 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combining Deep Learning and Model-Based Methods for Robust Real-Time Semantic Landmark Detection
Sep 02, 2019

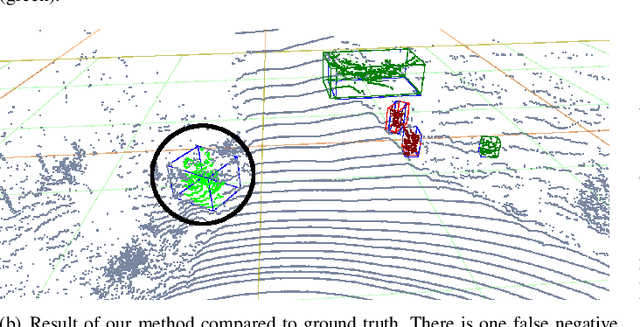
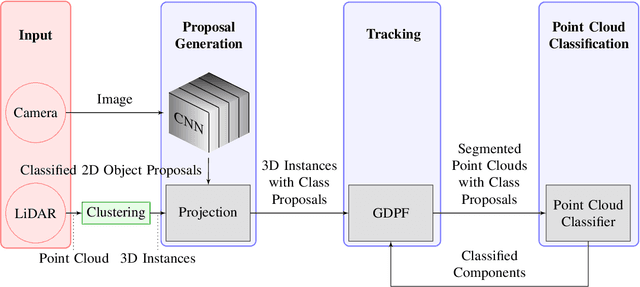

Compared to abstract features, significant objects, so-called landmarks, are a more natural means for vehicle localization and navigation, especially in challenging unstructured environments. The major challenge is to recognize landmarks in various lighting conditions and changing environment (growing vegetation) while only having few training samples available. We propose a new method which leverages Deep Learning as well as model-based methods to overcome the need of a large data set. Using RGB images and light detection and ranging (LiDAR) point clouds, our approach combines state-of-the-art classification results of Convolutional Neural Networks (CNN), with robust model-based methods by taking prior knowledge of previous time steps into account. Evaluations on a challenging real-wold scenario, with trees and bushes as landmarks, show promising results over pure learning-based state-of-the-art 3D detectors, while being significant faster.
Demonstration of Panda: A Weakly Supervised Entity Matching System
Jun 21, 2021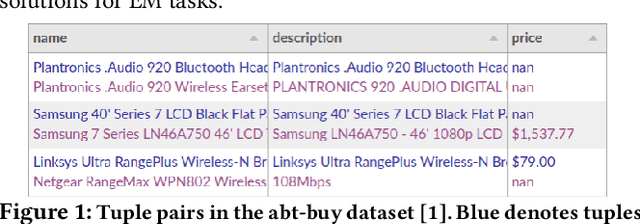

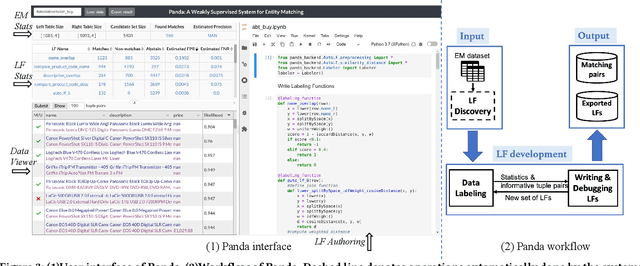
Entity matching (EM) refers to the problem of identifying tuple pairs in one or more relations that refer to the same real world entities. Supervised machine learning (ML) approaches, and deep learning based approaches in particular, typically achieve state-of-the-art matching results. However, these approaches require many labeled examples, in the form of matching and non-matching pairs, which are expensive and time-consuming to label. In this paper, we introduce Panda, a weakly supervised system specifically designed for EM. Panda uses the same labeling function abstraction as Snorkel, where labeling functions (LF) are user-provided programs that can generate large amounts of (somewhat noisy) labels quickly and cheaply, which can then be combined via a labeling model to generate accurate final predictions. To support users developing LFs for EM, Panda provides an integrated development environment (IDE) that lives in a modern browser architecture. Panda's IDE facilitates the development, debugging, and life-cycle management of LFs in the context of EM tasks, similar to how IDEs such as Visual Studio or Eclipse excel in general-purpose programming. Panda's IDE includes many novel features purpose-built for EM, such as smart data sampling, a builtin library of EM utility functions, automatically generated LFs, visual debugging of LFs, and finally, an EM-specific labeling model. We show in this demo that Panda IDE can greatly accelerate the development of high-quality EM solutions using weak supervision.
