 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Invariant Policy Learning: A Causal Perspective
Jun 07, 2021
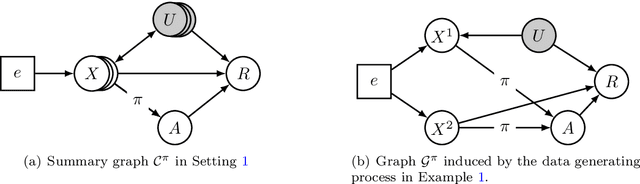
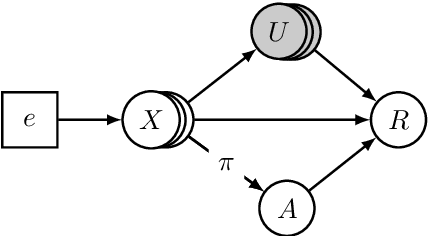
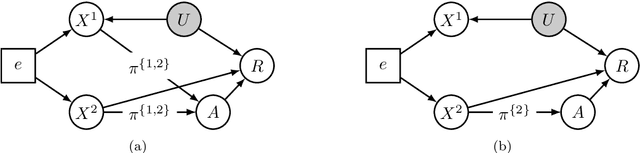
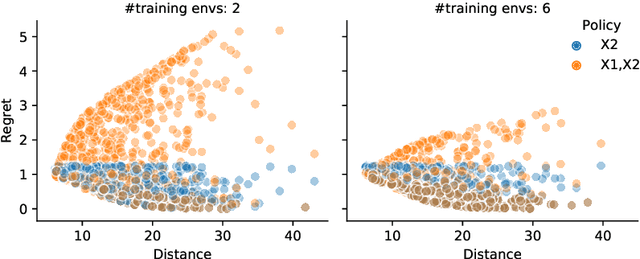
In the past decade, contextual bandit and reinforcement learning algorithms have been successfully used in various interactive learning systems such as online advertising, recommender systems, and dynamic pricing. However, they have yet to be widely adopted in high-stakes application domains, such as healthcare. One reason may be that existing approaches assume that the underlying mechanisms are static in the sense that they do not change over time or over different environments. In many real world systems, however, the mechanisms are subject to shifts across environments which may invalidate the static environment assumption. In this paper, we tackle the problem of environmental shifts under the framework of offline contextual bandits. We view the environmental shift problem