 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comprehensive Assessment of Dialog Evaluation Metrics
Jun 07, 2021
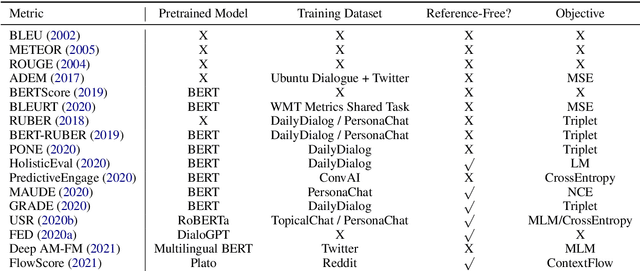
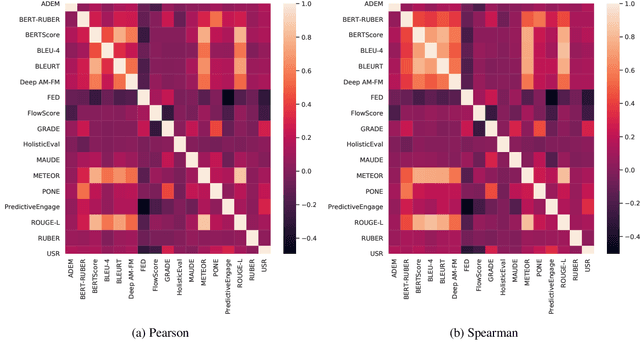

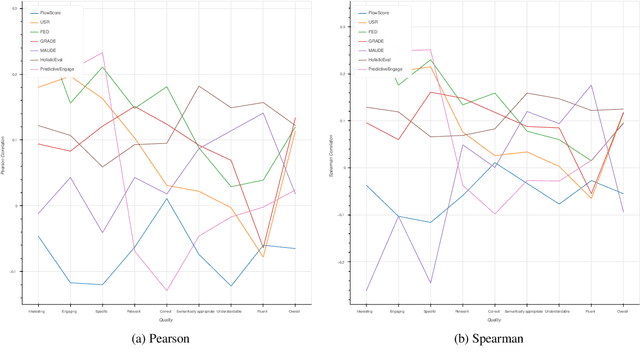
Automatic evaluation metrics are a crucial component of dialog systems research. Standard language evaluation metrics are known to be ineffective for evaluating dialog. As such, recent research has proposed a number of novel, dialog-specific metrics that correlate better with human judgements. Due to the fast pace of research, many of these metrics have been assessed on different datasets and there has as yet been no time for a systematic comparison between them. To this end, this paper provides a comprehensive assessment of recently proposed dialog evaluation metrics on a number of datasets. In this paper, 17 different automatic evaluation metrics are evaluated on 10 different datasets. Furthermore, the metrics are assessed in different settings, to better qualify their respective strengths and weaknesses. Metrics are assessed (1) on both the turn level and the dialog level, (2) for different dialog lengths, (3) for different dialog qualities (e.g., coherence, engaging), (4) for different types of response generation models (i.e., generative, retrieval, simple models and state-of-the-art models), (5) taking into account the similarity of different metrics and (6) exploring combinations of different metrics. This comprehensive assessment offers several takeaways pertaining to dialog evaluation metrics in general. It also suggests how to best assess evaluation metrics and indicates promising directions for future work.
1D CNN Architectures for Music Genre Classification
May 15, 2021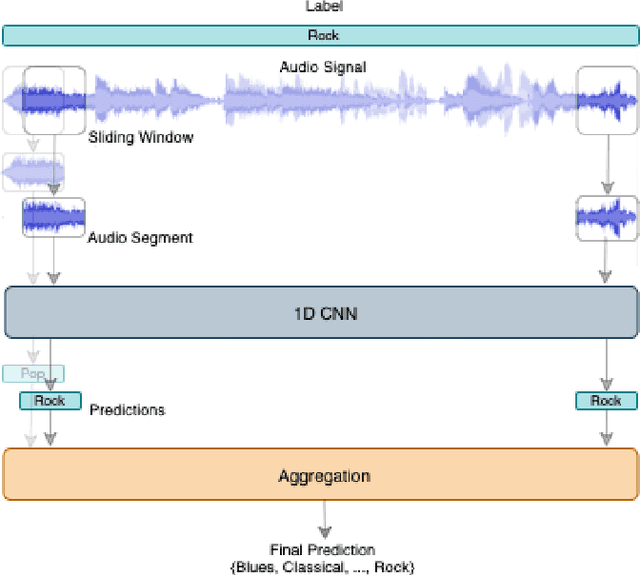
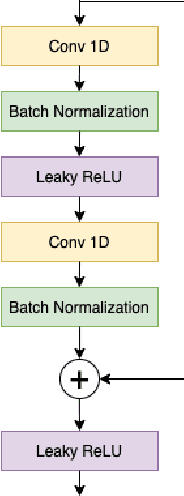
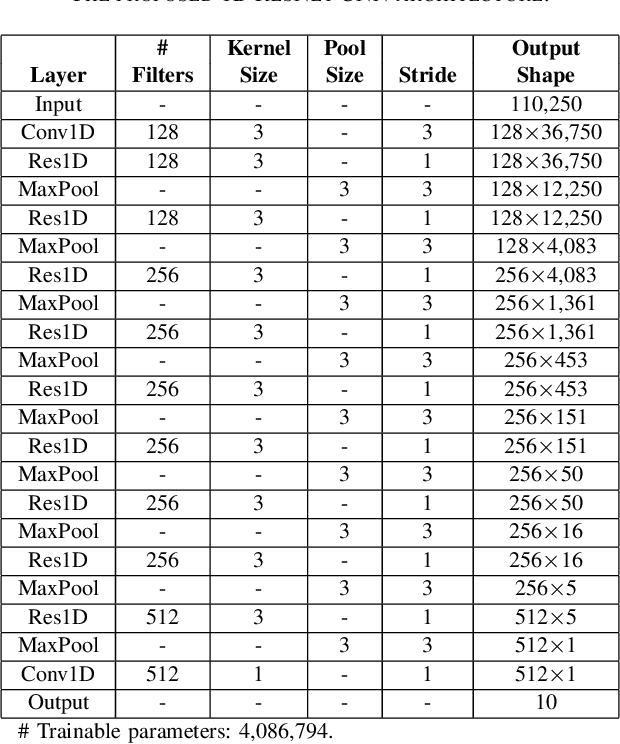
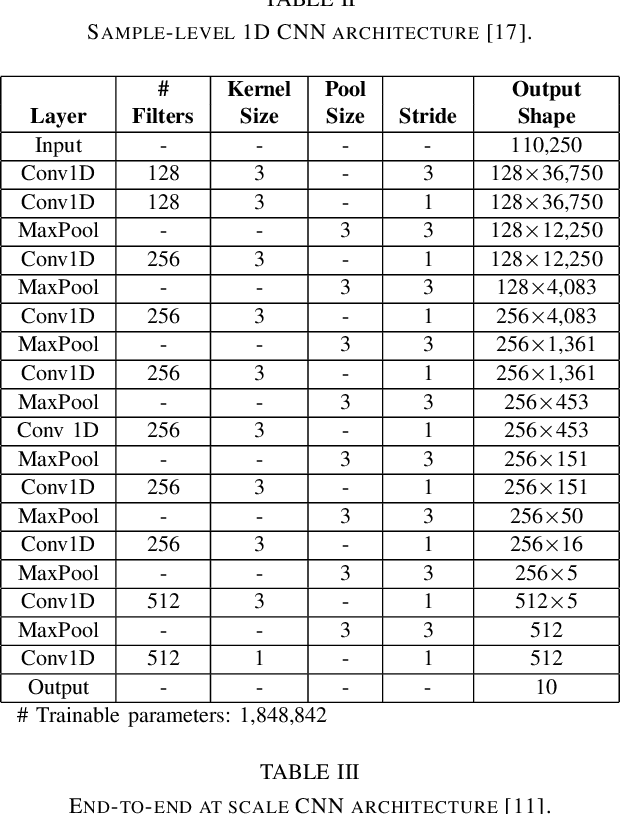
This paper proposes a 1D residual convolutional neural network (CNN) architecture for music genre classification and compares it with other recent 1D CNN architectures. The 1D CNNs learn a representation and a discriminant directly from the raw audio signal. Several convolutional layers capture the time-frequency characteristics of the audio signal and learn various filters relevant to the music genre recognition task. The proposed approach splits the audio signal into overlapped segments using a sliding window to comply with the fixed-length input constraint of the 1D CNNs. As a result, music genre classification can be carried out on a single audio segment or on the aggregation of the predictions on several audio segments, which improves the final accuracy. The performance of the proposed 1D residual CNN is assessed on a public dataset of 1,000 audio clips. The experimental results have shown that it achieves 80.93% of mean accuracy in classifying music genres and outperforms other 1D CNN architectures.
