 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Speed Planning Using Bezier Polynomials with Trapezoidal Corridors
Apr 23, 2021
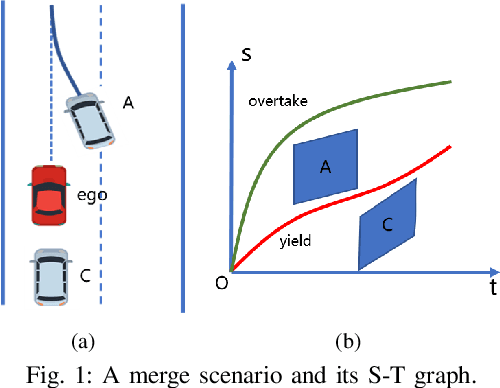
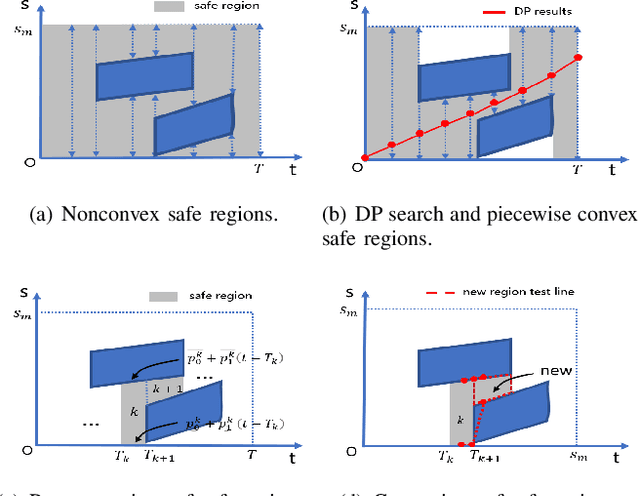
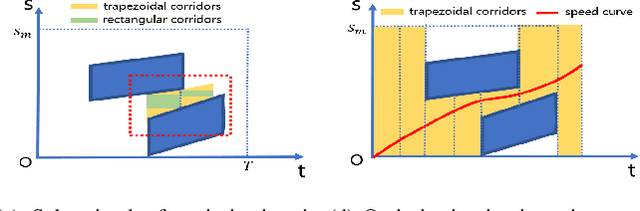

To generate safe and real-time trajectories for an autonomous vehicle in dynamic environments, path and speed decoupled planning methods are often considered. This paper studies speed planning, which mainly deals with dynamic obstacle avoidance given the planning path. The main challenges lie in the decisions in non-convex space and the trade-off between safety, comfort and efficiency performances. This work uses dynamic programming to search heuristic waypoints on the S-T graph and to construct convex feasible spaces. Further, a piecewise Bezier polynomials optimization approach with trapezoidal corridors is presented, which theoretically guarantees the safety and optimality of the trajectory. The simulations verify the effectiveness of the proposed approach.
