 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Repulsive Prototypes for Adversarial Robustness
May 26, 2021
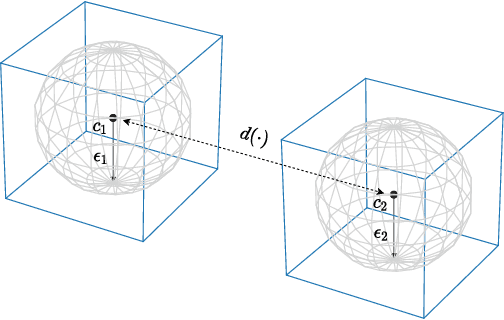
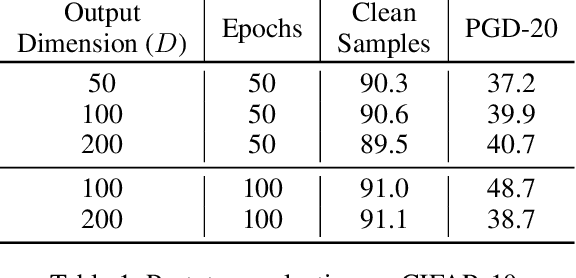
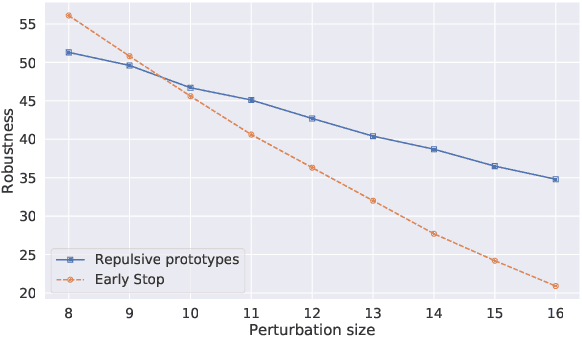
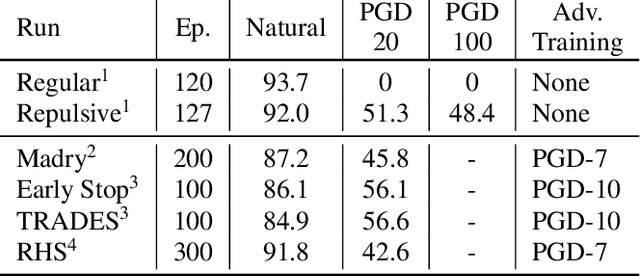
While many defences against adversarial examples have been proposed, finding robust machine learning models is still an open problem. The most compelling defence to date is adversarial training and consists of complementing the training data set with adversarial examples. Yet adversarial training severely impacts training time and depends on finding representative adversarial samples. In this paper we propose to train models on output spaces with large class separation in order to gain robustness without adversarial training. We introduce a method to partition the output space into class prototypes with large separation and train models to preserve it. Experimental results shows that models trained with these prototypes -- which we call deep repulsive prototypes -- gain robustness competitive with adversarial training, while also preserving more accuracy on natural samples. Moreover, the models are more resilient to large perturbation sizes. For example, we obtained over 50% robustness for CIFAR-10, with 92% accuracy on natural samples and over 20% robustness for CIFAR-100, with 71% accuracy on natural samples without adversarial training. For both data sets, the models preserved robustness against large perturbations better than adversarially trained models.