* video can be found at https://chu-data-lab.cc.gatech.edu/ml-for-data-integration/
A Streaming End-to-End Framework For Spoken Language Understanding
Jun 08, 2021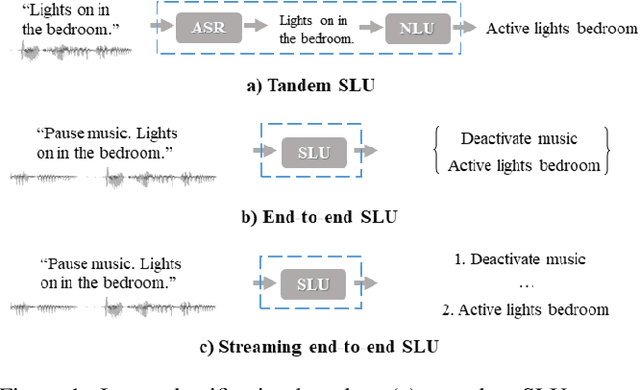
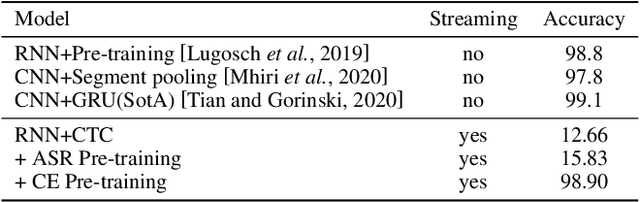
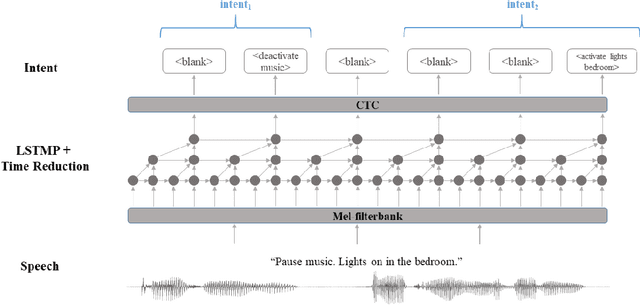

End-to-end spoken language understanding (SLU) has recently attracted increasing interest. Compared to the conventional tandem-based approach that combines speech recognition and language understanding as separate modules, the new approach extracts users' intentions directly from the speech signals, resulting in joint optimization and low latency. Such an approach, however, is typically designed to process one intention at a time, which leads users to take multiple rounds to fulfill their requirements while interacting with a dialogue system. In this paper, we propose a streaming end-to-end framework that can process multiple intentions in an online and incremental way. The backbone of our framework is a unidirectional RNN trained with the connectionist temporal classification (CTC) criterion. By this design, an intention can be identified when sufficient evidence has been accumulated, and multiple intentions can be identified sequentially. We evaluate our solution on the Fluent Speech Commands (FSC) dataset and the intent detection accuracy is about 97 % on all multi-intent settings. This result is comparable to the performance of the state-of-the-art non-streaming models, but is achieved in an online and incremental way. We also employ our model to a keyword spotting task using the Google Speech Commands dataset and the results are also highly promising.
