 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inferring Objectives in Continuous Dynamic Games from Noise-Corrupted Partial State Observations
Jun 16, 2021
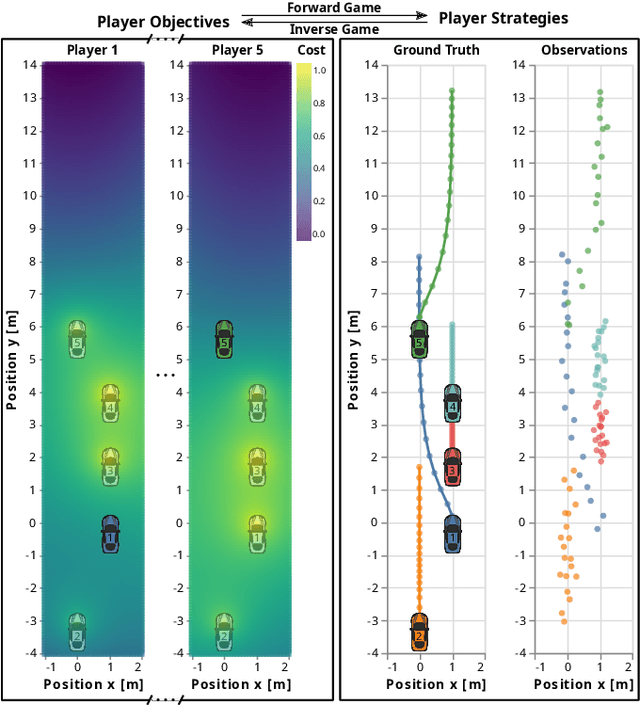
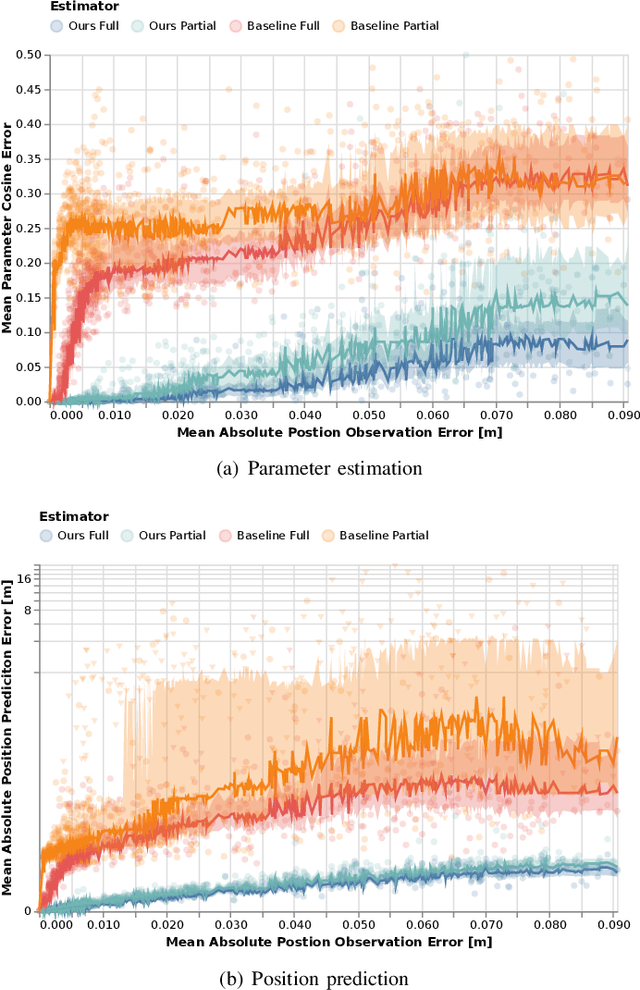
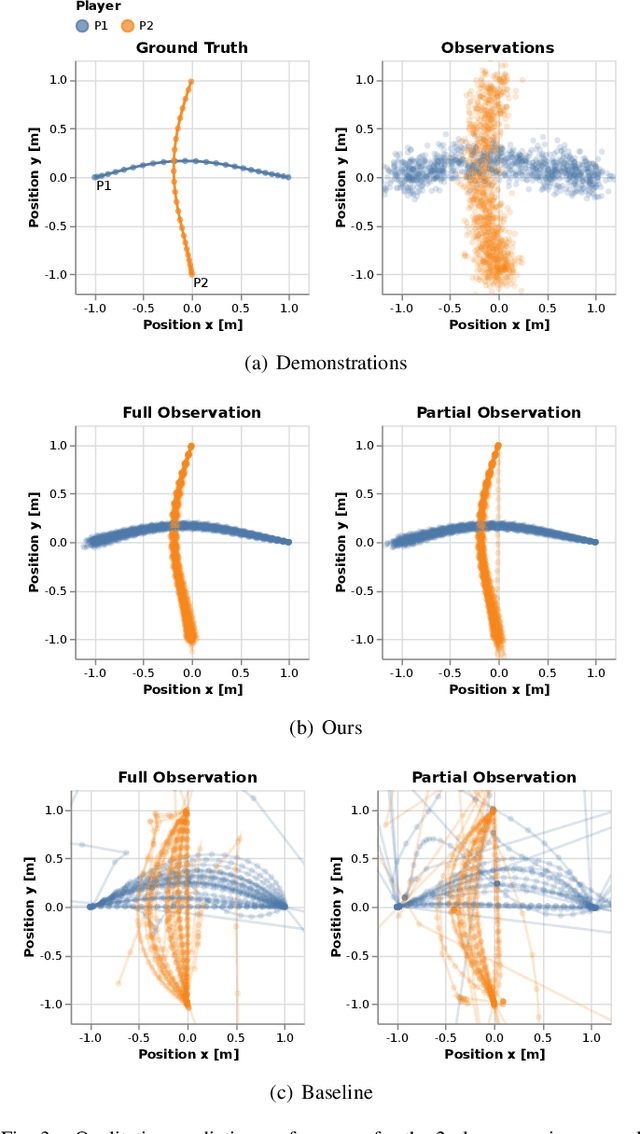
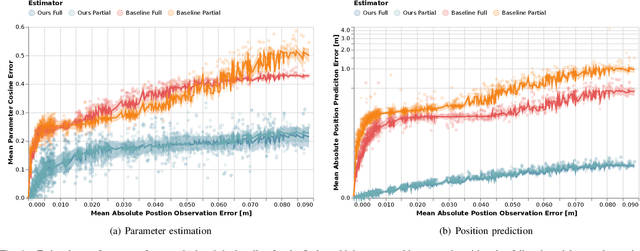
Robots and autonomous systems must interact with one another and their environment to provide high-quality services to their users. Dynamic game theory provides an expressive theoretical framework for modeling scenarios involving multiple agents with differing objectives interacting over time. A core challenge when formulating a dynamic game is designing objectives for each agent that capture desired behavior. In this paper, we propose a method for inferring parametric objective models of multiple agents based on observed interactions. Our inverse game solver jointly optimizes player objectives and continuous-state estimates by coupling them through Nash equilibrium constraints. Hence, our method is able to directly maximize the observation likelihood rather than other non-probabilistic surrogate criteria. Our method does not require full observations of game states or player strategies to identify player objectives. Instead, it robustly recovers this information from noisy, partial state observations. As a byproduct of estimating player objectives, our method computes a Nash equilibrium trajectory corresponding to those objectives. Thus, it is suitable for downstream trajectory forecasting tasks. We demonstrate our method in several simulated traffic scenarios. Results show that it reliably estimates player objectives from a short sequence of noise-corrupted partial state observations. Furthermore, using the estimated objectives, our method makes accurate predictions of each player's trajectory.
