 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Barbershop: GAN-based Image Compositing using Segmentation Masks
Jun 02, 2021

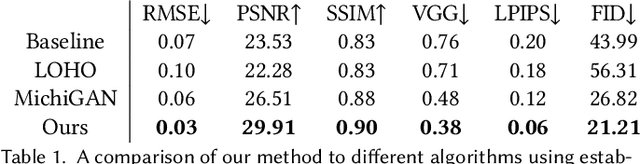
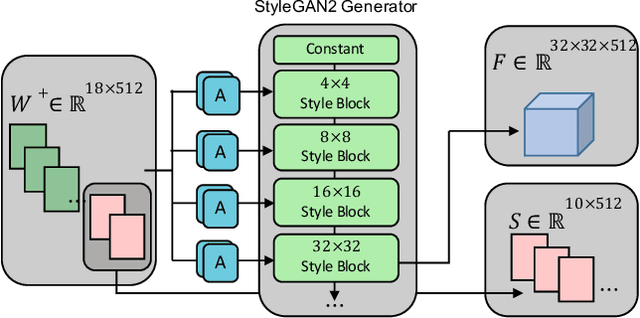

Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains difficult to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending which is better at preserving detail and encoding spatial information, and propose a new GAN-embedding algorithm which is able to slightly modify images to conform to a common segmentation mask. Our novel representation enables the transfer of the visual properties from multiple reference images including specific details such as moles and wrinkles, and because we do image blending in a latent-space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present in other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
On the Complexity of SHAP-Score-Based Explanations: Tractability via Knowledge Compilation and Non-Approximability Results
Apr 16, 2021
In Machine Learning, the $\mathsf{SHAP}$-score is a version of the Shapley value that is used to explain the result of a learned model on a specific entity by assigning a score to every feature. While in general computing Shapley values is an intractable problem, we prove a strong positive result stating that the $\mathsf{SHAP}$-score can be computed in polynomial time over deterministic and decomposable Boolean circuits. Such circuits are studied in the field of Knowledge Compilation and generalize a wide range of Boolean circuits and binary decision diagrams classes, including binary decision trees and Ordered Binary Decision Diagrams (OBDDs). We also establish the computational limits of the SHAP-score by observing that computing it over a class of Boolean models is always polynomially as hard as the model counting problem for that class. This implies that both determinism and decomposability are essential properties for the circuits that we consider. It also implies that computing $\mathsf{SHAP}$-scores is intractable as well over the class of propositional formulas in DNF. Based on this negative result, we look for the existence of fully-polynomial randomized approximation schemes (FPRAS) for computing $\mathsf{SHAP}$-scores over such class. In contrast to the model counting problem for DNF formulas, which admits an FPRAS, we prove that no such FPRAS exists for the computation of $\mathsf{SHAP}$-scores. Surprisingly, this negative result holds even for the class of monotone formulas in DNF. These techniques can be further extended to prove another strong negative result: Under widely believed complexity assumptions, there is no polynomial-time algorithm that checks, given a monotone DNF formula $\varphi$ and features $x,y$, whether the $\mathsf{SHAP}$-score of $x$ in $\varphi$ is smaller than the $\mathsf{SHAP}$-score of $y$ in $\varphi$.