On Finding the $K$-best Non-projective Dependency Trees
Jun 01, 2021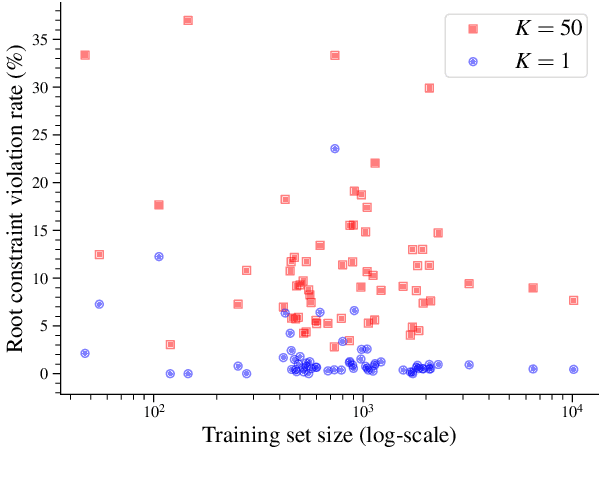
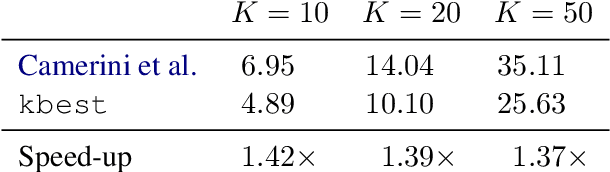
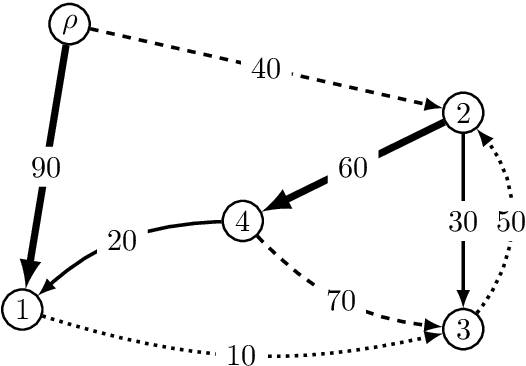

The connection between the maximum spanning tree in a directed graph and the best dependency tree of a sentence has been exploited by the NLP community. However, for many dependency parsing schemes, an important detail of this approach is that the spanning tree must have exactly one edge emanating from the root. While work has been done to efficiently solve this problem for finding the one-best dependency tree, no research has attempted to extend this solution to finding the $K$-best dependency trees. This is arguably a more important extension as a larger proportion of decoded trees will not be subject to the root constraint of dependency trees. Indeed, we show that the rate of root constraint violations increases by an average of $13$ times when decoding with $K\!=\!50$ as opposed to $K\!=\!1$. In this paper, we provide a simplification of the $K$-best spanning tree algorithm of Camerini et al. (1980). Our simplification allows us to obtain a constant time speed-up over the original algorithm. Furthermore, we present a novel extension of the algorithm for decoding the $K$-best dependency trees of a graph which are subject to a root constraint.
Person Re-Identification with a Locally Aware Transformer
Jun 08, 2021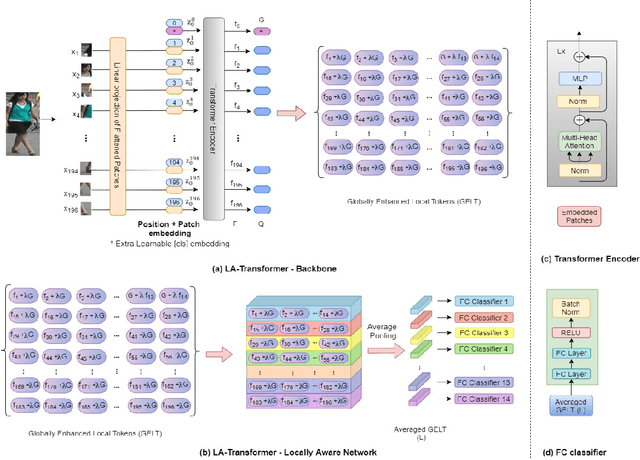
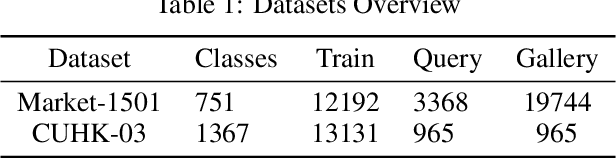
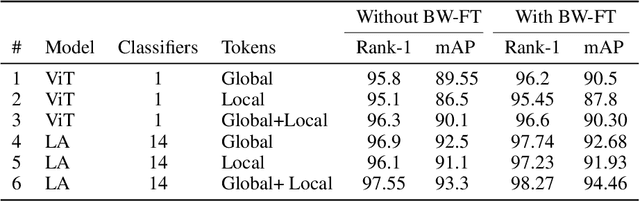
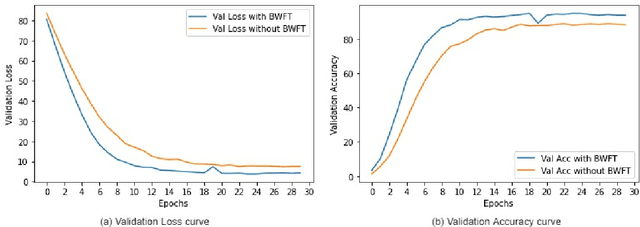
Person Re-Identification is an important problem in computer vision-based surveillance applications, in which the same person is attempted to be identified from surveillance photographs in a variety of nearby zones. At present, the majority of Person re-ID techniques are based on Convolutional Neural Networks (CNNs), but Vision Transformers are beginning to displace pure CNNs for a variety of object recognition tasks. The primary output of a vision transformer is a global classification token, but vision