EXPObench: Benchmarking Surrogate-based Optimisation Algorithms on Expensive Black-box Functions
Jun 08, 2021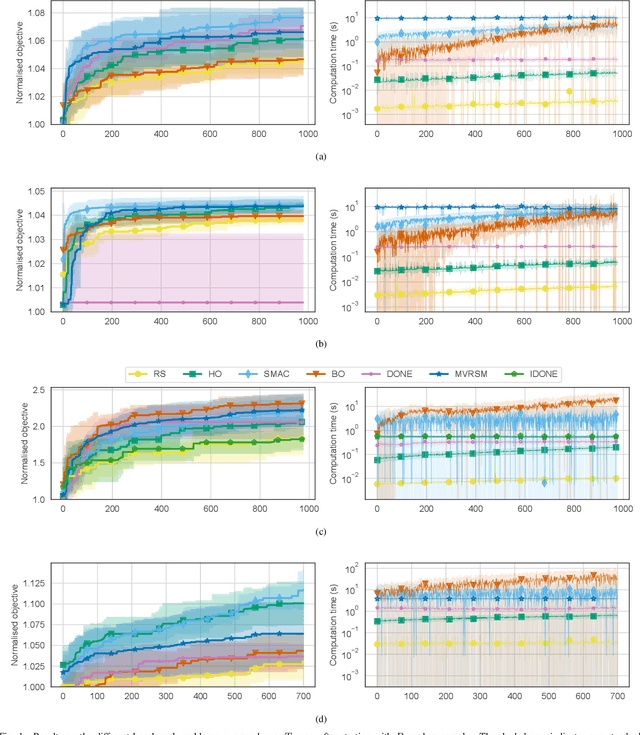
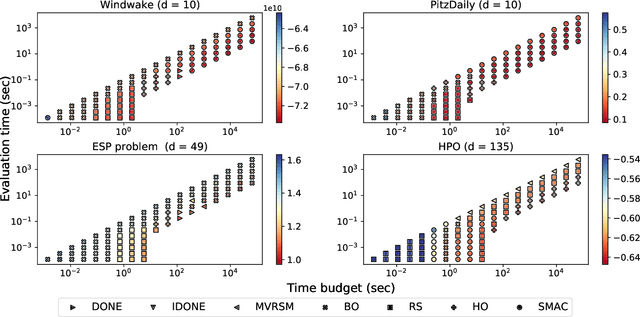
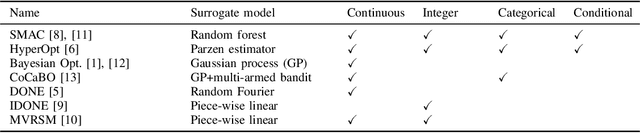
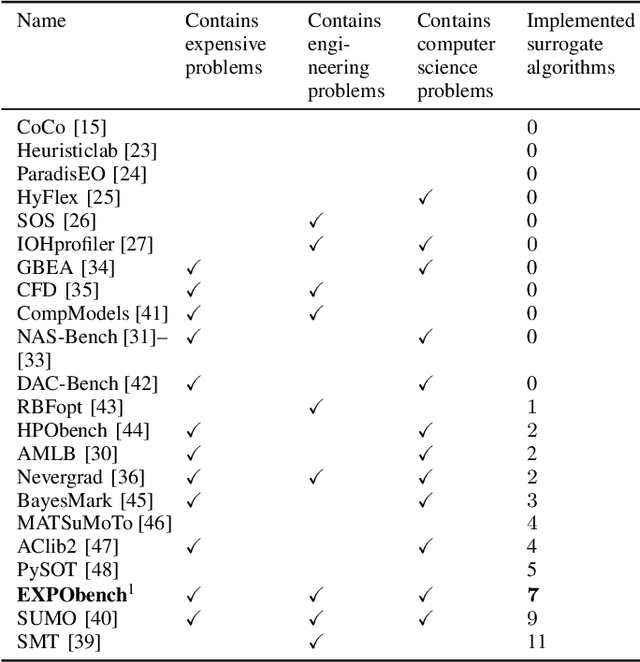
Surrogate algorithms such as Bayesian optimisation are especially designed for black-box optimisation problems with expensive objectives, such as hyperparameter tuning or simulation-based optimisation. In the literature, these algorithms are usually evaluated with synthetic benchmarks which are well established but have no expensive objective, and only on one or two real-life applications which vary wildly between papers. There is a clear lack of standardisation when it comes to benchmarking surrogate algorithms on real-life, expensive, black-box objective functions. This makes it very difficult to draw conclusions on the effect of algorithmic contributions. A new benchmark library, EXPObench, provides first steps towards such a standardisation. The library is used to provide an extensive comparison of six different surrogate algorithms on four expensive optimisation problems from different real-life applications. This has led to new insights regarding the relative importance of exploration, the evaluation time of the objective, and the used model. A further contribution is that we make the algorithms and benchmark problem instances publicly available, contributing to more uniform analysis of surrogate algorithms. Most importantly, we include the performance of the six algorithms on all evaluated problem instances. This results in a unique new dataset that lowers the bar for researching new methods as the number of expensive evaluations required for comparison is significantly reduced.