CoDE: Collocation for Demonstration Encoding
May 07, 2021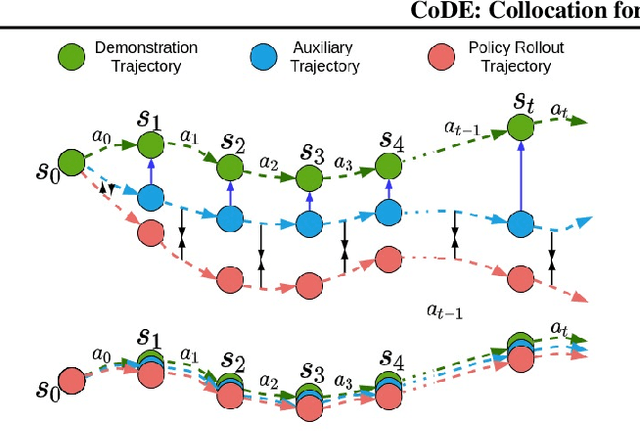
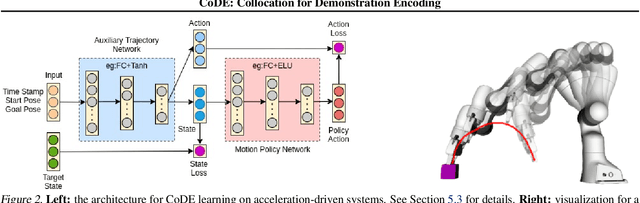
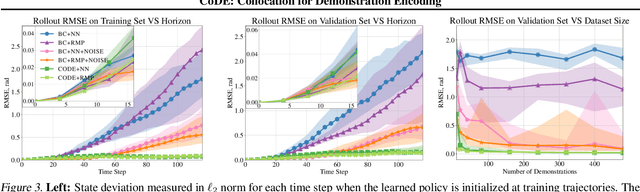
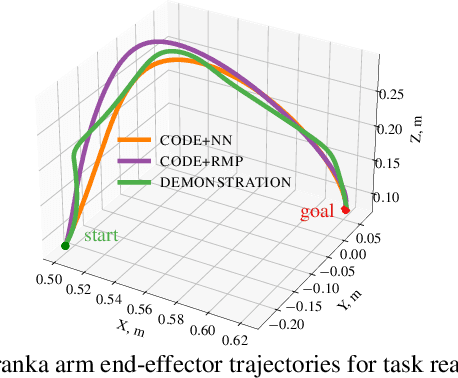
Roboticists frequently turn to Imitation learning (IL) for data efficient policy learning. Many IL methods, canonicalized by the seminal work on Dataset Aggregation (DAgger), combat distributional shift issues with older Behavior Cloning (BC) methods by introducing oracle experts. Unfortunately, access to oracle experts is often unrealistic in practice; data frequently comes from manual offline methods such as lead-through or teleoperation. We present a data-efficient imitation learning technique called Collocation for Demonstration Encoding (CoDE) that operates on only a fixed set of trajectory demonstrations by modeling learning as empirical risk minimization. We circumvent problematic back-propagation through time problems by introducing an auxiliary trajectory network taking inspiration from collocation techniques in optimal control. Our method generalizes well and is much more data efficient than standard BC methods. We present experiments on a 7-degree-of-freedom (DoF) robotic manipulator learning behavior shaping policies for efficient tabletop operation.
Laughing Heads: Can Transformers Detect What Makes a Sentence Funny?
May 19, 2021
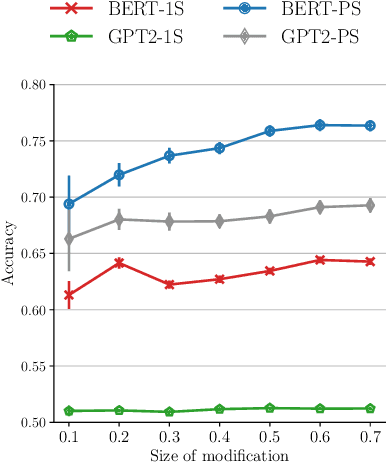
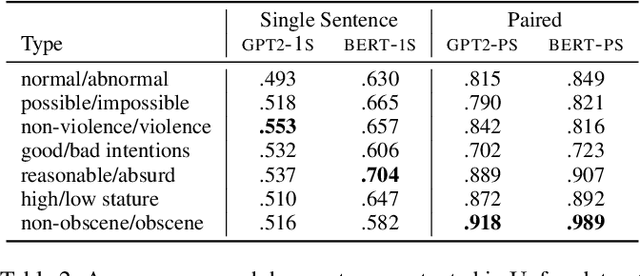
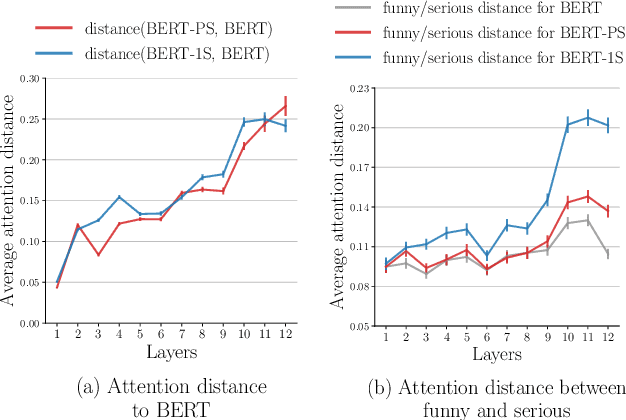
The automatic detection of humor poses a grand challenge for natural language processing. Transformer-based systems have recently achieved remarkable results on this task, but they usually (1)~were evaluated in setups where serious vs humorous texts came from entirely different sources, and (2)~focused on benchmarking performance without providing insights into how the models work. We make progress in both respects by training and analyzing transformer-based humor recognition models on a recently introduced dataset consisting of minimal pairs of aligned sentences, one serious, the other humorous. We find that, although our aligned dataset is much harder than previous datasets, transformer-based models recognize the humorous sentence in an aligned pair with high accuracy (78%). In a careful error analysis, we characterize easy vs hard instances. Finally, by analyzing attention weights, we obtain important insights into the mechanisms by which transformers recognize humor. Most remarkably, we find clear evidence that one single attention head learns to recognize the words that make a test sentence humorous, even without access to this information at training time.
