 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transform-Based Multilinear Dynamical System for Tensor Time Series Analysis
Nov 18, 2018
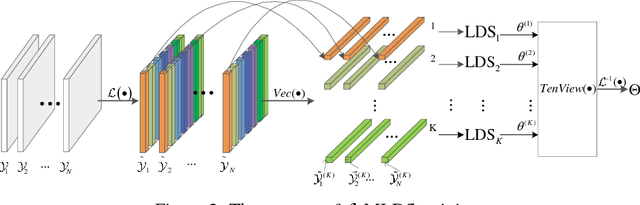
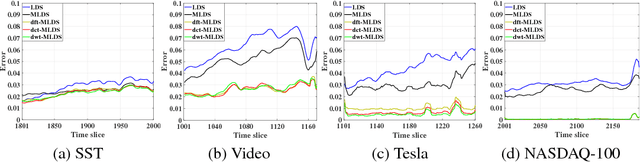
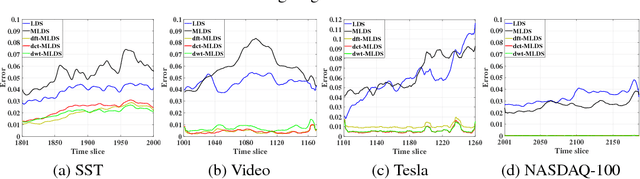
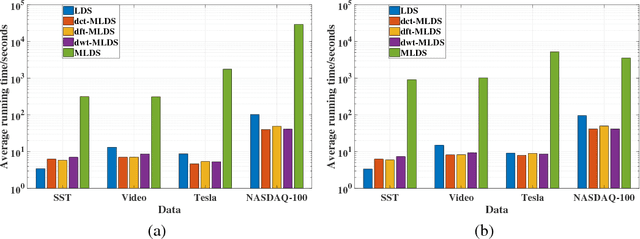
We propose a novel multilinear dynamical system (MLDS) in a transform domain, named $\mathcal{L}$-MLDS, to model tensor time series. With transformations applied to a tensor data, the latent multidimensional correlations among the frontal slices are built, and thus resulting in the computational independence in the transform domain. This allows the exact separability of the multi-dimensional problem into multiple smaller LDS problems. To estimate the system parameters, we utilize the expectation-maximization (EM) algorithm to determine the parameters of each LDS. Further, $\mathcal{L}$-MLDSs significantly reduce the model parameters and allows parallel processing. Our general $\mathcal{L}$-MLDS model is implemented based on different transforms: discrete Fourier transform, discrete cosine transform and discrete wavelet transform. Due to the nonlinearity of these transformations, $\mathcal{L}$-MLDS is able to capture the nonlinear correlations within the data unlike the MLDS \cite{rogers2013multilinear} which assumes multi-way linear correlations. Using four real datasets, the proposed $\mathcal{L}$-MLDS is shown to achieve much higher prediction accuracy than the state-of-the-art MLDS and LDS with an equal number of parameters under different noise models. In particular, the relative errors are reduced by $50\% \sim 99\%$. Simultaneously, $\mathcal{L}$-MLDS achieves an exponential improvement in the model's training time than MLDS.
Investigating the Evolvability of Web Page Load Time
Feb 22, 2018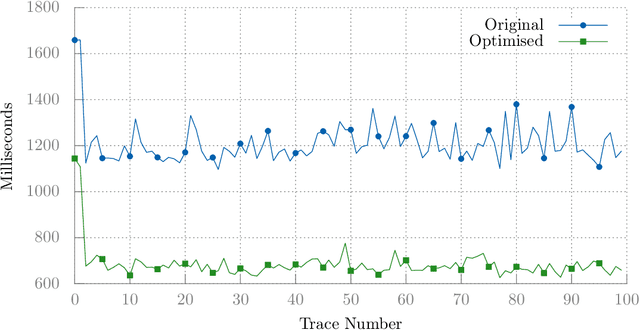
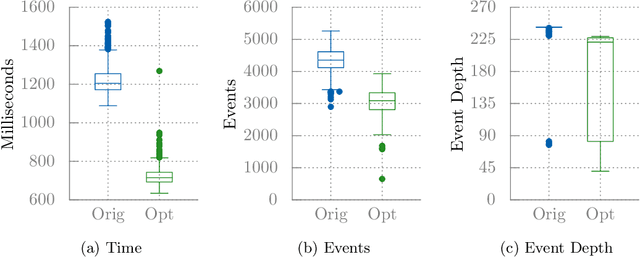
Client-side Javascript execution environments (browsers) allow anonymous functions and event-based programming concepts such as callbacks. We investigate whether a mutate-and-test approach can be used to optimise web page load time in these environments. First, we characterise a web page load issue in a benchmark web page and derive performance metrics from page load event traces. We parse Javascript source code to an AST and make changes to method calls which appear in a web page load event trace. We present an operator based solely on code deletion and evaluate an existing "community-contributed" performance optimising code transform. By exploring Javascript code changes and exploiting combinations of non-destructive changes, we can optimise page load time by 41% in our benchmark web page.
