 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Kalman filter-based dynamic state estimation of natural gas pipeline networks
Feb 26, 2021

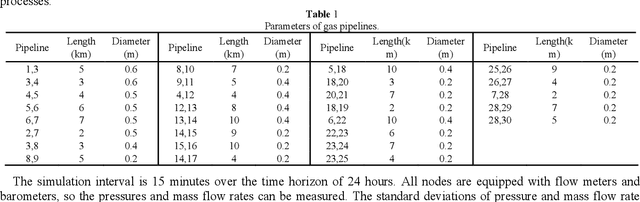
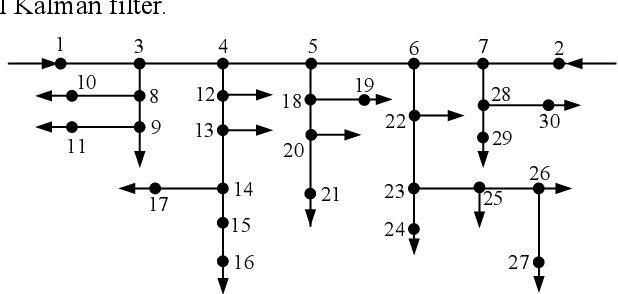
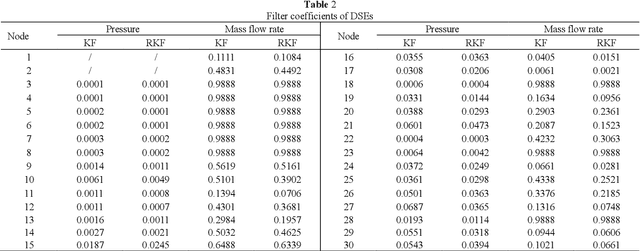
To obtain the accurate transient states of the big scale natural gas pipeline networks under the bad data and non-zero mean noises conditions, a robust Kalman filter-based dynamic state estimation method is proposed using the linearized gas pipeline transient flow equations in this paper. Firstly, the dynamic state estimation model is built. Since the gas pipeline transient flow equations are less than the states, the boundary conditions are used as supplementary constraints to predict the transient states. To increase the measurement redundancy, the zero mass flow rate constraints at the sink nodes are taken as virtual measurements. Secondly, to ensure the stability under bad data condition, the robust Kalman filter algorithm is proposed by introducing a time-varying scalar matrix to regulate the measurement error variances correctly according to the innovation vector at every time step. At last, the proposed method is applied to a 30-node gas pipeline networks in several kinds of measurement conditions. The simulation shows that the proposed robust dynamic state estimation can decrease the effects of bad data and achieve better estimating results.
SoundDet: Polyphonic Sound Event Detection and Localization from Raw Waveform
Jun 13, 2021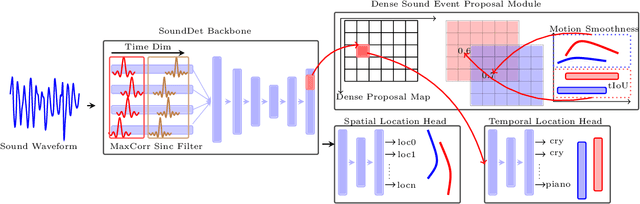
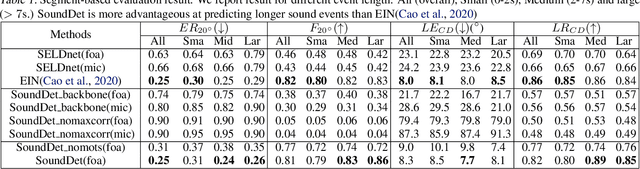
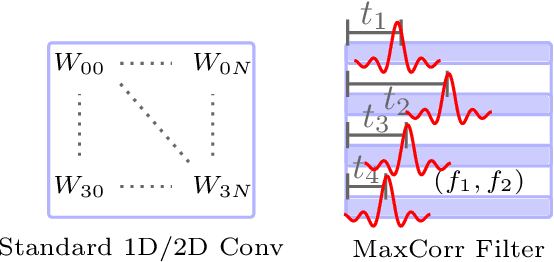
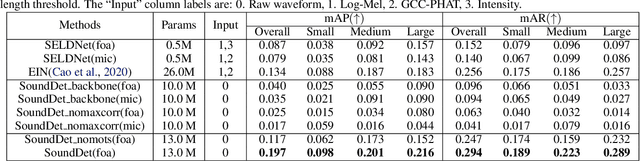
