 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scaling the Convex Barrier with Sparse Dual Algorithms
Jan 26, 2021
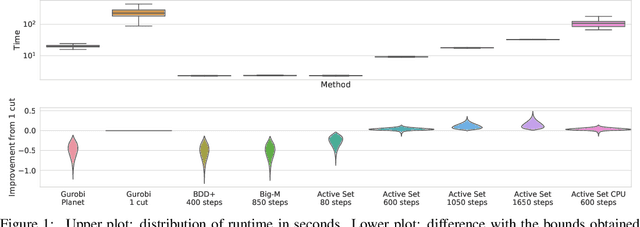
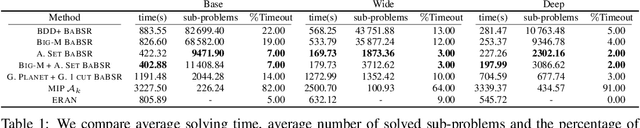
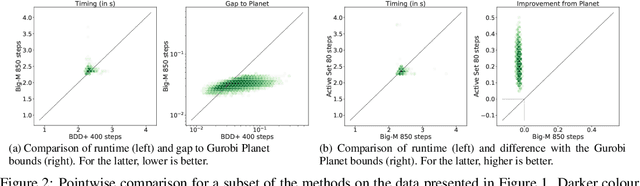
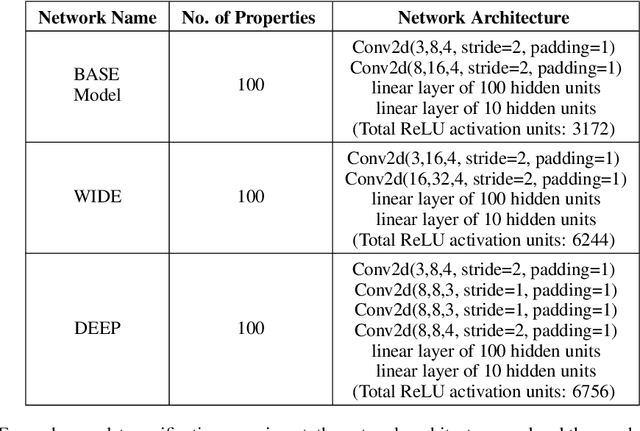
Tight and efficient neural network bounding is crucial to the scaling of neural network verification systems. Many efficient bounding algorithms have been presented recently, but they are often too loose to verify more challenging properties. This is due to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise-linear activations exists, it comes at the cost of exponentially many constraints and currently lacks an efficient customized solver. We alleviate this deficiency by presenting two novel dual algorithms: one operates a subgradient method on a small active set of dual variables, the other exploits the sparsity of Frank-Wolfe type optimizers to incur only a linear memory cost. Both methods recover the strengths of the new relaxation: tightness and a linear separation oracle. At the same time, they share the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we can obtain better bounds than off-the-shelf solvers in only a fraction of their running time, attaining significant formal verification speed-ups.
Robustifying $\ell_\infty$ Adversarial Training to the Union of Perturbation Models
Jun 07, 2021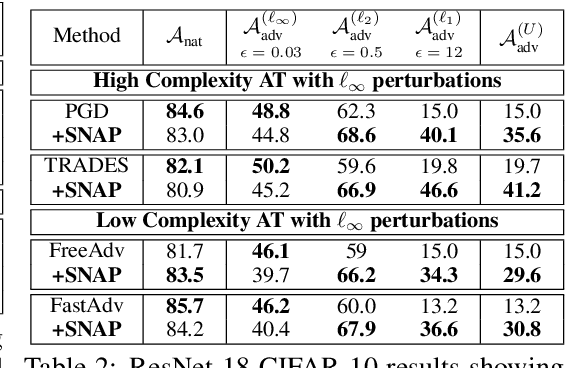
