 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Instance-Wise Classification in Correlated Feature Spaces
Jun 08, 2021
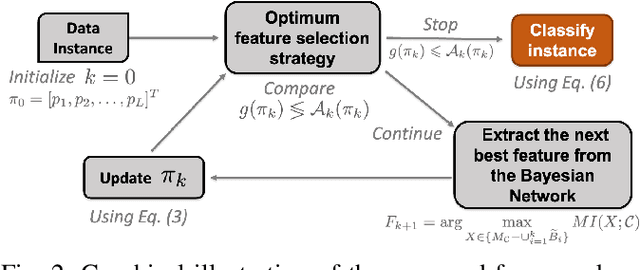
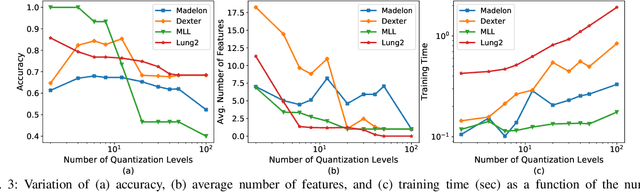
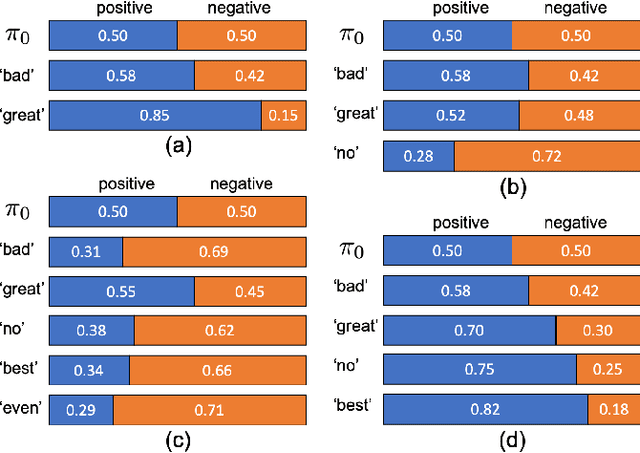
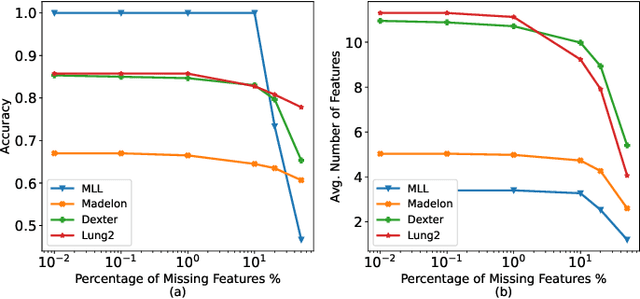
In a typical supervised machine learning setting, the predictions on all test instances are based on a common subset of features discovered during model training. However, using a different subset of features that is most informative for each test instance individually may not only improve prediction accuracy, but also the overall interpretability of the model. At the same time, feature selection methods for classification have been known to be the most effective when many features are irrelevant and/or uncorrelated. In fact, feature selection ignoring correlations between features can lead to poor classification performance. In this work, a Bayesian network is utilized to model feature dependencies. Using the dependency network, a new method is proposed that sequentially selects the best feature to evaluate for each test instance individually, and stops the selection process to make a prediction once it determines that no further improvement can be achieved with respect to classification accuracy. The optimum number of features to acquire and the optimum classification strategy are derived for each test instance. The theoretical properties of the optimum solution are analyzed, and a new algorithm is proposed that takes advantage of these properties to implement a robust and scalable solution for high dimensional settings. The effectiveness, generalizability, and scalability of the proposed method is illustrated on a variety of real-world datasets from diverse application domains.