ACNet: Mask-Aware Attention with Dynamic Context Enhancement for Robust Acne Detection
May 31, 2021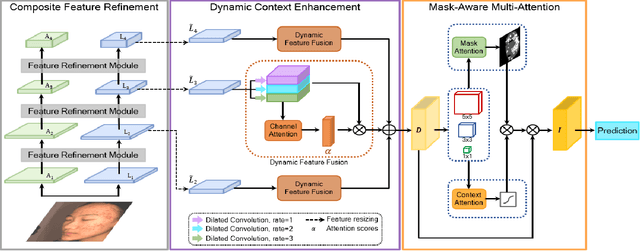
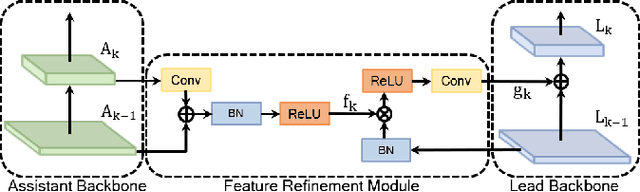
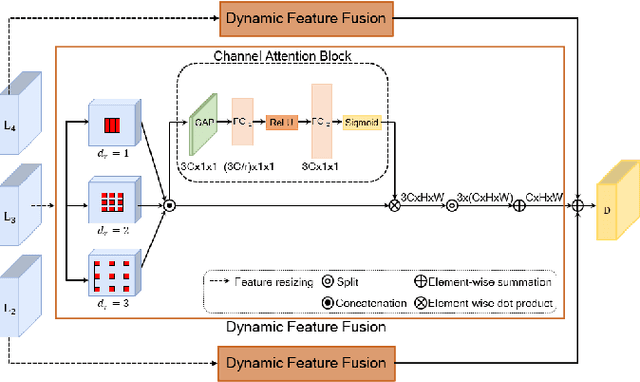
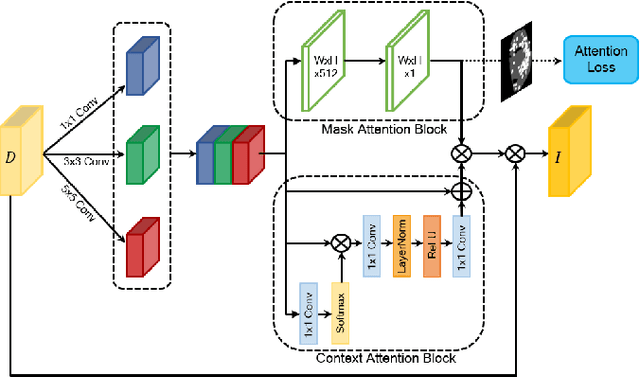
Computer-aided diagnosis has recently received attention for its advantage of low cost and time efficiency. Although deep learning played a major role in the recent success of acne detection, there are still several challenges such as color shift by inconsistent illumination, variation in scales, and high density distribution. To address these problems, we propose an acne detection network which consists of three components, specifically: Composite Feature Refinement, Dynamic Context Enhancement, and Mask-Aware Multi-Attention. First, Composite Feature Refinement integrates semantic information and fine details to enrich feature representation, which mitigates the adverse impact of imbalanced illumination. Then, Dynamic Context Enhancement controls different receptive fields of multi-scale features for context enhancement to handle scale variation. Finally, Mask-Aware Multi-Attention detects densely arranged and small acne by suppressing uninformative regions and highlighting probable acne regions. Experiments are performed on acne image dataset ACNE04 and natural image dataset PASCAL VOC 2007. We demonstrate how our method achieves the state-of-the-art result on ACNE04 and competitive performance with previous state-of-the-art methods on the PASCAL VOC 2007.
Cellular, Wide-Area, and Non-Terrestrial IoT: A Survey on 5G Advances and the Road Towards 6G
Jul 07, 2021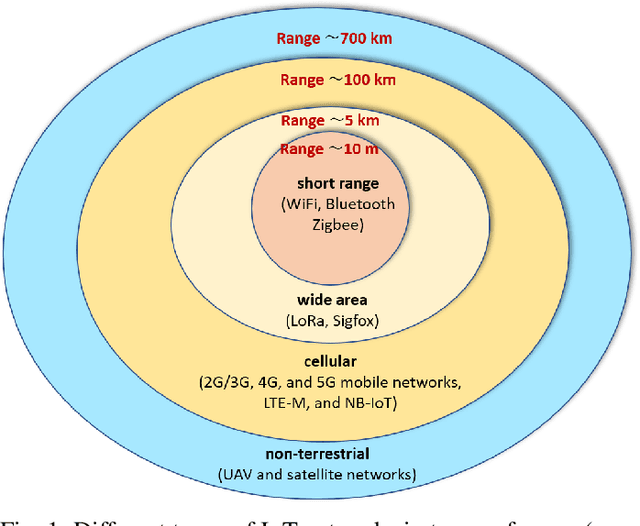

The next wave of wireless technologies is proliferating in connecting things among themselves as well as to humans. In the era of the Internet of things (IoT), billions of sensors, machines, vehicles, drones, and robots will be connected, making the world around us smarter. The IoT will encompass devices that must wirelessly communicate a diverse set of data gathered from the environment for myriad new applications. The ultimate goal is to extract insights from this data and develop solutions that improve quality of life and generate new revenue. Providing large-scale, long-lasting, reliable, and near real-time connectivity is the major challenge in enabling a smart connected world. This paper provides a comprehensive survey on existing and emerging communication solutions for serving IoT applications in the context of cellular, wide-area, as well as non-terrestrial networks. Specifically, wireless technology enhancements for providing IoT access in fifth-generation (5G) and beyond cellular networks, and communication networks over the unlicensed spectrum are presented. Aligned with the main key performance indicators of 5G and beyond 5G networks, we investigate solutions and standards that enable energy efficiency, reliability, low latency, and scalability (connection density) of current and future IoT networks. The solutions include grant-free access and channel coding for short-packet communications, non-orthogonal multiple access, and on-device intelligence. Further, a vision of new paradigm shifts in communication networks in the 2030s is provided, and the integration of the associated new technologies like artificial intelligence, non-terrestrial networks, and new spectra is elaborated. Finally, future research directions toward beyond 5G IoT networks are pointed out.
