 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NeuPDE: Neural Network Based Ordinary and Partial Differential Equations for Modeling Time-Dependent Data
Aug 08, 2019


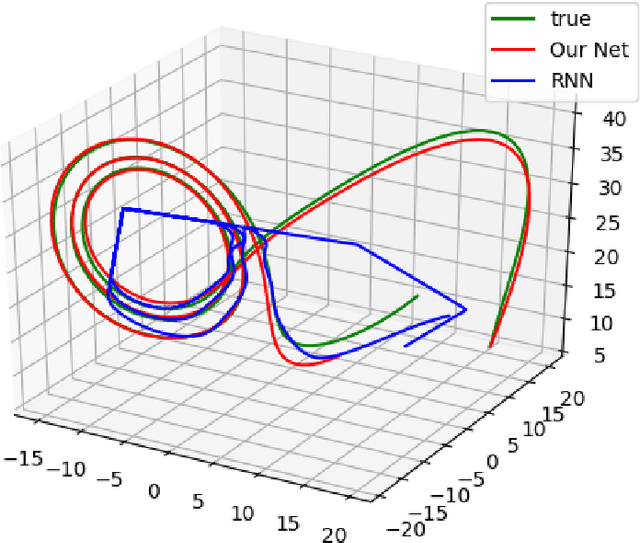
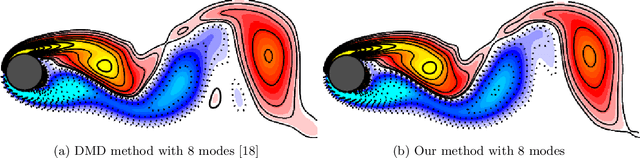
We propose a neural network based approach for extracting models from dynamic data using ordinary and partial differential equations. In particular, given a time-series or spatio-temporal dataset, we seek to identify an accurate governing system which respects the intrinsic differential structure. The unknown governing model is parameterized by using both (shallow) multilayer perceptrons and nonlinear differential terms, in order to incorporate relevant correlations between spatio-temporal samples. We demonstrate the approach on several examples where the data is sampled from various dynamical systems and give a comparison to recurrent networks and other data-discovery methods. In addition, we show that for MNIST and Fashion MNIST, our approach lowers the parameter cost as compared to other deep neural networks.
Randomized Exploration is Near-Optimal for Tabular MDP
Feb 19, 2021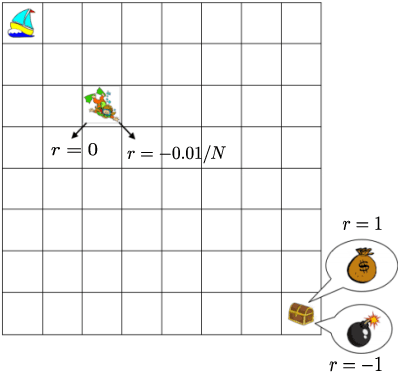
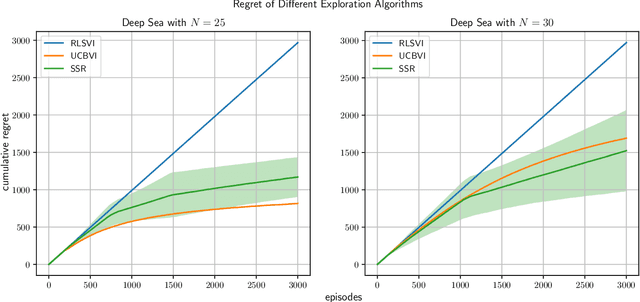
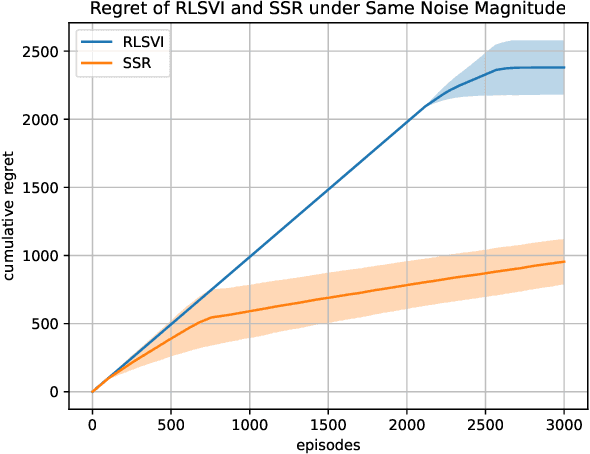
We study exploration using randomized value functions in Thompson Sampling (TS)-like algorithms in reinforcement learning. This type of algorithms enjoys appealing empirical performance. We show that when we use 1) a single random seed in each episode, and 2) a Bernstein-type magnitude of noise, we obtain a worst-case $\widetilde{O}\left(H\sqrt{SAT}\right)$ regret bound for episodic time-inhomogeneous Markov Decision Process where $S$ is the size of state space, $A$ is the size of action space, $H$ is the planning horizon and $T$ is the number of interactions. This bound polynomially improves all existing bounds for TS-like algorithms based on randomized value functions, and for the first time, matches the $\Omega\left(H\sqrt{SAT}\right)$ lower bound up to logarithmic factors. Our result highlights that randomized exploration can be near-optimal, which was previously only achieved by optimistic algorithms.