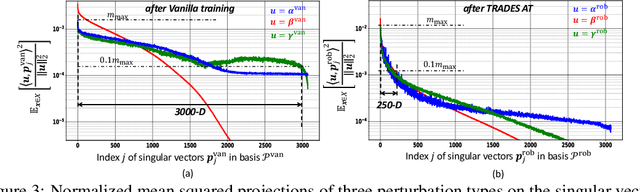
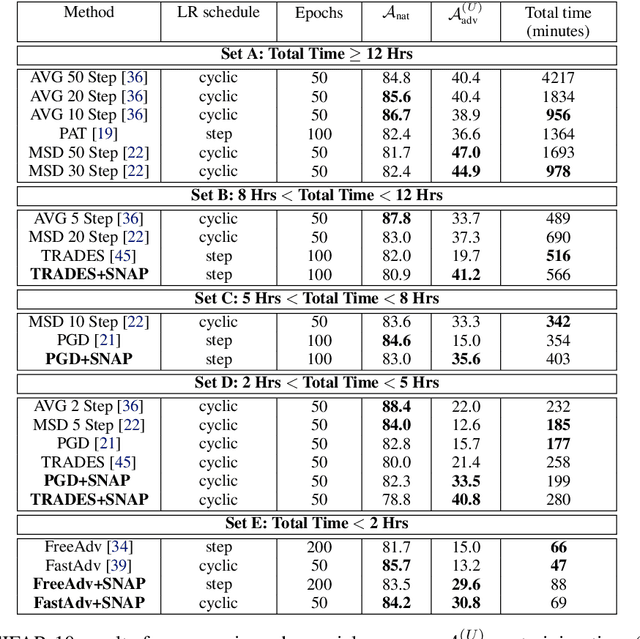
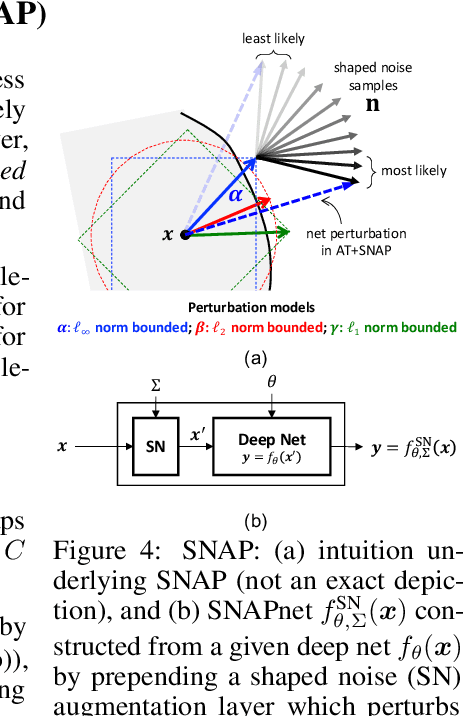
Classical adversarial training (AT) frameworks are designed to achieve high adversarial accuracy against a single attack type, typically $\ell_\infty$ norm-bounded perturbations. Recent extensions in AT have focused on defending against the union of multiple perturbations but this benefit is obtained at the expense of a significant (up to $10\times$) increase in training complexity over single-attack $\ell_\infty$ AT. In this work, we expand the capabilities of widely popular single-attack $\ell_\infty$ AT frameworks to provide robustness to the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations while preserving their training efficiency. Our technique, referred to as Shaped Noise Augmented Processing (SNAP), exploits a well-established byproduct of single-attack AT frameworks -- the reduction in the curvature of the decision boundary of networks. SNAP prepends a given deep net with a shaped noise augmentation layer whose distribution is learned along with network parameters using any standard single-attack AT. As a result, SNAP enhances adversarial accuracy of ResNet-18 on CIFAR-10 against the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations by 14%-to-20% for four state-of-the-art (SOTA) single-attack $\ell_\infty$ AT frameworks, and, for the first time, establishes a benchmark for ResNet-50 and ResNet-101 on ImageNet.
