 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
Jun 14, 2021
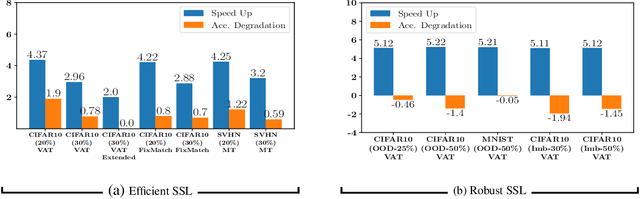


Semi-supervised learning (SSL) algorithms have had great success in recent years in limited labeled data regimes. However, the current state-of-the-art SSL algorithms are computationally expensive and entail significant compute time and energy requirements. This can prove to be a huge limitation for many smaller companies and academic groups. Our main insight is that training on a subset of unlabeled data instead of entire unlabeled data enables the current SSL algorithms to converge faster, thereby reducing the computational costs significantly. In this work, we propose RETRIEVE, a coreset selection framework for efficient and robust semi-supervised learning. RETRIEVE selects the coreset by solving a mixed discrete-continuous bi-level optimization problem such that the selected coreset minimizes the labeled set loss. We use a one-step gradient approximation and show that the discrete optimization problem is approximately submodular, thereby enabling simple greedy algorithms to obtain the coreset. We empirically demonstrate on several real-world datasets that existing SSL algorithms like VAT, Mean-Teacher, FixMatch, when used with RETRIEVE, achieve a) faster training times, b) better performance when unlabeled data consists of Out-of-Distribution(OOD) data and imbalance. More specifically, we show that with minimal accuracy degradation, RETRIEVE achieves a speedup of around 3X in the traditional SSL setting and achieves a speedup of 5X compared to state-of-the-art (SOTA) robust SSL algorithms in the case of imbalance and OOD data.
A Decentralized Multi-UAV Spatio-Temporal Multi-Task Allocation Approach for Perimeter Defense
Feb 15, 2021
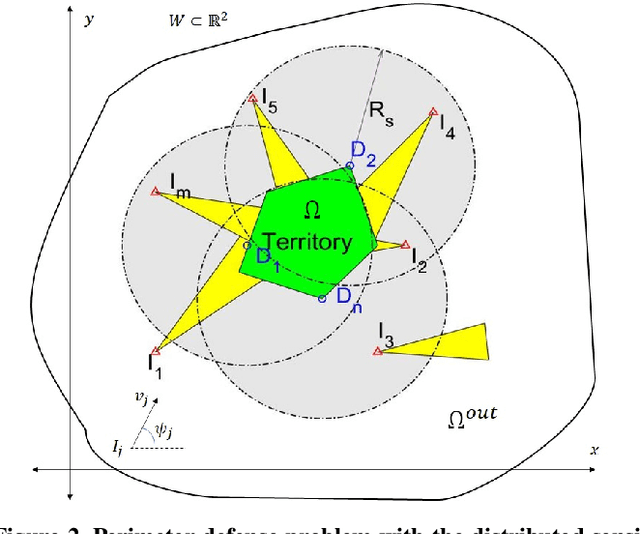
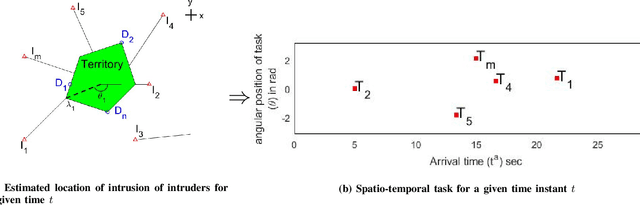
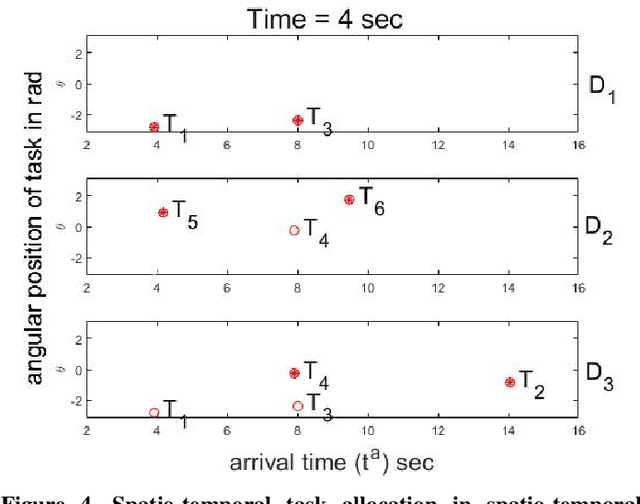
This paper provides a new solution approach to a multi-player perimeter defense game, in which the intruders' team tries to enter the territory, and a team of defenders protects the territory by capturing intruders on the perimeter of the territory. The objective of the defenders is to detect and capture the intruders before the intruders enter the territory. Each defender independently senses the intruder and computes his trajectory to capture the assigned intruders in a cooperative fashion. The intruder is estimated to reach a specific location on the perimeter at a specific time. Each intruder is viewed as a spatio-temporal task, and