 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Satellite- and Cache-assisted UAV: A Joint Cache Placement, Resource Allocation, and Trajectory Optimization for 6G Aerial Networks
Jun 09, 2021
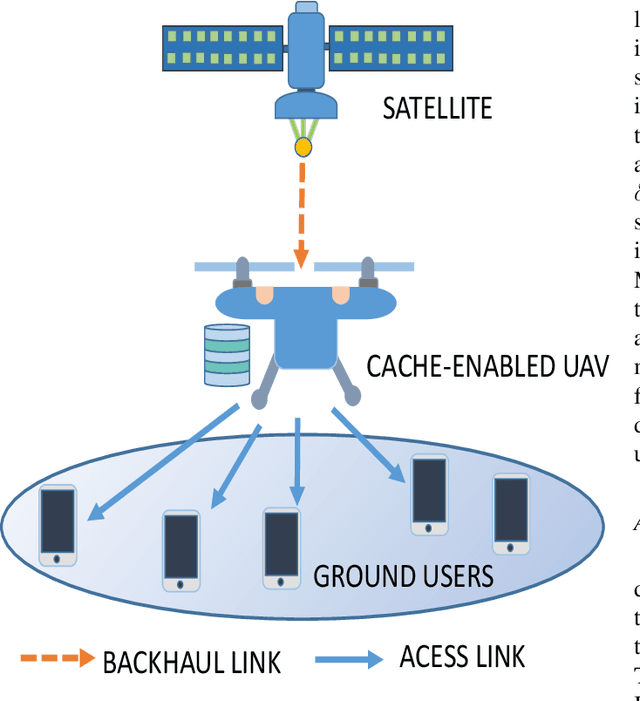
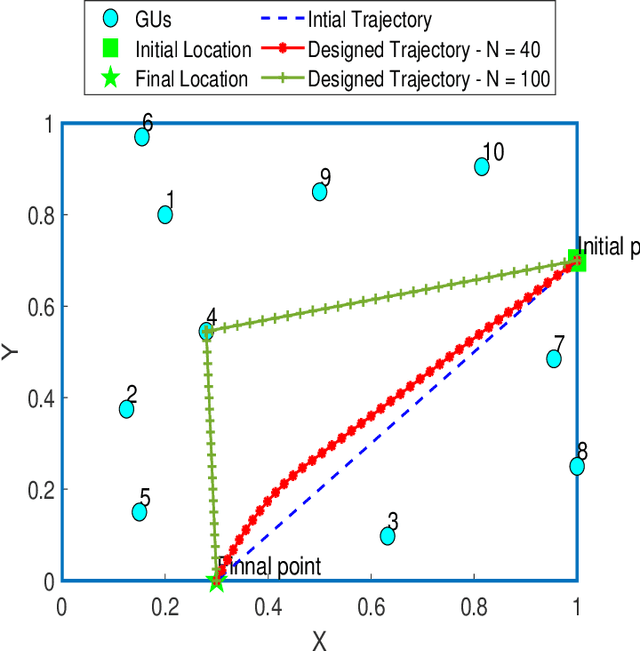
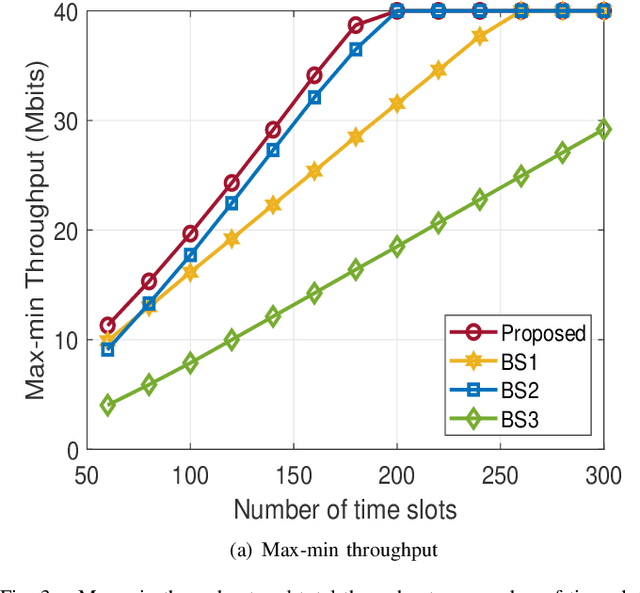
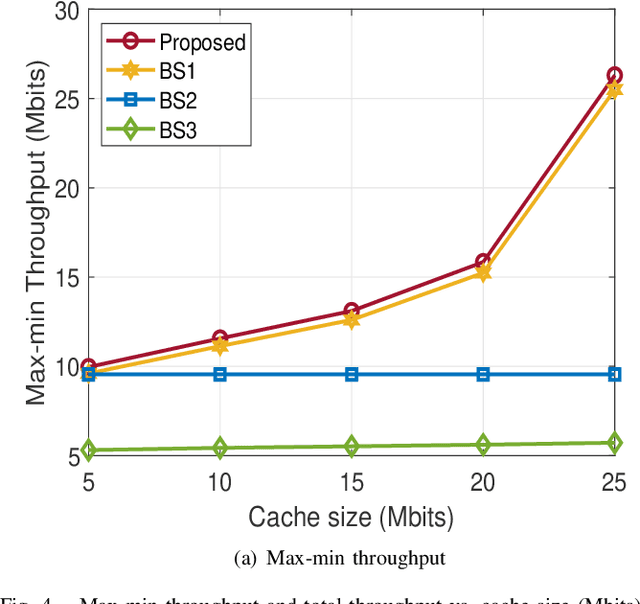
This paper considers LEO satellite- and cache-assisted UAV communications for content delivery in terrestrial networks, which shows great potential for next-generation systems to provide ubiquitous connectivity and high capacity. Specifically, caching is provided by the UAV to reduce backhaul congestion, and the LEO satellite supports the UAV's backhaul link. In this context, we aim to maximize the minimum achievable throughput per ground user (GU) by jointly optimizing cache placement, the UAV's resource allocation, and trajectory while cache capacity and flight time are limited. The formulated problem is challenging to solve directly due to its non-convexity and combinatorial nature. To find a solution, the problem is decomposed into three sub-problems: (1) cache placement optimization with fixed UAV resources and trajectory, followed by (2) the UAV resources optimization with fixed cache placement vector and trajectory, and finally, (3) we optimize the UAV trajectory with fixed cache placement and UAV resources. Based on the solutions of sub-problems, an efficient alternating algorithm is proposed utilizing the block coordinate descent (BCD) and successive convex approximation (SCA) methods. Simulation results show that the max-min throughput and total achievable throughput enhancement can be achieved by applying our proposed algorithm instead of other benchmark schemes.
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
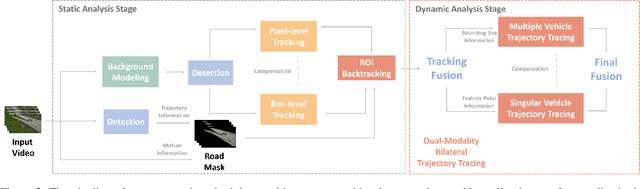