Non-linear frequency warping using constant-Q transformation for speech emotion recognition
Feb 08, 2021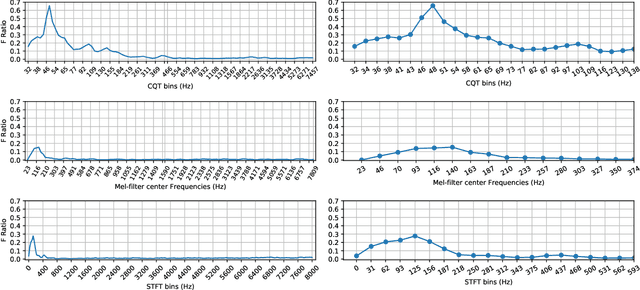
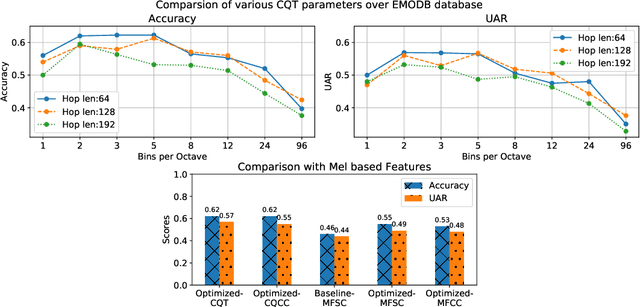

In this work, we explore the constant-Q transform (CQT) for speech emotion recognition (SER). The CQT-based time-frequency analysis provides variable spectro-temporal resolution with higher frequency resolution at lower frequencies. Since lower-frequency regions of speech signal contain more emotion-related information than higher-frequency regions, the increased low-frequency resolution of CQT makes it more promising for SER than standard short-time Fourier transform (STFT). We present a comparative analysis of short-term acoustic features based on STFT and CQT for SER with deep neural network (DNN) as a back-end classifier. We optimize different parameters for both features. The CQT-based features outperform the STFT-based spectral features for SER experiments. Further experiments with cross-corpora evaluation demonstrate that the CQT-based systems provide better generalization with out-of-domain training data.
Distributed Online Learning with Multiple Kernels
Feb 26, 2021
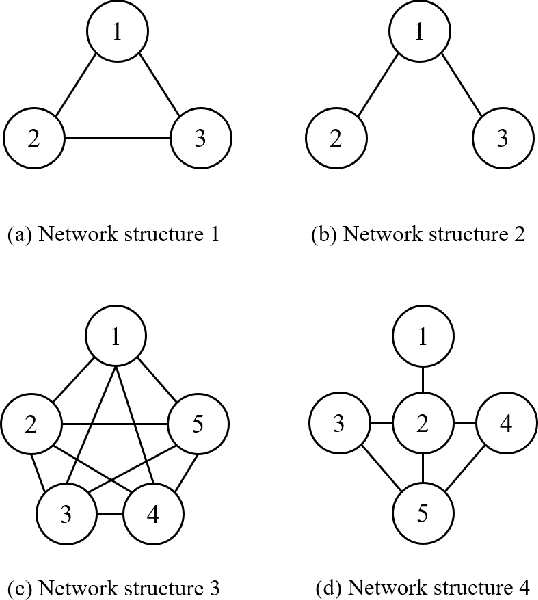
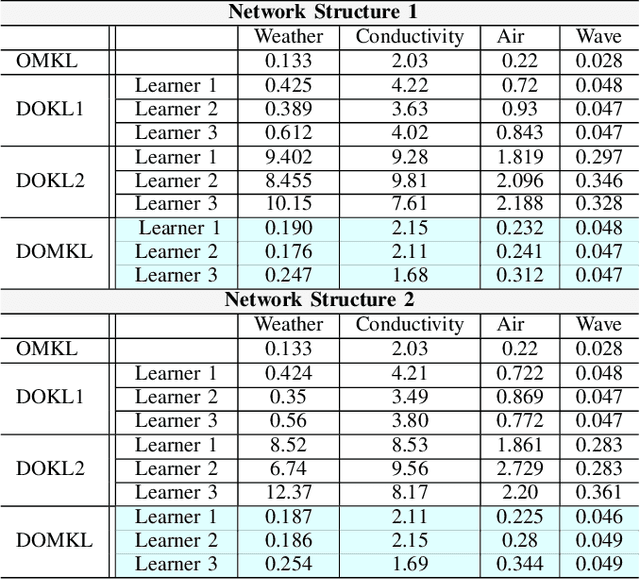
We consider the problem of learning a nonlinear function over a network of learners in a fully decentralized fashion. Online learning is additionally assumed, where every learner receives continuous streaming data locally. This learning model is called a fully distributed online learning (or a fully decentralized online federated learning). For this model, we propose a novel learning framework with multiple kernels, which is named DOMKL. The proposed DOMKL is devised by harnessing the principles of an online alternating direction method of multipliers and a distributed Hedge algorithm. We theoretically prove that DOMKL over T time slots can achieve an optimal sublinear regret, implying that every learner in the network can learn a common function which has a diminishing gap from the best function in hindsight. Our analysis also reveals that DOMKL yields the same asymptotic performance of the state-of-the-art centralized approach while keeping local data at edge learners. Via numerical tests with real datasets, we demonstrate the effectiveness of the proposed DOMKL on various online regression and time-series prediction tasks.