Binary TTC: A Temporal Geofence for Autonomous Navigation
Jan 12, 2021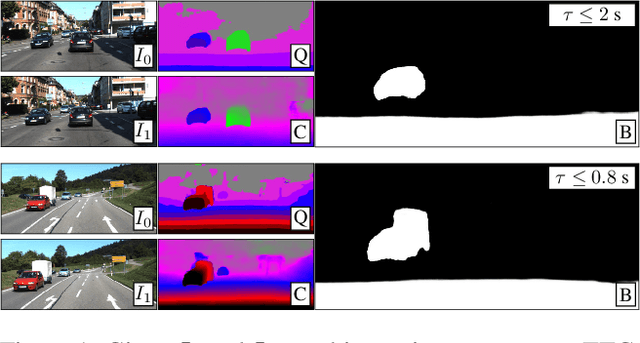
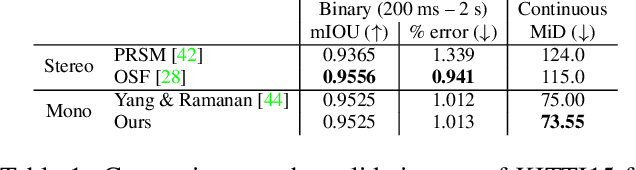

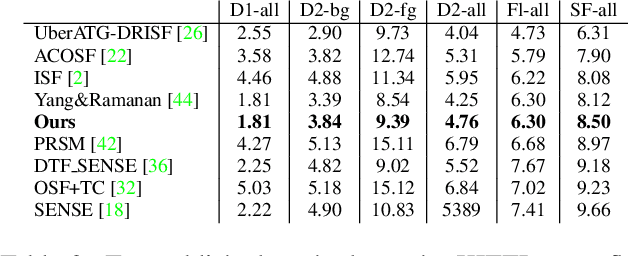
Time-to-contact (TTC), the time for an object to collide with the observer's plane, is a powerful tool for path planning: it is potentially more informative than the depth, velocity, and acceleration of objects in the scene -- even for humans. TTC presents several advantages, including requiring only a monocular, uncalibrated camera. However, regressing TTC for each pixel is not straightforward, and most existing methods make over-simplifying assumptions about the scene. We address this challenge by estimating TTC via a series of simpler, binary classifications. We predict with low latency whether the observer will collide with an obstacle within a certain time, which is often more critical than knowing exact, per-pixel TTC. For such scenarios, our method offers a temporal geofence in 6.4 ms -- over 25x faster than existing methods. Our approach can also estimate per-pixel TTC with arbitrarily fine quantization (including continuous values), when the computational budget allows for it. To the best of our knowledge, our method is the first to offer TTC information (binary or coarsely quantized) at sufficiently high frame-rates for practical use.
An Optimal Reduction of TV-Denoising to Adaptive Online Learning
Jan 26, 2021


We consider the problem of estimating a function from $n$ noisy samples whose discrete Total Variation (TV) is bounded by $C_n$. We reveal a deep connection to the seemingly disparate problem of Strongly Adaptive online learning (Daniely et al, 2015) and provide an $O(n \log n)$ time algorithm that attains the near minimax optimal rate of $\tilde O (n^{1/3}C_n^{2/3})$ under squared error loss. The resulting algorithm runs online and optimally adapts to the unknown smoothness parameter $C_n$. This leads to a new and more versatile alternative to wavelets-based methods for (1) adaptively estimating TV bounded functions; (2) online forecasting of TV bounded trends in time series.
