 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Mar 31, 2021
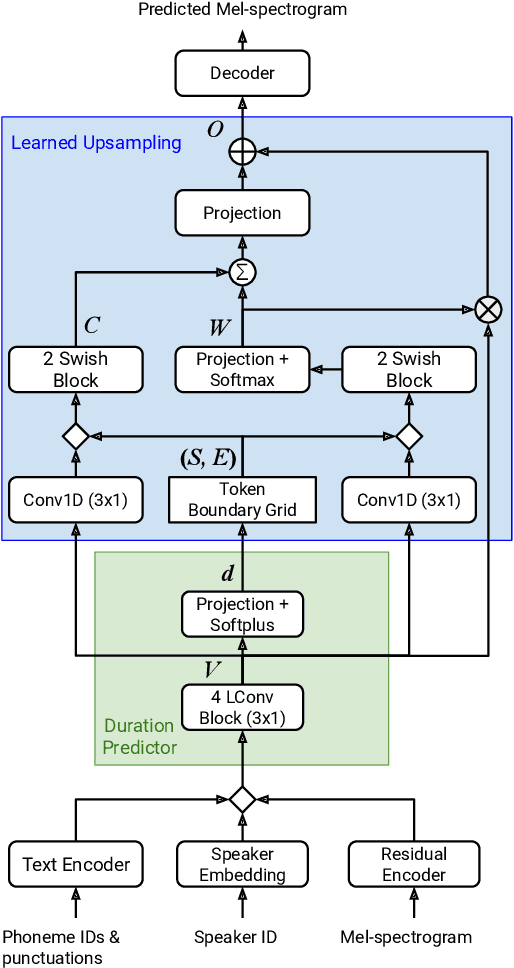
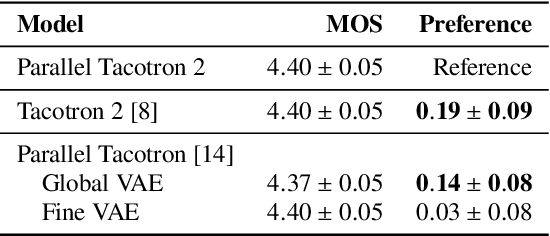
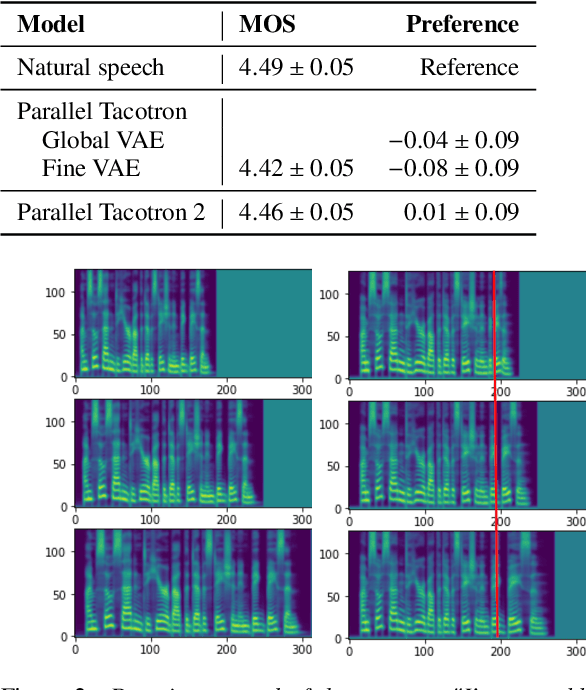

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
Attention-guided Temporal Coherent Video Object Matting
May 24, 2021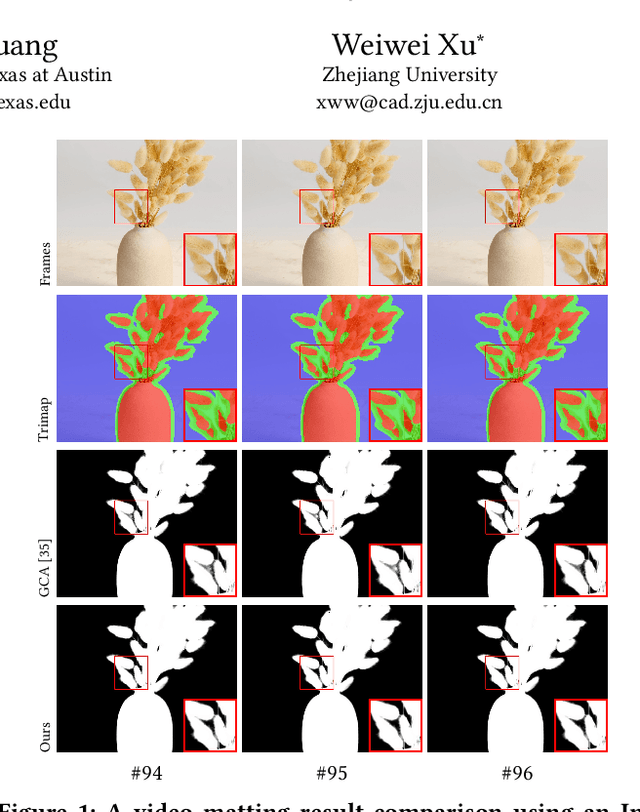
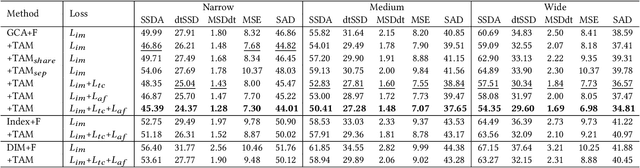
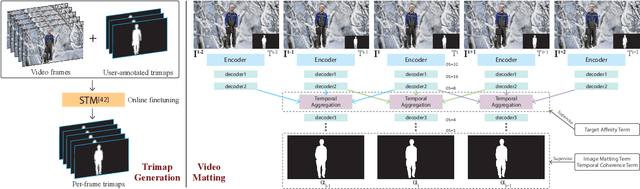
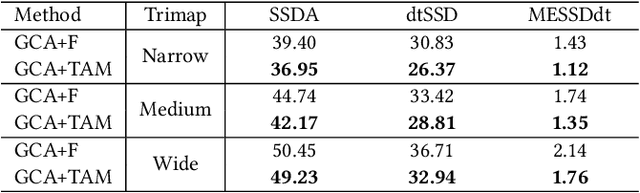
This paper proposes a novel deep learning-based video object matting method that can achieve temporally coherent matting results. Its key component is an attention-based temporal aggregation module that maximizes image matting networks' strength for video matting networks. This module computes temporal correlations for pixels adjacent to each other along the time axis in feature space to be robust against motion noises. We also design a novel loss term to train the attention weights, which drastically boosts the video matting performance. Besides, we show how to effectively solve the trimap generation problem by fine-tuning a state-of-the-art video object segmentation network with a sparse set of user-annotated keyframes. To facilitate video matting and trimap generation networks' training, we construct a large-scale video matting dataset with 80 training and 28 validation foreground video clips with ground-truth alpha mattes. Experimental results show that our method can generate high-quality alpha mattes for various videos featuring appearance change, occlusion, and fast motion. Our code and dataset can be found at https://github.com/yunkezhang/TCVOM
On the Concept of Frequency in Signal Processing
May 24, 2021Frequency is a central concept in Mathematics, Physics, and Signal Processing. It is the main tool for describing the oscillatory behavior of signals, which is usually argued to be the manifestation of some of their key features, depending on their nature. For instance, this is the case of Electroencephalographic signals. Hence, frequency is substantially present in the most common methodologies for analyzing signals, as the Fourier Analysis or the Time-Frequency Analysis. However, in spite of its importance as a keystone in Signal Processing, and its seemingly simple meaning, its mathematical foundation is not as straightforward as it may seem at first glance. A naive interpretation of the different mathematical concepts modelling frequency can be misleading, as their actual meanings essentially differ from the intuitive notion which are supposed to represent. In our opinion, this circumstance should be taken into account in order to develop appropriate signal analyzing and processing tools in some applications. In the current text we discuss this topic, with the main goal to draw the attention of the mathematical and engineering community to this point,often overlooked.