End-to-End Multihop Retrieval for Compositional Question Answering over Long Documents
Jun 01, 2021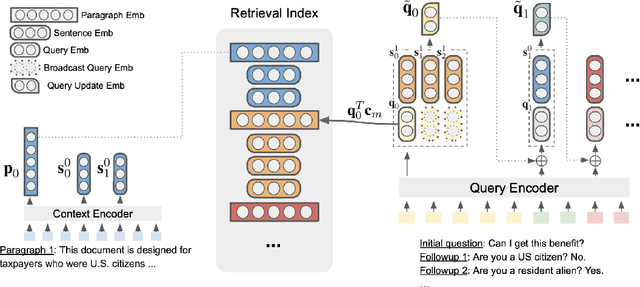
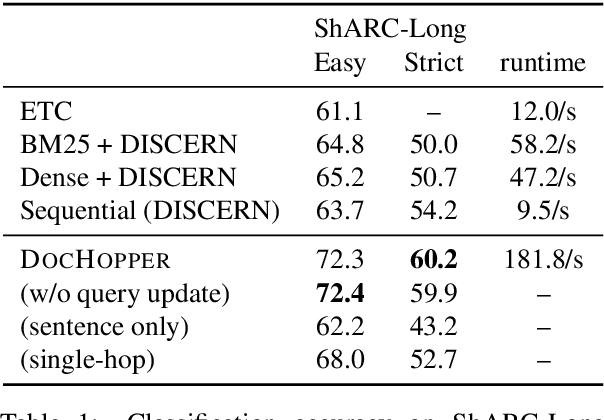
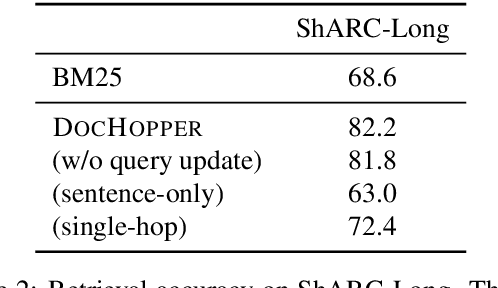
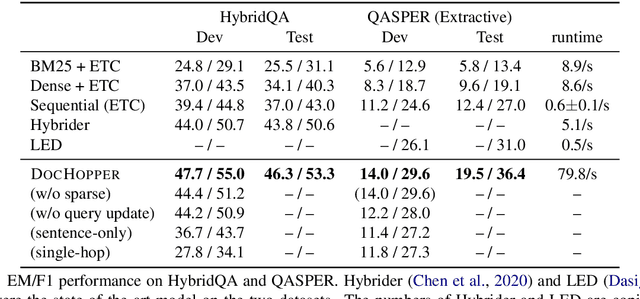
Answering complex questions from long documents requires aggregating multiple pieces of evidence and then predicting the answers. In this paper, we propose a multi-hop retrieval method, DocHopper, to answer compositional questions over long documents. At each step, DocHopper retrieves a paragraph or sentence embedding from the document, mixes the retrieved result with the query, and updates the query for the next step. In contrast to many other retrieval-based methods (e.g., RAG or REALM) the query is not augmented with a token sequence: instead, it is augmented by "numerically" combining it with another neural representation. This means that model is end-to-end differentiable. We demonstrate that utilizing document structure in this was can largely improve question-answering and retrieval performance on long documents. We experimented with DocHopper on three different QA tasks that require reading long documents to answer compositional questions: discourse entailment reasoning, factual QA with table and text, and information seeking QA from academic papers. DocHopper outperforms all baseline models and achieves state-of-the-art results on all datasets. Additionally, DocHopper is efficient at inference time, being 3~10 times faster than the baselines.
Circumpapillary OCT-Focused Hybrid Learning for Glaucoma Grading Using Tailored Prototypical Neural Networks
Jun 25, 2021
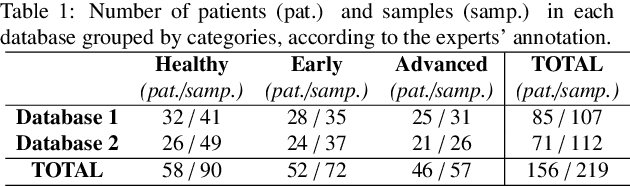
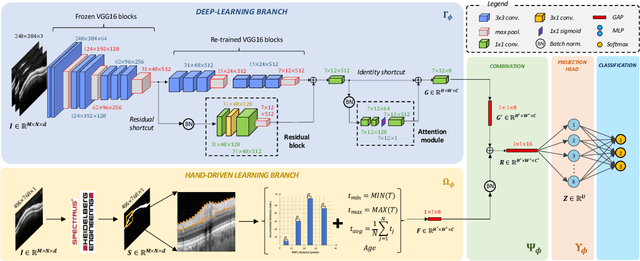

Glaucoma is one of the leading causes of blindness worldwide and Optical Coherence Tomography (OCT) is the quintessential imaging technique for its detection. Unlike most of the state-of-the-art studies focused on glaucoma detection, in this paper, we propose, for the first time, a novel framework for glaucoma grading using raw circumpapillary B-scans. In particular, we set out a new OCT-based hybrid network which combines hand-driven and deep learning algorithms. An OCT-specific descriptor is proposed to extract hand-crafted features related to the retinal nerve fibre layer (RNFL). In parallel, an innovative CNN is developed using skip-connections to include tailored residual and attention modules to refine the automatic features of the latent space. The proposed architecture is used as a backbone to conduct a novel few-shot learning based on static and dynamic prototypical networks. The k-shot paradigm is redefined giving rise to a supervised end-to-end system which provides substantial improvements discriminating between healthy, early and advanced glaucoma samples. The training and evaluation processes of the dynamic prototypical network are addressed from two fused databases acquired via Heidelberg Spectralis system. Validation and testing results reach a categorical accuracy of 0.9459 and 0.8788 for glaucoma grading, respectively. Besides, the high performance reported by the proposed model for glaucoma detection deserves a special mention. The findings from the class activation maps are directly in line with the clinicians' opinion since the heatmaps pointed out the RNFL as the most relevant structure for glaucoma diagnosis.