through the lens of causality and propose multi-environment contextual bandits that allow for changes in the underlying mechanisms. We adopt the concept of invariance from the causality literature and introduce the notion of policy invariance. We argue that policy invariance is only relevant if unobserved confounders are present and show that, in that case, an optimal invariant policy is guaranteed, under certain assumptions, to generalize across environments. Our results do not only provide a solution to the environmental shift problem but also establish concrete connections among causality, invariance and contextual bandits.
Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Mar 31, 2021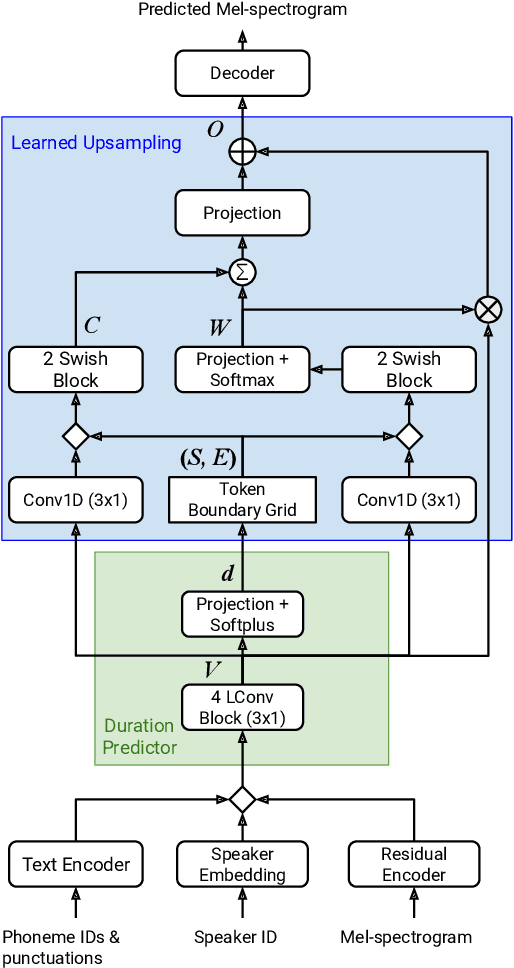
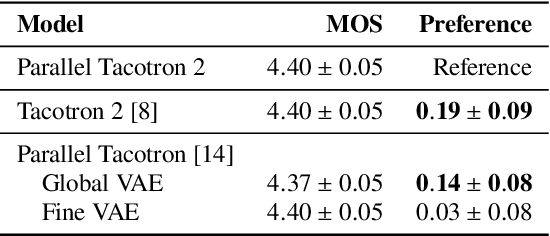
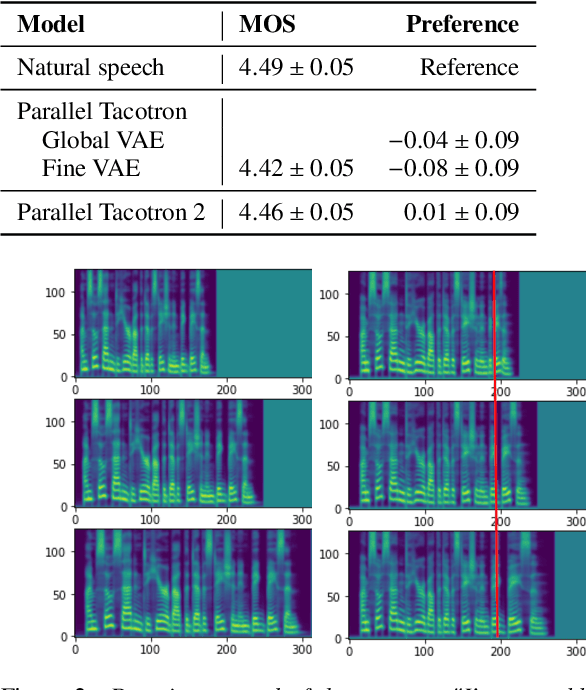

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
1D CNN Architectures for Music Genre Classification
May 15, 2021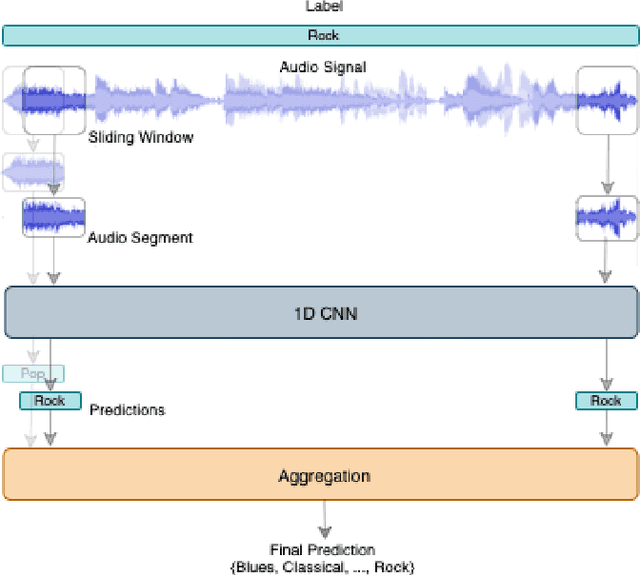
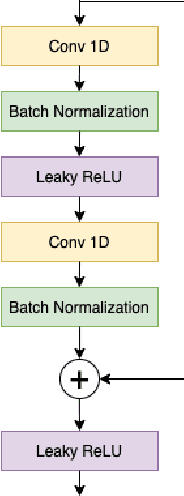
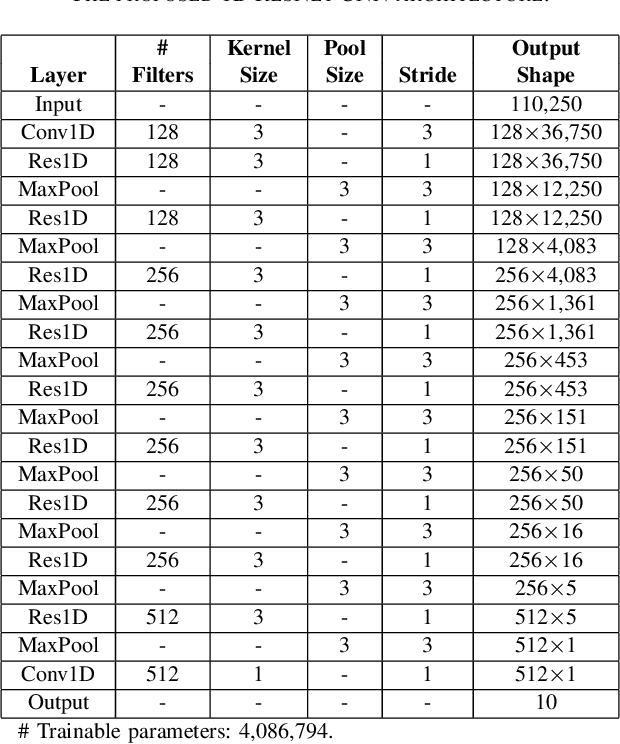