Large-scale phase retrieval
Apr 06, 2021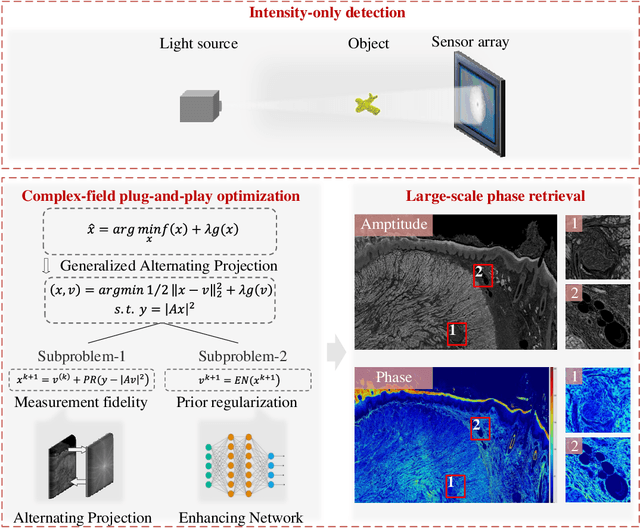
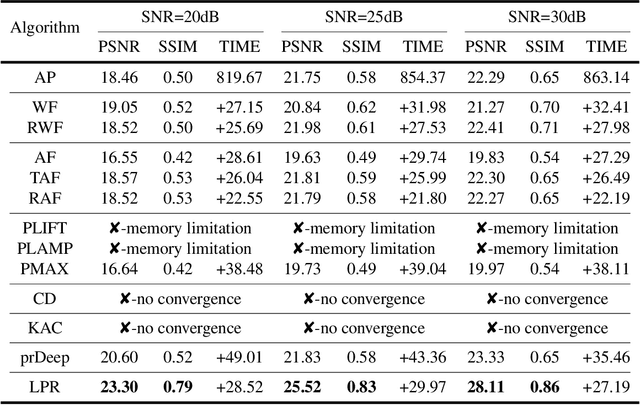
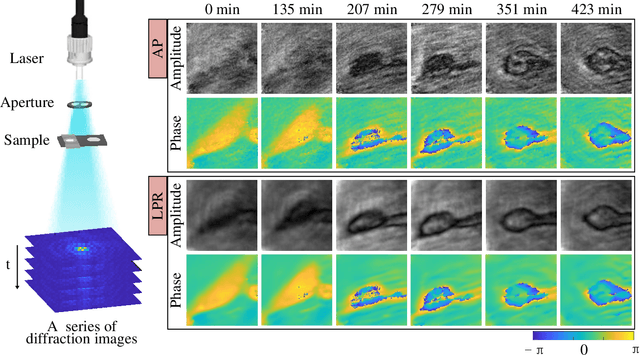
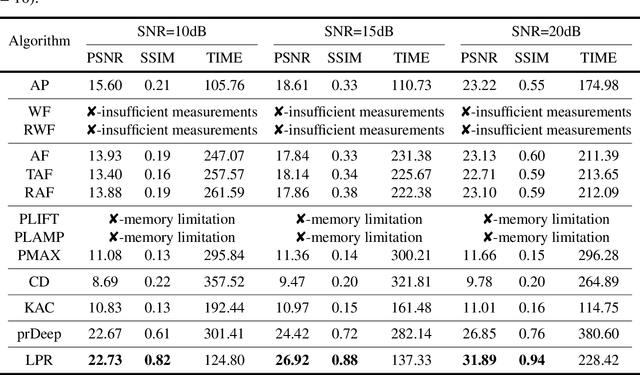
High-throughput computational imaging requires efficient processing algorithms to retrieve multi-dimensional and multi-scale information. In computational phase imaging, phase retrieval (PR) is required to reconstruct both amplitude and phase in complex space from intensity-only measurements. The existing PR algorithms suffer from the tradeoff among low computational complexity, robustness to measurement noise and strong generalization on different modalities. In this work, we report an efficient large-scale phase retrieval technique termed as LPR. It extends the plug-and-play generalized-alternating-projection framework from real space to nonlinear complex space. The alternating projection solver and enhancing neural network are respectively derived to tackle the measurement formation and statistical prior regularization. This framework compensates the shortcomings of each operator, so as to realize high-fidelity phase retrieval with low computational complexity and strong generalization. We applied the technique for a series of computational phase imaging modalities including coherent diffraction imaging, coded diffraction pattern imaging, and Fourier ptychographic microscopy. Extensive simulations and experiments validate that the technique outperforms the existing PR algorithms with as much as 17dB enhancement on signal-to-noise ratio, and more than one order-of-magnitude increased running efficiency. Besides, we for the first time demonstrate ultra-large-scale phase retrieval at the 8K level (7680$\times$4320 pixels) in minute-level time.
