 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Smile Like You Mean It: Driving Animatronic Robotic Face with Learned Models
May 26, 2021
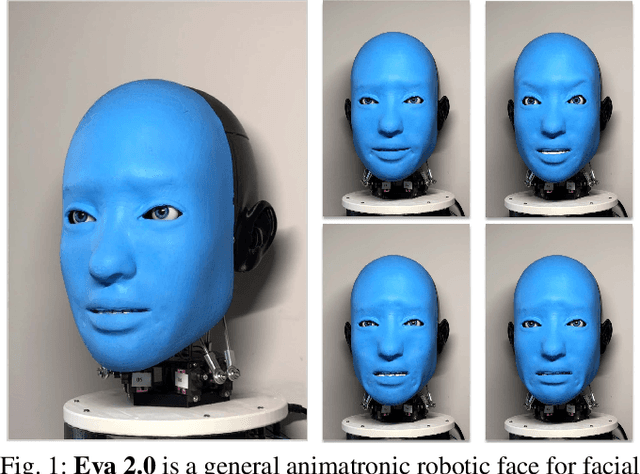



Ability to generate intelligent and generalizable facial expressions is essential for building human-like social robots. At present, progress in this field is hindered by the fact that each facial expression needs to be programmed by humans. In order to adapt robot behavior in real time to different situations that arise when interacting with human subjects, robots need to be able to train themselves without requiring human labels, as well as make fast action decisions and generalize the acquired knowledge to diverse and new contexts. We addressed this challenge by designing a physical animatronic robotic face with soft skin and by developing a vision-based self-supervised learning framework for facial mimicry. Our algorithm does not require any knowledge of the robot's kinematic model, camera calibration or predefined expression set. By decomposing the learning process into a generative model and an inverse model, our framework can be trained using a single motor babbling dataset. Comprehensive evaluations show that our method enables accurate and diverse face mimicry across diverse human subjects. The project website is at http://www.cs.columbia.edu/~bchen/aiface/
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 18, 2021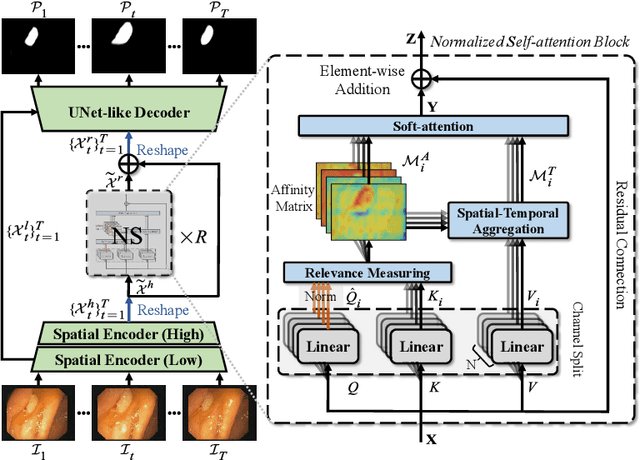
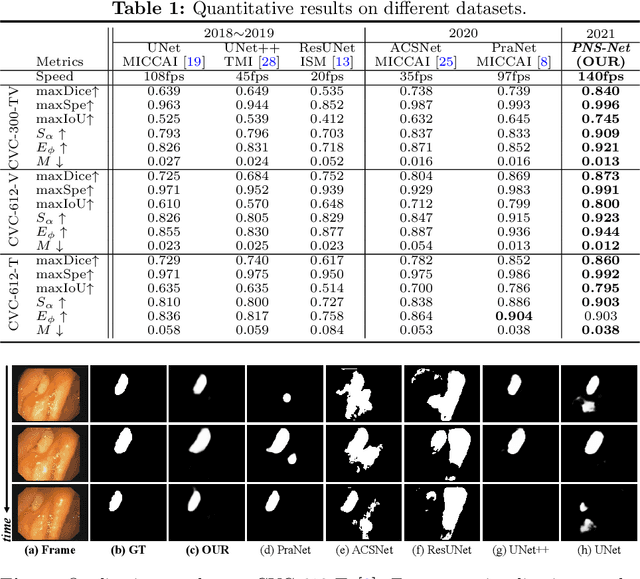
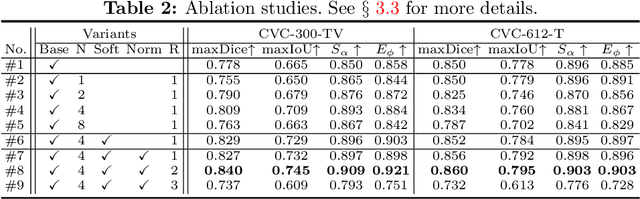
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