transformers also yield local tokens which contain additional information about local regions of the image. Techniques to make use of these local tokens to improve classification accuracy are an active area of research. We propose a novel Locally Aware Transformer (LA-Transformer) that employs a Parts-based Convolution Baseline (PCB)-inspired strategy for aggregating globally enhanced local classification tokens into an ensemble of $\sqrt{N}$ classifiers, where $N$ is the number of patches. An additional novelty is that we incorporate blockwise fine-tuning which further improves re-ID accuracy. LA-Transformer with blockwise fine-tuning achieves rank-1 accuracy of $98.27 \%$ with standard deviation of $0.13$ on the Market-1501 and $98.7\%$ with standard deviation of $0.2$ on the CUHK03 dataset respectively, outperforming all other state-of-the-art published methods at the time of writing.
Mitigating Gradient-based Adversarial Attacks via Denoising and Compression
Apr 03, 2021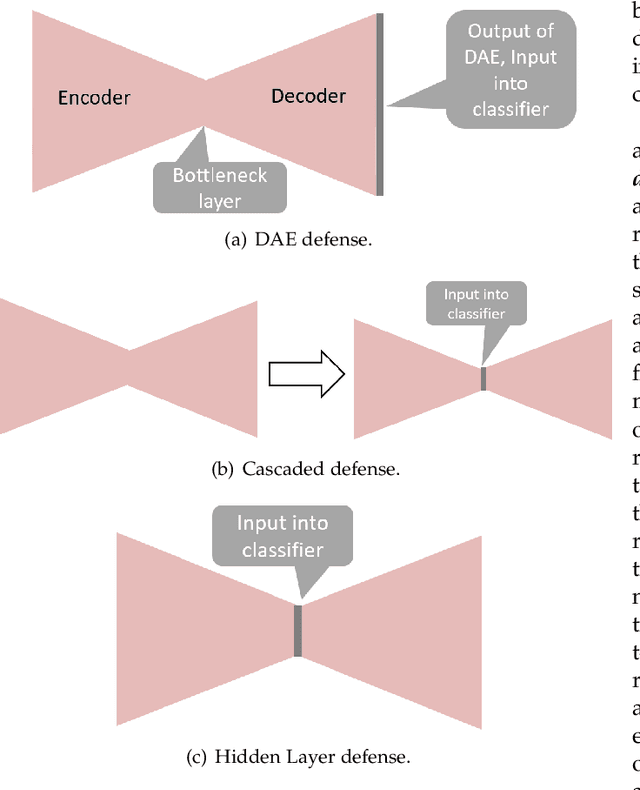
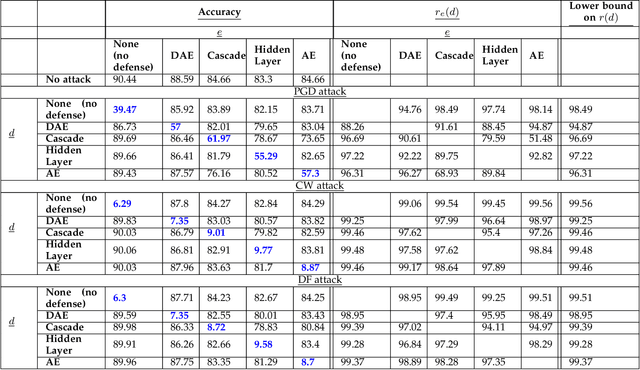
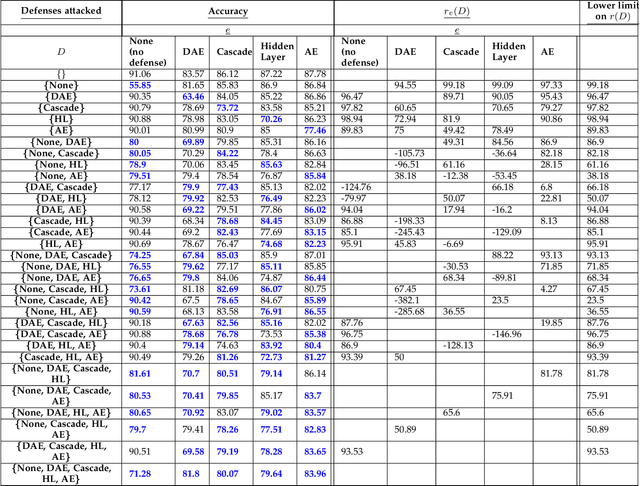
Gradient-based adversarial attacks on deep neural networks pose a serious threat, since they can be deployed by adding imperceptible perturbations to the test data of any network, and the risk they introduce cannot be assessed through the network's original training performance. Denoising and dimensionality reduction are two distinct methods that have been independently investigated to combat such attacks. While denoising offers the ability to tailor the defense to the specific nature of the attack, dimensionality reduction offers the advantage of potentially removing previously unseen perturbations, along with reducing the training time of the network being defended. We propose strategies to combine the advantages of these two defense mechanisms. First, we propose the cascaded defense, which involves denoising followed by dimensionality reduction. To reduce the training time of the defense for a small trade-off in performance, we propose the hidden layer defense, which