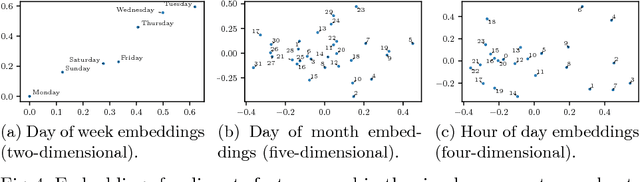
The size of a website's active user base directly affects its value. Thus, it is important to monitor and influence a user's likelihood to return to a site. Essential to this is predicting when a user will return. Current state of the art approaches to solve this problem come in two flavors: (1) Recurrent Neural Network (RNN) based solutions and (2) survival analysis methods. We observe that both techniques are severely limited when applied to this problem. Survival models can only incorporate aggregate representations of users instead of automatically learning a representation directly from a raw time series of user actions. RNNs can automatically learn features, but can not be directly trained with examples of non-returning users who have no target value for their return time. We develop a novel RNN survival model that removes the limitations of the state of the art methods. We demonstrate that this model can successfully be applied to return time prediction on a large e-commerce dataset with a superior ability to discriminate between returning and non-returning users than either method applied in isolation.
MoleHD: Automated Drug Discovery using Brain-Inspired Hyperdimensional Computing
Jun 05, 2021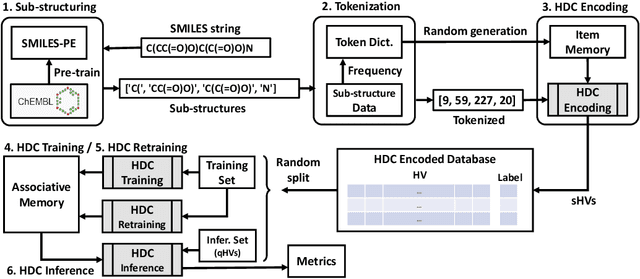
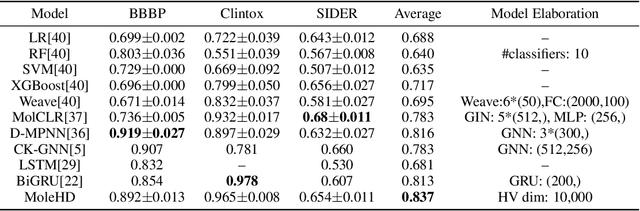
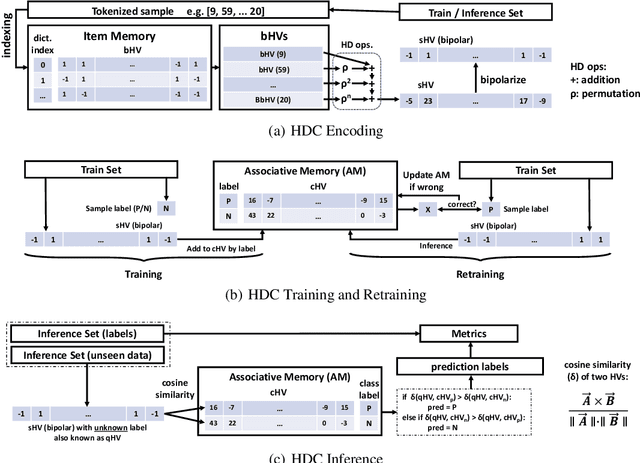
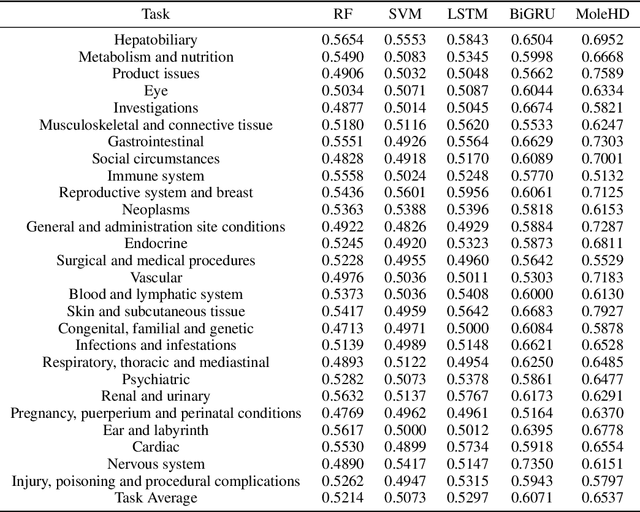
Modern drug discovery is often time-consuming, complex and cost-ineffective due to the large volume of molecular data and complicated molecular properties. Recently, machine learning algorithms have shown promising results in virtual screening of automated drug discovery by predicting molecular properties. While emerging learning methods such as graph neural networks and recurrent neural networks exhibit high accuracy, they are also notoriously computation-intensive and memory-intensive with operations such as feature embeddings or deep convolutions. In this paper, we propose a viable alternative to neural network classifiers. We present MoleHD, a method based on brain-inspired hyperdimensional computing (HDC) for molecular property prediction. We first transform the SMILES presentation of molecules