Automatic 2D-3D Registration without Contrast Agent during Neurovascular Interventions
Jun 08, 2021
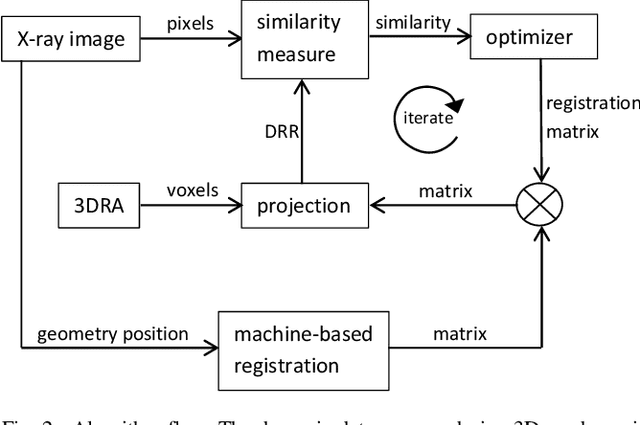
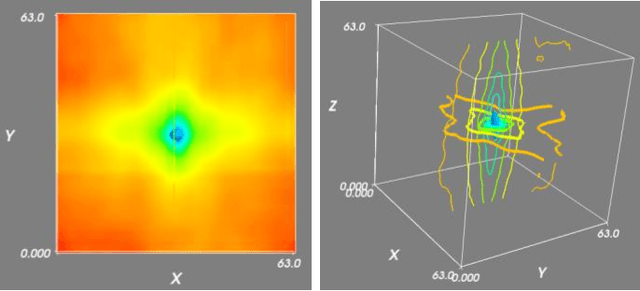
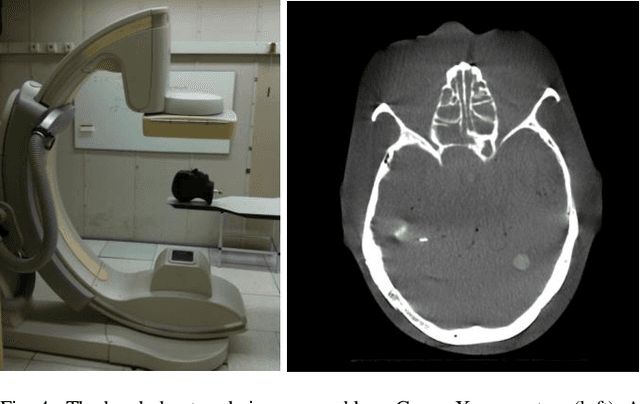
Fusing live fluoroscopy images with a 3D rotational reconstruction of the vasculature allows to navigate endovascular devices in minimally invasive neuro-vascular treatment, while reducing the usage of harmful iodine contrast medium. The alignment of the fluoroscopy images and the 3D reconstruction is initialized using the sensor information of the X-ray C-arm geometry. Patient motion is then corrected by an image-based registration algorithm, based on a gradient difference similarity measure using digital reconstructed radiographs of the 3D reconstruction. This algorithm does not require the vessels in the fluoroscopy image to be filled with iodine contrast agent, but rather relies on gradients in the image (bone structures, sinuses) as landmark features. This paper investigates the accuracy, robustness and computation time aspects of the image-based registration algorithm. Using phantom experiments 97% of the registration attempts passed the success criterion of a residual registration error of less than 1 mm translation and 3{\deg} rotation. The paper establishes a new method for validation of 2D-3D registration without requiring changes to the clinical workflow, such as attaching fiducial markers. As a consequence, this method can be retrospectively applied to pre-existing clinical data. For clinical data experiments, 87% of the registration attempts passed the criterion of a residual translational error of < 1 mm, and 84% possessed a rotational error of < 3{\deg}.
PDWN: Pyramid Deformable Warping Network for Video Interpolation
Apr 04, 2021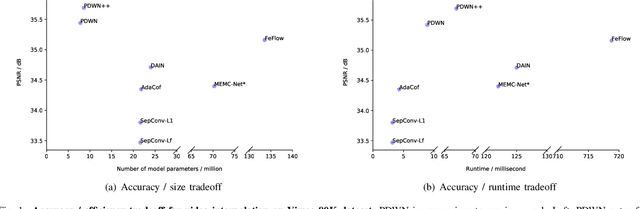
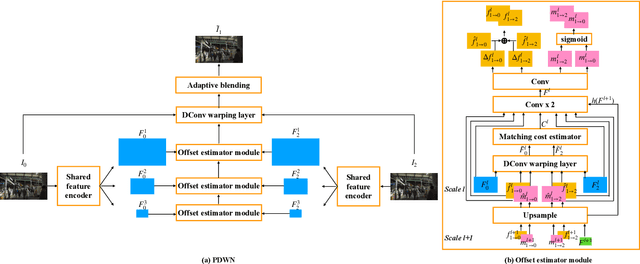


Video interpolation aims to generate a non-existent intermediate frame given the past and future frames. Many state-of-the-art methods achieve promising results by estimating the optical flow between the known frames and then generating the backward flows between the middle frame and the known frames. However, these methods usually suffer from the inaccuracy of estimated optical flows and require additional models or information to compensate for flow estimation errors. Following the recent development in using deformable convolution (DConv) for video interpolation, we propose a light but effective model, called Pyramid Deformable Warping Network (PDWN). PDWN uses a pyramid structure to generate DConv offsets of the unknown middle frame with respect to the known frames through coarse-to-fine successive refinements. Cost volumes between warped features are calculated at every pyramid level to help the offset inference. At the finest scale, the two warped frames are adaptively blended to generate the middle frame. Lastly, a context enhancement network further enhances the contextual detail of the final output. Ablation studies demonstrate the effectiveness of the coarse-to-fine offset refinement, cost volumes, and DConv. Our method achieves better or on-par accuracy compared to state-of-the-art models on multiple datasets while the number of model parameters and the inference time are substantially less than previous models. Moreover, we present an extension of the proposed framework to use four input frames, which can achieve significant improvement over using only two input frames, with only a slight increase in the model size and inference time.