involves feeding the output of the encoder of a denoising autoencoder into the network. Further, we discuss how adaptive attacks against these defenses could become significantly weak when an alternative defense is used, or when no defense is used. In this light, we propose a new metric to evaluate a defense which measures the sensitivity of the adaptive attack to modifications in the defense. Finally, we present a guideline for building an ordered repertoire of defenses, a.k.a. a defense infrastructure, that adjusts to limited computational resources in presence of uncertainty about the attack strategy.
Collaborative Nonstationary Multivariate Gaussian Process Model
Jun 01, 2021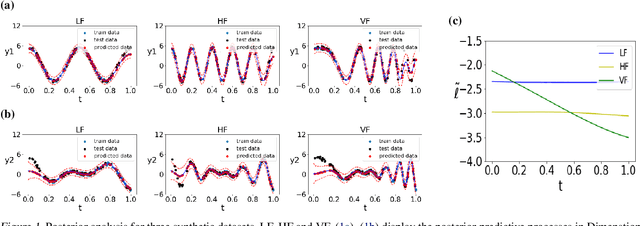
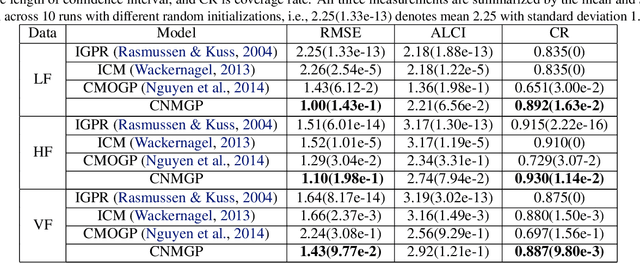
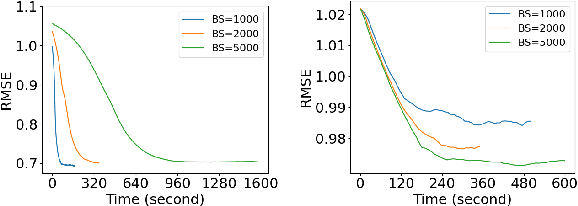

Currently, multi-output Gaussian process regression models either do not model nonstationarity or are associated with severe computational burdens and storage demands. Nonstationary multi-variate Gaussian process models (NMGP) use a nonstationary covariance function with an input-dependent linear model of coregionalisation to jointly model input-dependent correlation, scale, and smoothness of outputs. Variational sparse approximation relies on inducing points to enable scalable computations. Here, we take the best of both worlds: considering an inducing variable framework on the underlying latent functions in NMGP, we propose a novel model called the collaborative nonstationary Gaussian process model(CNMGP). For CNMGP, we derive computationally tractable variational bounds amenable to doubly stochastic variational inference. Together, this allows us to model data in which outputs do not share a common input set, with a computational complexity that is independent of the size of the inputs and outputs. We illustrate the performance of our method on synthetic data and three real datasets and show that our model generally pro-vides better predictive performance than the state-of-the-art, and also provides estimates of time-varying correlations that differ across outputs.