Event-Triggered Safety-Critical Control for Systems with Unknown Dynamics
Mar 29, 2021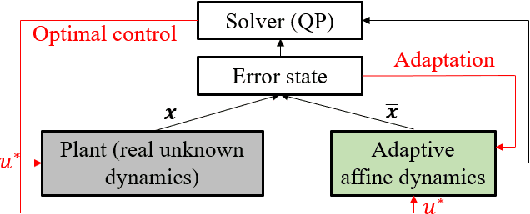
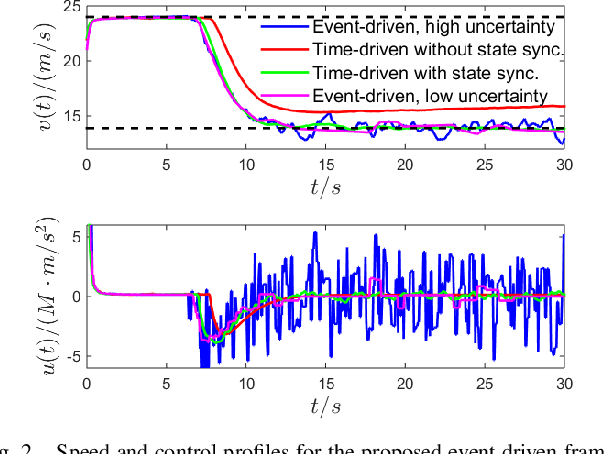
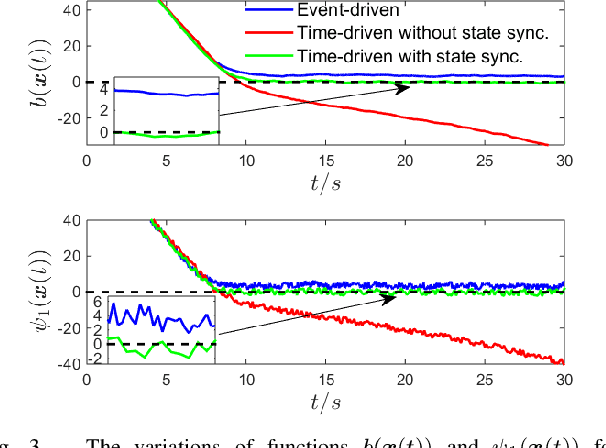
This paper addresses the problem of safety-critical control for systems with unknown dynamics. It has been shown that stabilizing affine control systems to desired (sets of) states while optimizing quadratic costs subject to state and control constraints can be reduced to a sequence of quadratic programs (QPs) by using Control Barrier Functions (CBFs) and Control Lyapunov Functions (CLFs). Our recently proposed High Order CBFs (HOCBFs) can accommodate constraints of arbitrary relative degree. One of the main challenges in this approach is obtaining accurate system dynamics, which is especially difficult for systems that require online model identification given limited computational resources and system data. In order to approximate the real unmodelled system dynamics, we define adaptive affine control dynamics which are updated based on the error states obtained by real-time sensor measurements. We define a HOCBF for a safety requirement on the unmodelled system based on the adaptive dynamics and error states, and reformulate the safety-critical control problem as the above mentioned QP. Then, we determine the events required to solve the QP in order to guarantee safety. We also derive a condition that guarantees the satisfaction of the HOCBF constraint between events. We illustrate the effectiveness of the proposed framework on an adaptive cruise control problem and compare it with the classical time-driven approach.