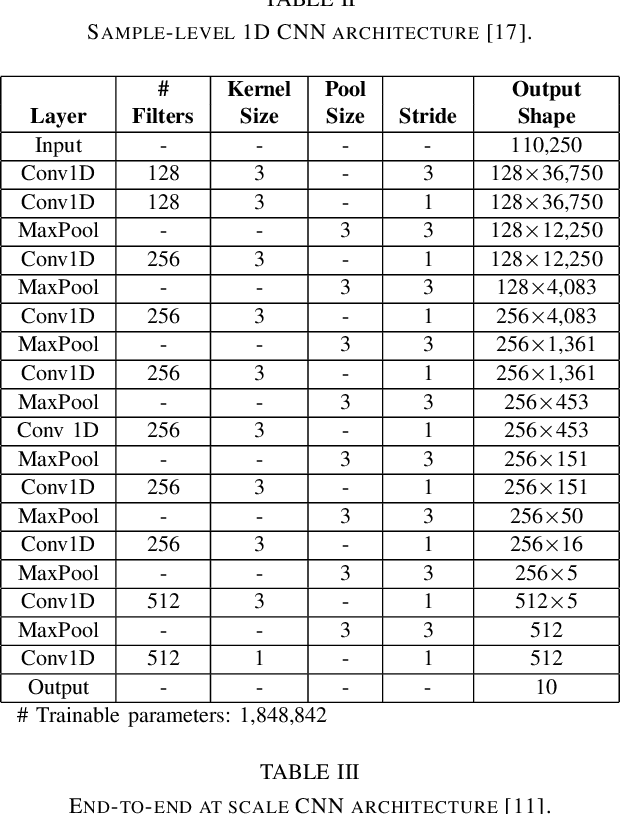
This paper proposes a 1D residual convolutional neural network (CNN) architecture for music genre classification and compares it with other recent 1D CNN architectures. The 1D CNNs learn a representation and a discriminant directly from the raw audio signal. Several convolutional layers capture the time-frequency characteristics of the audio signal and learn various filters relevant to the music genre recognition task. The proposed approach splits the audio signal into overlapped segments using a sliding window to comply with the fixed-length input constraint of the 1D CNNs. As a result, music genre classification can be carried out on a single audio segment or on the aggregation of the predictions on several audio segments, which improves the final accuracy. The performance of the proposed 1D residual CNN is assessed on a public dataset of 1,000 audio clips. The experimental results have shown that it achieves 80.93% of mean accuracy in classifying music genres and outperforms other 1D CNN architectures.