Facial Micro-Expression Spotting and Recognition using Time Contrasted Feature with Visual Memory
Feb 09, 2019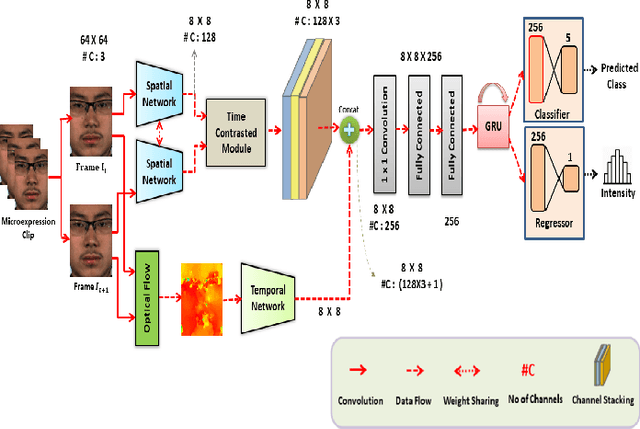
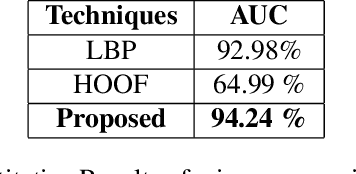
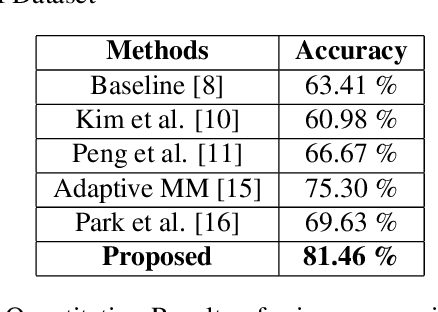

Facial micro-expressions are sudden involuntary minute muscle movements which reveal true emotions that people try to conceal. Spotting a micro-expression and recognizing it is a major challenge owing to its short duration and intensity. Many works pursued traditional and deep learning based approaches to solve this issue but compromised on learning low-level features and higher accuracy due to unavailability of datasets. This motivated us to propose a novel joint architecture of spatial and temporal network which extracts time-contrasted features from the feature maps to contrast out micro-expression from rapid muscle movements. The usage of time contrasted features greatly improved the spotting of micro-expression from inconspicuous facial movements. Also, we include a memory module to predict the class and intensity of the micro-expression across the temporal frames of the micro-expression clip. Our method achieves superior performance in comparison to other conventional approaches on CASMEII dataset.
A Framework for Integrating Gesture Generation Models into Interactive Conversational Agents
Feb 24, 2021Embodied conversational agents (ECAs) benefit from non-verbal behavior for natural and efficient interaction with users. Gesticulation - hand and arm movements accompanying speech - is an essential part of non-verbal behavior. Gesture generation models have been developed for several decades: starting with rule-based and ending with mainly data-driven methods. To date, recent end-to-end gesture generation methods have not been evaluated in a real-time interaction with users. We present a proof-of-concept framework, which is intended to facilitate evaluation of modern gesture generation models in interaction. We demonstrate an extensible open-source framework that contains three components: 1) a 3D interactive agent; 2) a chatbot backend; 3) a gesticulating system. Each component can be replaced, making the proposed framework applicable for investigating the effect of different gesturing models in real-time interactions with different communication modalities, chatbot backends, or different agent appearances. The code and video are available at the project page https://nagyrajmund.github.io/project/gesturebot.