An Error-Based Approximation Sensing Circuit for Event-Triggered, Low Power Wearable Sensors
Jun 25, 2021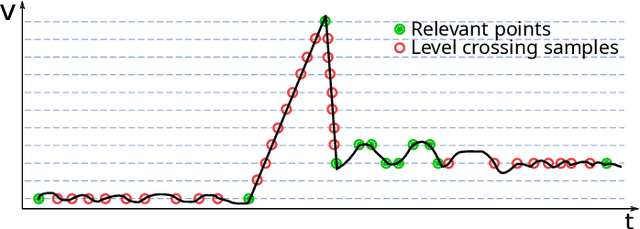
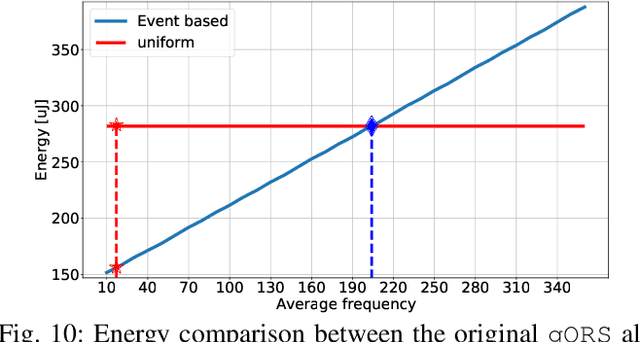
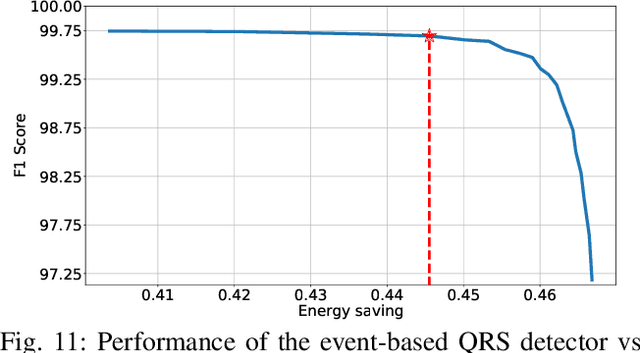
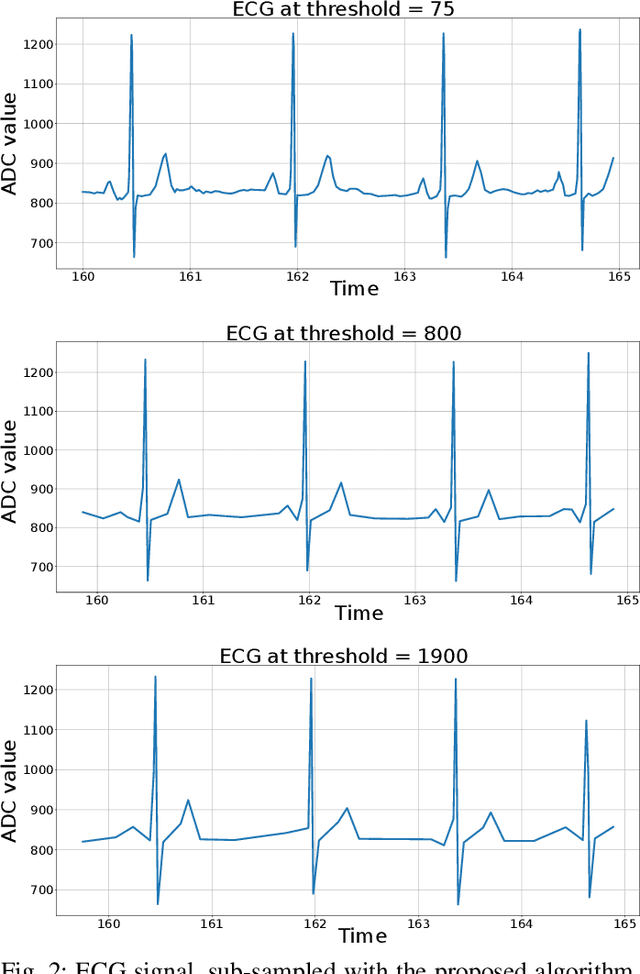
Event-based sensors have the potential to optimize energy consumption at every stage in the signal processing pipeline, including data acquisition, transmission, processing and storage. However, almost all state-of-the-art systems are still built upon the classical Nyquist-based periodic signal acquisition. In this work, we design and validate the Polygonal Approximation Sampler (PAS), a novel circuit to implement a general-purpose event-based sampler using a polygonal approximation algorithm as the underlying sampling trigger. The circuit can be dynamically reconfigured to produce a coarse or a detailed reconstruction of the analog input, by adjusting the error threshold of the approximation. The proposed circuit is designed at the Register Transfer Level and processes each input sample received from the ADC in a single clock cycle. The PAS has been tested with three different types of archetypal signals captured by wearable devices (electrocardiogram, accelerometer and respiration data) and compared with a standard periodic ADC. These tests show that single-channel signals, with slow variations and constant segments (like the used single-lead ECG and the respiration