The Early Bird Catches the Worm: Better Early Life Cycle Defect Predictors
May 24, 2021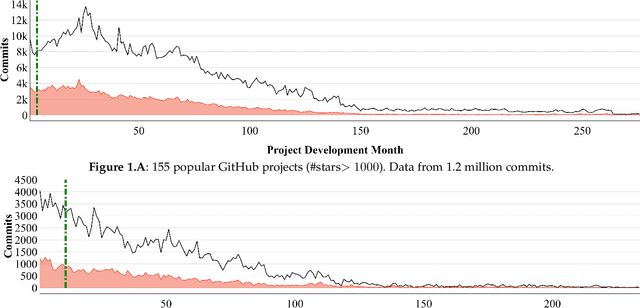
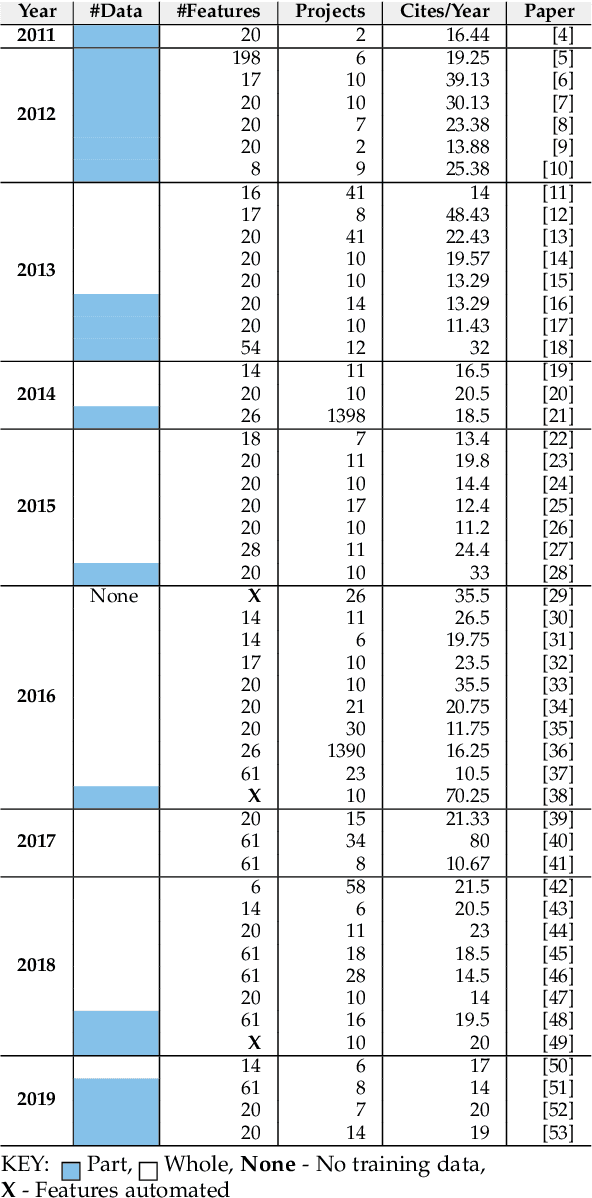
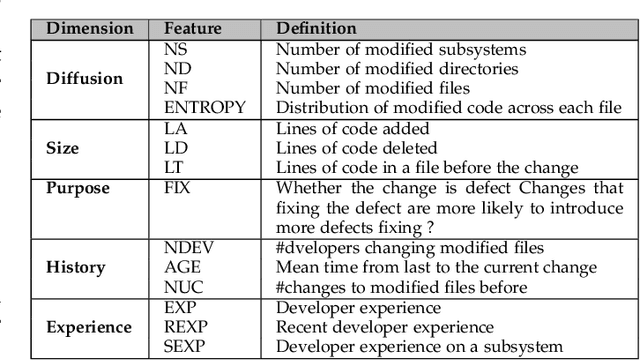
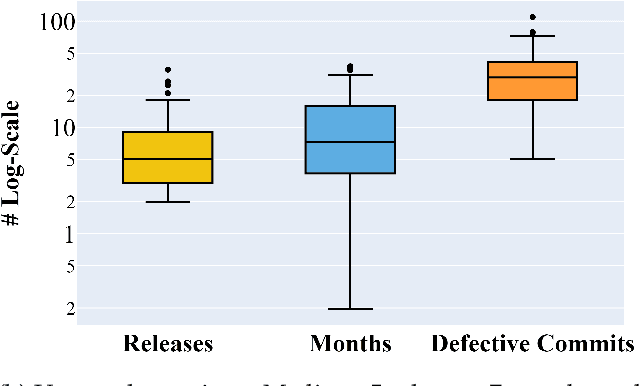
Before researchers rush to reason across all available data, they should first check if the information is densest within some small region. We say this since, in 240 GitHub projects, we find that the information in that data ``clumps'' towards the earliest parts of the project. In fact, a defect prediction model learned from just the first 150 commits works as well, or better than state-of-the-art alternatives. Using just this early life cycle data, we can build models very quickly (using weeks, not months, of CPU time). Also, we can find simple models (with just two features) that generalize to hundreds of software projects. Based on this experience, we warn that prior work on generalizing software engineering defect prediction models may have needlessly complicated an inherently simple process. Further, prior work that focused on later-life cycle data now needs to be revisited since their conclusions were drawn from relatively uninformative regions. Replication note: all our data and scripts are online at https://github.com/snaraya7/early-defect-prediction-tse.