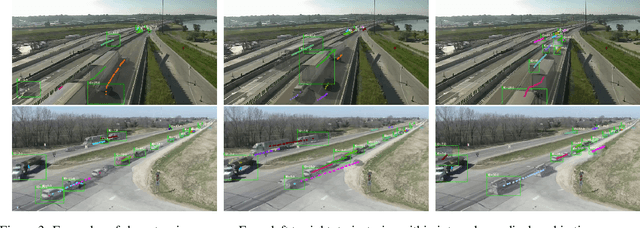
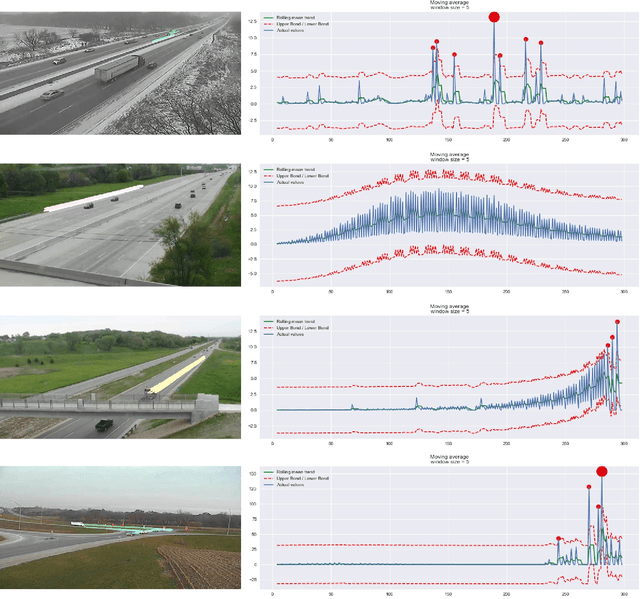
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.
Ground Encoding: Learned Factor Graph-based Models for Localizing Ground Penetrating Radar
Mar 29, 2021

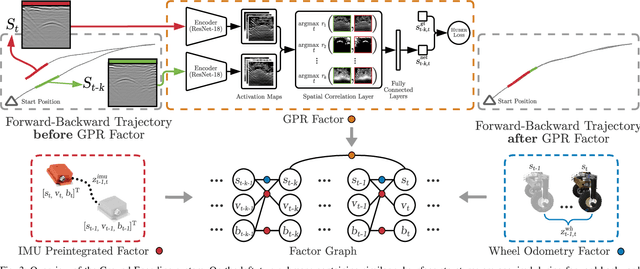

We address the problem of robot localization using ground penetrating radar (GPR) sensors. Current approaches for localization with GPR sensors require a priori maps of the system's environment as well as access to approximate global positioning (GPS) during operation. In this paper, we propose a novel, real-time GPR-based localization system for unknown and GPS-denied environments. We model the localization problem as an inference over a factor graph. Our approach combines 1D single-channel GPR measurements to form 2D image submaps. To use these GPR images in the graph, we need sensor models that can map noisy, high-dimensional image measurements into the state space. These are challenging to obtain a priori since image generation has a complex dependency on subsurface composition and radar physics, which itself varies with sensors and variations in subsurface electromagnetic properties. Our key idea is to instead learn relative sensor models directly from GPR data that map non-sequential GPR image pairs to relative robot motion. These models are incorporated as factors within the factor graph with relative motion predictions correcting for accumulated drift in the position estimates. We demonstrate our approach over datasets collected across multiple locations using a custom designed experimental rig. We show reliable, real-time localization using only GPR and odometry measurements for varying trajectories in three distinct GPS-denied environments. For our supplementary video, see https://youtu.be/HXXgdTJzqyw.