Real-Time Freespace Segmentation on Autonomous Robots for Detection of Obstacles and Drop-Offs
Feb 03, 2019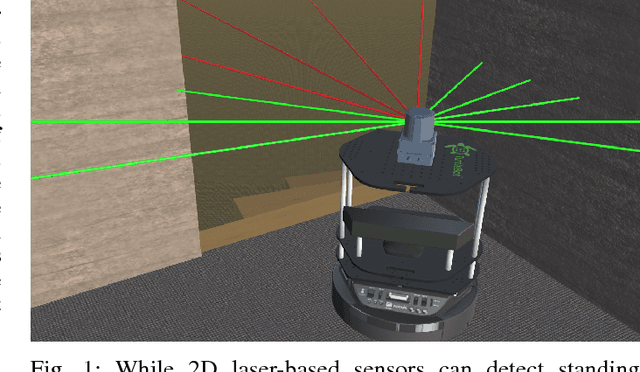


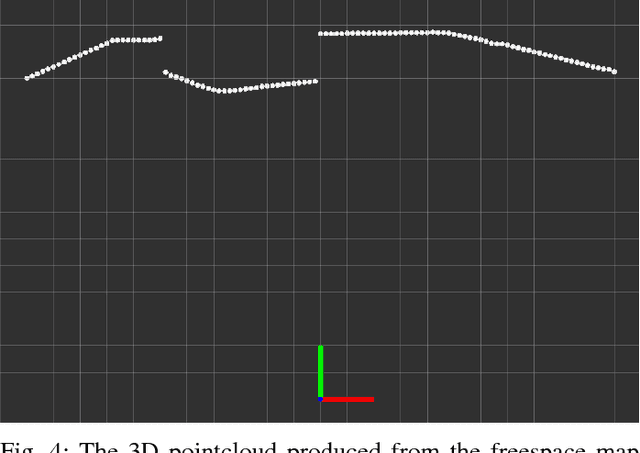
Mobile robots navigating in indoor and outdoor environments must be able to identify and avoid unsafe terrain. Although a significant amount of work has been done on the detection of standing obstacles (solid obstructions), not much work has been done on the detection of negative obstacles (e.g. dropoffs, ledges, downward stairs). We propose a method of terrain safety segmentation using deep convolutional networks. Our custom semantic segmentation architecture uses a single camera as input and creates a freespace map distinguishing safe terrain and obstacles. We then show how this freespace map can be used for real-time navigation on an indoor robot. The results show that our system generalizes well, is suitable for real-time operation, and runs at around 55 fps on a small indoor robot powered by a low-power embedded GPU.