Initializing LSTM internal states via manifold learning
Apr 27, 2021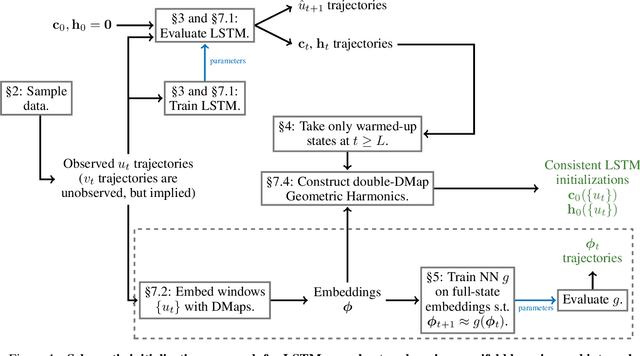
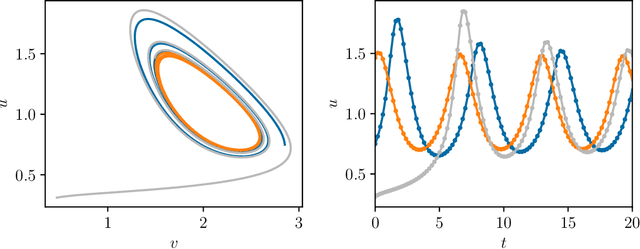
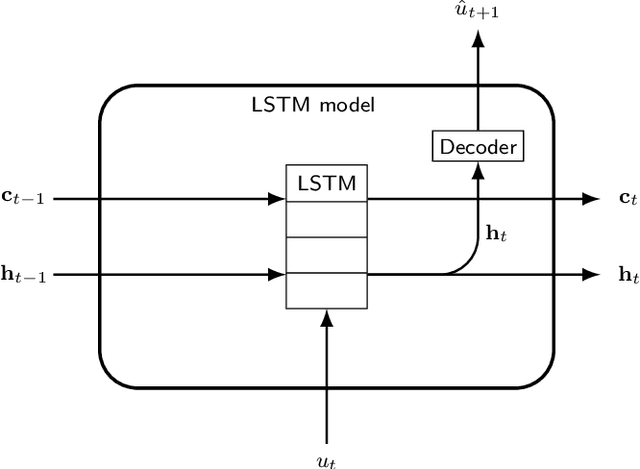
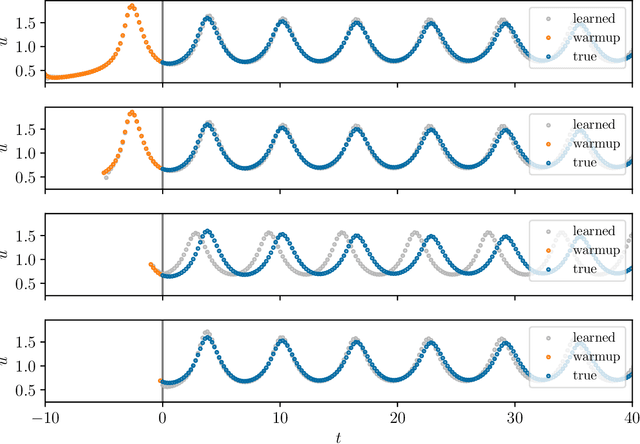
We present an approach, based on learning an intrinsic data manifold, for the initialization of the internal state values of LSTM recurrent neural networks, ensuring consistency with the initial observed input data. Exploiting the generalized synchronization concept, we argue that the converged, "mature" internal states constitute a function on this learned manifold. The dimension of this manifold then dictates the length of observed input time series data required for consistent initialization. We illustrate our approach through a partially observed chemical model system, where initializing the internal LSTM states in this fashion yields visibly improved performance. Finally, we show that learning this data manifold enables the transformation of partially observed dynamics into fully observed ones, facilitating alternative identification paths for nonlinear dynamical systems.