We present a new framework SoundDet, which is an end-to-end trainable and light-weight framework, for polyphonic moving sound event detection and localization. Prior methods typically approach this problem by preprocessing raw waveform into time-frequency representations, which is more amenable to process with well-established image processing pipelines. Prior methods also detect in segment-wise manner, leading to incomplete and partial detections. SoundDet takes a novel approach and directly consumes the raw, multichannel waveform and treats the spatio-temporal sound event as a complete ``sound-object" to be detected. Specifically, SoundDet consists of a backbone neural network and two parallel heads for temporal detection and spatial localization, respectively. Given the large sampling rate of raw waveform, the backbone network first learns a set of phase-sensitive and frequency-selective bank of filters to explicitly retain direction-of-arrival information, whilst being highly computationally and parametrically efficient than standard 1D/2D convolution. A dense sound event proposal map is then constructed to handle the challenges of predicting events with large varying temporal duration. Accompanying the dense proposal map are a temporal overlapness map and a motion smoothness map that measure a proposal's confidence to be an event from temporal detection accuracy and movement consistency perspective. Involving the two maps guarantees SoundDet to be trained in a spatio-temporally unified manner. Experimental results on the public DCASE dataset show the advantage of SoundDet on both segment-based and our newly proposed event-based evaluation system.
Fully General Online Imitation Learning
Feb 17, 2021

In imitation learning, imitators and demonstrators are policies for picking actions given past interactions with the environment. If we run an imitator, we probably want events to unfold similarly to the way they would have if the demonstrator had been acting the whole time. No existing work provides formal guidance in how this might be accomplished, instead restricting