 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VisioRed: A Visualisation Tool for Interpretable Predictive Maintenance
Mar 31, 2021
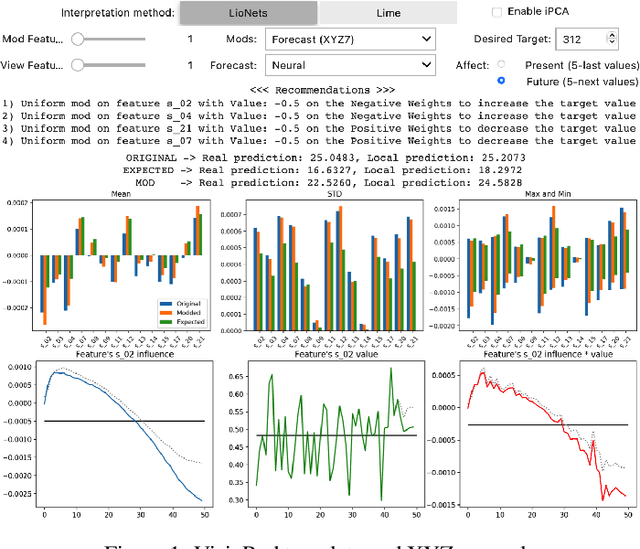
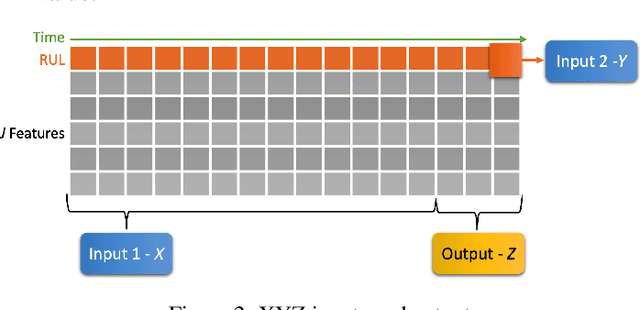
The use of machine learning rapidly increases in high-risk scenarios where decisions are required, for example in healthcare or industrial monitoring equipment. In crucial situations, a model that can offer meaningful explanations of its decision-making is essential. In industrial facilities, the equipment's well-timed maintenance is vital to ensure continuous operation to prevent money loss. Using machine learning, predictive and prescriptive maintenance attempt to anticipate and prevent eventual system failures. This paper introduces a visualisation tool incorporating interpretations to display information derived from predictive maintenance models, trained on time-series data.
Spatiotemporal Spike-Pattern Selectivity in Single Mixed-Signal Neurons with Balanced Synapses
Jun 10, 2021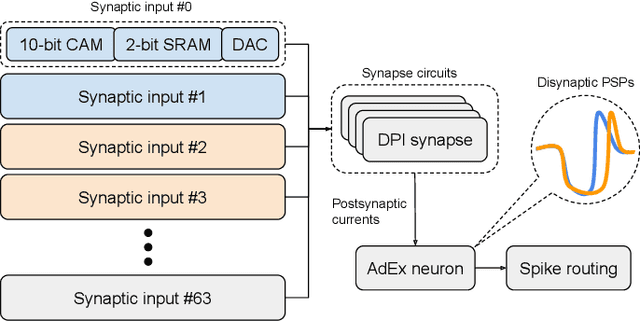
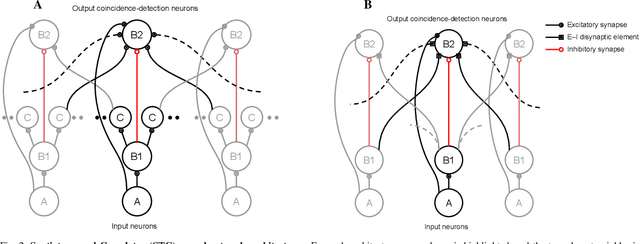
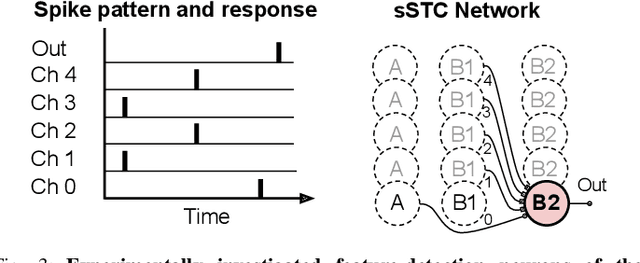
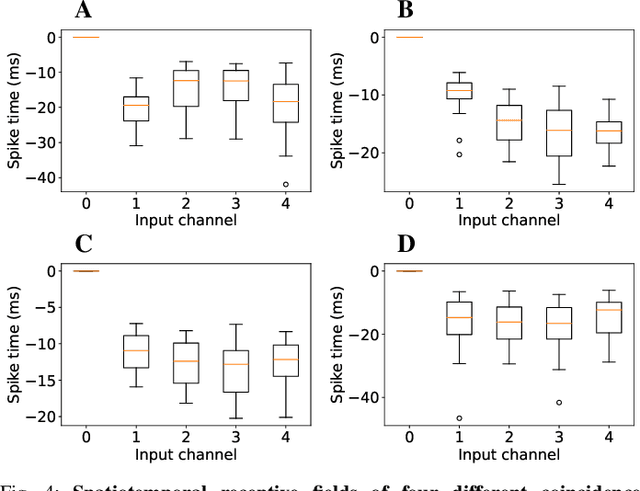
Realizing the potential of mixed-signal neuromorphic processors for ultra-low-power inference and learning requires efficient use of their inhomogeneous analog circuitry as well as sparse, time-based information encoding and processing. Here, we investigate spike-timing-based spatiotemporal receptive fields of output-neurons in the Spatiotemporal Correlator (STC) network, for which we used excitatory-inhibitory balanced disynaptic inputs instead of dedicated axonal or neuronal delays. We present hardware-in-the-loop experiments with a mixed-signal DYNAP-SE neuromorphic processor, in which five-dimensional receptive fields of hardware neurons were mapped by randomly sampling input spike-patterns from a uniform distribution. We find that, when the balanced disynaptic elements are randomly programmed, some of the neurons display distinct receptive fields. Furthermore, we demonstrate how a neuron was tuned to detect a particular spatiotemporal feature, to which it initially was non-selective, by activating a different subset of the inhomogeneous analog synaptic circuits. The