The temporal overfitting problem with applications in wind power curve modeling
Dec 02, 2020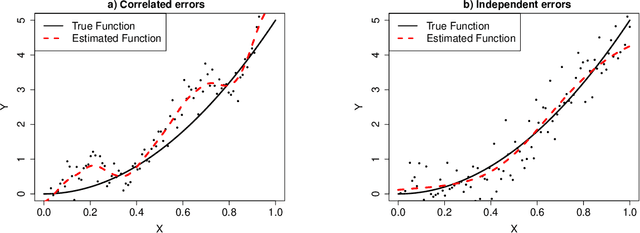
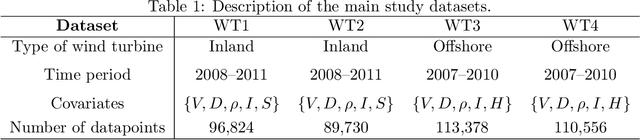
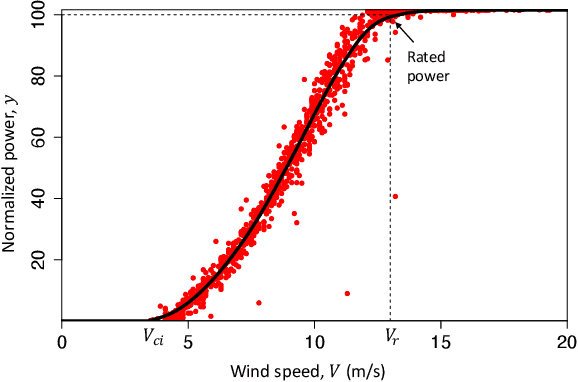
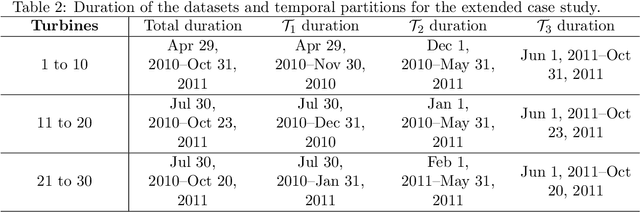
This paper is concerned with a nonparametric regression problem in which the independence assumption of the input variables and the residuals is no longer valid. Using existing model selection methods, like cross validation, the presence of temporal autocorrelation in the input variables and the error terms leads to model overfitting. This phenomenon is referred to as temporal overfitting, which causes loss of performance while predicting responses for a time domain different from the training time domain. We propose a new method to tackle the temporal overfitting problem. Our nonparametric model is partitioned into two parts -- a time-invariant component and a time-varying component, each of which is modeled through a Gaussian process regression. The key in our inference is a thinning-based strategy, an idea borrowed from Markov chain Monte Carlo sampling, to estimate the two components, respectively. Our specific application in this paper targets the power curve modeling in wind energy. In our numerical studies, we compare extensively our proposed method with both existing power curve models and available ideas for handling temporal overfitting. Our approach yields significant improvement in prediction both in and outside the time domain covered by the training data.