the defenders are assigned to execute these spatio-temporal tasks. At any given time, the perimeter defense problem is converted into a Decentralized Multi-UAV Spatio-Temporal Multi-Task Allocation (DMUST-MTA) problem. The cost of executing a task for a trajectory is defined by a composite cost function of both the spatial and temporal components. In this paper, a decentralized consensus-based bundle algorithm has been modified to solve the spatio-temporal multi-task allocation problem, and the performance evaluation of the proposed approach is carried out based on Monte-Carlo simulations. The simulation results show the effectiveness of the proposed approach to solve the perimeter defense game under different scenarios. Performance comparison with a state-of-the-art centralized approach with full observability, clearly indicates that DMUST-MTA achieves similar performance in a decentralized way with partial observability conditions with a lesser computational time and easy scaling up.
Reconfigurable Architecture for Spatial Sensing in Wideband Radio Front-End
May 26, 2021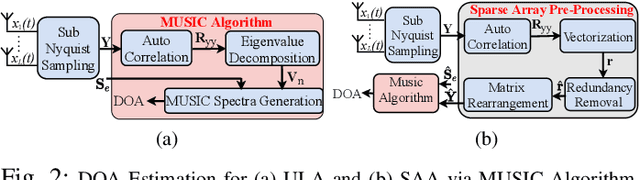
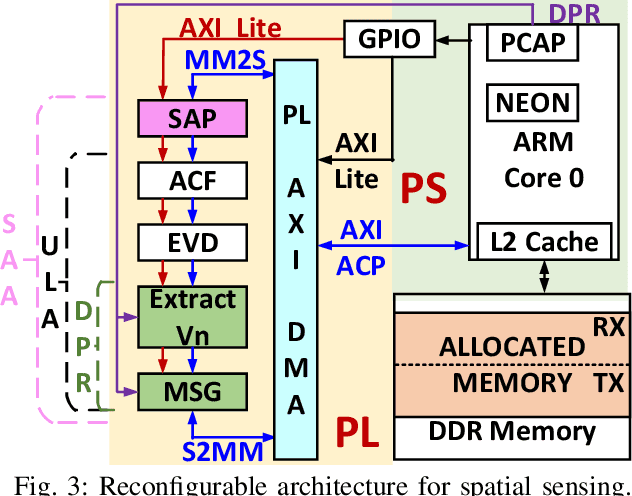
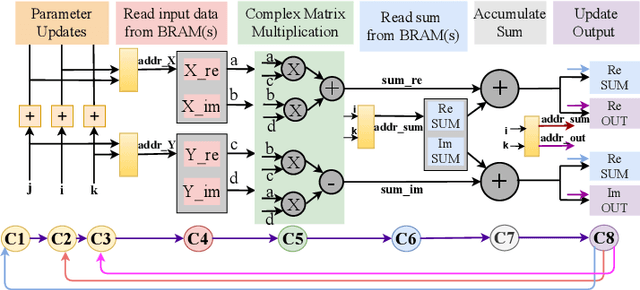
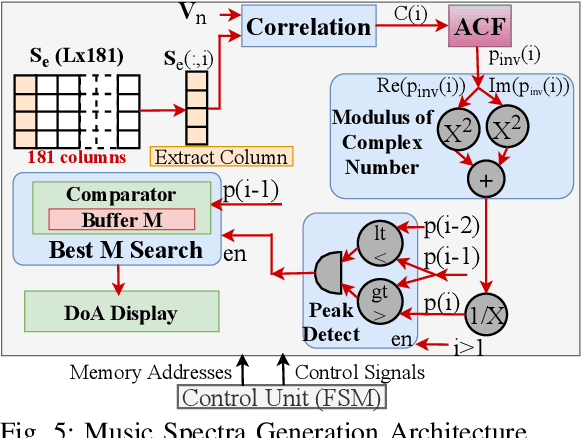
The deployment of cellular spectrum in licensed, shared and unlicensed spectrum demands wideband sensing over non-contiguous sub-6 GHz spectrum. To improve the spectrum and energy efficiency, beamforming and massive multi-antenna systems are being explored which demand spatial sensing i.e. blind identification of vacant frequency bands and direction-of-arrival (DoA) of the occupied bands. We propose a reconfigurable architecture to perform spatial sensing of multi-band spectrum digitized via wideband radio front-end comprising of the sparse antenna array (SAA) and Sub-Nyquist Sampling (SNS). The proposed architecture comprises SAA pre-processing and algorithms to perform spatial sensing directly on SNS samples. The proposed architecture is realized on Zynq System on Chip (SoC), consisting of the ARM processor and FPGA, via hardware-software co-design (HSCD). Using the dynamic partial reconfiguration (DPR), on-the-fly switching between algorithms depending on the number of active signals in the sensed spectrum is enabled. The functionality, resource utilization, and execution time of the proposed architecture are analyzed for various HSCD configurations, word-length, number of digitized samples, signal-to-noise ratio (SNR), and antenna array (sparse/non-sparse).