Inferring Objectives in Continuous Dynamic Games from Noise-Corrupted Partial State Observations
Jun 07, 2021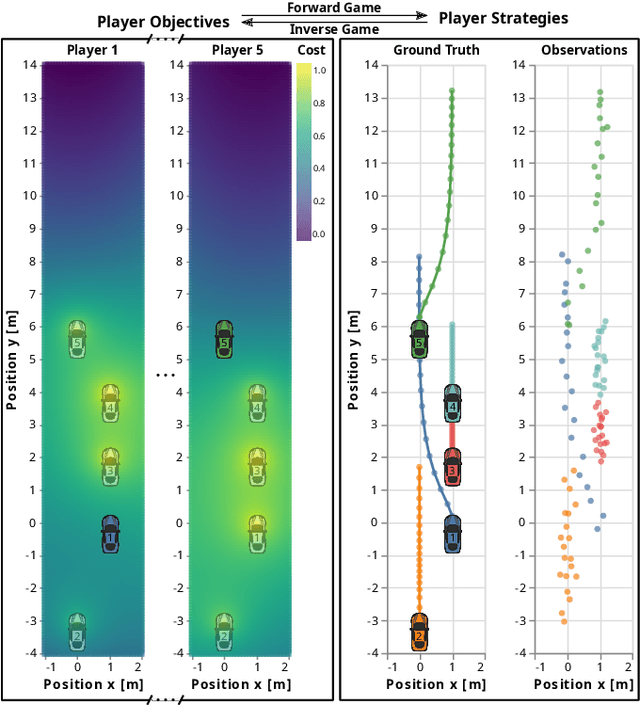
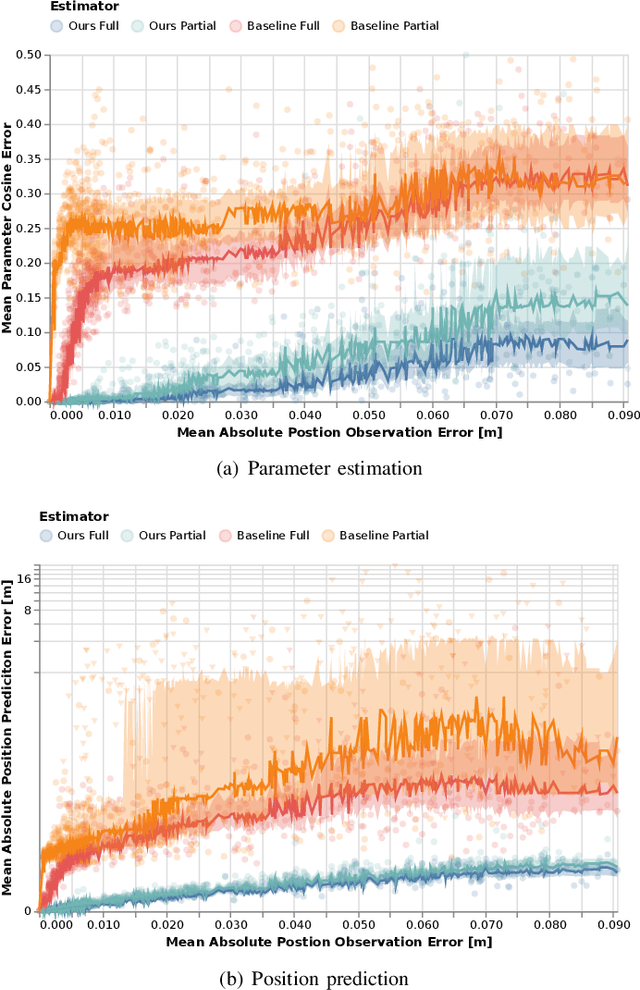
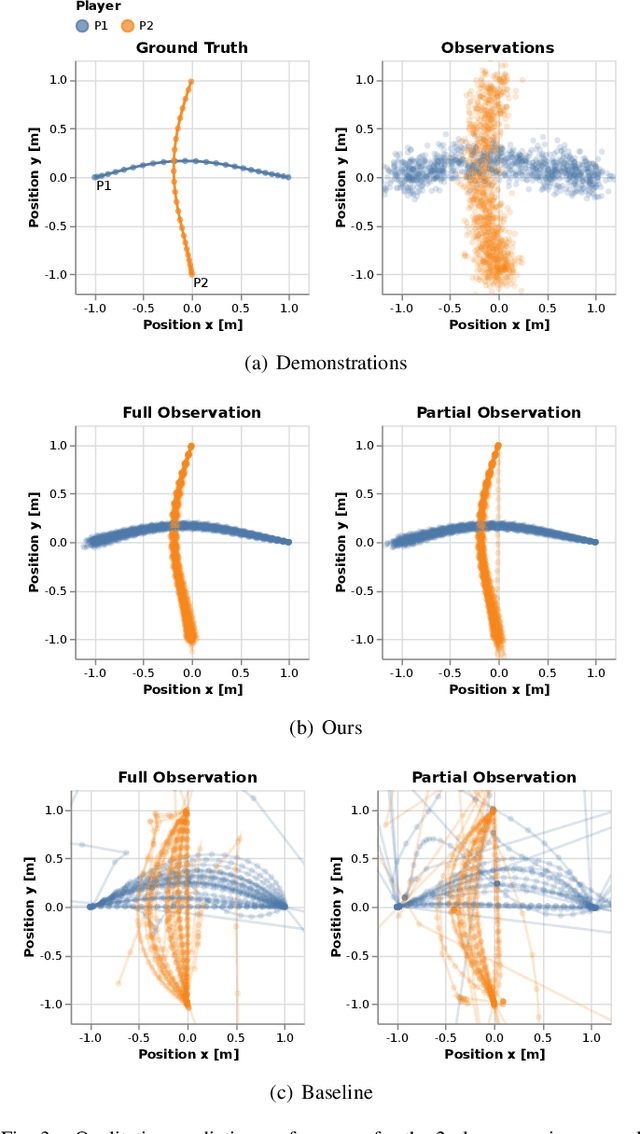
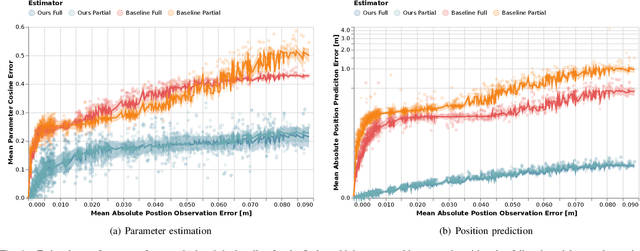
Robots and autonomous systems must interact with one another and their environment to provide high-quality services to their users. Dynamic game theory provides an expressive theoretical framework for modeling scenarios involving multiple agents with differing objectives interacting over time. A core challenge when formulating a dynamic game is designing objectives for each agent that capture desired behavior. In this paper, we propose a method for inferring parametric objective models of multiple agents based on observed interactions. Our inverse game solver jointly optimizes player objectives and continuous-state estimates by coupling them through Nash equilibrium constraints. Hence, our method is able to directly maximize the observation likelihood rather than other non-probabilistic surrogate criteria. Our method does not require full observations of game states or player strategies to identify player objectives. Instead, it robustly recovers this information from noisy, partial state observations. As a byproduct of estimating player objectives, our method computes a Nash equilibrium trajectory corresponding to those objectives. Thus, it is suitable for downstream trajectory forecasting tasks. We demonstrate our method in several simulated traffic scenarios. Results show that it reliably estimates player objectives from single short sequences of noisy, partially observed interactions. Furthermore, using the estimated objectives, our method makes accurate predictions of each player's trajectory.
