 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STRESS: Super-Resolution for Dynamic Fetal MRI using Self-Supervised Learning
Jun 23, 2021
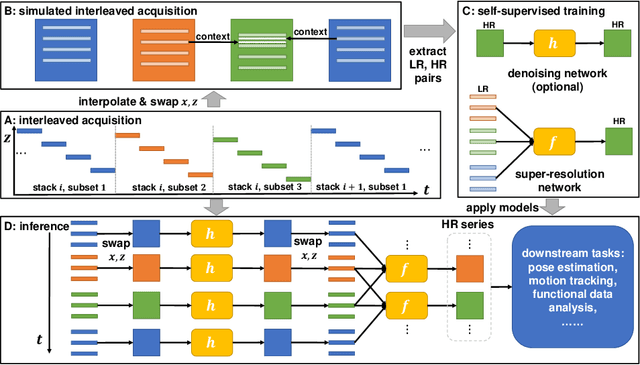
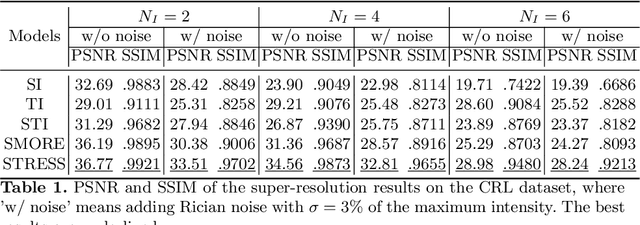
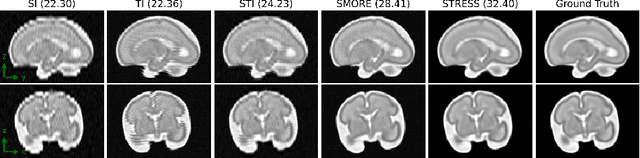

Fetal motion is unpredictable and rapid on the scale of conventional MR scan times. Therefore, dynamic fetal MRI, which aims at capturing fetal motion and dynamics of fetal function, is limited to fast imaging techniques with compromises in image quality and resolution. Super-resolution for dynamic fetal MRI is still a challenge, especially when multi-oriented stacks of image slices for oversampling are not available and high temporal resolution for recording the dynamics of the fetus or placenta is desired. Further, fetal motion makes it difficult to acquire high-resolution images for supervised learning methods. To address this problem, in this work, we propose STRESS (Spatio-Temporal Resolution Enhancement with Simulated Scans), a self-supervised super-resolution framework for dynamic fetal MRI with interleaved slice acquisitions. Our proposed method simulates an interleaved slice acquisition along the high-resolution axis on the originally acquired data to generate pairs of low- and high-resolution images. Then, it trains a super-resolution network by exploiting both spatial and temporal correlations in the MR time series, which is used to enhance the resolution of the original data. Evaluations on both simulated and in utero data show that our proposed method outperforms other self-supervised super-resolution methods and improves image quality, which is beneficial to other downstream tasks and evaluations.