Binarized Weight Error Networks With a Transition Regularization Term
May 09, 2021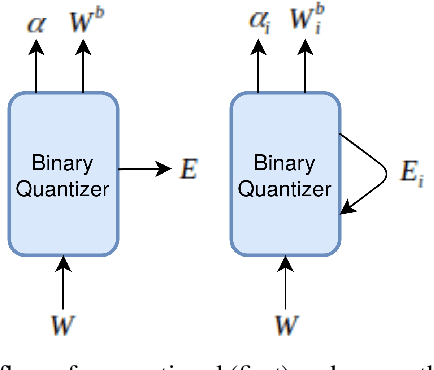
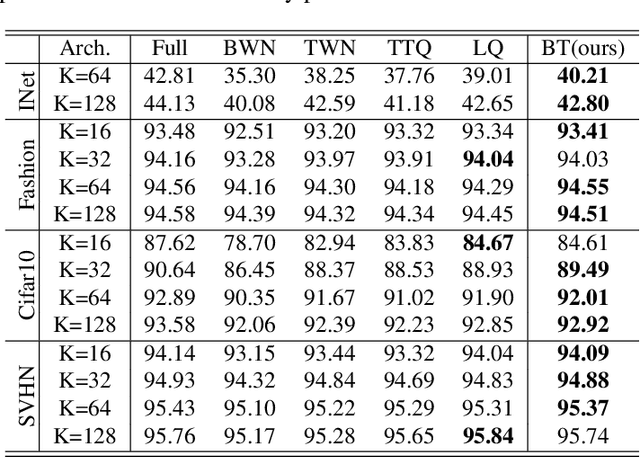

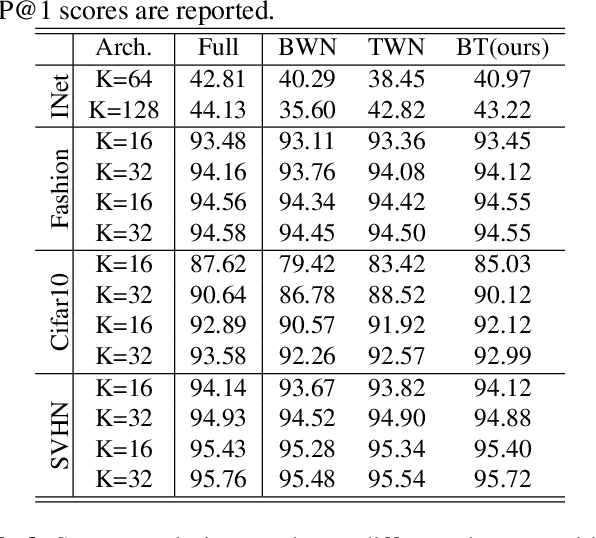
This paper proposes a novel binarized weight network (BT) for a resource-efficient neural structure. The proposed model estimates a binary representation of weights by taking into account the approximation error with an additional term. This model increases representation capacity and stability, particularly for shallow networks, while the computation load is theoretically reduced. In addition, a novel regularization term is introduced that is suitable for all threshold-based binary precision networks. This term penalizes the trainable parameters that are far from the thresholds at which binary transitions occur. This step promotes a swift modification for binary-precision responses at train time. The experimental results are carried out for two sets of tasks: visual classification and visual inverse problems. Benchmarks for Cifar10, SVHN, Fashion, ImageNet2012, Set5, Set14, Urban and BSD100 datasets show that our method outperforms all counterparts with binary precision.