A Scalable and Reproducible System-on-Chip Simulation for Reinforcement Learning
Apr 27, 2021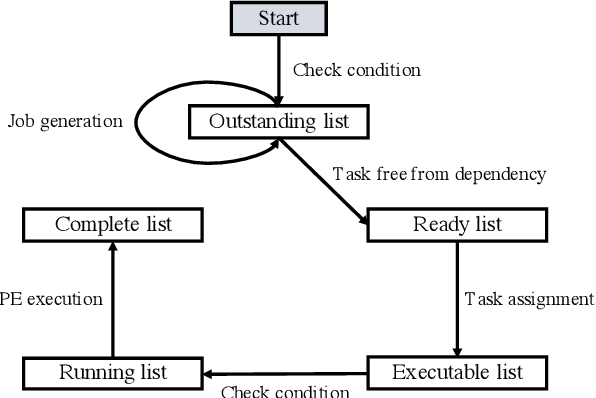
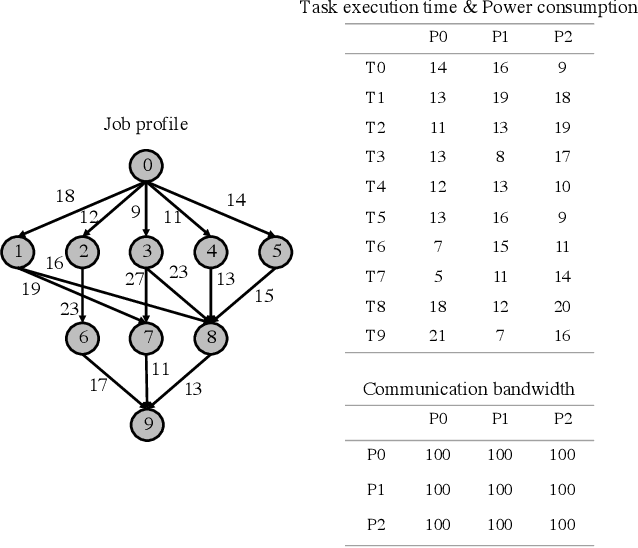
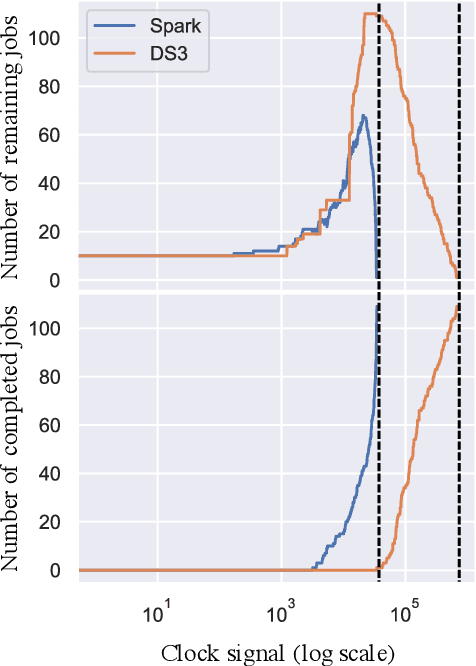
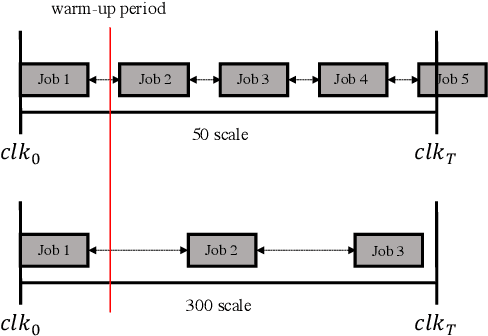
Deep Reinforcement Learning (DRL) underlies in a simulated environment and optimizes objective goals. By extending the conventional interaction scheme, this paper proffers gym-ds3, a scalable and reproducible open environment tailored for a high-fidelity Domain-Specific System-on-Chip (DSSoC) application. The simulation corroborates to schedule hierarchical jobs onto heterogeneous System-on-Chip (SoC) processors and bridges the system to reinforcement learning research. We systematically analyze the representative SoC simulator and discuss the primary challenging aspects that the system (1) continuously generates indefinite jobs at a rapid injection rate, (2) optimizes complex objectives, and (3) operates in steady-state scheduling. We provide exemplary snippets and experimentally demonstrate the run-time performances on different schedulers that successfully mimic results achieved from the standard DS3 framework and real-world embedded systems.