focus to environments that restart, making learning unusually easy, and conveniently limiting the significance of any mistake. We address a fully general setting, in which the (stochastic) environment and demonstrator never reset, not even for training purposes. Our new conservative Bayesian imitation learner underestimates the probabilities of each available action, and queries for more data with the remaining probability. Our main result: if an event would have been unlikely had the demonstrator acted the whole time, that event's likelihood can be bounded above when running the (initially totally ignorant) imitator instead. Meanwhile, queries to the demonstrator rapidly diminish in frequency.
Itsy Bitsy SpiderNet: Fully Connected Residual Network for Fraud Detection
May 17, 2021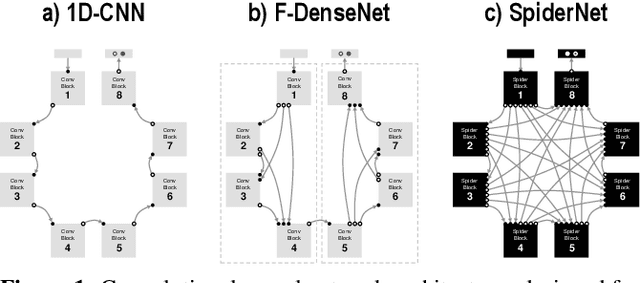
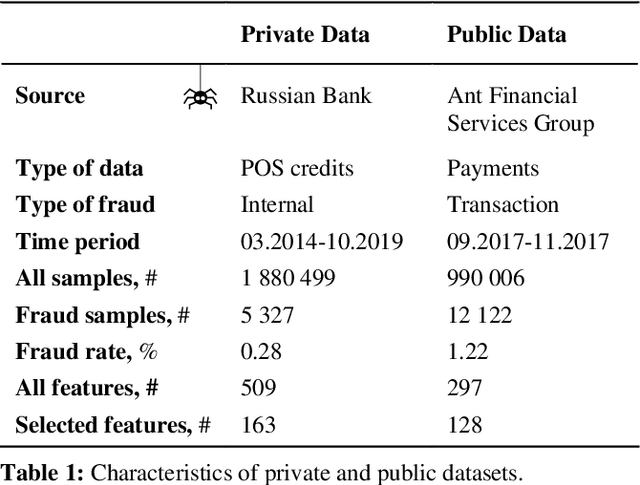
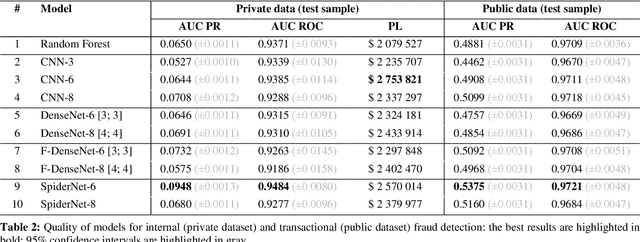
With the development of high technology, the scope of fraud is increasing, resulting in annual losses of billions of dollars worldwide. The preventive protection measures become obsolete and vulnerable over time, so effective detective tools are needed. In this paper, we propose a convolutional neural network architecture SpiderNet designed to solve fraud detection problems. We noticed that the principles of pooling and convolutional layers in neural networks are very similar to the way antifraud analysts work when conducting investigations. Moreover, the skip-connections used in neural networks make the usage of features of various power in antifraud models possible. Our experiments have shown that SpiderNet provides better quality compared to Random Forest and adapted for antifraud modeling problems 1D-CNN, 1D-DenseNet, F-DenseNet neural networks. We also propose new approaches for fraud feature engineering called B-tests and W-tests, which generalize the concepts of Benford's Law for fraud anomalies detection. Our results showed that B-tests and W-tests give a significant increase to the quality of our antifraud models. The SpiderNet code is available at https://github.com/aasmirnova24/SpiderNet