One Billion Audio Sounds from GPU-enabled Modular Synthesis
Apr 27, 2021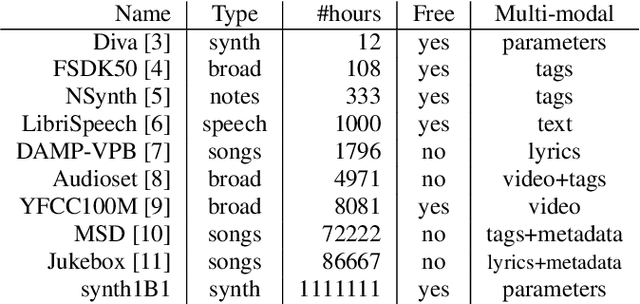
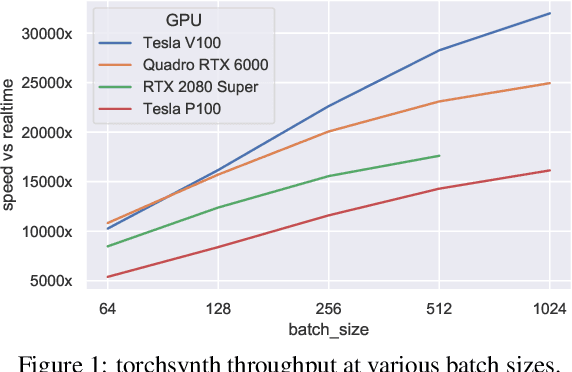
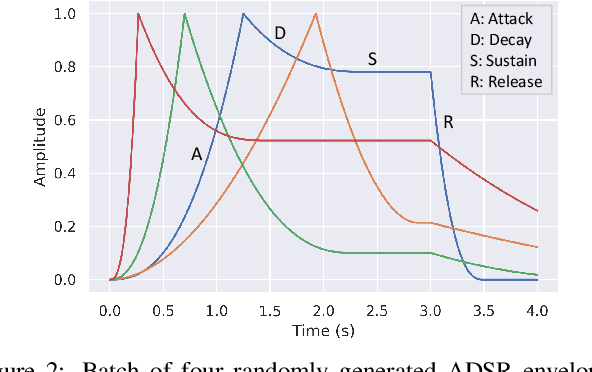
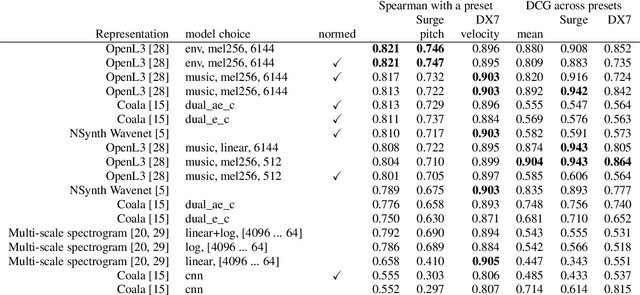
We release synth1B1, a multi-modal audio corpus consisting of 1 billion 4-second synthesized sounds, which is 100x larger than any audio dataset in the literature. Each sound is paired with the corresponding latent parameters used to generate it. synth1B1 samples are deterministically generated on-the-fly 16200x faster than real-time (714MHz) on a single GPU using torchsynth (https://github.com/torchsynth/torchsynth), an open-source modular synthesizer we release. Additionally, we release two new audio datasets: FM synth timbre (https://zenodo.org/record/4677102) and subtractive synth pitch (https://zenodo.org/record/4677097). Using these datasets, we demonstrate new rank-based synthesizer-motivated evaluation criteria for existing audio representations. Finally, we propose novel approaches to synthesizer hyperparameter optimization, and demonstrate how perceptually-correlated auditory distances could enable new applications in synthesizer design.
