 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QoS-Aware Power Minimization of Distributed Many-Core Servers using Transfer Q-Learning
Feb 02, 2021
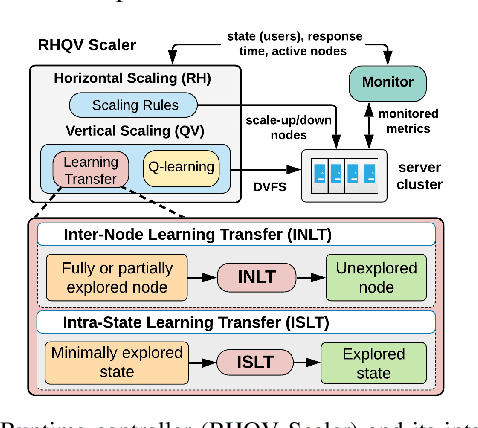
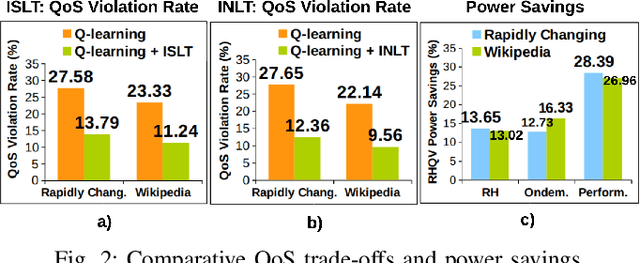
Web servers scaled across distributed systems necessitate complex runtime controls for providing quality of service (QoS) guarantees as well as minimizing the energy costs under dynamic workloads. This paper presents a QoS-aware runtime controller using horizontal scaling (node allocation) and vertical scaling (resource allocation within nodes) methods synergistically to provide adaptation to workloads while minimizing the power consumption under QoS constraint (i.e., response time). A horizontal scaling determines the number of active nodes based on workload demands and the required QoS according to a set of rules. Then, it is coupled with vertical scaling using transfer Q-learning, which further tunes power/performance based on workload profile using dynamic voltage/frequency scaling (DVFS). It transfers Q-values within minimally explored states reducing exploration requirements. In addition, the approach exploits a scalable architecture of the many-core server allowing to reuse available knowledge from fully or partially explored nodes. When combined, these methods allow to reduce the exploration time and QoS violations when compared to model-free Q-learning. The technique balances design-time and runtime costs to maximize the portability and operational optimality demonstrated through persistent power reductions with minimal QoS violations under different workload scenarios on heterogeneous multi-processing nodes of a server cluster.