BiAdam: Fast Adaptive Bilevel Optimization Methods
Jun 30, 2021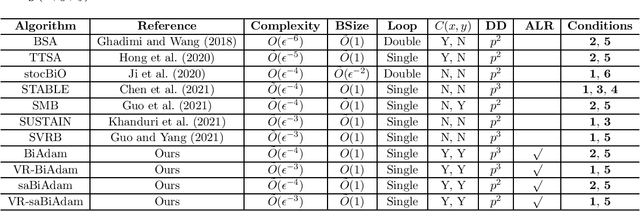
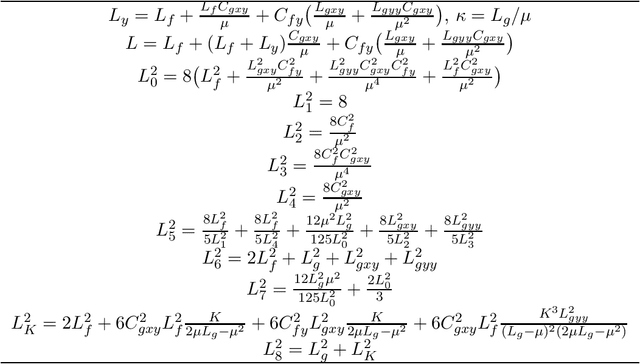
Bilevel optimization recently has attracted increased interest in machine learning due to its many applications such as hyper-parameter optimization and policy optimization. Although some methods recently have been proposed to solve the bilevel problems, these methods do not consider using adaptive learning rates. To fill this gap, in the paper, we propose a class of fast and effective adaptive methods for solving bilevel optimization problems that the outer problem is possibly nonconvex and the inner problem is strongly-convex. Specifically, we propose a fast single-loop BiAdam algorithm based on the basic momentum technique, which achieves a sample complexity of $\tilde{O}(\epsilon^{-4})$ for finding an $\epsilon$-stationary point. At the same time, we propose an accelerated version of BiAdam algorithm (VR-BiAdam) by using variance reduced technique, which reaches the best known sample complexity of $\tilde{O}(\epsilon^{-3})$. To further reduce computation in estimating derivatives, we propose a fast single-loop stochastic approximated BiAdam algorithm (saBiAdam) by avoiding the Hessian inverse, which still achieves a sample complexity of $\tilde{O}(\epsilon^{-4})$ without large batches. We further present an accelerated version of saBiAdam algorithm (VR-saBiAdam), which also reaches the best known sample complexity of $\tilde{O}(\epsilon^{-3})$. We apply the unified adaptive matrices to our methods as the SUPER-ADAM \citep{huang2021super}, which including many types of adaptive learning rates. Moreover, our framework can flexibly use the momentum and variance reduced techniques. In particular, we provide a useful convergence analysis framework for both the constrained and unconstrained bilevel optimization. To the best of our knowledge, we first study the adaptive bilevel optimization methods with adaptive learning rates.
Segmenting Hyperspectral Images Using Spectral-Spatial Convolutional Neural Networks With Training-Time Data Augmentation
Jul 27, 2019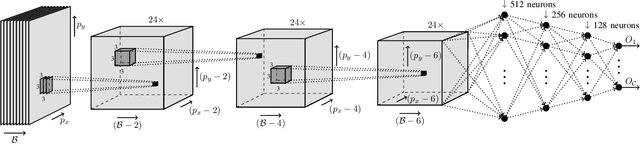
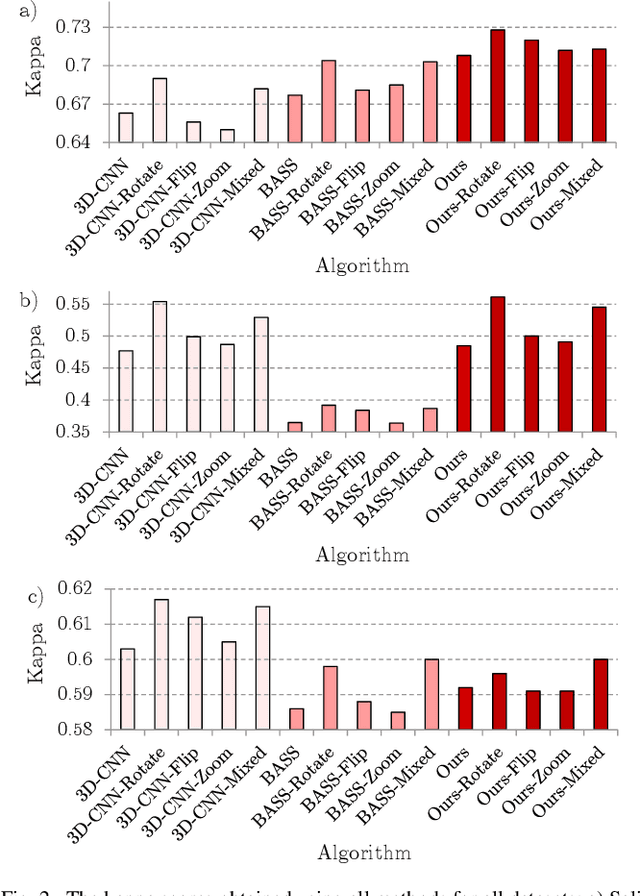