Non-isomorphic Inter-modality Graph Alignment and Synthesis for Holistic Brain Mapping
Jun 30, 2021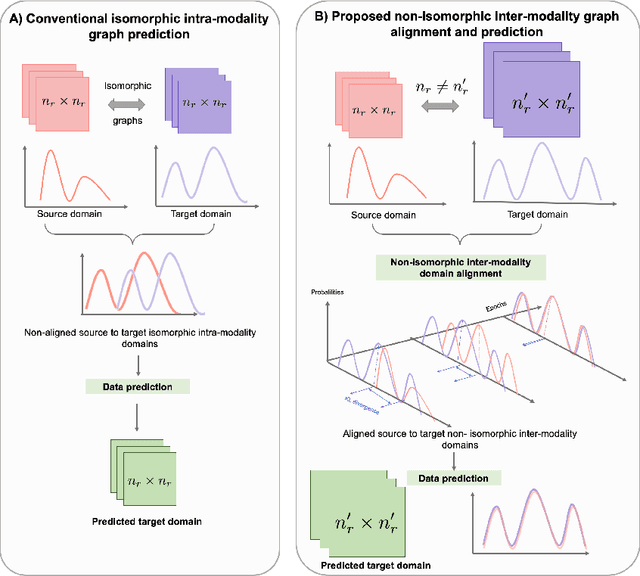
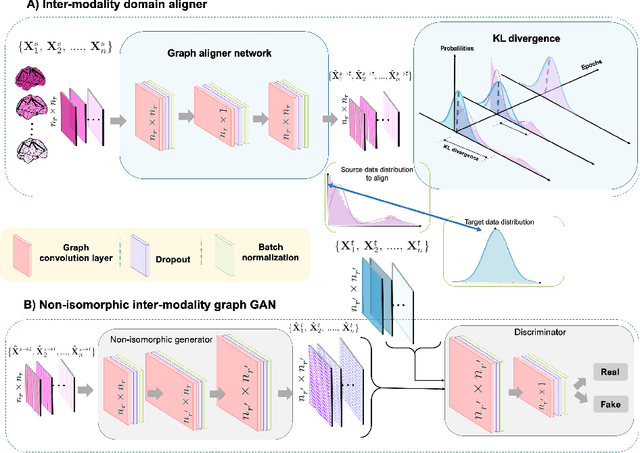
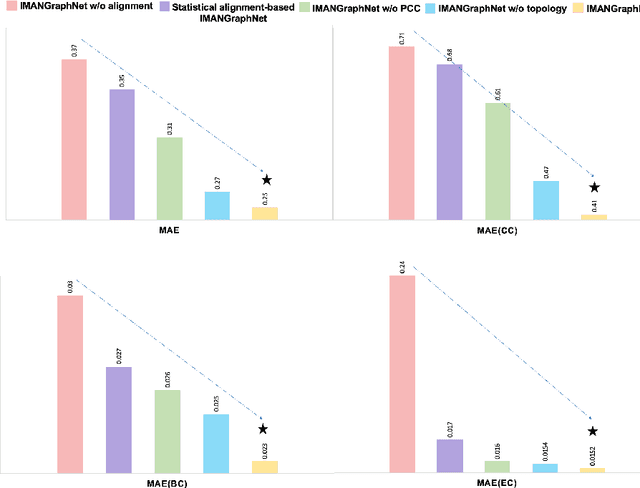
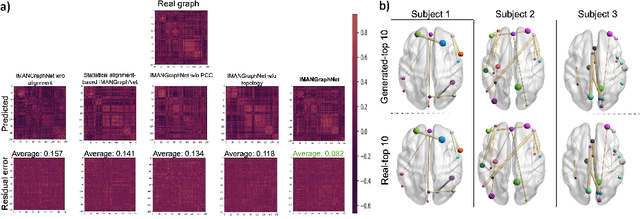
Brain graph synthesis marked a new era for predicting a target brain graph from a source one without incurring the high acquisition cost and processing time of neuroimaging data. However, existing multi-modal graph synthesis frameworks have several limitations. First, they mainly focus on generating graphs from the same domain (intra-modality), overlooking the rich multimodal representations of brain connectivity (inter-modality). Second, they can only handle isomorphic graph generation tasks, limiting their generalizability to synthesizing target graphs with a different node size and topological structure from those of the source one. More importantly, both target and source domains might have different distributions, which causes a domain fracture between them (i.e., distribution misalignment). To address such challenges, we propose an inter-modality aligner of non-isomorphic graphs (IMANGraphNet) framework to infer a target graph modality based on a given modality. Our three core contributions lie in (i) predicting a target graph (e.g., functional) from a source graph (e.g., morphological) based on a novel graph generative adversarial network (gGAN); (ii) using non-isomorphic graphs for both source and target domains with a different number of nodes, edges and structure; and (iii) enforcing the predicted target distribution to match that of the ground truth graphs using a graph autoencoder to relax the designed loss oprimization. To handle the unstable behavior of gGAN, we design a new Ground Truth-Preserving (GT-P) loss function to guide the generator in learning the topological structure of ground truth brain graphs. Our comprehensive experiments on predicting functional from morphological graphs demonstrate the outperformance of IMANGraphNet in comparison with its variants. This can be further leveraged for integrative and holistic brain mapping in health and disease.