Orbital dynamics of binary black hole systems can be learned from gravitational wave measurements
Feb 25, 2021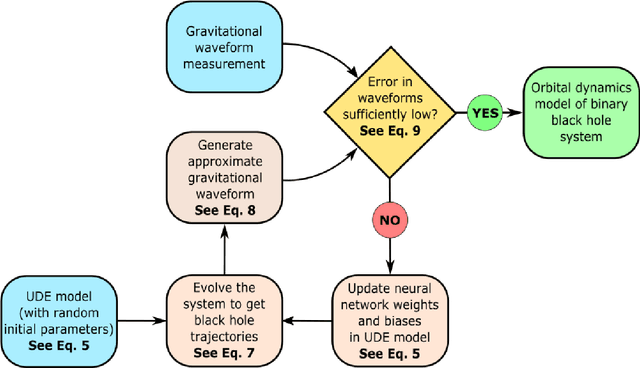
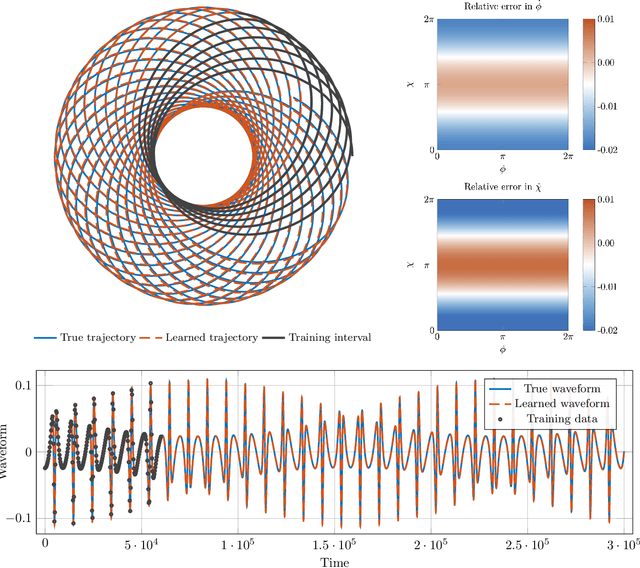
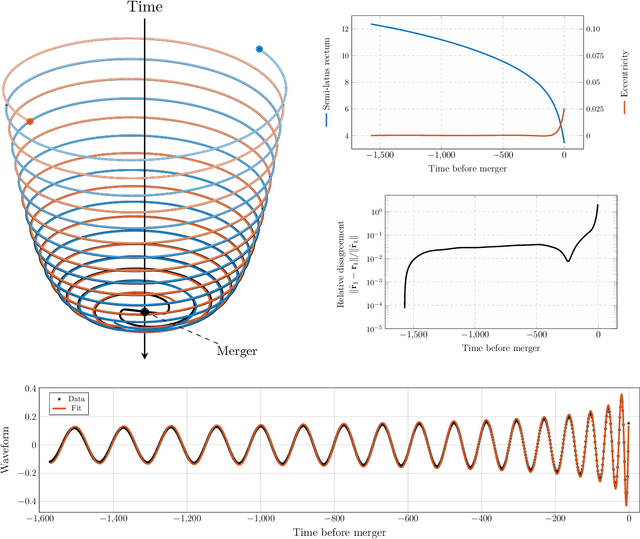
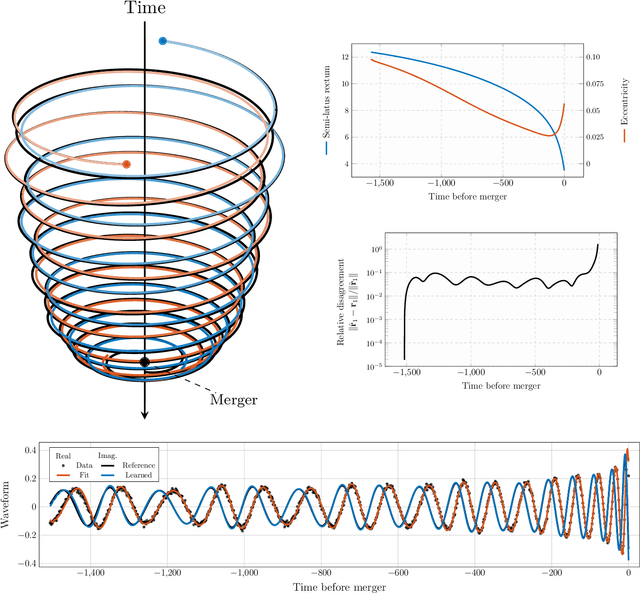
We introduce a gravitational waveform inversion strategy that discovers mechanical models of binary black hole (BBH) systems. We show that only a single time series of (possibly noisy) waveform data is necessary to construct the equations of motion for a BBH system. Starting with a class of universal differential equations parameterized by feed-forward neural networks, our strategy involves the construction of a space of plausible mechanical models and a physics-informed constrained optimization within that space to minimize the waveform error. We apply our method to various BBH systems including extreme and comparable mass ratio systems in eccentric and non-eccentric orbits. We show the resulting differential equations apply to time durations longer than the training interval, and relativistic effects, such as perihelion precession, radiation reaction, and orbital plunge, are automatically accounted for. The methods outlined here provide a new, data-driven approach to studying the dynamics of binary black hole systems.