Protein sequence-to-structure learning: Is this the end(-to-end revolution)?
May 16, 2021
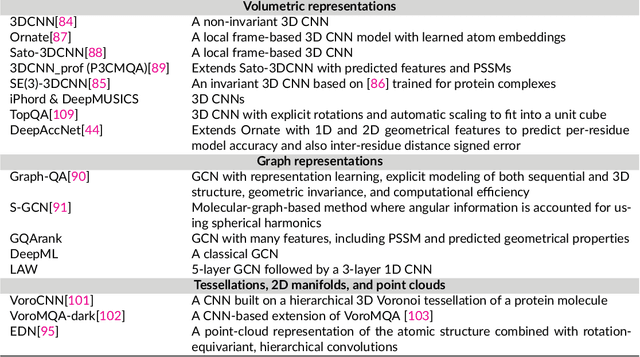
The potential of deep learning has been recognized in the protein structure prediction community for some time, and became indisputable after CASP13. In CASP14, deep learning has boosted the field to unanticipated levels reaching near-experimental accuracy. This success comes from advances transferred from other machine learning areas, as well as methods specifically designed to deal with protein sequences and structures, and their abstractions. Novel emerging approaches include (i) geometric learning, i.e. learning on representations such as graphs, 3D Voronoi tessellations, and point clouds; (ii) pre-trained protein language models leveraging attention; (iii) equivariant architectures preserving the symmetry of 3D space; (iv) use of large meta-genome databases; (v) combinations of protein representations; (vi) and finally truly end-to-end architectures, i.e. differentiable models starting from a sequence and returning a 3D structure. Here, we provide an overview and our opinion of the novel deep learning approaches developed in the last two years and widely used in CASP14.
Anytime Diagnosis for Reconfiguration
Feb 19, 2021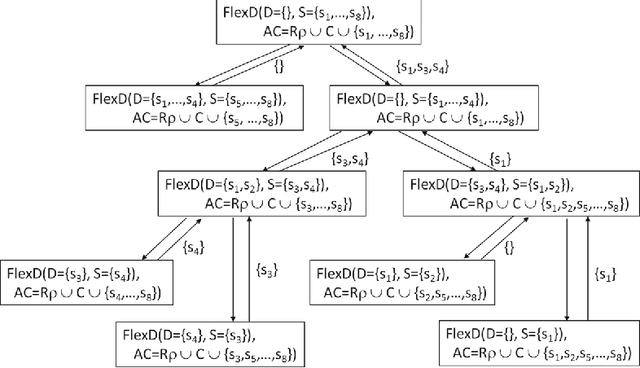
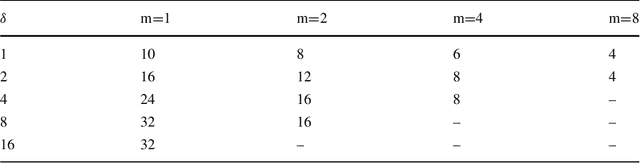
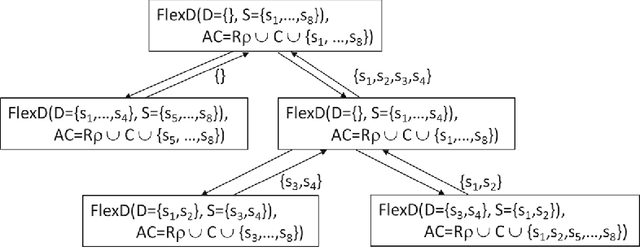
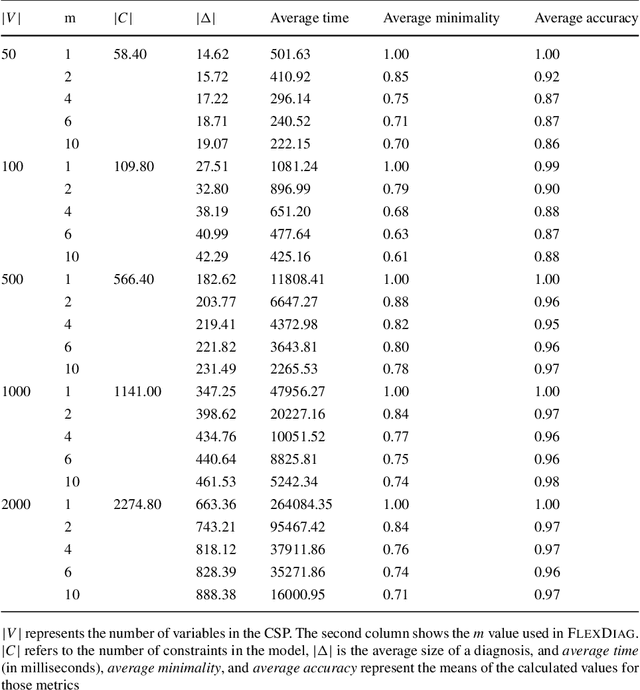
Many domains require scalable algorithms that help to determine diagnoses efficiently and often within predefined time limits. Anytime diagnosis is able to determine solutions in such a way and thus is especially useful in real-time scenarios such as production