Cardiac Functional Analysis with Cine MRI via Deep Learning Reconstruction
May 17, 2021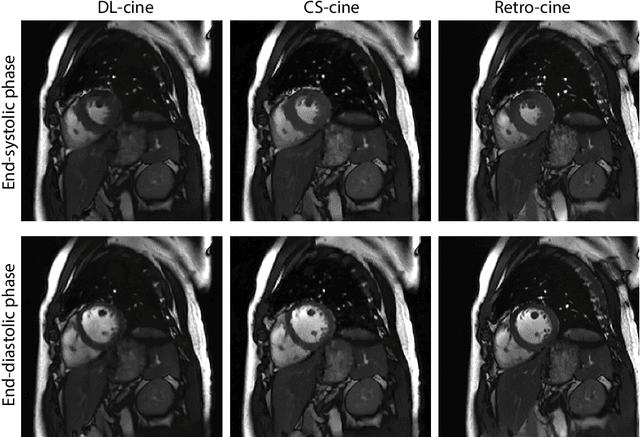
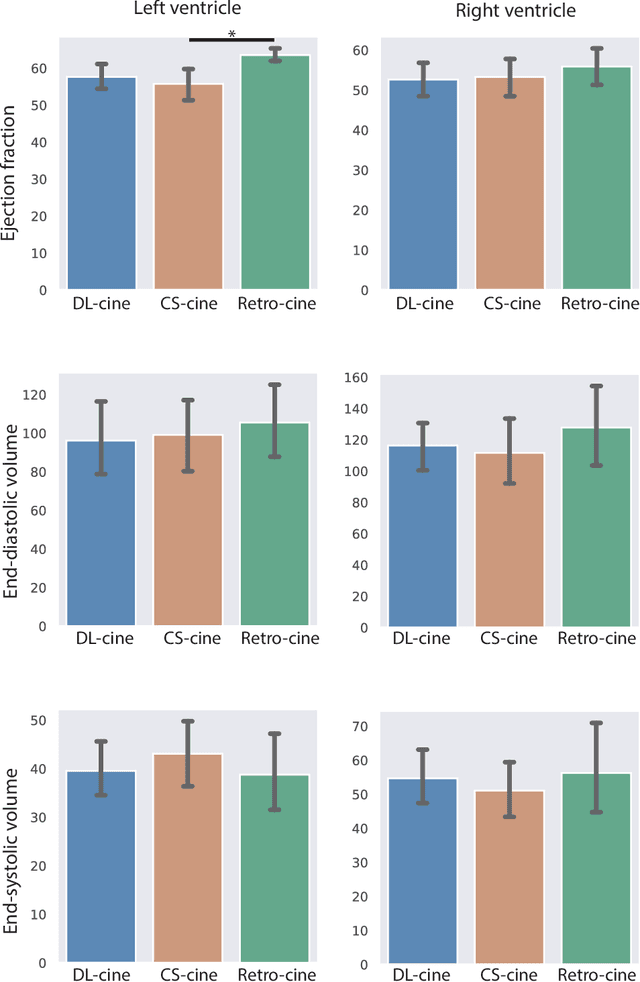
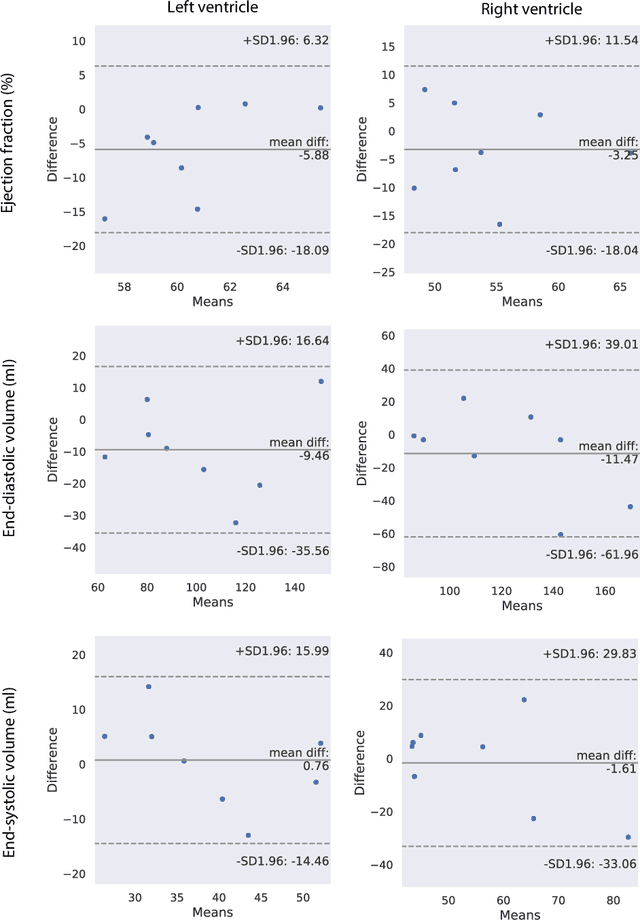
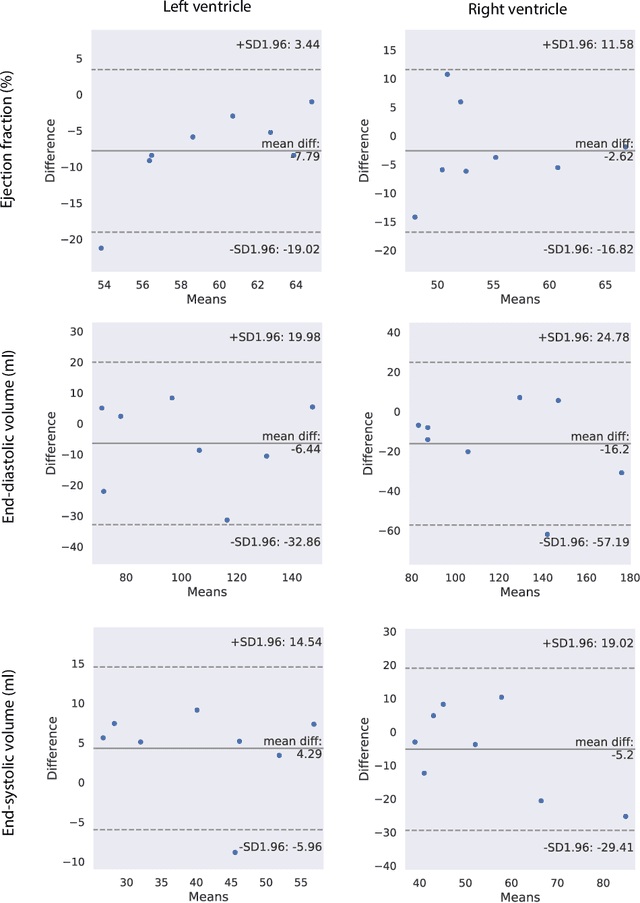
Retrospectively gated cine (retro-cine) MRI is the clinical standard for cardiac functional analysis. Deep learning (DL) based methods have been proposed for the reconstruction of highly undersampled MRI data and show superior image quality and magnitude faster reconstruction time than CS-based methods. Nevertheless, it remains unclear whether DL reconstruction is suitable for cardiac function analysis. To address this question, in this study we evaluate and compare the cardiac functional values (EDV, ESV and EF for LV and RV, respectively) obtained from highly accelerated MRI acquisition using DL based reconstruction algorithm (DL-cine) with values from CS-cine and conventional retro-cine. To the best of our knowledge, this is the first work to evaluate the cine MRI with deep learning reconstruction for cardiac function analysis and compare it with other conventional methods. The cardiac functional values obtained from cine MRI with deep learning reconstruction are consistent with values from clinical standard retro-cine MRI.