Towards an Automated Pipeline for Detecting and Classifying Malware through Machine Learning
Jun 10, 2021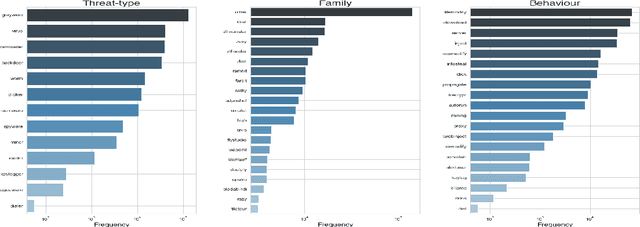

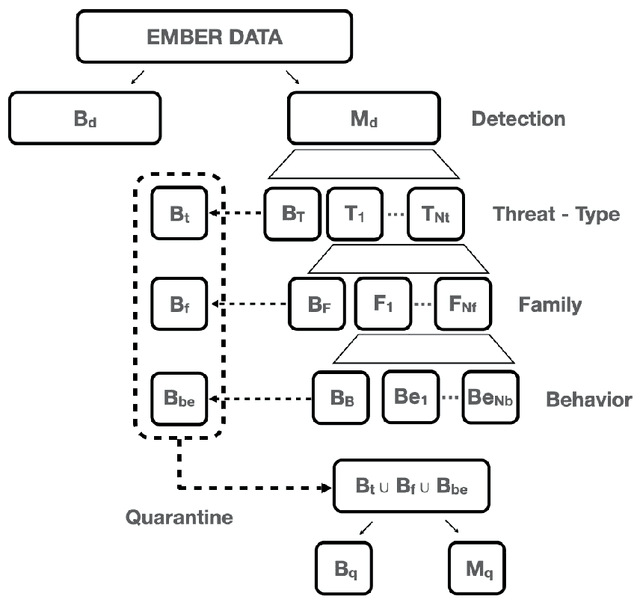
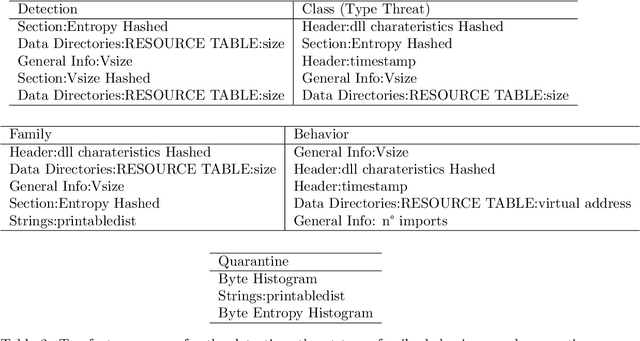
The constant growth in the number of malware - software or code fragment potentially harmful for computers and information networks - and the use of sophisticated evasion and obfuscation techniques have seriously hindered classic signature-based approaches. On the other hand, malware detection systems based on machine learning techniques started offering a promising alternative to standard approaches, drastically reducing analysis time and turning out to be more robust against evasion and obfuscation techniques. In this paper, we propose a malware taxonomic classification pipeline able to classify Windows Portable Executable files (PEs). Given an input PE sample, it is first classified as either malicious or benign. If malicious, the pipeline further analyzes it in order to establish its threat type, family, and behavior(s). We tested the proposed pipeline on the open source dataset EMBER, containing approximately 1 million PE samples, analyzed through static analysis. Obtained malware detection results are comparable to other academic works in the current state of art and, in addition, we provide an in-depth classification of malicious samples. Models used in the pipeline provides interpretable results which can help security analysts in better understanding decisions taken by the automated pipeline.
On the adoption of abductive reasoning for time series interpretation
Jun 25, 2018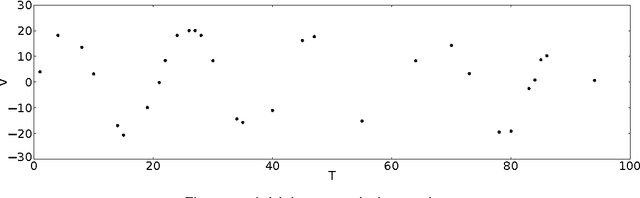
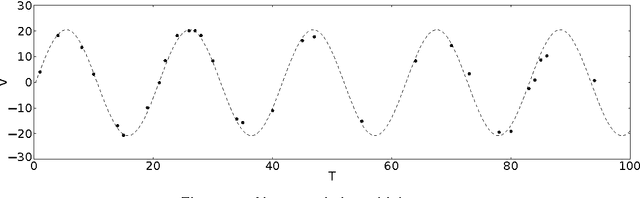


Time series interpretation aims to provide an explanation of what is observed in terms of its underlying processes. The present work is based on the assumption that the common classification-based approaches to time series interpretation suffer from a set of inherent weaknesses, whose ultimate cause lies in the monotonic nature of the deductive reasoning paradigm. In this document we propose a new approach to this problem, based on the initial hypothesis that abductive reasoning properly accounts for the human ability to identify and characterize the patterns appearing in a time series. The result of this interpretation is a set of conjectures in the form of observations, organized into an abstraction hierarchy and explaining what has been observed. A knowledge-based framework and a set of algorithms for the interpretation task are provided, implementing a hypothesize-and-test cycle guided by an attentional mechanism. As a representative application domain, interpretation of the electrocardiogram allows us to highlight the strengths of the proposed approach in comparison with traditional classification-based approaches.