Towards Speeding up Adversarial Training in Latent Spaces
Feb 01, 2021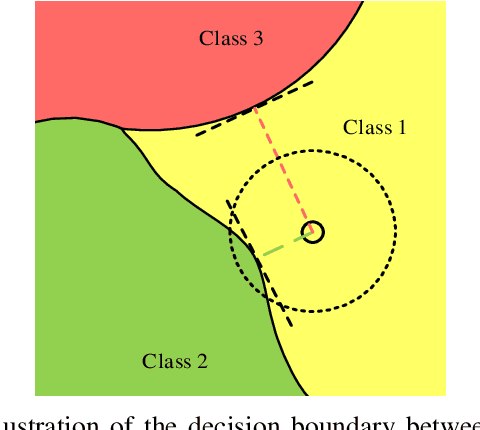
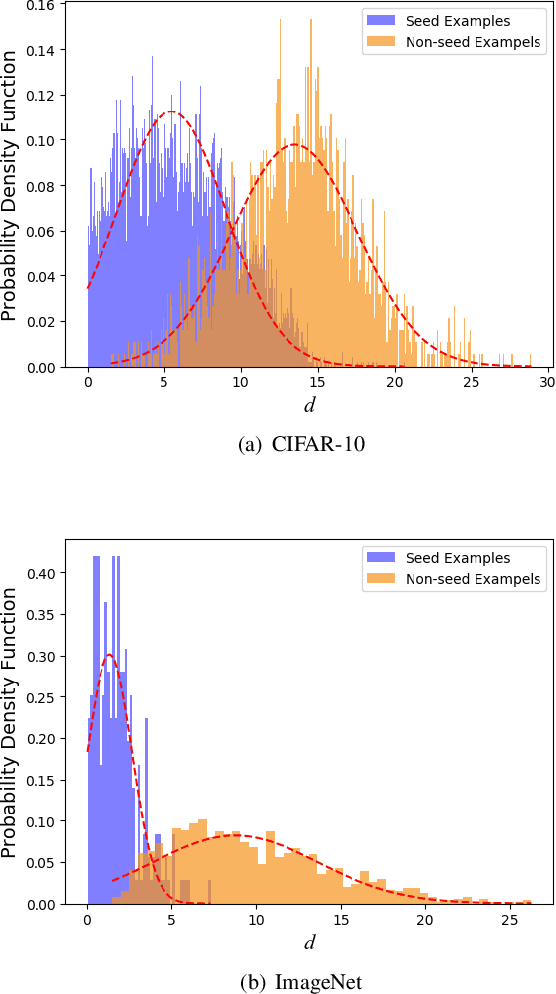
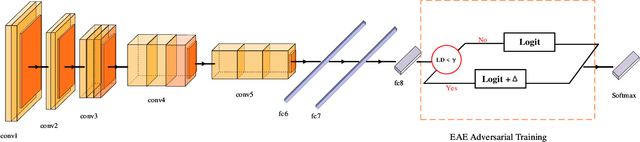
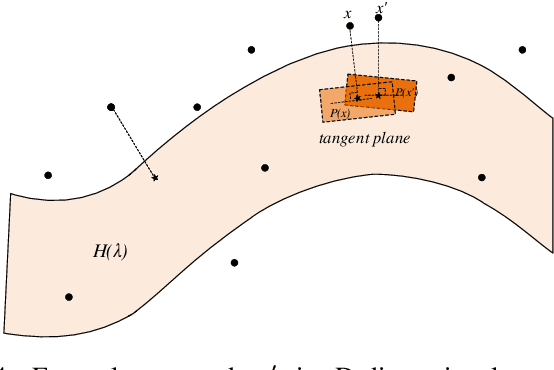
Adversarial training is wildly considered as the most effective way to defend against adversarial examples. However, existing adversarial training methods consume unbearable time cost, since they need to generate adversarial examples in the input space, which accounts for the main part of total time-consuming. For speeding up the training process, we propose a novel adversarial training method that does not need to generate real adversarial examples. We notice that a clean example is closer to the decision boundary of the class with the second largest logit component than any other class besides its own class. Thus, by adding perturbations to logits to generate Endogenous Adversarial Examples(EAEs) -- adversarial examples in the latent space, it can avoid calculating gradients to speed up the training process. We further gain a deep insight into the existence of EAEs by the theory of manifold. To guarantee the added perturbation is within the range of constraint, we use statistical distributions to select seed examples to craft EAEs. Extensive experiments are conducted on CIFAR-10 and ImageNet, and the results show that compare with state-of-the-art "Free" and "Fast" methods, our EAE adversarial training not only shortens the training time, but also enhances the robustness of the model. Moreover, the EAE adversarial training has little impact on the accuracy of clean examples than the existing methods.