Clustering Time Series with Nonlinear Dynamics: A Bayesian Non-Parametric and Particle-Based Approach
Oct 24, 2018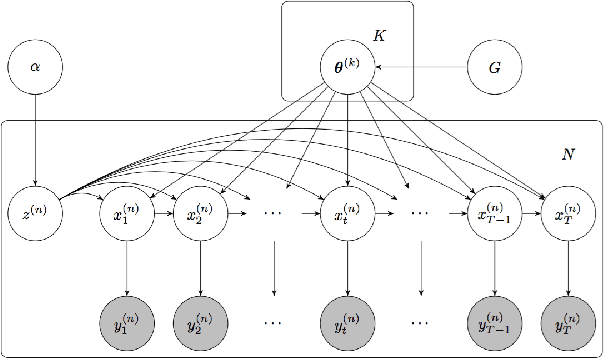



We propose a statistical framework for clustering multiple time series that exhibit nonlinear dynamics into an a-priori-unknown number of sub-groups that each comprise time series with similar dynamics. Our motivation comes from neuroscience where an important problem is to identify, within a large assembly of neurons, sub-groups that respond similarly to a stimulus or contingency. In the neural setting, conditioned on cluster membership and the parameters governing the dynamics, time series within a cluster are assumed independent and generated according to a nonlinear binomial state-space model. We derive a Metropolis-within-Gibbs algorithm for full Bayesian inference that alternates between sampling of cluster membership and sampling of parameters of interest. The Metropolis step is a PMMH iteration that requires an unbiased, low variance estimate of the likelihood function of a nonlinear state-space model. We leverage recent results on controlled sequential Monte Carlo to estimate likelihood functions more efficiently compared to the bootstrap particle filter. We apply the framework to time series acquired from the prefrontal cortex of mice in an experiment designed to characterize the neural underpinnings of fear.
NeuPDE: Neural Network Based Ordinary and Partial Differential Equations for Modeling Time-Dependent Data
Aug 08, 2019

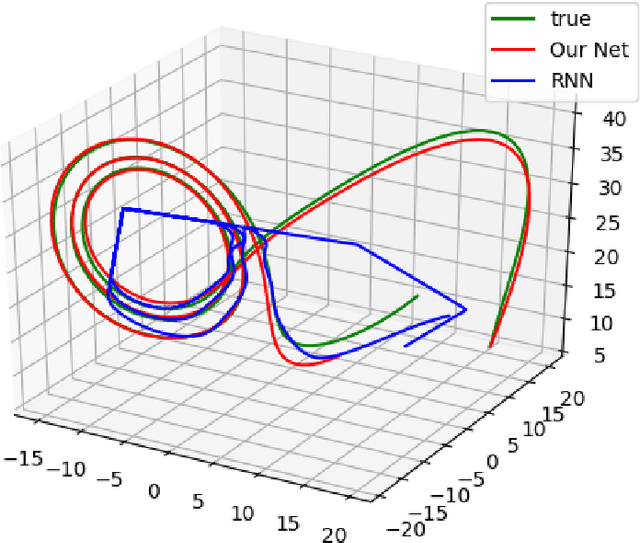
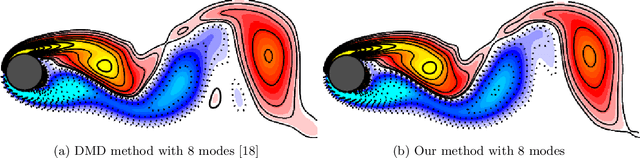
We propose a neural network based approach for extracting models from dynamic data using ordinary and partial differential equations. In particular, given a time-series or spatio-temporal dataset, we seek to identify an accurate governing system which respects the intrinsic differential structure. The unknown governing model is parameterized by using both (shallow) multilayer perceptrons and nonlinear differential terms, in order to incorporate relevant correlations between spatio-temporal samples. We demonstrate the approach on several examples where the data is sampled from various dynamical systems and give a comparison to recurrent networks and other data-discovery methods. In addition, we show that for MNIST and Fashion MNIST, our approach lowers the parameter cost as compared to other deep neural networks.