Multi-Task Learning for Scalable and Dense Multi-Layer Bayesian Map Inference
Jun 28, 2021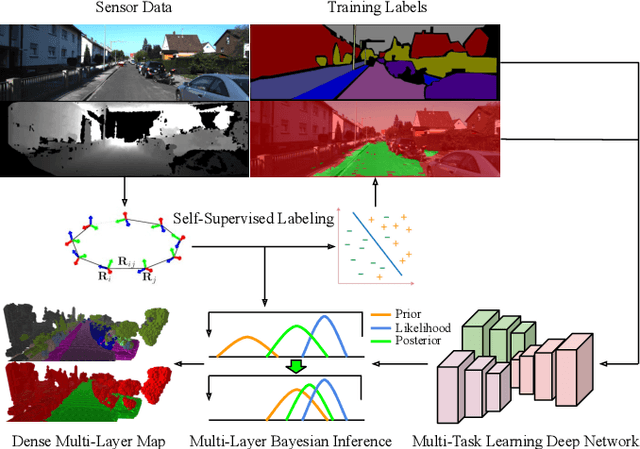


This paper presents a novel and flexible multi-task multi-layer Bayesian mapping framework with readily extendable attribute layers. The proposed framework goes beyond modern metric-semantic maps to provide even richer environmental information for robots in a single mapping formalism while exploiting existing inter-layer correlations. It removes the need for a robot to access and process information from many separate maps when performing a complex task and benefits from the correlation between map layers, advancing the way robots interact with their environments. To this end, we design a multi-task deep neural network with attention mechanisms as our front-end to provide multiple observations for multiple map layers simultaneously. Our back-end runs a scalable closed-form Bayesian inference with only logarithmic time complexity. We apply the framework to build a dense robotic map including metric-semantic occupancy and traversability layers. Traversability ground truth labels are automatically generated from exteroceptive sensory data in a self-supervised manner. We present extensive experimental results on publicly available data sets and data collected by a 3D bipedal robot platform on the University of Michigan North Campus and show reliable mapping performance in different environments. Finally, we also discuss how the current framework can be extended to incorporate more information such as friction, signal strength, temperature, and physical quantity concentration using Gaussian map layers. The software for reproducing the presented results or running on customized data is made publicly available.
Measuring and Increasing Context Usage in Context-Aware Machine Translation
Jun 02, 2021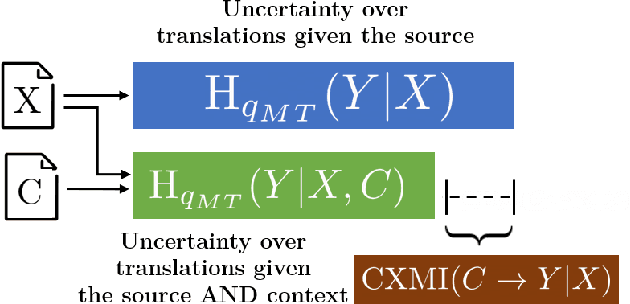

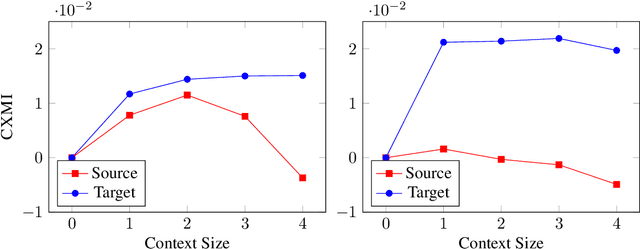
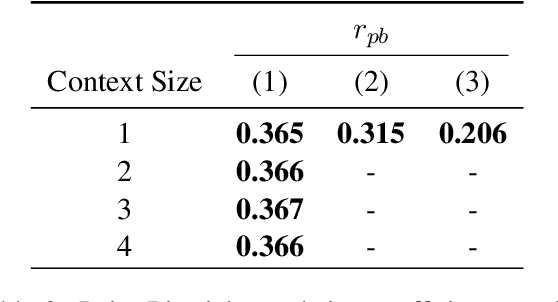
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context -- context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify the usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that conditioning on a longer context has a diminishing effect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method increases context usage and that this reflects on the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