scheduling, robot control, and communication networks management where diagnosis and corresponding reconfiguration capabilities play a major role. Anytime diagnosis in many cases comes along with a trade-off between diagnosis quality and the efficiency of diagnostic reasoning. In this paper we introduce and analyze FlexDiag which is an anytime direct diagnosis approach. We evaluate the algorithm with regard to performance and diagnosis quality using a configuration benchmark from the domain of feature models and an industrial configuration knowledge base from the automotive domain. Results show that FlexDiag helps to significantly increase the performance of direct diagnosis search with corresponding quality tradeoffs in terms of minimality and accuracy.
Language Models are Few-Shot Butlers
Apr 16, 2021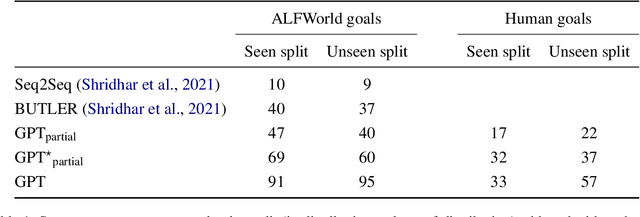
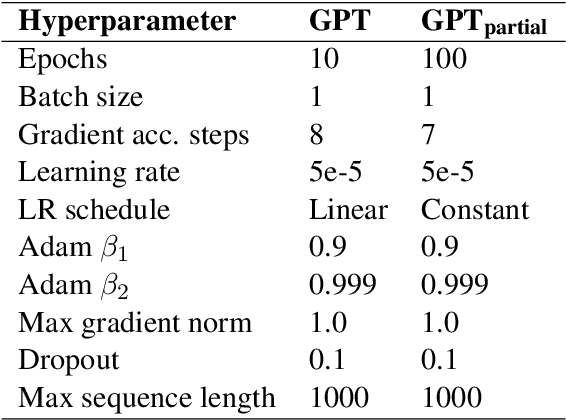
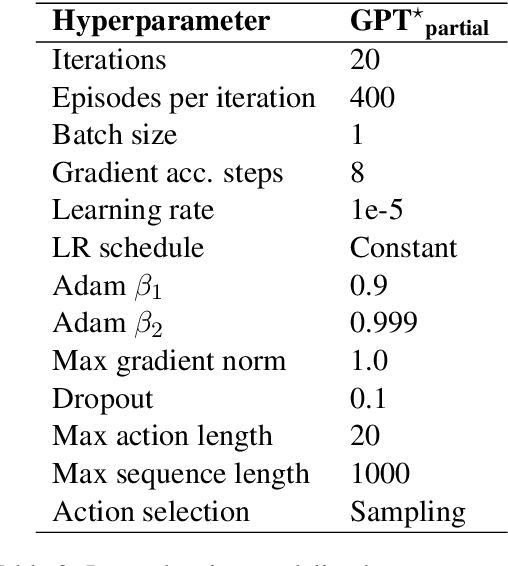
Pretrained language models demonstrate strong performance in most NLP tasks when fine-tuned on small task-specific datasets. Hence, these autoregressive models constitute ideal agents to operate in text-based environments where language understanding and generative capabilities are essential. Nonetheless, collecting expert demonstrations in such environments is a time-consuming endeavour. We introduce a two-stage procedure to learn from a small set of demonstrations and further improve by interacting with an environment. We show that language models fine-tuned with only 1.2% of the expert demonstrations and a simple reinforcement learning algorithm achieve a 51% absolute improvement in success rate over existing methods in the ALFWorld environment.