Machine Learning Implicit Solvation for Molecular Dynamics
Jun 14, 2021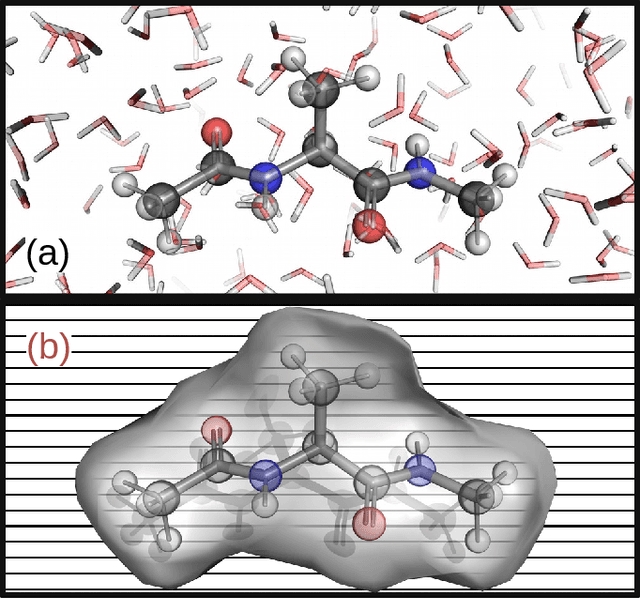
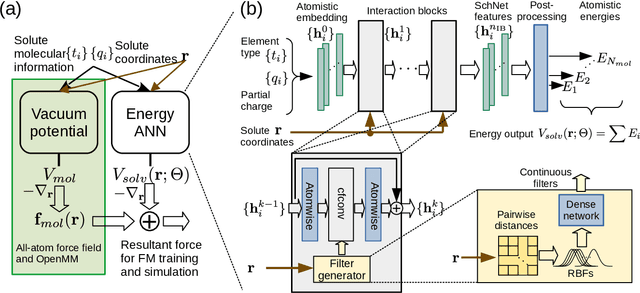
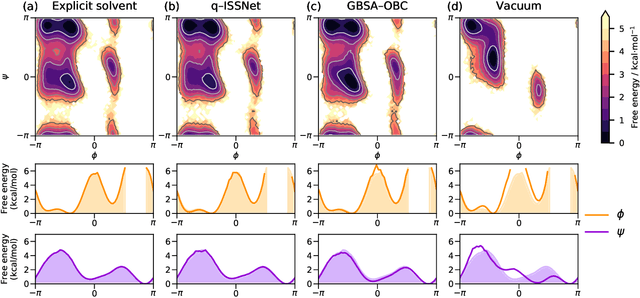
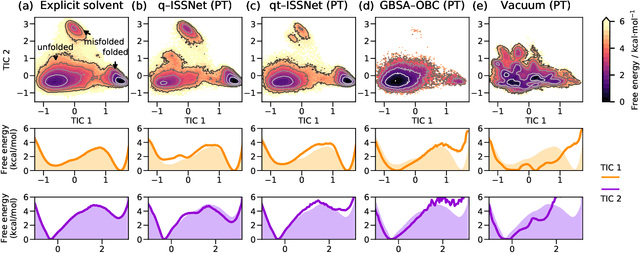
Accurate modeling of the solvent environment for biological molecules is crucial for computational biology and drug design. A popular approach to achieve long simulation time scales for large system sizes is to incorporate the effect of the solvent in a mean-field fashion with implicit solvent models. However, a challenge with existing implicit solvent models is that they often lack accuracy or certain physical properties compared to explicit solvent models, as the many-body effects of the neglected solvent molecules is difficult to model as a mean field. Here, we leverage machine learning (ML) and multi-scale coarse graining (CG) in order to learn implicit solvent models that can approximate the energetic and thermodynamic properties of a given explicit solvent model with arbitrary accuracy, given enough training data. Following the previous ML--CG models CGnet and CGSchnet, we introduce ISSNet, a graph neural network, to model the implicit solvent potential of mean force. ISSNet can learn from explicit solvent simulation data and be readily applied to MD simulations. We compare the solute conformational distributions under different solvation treatments for two peptide systems. The results indicate that ISSNet models can outperform widely-used generalized Born and surface area models in reproducing the thermodynamics of small protein systems with respect to explicit solvent. The success of this novel method demonstrates the potential benefit of applying machine learning methods in accurate modeling of solvent effects for in silico research and biomedical applications.