AISPEECH-SJTU accent identification system for the Accented English Speech Recognition Challenge
Feb 19, 2021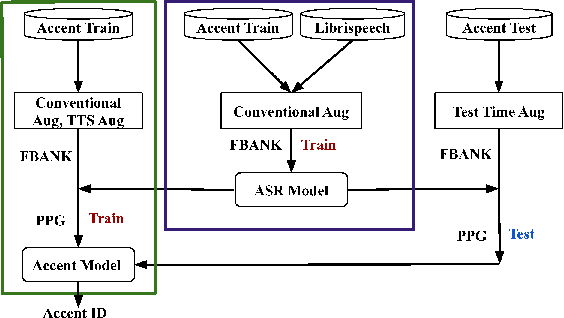
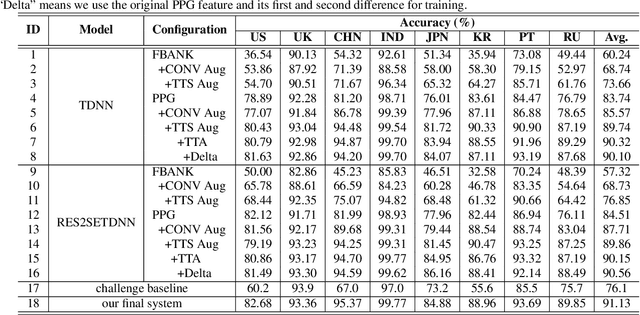
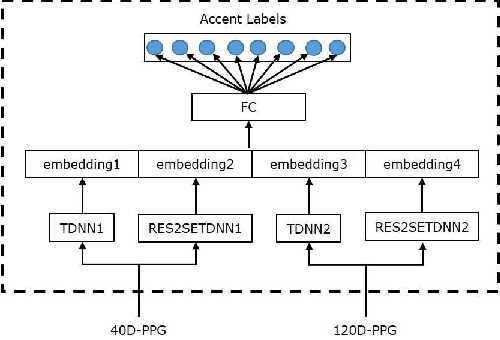
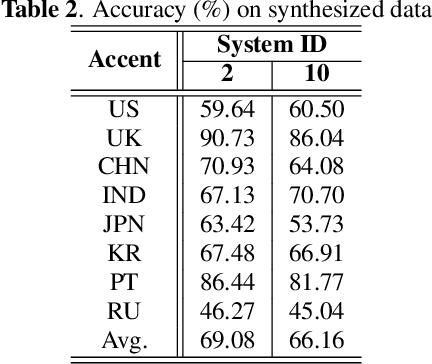
This paper describes the AISpeech-SJTU system for the accent identification track of the Interspeech-2020 Accented English Speech Recognition Challenge. In this challenge track, only 160-hour accented English data collected from 8 countries and the auxiliary Librispeech dataset are provided for training. To build an accurate and robust accent identification system, we explore the whole system pipeline in detail. First, we introduce the ASR based phone posteriorgram (PPG) feature to accent identification and verify its efficacy. Then, a novel TTS based approach is carefully designed to augment the very limited accent training data for the first time. Finally, we propose the test time augmentation and embedding fusion schemes to further improve the system performance. Our final system is ranked first in the challenge and outperforms all the other participants by a large margin. The submitted system achieves 83.63\% average accuracy on the challenge evaluation data, ahead of the others by more than 10\% in absolute terms.
MILP, pseudo-boolean, and OMT solvers for optimal fault-tolerant placements of relay nodes in mission critical wireless networks
Jun 20, 2021
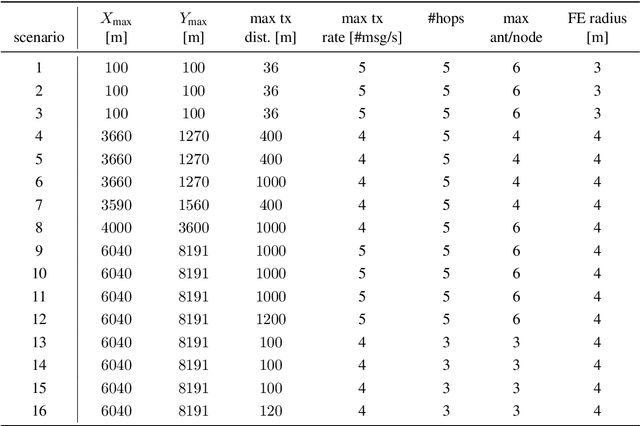
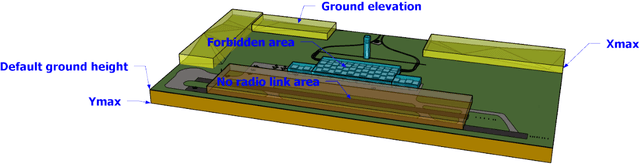
In critical infrastructures like airports, much care has to be devoted in protecting radio communication networks from external electromagnetic interference. Protection of such mission-critical radio communication networks is usually tackled by exploiting radiogoniometers: at least three suitably deployed radiogoniometers, and a gateway gathering information from them, permit to monitor and localise sources of electromagnetic emissions that are not supposed to be present in the monitored area. Typically, radiogoniometers are connected to the gateway through relay nodes. As a result, some degree of fault-tolerance for the network of relay nodes is essential in order to offer a reliable monitoring. On the other hand, deployment of relay nodes is typically quite expensive. As a result, we have two conflicting requirements: minimise costs while guaranteeing a given fault-tolerance. In this paper, we address the problem of computing a deployment for relay nodes that minimises the relay node network cost while at the same time guaranteeing proper working of the network even when some of the relay nodes (up to a given maximum number) become faulty (fault-tolerance). We show that, by means of a computation-intensive pre-processing on a HPC infrastructure, the above optimisation problem can be encoded as a 0/1 Linear Program, becoming suitable to be approached with standard Artificial Intelligence reasoners like MILP, PB-SAT, and SMT/OMT solvers. Our problem formulation enables us to present experimental results comparing the performance of these three solving technologies on a real case study of a relay node network deployment in areas of the Leonardo da Vinci Airport in Rome, Italy.