Initializing LSTM internal states via manifold learning
Apr 27, 2021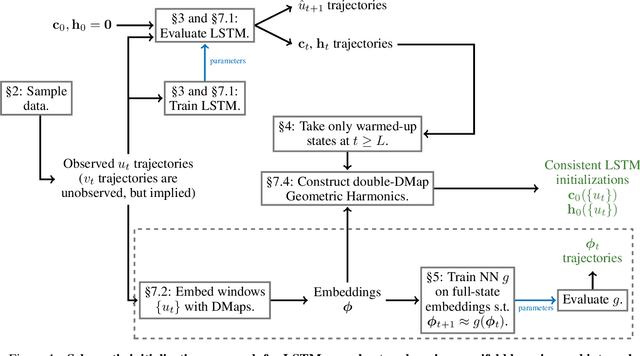
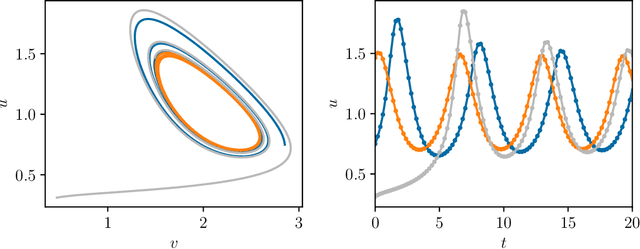
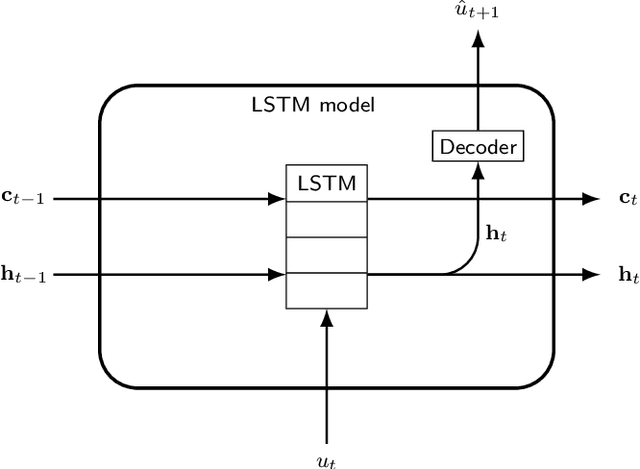
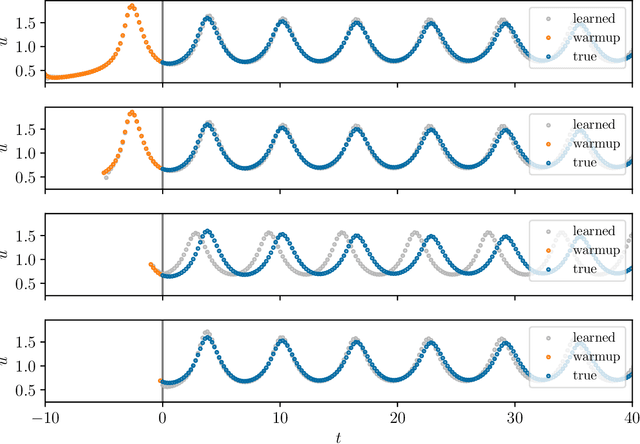
We present an approach, based on learning an intrinsic data manifold, for the initialization of the internal state values of LSTM recurrent neural networks, ensuring consistency with the initial observed input data. Exploiting the generalized synchronization concept, we argue that the converged, "mature" internal states constitute a function on this learned manifold. The dimension of this manifold then dictates the length of observed input time series data required for consistent initialization. We illustrate our approach through a partially observed chemical model system, where initializing the internal LSTM states in this fashion yields visibly improved performance. Finally, we show that learning this data manifold enables the transformation of partially observed dynamics into fully observed ones, facilitating alternative identification paths for nonlinear dynamical systems.