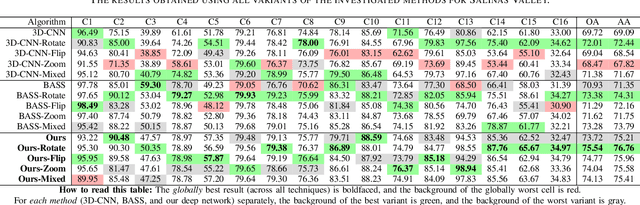
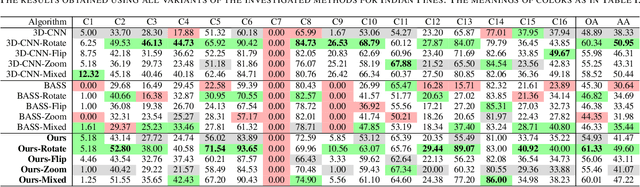
Hyperspectral imaging provides detailed information about the scanned objects, as it captures their spectral characteristics within a large number of wavelength bands. Classification of such data has become an active research topic due to its wide applicability in a variety of fields. Deep learning has established the state of the art in the area, and it constitutes the current research mainstream. In this letter, we introduce a new spectral-spatial convolutional neural network, benefitting from a battery of data augmentation techniques which help deal with a real-life problem of lacking ground-truth training data. Our rigorous experiments showed that the proposed method outperforms other spectral-spatial techniques from the literature, and delivers precise hyperspectral classification in real time.
Fast Rate Learning in Stochastic First Price Bidding
Jul 05, 2021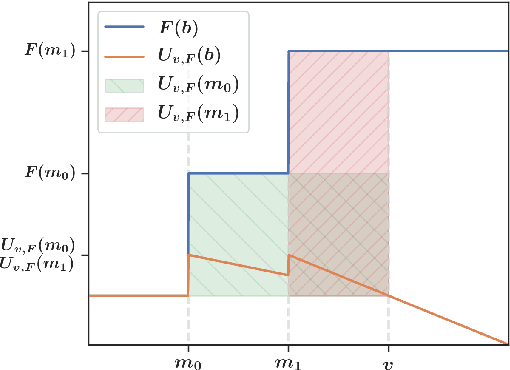
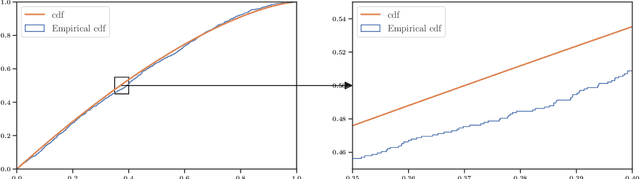
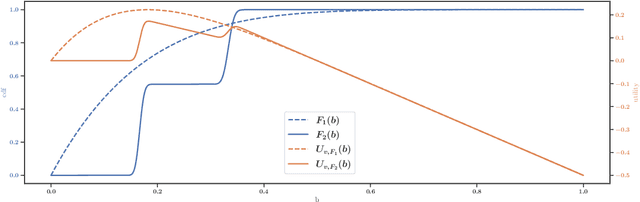
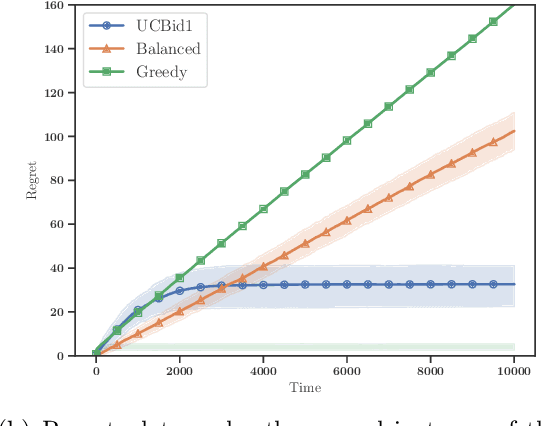
First-price auctions have largely replaced traditional bidding approaches based on Vickrey auctions in programmatic advertising. As far as learning is concerned, first-price auctions are more challenging because the optimal bidding strategy does not only depend on the value of the item but also requires some knowledge of the other bids. They have already given rise to several works in sequential learning, many of which consider models for which the value of the buyer or the opponents' maximal bid is chosen in an adversarial manner. Even in the simplest settings, this gives rise to algorithms whose regret grows as $\sqrt{T}$ with respect to the time horizon $T$. Focusing on the case where the buyer plays against a stationary stochastic environment, we show how to achieve significantly lower regret: when the opponents' maximal bid distribution is known we provide an algorithm whose regret can be as low as $\log^2(T)$; in the case where the distribution must be learnt sequentially, a generalization of this algorithm can achieve $T^{1/3+ \epsilon}$ regret, for any $\epsilon>0$. To obtain these