On User Interfaces for Large-Scale Document-Level Human Evaluation of Machine Translation Outputs
Apr 21, 2021
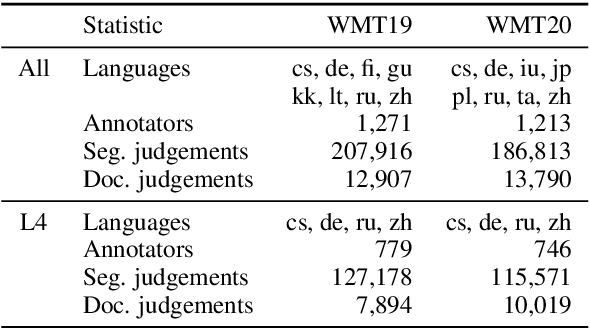
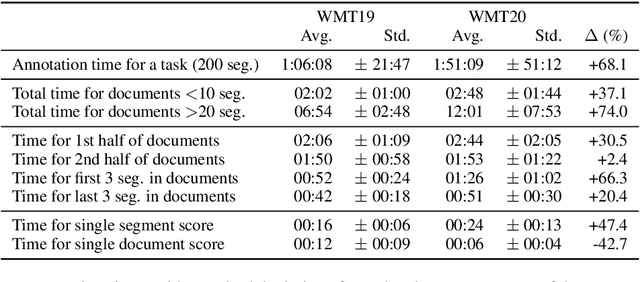

Recent studies emphasize the need of document context in human evaluation of machine translations, but little research has been done on the impact of user interfaces on annotator productivity and the reliability of assessments. In this work, we compare human assessment data from the last two WMT evaluation campaigns collected via two different methods for document-level evaluation. Our analysis shows that a document-centric approach to evaluation where the annotator is presented with the entire document context on a screen leads to higher quality segment and document level assessments. It improves the correlation between segment and document scores and increases inter-annotator agreement for document scores but is considerably more time consuming for annotators.
Self-supervised Depth Estimation Leveraging Global Perception and Geometric Smoothness Using On-board Videos
Jun 07, 2021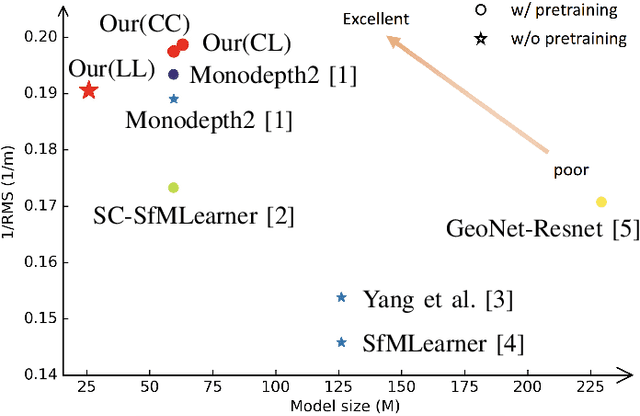
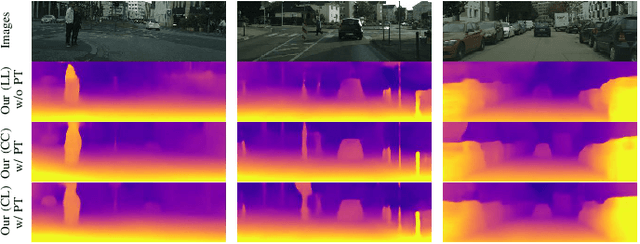
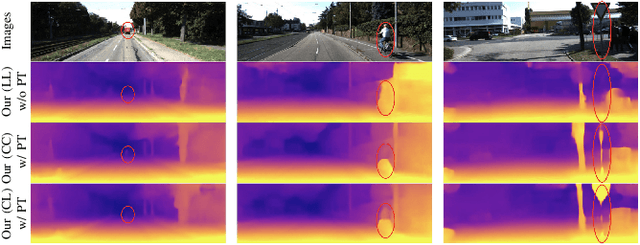
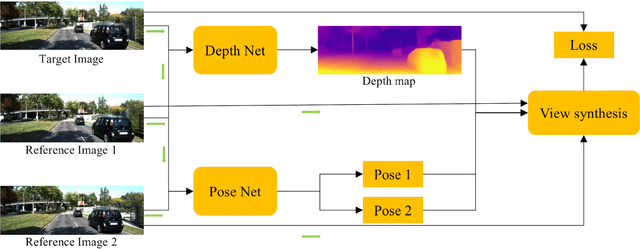
Self-supervised depth estimation has drawn much attention in recent years as it does not require labeled data but image sequences. Moreover, it can be conveniently used in various applications, such as autonomous driving, robotics, realistic navigation, and smart cities. However, extracting global contextual information from images and predicting a geometrically natural depth map remain challenging. In this paper, we present DLNet for pixel-wise depth estimation, which simultaneously extracts global and local features with the aid of our depth Linformer block. This block consists of the Linformer and innovative soft split multi-layer perceptron blocks. Moreover, a three-dimensional geometry smoothness loss is proposed to predict a geometrically natural depth map by imposing the second-order smoothness constraint on the predicted three-dimensional point clouds, thereby realizing improved performance as a byproduct. Finally, we explore the multi-scale prediction strategy and propose the maximum margin dual-scale prediction strategy for further performance improvement. In experiments on the KITTI and Make3D benchmarks, the proposed DLNet achieves performance competitive to those of the state-of-the-art methods, reducing time and space complexities by more than $62\%$ and $56\%$, respectively. Extensive testing on various real-world situations further demonstrates the strong practicality and generalization capability of the proposed model.