Real-Time Driver State Monitoring Using a CNN Based Spatio-Temporal Approach
Jul 18, 2019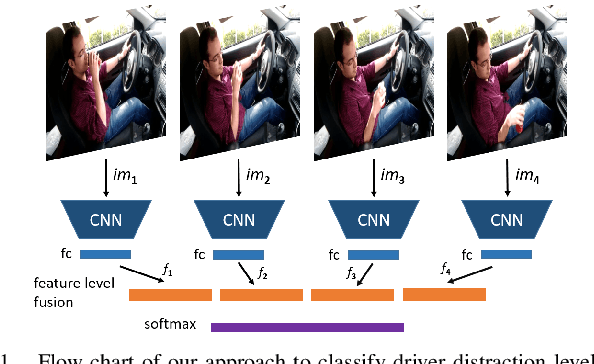


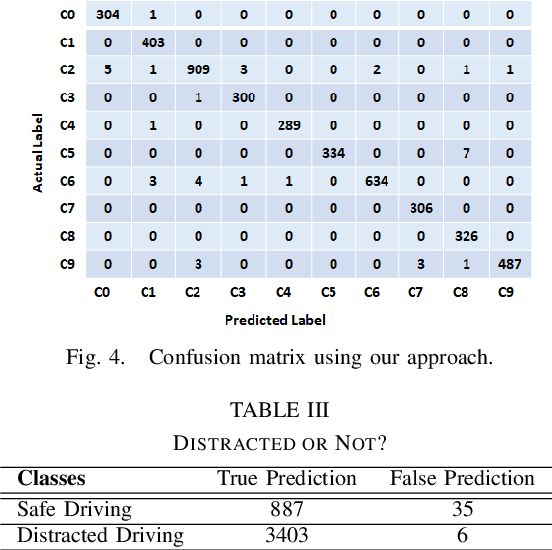
Many road accidents occur due to distracted drivers. Today, driver monitoring is essential even for the latest autonomous vehicles to alert distracted drivers in order to take over control of the vehicle in case of emergency. In this paper, a spatio-temporal approach is applied to classify drivers' distraction level and movement decisions using convolutional neural networks (CNNs). We approach this problem as action recognition to benefit from temporal information in addition to spatial information. Our approach relies on features extracted from sparsely selected frames of an action using a pre-trained BN-Inception network. Experiments show that our approach outperforms the state-of-the art results on the Distracted Driver Dataset (96.31%), with an accuracy of 99.10% for 10-class classification while providing real-time performance. We also analyzed the impact of fusion using RGB and optical flow modalities with a very recent data level fusion strategy. The results on the Distracted Driver and Brain4Cars datasets show that fusion of these modalities further increases the accuracy.
Multi-Phase Locking Value: A Generalized Method for Determining Instantaneous Multi-frequency Phase Coupling
Feb 20, 2021
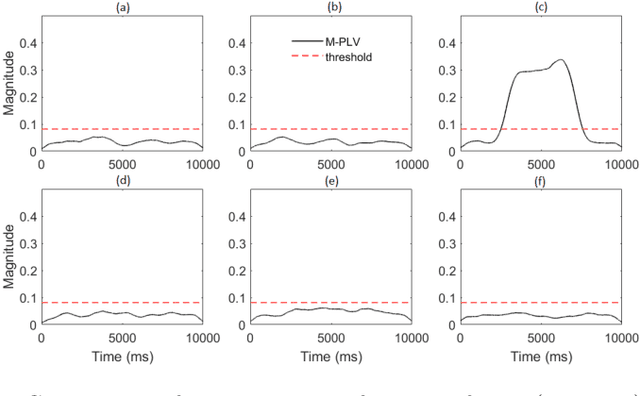
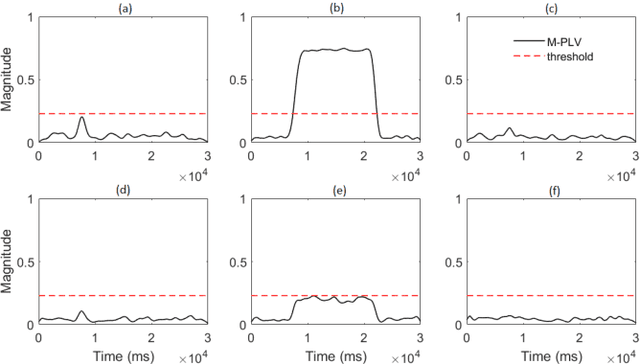
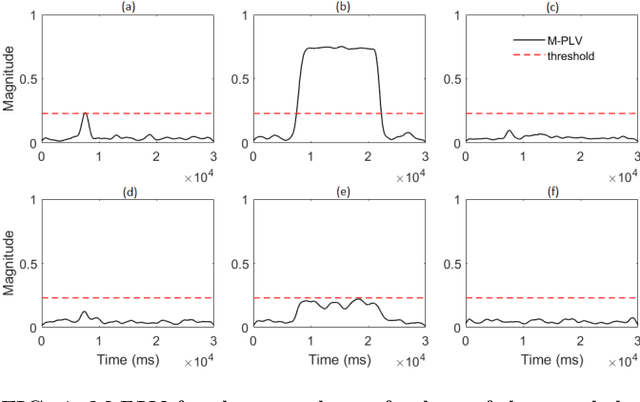
Many physical, biological and neural systems behave as coupled oscillators, with characteristic phase coupling across different frequencies. Methods such as $n:m$ phase locking value and bi-phase locking value have previously been proposed to quantify phase coupling between two resonant frequencies (e.g. $f$, $2f/3$) and across three frequencies (e.g. $f_1$, $f_2$, $f_1+f_2$), respectively. However, the existing phase coupling metrics have their limitations and limited applications. They cannot be used to detect or quantify phase coupling across multiple frequencies (e.g. $f_1$, $f_2$, $f_3$, $f_4$, $f_1+f_2+f_3-f_4$), or coupling that involves non-integer multiples of the frequencies (e.g. $f_1$, $f_2$, $2f_1/3+f_2/3$). To address the gap, this paper proposes a generalized approach, named multi-phase locking value (M-PLV), for the quantification