energy dissipation of the balanced synaptic elements is one order of magnitude lower per lateral connection (0.65 nJ vs 9.3 nJ per spike) than former delay-based neuromorphic hardware implementations. Thus, we show how the inhomogeneous synaptic circuits could be utilized for resource-efficient implementation of STC network layers, in a way that enables synapse-address reprogramming as a discrete mechanism for feature tuning.
Time-Contrastive Learning Based Deep Bottleneck Features for Text-Dependent Speaker Verification
May 11, 2019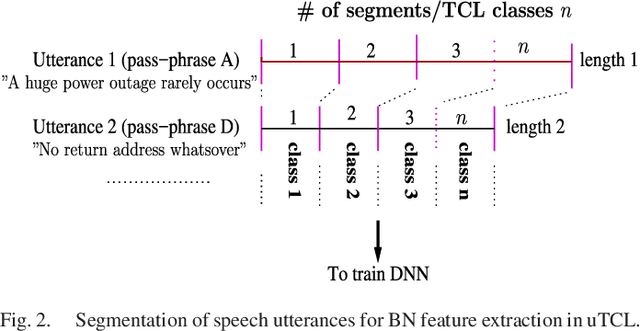
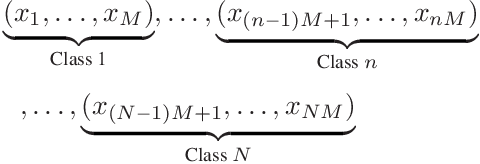
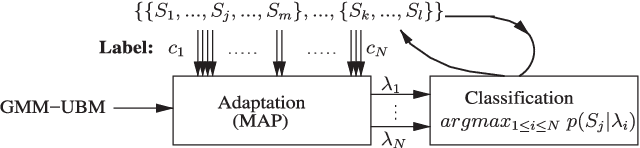
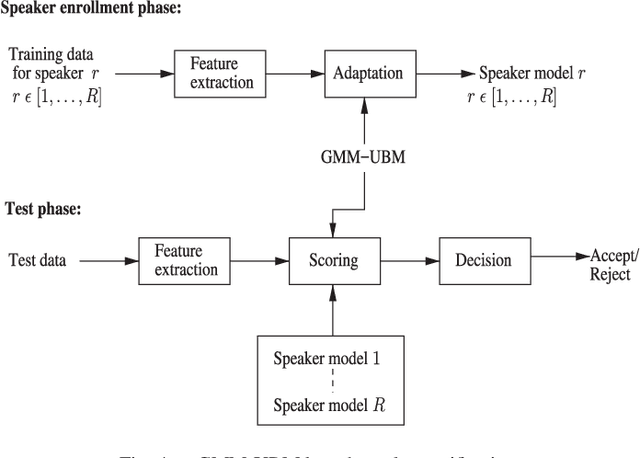
There are a number of studies about extraction of bottleneck (BN) features from deep neural networks (DNNs)trained to discriminate speakers, pass-phrases and triphone states for improving the performance of text-dependent speaker verification (TD-SV). However, a moderate success has been achieved. A recent study [1] presented a time contrastive learning (TCL) concept to explore the non-stationarity of brain signals for classification of brain states. Speech signals have similar non-stationarity property, and TCL further has the advantage of having no need for labeled data. We therefore present a TCL based BN feature extraction method. The method uniformly partitions each speech utterance in a training dataset into a predefined number of multi-frame segments. Each segment in an utterance corresponds to one class, and class labels are shared across utterances. DNNs are then trained to discriminate all speech frames among the classes to exploit the temporal structure of speech. In addition, we propose a segment-based unsupervised clustering algorithm to re-assign class labels to the segments. TD-SV experiments were conducted on the RedDots challenge database. The TCL-DNNs were trained using speech data of fixed pass-phrases that were excluded from the TD-SV evaluation set, so the learned features can be considered phrase-independent. We compare the performance of the proposed TCL bottleneck (BN) feature with those of short-time cepstral features and BN features extracted from DNNs discriminating speakers, pass-phrases, speaker+pass-phrase, as