* Submitted for review to IEEE CS&T
Revisiting Model Stitching to Compare Neural Representations
Jun 14, 2021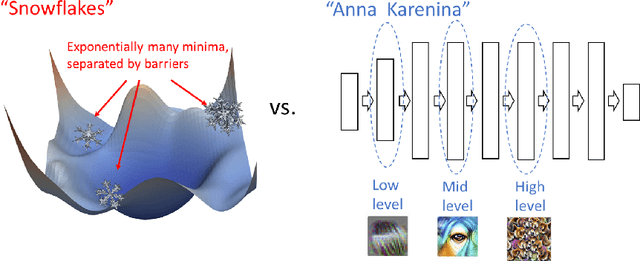

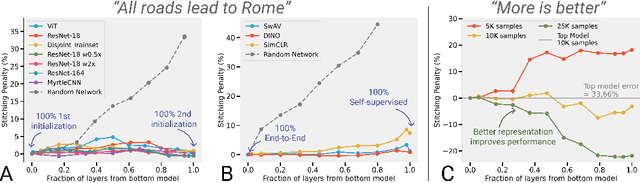
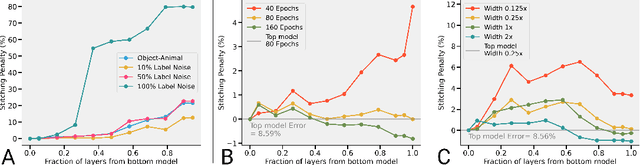
We revisit and extend model stitching (Lenc & Vedaldi 2015) as a methodology to study the internal representations of neural networks. Given two trained and frozen models $A$ and $B$, we consider a "stitched model'' formed by connecting the bottom-layers of $A$ to the top-layers of $B$, with a simple trainable layer between them. We argue that model stitching is a powerful and perhaps under-appreciated tool, which reveals aspects of representations that measures such as centered kernel alignment (CKA) cannot. Through extensive experiments, we use model stitching to obtain quantitative verifications for intuitive statements such as "good networks learn similar representations'', by demonstrating that good networks of the same architecture, but trained in very different ways (e.g.: supervised vs. self-supervised learning), can be stitched to each other without drop in performance. We also give evidence for the intuition that "more is better'' by showing that representations learnt with (1) more data, (2) bigger width, or (3) more training time can be "plugged in'' to weaker models to improve performance. Finally, our experiments reveal a new structural property of SGD which we call "stitching connectivity'', akin to mode-connectivity: typical minima reached by SGD can all be stitched to each other with minimal change in accuracy.