End-to-End Multihop Retrieval for Compositional Question Answering over Long Documents
Jun 01, 2021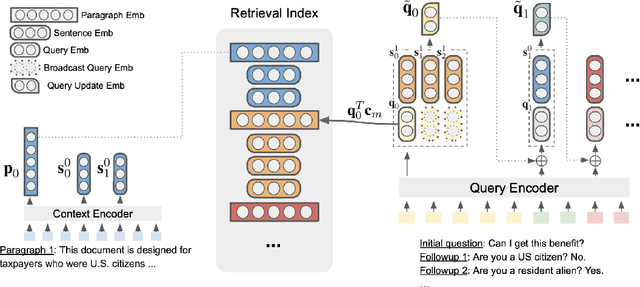
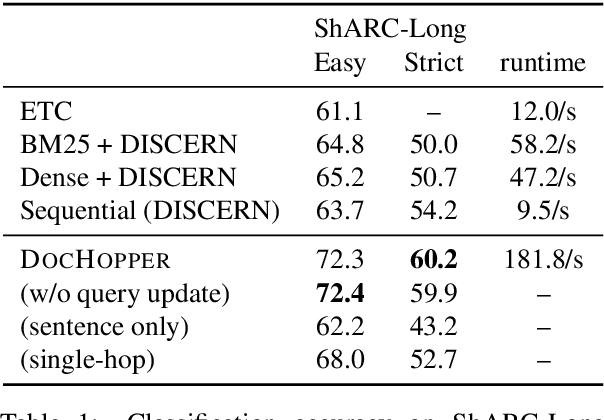
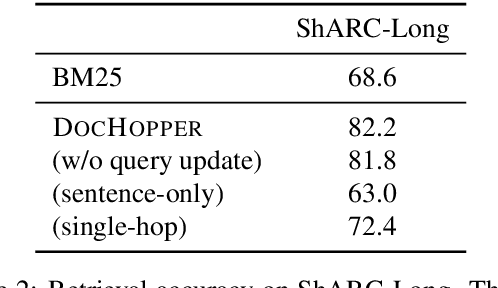
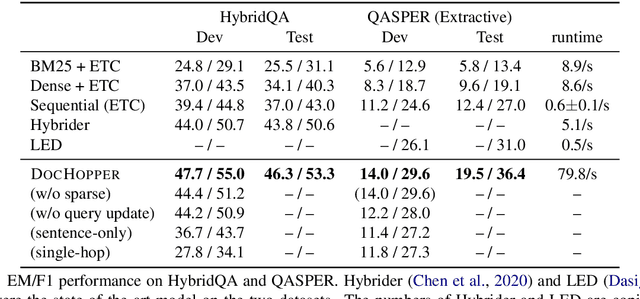
Answering complex questions from long documents requires aggregating multiple pieces of evidence and then predicting the answers. In this paper, we propose a multi-hop retrieval method, DocHopper, to answer compositional questions over long documents. At each step, DocHopper retrieves a paragraph or sentence embedding from the document, mixes the retrieved result with the query, and updates the query for the next step. In contrast to many other retrieval-based methods (e.g., RAG or REALM) the query is not augmented with a token sequence: instead, it is augmented by "numerically" combining it with another neural representation. This means that model is end-to-end differentiable. We demonstrate that utilizing document structure in this was can largely improve question-answering and retrieval performance on long documents. We experimented with DocHopper on three different QA tasks that require reading long documents to answer compositional questions: discourse entailment reasoning, factual QA with table and text, and information seeking QA from academic papers. DocHopper outperforms all baseline models and achieves state-of-the-art results on all datasets. Additionally, DocHopper is efficient at inference time, being 3~10 times faster than the baselines.
Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Mar 31, 2021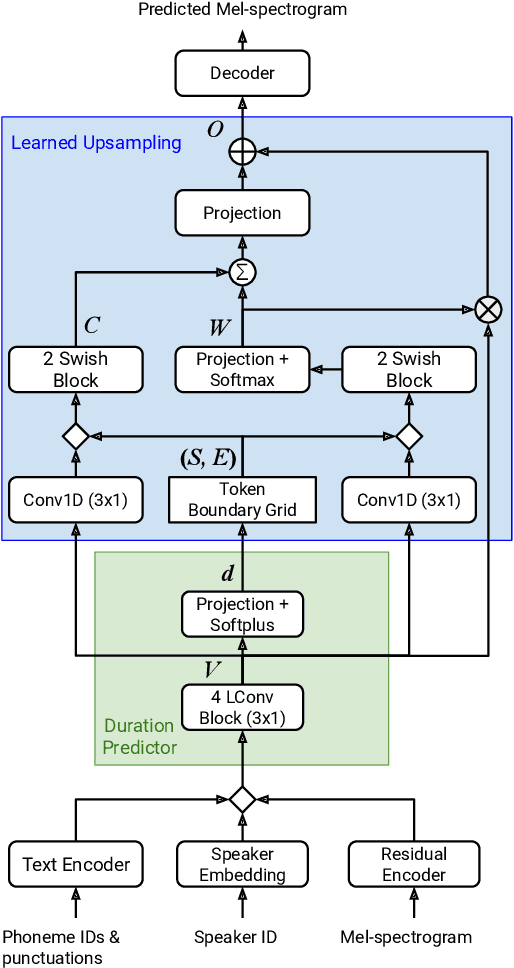
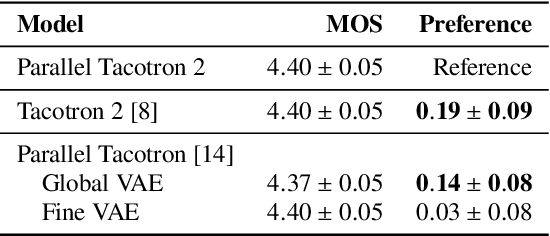
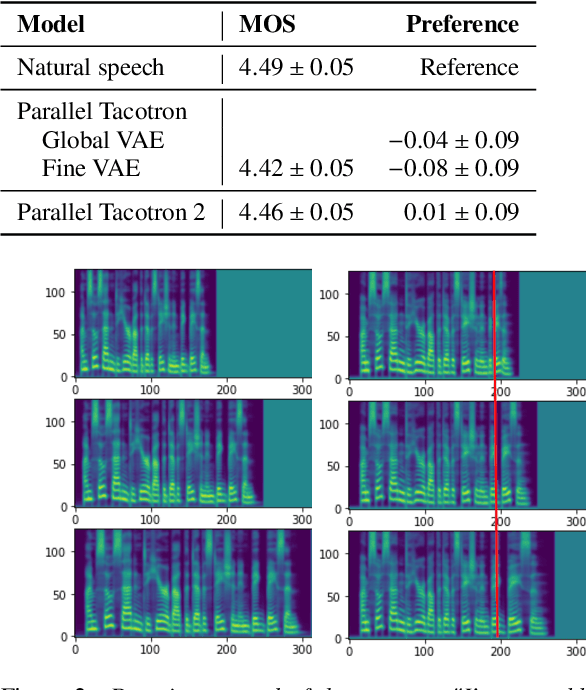

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
Language Models are Few-Shot Butlers
Apr 16, 2021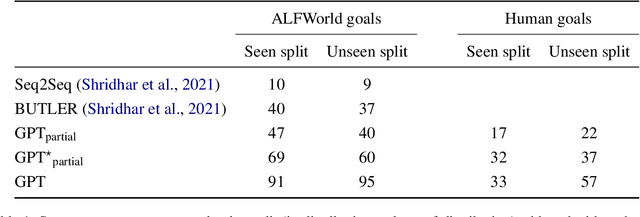
Pretrained language models demonstrate strong performance in most NLP tasks when fine-tuned on small task-specific datasets. Hence, these autoregressive models constitute ideal agents to operate in text-based environments where language understanding and generative capabilities are essential. Nonetheless, collecting expert demonstrations in such environments is a time-consuming endeavour. We introduce a two-stage procedure to learn from a small set of demonstrations and further improve by interacting with an environment. We show that language models fine-tuned with only 1.2% of the expert demonstrations and a simple reinforcement learning algorithm achieve a 51% absolute improvement in success rate over existing methods in the ALFWorld environment.