Longitudinal Citation Prediction using Temporal Graph Neural Networks
Dec 10, 2020
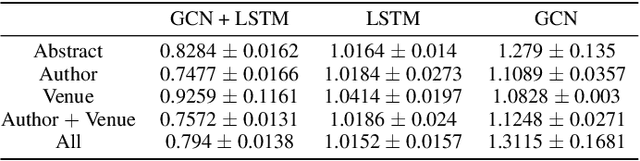
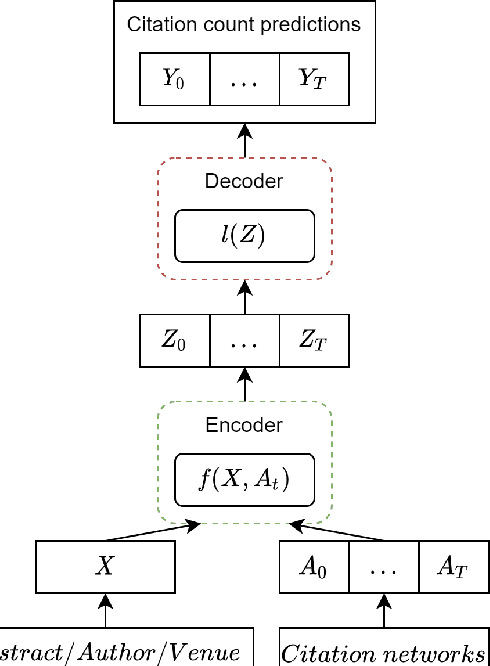
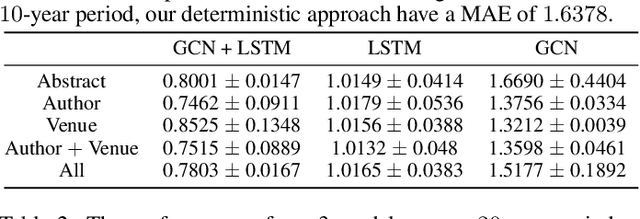
Citation count prediction is the task of predicting the number of citations a paper has gained after a period of time. Prior work viewed this as a static prediction task. As papers and their citations evolve over time, considering the dynamics of the number of citations a paper will receive would seem logical. Here, we introduce the task of sequence citation prediction, where the goal is to accurately predict the trajectory of the number of citations a scholarly work receives over time. We propose to view papers as a structured network of citations, allowing us to use topological information as a learning signal. Additionally, we learn how this dynamic citation network changes over time and the impact of paper meta-data such as authors, venues and abstracts. To approach the introduced task, we derive a dynamic citation network from Semantic Scholar which spans over 42 years. We present a model which exploits topological and temporal information using graph convolution networks paired with sequence prediction, and compare it against multiple baselines, testing the importance of topological and temporal information and analyzing model performance. Our experiments show that leveraging both the temporal and topological information greatly increases the performance of predicting citation counts over time.