Generator Surgery for Compressed Sensing
Feb 22, 2021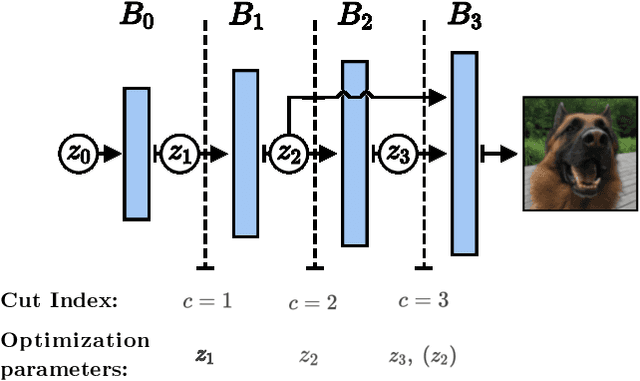
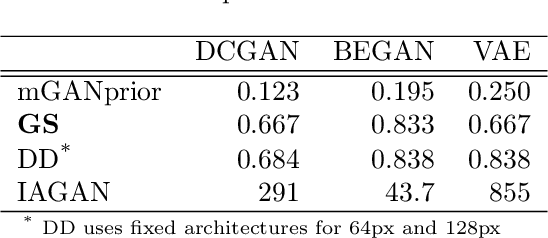
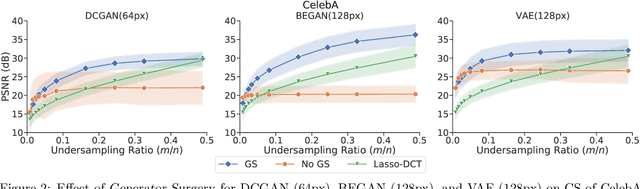
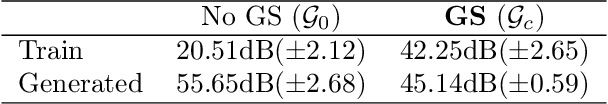
Image recovery from compressive measurements requires a signal prior for the images being reconstructed. Recent work has explored the use of deep generative models with low latent dimension as signal priors for such problems. However, their recovery performance is limited by high representation error. We introduce a method for achieving low representation error using generators as signal priors. Using a pre-trained generator, we remove one or more initial blocks at test time and optimize over the new, higher-dimensional latent space to recover a target image. Experiments demonstrate significantly improved reconstruction quality for a variety of network architectures. This approach also works well for out-of-training-distribution images and is competitive with other state-of-the-art methods. Our experiments show that test-time architectural modifications can greatly improve the recovery quality of generator signal priors for compressed sensing.
Fusion of Heterogeneous Friction Estimates for Traction Adaptive Motion Planning and Control
May 14, 2021

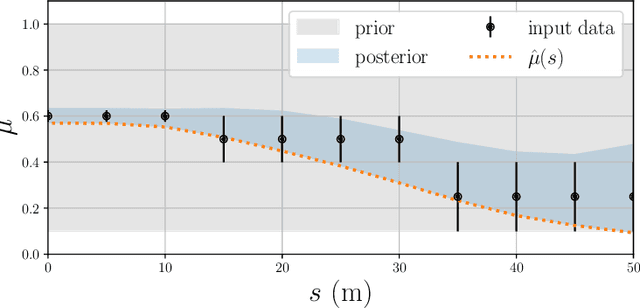
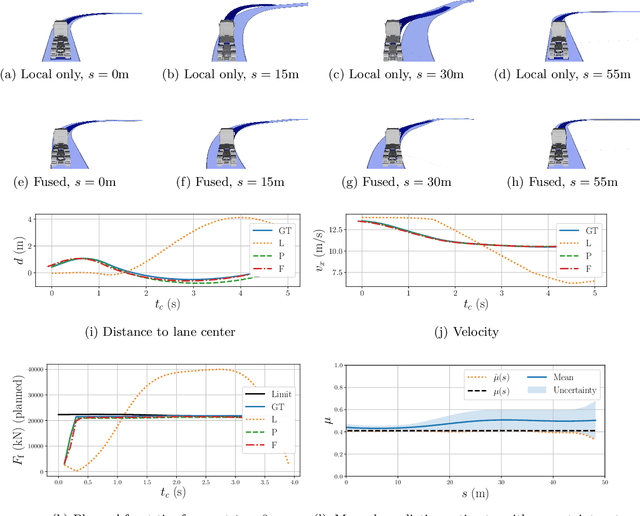
Traction adaptive motion planning and control has potential to improve an an automated vehicle's ability to avoid accident in a critical situation. However, such functionality require an accurate friction estimate for the road ahead of the vehicle that is updated in real time. Current state of the art friction estimation techniques include high accuracy local friction estimation in the presence of tire slip, as well as rough classification of the road surface ahead of the vehicle, based on forward looking camera. In this paper we show that neither of these techniques in isolation yield satisfactory behavior when deployed with traction adaptive motion planning and control functionality. However, fusion of the two provides sufficient accuracy, availability and foresight to yield near optimal behavior. To this end, we propose a fusion method based on heteroscedastic gaussian process regression, and present initial simulation based results.