FEAR: A Simple Lightweight Method to Rank Architectures
Jun 07, 2021

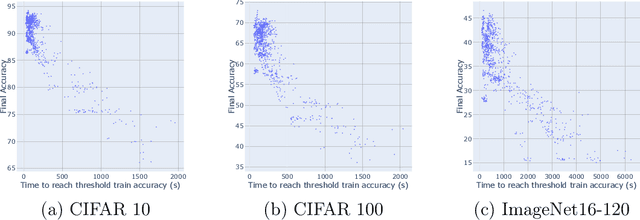
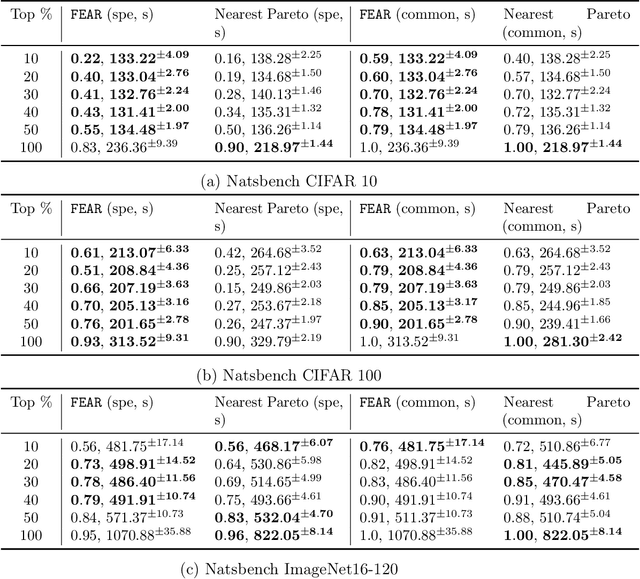
The fundamental problem in Neural Architecture Search (NAS) is to efficiently find high-performing architectures from a given search space. We propose a simple but powerful method which we call FEAR, for ranking architectures in any search space. FEAR leverages the viewpoint that neural networks are powerful non-linear feature extractors. First, we train different architectures in the search space to the same training or validation error. Then, we compare the usefulness of the features extracted by each architecture. We do so with a quick training keeping most of the architecture frozen. This gives fast estimates of the relative performance. We validate FEAR on Natsbench topology search space on three different datasets against competing baselines and show strong ranking correlation especially compared to recently proposed zero-cost methods. FEAR particularly excels at ranking high-performance architectures in the search space. When used in the inner loop of discrete search algorithms like random search, FEAR can cut down the search time by approximately 2.4X without losing accuracy. We additionally empirically study very recently proposed zero-cost measures for ranking and find that they breakdown in ranking performance as training proceeds and also that data-agnostic ranking scores which ignore the dataset do not generalize across dissimilar datasets.
Model identification for ARMA time series through convolutional neural networks
Apr 12, 2018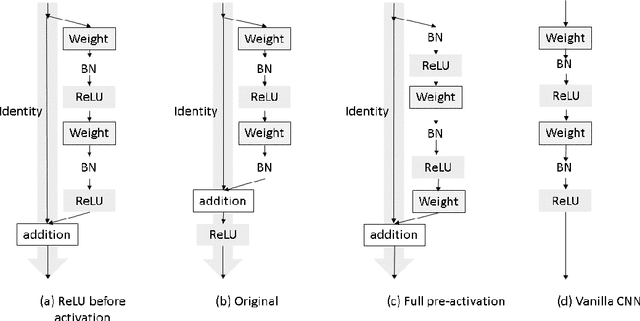
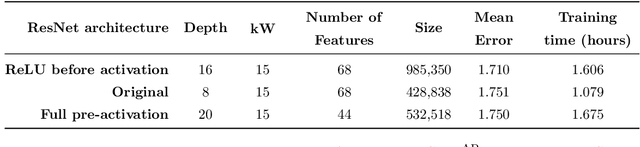
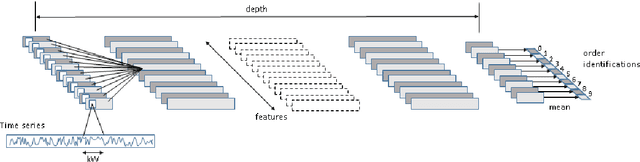
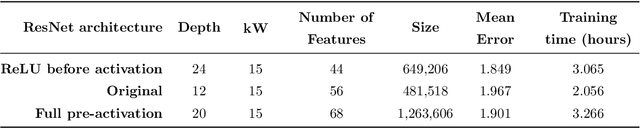
In this paper, we use convolutional neural networks to address the problem of model identification for autoregressive moving average time series models. We compare the performance of several neural network architectures, trained on simulated time series, with likelihood based methods, in particular the Akaike and Bayesian information criteria. We find that our neural networks can significantly outperform these likelihood based methods in terms of accuracy and, by orders of magnitude, in terms of speed.