into feature vectors by SMILE-PE tokenizers pretrained on the ChEMBL database. Then, we develop HDC encoders to project such features into high-dimensional vectors that are used for training and inference. We perform an extensive evaluation using 30 classification tasks from 3 widely-used molecule datasets and compare MoleHD with 10 baseline methods including 6 SOTA neural network classifiers. Results show that MoleHD is able to outperform all the baseline methods on average across 30 classification tasks with significantly reduced computing cost. To the best of our knowledge, we develop the first HDC-based method for drug discovery. The promising results presented in this paper can potentially lead to a novel path in drug discovery research.
TabAug: Data Driven Augmentation for Enhanced Table Structure Recognition
May 15, 2021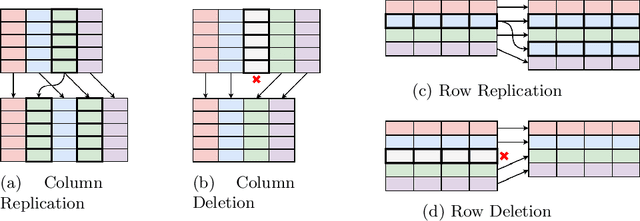
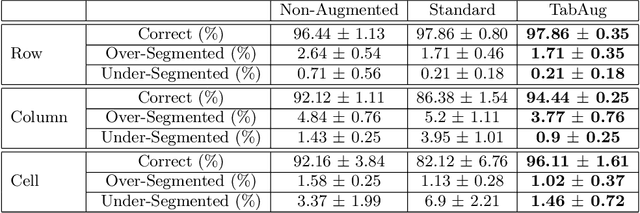
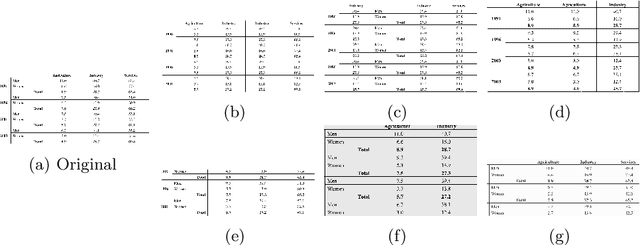
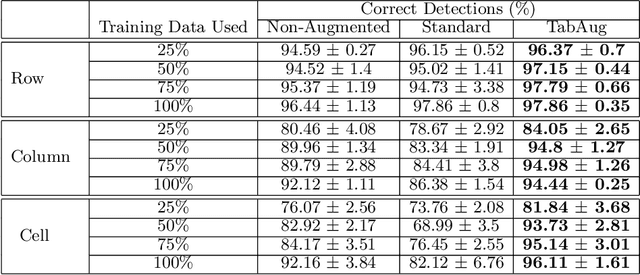
Table Structure Recognition is an essential part of end-to-end tabular data extraction in document images. The recent success of deep learning model architectures in computer vision remains to be non-reflective in table structure recognition, largely because extensive datasets for this domain are still unavailable while labeling new data is expensive and time-consuming. Traditionally, in computer vision, these challenges are addressed by standard augmentation techniques that are based on image transformations like color jittering and random cropping. As demonstrated by our experiments, these techniques are not effective for the task of table structure recognition. In this paper, we propose TabAug, a re-imagined Data Augmentation technique that produces structural changes in table images through replication and deletion of rows and columns. It also consists of a data-driven probabilistic model that allows control over the augmentation process. To demonstrate the efficacy of our approach, we perform experimentation on ICDAR 2013 dataset where our approach shows consistent improvements in all aspects of the evaluation metrics, with cell-level correct detections improving from 92.16% to 96.11% over the baseline.