Detecting Spurious Correlations with Sanity Tests for Artificial Intelligence Guided Radiology Systems
Mar 04, 2021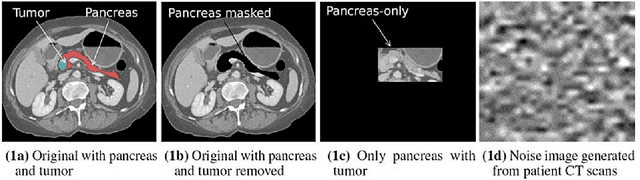

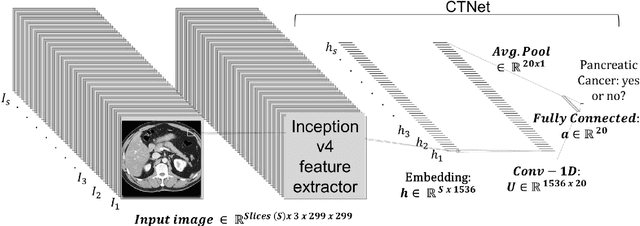

Artificial intelligence (AI) has been successful at solving numerous problems in machine perception. In radiology, AI systems are rapidly evolving and show progress in guiding treatment decisions, diagnosing, localizing disease on medical images, and improving radiologists' efficiency. A critical component to deploying AI in radiology is to gain confidence in a developed system's efficacy and safety. The current gold standard approach is to conduct an analytical validation of performance on a generalization dataset from one or more institutions, followed by a clinical validation study of the system's efficacy during deployment. Clinical validation studies are time-consuming, and best practices dictate limited re-use of analytical validation data, so it is ideal to know ahead of time if a system is likely to fail analytical or clinical validation. In this paper, we describe a series of sanity tests to identify when a system performs well on development data for the wrong reasons. We illustrate the sanity tests' value by designing a deep learning system to classify pancreatic cancer seen in computed tomography scans.
End-to-End Multihop Retrieval for Compositional Question Answering over Long Documents
Jun 01, 2021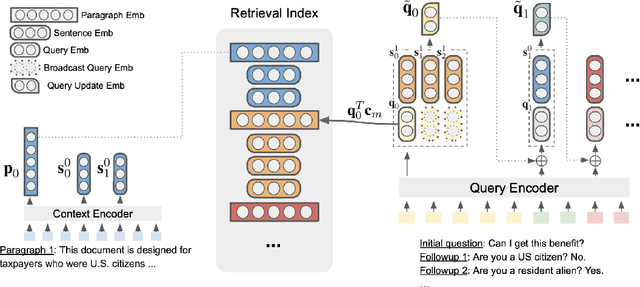
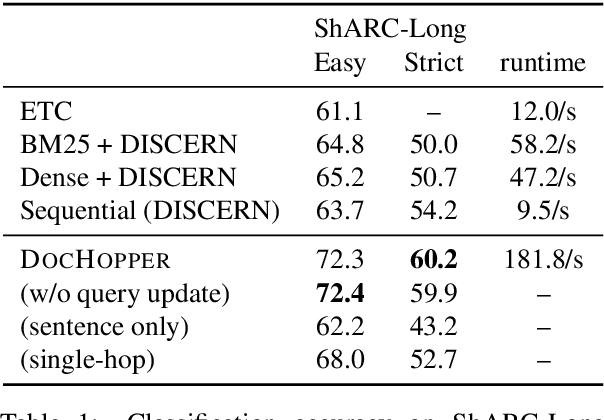
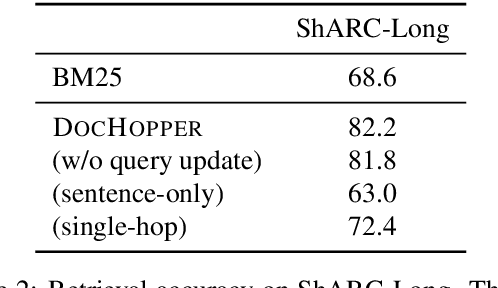
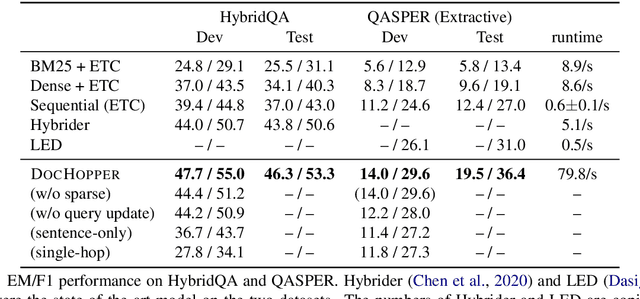