John praised Mary because he? Implicit Causality Bias and Its Interaction with Explicit Cues in LMs
Jun 02, 2021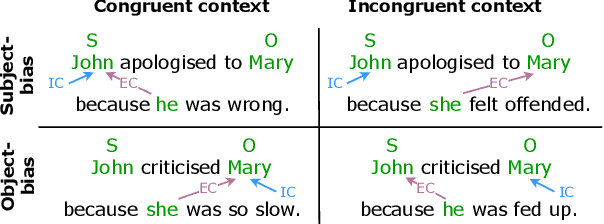
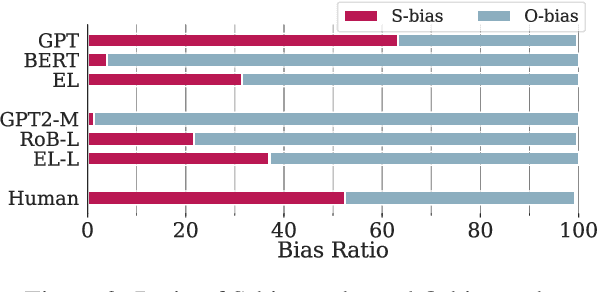
Some interpersonal verbs can implicitly attribute causality to either their subject or their object and are therefore said to carry an implicit causality (IC) bias. Through this bias, causal links can be inferred from a narrative, aiding language comprehension. We investigate whether pre-trained language models (PLMs) encode IC bias and use it at inference time. We find that to be the case, albeit to different degrees, for three distinct PLM architectures. However, causes do not always need to be implicit -- when a cause is explicitly stated in a subordinate clause, an incongruent IC bias associated with the verb in the main clause leads to a delay in human processing. We hypothesize that the temporary challenge humans face in integrating the two contradicting signals, one from the lexical semantics of the verb, one from the sentence-level semantics, would be reflected in higher error rates for models on tasks dependent on causal links. The results of our study lend support to this hypothesis, suggesting that PLMs tend to prioritize lexical patterns over higher-order signals.
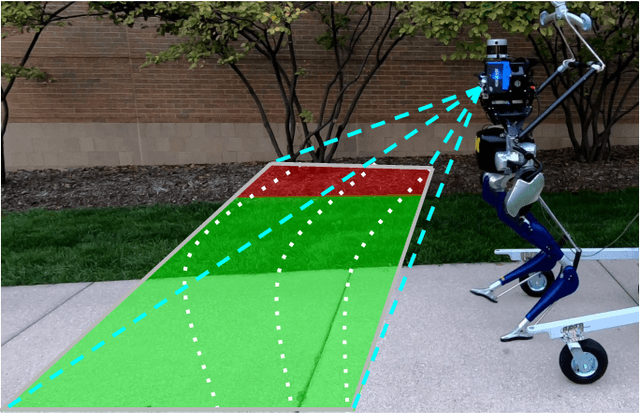
Toward Robotic Weed Control: Detection of Nutsedge Weed in Bermudagrass Turf Using Inaccurate and Insufficient Training Data
Jun 16, 2021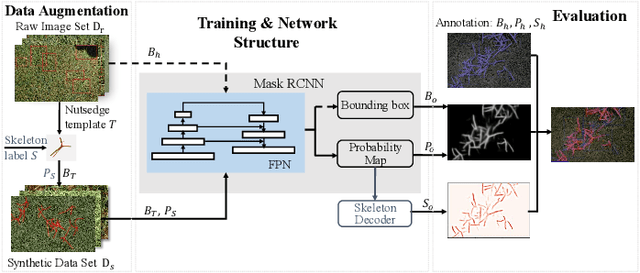
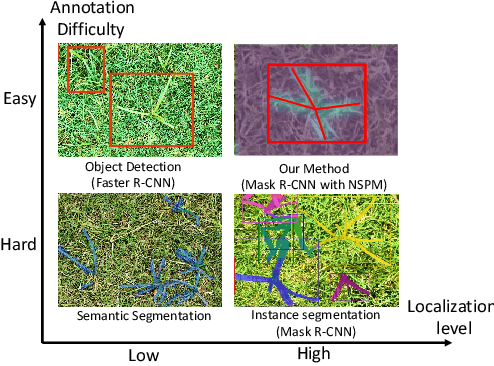
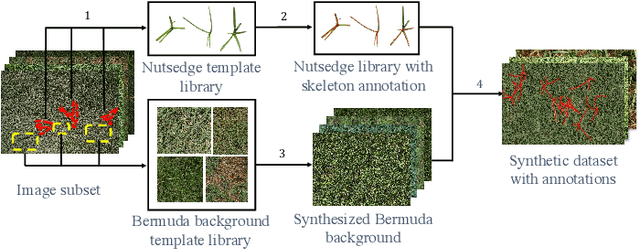

To enable robotic weed control, we develop algorithms to detect nutsedge weed from bermudagrass turf. Due to the similarity between the weed and the background turf, manual data labeling is expensive and error-prone. Consequently, directly applying deep learning methods for object detection cannot generate satisfactory results. Building on an instance detection approach (i.e. Mask R-CNN), we combine synthetic data with raw data to train the network. We propose an algorithm to generate high fidelity synthetic data, adopting different levels of annotations to reduce labeling cost. Moreover, we construct a nutsedge skeleton-based probabilistic map (NSPM) as the neural network input to reduce the reliance