Robust Egocentric Photo-realistic Facial Expression Transfer for Virtual Reality
Apr 10, 2021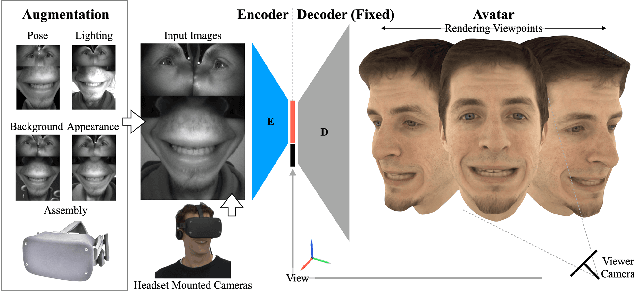
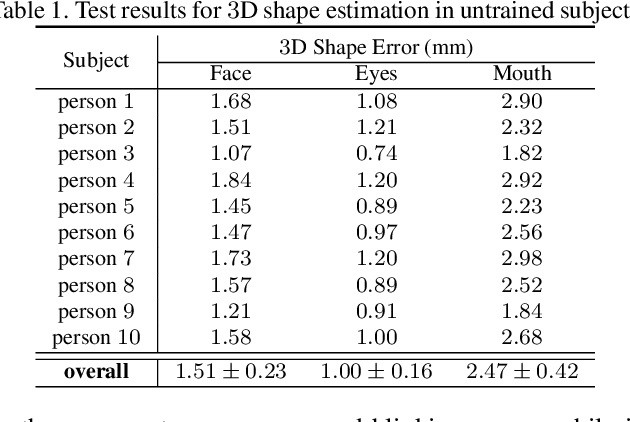

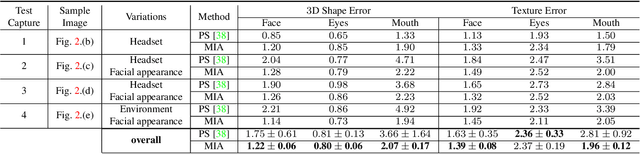
Social presence, the feeling of being there with a real person, will fuel the next generation of communication systems driven by digital humans in virtual reality (VR). The best 3D video-realistic VR avatars that minimize the uncanny effect rely on person-specific (PS) models. However, these PS models are time-consuming to build and are typically trained with limited data variability, which results in poor generalization and robustness. Major sources of variability that affects the accuracy of facial expression transfer algorithms include using different VR headsets (e.g., camera configuration, slop of the headset), facial appearance changes over time (e.g., beard, make-up), and environmental factors (e.g., lighting, backgrounds). This is a major drawback for the scalability of these models in VR. This paper makes progress in overcoming these limitations by proposing an end-to-end multi-identity architecture (MIA) trained with specialized augmentation strategies. MIA drives the shape component of the avatar from three cameras in the VR headset (two eyes, one mouth), in untrained subjects, using minimal personalized information (i.e., neutral 3D mesh shape). Similarly, if the PS texture decoder is available, MIA is able to drive the full avatar (shape+texture) robustly outperforming PS models in challenging scenarios. Our key contribution to improve robustness and generalization, is that our method implicitly decouples, in an unsupervised manner, the facial expression from nuisance factors (e.g., headset, environment, facial appearance). We demonstrate the superior performance and robustness of the proposed method versus state-of-the-art PS approaches in a variety of experiments.
Investigating the Evolvability of Web Page Load Time
Feb 22, 2018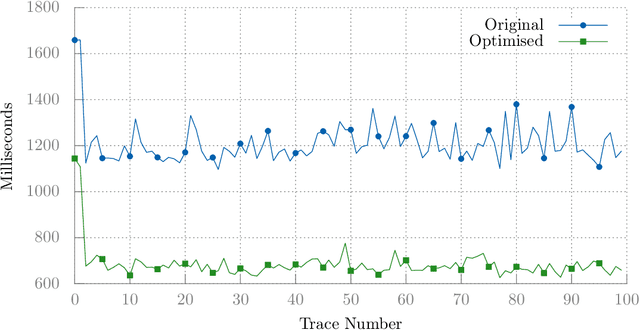
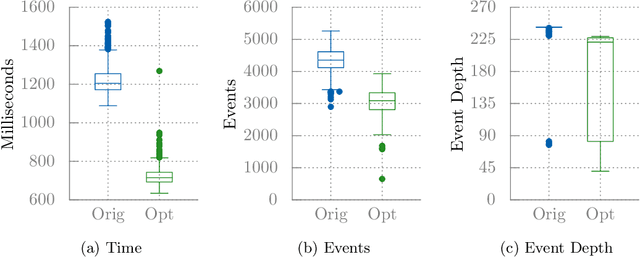
Client-side Javascript execution environments (browsers) allow anonymous functions and event-based programming concepts such as callbacks. We investigate whether a mutate-and-test approach can be used to optimise web page load time in these environments. First, we characterise a web page load issue in a benchmark web page and derive performance metrics from page load event traces. We parse Javascript source code to an AST and make changes to method calls which appear in a web page load event trace. We present an operator based solely on code deletion and evaluate an existing "community-contributed" performance optimising code transform. By exploring Javascript code changes and exploiting combinations of non-destructive changes, we can optimise page load time by 41% in our benchmark web page.