Polynomial Graph Parsing with Non-Structural Reentrancies
May 06, 2021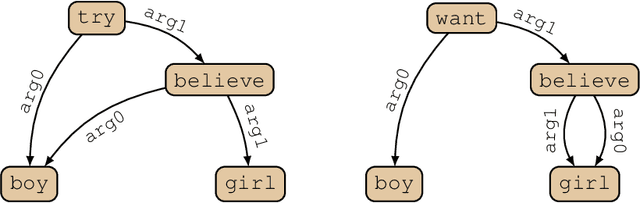

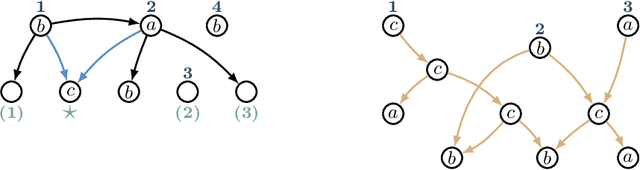
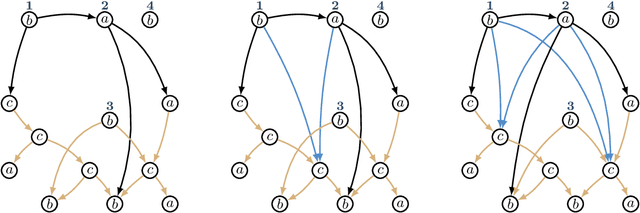
Graph-based semantic representations are valuable in natural language processing, where it is often simple and effective to represent linguistic concepts as nodes, and relations as edges between them. Several attempts has been made to find a generative device that is sufficiently powerful to represent languages of semantic graphs, while at the same allowing efficient parsing. We add to this line of work by introducing graph extension grammar, which consists of an algebra over graphs together with a regular tree grammar that generates expressions over the operations of the algebra. Due to the design of the operations, these grammars can generate graphs with non-structural reentrancies; a type of node-sharing that is excessively common in formalisms such as abstract meaning representation, but for which existing devices offer little support. We provide a parsing algorithm for graph extension grammars, which is proved to be correct and run in polynomial time.
Limitations of machine learning for building energy prediction: ASHRAE Great Energy Predictor III Kaggle competition error analysis
Jun 25, 2021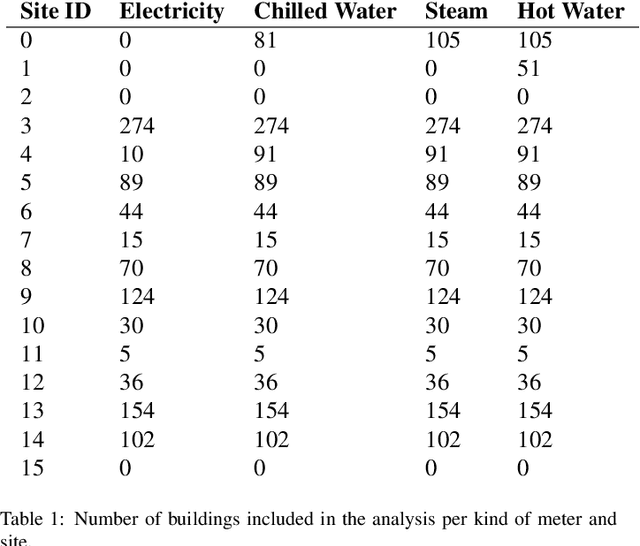
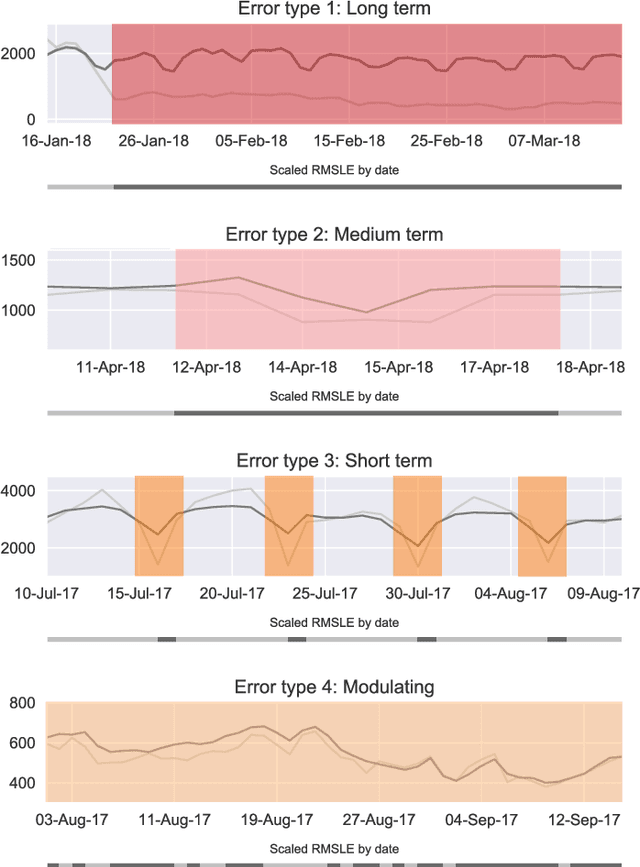
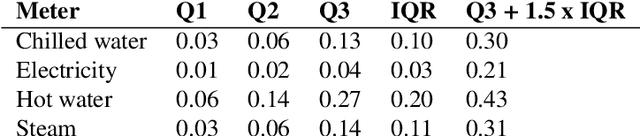
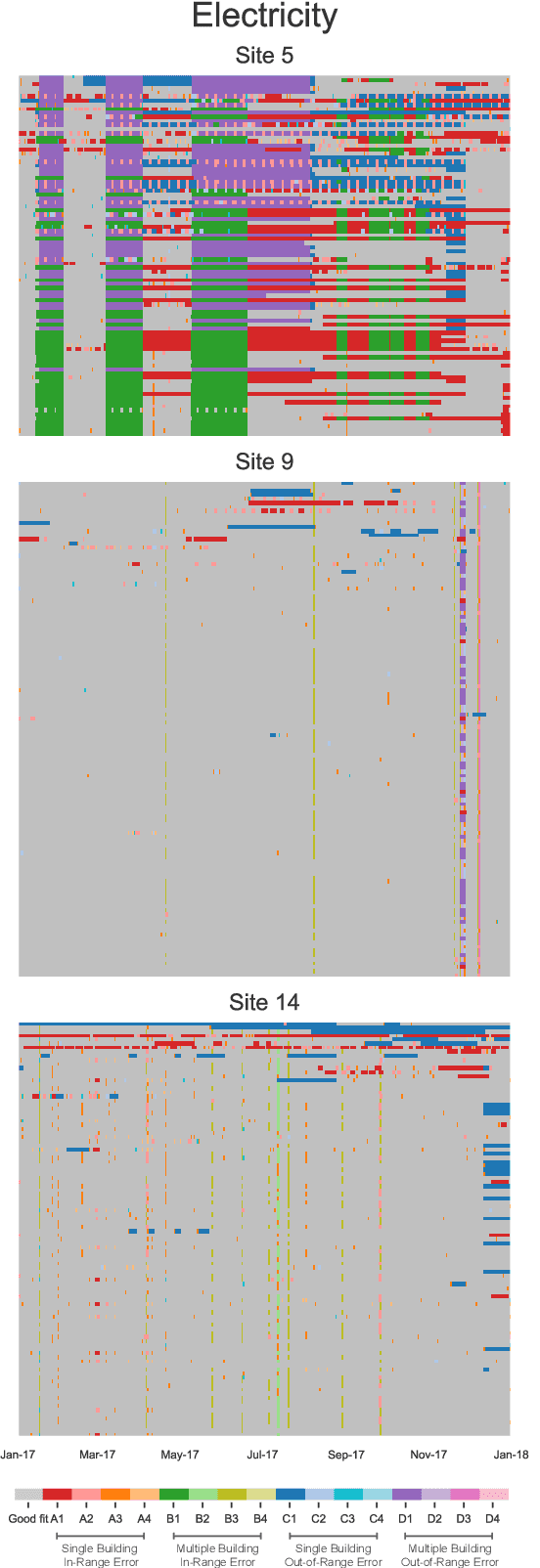