on pixel-wise precise labeling. We also modify loss function from cross entropy to Kullback-Leibler divergence which accommodates uncertainty in the labeling process. We implement the proposed algorithm and compare it with both Faster R-CNN and Mask R-CNN. The results show that our design can effectively overcome the impact of imprecise and insufficient training sample issues and significantly outperform the Faster R-CNN counterpart with a false negative rate of only 0.4%. In particular, our approach also reduces labeling time by 95% while achieving better performance if comparing with the original Mask R-CNN approach.
Research on Mosaic Image Data Enhancement for Overlapping Ship Targets
May 11, 2021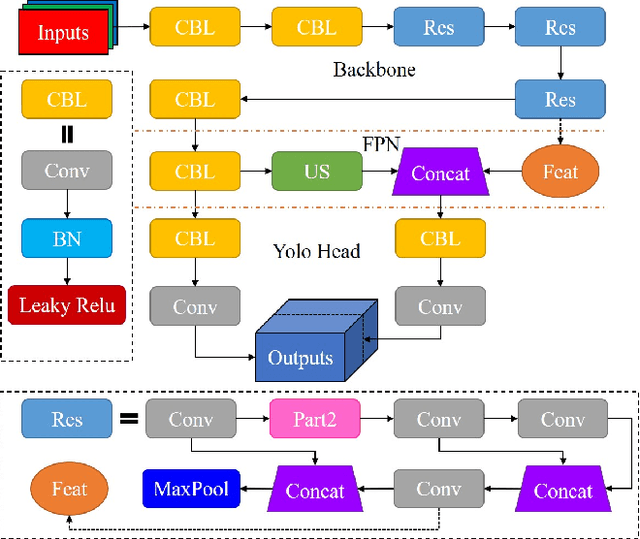

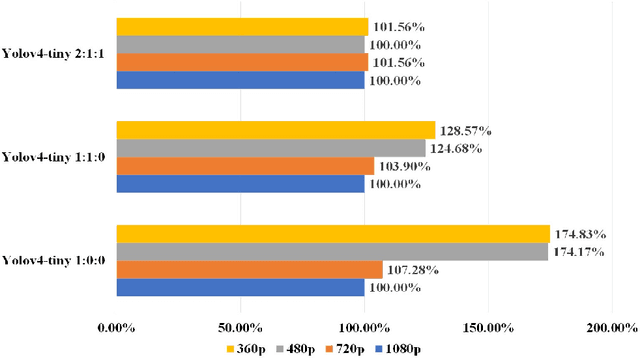
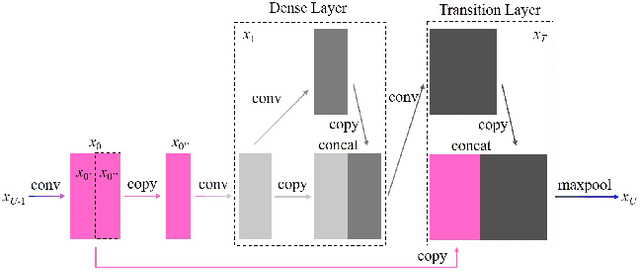
The problem of overlapping occlusion in target recognition has been a difficult research problem, and the situation of mutual occlusion of ship targets in narrow waters still exists. In this paper, an improved mosaic data enhancement method is proposed, which optimizes the reading method of the data set, strengthens the learning ability of the detection algorithm for local features, improves the recognition accuracy of overlapping targets while keeping the test speed unchanged, reduces the decay rate of recognition ability under different resolutions, and strengthens the robustness of the algorithm. The real test experiments prove that, relative to the original algorithm, the improved algorithm improves the recognition accuracy of overlapping targets by 2.5%, reduces the target loss time by 17%, and improves the recognition stability under different video resolutions by 27.01%.
Finding a latent k-simplex in O(k . nnz(data)) time via Subset Smoothing
Apr 19, 2019The core problem in many Latent Variable Models, widely used in Unsupervised Learning is to find a latent k-simplex K in Rd given perturbed points from it, many of which lie far outside the simplex. This problem was stated in [2] as an open problem. We address this problem under two deterministic assumptions which replace varied stochastic assumptions specific to relevant individual models. Our first contribution is to show that the convex hull K' of the averages of all delta n sized subsets of data points is close to K. We call this