* 33 pages, 11 figures
Markdowns in E-Commerce Fresh Retail: A Counterfactual Prediction and Multi-Period Optimization Approach
May 19, 2021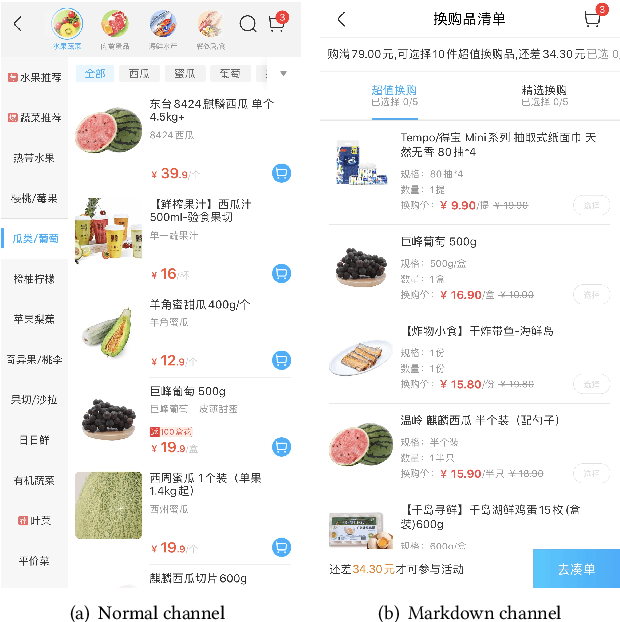

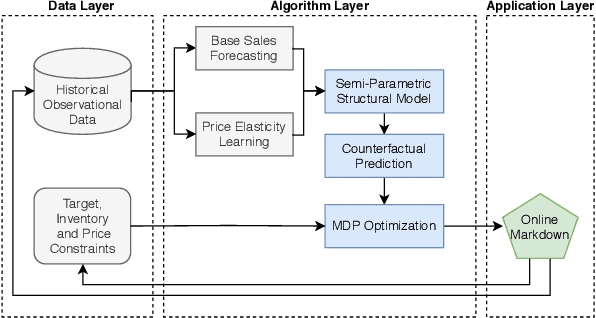
In this paper, by leveraging abundant observational transaction data, we propose a novel data-driven and interpretable pricing approach for markdowns, consisting of counterfactual prediction and multi-period price optimization. Firstly, we build a semi-parametric structural model to learn individual price elasticity and predict counterfactual demand. This semi-parametric model takes advantage of both the predictability of nonparametric machine learning model and the interpretability of economic model. Secondly, we propose a multi-period dynamic pricing algorithm to maximize the overall profit of a perishable product over its finite selling horizon. Different with the traditional approaches that use the deterministic demand, we model the uncertainty of counterfactual demand since it inevitably has randomness in the prediction process. Based on the stochastic model, we derive a sequential pricing strategy by Markov decision process, and design a two-stage algorithm to solve it. The proposed algorithm is very efficient. It reduces the time complexity from exponential to polynomial. Experimental results show the advantages of our pricing algorithm, and the proposed framework has been successfully deployed to the well-known e-commerce fresh retail scenario - Freshippo.