Understanding Team Collaboration in Artificial Intelligence from the perspective of Geographic Distance
Dec 25, 2020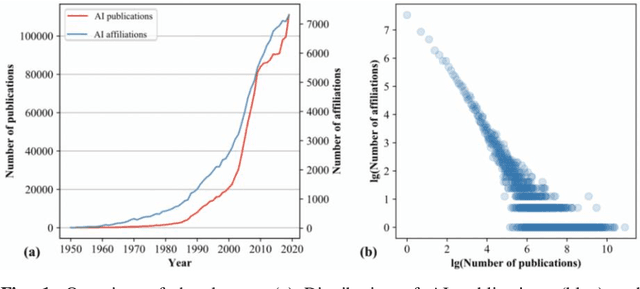
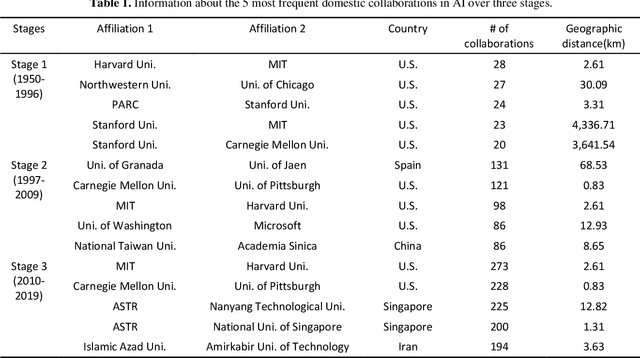
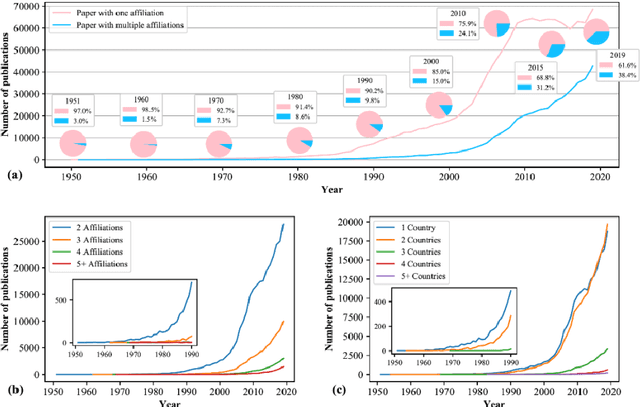

This paper analyzes team collaboration in the field of Artificial Intelligence (AI) from the perspective of geographic distance. We obtained 1,584,175 AI related publications during 1950-2019 from the Microsoft Academic Graph. Three latitude-and-longitude-based indicators were employed to quantify the geographic distance of collaborations in AI over time at domestic and international levels. The results show team collaborations in AI has been more popular in the field over time with around 42,000 (38.4%) multiple-affiliation AI publications in 2019. The changes in geographic distances of team collaborations indicate the increase of breadth and density for both domestic and international collaborations in AI over time. In addition, the United States produced the largest number of single-country and internationally collaborated AI publications, and China has played an important role in international collaborations in AI after 2010.
Neural News Recommendation with Negative Feedback
Jan 12, 2021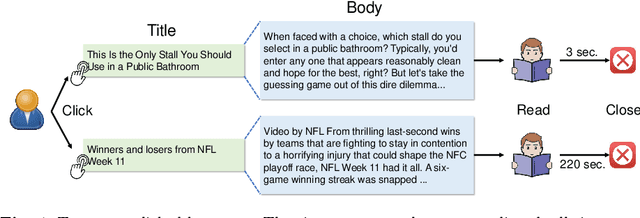

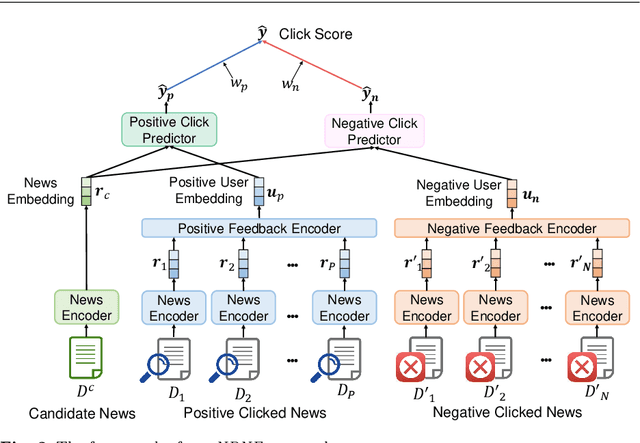
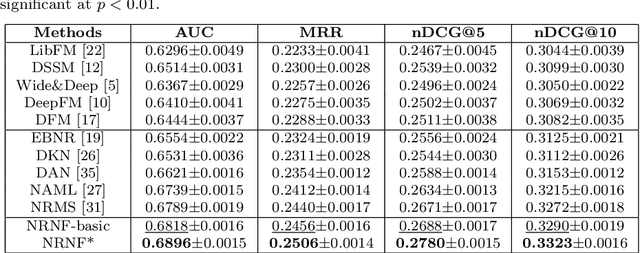
News recommendation is important for online news services. Precise user interest modeling is critical for personalized news recommendation. Existing news recommendation methods usually rely on the implicit feedback of users like news clicks to model user interest. However, news click may not necessarily reflect user interests because users may click a news due to the attraction of its title but feel disappointed at its content. The dwell time of news reading is an important clue for user interest