of various types of instantaneous multi-frequency phase coupling. Different from most instantaneous phase coupling metrics that measure the simultaneous phase coupling, the proposed M-PLV method also allows the detection of delayed phase coupling and the associated time lag between coupled oscillators. The M-PLV has been tested on cases where synthetic coupled signals are generated using white Gaussian signals, and a system comprised of multiple coupled R\"ossler oscillators. Results indicate that the M-PLV can provide a reliable estimation of the time window and frequency combination where the phase coupling is significant, as well as a precise determination of time lag in the case of delayed coupling. This method has the potential to become a powerful new tool for exploring phase coupling in complex nonlinear dynamic systems.
An Explanatory Query-Based Framework for Exploring Academic Expertise
May 31, 2021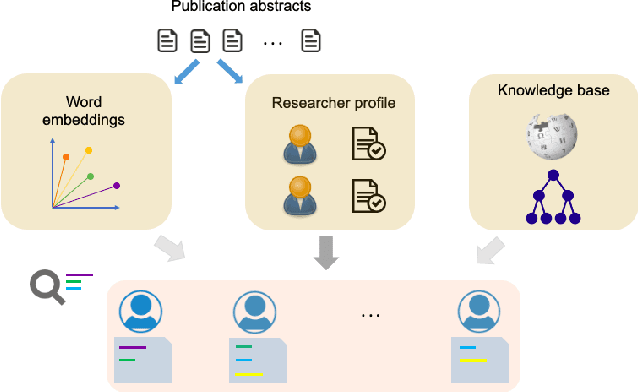



The success of research institutions heavily relies upon identifying the right researchers "for the job": researchers may need to identify appropriate collaborators, often from across disciplines; students may need to identify suitable supervisors for projects of their interest; administrators may need to match funding opportunities with relevant researchers, and so on. Usually, finding potential collaborators in institutions is a time-consuming manual search task prone to bias. In this paper, we propose a novel query-based framework for searching, scoring, and exploring research expertise automatically, based upon processing abstracts of academic publications. Given user queries in natural language, our framework finds researchers with relevant expertise, making use of domain-specific knowledge bases and word embeddings. It also generates explanations for its recommendations. We evaluate our framework with an institutional repository of papers from a leading university, using, as baselines, artificial neural networks and transformer-based models for a multilabel classification task to identify authors of publication abstracts. We also assess the cross-domain effectiveness of our framework with a (separate) research funding repository for the same institution. We show that our simple method is effective in identifying matches, while satisfying desirable properties and being efficient.