Real-Time Steganalysis for Stream Media Based on Multi-channel Convolutional Sliding Windows
Feb 04, 2019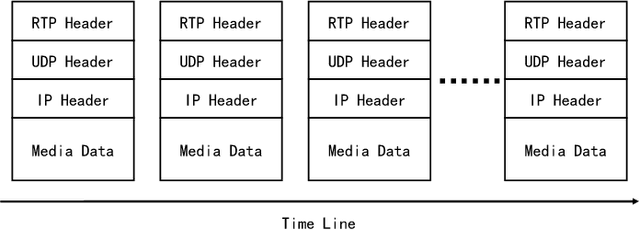
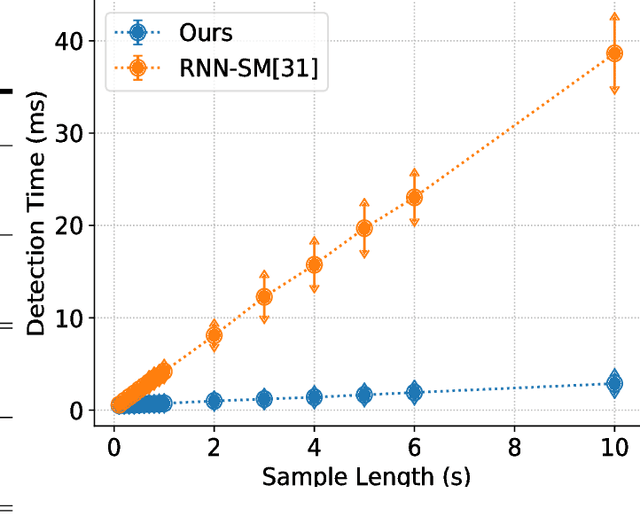
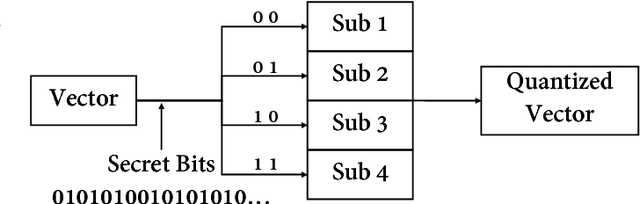
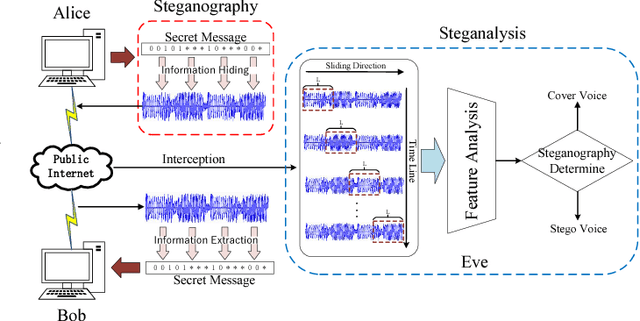
Previous VoIP steganalysis methods face great challenges in detecting speech signals at low embedding rates, and they are also generally difficult to perform real-time detection, making them hard to truly maintain cyberspace security. To solve these two challenges, in this paper, combined with the sliding window detection algorithm and Convolution Neural Network we propose a real-time VoIP steganalysis method which based on multi-channel convolution sliding windows. In order to analyze the correlations between frames and different neighborhood frames in a VoIP signal, we define multi channel sliding detection windows. Within each sliding window, we design two feature extraction channels which contain multiple convolution layers with multiple convolution kernels each layer to extract correlation features of the input signal. Then based on these extracted features, we use a forward fully connected network for feature fusion. Finally, by analyzing the statistical distribution of these features, the discriminator will determine whether the input speech signal contains covert information or not.We designed several experiments to test the proposed model's detection ability under various conditions, including different embedding rates, different speech length, etc. Experimental results showed that the proposed model outperforms all the previous methods, especially in the case of low embedding rate, which showed state-of-the-art performance. In addition, we also tested the detection efficiency of the proposed model, and the results showed that it can achieve almost real-time detection of VoIP speech signals.