Graph Deep Factors for Forecasting
Oct 14, 2020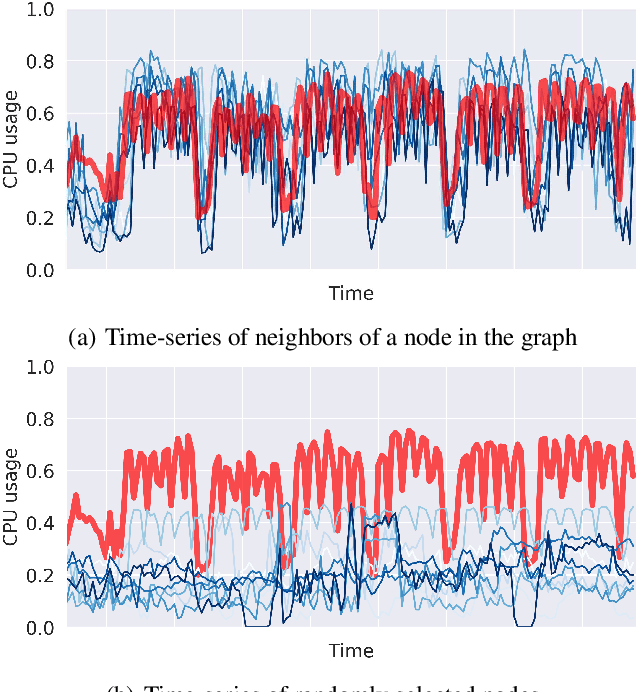
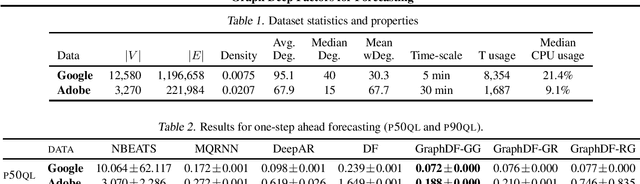

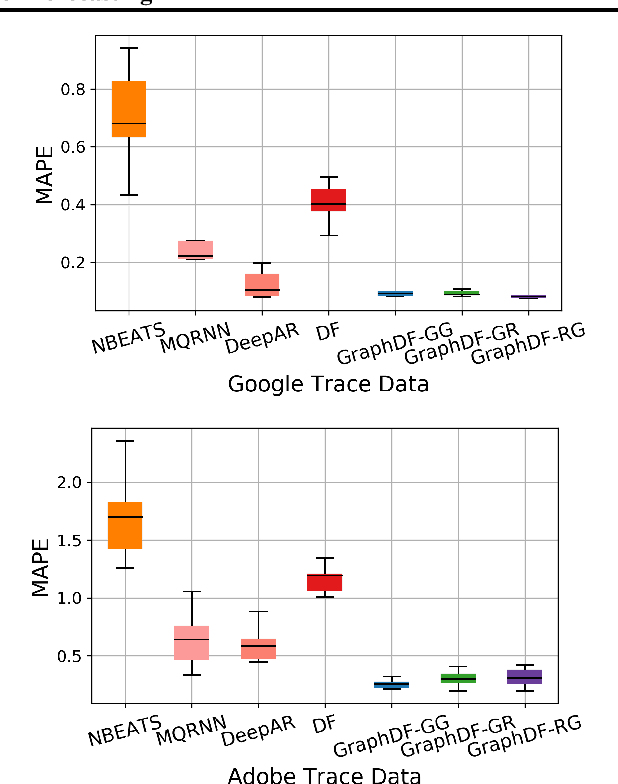
Deep probabilistic forecasting techniques have recently been proposed for modeling large collections of time-series. However, these techniques explicitly assume either complete independence (local model) or complete dependence (global model) between time-series in the collection. This corresponds to the two extreme cases where every time-series is disconnected from every other time-series in the collection or likewise, that every time-series is related to every other time-series resulting in a completely connected graph. In this work, we propose a deep hybrid probabilistic graph-based forecasting framework called Graph Deep Factors (GraphDF) that goes beyond these two extremes by allowing nodes and their time-series to be connected to others in an arbitrary fashion. GraphDF is a hybrid forecasting framework that consists of a relational global and relational local model. In particular, we propose a relational global model that learns complex non-linear time-series patterns globally using the structure of the graph to improve both forecasting accuracy and computational efficiency. Similarly, instead of modeling every time-series independently, we learn a relational local model that not only considers its individual time-series but also the time-series of nodes that are connected in the graph. The experiments demonstrate the effectiveness of the proposed deep hybrid graph-based forecasting model compared to the state-of-the-art methods in terms of its forecasting accuracy, runtime, and scalability. Our case study reveals that GraphDF can successfully generate cloud usage forecasts and opportunistically schedule workloads to increase cloud cluster utilization by 47.5% on average.