Automatic Construction of Sememe Knowledge Bases via Dictionaries
May 26, 2021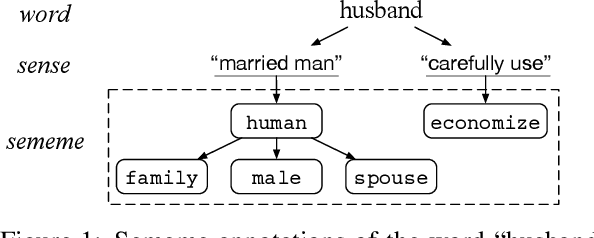
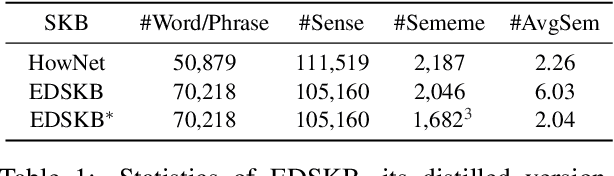

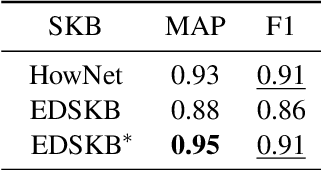
A sememe is defined as the minimum semantic unit in linguistics. Sememe knowledge bases (SKBs), which comprise words annotated with sememes, enable sememes to be applied to natural language processing. So far a large body of research has showcased the unique advantages and effectiveness of SKBs in various tasks. However, most languages have no SKBs, and manual construction of SKBs is time-consuming and labor-intensive. To tackle this challenge, we propose a simple and fully automatic method of building an SKB via an existing dictionary. We use this method to build an English SKB and a French SKB, and conduct comprehensive evaluations from both intrinsic and extrinsic perspectives. Experimental results demonstrate that the automatically built English SKB is even superior to HowNet, the most widely used SKB that takes decades to build manually. And both the English and French SKBs can bring obvious performance enhancement in multiple downstream tasks. All the code and data of this paper (except the copyrighted dictionaries) can be obtained at https://github.com/thunlp/DictSKB.
When Can Liquid Democracy Unveil the Truth?
Apr 05, 2021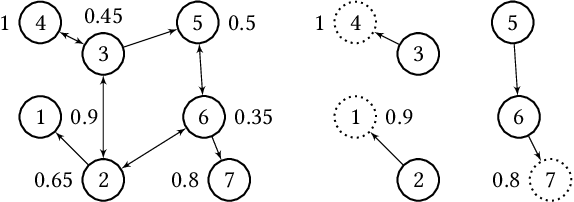
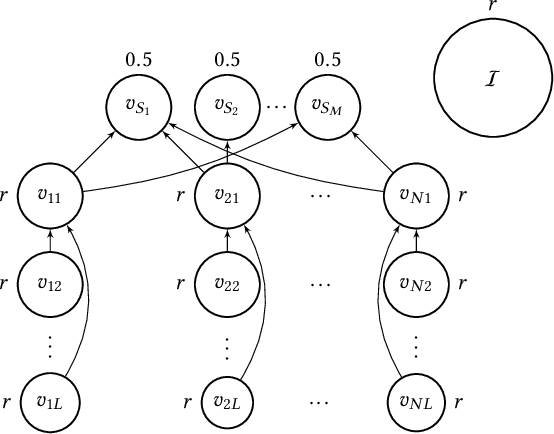
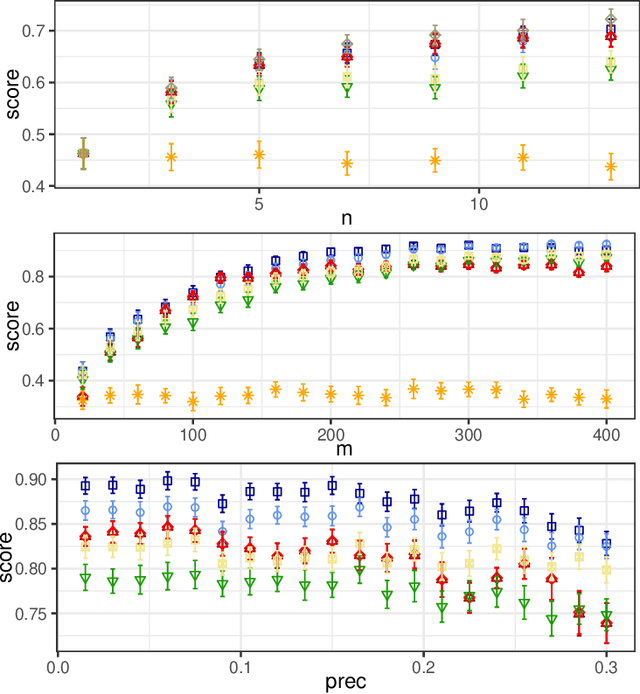
In this paper, we investigate the so-called ODP-problem that has been formulated by Caragiannis and Micha [10]. Here, we are in a setting with two election alternatives out of which one is assumed to be correct. In ODP, the goal is to organise the delegations in the social network in order to maximize the probability that the correct alternative, referred to as ground truth, is elected. While the problem is known to be computationally hard, we strengthen existing hardness results by providing a novel strong approximation hardness result: For any positive constant $C$, we prove that, unless $P=NP$, there is no polynomial-time algorithm for ODP that achieves an approximation guarantee of $\alpha \ge (\ln n)^{-C}$, where $n$ is the number of voters. The reduction designed for this result uses poorly connected social networks in which some voters suffer from misinformation. Interestingly, under some hypothesis on either the accuracies of voters or the connectivity of the network, we obtain a polynomial-time $1/2$-approximation algorithm. This observation proves formally that the connectivity of the social network is a key feature for the efficiency of the liquid democracy paradigm. Lastly, we run extensive simulations and observe that simple algorithms (working either in a centralized or decentralized way) outperform direct democracy on a large class of instances. Overall, our contributions yield new insights on the question in which situations liquid democracy can be beneficial.