Optimising Resource Management for Embedded Machine Learning
May 08, 2021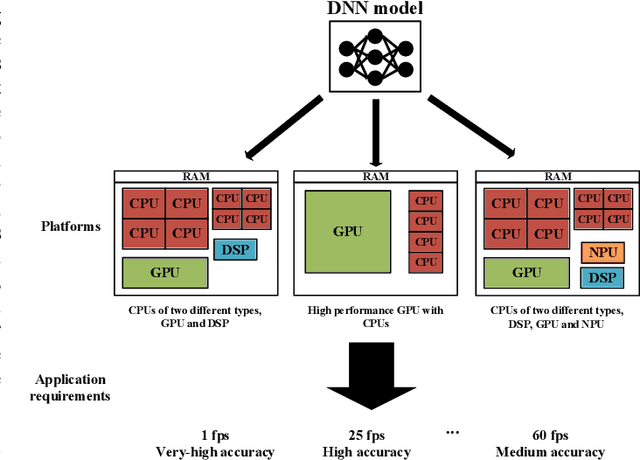
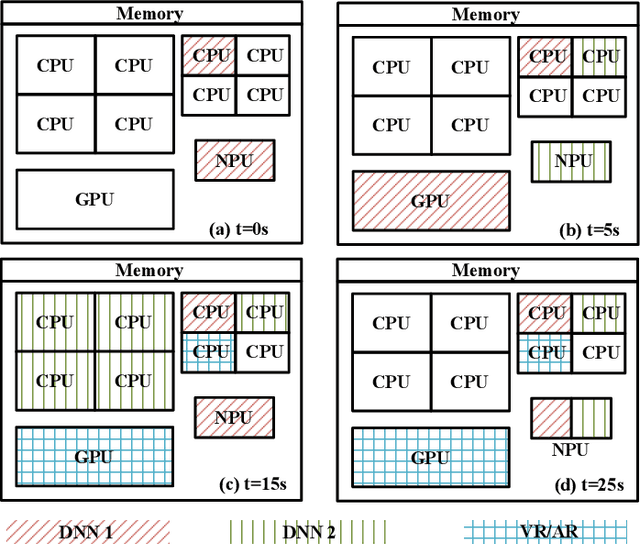
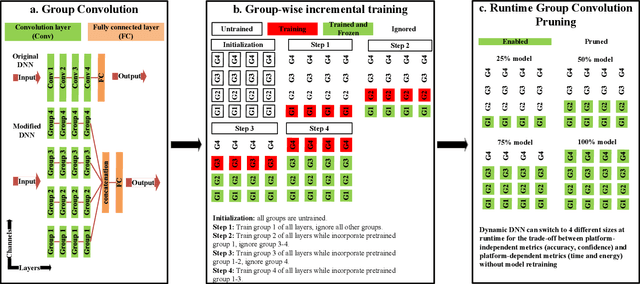
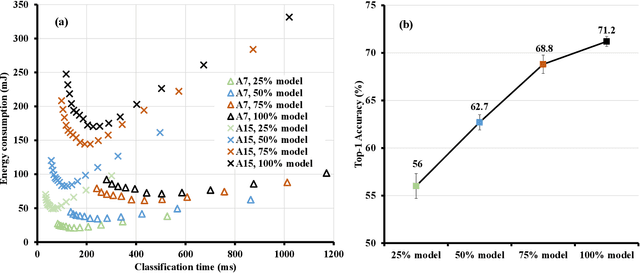
Machine learning inference is increasingly being executed locally on mobile and embedded platforms, due to the clear advantages in latency, privacy and connectivity. In this paper, we present approaches for online resource management in heterogeneous multi-core systems and show how they can be applied to optimise the performance of machine learning workloads. Performance can be defined using platform-dependent (e.g. speed, energy) and platform-independent (accuracy, confidence) metrics. In particular, we show how a Deep Neural Network (DNN) can be dynamically scalable to trade-off these various performance metrics. Achieving consistent performance when executing on different platforms is necessary yet challenging, due to the different resources provided and their capability, and their time-varying availability when executing alongside other workloads. Managing the interface between available hardware resources (often numerous and heterogeneous in nature), software requirements, and user experience is increasingly complex.