Integrated Motion Planner for Real-time Aerial Videography with a Drone in a Dense Environment
Nov 21, 2019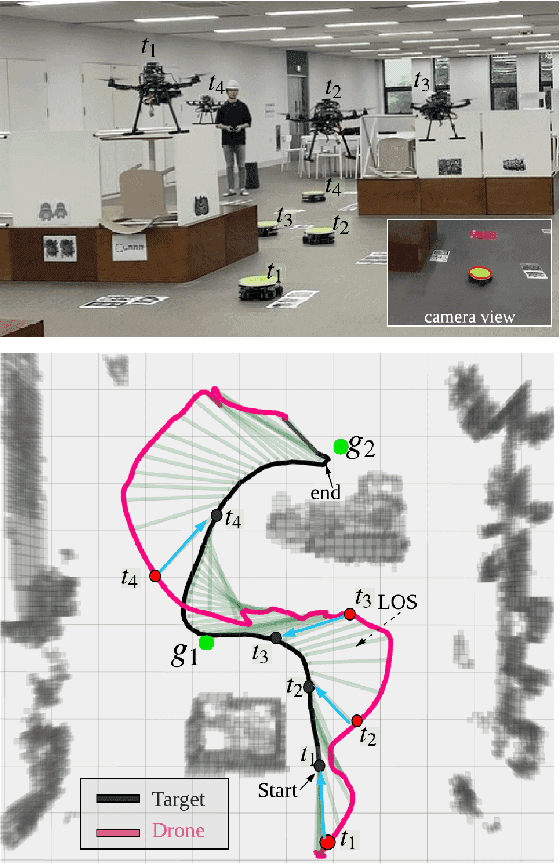
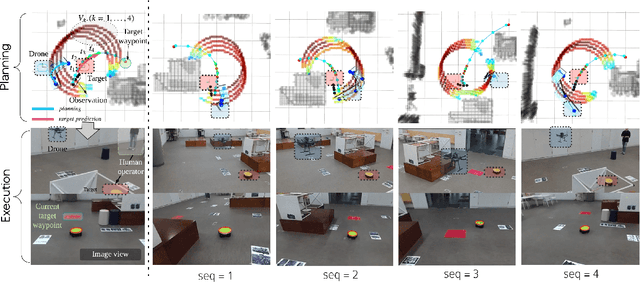
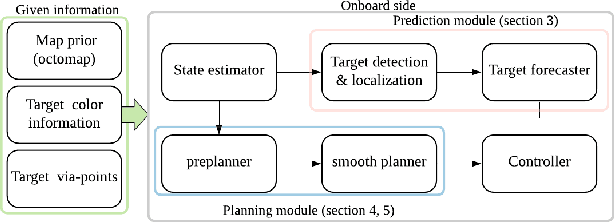
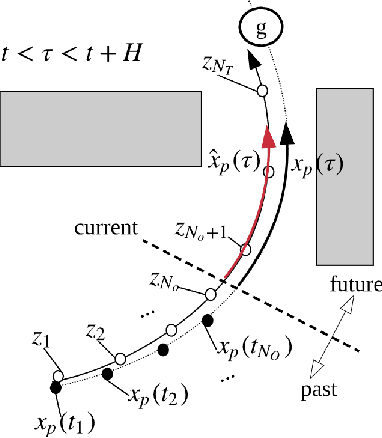
This letter suggests an integrated approach for a drone (or multirotor) to perform an autonomous videography task in a 3-D obstacle environment by following a moving object. The proposed system includes 1) a target motion prediction module which can be applied to dense environments and 2) a hierarchical chasing planner based on a proposed metric for visibility. In the prediction module, we minimize observation error given that the target object itself does not collide with obstacles. The estimated future trajectory of target is obtained by covariant optimization. The other module, chasing planner, is in a bi-level structure composed of preplanner and smooth planner. In the first phase, we leverage a graph-search method to preplan a chasing corridor which incorporates safety and visibility of target during a time window. In the subsequent phase, we generate a smooth and dynamically feasible path within the corridor using quadratic programming (QP). We validate our approach with multiple complex scenarios and actual experiments. The source code can be found in https://github.com/icsl-Jeon/traj_gen_vis
Learning to Detect Multi-Modal Grasps for Dexterous Grasping in Dense Clutter
Jun 07, 2021



Grasping arbitrary objects in densely cluttered novel environments is a crucial skill for robots. Though many existing systems enable two-finger parallel-jaw grippers to pick items from clutter, these grippers cannot perform multiple types of grasps. However, multi-modal grasping with multi-finger grippers could much more effectively clear objects of varying sizes from cluttered scenes. We propose an approach to multi-model grasp detection that jointly predicts the probabilities that several types of grasps succeed at a given grasp pose. Given a partial point cloud of a scene, the algorithm proposes a set of