Dynamics, behaviours, and anomaly persistence in cryptocurrencies and equities surrounding COVID-19
Jan 03, 2021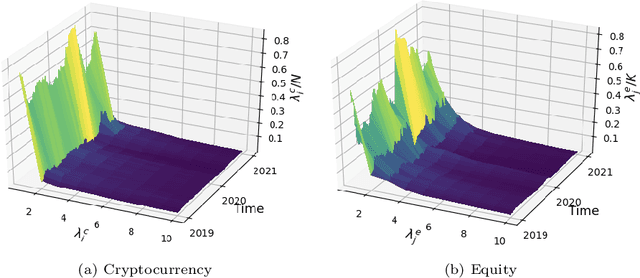
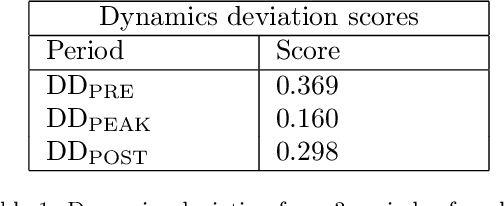
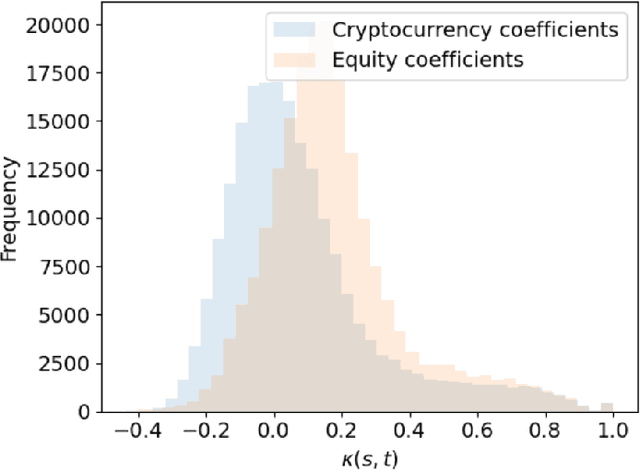
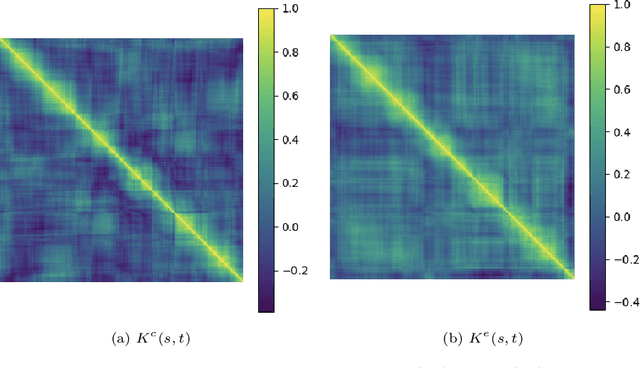
This paper uses new and recently introduced methodologies to study the similarity in the dynamics and behaviours of cryptocurrencies and equities surrounding the COVID-19 pandemic. We study two collections; 45 cryptocurrencies and 72 equities, both independently and in conjunction. First, we examine the evolution of cryptocurrency and equity market dynamics, with a particular focus on their change during the COVID-19 pandemic. We demonstrate markedly more similar dynamics during times of crisis. Next, we apply recently introduced methods to contrast trajectories, erratic behaviours, and extreme values among the two multivariate time series. Finally, we introduce a new framework for determining the persistence of market anomalies over time. Surprisingly, we find that although cryptocurrencies exhibit stronger collective dynamics and correlation in all market conditions, equities behave more similarly in their trajectories, extremes, and show greater persistence in anomalies over time.