Demonstration of Panda: A Weakly Supervised Entity Matching System
Jun 21, 2021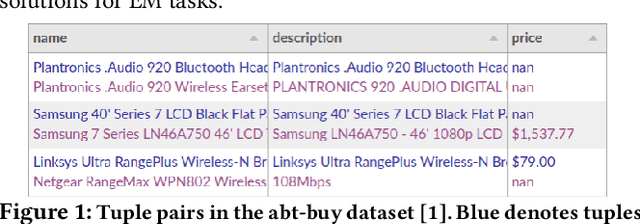

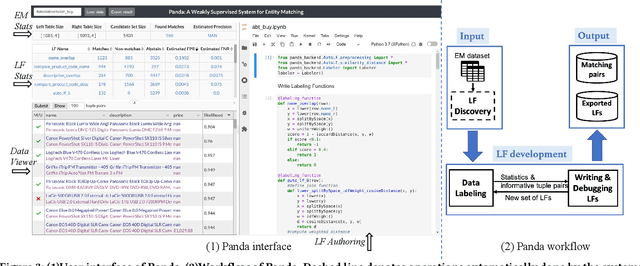
Entity matching (EM) refers to the problem of identifying tuple pairs in one or more relations that refer to the same real world entities. Supervised machine learning (ML) approaches, and deep learning based approaches in particular, typically achieve state-of-the-art matching results. However, these approaches require many labeled examples, in the form of matching and non-matching pairs, which are expensive and time-consuming to label. In this paper, we introduce Panda, a weakly supervised system specifically designed for EM. Panda uses the same labeling function abstraction as Snorkel, where labeling functions (LF) are user-provided programs that can generate large amounts of (somewhat noisy) labels quickly and cheaply, which can then be combined via a labeling model to generate accurate final predictions. To support users developing LFs for EM, Panda provides an integrated development environment (IDE) that lives in a modern browser architecture. Panda's IDE facilitates the development, debugging, and life-cycle management of LFs in the context of EM tasks, similar to how IDEs such as Visual Studio or Eclipse excel in general-purpose programming. Panda's IDE includes many novel features purpose-built for EM, such as smart data sampling, a builtin library of EM utility functions, automatically generated LFs, visual debugging of LFs, and finally, an EM-specific labeling model. We show in this demo that Panda IDE can greatly accelerate the development of high-quality EM solutions using weak supervision.