Optimization of Service Addition in Multilevel Index Model for Edge Computing
Jun 19, 2021



With the development of Edge Computing and Artificial Intelligence (AI) technologies, edge devices are witnessed to generate data at unprecedented volume. The Edge Intelligence (EI) has led to the emergence of edge devices in various application domains. The EI can provide efficient services to delay-sensitive applications, where the edge devices are deployed as edge nodes to host the majority of execution, which can effectively manage services and improve service discovery efficiency. The multilevel index model is a well-known model used for indexing service, such a model is being introduced and optimized in the edge environments to efficiently services discovery whilst managing large volumes of data. However, effectively updating the multilevel index model by adding new services timely and precisely in the dynamic Edge Computing environments is still a challenge. Addressing this issue, this paper proposes a designated key selection method to improve the efficiency of adding services in the multilevel index models. Our experimental results show that in the partial index and the full index of multilevel index model, our method reduces the service addition time by around 84% and 76%, respectively when compared with the original key selection method and by around 78% and 66%, respectively when compared with the random selection method. Our proposed method significantly improves the service addition efficiency in the multilevel index model, when compared with existing state-of-the-art key selection methods, without compromising the service retrieval stability to any notable level.
Q-attention: Enabling Efficient Learning for Vision-based Robotic Manipulation
May 31, 2021
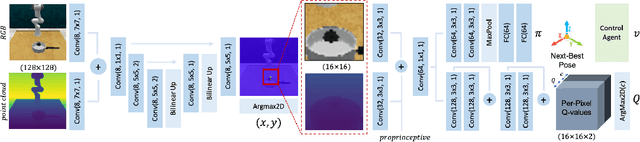
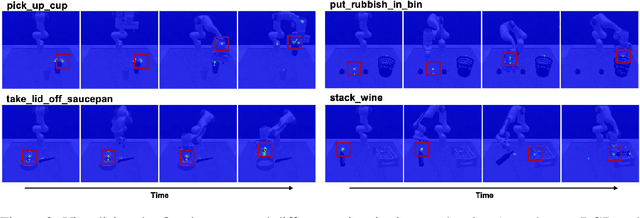
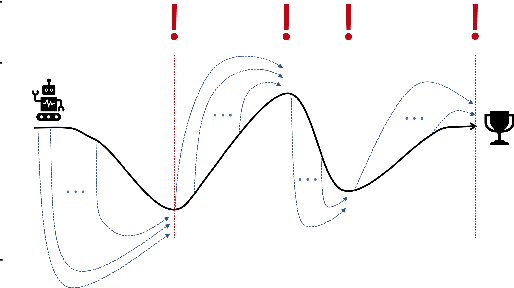
Despite the success of reinforcement learning methods, they have yet to have their breakthrough moment when applied to a broad range of robotic manipulation tasks. This is partly due to the fact that reinforcement learning algorithms are notoriously difficult and time consuming to train, which is exacerbated when training from images rather than full-state inputs. As humans perform manipulation tasks, our eyes closely monitor every step of the process with our gaze focusing sequentially on the objects being manipulated. With this in mind, we present our Attention-driven Robotic Manipulation (ARM) algorithm, which is a general manipulation algorithm that can be applied to a range of sparse-rewarded tasks, given only a small number of demonstrations. ARM splits the complex task of manipulation into a 3 stage pipeline: (1) a Q-attention agent extracts interesting pixel locations from RGB and point cloud inputs, (2) a next-best pose agent that accepts crops from the Q-attention agent and outputs poses, and (3) a control agent that takes the goal pose and outputs joint actions. We show that current learning algorithms fail on a range of RLBench tasks, whilst ARM is successful.