EXPObench: Benchmarking Surrogate-based Optimisation Algorithms on Expensive Black-box Functions
Jun 08, 2021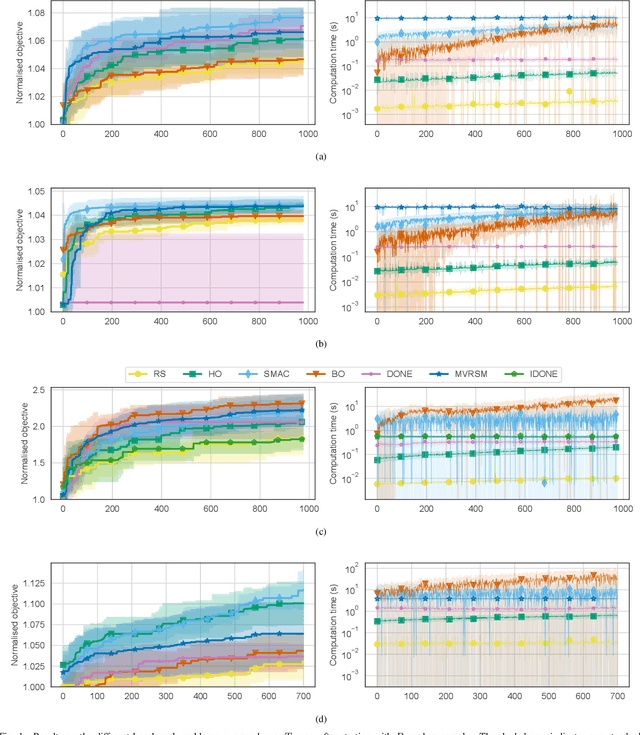
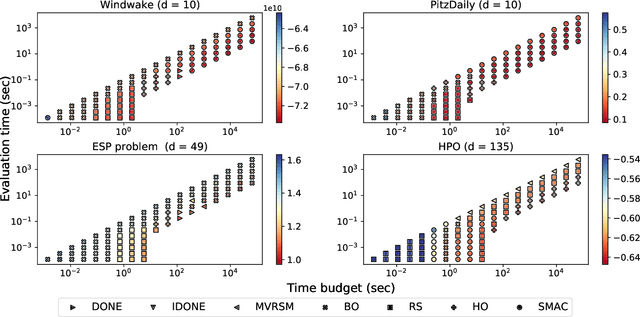
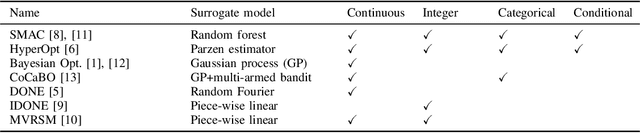
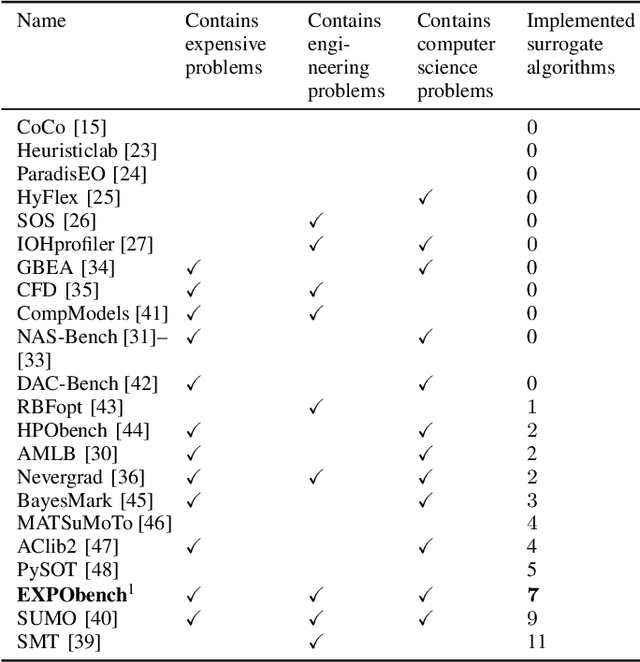
Surrogate algorithms such as Bayesian optimisation are especially designed for black-box optimisation problems with expensive objectives, such as hyperparameter tuning or simulation-based optimisation. In the literature, these algorithms are usually evaluated with synthetic benchmarks which are well established but have no expensive objective, and only on one or two real-life applications which vary wildly between papers. There is a clear lack of standardisation when it comes to benchmarking surrogate algorithms on real-life, expensive, black-box objective functions. This makes it very difficult to draw conclusions on the effect of algorithmic contributions. A new benchmark library, EXPObench, provides first steps towards such a standardisation. The library is used to provide an extensive comparison of six different surrogate algorithms on four expensive optimisation problems from different real-life applications. This has led to new insights regarding the relative importance of exploration, the evaluation time of the objective, and the used model. A further contribution is that we make the algorithms and benchmark problem instances publicly available, contributing to more uniform analysis of surrogate