* video can be found at https://chu-data-lab.cc.gatech.edu/ml-for-data-integration/
Modeling preference time in middle distance triathlons
Jul 03, 2017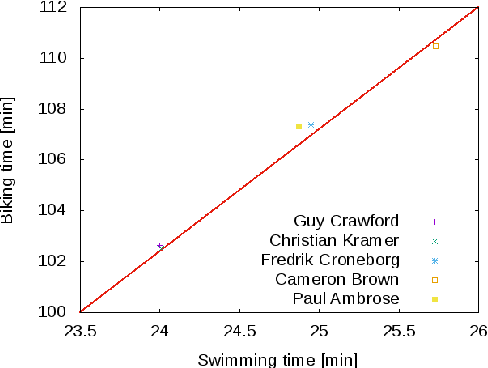
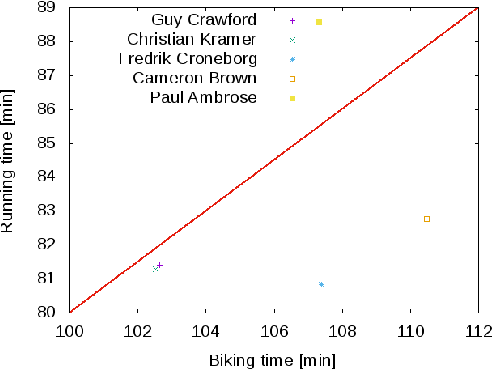
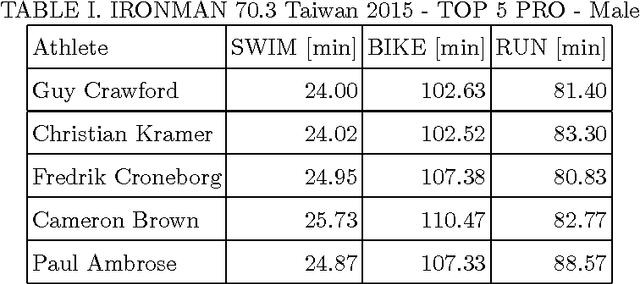

Modeling preference time in triathlons means predicting the intermediate times of particular sports disciplines by a given overall finish time in a specific triathlon course for the athlete with the known personal best result. This is a hard task for athletes and sport trainers due to a lot of different factors that need to be taken into account, e.g., athlete's abilities, health, mental preparations and even their current sports form. So far, this process was calculated manually without any specific software tools or using the artificial intelligence. This paper presents the new solution for modeling preference time in middle distance triathlons based on particle swarm optimization algorithm and archive of existing sports results. Initial results are presented, which suggest the usefulness of proposed approach, while remarks for future improvements and use are also emphasized.
Transform-Based Multilinear Dynamical System for Tensor Time Series Analysis
Nov 18, 2018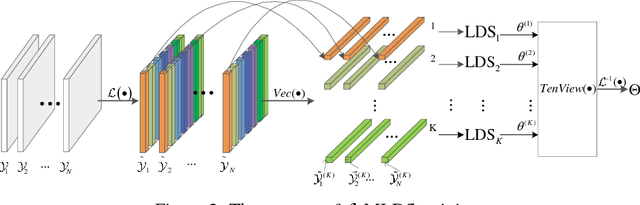
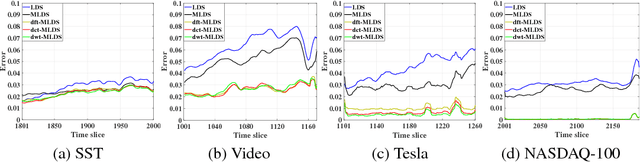
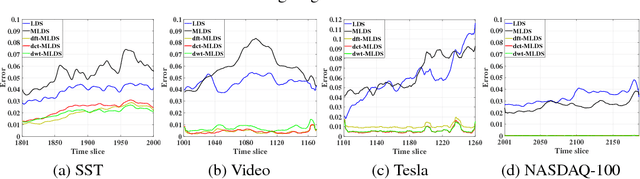
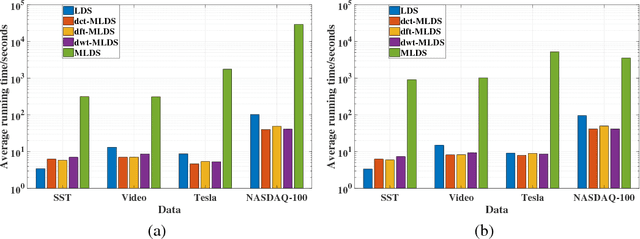
We propose a novel multilinear dynamical system (MLDS) in a transform domain, named $\mathcal{L}$-MLDS, to model tensor time series. With transformations applied to a tensor data, the latent multidimensional correlations among the frontal slices are built, and thus resulting in the computational independence in the transform domain. This allows the exact separability of the multi-dimensional problem into multiple smaller LDS problems. To estimate the system parameters, we utilize the expectation-maximization (EM) algorithm to determine the parameters of each LDS. Further, $\mathcal{L}$-MLDSs significantly reduce the model parameters and allows parallel processing. Our general $\mathcal{L}$-MLDS model is implemented based on different transforms: discrete Fourier transform, discrete cosine transform and discrete wavelet transform. Due to the nonlinearity of these transformations, $\mathcal{L}$-MLDS is able to capture the nonlinear correlations within the data unlike the MLDS \cite{rogers2013multilinear} which assumes multi-way linear correlations. Using four real datasets, the proposed $\mathcal{L}$-MLDS is shown to achieve much higher prediction accuracy than the state-of-the-art MLDS and LDS with an equal number of parameters under different noise models. In particular, the relative errors are reduced by $50\% \sim 99\%$. Simultaneously, $\mathcal{L}$-MLDS achieves an exponential improvement in the model's training time than MLDS.