subset-smoothing. While K' can have exponentially many vertices, it is easily seen to have a polynomial time Optimization Oracle which in fact runs in time O(nnz(data)). This is the starting point for our algorithm. The algorithm is simple: it has k stages in each of which we use the oracle to find maximum of a carefully chosen linear function over K'; the optimal x is an approximation to a new vertex of K. The simplicity does not carry over to the proof of correctness. The proof is involved and uses existing and new tools from Numerical Analysis, especially angles between singular spaces of close-by matrices. However, the simplicity of the algorithm, especially the fact the only way we use the data is to do matrix-vector products leads to the claimed time bound. This matches the best known algorithms in the special cases and is better when the input is sparse as indeed is the case in many applications. Our algorithm applies to many special cases, including Topic Models, Approximate Non-negative Matrix factorization, Overlapping community Detection and Clustering.
On the adoption of abductive reasoning for time series interpretation
Jun 25, 2018
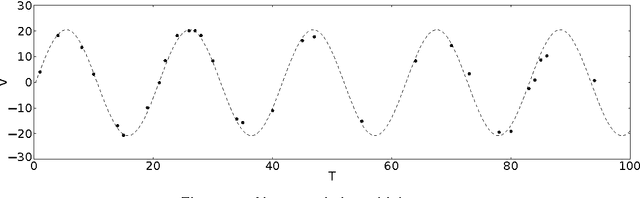


Time series interpretation aims to provide an explanation of what is observed in terms of its underlying processes. The present work is based on the assumption that the common classification-based approaches to time series interpretation suffer from a set of inherent weaknesses, whose ultimate cause lies in the monotonic nature of the deductive reasoning paradigm. In this document we propose a new approach to this problem, based on the initial hypothesis that abductive reasoning properly accounts for the human ability to identify and characterize the patterns appearing in a time series. The result of this interpretation is a set of conjectures in the form of observations, organized into an abstraction hierarchy and explaining what has been observed. A knowledge-based framework and a set of algorithms for the interpretation task are provided, implementing a hypothesize-and-test cycle guided by an attentional mechanism. As a representative application domain, interpretation of the electrocardiogram allows us to highlight the strengths of the proposed approach in comparison with traditional classification-based approaches.