* 44 pages, 9 figures
Finding a latent k-simplex in O(k . nnz(data)) time via Subset Smoothing
Apr 19, 2019The core problem in many Latent Variable Models, widely used in Unsupervised Learning is to find a latent k-simplex K in Rd given perturbed points from it, many of which lie far outside the simplex. This problem was stated in [2] as an open problem. We address this problem under two deterministic assumptions which replace varied stochastic assumptions specific to relevant individual models. Our first contribution is to show that the convex hull K' of the averages of all delta n sized subsets of data points is close to K. We call this subset-smoothing. While K' can have exponentially many vertices, it is easily seen to have a polynomial time Optimization Oracle which in fact runs in time O(nnz(data)). This is the starting point for our algorithm. The algorithm is simple: it has k stages in each of which we use the oracle to find maximum of a carefully chosen linear function over K'; the optimal x is an approximation to a new vertex of K. The simplicity does not carry over to the proof of correctness. The proof is involved and uses existing and new tools from Numerical Analysis, especially angles between singular spaces of close-by matrices. However, the simplicity of the algorithm, especially the fact the only way we use the data is to do matrix-vector products leads to the claimed time bound. This matches the best known algorithms in the special cases and is better when the input is sparse as indeed is the case in many applications. Our algorithm applies to many special cases, including Topic Models, Approximate Non-negative Matrix factorization, Overlapping community Detection and Clustering.
Recent Advances on Sub-Nyquist Sampling-Based Wideband Spectrum Sensing
May 07, 2021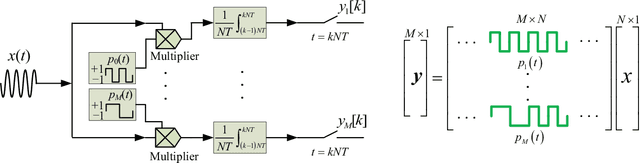
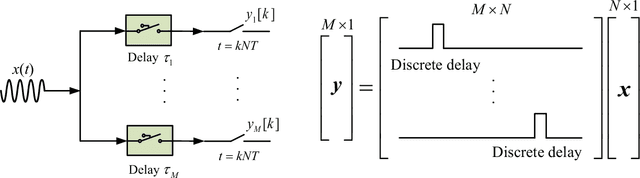
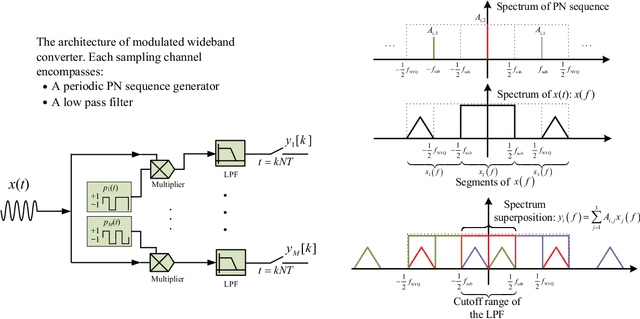
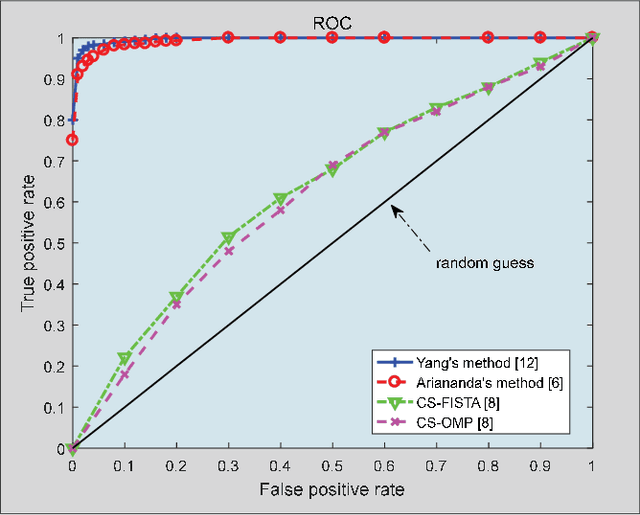
Cognitive radio (CR) is a promising technology enabling efficient utilization of the spectrum resource for future wireless systems. As future CR networks are envisioned to operate over a wide frequency range, advanced wideband spectrum sensing (WBSS) capable of quickly and reliably detecting idle spectrum bands across a wide frequency span is essential. In this article, we provide an overview of recent advances on sub-Nyquist sampling-based WBSS techniques, including compressed sensing-based methods and compressive covariance sensing-based methods. An elaborate discussion of the pros and cons of each approach is presented, along with some challenging issues for future research. A comparative study suggests that the compressive covariance sensing-based approach offers a more competitive solution for reliable real-time WBSS.