A Streaming End-to-End Framework For Spoken Language Understanding
Jun 08, 2021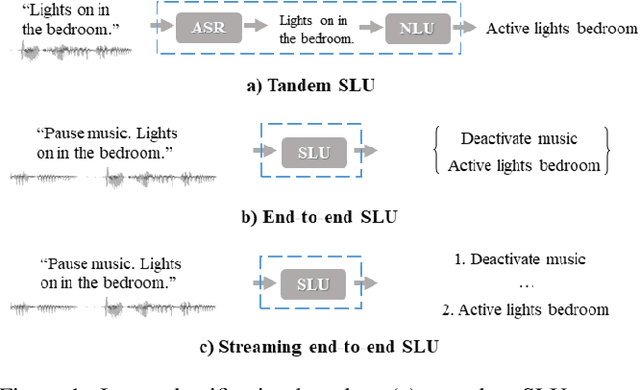
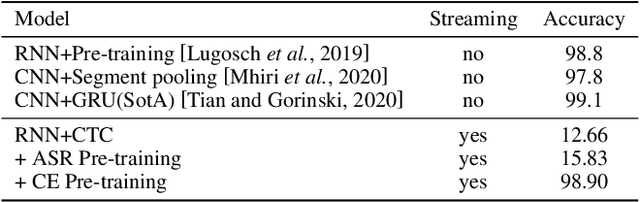
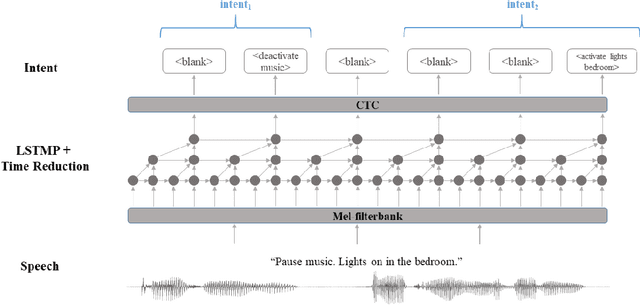

End-to-end spoken language understanding (SLU) has recently attracted increasing interest. Compared to the conventional tandem-based approach that combines speech recognition and language understanding as separate modules, the new approach extracts users' intentions directly from the speech signals, resulting in joint optimization and low latency. Such an approach, however, is typically designed to process one intention at a time, which leads users to take multiple rounds to fulfill their requirements while interacting with a dialogue system. In this paper, we propose a streaming end-to-end framework that can process multiple intentions in an online and incremental way. The backbone of our framework is a unidirectional RNN trained with the connectionist temporal classification (CTC) criterion. By this design, an intention can be identified when sufficient evidence has been accumulated, and multiple intentions can be identified sequentially. We evaluate our solution on the Fluent Speech Commands (FSC) dataset and the intent detection accuracy is about 97 % on all multi-intent settings. This result is comparable to the performance of the state-of-the-art non-streaming models, but is achieved in an online and incremental way. We also employ our model to a keyword spotting task using the Google Speech Commands dataset and the results are also highly promising.