signals) take great advantage from the used sampling technique, reducing the amount of data used up to 99% without significant performance degradation. At the same time, multi-channel signals (like the six-dimensional accelerometer signal) can still benefit from the designed circuit, achieving a reduction factor up to 80% with minor performance degradation. These results open the door to new types of wearable sensors with reduced size and higher battery lifetime.
Learning a Dynamic Map of Visual Appearance
Dec 29, 2020
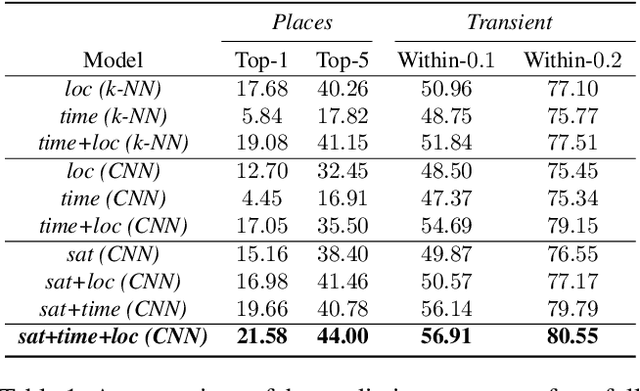

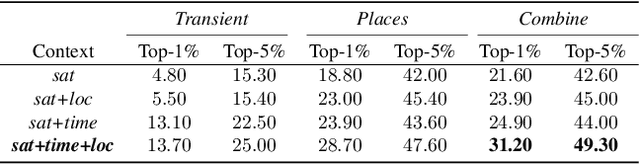
The appearance of the world varies dramatically not only from place to place but also from hour to hour and month to month. Every day billions of images capture this complex relationship, many of which are associated with precise time and location metadata. We propose to use these images to construct a global-scale, dynamic map of visual appearance attributes. Such a map enables fine-grained understanding of the expected appearance at any geographic location and time. Our approach integrates dense overhead imagery with location and time metadata into a general framework capable of mapping a wide variety of visual attributes. A key feature of our approach is that it requires no manual data annotation. We demonstrate how this approach can support various applications, including image-driven mapping, image geolocalization, and metadata verification.