modeling, since short reading dwell time usually indicates low and even negative interest. Thus, incorporating the negative feedback inferred from the dwell time of news reading can improve the quality of user modeling. In this paper, we propose a neural news recommendation approach which can incorporate the implicit negative user feedback. We propose to distinguish positive and negative news clicks according to their reading dwell time, and respectively learn user representations from positive and negative news clicks via a combination of Transformer and additive attention network. In addition, we propose to compute a positive click score and a negative click score based on the relevance between candidate news representations and the user representations learned from the positive and negative news clicks. The final click score is a combination of positive and negative click scores. Besides, we propose an interactive news modeling method to consider the relatedness between title and body in news modeling. Extensive experiments on real-world dataset validate that our approach can achieve more accurate user interest modeling for news recommendation.
Coordinated Motion Planning Through Randomized k-Opt
Mar 28, 2021
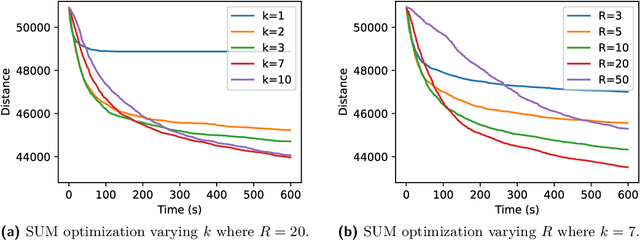
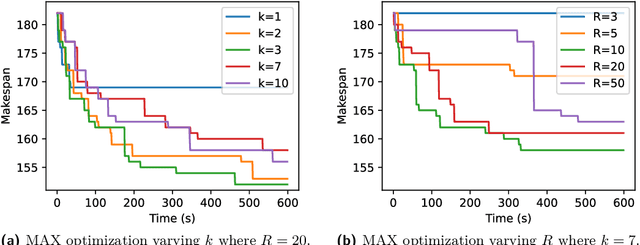
This paper examines the approach taken by team gitastrophe in the CG:SHOP 2021 challenge. The challenge was to find a sequence of simultaneous moves of square robots between two given configurations that minimized either total distance travelled or makespan (total time). Our winning approach has two main components: an initialization phase that finds a good initial solution, and a $k$-opt local search phase which optimizes this solution. This led to a first place finish in the distance category and a third place finish in the makespan category.