GeoMol: Torsional Geometric Generation of Molecular 3D Conformer Ensembles
Jun 08, 2021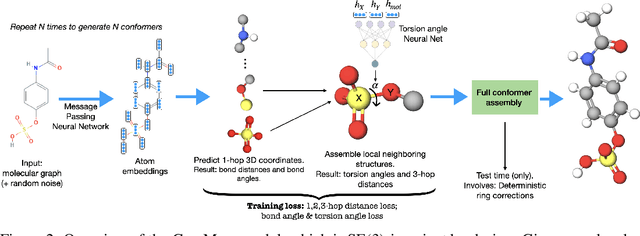
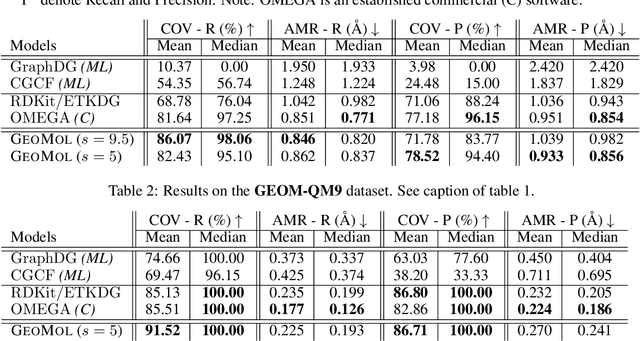
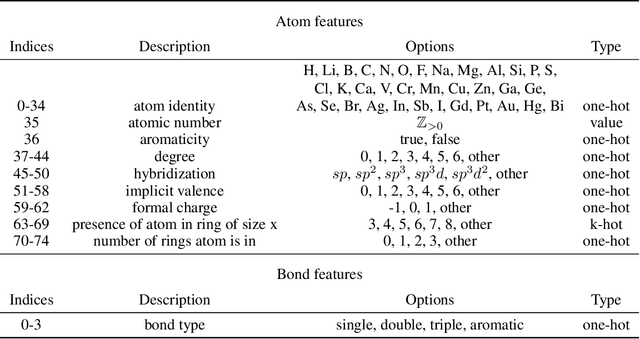
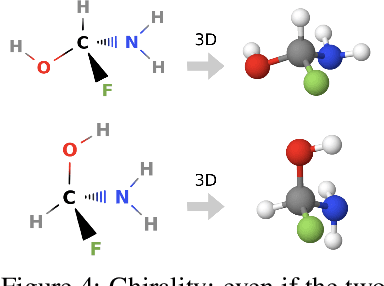
Prediction of a molecule's 3D conformer ensemble from the molecular graph holds a key role in areas of cheminformatics and drug discovery. Existing generative models have several drawbacks including lack of modeling important molecular geometry elements (e.g. torsion angles), separate optimization stages prone to error accumulation, and the need for structure fine-tuning based on approximate classical force-fields or computationally expensive methods such as metadynamics with approximate quantum mechanics calculations at each geometry. We propose GeoMol--an end-to-end, non-autoregressive and SE(3)-invariant machine learning approach to generate distributions of low-energy molecular 3D conformers. Leveraging the power of message passing neural networks (MPNNs) to capture local and global graph information, we predict local atomic 3D structures and torsion angles, avoiding unnecessary over-parameterization of the geometric degrees of freedom (e.g. one angle per non-terminal bond). Such local predictions suffice both for the training loss computation, as well as for the full deterministic conformer assembly (at test time). We devise a non-adversarial optimal transport based loss function to promote diverse conformer generation. GeoMol predominantly outperforms popular open-source, commercial, or state-of-the-art machine learning (ML) models, while achieving significant speed-ups. We expect such differentiable 3D structure generators to significantly impact molecular modeling and related applications.