Scaling the Convex Barrier with Sparse Dual Algorithms
Jan 26, 2021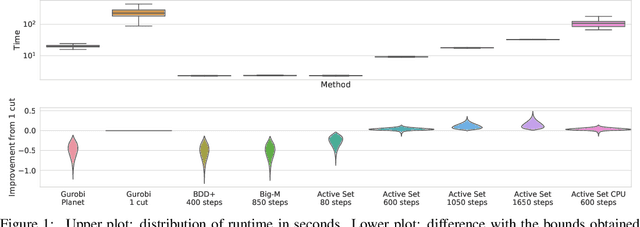
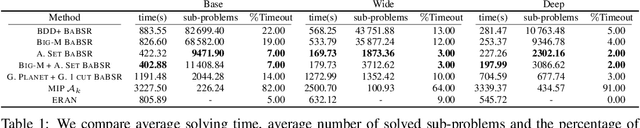
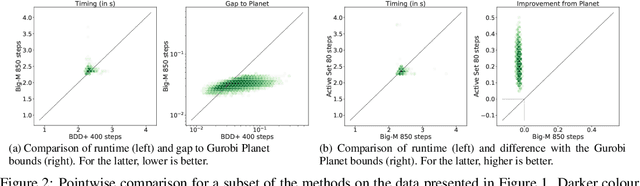
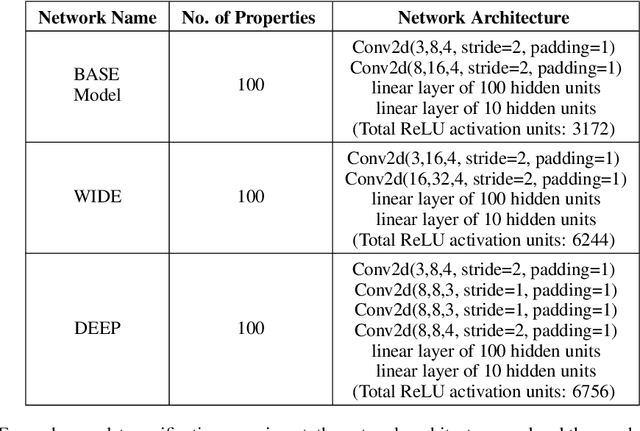
Tight and efficient neural network bounding is crucial to the scaling of neural network verification systems. Many efficient bounding algorithms have been presented recently, but they are often too loose to verify more challenging properties. This is due to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise-linear activations exists, it comes at the cost of exponentially many constraints and currently lacks an efficient customized solver. We alleviate this deficiency by presenting two novel dual algorithms: one operates a subgradient method on a small active set of dual variables, the other exploits the sparsity of Frank-Wolfe type optimizers to incur only a linear memory cost. Both methods recover the strengths of the new relaxation: tightness and a linear separation oracle. At the same time, they share the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we can obtain better bounds than off-the-shelf solvers in only a fraction of their running time, attaining significant formal verification speed-ups.