results, we introduce two novel ideas that can be of interest in their own right. First, by transposing results obtained in the posted price setting, we provide conditions under which the first-price biding utility is locally quadratic around its optimum. Second, we leverage the observation that, on small sub-intervals, the concentration of the variations of the empirical distribution function may be controlled more accurately than by using the classical Dvoretzky-Kiefer-Wolfowitz inequality. Numerical simulations confirm that our algorithms converge much faster than alternatives proposed in the literature for various bid distributions, including for bids collected on an actual programmatic advertising platform.
MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift
Jun 07, 2021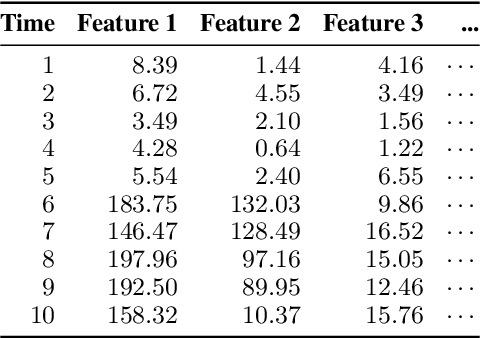
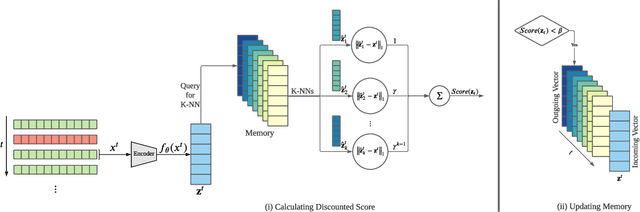
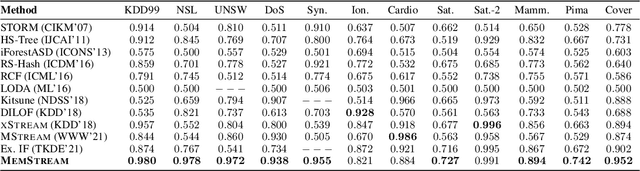
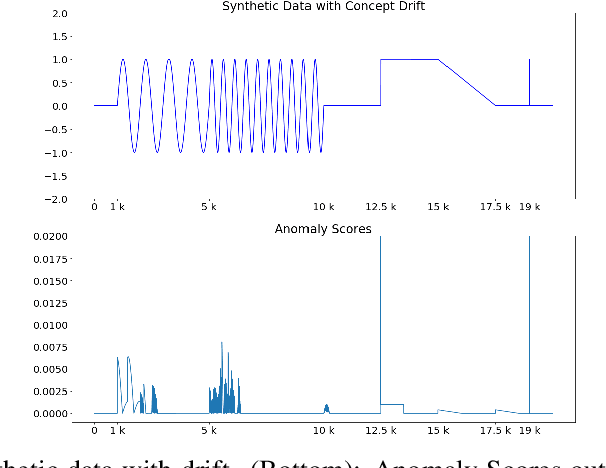
Given a stream of entries over time in a multi-aspect data setting where concept drift is present, how can we detect anomalous activities? Most of the existing unsupervised anomaly detection approaches seek to detect anomalous events in an offline fashion and require a large amount of data for training. This is not practical in real-life scenarios where we receive the data in a streaming manner and do not know the size of the stream beforehand. Thus, we need a data-efficient method that can detect and adapt to changing data trends, or concept drift, in an online manner. In this work, we propose MemStream, a streaming multi-aspect anomaly detection framework, allowing us to detect unusual events as they occur while being resilient to concept drift. We leverage the power of a denoising autoencoder to learn representations and a memory module to learn the dynamically changing trend in data without the need for labels. We prove the optimum memory size required for effective drift handling. Furthermore, MemStream makes use of two architecture design choices to be robust to memory poisoning. Experimental results show the effectiveness of our approach compared to state-of-the-art streaming baselines using 2 synthetic datasets and 11 real-world datasets.