well as monophones whose labels and boundaries are generated by three different automatic speech recognition (ASR) systems. Experimental results show that the proposed TCL-BN outperforms cepstral features and speaker+pass-phrase discriminant BN features, and its performance is on par with those of ASR derived BN features. Moreover,....
* Copyright (c) 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
HELP: Hardware-Adaptive Efficient Latency Predictor for NAS via Meta-Learning
Jun 16, 2021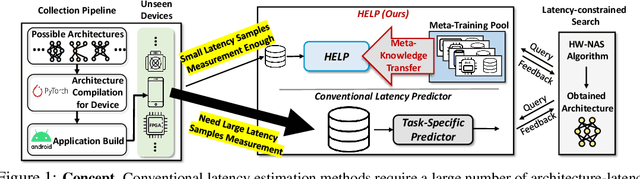
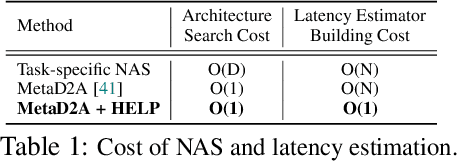
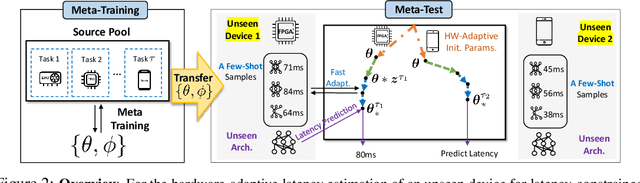
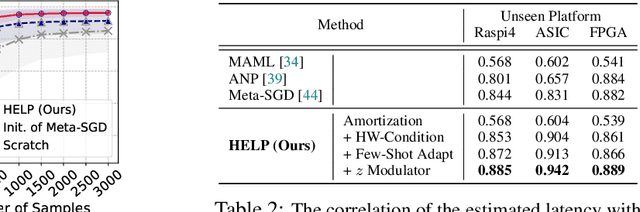
For deployment, neural architecture search should be hardware-aware, in order to satisfy the device-specific constraints (e.g., memory usage, latency and energy consumption) and enhance the model efficiency. Existing methods on hardware-aware NAS collect a large number of samples (e.g., accuracy and latency) from a target device, either builds a lookup table or a latency estimator. However, such approach is impractical in real-world scenarios as there exist numerous devices with different hardware specifications, and collecting samples from such a large number of devices will require prohibitive computational and monetary cost. To overcome such limitations, we propose Hardware-adaptive Efficient Latency Predictor (HELP), which formulates the device-specific latency estimation problem as a meta-learning problem, such that we can estimate the latency of a model's performance for a given task on an unseen device with a few samples. To this end, we introduce novel hardware embeddings to embed any devices considering them as black-box functions that output latencies, and meta-learn the hardware-adaptive latency predictor in a device-dependent manner, using the hardware embeddings. We validate the proposed HELP for its latency estimation performance on unseen platforms, on which it achieves high estimation performance with as few as 10 measurement samples, outperforming all relevant baselines. We also validate end-to-end NAS frameworks using HELP against ones without it, and show that it largely reduces the total time cost of the base NAS method, in latency-constrained settings.