Towards Speeding up Adversarial Training in Latent Spaces
Feb 01, 2021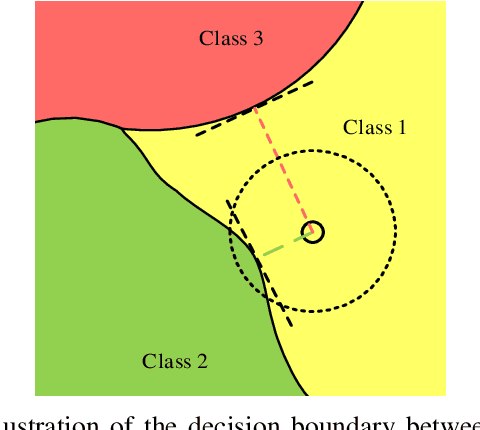
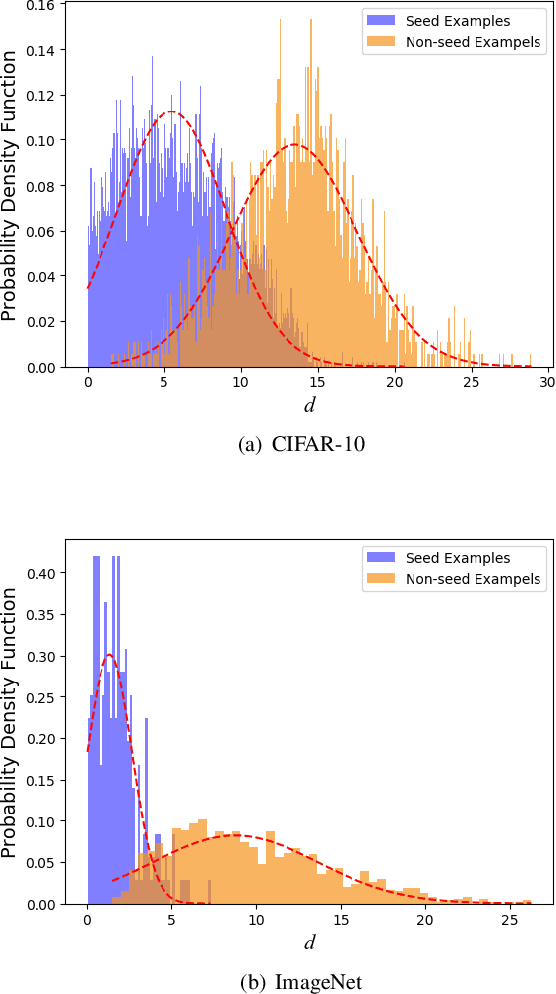
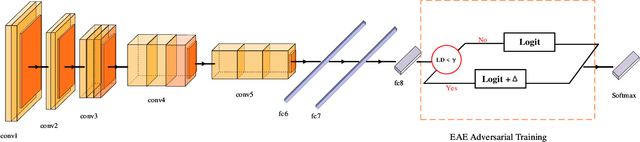
Adversarial training is wildly considered as the most effective way to defend against adversarial examples. However, existing adversarial training methods consume unbearable time cost, since they need to generate adversarial examples in the input space, which accounts for the main part of total time-consuming. For speeding up the training process, we propose a novel adversarial training method that does not need to generate real adversarial examples. We notice that a clean example is closer to the decision boundary of the class with the second largest logit component than any other class besides its own class. Thus, by adding perturbations to logits to generate Endogenous Adversarial Examples(EAEs) -- adversarial examples in the latent space, it can avoid calculating gradients to speed up the training process. We further gain a deep insight into the existence of EAEs by the theory of manifold. To guarantee the added perturbation is within the range of constraint, we use statistical distributions to select seed examples to craft EAEs. Extensive experiments are conducted on CIFAR-10 and ImageNet, and the results show that compare with state-of-the-art "Free" and "Fast" methods, our EAE adversarial training not only shortens the training time, but also enhances the robustness of the model. Moreover, the EAE adversarial training has little impact on the accuracy of clean examples than the existing methods.