Information Avoidance and Overvaluation in Sequential Decision Making under Epistemic Constraints
Jun 09, 2021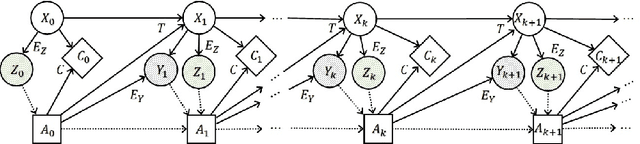
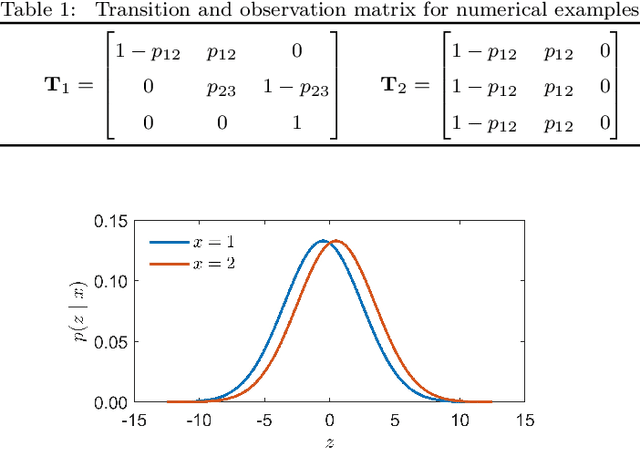
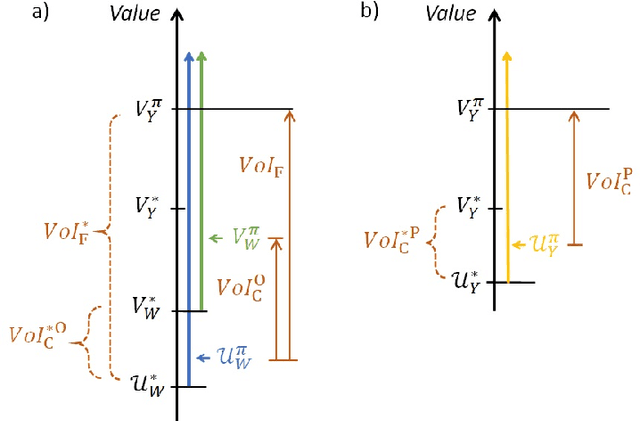
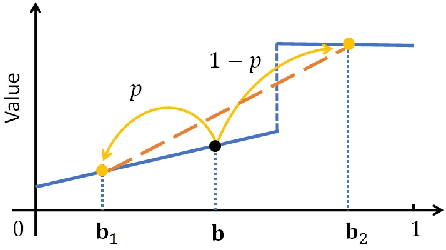
Decision makers involved in the management of civil assets and systems usually take actions under constraints imposed by societal regulations. Some of these constraints are related to epistemic quantities, as the probability of failure events and the corresponding risks. Sensors and inspectors can provide useful information supporting the control process (e.g. the maintenance process of an asset), and decisions about collecting this information should rely on an analysis of its cost and value. When societal regulations encode an economic perspective that is not aligned with that of the decision makers, the Value of Information (VoI) can be negative (i.e., information sometimes hurts), and almost irrelevant information can even have a significant value (either positive or negative), for agents acting under these epistemic constraints. We refer to these phenomena as Information Avoidance (IA) and Information OverValuation (IOV). In this paper, we illustrate how to assess VoI in sequential decision making under epistemic constraints (as those imposed by societal regulations), by modeling a Partially Observable Markov Decision Processes (POMDP) and evaluating non optimal policies via Finite State Controllers (FSCs). We focus on the value of collecting information at current time, and on that of collecting sequential information, we illustrate how these values are related and we discuss how IA and IOV can occur in those settings.