feasible grasp candidates, then estimates the probabilities that a grasp of each type would succeed at each candidate pose. Predicting grasp success probabilities directly from point clouds makes our approach agnostic to the number and placement of depth sensors at execution time. We evaluate our system both in simulation and on a real robot with a Robotiq 3-Finger Adaptive Gripper. We compare our network against several baselines that perform fewer types of grasps. Our experiments show that a system that explicitly models grasp type achieves an object retrieval rate 8.5% higher in a complex cluttered environment than our highest-performing baseline.
Concave Utility Reinforcement Learning: the Mean-field Game viewpoint
Jun 07, 2021
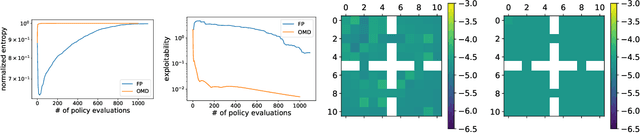
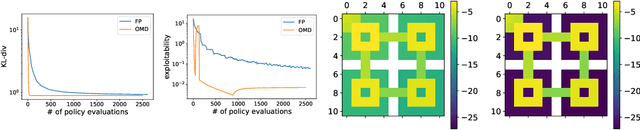

Concave Utility Reinforcement Learning (CURL) extends RL from linear to concave utilities in the occupancy measure induced by the agent's policy. This encompasses not only RL but also imitation learning and exploration, among others. Yet, this more general paradigm invalidates the classical Bellman equations, and calls for new algorithms. Mean-field Games (MFGs) are a continuous approximation of many-agent RL. They consider the limit case of a continuous distribution of identical agents, anonymous with symmetric interests, and reduce the problem to the study of a single representative agent in interaction with the full population. Our core contribution consists in showing that CURL is a subclass of MFGs. We think this important to bridge together both communities. It also allows to shed light on aspects of both fields: we show the equivalence between concavity in CURL and monotonicity in the associated MFG, between optimality conditions in CURL and Nash equilibrium in MFG, or that Fictitious Play (FP) for this class of MFGs is simply Frank-Wolfe, bringing the first convergence rate for discrete-time FP for MFGs. We also experimentally demonstrate that, using algorithms recently introduced for solving MFGs, we can address the CURL problem more efficiently.