algorithms. Most importantly, we include the performance of the six algorithms on all evaluated problem instances. This results in a unique new dataset that lowers the bar for researching new methods as the number of expensive evaluations required for comparison is significantly reduced.
Machine Learning Implicit Solvation for Molecular Dynamics
Jun 14, 2021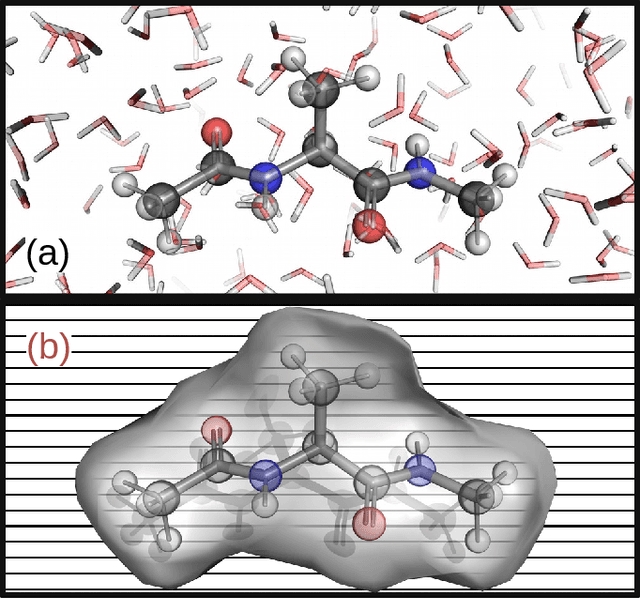
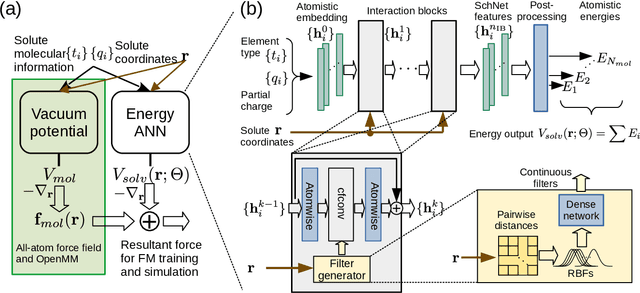
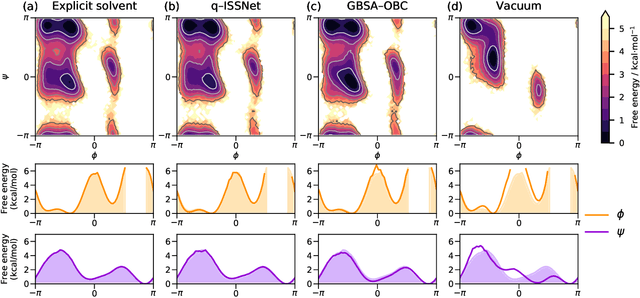
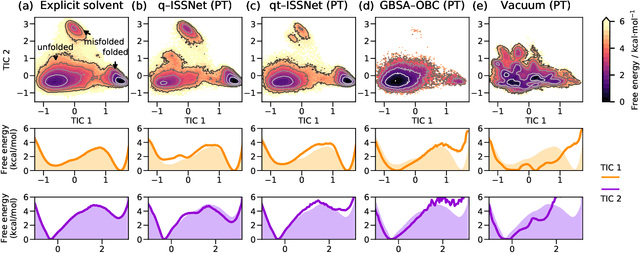
Accurate modeling of the solvent environment for biological molecules is crucial for computational biology and drug design. A popular approach to achieve long simulation time scales for large system sizes is to incorporate the effect of the solvent in a mean-field fashion with implicit solvent models. However, a challenge with existing implicit solvent models is that they often lack accuracy or certain physical properties compared to explicit solvent models, as the many-body effects of the neglected solvent molecules is difficult to model as a mean field. Here, we leverage machine learning (ML) and multi-scale coarse graining (CG) in order to learn implicit solvent models that can approximate the energetic and thermodynamic properties of a given explicit solvent model with arbitrary accuracy, given enough training data. Following the previous ML--CG models CGnet and CGSchnet, we introduce ISSNet, a graph neural network, to model the implicit solvent potential of mean force. ISSNet can learn from explicit solvent simulation data and be readily applied to MD simulations. We compare the solute conformational distributions under different solvation treatments