Modeling preference time in middle distance triathlons
Jul 03, 2017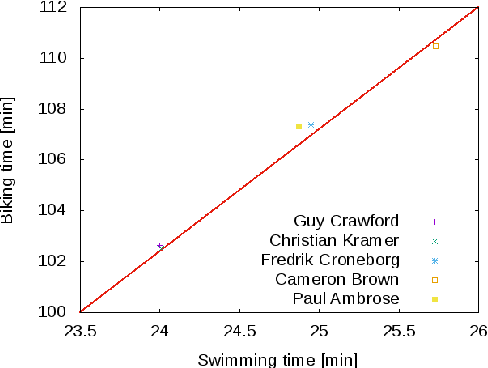
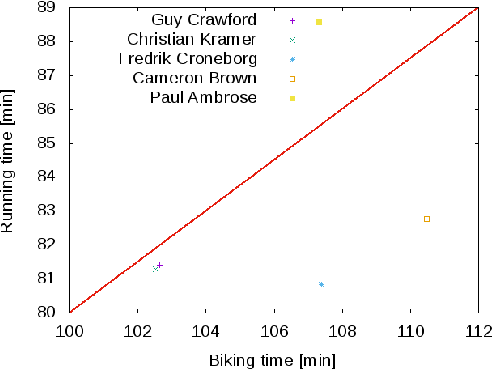
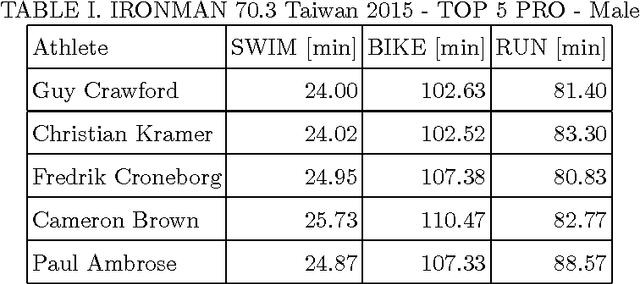

Modeling preference time in triathlons means predicting the intermediate times of particular sports disciplines by a given overall finish time in a specific triathlon course for the athlete with the known personal best result. This is a hard task for athletes and sport trainers due to a lot of different factors that need to be taken into account, e.g., athlete's abilities, health, mental preparations and even their current sports form. So far, this process was calculated manually without any specific software tools or using the artificial intelligence. This paper presents the new solution for modeling preference time in middle distance triathlons based on particle swarm optimization algorithm and archive of existing sports results. Initial results are presented, which suggest the usefulness of proposed approach, while remarks for future improvements and use are also emphasized.