Using Diachronic Distributed Word Representations as Models of Lexical Development in Children
May 11, 2021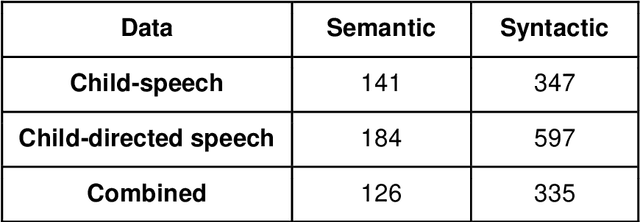
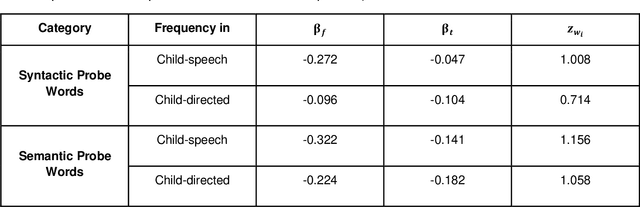
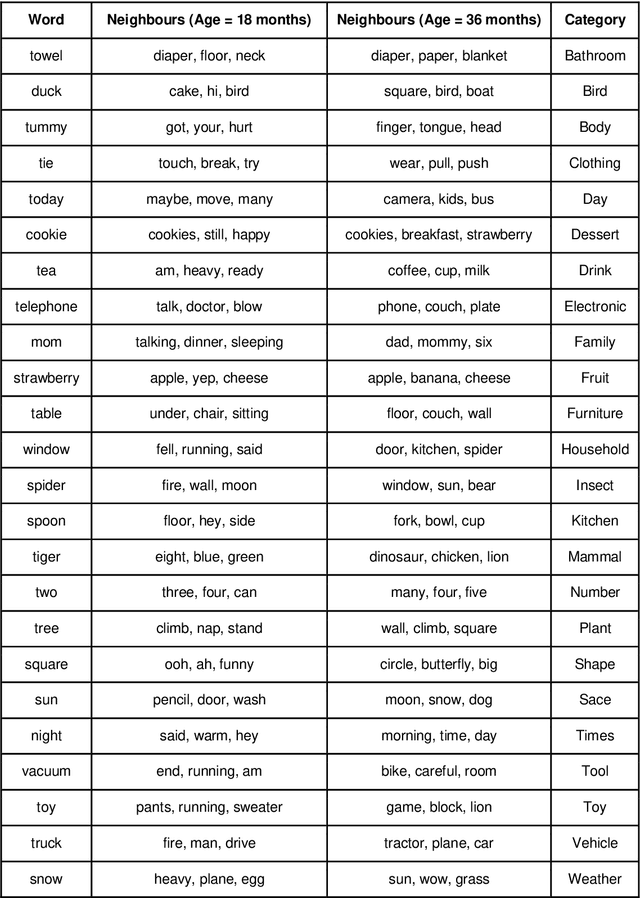
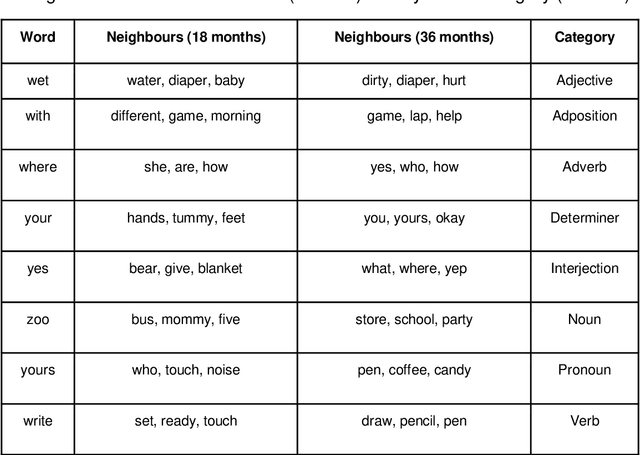
Recent work has shown that distributed word representations can encode abstract semantic and syntactic information from child-directed speech. In this paper, we use diachronic distributed word representations to perform temporal modeling and analysis of lexical development in children. Unlike all previous work, we use temporally sliced speech corpus to learn distributed word representations of child and child-directed speech. Through our modeling experiments, we demonstrate the dynamics of growing lexical knowledge in children over time, as compared against a saturated level of lexical knowledge in child-directed adult speech. We also fit linear mixed-effects models with the rate of semantic change in the diachronic representations and word frequencies. This allows us to inspect the role of word frequencies towards lexical development in children. Further, we perform a qualitative analysis of the diachronic representations from our model, which reveals the categorization and word associations in the mental lexicon of children.