Egocentric Videoconferencing
Jul 07, 2021

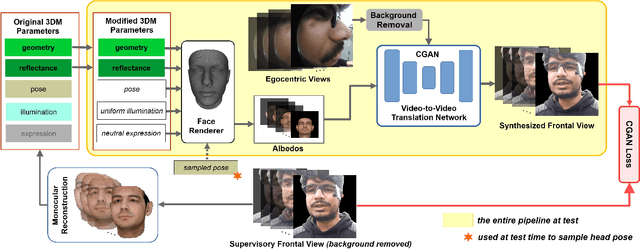

We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
* Mohamed Elgharib and Mohit Mendiratta contributed equally to this work. http://gvv.mpi-inf.mpg.de/projects/EgoChat/
Analysis of bio-electro-chemical signals from passive sweat-based wearable electro-impedance spectroscopy (EIS) towards assessing blood glucose modulations
Apr 05, 2021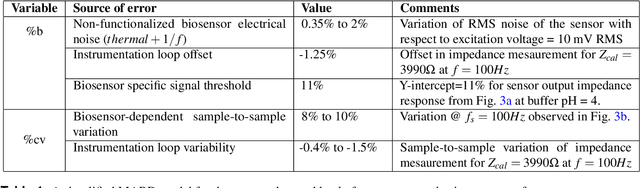
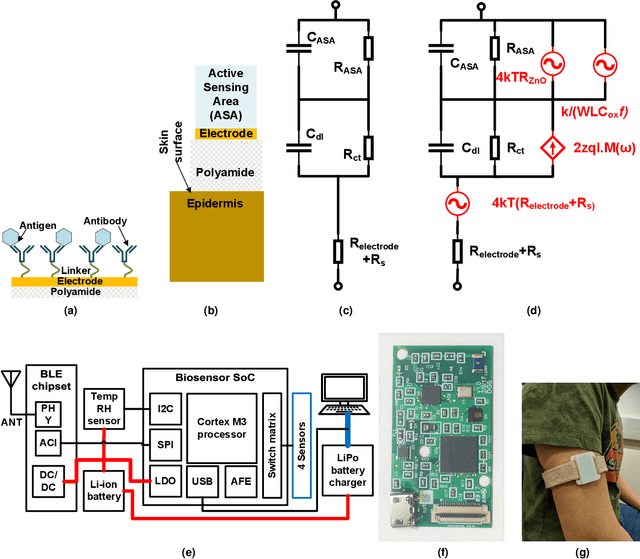
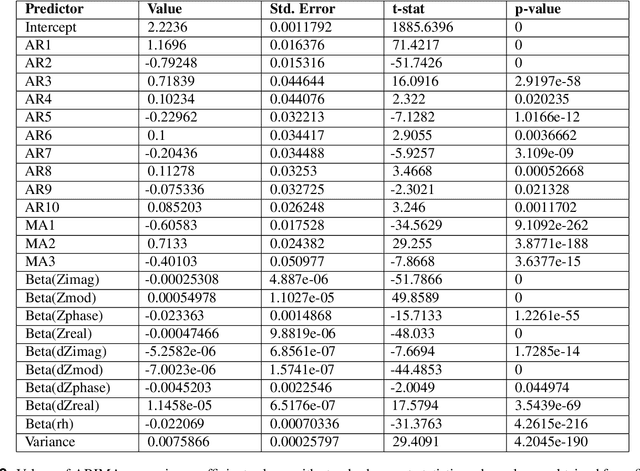
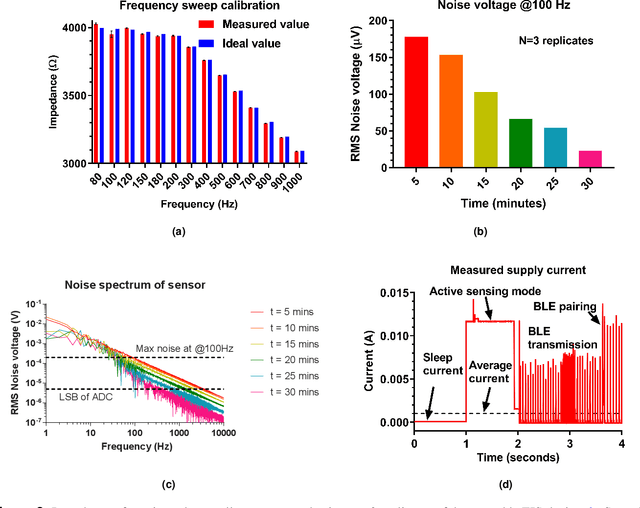
There has been a recent tremendous interest in label-free detection of biomarkers which is a critical enabler of point-of-need diagnostics. A low-power, small form factor, multiplexed wearable system is proposed for continuous detection of glucose in passively expressed sweat using electrochemical impedance spectroscopy (EIS) measurement. The wearable EIS system consists of a sensing analog front end integrated with low-volume (1-5 $\mu$L) ultra-sensitive flexible biosensors. A passive sweat sensor was designed to integrate a glucose oxidase electrochemical system on active semiconducting material. The non-faradaic EIS response of the biosensor was used to calibrate the analog front end response using ratiometric Discrete Fourier Transform (DFT) for a shorter measurement time. In this work, a stringent assessment of a continuous glucose sensing platform is performed in a bottom-up approach, going from the biosensor to the system to the interaction with a human subject. The active semiconductor-based biosensors are dosed with glucose concentrations ranging from 5-200 mg/dL and detection is performed using the analog front