for two peptide systems. The results indicate that ISSNet models can outperform widely-used generalized Born and surface area models in reproducing the thermodynamics of small protein systems with respect to explicit solvent. The success of this novel method demonstrates the potential benefit of applying machine learning methods in accurate modeling of solvent effects for in silico research and biomedical applications.
On Topology Inference for Networked Dynamical Systems: Principles and Performances
Jun 02, 2021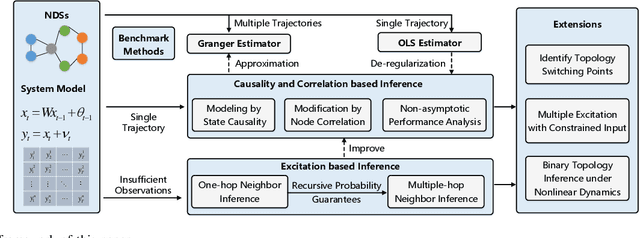
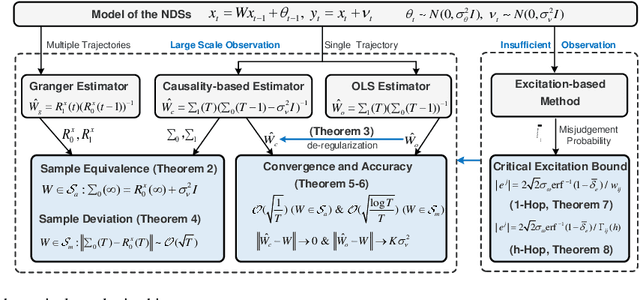
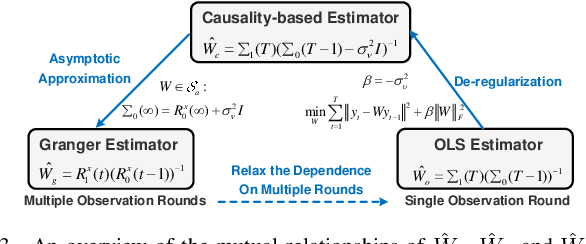
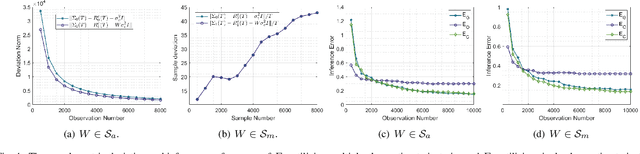
Topology inference for networked dynamical systems (NDSs) plays a crucial role in many areas. Knowledge of the system topology can aid in detecting anomalies, spotting trends, predicting future behavior and so on. Different from the majority of pioneering works, this paper investigates the principles and performances of topology inference from the perspective of node causality and correlation. Specifically, we advocate a comprehensive analysis framework to unveil the mutual relationship, convergence and accuracy of the proposed methods and other benchmark methods, i.e., the Granger and ordinary least square (OLS) estimators. Our method allows for unknown observation noises, both asymptotic and marginal stabilities for NDSs, while encompasses a correlation-based modification design to alleviate performance degradation in small observation scale. To explicitly demonstrate the inference performance of the estimators, we leverage the concentration measure in Gaussian space, and derive the