Machine learning for building energy prediction has exploded in popularity in recent years, yet understanding its limitations and potential for improvement are lacking. The ASHRAE Great Energy Predictor III (GEPIII) Kaggle competition was the largest building energy meter machine learning competition ever held with 4,370 participants who submitted 39,403 predictions. The test data set included two years of hourly electricity, hot water, chilled water, and steam readings from 2,380 meters in 1,448 buildings at 16 locations. This paper analyzes the various sources and types of residual model error from an aggregation of the competition's top 50 solutions. This analysis reveals the limitations for machine learning using the standard model inputs of historical meter, weather, and basic building metadata. The types of error are classified according to the amount of time errors occur in each instance, abrupt versus gradual behavior, the magnitude of error, and whether the error existed on single buildings or several buildings at once from a single location. The results show machine learning models have errors within a range of acceptability on 79.1% of the test data. Lower magnitude model errors occur in 16.1% of the test data. These discrepancies can likely be addressed through additional training data sources or innovations in machine learning. Higher magnitude errors occur in 4.8% of the test data and are unlikely to be accurately predicted regardless of innovation. There is a diversity of error behavior depending on the energy meter type (electricity prediction models have unacceptable error in under 10% of test data, while hot water is over 60%) and building use type (public service less than 14%, while technology/science is just over 46%).