Robustifying $\ell_\infty$ Adversarial Training to the Union of Perturbation Models
Jun 07, 2021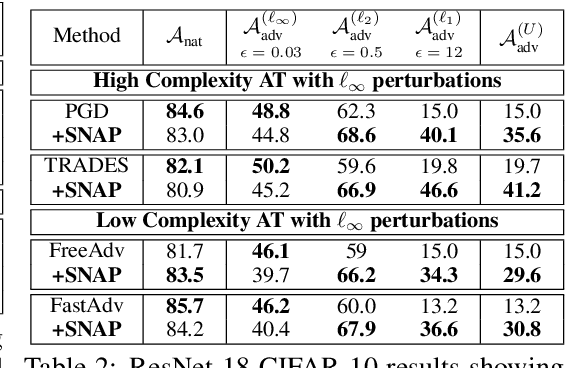
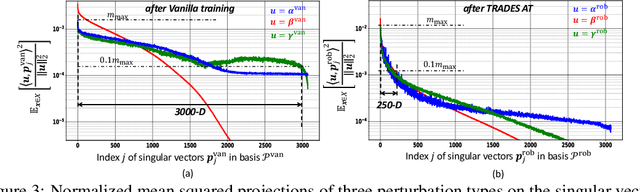
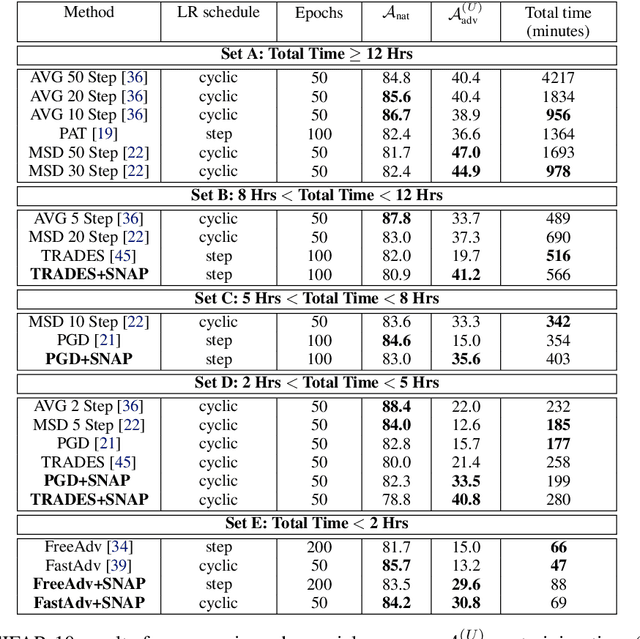
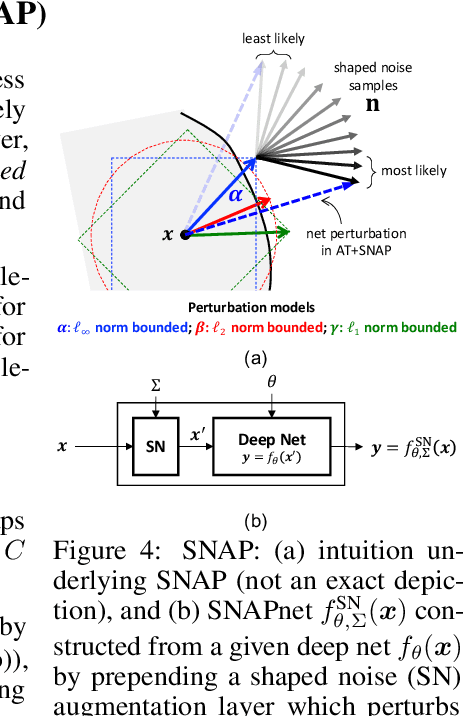
Classical adversarial training (AT) frameworks are designed to achieve high adversarial accuracy against a single attack type, typically $\ell_\infty$ norm-bounded perturbations. Recent extensions in AT have focused on defending against the union of multiple perturbations but this benefit is obtained at the expense of a significant (up to $10\times$) increase in training complexity over single-attack $\ell_\infty$ AT. In this work, we expand the capabilities of widely popular single-attack $\ell_\infty$ AT frameworks to provide robustness to the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations while preserving their training efficiency. Our technique, referred to as Shaped Noise Augmented Processing (SNAP), exploits a well-established byproduct of single-attack AT frameworks -- the reduction in the curvature of the decision boundary of networks. SNAP prepends a given deep net with a shaped noise augmentation layer whose distribution is learned along with network parameters using any standard single-attack AT. As a result, SNAP enhances adversarial accuracy of ResNet-18 on CIFAR-10 against the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations by 14%-to-20% for four state-of-the-art (SOTA) single-attack $\ell_\infty$ AT frameworks, and, for the first time, establishes a benchmark for ResNet-50 and ResNet-101 on ImageNet.