Mediating between Contact Feasibility and Robustness of Trajectory Optimization through Chance Complementarity Constraints
May 20, 2021
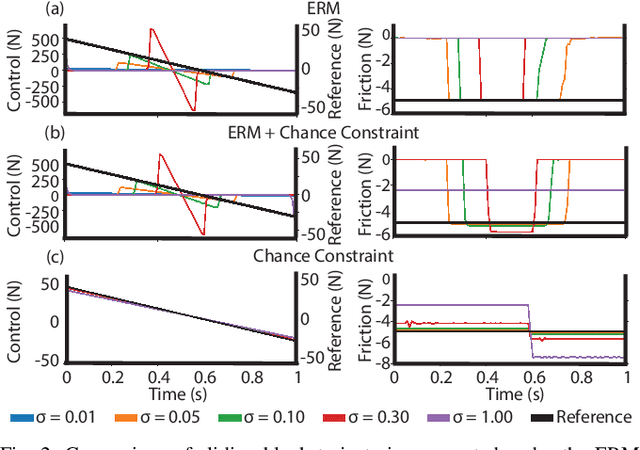
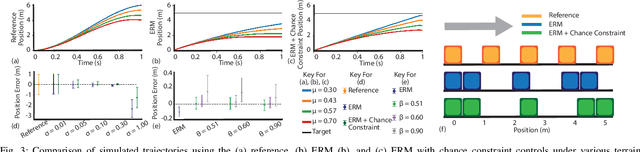
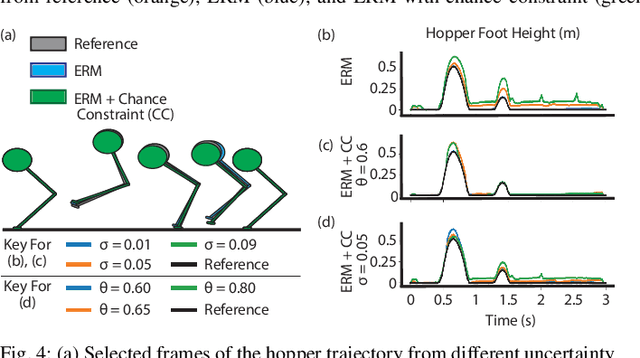
As robots move from the laboratory into the real world, motion planning will need to account for model uncertainty and risk. For robot motions involving intermittent contact, planning for uncertainty in contact is especially important, as failure to successfully make and maintain contact can be catastrophic. Here, we model uncertainty in terrain geometry and friction characteristics, and combine a risk-sensitive objective with chance constraints to provide a trade-off between robustness to uncertainty and constraint satisfaction with an arbitrarily high feasibility guarantee. We evaluate our approach in two simple examples: a push-block system for benchmarking and a single-legged hopper. We demonstrate that chance constraints alone produce trajectories similar to those produced using strict complementarity constraints; however, when equipped with a robust objective, we show the chance constraints can mediate a trade-off between robustness to uncertainty and strict constraint satisfaction and also reduce the solve time compared to using the robust cost alone. Thus, our study may represent an important step towards reasoning about contact uncertainty in motion planning.