Learning Image Attacks toward Vision Guided Autonomous Vehicles
May 17, 2021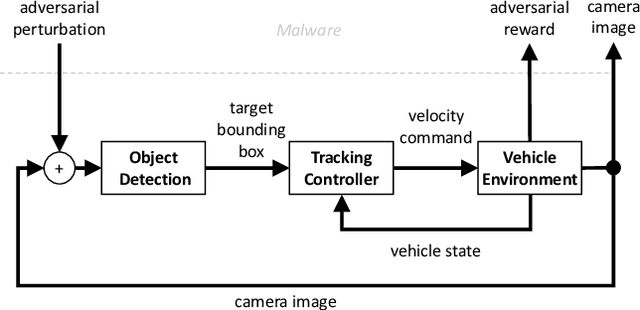

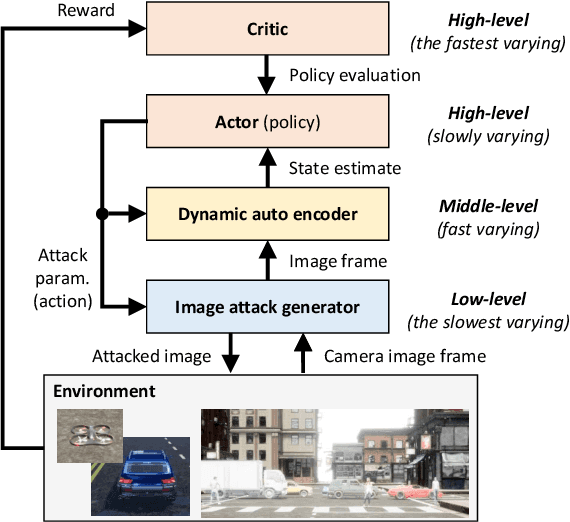

While adversarial neural networks have been shown successful for static image attacks, very few approaches have been developed for attacking online image streams while taking into account the underlying physical dynamics of autonomous vehicles, their mission, and environment. This paper presents an online adversarial machine learning framework that can effectively misguide autonomous vehicles' missions. In the existing image attack methods devised toward autonomous vehicles, optimization steps are repeated for every image frame. This framework removes the need for fully converged optimization at every frame to realize image attacks in real-time. Using reinforcement learning, a generative neural network is trained over a set of image frames to obtain an attack policy that is more robust to dynamic and uncertain environments. A state estimator is introduced for processing image streams to reduce the attack policy's sensitivity to physical variables such as unknown position and velocity. A simulation study is provided to validate the results.
Adversarial Attacks on Deep Models for Financial Transaction Records
Jun 15, 2021
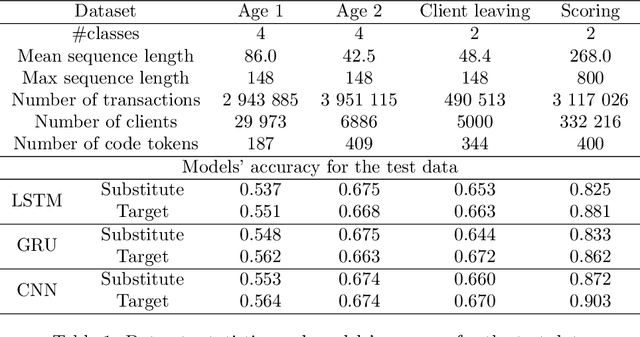
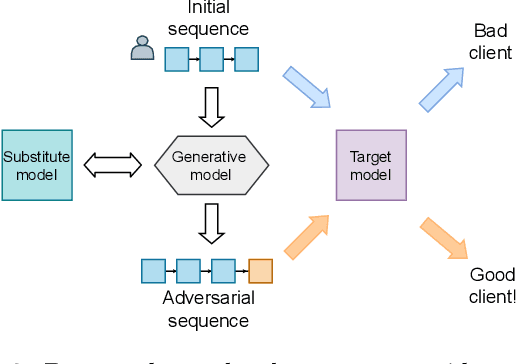
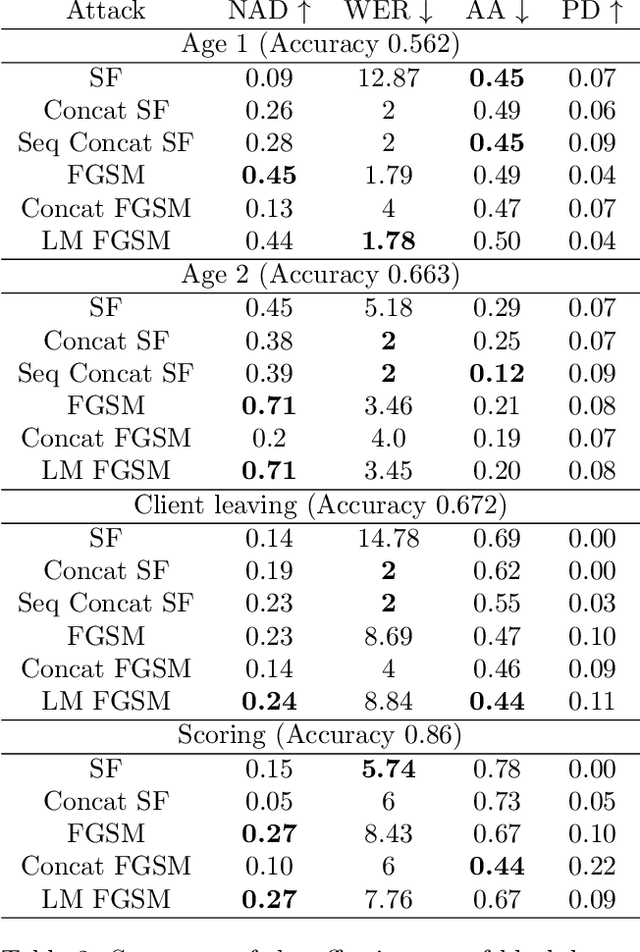
Machine learning models using transaction records as inputs are popular among financial institutions. The most efficient models use deep-learning architectures similar to those in the NLP community, posing a challenge due to their tremendous number of parameters and limited robustness. In particular, deep-learning models are vulnerable to adversarial attacks: a little change in the input harms the model's output. In this work, we examine adversarial attacks on transaction records data and defences from these attacks. The transaction records data have a different structure than the canonical NLP or time series data, as neighbouring records are less connected than words in sentences, and each record consists of both discrete merchant code and continuous transaction amount. We consider a black-box attack scenario, where the attack doesn't know the true decision