JSI at the FinSim-2 task: Ontology-Augmented Financial Concept Classification
Jun 17, 2021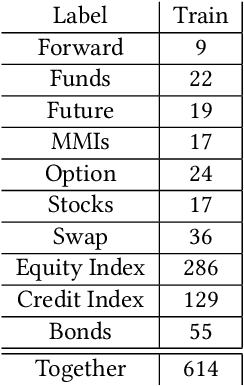
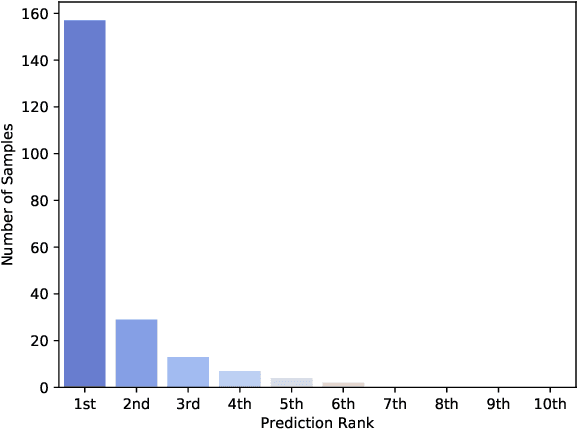
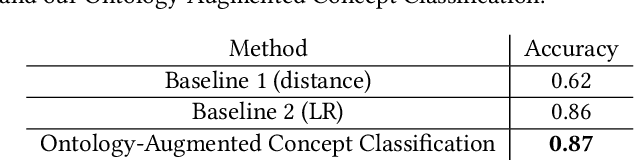

Ontologies are increasingly used for machine reasoning over the last few years. They can provide explanations of concepts or be used for concept classification if there exists a mapping from the desired labels to the relevant ontology. Another advantage of using ontologies is that they do not need a learning process, meaning that we do not need the train data or time before using them. This paper presents a practical use of an ontology for a classification problem from the financial domain. It first transforms a given ontology to a graph and proceeds with generalization with the aim to find common semantic descriptions of the input sets of financial concepts. We present a solution to the shared task on Learning Semantic Similarities for the Financial Domain (FinSim-2 task). The task is to design a system that can automatically classify concepts from the Financial domain into the most relevant hypernym concept in an external ontology - the Financial Industry Business Ontology. We propose a method that maps given concepts to the mentioned ontology and performs a graph search for the most relevant hypernyms. We also employ a word vectorization method and a machine learning classifier to supplement the method with a ranked list of labels for each concept.
IntelliCAT: Intelligent Machine Translation Post-Editing with Quality Estimation and Translation Suggestion
May 25, 2021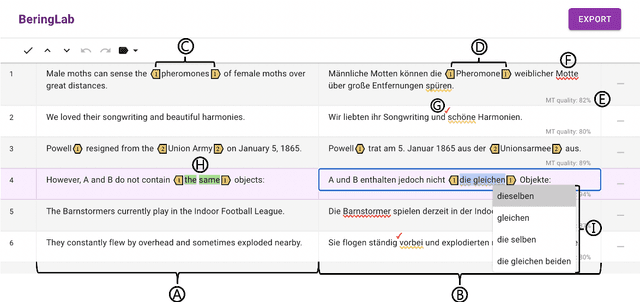
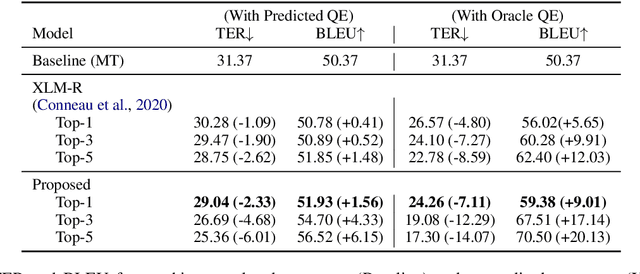
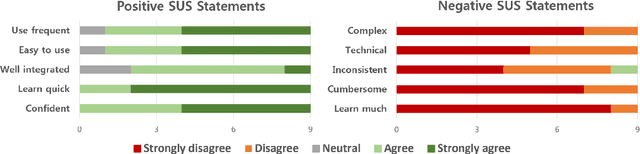
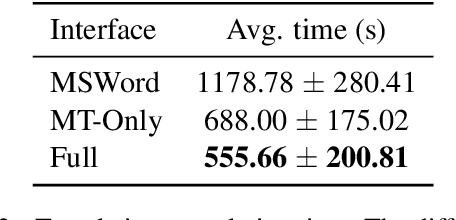
We present IntelliCAT, an interactive translation interface with neural models that streamline the post-editing process on machine translation output. We leverage two quality estimation (QE) models at different granularities: sentence-level QE, to predict the quality of each machine-translated sentence, and word-level QE, to locate the parts