SISA: Securing Images by Selective Alteration
Jun 20, 2021
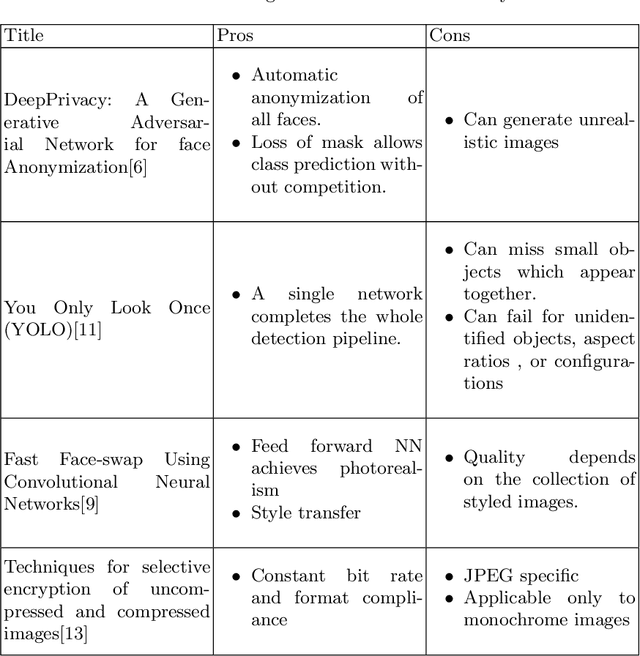
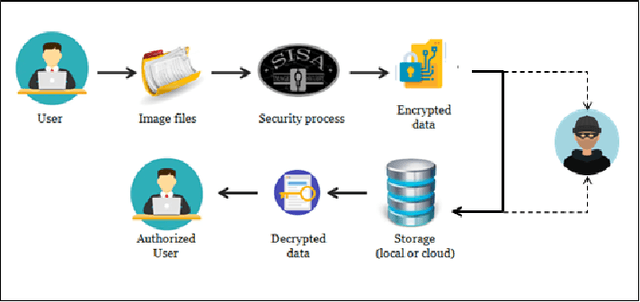

With an increase in mobile and camera devices' popularity, digital content in the form of images has increased drastically. As personal life is being continuously documented in pictures, the risk of losing it to eavesdroppers is a matter of grave concern. Secondary storage is the most preferred medium for the storage of personal and other images. Our work is concerned with the security of such images. While encryption is the best way to ensure image security, full encryption and decryption is a computationally-intensive process. Moreover, as cameras are getting better every day, image quality, and thus, the pixel density has increased considerably. The increased pixel density makes encryption and decryption more expensive. We, therefore, delve into selective encryption and selective blurring based on the region of interest. Instead of encrypting or blurring the entire photograph, we only encode selected regions of the image. We present a comparative analysis of the partial and full encryption of the photos. This kind of encoding will help us lower the encryption overhead without compromising security. The applications utilizing this technique will become more usable due to the reduction in the decryption time. Additionally, blurred images being more readable than encrypted ones, allowed us to define the level of security. We leverage the machine learning algorithms like Mask-RCNN (Region-based convolutional neural network) and YOLO (You Only Look Once) to select the region of interest. These algorithms have set new benchmarks for object recognition. We develop an end to end system to demonstrate our idea of selective encryption.