End-to-End Deep Fault Tolerant Control
May 28, 2021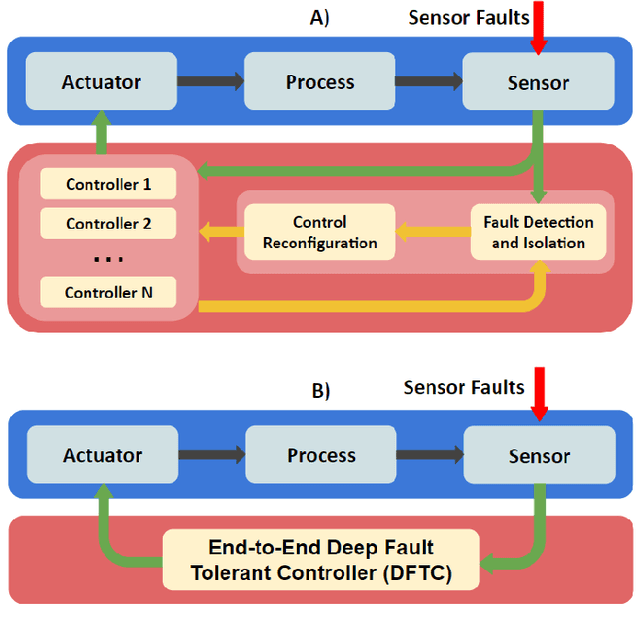
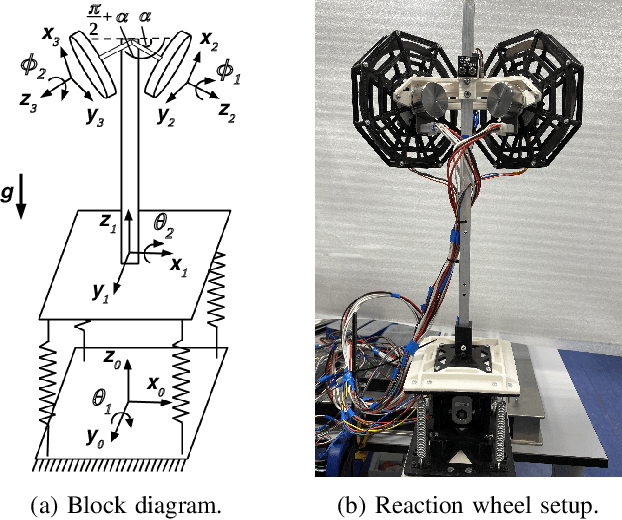
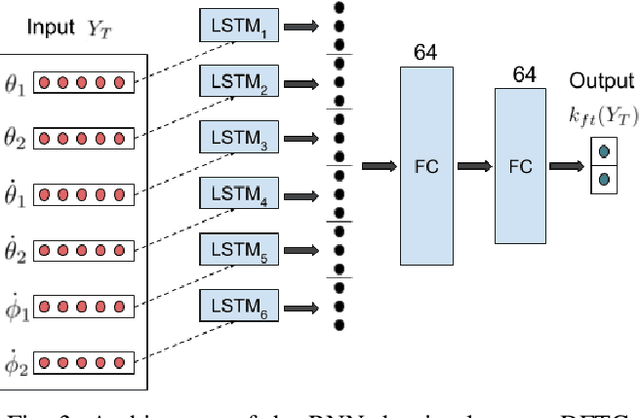
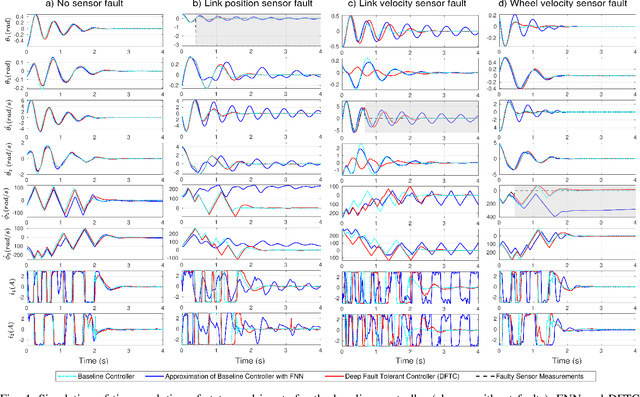
Ideally, accurate sensor measurements are needed to achieve a good performance in the closed-loop control of mechatronic systems. As a consequence, sensor faults will prevent the system from working correctly, unless a fault-tolerant control (FTC) architecture is adopted. As model-based FTC algorithms for nonlinear systems are often challenging to design, this paper focuses on a new method for FTC in the presence of sensor faults, based on deep learning. The considered approach replaces the phases of fault detection and isolation and controller design with a single recurrent neural network, which has the value of past sensor measurements in a given time window as input, and the current values of the control variables as output. This end-to-end deep FTC method is applied to a mechatronic system composed of a spherical inverted pendulum, whose configuration is changed via reaction wheels, in turn actuated by electric motors. The simulation and experimental results show that the proposed method can handle abrupt faults occurring in link position/velocity sensors. The provided supplementary material includes a video of real-world experiments and the software source code.