non-asymptotic rates of the inference errors for linear time-invariant (LTI) cases. Considering when the observations are not sufficient to support the estimators, we provide an excitation-based method to infer the one-hop and multi-hop neighbors with probability guarantees. Furthermore, we point out the theoretical results can be extended to switching topologies and nonlinear dynamics cases. Extensive simulations highlight the outperformance of the proposed method.
Decentralized Control of a Hexapod Robot Using a Wireless Time Synchronized Network
Aug 23, 2018
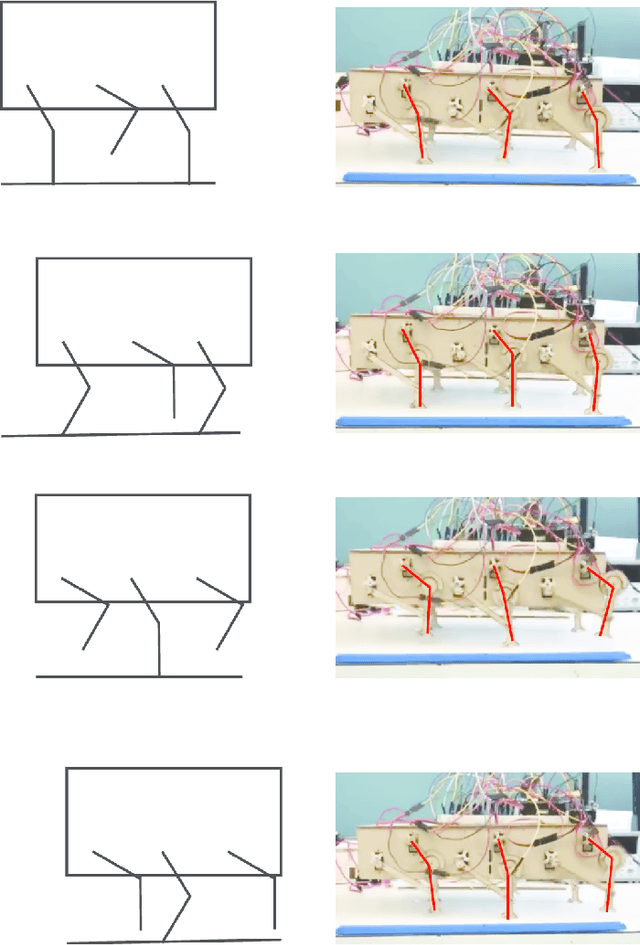

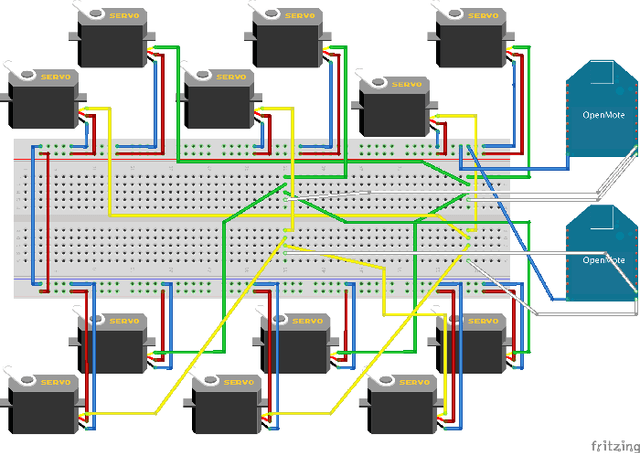
Robots and control systems rely upon precise timing of sensors and actuators in order to operate intelligently. We present a functioning hexapod robot that walks with a dual tripod gait; each tripod is actuated using its own local controller running on a separate wireless node. We compare and report the results of operating the robot using two different decentralized control schemes. With the first scheme, each controller relies on its own local clock to generate control signals for the tripod it controls. With the second scheme, each controller relies on a variable that is local to itself but that is necessarily the same across controllers as a by-product of their host nodes being part of a time synchronized IEEE802.15.4e network. The gait synchronization error (time difference between what both controllers believe is the start of the gait period) grows linearly when the controllers use their local clocks, but remains bounded to within 112 microseconds when the controllers use their nodes' time synchronized local variable.