PDWN: Pyramid Deformable Warping Network for Video Interpolation
Apr 04, 2021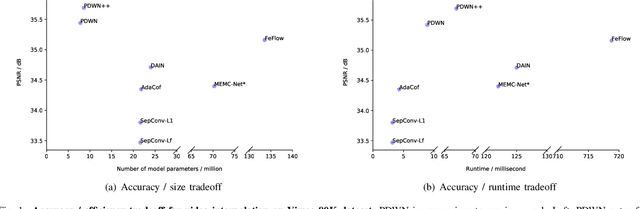
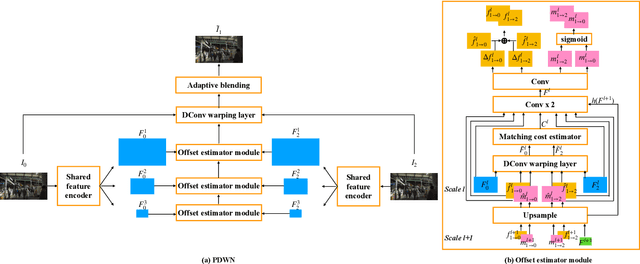


Video interpolation aims to generate a non-existent intermediate frame given the past and future frames. Many state-of-the-art methods achieve promising results by estimating the optical flow between the known frames and then generating the backward flows between the middle frame and the known frames. However, these methods usually suffer from the inaccuracy of estimated optical flows and require additional models or information to compensate for flow estimation errors. Following the recent development in using deformable convolution (DConv) for video interpolation, we propose a light but effective model, called Pyramid Deformable Warping Network (PDWN). PDWN uses a pyramid structure to generate DConv offsets of the unknown middle frame with respect to the known frames through coarse-to-fine successive refinements. Cost volumes between warped features are calculated at every pyramid level to help the offset inference. At the finest scale, the two warped frames are adaptively blended to generate the middle frame. Lastly, a context enhancement network further enhances the contextual detail of the final output. Ablation studies demonstrate the effectiveness of the coarse-to-fine offset refinement, cost volumes, and DConv. Our method achieves better or on-par accuracy compared to state-of-the-art models on multiple datasets while the number of model parameters and the inference time are substantially less than previous models. Moreover, we present an extension of the proposed framework to use four input frames, which can achieve significant improvement over using only two input frames, with only a slight increase in the model size and inference time.
Real-Time Workload Classification during Driving using HyperNetworks
Oct 07, 2018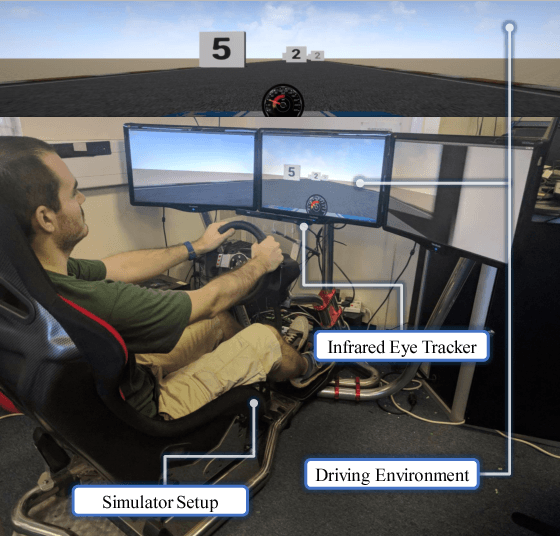
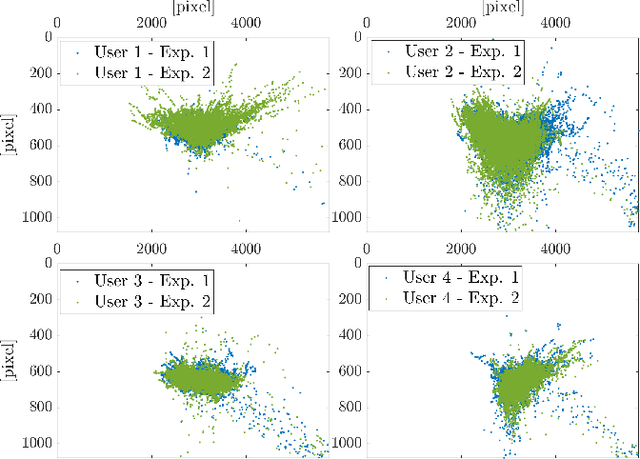
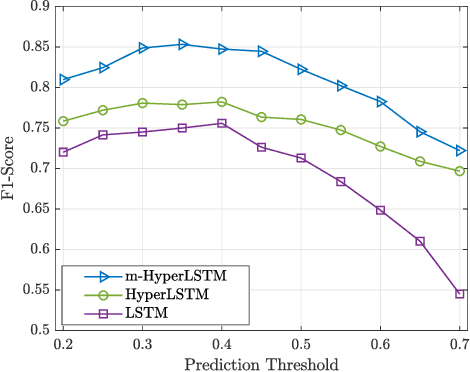
Classifying human cognitive states from behavioral and physiological signals is a challenging problem with important applications in robotics. The problem is challenging due to the data variability among individual users, and sensor artefacts. In this work, we propose an end-to-end framework for real-time cognitive workload classification with mixture Hyper Long Short Term Memory Networks, a novel variant of HyperNetworks. Evaluating the proposed approach on an eye-gaze pattern dataset collected from simulated driving scenarios of different cognitive demands, we show that the proposed framework outperforms previous baseline methods and achieves 83.9\% precision and 87.8\% recall during test. We also demonstrate the merit of our proposed architecture by showing improved performance over other LSTM-based methods.