Circumpapillary OCT-Focused Hybrid Learning for Glaucoma Grading Using Tailored Prototypical Neural Networks
Jun 25, 2021
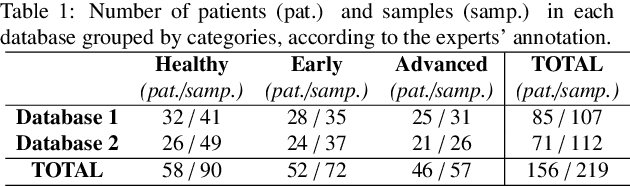
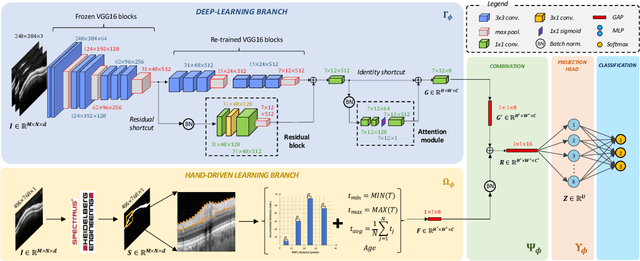

Glaucoma is one of the leading causes of blindness worldwide and Optical Coherence Tomography (OCT) is the quintessential imaging technique for its detection. Unlike most of the state-of-the-art studies focused on glaucoma detection, in this paper, we propose, for the first time, a novel framework for glaucoma grading using raw circumpapillary B-scans. In particular, we set out a new OCT-based hybrid network which combines hand-driven and deep learning algorithms. An OCT-specific descriptor is proposed to extract hand-crafted features related to the retinal nerve fibre layer (RNFL). In parallel, an innovative CNN is developed using skip-connections to include tailored residual and attention modules to refine the automatic features of the latent space. The proposed architecture is used as a backbone to conduct a novel few-shot learning based on static and dynamic prototypical networks. The k-shot paradigm is redefined giving rise to a supervised end-to-end system which provides substantial improvements discriminating between healthy, early and advanced glaucoma samples. The training and evaluation processes of the dynamic prototypical network are addressed from two fused databases acquired via Heidelberg Spectralis system. Validation and testing results reach a categorical accuracy of 0.9459 and 0.8788 for glaucoma grading, respectively. Besides, the high performance reported by the proposed model for glaucoma detection deserves a special mention. The findings from the class activation maps are directly in line with the clinicians' opinion since the heatmaps pointed out the RNFL as the most relevant structure for glaucoma diagnosis.