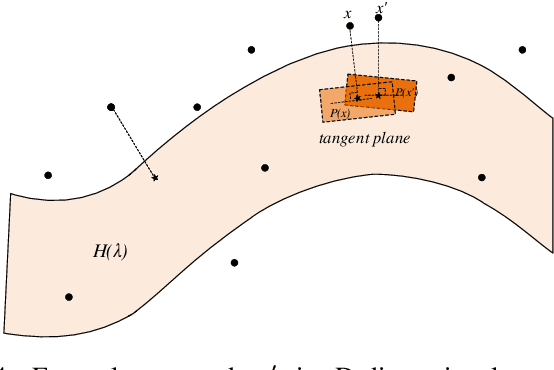
Ego-based Entropy Measures for Structural Representations on Graphs
Feb 17, 2021
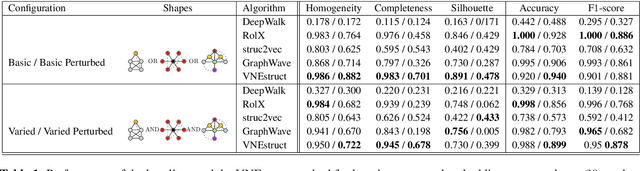
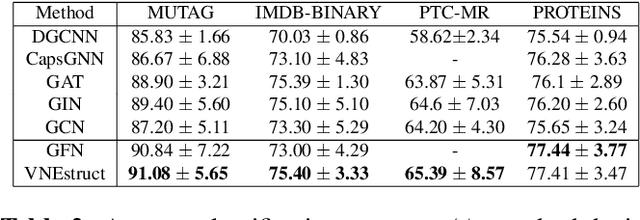
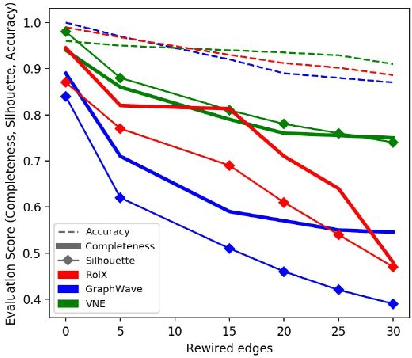
Machine learning on graph-structured data has attracted high research interest due to the emergence of Graph Neural Networks (GNNs). Most of the proposed GNNs are based on the node homophily, i.e neighboring nodes share similar characteristics. However, in many complex networks, nodes that lie to distant parts of the graph share structurally equivalent characteristics and exhibit similar roles (e.g chemical properties of distant atoms in a molecule, type of social network users). A growing literature proposed representations that identify structurally equivalent nodes. However, most of the existing methods require high time and space complexity. In this paper, we propose VNEstruct, a simple approach, based on entropy measures of the neighborhood's topology, for generating low-dimensional structural representations, that is time-efficient and robust to graph perturbations. Empirically, we observe that VNEstruct exhibits robustness on structural role identification tasks. Moreover, VNEstruct can achieve state-of-the-art performance on graph classification, without incorporating the graph structure information in the optimization, in contrast to GNN competitors.
Learning Normal Dynamics in Videos with Meta Prototype Network
May 10, 2021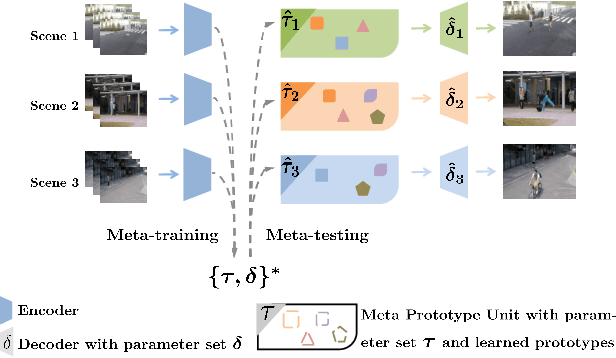
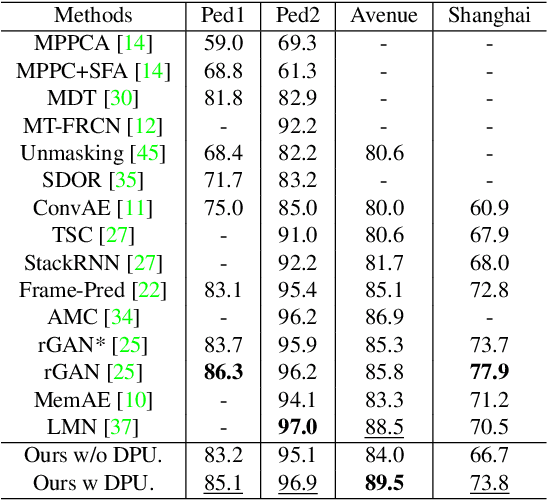
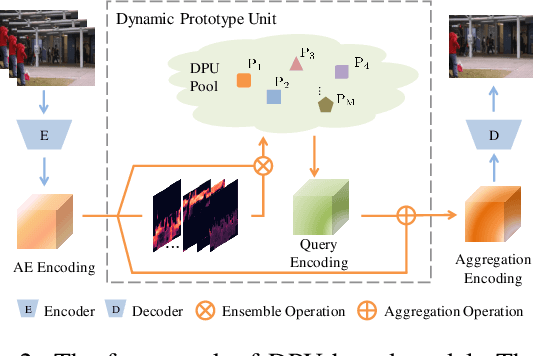
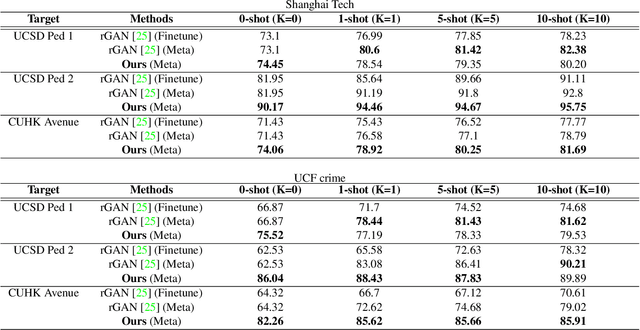
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory-consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a dynamic prototype unit (DPU) to encode the normal dynamics as prototypes in real time, free from extra memory cost. In addition, we introduce meta-learning to our DPU to form a novel few-shot normalcy learner, namely Meta-Prototype Unit (MPU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method.