Augmenting Scientific Papers with Just-in-Time, Position-Sensitive Definitions of Terms and Symbols
Sep 29, 2020
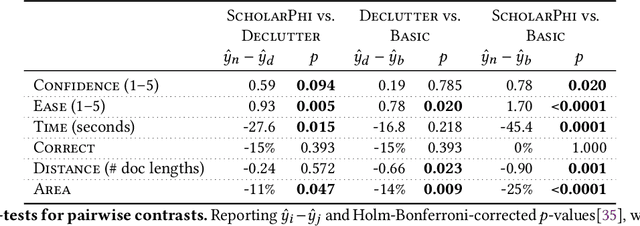

Despite the central importance of research papers to scientific progress, they can be difficult to read. Comprehension is often stymied when the information needed to understand a passage resides somewhere else: in another section, or in another paper. In this work, we envision how interfaces can bring definitions of technical terms and symbols to readers when and where they need them most. We introduce ScholarPhi, an augmented reading interface with four novel features: (1) tooltips that surface position-sensitive definitions from elsewhere in a paper, (2) a filter over the paper that "declutters" it to reveal how the term or symbol is used across the paper, (3) automatic equation diagrams that expose multiple definitions in parallel, and (4) an automatically generated glossary of important terms and symbols. A usability study showed that the tool helps researchers of all experience levels read papers. Furthermore, researchers were eager to have ScholarPhi's definitions available to support their everyday reading.
Computer Users Have Unique Yet Temporally Inconsistent Computer Usage Profiles
May 20, 2021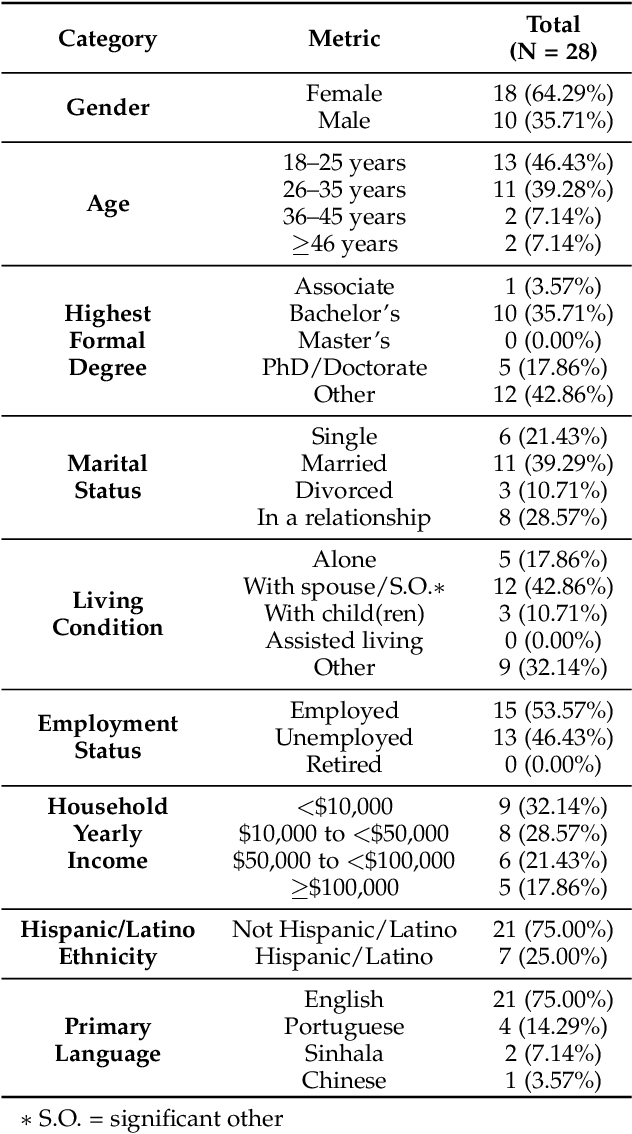