Robust and Interpretable Temporal Convolution Network for Event Detection in Lung Sound Recordings
Jun 30, 2021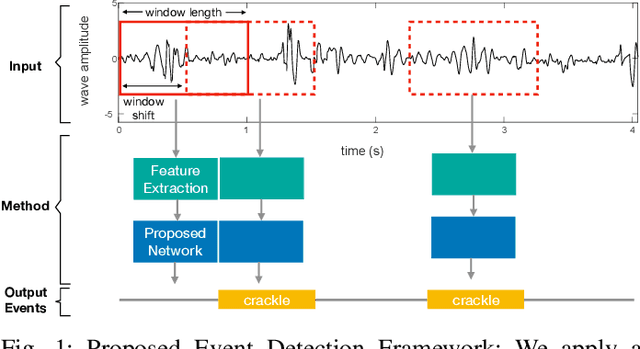
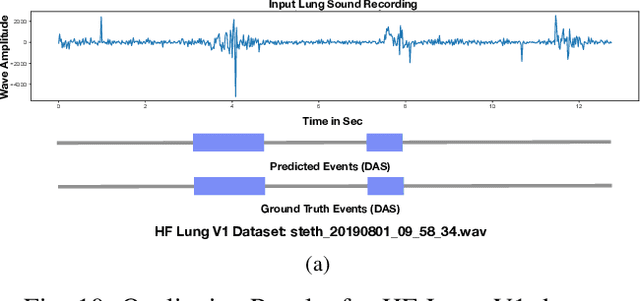
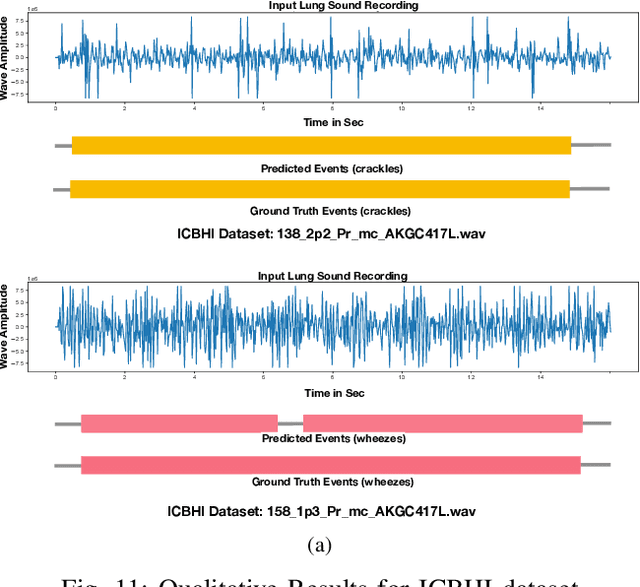
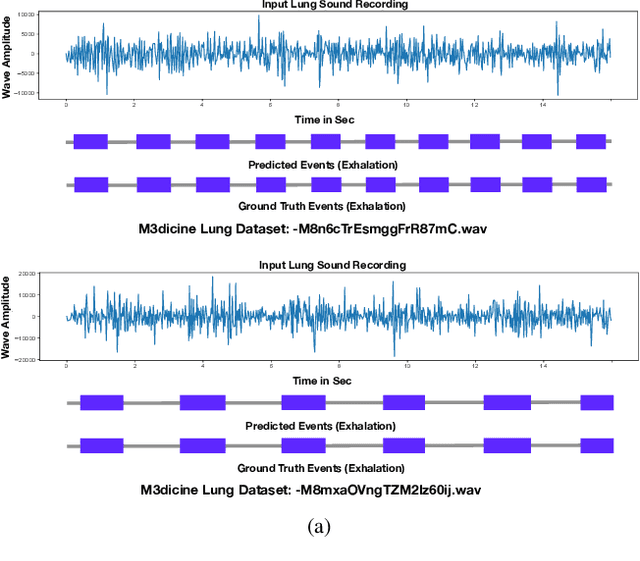
This paper proposes a novel framework for lung sound event detection, segmenting continuous lung sound recordings into discrete events and performing recognition on each event. Exploiting the lightweight nature of Temporal Convolution Networks (TCNs) and their superior results compared to their recurrent counterparts, we propose a lightweight, yet robust, and completely interpretable framework for lung sound event detection. We propose the use of a multi-branch TCN architecture and exploit a novel fusion strategy to combine the resultant features from these branches. This not only allows the network to retain the most salient information across different temporal granularities and disregards irrelevant information, but also allows our network to process recordings of arbitrary length. Results: The proposed method is evaluated on multiple public and in-house benchmarks of irregular and noisy recordings of the respiratory auscultation process for the identification of numerous auscultation events including inhalation, exhalation, crackles, wheeze, stridor, and rhonchi. We exceed the state-of-the-art results in all evaluations. Furthermore, we empirically analyse the effect of the proposed multi-branch TCN architecture and the feature fusion strategy and provide quantitative and qualitative evaluations to illustrate their efficiency. Moreover, we provide an end-to-end model interpretation pipeline that interprets the operations of all the components of the proposed framework. Our analysis of different feature fusion strategies shows that the proposed feature concatenation method leads to better suppression of non-informative features, which drastically reduces the classifier overhead resulting in a robust lightweight network.The lightweight nature of our model allows it to be deployed in end-user devices such as smartphones, and it has the ability to generate predictions in real-time.