of the machine-translated sentence that need correction. Additionally, we introduce a novel translation suggestion model conditioned on both the left and right contexts, providing alternatives for specific words or phrases for correction. Finally, with word alignments, IntelliCAT automatically preserves the original document's styles in the translated document. The experimental results show that post-editing based on the proposed QE and translation suggestions can significantly improve translation quality. Furthermore, a user study reveals that three features provided in IntelliCAT significantly accelerate the post-editing task, achieving a 52.9\% speedup in translation time compared to translating from scratch. The interface is publicly available at https://intellicat.beringlab.com/.
Imputation of Clinical Covariates in Time Series
Dec 02, 2018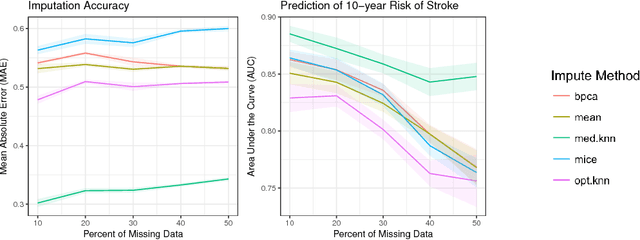
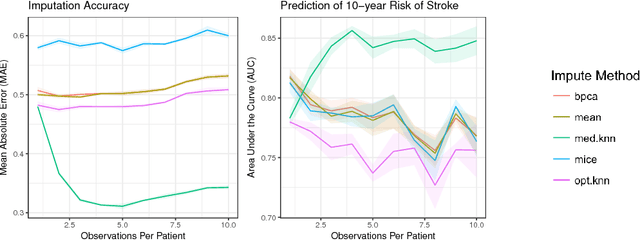
Missing data is a common problem in real-world settings and particularly relevant in healthcare applications where researchers use Electronic Health Records (EHR) and results of observational studies to apply analytics methods. This issue becomes even more prominent for longitudinal data sets, where multiple instances of the same individual correspond to different observations in time. Standard imputation methods do not take into account patient specific information incorporated in multivariate panel data. We introduce the novel imputation algorithm MedImpute that addresses this problem, extending the flexible framework of OptImpute suggested by Bertsimas et al. (2018). Our algorithm provides imputations for data sets with missing continuous and categorical features, and we present the formulation and implement scalable first-order methods for a $K$-NN model. We test the performance of our algorithm on longitudinal data from the Framingham Heart Study when data are missing completely at random (MCAR). We demonstrate that MedImpute leads to significant improvements in both imputation accuracy and downstream model AUC compared to state-of-the-art methods.