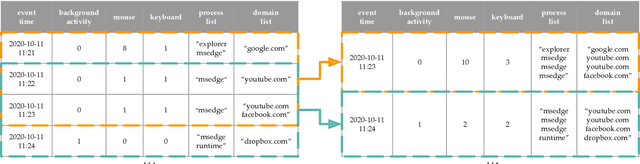
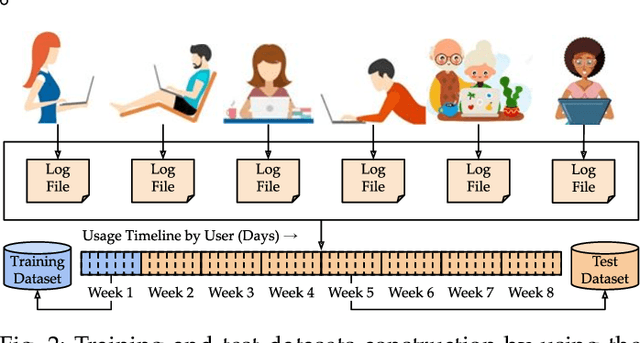
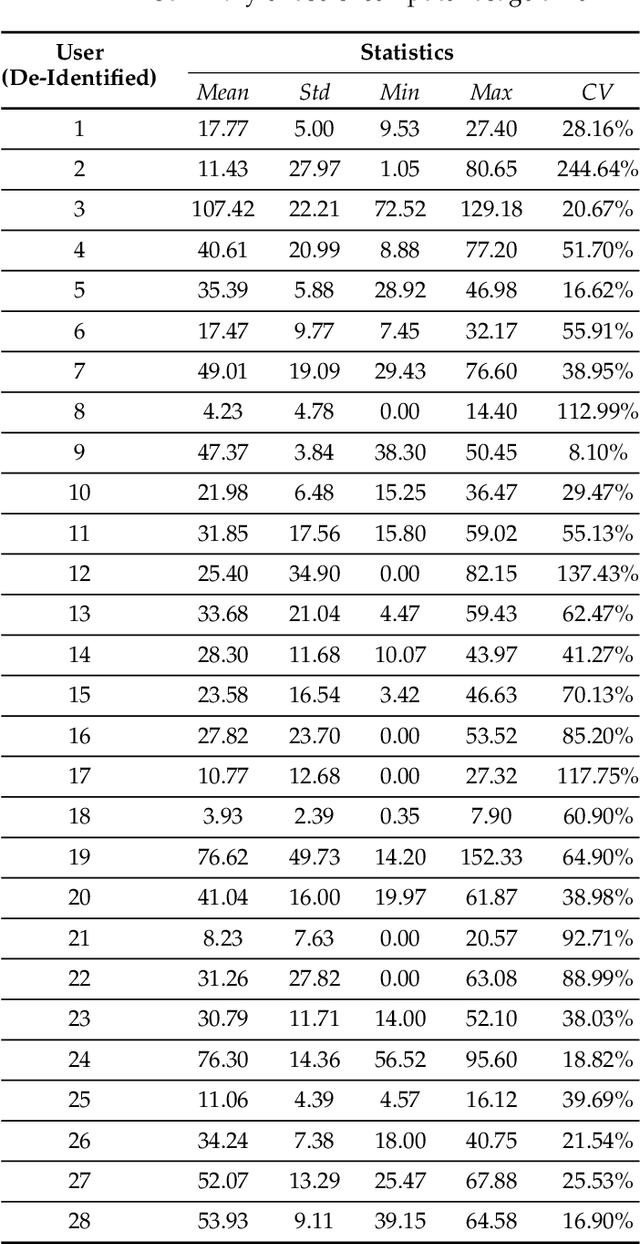
This paper investigates whether computer usage profiles comprised of process-, network-, mouse- and keystroke-related events are unique and temporally consistent in a naturalistic setting, discussing challenges and opportunities of using such profiles in applications of continuous authentication. We collected ecologically-valid computer usage profiles from 28 MS Windows 10 computer users over 8 weeks and submitted this data to comprehensive machine learning analysis involving a diverse set of online and offline classifiers. We found that (i) computer usage profiles have the potential to uniquely characterize computer users (with a maximum F-score of 99.94%); (ii) network-related events were the most useful features to properly recognize profiles (95.14% of the top features distinguishing users being network-related); (iii) user profiles were mostly inconsistent over the 8-week data collection period, with 92.86% of users exhibiting drifts in terms of time and usage habits; and (iv) online models are better suited to handle computer usage profiles compared to offline models (maximum F-score for each approach was 95.99% and 99.94%, respectively).