Supporting Cognitive and Emotional Empathic Writing of Students
May 31, 2021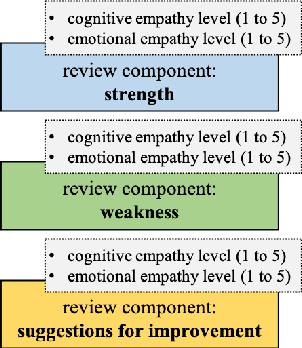


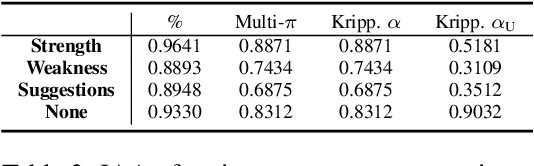
We present an annotation approach to capturing emotional and cognitive empathy in student-written peer reviews on business models in German. We propose an annotation scheme that allows us to model emotional and cognitive empathy scores based on three types of review components. Also, we conducted an annotation study with three annotators based on 92 student essays to evaluate our annotation scheme. The obtained inter-rater agreement of {\alpha}=0.79 for the components and the multi-{\pi}=0.41 for the empathy scores indicate that the proposed annotation scheme successfully guides annotators to a substantial to moderate agreement. Moreover, we trained predictive models to detect the annotated empathy structures and embedded them in an adaptive writing support system for students to receive individual empathy feedback independent of an instructor, time, and location. We evaluated our tool in a peer learning exercise with 58 students and found promising results for perceived empathy skill learning, perceived feedback accuracy, and intention to use. Finally, we present our freely available corpus of 500 empathy-annotated, student-written peer reviews on business models and our annotation guidelines to encourage future research on the design and development of empathy support systems.
Detecting Spurious Correlations with Sanity Tests for Artificial Intelligence Guided Radiology Systems
Mar 04, 2021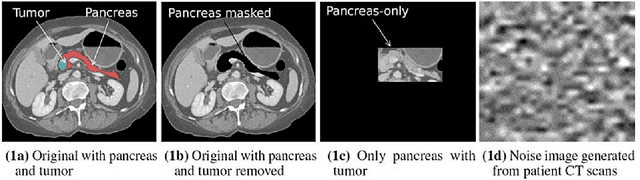

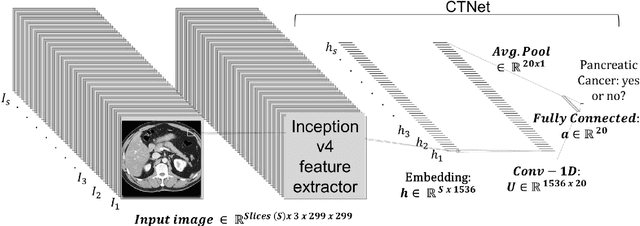

Artificial intelligence (AI) has been successful at solving numerous problems in machine perception. In radiology, AI systems are rapidly evolving and show progress in guiding treatment decisions, diagnosing, localizing disease on medical images, and improving radiologists' efficiency. A critical component to deploying AI in radiology is to gain confidence in a developed system's efficacy and safety. The current gold standard approach is to conduct an analytical validation of performance on a generalization dataset from one or more institutions, followed by a clinical validation study of the system's efficacy during deployment. Clinical validation studies are time-consuming, and best practices dictate limited re-use of analytical validation data, so it is ideal to know ahead of time if a system is likely to fail analytical or clinical validation. In this paper, we describe a series of sanity tests to identify when a system performs well on development data for the wrong reasons. We illustrate the sanity tests' value by designing a deep learning system to classify pancreatic cancer seen in computed tomography scans.