Coach-Player Multi-Agent Reinforcement Learning for Dynamic Team Composition
May 18, 2021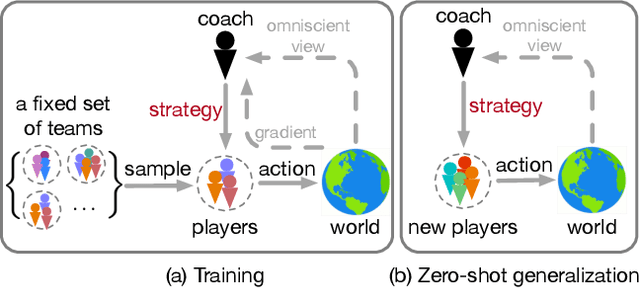
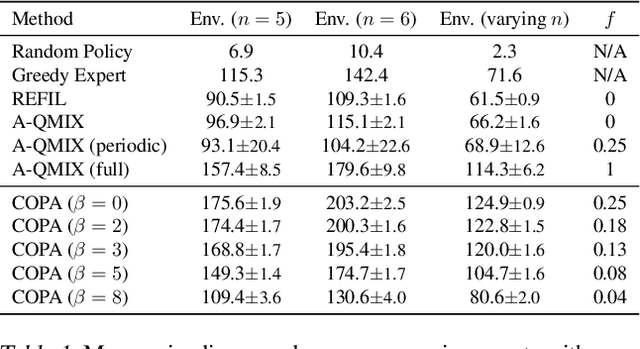
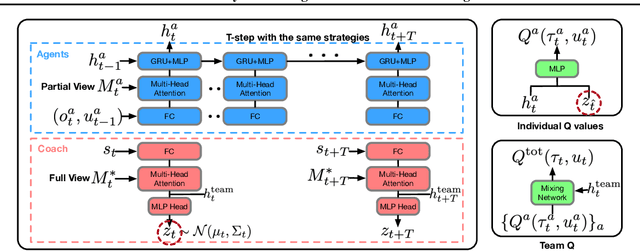
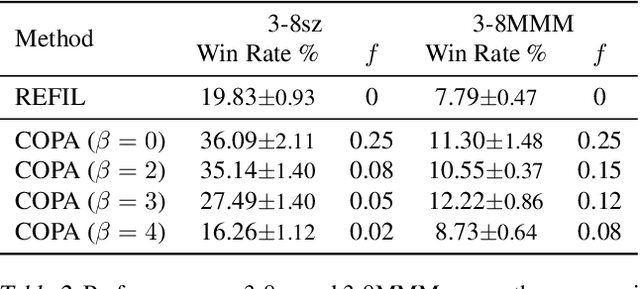
In real-world multiagent systems, agents with different capabilities may join or leave without altering the team's overarching goals. Coordinating teams with such dynamic composition is challenging: the optimal team strategy varies with the composition. We propose COPA, a coach-player framework to tackle this problem. We assume the coach has a global view of the environment and coordinates the players, who only have partial views, by distributing individual strategies. Specifically, we 1) adopt the attention mechanism for both the coach and the players; 2) propose a variational objective to regularize learning; and 3) design an adaptive communication method to let the coach decide when to communicate with the players. We validate our methods on a resource collection task, a rescue game, and the StarCraft micromanagement tasks. We demonstrate zero-shot generalization to new team compositions. Our method achieves comparable or better performance than the setting where all players have a full view of the environment. Moreover, we see that the performance remains high even when the coach communicates as little as 13% of the time using the adaptive communication strategy.