Simultaneous Scene Reconstruction and Whole-Body Motion Planning for Safe Operation in Dynamic Environments
Mar 05, 2021
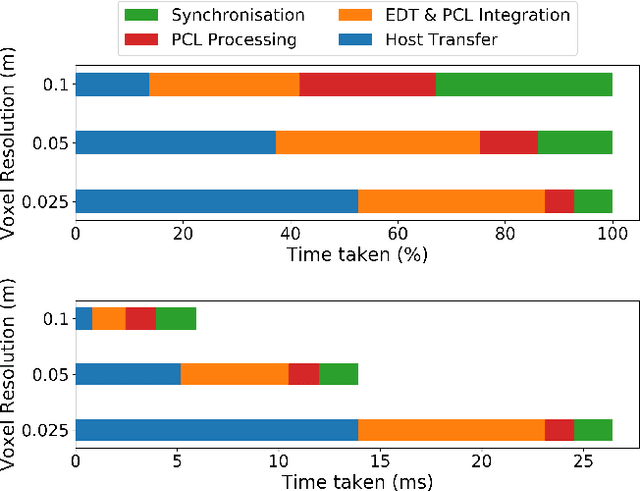

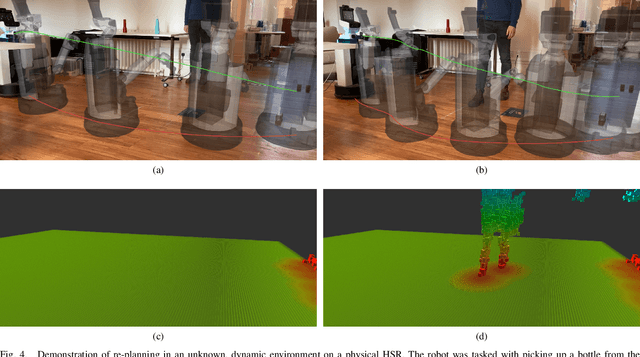
Recent work has demonstrated real-time mapping and reconstruction from dense perception, while motion planning based on distance fields has been shown to achieve fast, collision-free motion synthesis with good convergence properties. However, demonstration of a fully integrated system that can safely re-plan in unknown environments, in the presence of static and dynamic obstacles, has remained an open challenge. In this work, we first study the impact that signed and unsigned distance fields have on optimisation convergence, and the resultant error cost in trajectory optimisation problems in 2D path planning, arm manipulator motion planning, and whole-body loco-manipulation planning. We further analyse the performance of three state-of-the-art approaches to generating distance fields (Voxblox, Fiesta, and GPU-Voxels) for use in real-time environment reconstruction. Finally, we use our findings to construct a practical hybrid mapping and motion planning system which uses GPU-Voxels and GPMP2 to perform receding-horizon whole-body motion planning that can smoothly avoid moving obstacles in 3D space using live sensor data. Our results are validated in simulation and on a real-world Toyota Human Support Robot (HSR).
Comparing Representations in Tracking for Event Camera-based SLAM
Apr 20, 2021
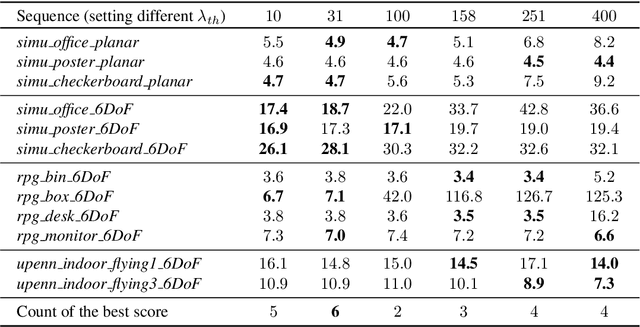

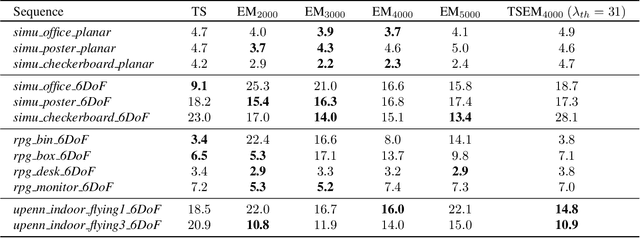
This paper investigates two typical image-type representations for event camera-based tracking: time surface (TS) and event map (EM). Based on the original TS-based tracker, we make use of these two representations' complementary strengths to develop an enhanced version. The proposed tracker consists of a general strategy to evaluate the optimization problem's degeneracy online and then switch proper representations. Both TS and EM are motion- and scene-dependent, and thus it is important to figure out their limitations in tracking. We develop six tracker variations and conduct a thorough comparison of them on sequences covering various scenarios and motion complexities. We release our implementations and detailed results to benefit the research community on event cameras: https: //github.com/gogojjh/ESVO_extension.