Dynamic Instance-Wise Classification in Correlated Feature Spaces
Jun 08, 2021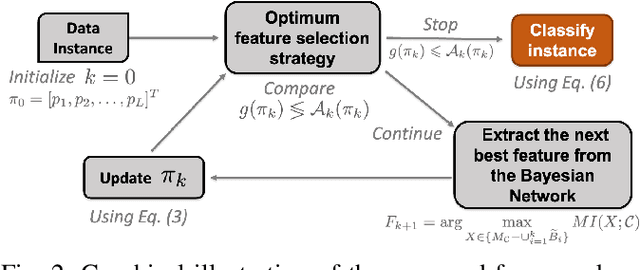
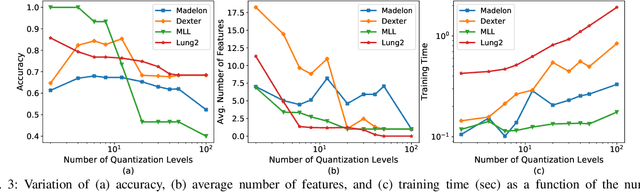
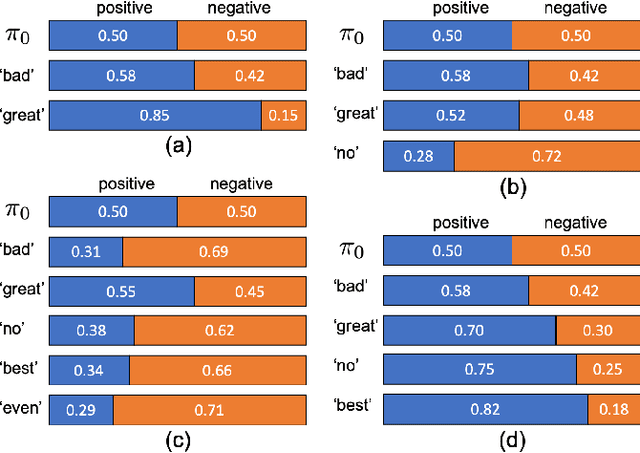
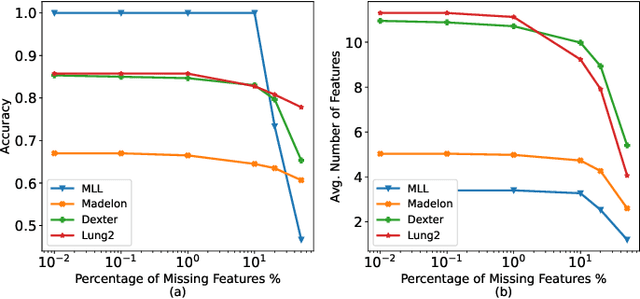
In a typical supervised machine learning setting, the predictions on all test instances are based on a common subset of features discovered during model training. However, using a different subset of features that is most informative for each test instance individually may not only improve prediction accuracy, but also the overall interpretability of the model. At the same time, feature selection methods for classification have been known to be the most effective when many features are irrelevant and/or uncorrelated. In fact, feature selection ignoring correlations between features can lead to poor classification performance. In this work, a Bayesian network is utilized to model feature dependencies. Using the dependency network, a new method is proposed that sequentially selects the best feature to evaluate for each test instance individually, and stops the selection process to make a prediction once it determines that no further improvement can be achieved with respect to classification accuracy. The optimum number of features to acquire and the optimum classification strategy are derived for each test instance. The theoretical properties of the optimum solution are analyzed, and a new algorithm is proposed that takes advantage of these properties to implement a robust and scalable solution for high dimensional settings. The effectiveness, generalizability, and scalability of the proposed method is illustrated on a variety of real-world datasets from diverse application domains.