model, and pay special attention to adding transaction tokens to the end of a sequence. These limitations provide more realistic scenario, previously unexplored in NLP world. The proposed adversarial attacks and the respective defences demonstrate remarkable performance using relevant datasets from the financial industry. Our results show that a couple of generated transactions are sufficient to fool a deep-learning model. Further, we improve model robustness via adversarial training or separate adversarial examples detection. This work shows that embedding protection from adversarial attacks improves model robustness, allowing a wider adoption of deep models for transaction records in banking and finance.
Learning to Rehearse in Long Sequence Memorization
Jun 02, 2021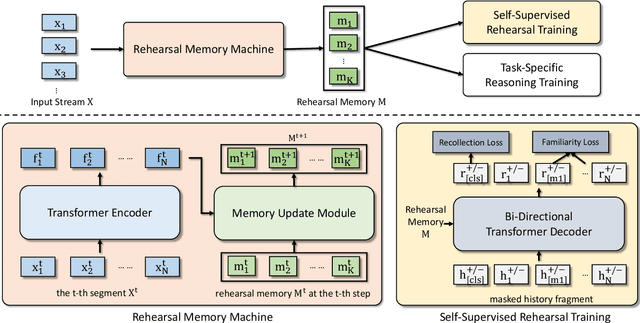
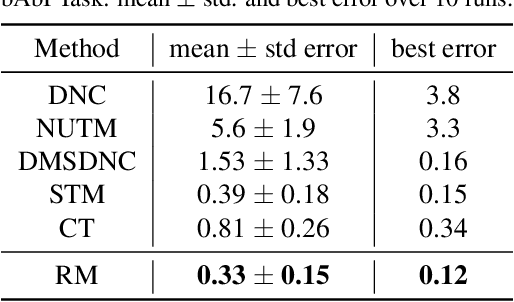
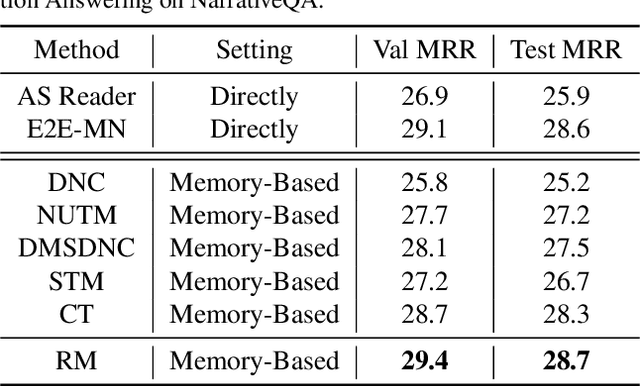
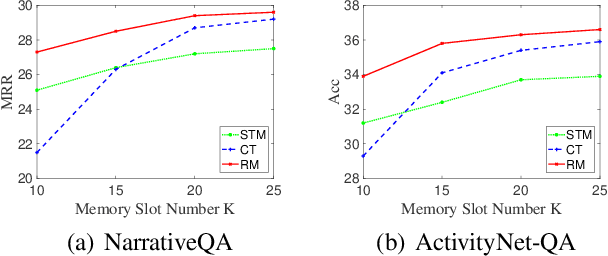
Existing reasoning tasks often have an important assumption that the input contents can be always accessed while reasoning, requiring unlimited storage resources and suffering from severe time delay on long sequences. To achieve efficient reasoning on long sequences with limited storage resources, memory augmented neural networks introduce a human-like write-read memory to compress and memorize the long input sequence in one pass, trying to answer subsequent queries only based on the memory. But they have two serious drawbacks: 1) they continually update the memory from current information and inevitably forget the early contents; 2) they do not distinguish what information is important and treat all contents equally. In this paper, we propose the Rehearsal Memory (RM) to enhance long-sequence memorization by self-supervised rehearsal with a history sampler. To alleviate the gradual forgetting of early information, we design self-supervised rehearsal training with recollection and familiarity tasks. Further, we design a history sampler to select informative fragments for rehearsal training, making the memory focus on the crucial information. We evaluate the performance of our rehearsal memory by the synthetic bAbI task and several downstream tasks, including text/video question answering and recommendation on long sequences.