Threshold-Based Data Exclusion Approach for Energy-Efficient Federated Edge Learning
Mar 30, 2021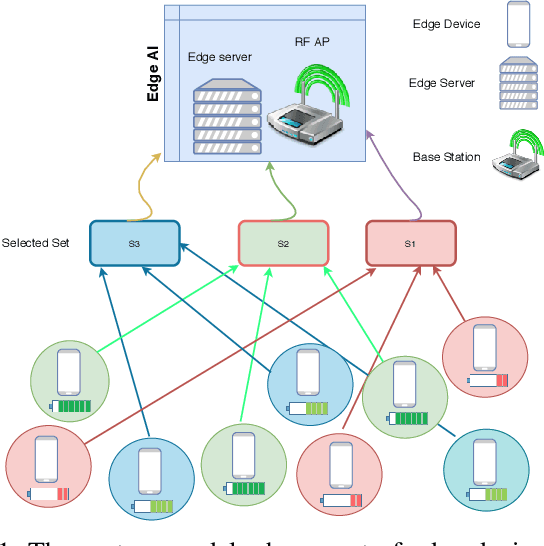
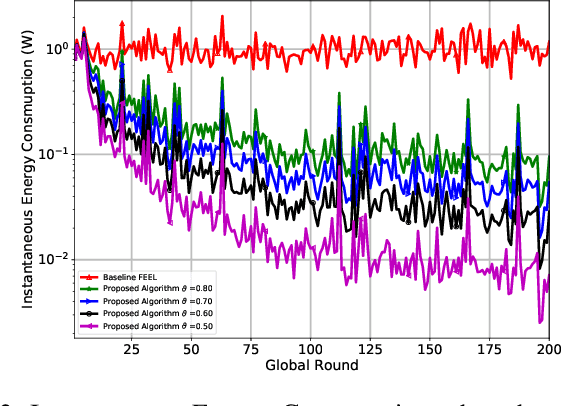
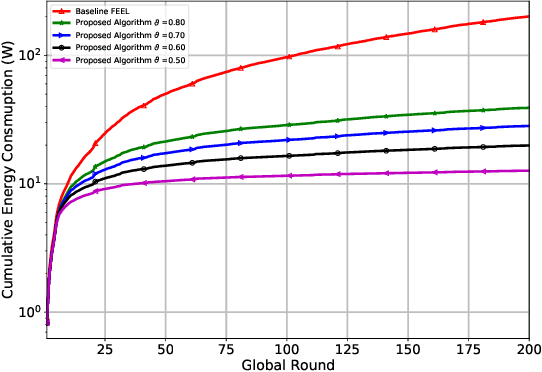
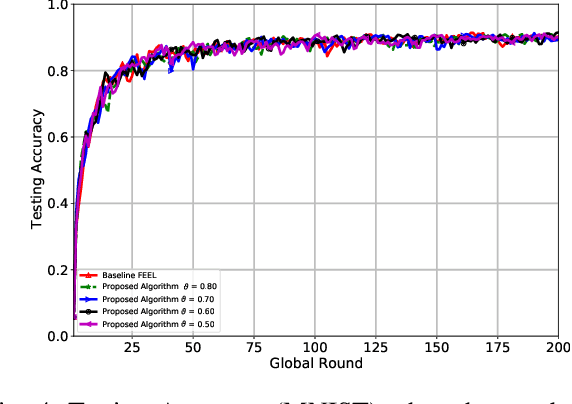
Federated edge learning (FEEL) is a promising distributed learning technique for next-generation wireless networks. FEEL preserves the user's privacy, reduces the communication costs, and exploits the unprecedented capabilities of edge devices to train a shared global model by leveraging a massive amount of data generated at the network edge. However, FEEL might significantly shorten energy-constrained participating devices' lifetime due to the power consumed during the model training round. This paper proposes a novel approach that endeavors to minimize computation and communication energy consumption during FEEL rounds to address this issue. First, we introduce a modified local training algorithm that intelligently selects only the samples that enhance the model's quality based on a predetermined threshold probability. Then, the problem is formulated as joint energy minimization and resource allocation optimization problem to obtain the optimal local computation time and the optimal transmission time that minimize the total energy consumption considering the worker's energy budget, available bandwidth, channel states, beamforming, and local CPU speed. After that, we introduce a tractable solution to the formulated problem that ensures the robustness of FEEL. Our simulation results show that our solution substantially outperforms the baseline FEEL algorithm as it reduces the local consumed energy by up to 79%.