Mitigating Gradient-based Adversarial Attacks via Denoising and Compression
Apr 03, 2021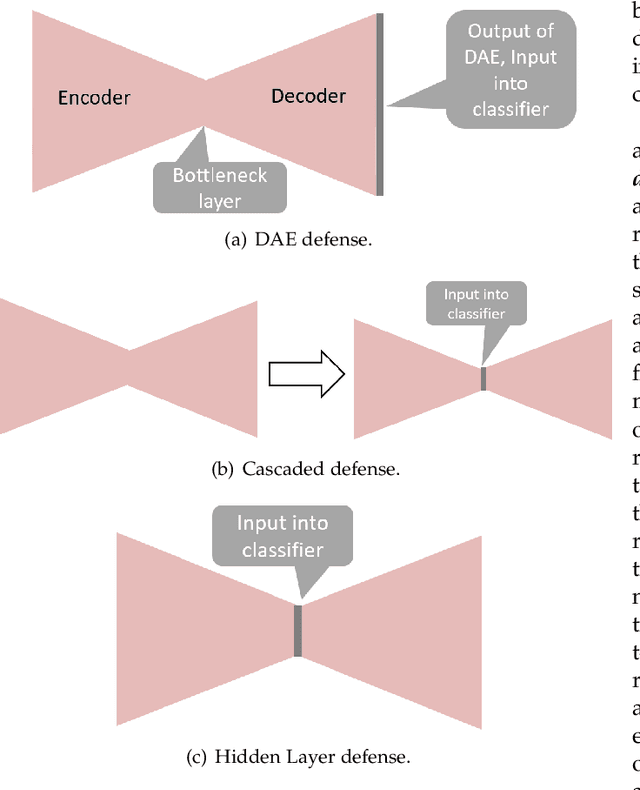
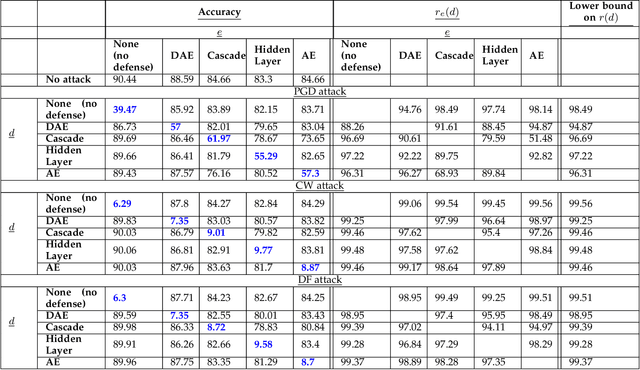
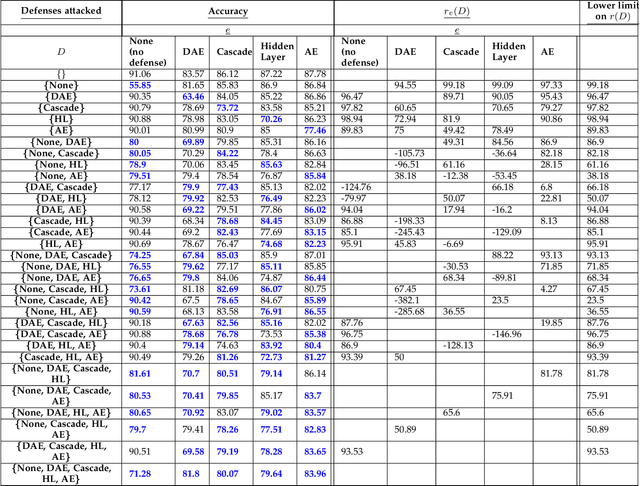
Gradient-based adversarial attacks on deep neural networks pose a serious threat, since they can be deployed by adding imperceptible perturbations to the test data of any network, and the risk they introduce cannot be assessed through the network's original training performance. Denoising and dimensionality reduction are two distinct methods that have been independently investigated to combat such attacks. While denoising offers the ability to tailor the defense to the specific nature of the attack, dimensionality reduction offers the advantage of potentially removing previously unseen perturbations, along with reducing the training time of the network being defended. We propose strategies to combine the advantages of these two defense mechanisms. First, we propose the cascaded defense, which involves denoising followed by dimensionality reduction. To reduce the training time of the defense for a small trade-off in performance, we propose the hidden layer defense, which involves feeding the output of the encoder of a denoising autoencoder into the network. Further, we discuss how adaptive attacks against these defenses could become significantly weak when an alternative defense is used, or when no defense is used. In this light, we propose a new metric to evaluate a defense which measures the sensitivity of the adaptive attack to modifications in the defense. Finally, we present a guideline for building an ordered repertoire of defenses, a.k.a. a defense infrastructure, that adjusts to limited computational resources in presence of uncertainty about the attack strategy.
Amortized Generation of Sequential Counterfactual Explanations for Black-box Models
Jun 07, 2021
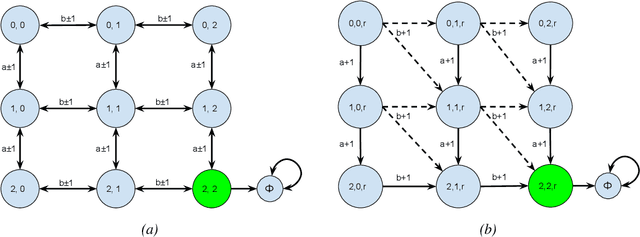

Explainable machine learning (ML) has gained traction in recent years due to the increasing adoption of ML-based systems in many sectors. Counterfactual explanations (CFEs) provide ``what if'' feedback of the form ``if an input datapoint were $x'$ instead of $x$, then an ML-based system's output would be $y'$ instead of $y$.'' CFEs are attractive due to their actionable feedback, amenability to existing legal frameworks, and fidelity to the underlying ML model. Yet, current CFE approaches are single shot -- that is, they assume $x$ can change to $x'$ in a single time period. We propose a novel stochastic-control-based approach that generates sequential CFEs, that is, CFEs that allow $x$ to move stochastically and sequentially across intermediate states to a final state $x'$. Our approach is model agnostic and black box. Furthermore, calculation of CFEs is amortized such that once trained, it applies to multiple datapoints without the need for re-optimization. In addition to these primary characteristics, our approach admits optional desiderata such as adherence to the data manifold, respect for causal relations, and sparsity -- identified by past research as desirable properties of CFEs. We evaluate our approach using three real-world datasets and show successful generation of sequential CFEs that respect other counterfactual desiderata.