end. In addition, a detailed analysis of battery life and performance of a wearable EIS system is discussed to define a figure of merit for an optimally integrated design. Moreover, a continuous glucose detection test is performed on a healthy human subject cohort to investigate the stability of the sensor-system mechanism for an 8-hour period, and a time-series-based, auto-regressive (AR) model was created for the system.
Continual Deterioration Prediction for Hospitalized COVID-19 Patients
Jan 19, 2021
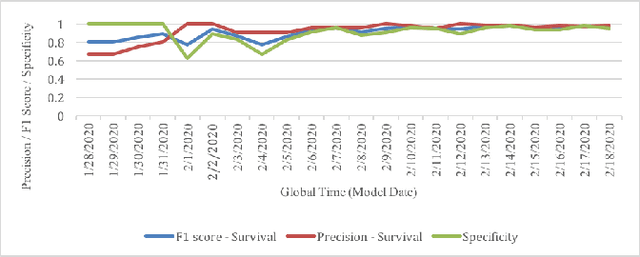
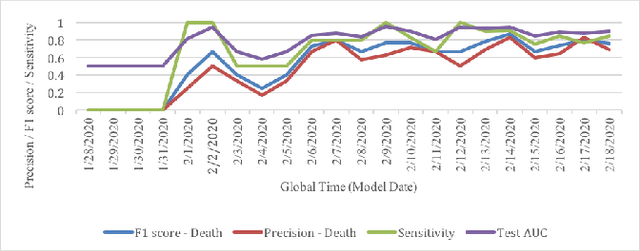

Leading up to August 2020, COVID-19 has spread to almost every country in the world, causing millions of infected and hundreds of thousands of deaths. In this paper, we first verify the assumption that clinical variables could have time-varying effects on COVID-19 outcomes. Then, we develop a temporal stratification approach to make daily predictions on patients' outcome at the end of hospital stay. Training data is segmented by the remaining length of stay, which is a proxy for the patient's overall condition. Based on this, a sequence of predictive models are built, one for each time segment. Thanks to the publicly shared data, we were able to build and evaluate prototype models. Preliminary experiments show 0.98 AUROC, 0.91 F1 score and 0.97 AUPR on continuous deterioration prediction, encouraging further development of the model as well as validations on different datasets. We also verify the key assumption which motivates our method. Clinical variables could have time-varying effects on COVID-19 outcomes. That is to say, the feature importance of a variable in the predictive model varies at different disease stages.