Atlas-Based Segmentation of Intracochlear Anatomy in Metal Artifact Affected CT Images of the Ear with Co-trained Deep Neural Networks
Jul 09, 2021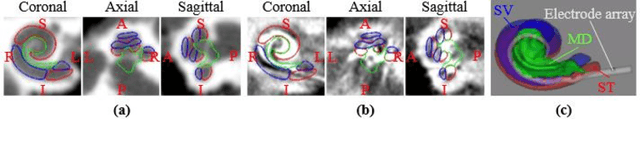
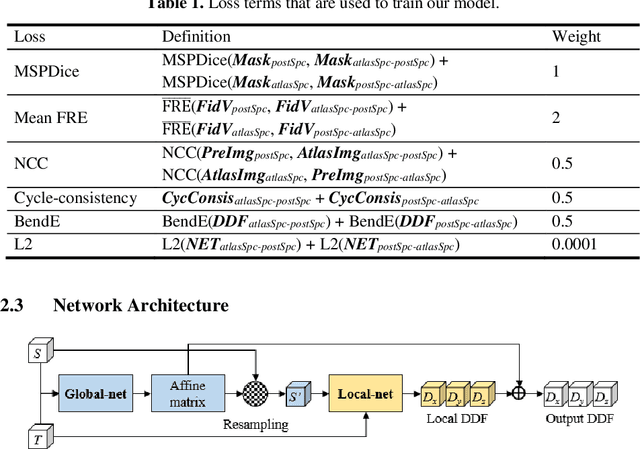
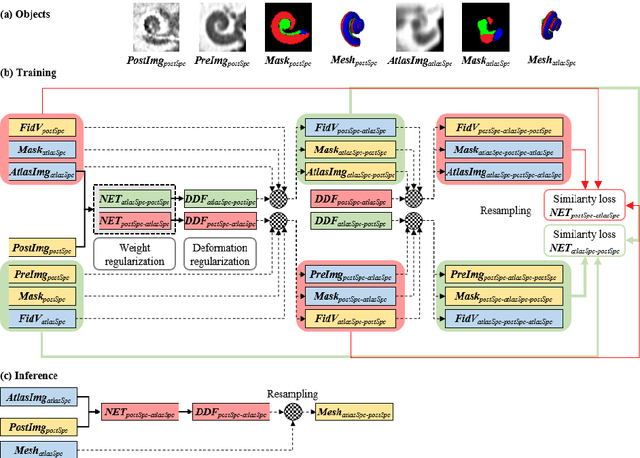
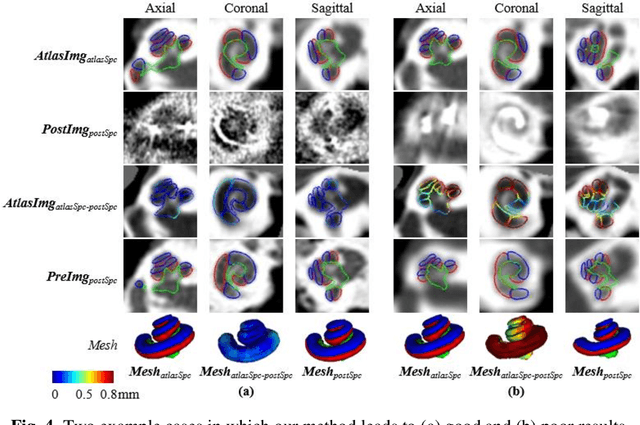
We propose an atlas-based method to segment the intracochlear anatomy (ICA) in the post-implantation CT (Post-CT) images of cochlear implant (CI) recipients that preserves the point-to-point correspondence between the meshes in the atlas and the segmented volumes. To solve this problem, which is challenging because of the strong artifacts produced by the implant, we use a pair of co-trained deep networks that generate dense deformation fields (DDFs) in opposite directions. One network is tasked with registering an atlas image to the Post-CT images and the other network is tasked with registering the Post-CT images to the atlas image. The networks are trained using loss functions based on voxel-wise labels, image content, fiducial registration error, and cycle-consistency constraint. The segmentation of the ICA in the Post-CT images is subsequently obtained by transferring the predefined segmentation meshes of the ICA in the atlas image to the Post-CT images using the corresponding DDFs generated by the trained registration networks. Our model can learn the underlying geometric features of the ICA even though they are obscured by the metal artifacts. We show that our end-to-end network produces results that are comparable to the current state of the art (SOTA) that relies on a two-steps approach that first uses conditional generative adversarial networks to synthesize artifact-free images from the Post-CT images and then uses an active shape model-based method to segment the ICA in the synthetic images. Our method requires a fraction of the time needed by the SOTA, which is important for end-user acceptance.