Asymptotic Performance of TDOA Estimation using Satellites
Jun 02, 2021



We present novel lower bounds on the localization error using a network of satellites randomly deployed on a sphere around Earth. Our new analysis approach characterizes the localization performance by its asymptotic behavior as the number of satellites gets large while assuming a dense network. Using the law of large numbers, we derive closed-form expressions for the asymptotic Cramer Rao bound (CRB) from which we draw valuable insights. The resulting expressions depend solely on the network statistics and are not a function of a particular network configuration. We consider two types of estimators. The first uses the exact statistical model, and hence employs both timing and amplitude information. The second estimator ignores the amplitudes and hence uses only time difference of arrival (TDOA) information. The asymptotic CRB indicates that for practical system setup, a TDOA estimator approaches the performance of the ideal estimator. For both estimators, the localization accuracy improves as satellites get closer to Earth. The latter finding is essential in light of the proliferation of low-Earth-orbit (LEO) satellites and motivates a further study of localization-performance in such networks. Besides, we show that the vertical localization accuracy is lower than the horizontal accuracy and is also more sensitive to the receiver field-of-view.
Identification of the nonlinear steering dynamics of an autonomous vehicle
May 10, 2021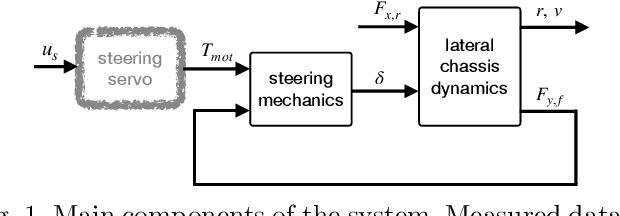

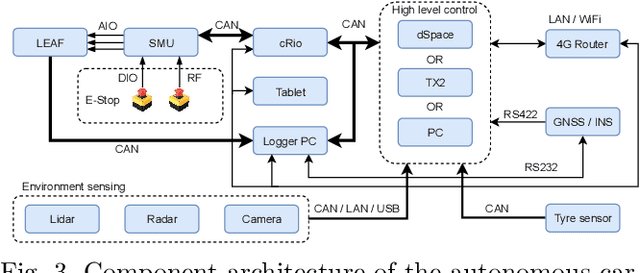
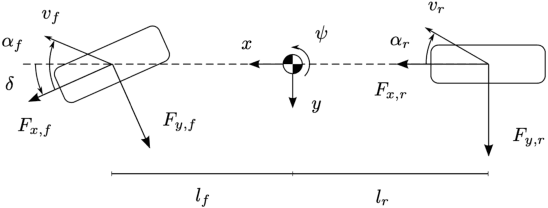
Automated driving applications require accurate vehicle specific models to precisely predict and control the motion dynamics. However, modern vehicles have a wide array of digital and mechatronic components that are difficult to model, manufactures do not disclose all details required for modelling and even existing models of subcomponents require coefficient estimation to match the specific characteristics of each vehicle and their change over time. Hence, it is attractive to use data-driven modelling to capture the relevant vehicle dynamics and synthesise model-based control solutions. In this paper, we address identification of the steering system of an autonomous car based on measured data. We show that the underlying dynamics are highly nonlinear and challenging to be captured, necessitating the use of data-driven methods that fuse the approximation capabilities of learning and the efficiency of dynamic system identification. We demonstrate that such a neural network based subspace-encoder method can successfully capture the underlying dynamics while other methods fall short to provide reliable results.