An Error-Based Approximation Sensing Circuit for Event-Triggered, Low Power Wearable Sensors
Jun 25, 2021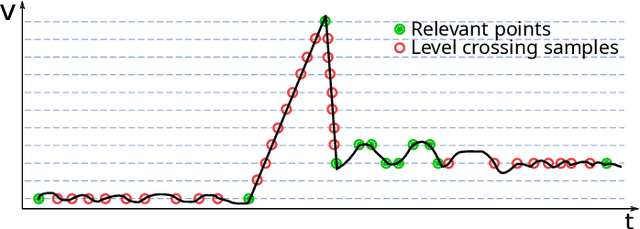
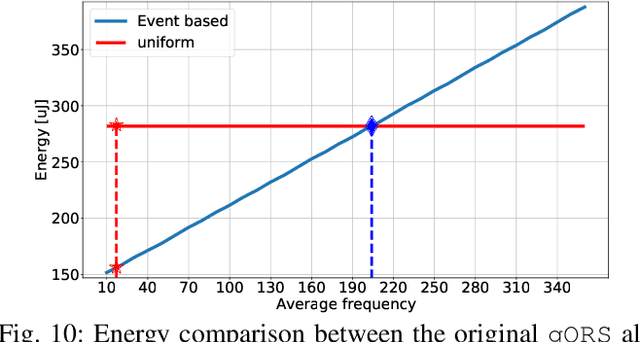
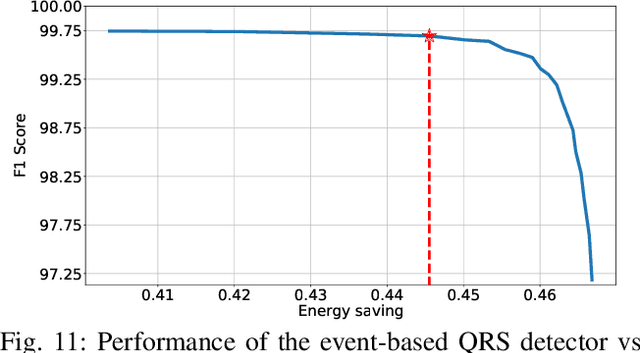
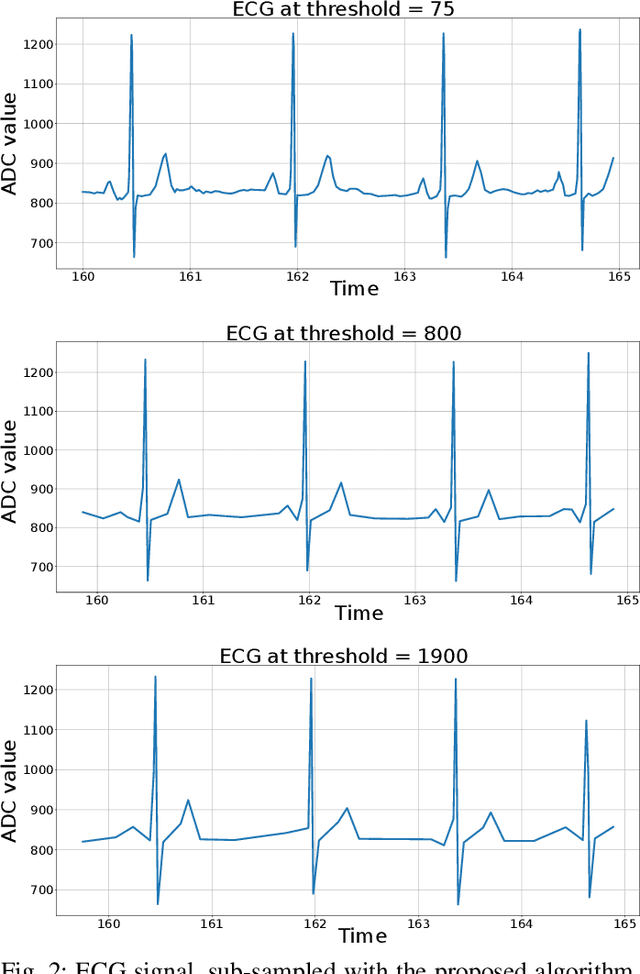
Event-based sensors have the potential to optimize energy consumption at every stage in the signal processing pipeline, including data acquisition, transmission, processing and storage. However, almost all state-of-the-art systems are still built upon the classical Nyquist-based periodic signal acquisition. In this work, we design and validate the Polygonal Approximation Sampler (PAS), a novel circuit to implement a general-purpose event-based sampler using a polygonal approximation algorithm as the underlying sampling trigger. The circuit can be dynamically reconfigured to produce a coarse or a detailed reconstruction of the analog input, by adjusting the error threshold of the approximation. The proposed circuit is designed at the Register Transfer Level and processes each input sample received from the ADC in a single clock cycle. The PAS has been tested with three different types of archetypal signals captured by wearable devices (electrocardiogram, accelerometer and respiration data) and compared with a standard periodic ADC. These tests show that single-channel signals, with slow variations and constant segments (like the used single-lead ECG and the respiration signals) take great advantage from the used sampling technique, reducing the amount of data used up to 99% without significant performance degradation. At the same time, multi-channel signals (like the six-dimensional accelerometer signal) can still benefit from the designed circuit, achieving a reduction factor up to 80% with minor performance degradation. These results open the door to new types of wearable sensors with reduced size and higher battery lifetime.