Non-isomorphic Inter-modality Graph Alignment and Synthesis for Holistic Brain Mapping
Jun 30, 2021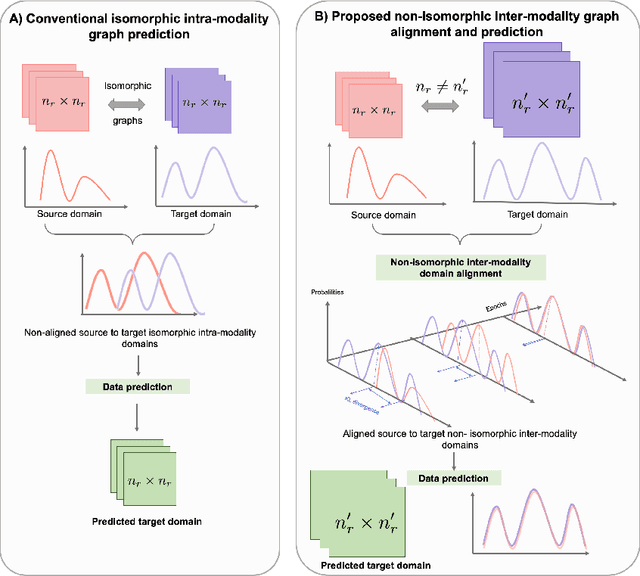
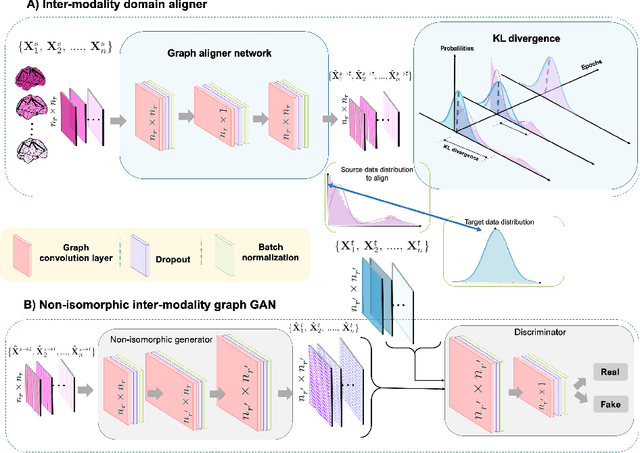
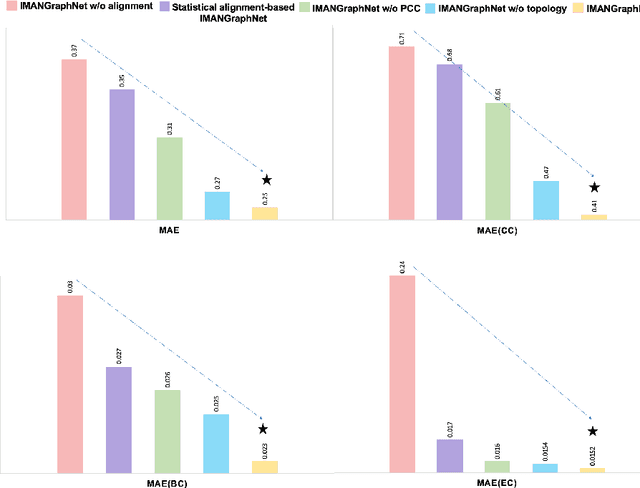
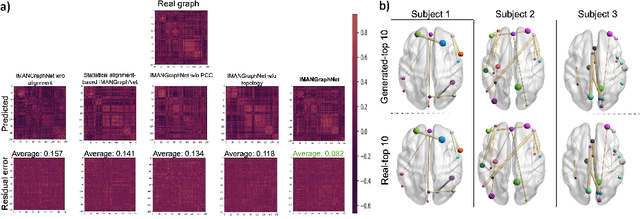
Brain graph synthesis marked a new era for predicting a target brain graph from a source one without incurring the high acquisition cost and processing time of neuroimaging data. However, existing multi-modal graph synthesis frameworks have several limitations. First, they mainly focus on generating graphs from the same domain (intra-modality), overlooking the rich multimodal representations of brain connectivity (inter-modality). Second, they can only handle isomorphic graph generation tasks, limiting their generalizability to synthesizing target graphs with a different node size and topological structure from those of the source one. More importantly, both target and source domains might have different distributions, which causes a domain fracture between them (i.e., distribution misalignment). To address such challenges, we propose an inter-modality aligner of non-isomorphic graphs (IMANGraphNet) framework to infer a target graph modality based on a given modality. Our three core contributions lie in (i) predicting a target graph (e.g., functional) from a source graph (e.g., morphological) based on a novel graph generative adversarial network (gGAN); (ii) using non-isomorphic graphs for both source and target domains with a different number of nodes, edges and structure; and (iii) enforcing the predicted target distribution to match that of the ground truth graphs using a graph autoencoder to