* 44 pages, 9 figures
CDSM -- Casual Inference using Deep Bayesian Dynamic Survival Models
Feb 24, 2021
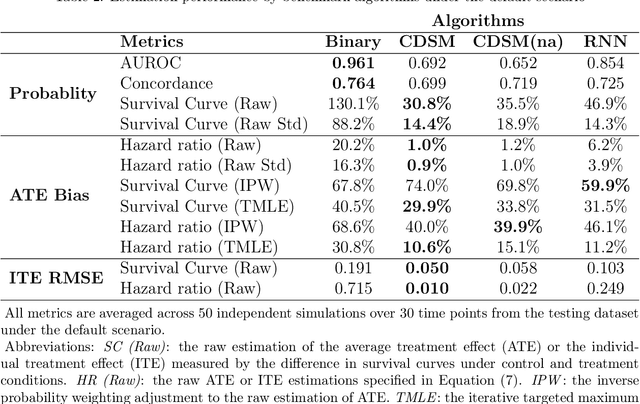
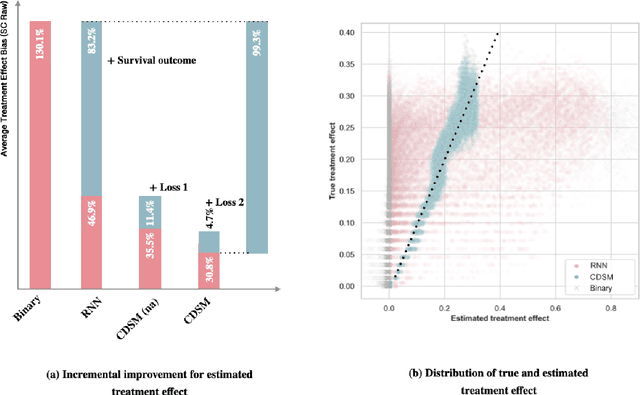
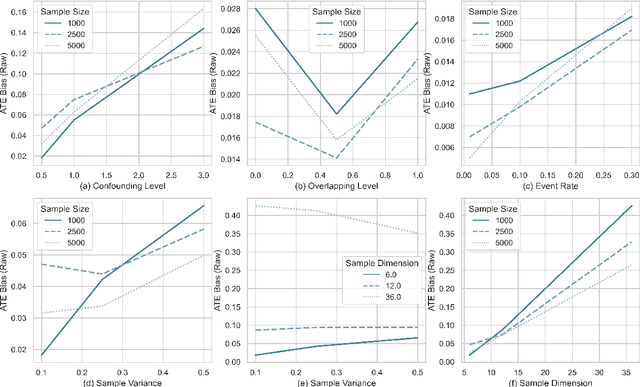
A smart healthcare system that supports clinicians for risk-calibrated treatment assessment typically requires the accurate modeling of time-to-event outcomes. To tackle this sequential treatment effect estimation problem, we developed causal dynamic survival model (CDSM) for causal inference with survival outcomes using longitudinal electronic health record (EHR). CDSM has impressive explanatory performance while maintaining the prediction capability of conventional binary neural network predictors. It borrows the strength from explanatory framework including the survival analysis and counterfactual framework and integrates them with the prediction power from a deep Bayesian recurrent neural network to extract implicit knowledge from EHR data. In two large clinical cohort studies, our model identified the conditional average treatment effect in accordance with previous literature yet detected individual effect heterogeneity over time and patient subgroups. The model provides individualized and clinically interpretable treatment effect estimations to improve patient outcomes.