Answering complex questions from long documents requires aggregating multiple pieces of evidence and then predicting the answers. In this paper, we propose a multi-hop retrieval method, DocHopper, to answer compositional questions over long documents. At each step, DocHopper retrieves a paragraph or sentence embedding from the document, mixes the retrieved result with the query, and updates the query for the next step. In contrast to many other retrieval-based methods (e.g., RAG or REALM) the query is not augmented with a token sequence: instead, it is augmented by "numerically" combining it with another neural representation. This means that model is end-to-end differentiable. We demonstrate that utilizing document structure in this was can largely improve question-answering and retrieval performance on long documents. We experimented with DocHopper on three different QA tasks that require reading long documents to answer compositional questions: discourse entailment reasoning, factual QA with table and text, and information seeking QA from academic papers. DocHopper outperforms all baseline models and achieves state-of-the-art results on all datasets. Additionally, DocHopper is efficient at inference time, being 3~10 times faster than the baselines.
Real-time On-Demand Crowd-powered Entity Extraction
Dec 06, 2017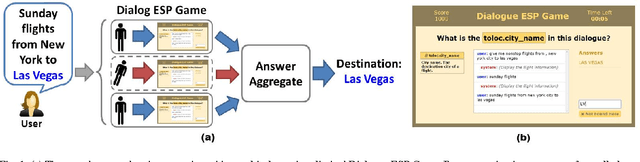
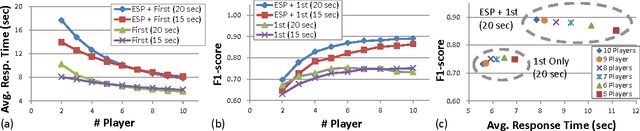
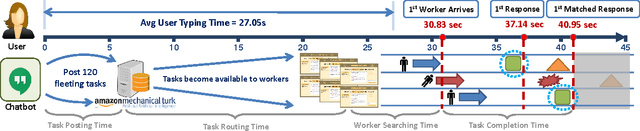
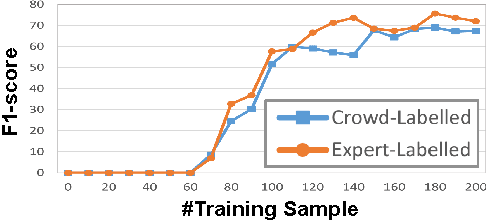
Output-agreement mechanisms such as ESP Game have been widely used in human computation to obtain reliable human-generated labels. In this paper, we argue that a "time-limited" output-agreement mechanism can be used to create a fast and robust crowd-powered component in interactive systems, particularly dialogue systems, to extract key information from user utterances on the fly. Our experiments on Amazon Mechanical Turk using the Airline Travel Information System (ATIS) dataset showed that the proposed approach achieves high-quality results with an average response time shorter than 9 seconds.