relax the designed loss oprimization. To handle the unstable behavior of gGAN, we design a new Ground Truth-Preserving (GT-P) loss function to guide the generator in learning the topological structure of ground truth brain graphs. Our comprehensive experiments on predicting functional from morphological graphs demonstrate the outperformance of IMANGraphNet in comparison with its variants. This can be further leveraged for integrative and holistic brain mapping in health and disease.
Deep Equilibrium Architectures for Inverse Problems in Imaging
Feb 16, 2021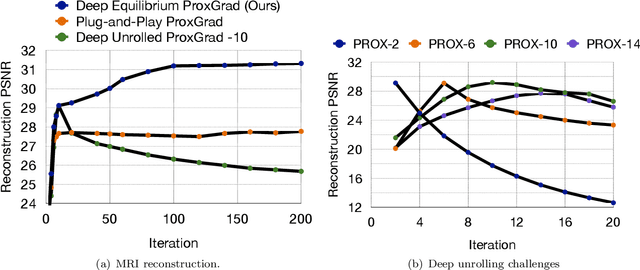
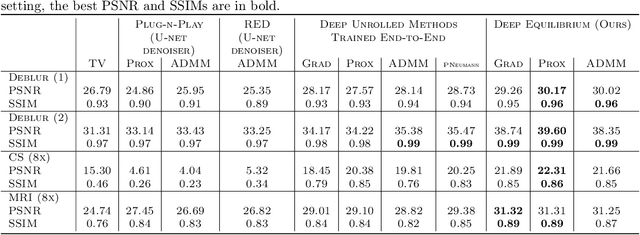
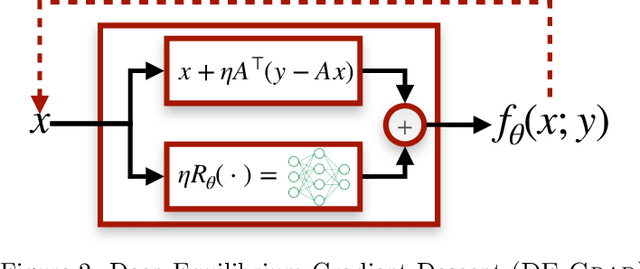
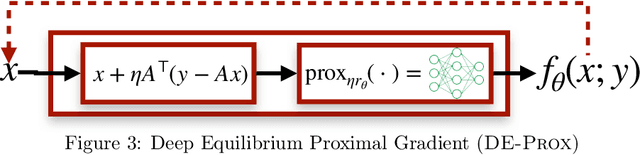
Recent efforts on solving inverse problems in imaging via deep neural networks use architectures inspired by a fixed number of iterations of an optimization method. The number of iterations is typically quite small due to difficulties in training networks corresponding to more iterations; the resulting solvers cannot be run for more iterations at test time without incurring significant errors. This paper describes an alternative approach corresponding to an {\em infinite} number of iterations, yielding up to a 4dB PSNR improvement in reconstruction accuracy above state-of-the-art alternatives and where the computational budget can be selected at test time to optimize context-dependent trade-offs between accuracy and computation. The proposed approach leverages ideas from Deep Equilibrium Models, where the fixed-point iteration is constructed to incorporate a known forward model and insights from classical optimization-based reconstruction methods.