Clustering Time Series with Nonlinear Dynamics: A Bayesian Non-Parametric and Particle-Based Approach
Oct 24, 2018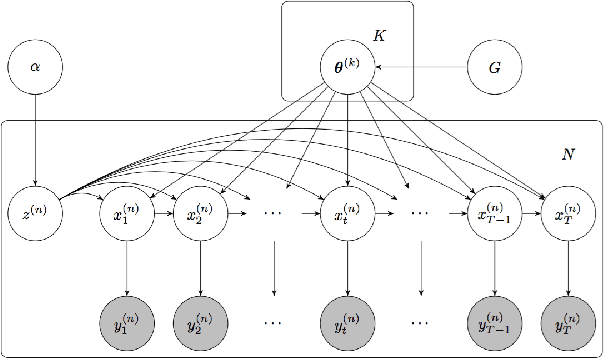



We propose a statistical framework for clustering multiple time series that exhibit nonlinear dynamics into an a-priori-unknown number of sub-groups that each comprise time series with similar dynamics. Our motivation comes from neuroscience where an important problem is to identify, within a large assembly of neurons, sub-groups that respond similarly to a stimulus or contingency. In the neural setting, conditioned on cluster membership and the parameters governing the dynamics, time series within a cluster are assumed independent and generated according to a nonlinear binomial state-space model. We derive a Metropolis-within-Gibbs algorithm for full Bayesian inference that alternates between sampling of cluster membership and sampling of parameters of interest. The Metropolis step is a PMMH iteration that requires an unbiased, low variance estimate of the likelihood function of a nonlinear state-space model. We leverage recent results on controlled sequential Monte Carlo to estimate likelihood functions more efficiently compared to the bootstrap particle filter. We apply the framework to time series acquired from the prefrontal cortex of mice in an experiment designed to characterize the neural underpinnings of fear.
Augmentation Inside the Network
Dec 19, 2020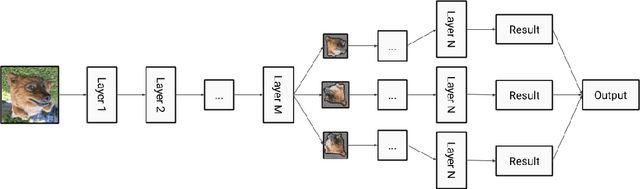
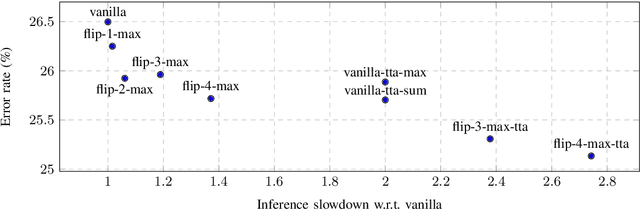
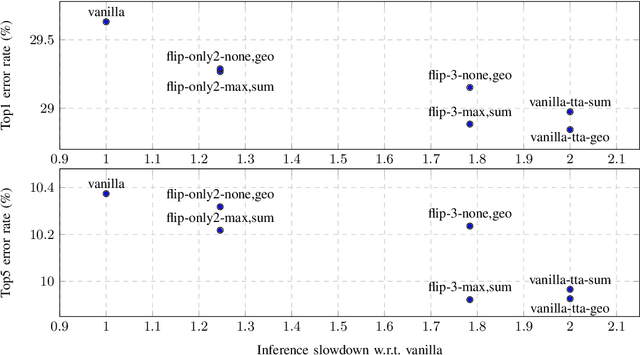
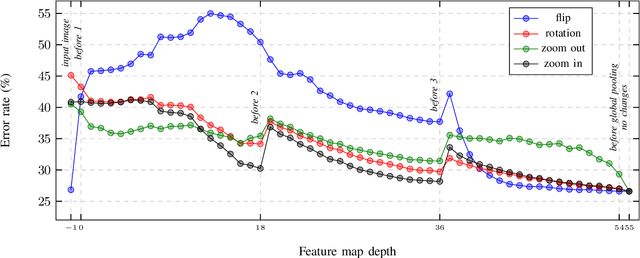
In this paper, we present augmentation inside the network, a method that simulates data augmentation techniques for computer vision problems on intermediate features of a convolutional neural network. We perform these transformations, changing the data flow through the network, and sharing common computations when it is possible. Our method allows us to obtain smoother speed-accuracy trade-off adjustment and achieves better results than using standard test-time augmentation (TTA) techniques. Additionally, our approach can improve model performance even further when coupled with test-time augmentation. We validate our method on the ImageNet-2012 and CIFAR-100 datasets for image classification. We propose a modification that is 30% faster than the flip test-time augmentation and achieves the same results for CIFAR-100.