An SDE Framework for Adversarial Training, with Convergence and Robustness Analysis
May 17, 2021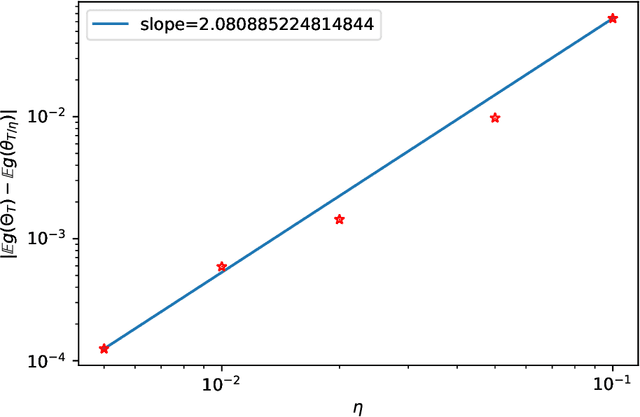
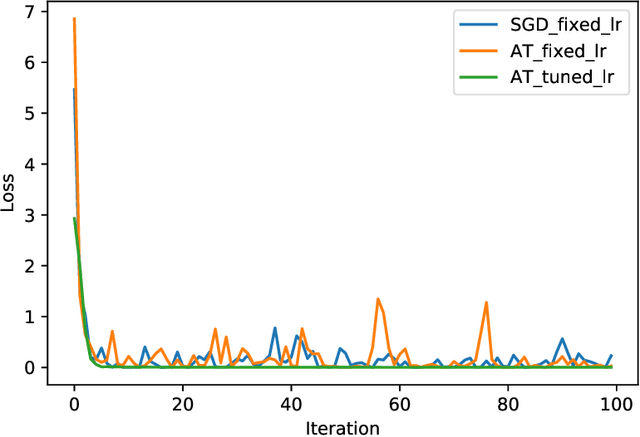
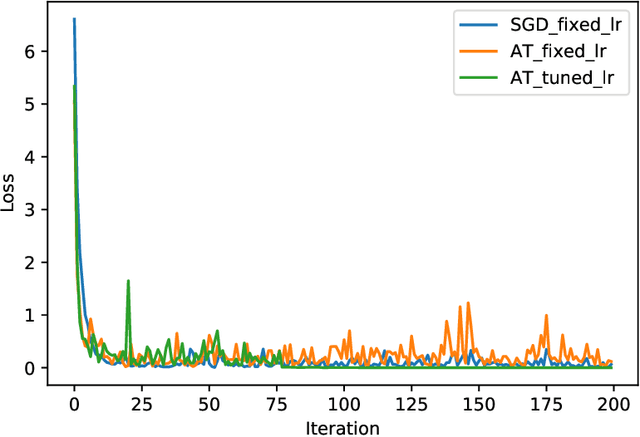
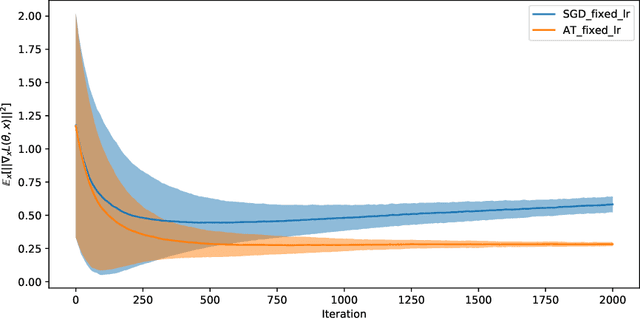
Adversarial training has gained great popularity as one of the most effective defenses for deep neural networks against adversarial perturbations on data points. Consequently, research interests have grown in understanding the convergence and robustness of adversarial training. This paper considers the min-max game of adversarial training by alternating stochastic gradient descent. It approximates the training process with a continuous-time stochastic-differential-equation (SDE). In particular, the error bound and convergence analysis is established. This SDE framework allows direct comparison between adversarial training and stochastic gradient descent; and confirms analytically the robustness of adversarial training from a (new) gradient-flow viewpoint. This analysis is then corroborated via numerical studies. To demonstrate the versatility of this SDE framework for algorithm design and parameter tuning, a stochastic control problem is formulated for learning rate adjustment, where the advantage of adaptive learning rate over fixed learning rate in terms of training loss is demonstrated through numerical experiments.