 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning for Adaptive Video Compressive Sensing
May 18, 2021
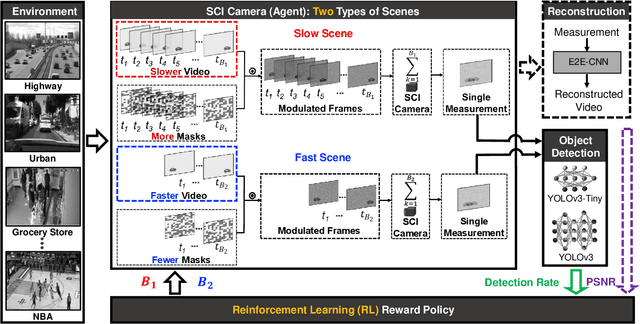


We apply reinforcement learning to video compressive sensing to adapt the compression ratio. Specifically, video snapshot compressive imaging (SCI), which captures high-speed video using a low-speed camera is considered in this work, in which multiple (B) video frames can be reconstructed from a snapshot measurement. One research gap in previous studies is how to adapt B in the video SCI system for different scenes. In this paper, we fill this gap utilizing reinforcement learning (RL). An RL model, as well as various convolutional neural networks for reconstruction, are learned to achieve adaptive sensing of video SCI systems. Furthermore, the performance of an object detection network using directly the video SCI measurements without reconstruction is also used to perform RL-based adaptive video compressive sensing. Our proposed adaptive SCI method can thus be implemented in low cost and real time. Our work takes the technology one step further towards real applications of video SCI.
Continual Deterioration Prediction for Hospitalized COVID-19 Patients
Jan 19, 2021
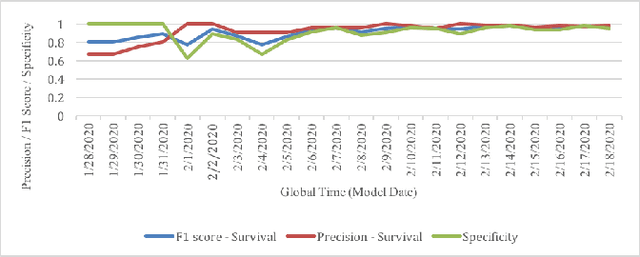
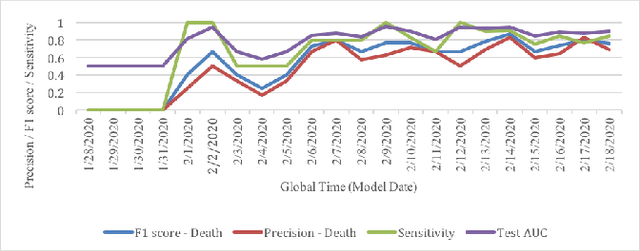

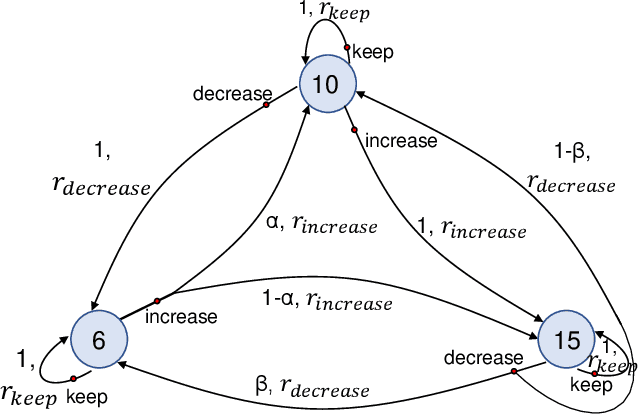
Leading up to August 2020, COVID-19 has spread to almost every country in the world, causing millions of infected and hundreds of thousands of deaths. In this paper, we first verify the assumption that clinical variables could have time-varying effects on COVID-19 outcomes. Then, we develop a temporal stratification approach to make daily predictions on patients' outcome at the end of hospital stay. Training data is segmented by the remaining length of stay, which is a proxy for the patient's overall condition. Based on this, a sequence of predictive models are built, one for each time segment. Thanks to the publicly shared data, we were able to build and evaluate prototype models. Preliminary experiments show 0.98 AUROC, 0.91 F1 score and 0.97 AUPR on continuous deterioration prediction, encouraging further development of the model as well as validations on different datasets. We also verify the key assumption which motivates our method. Clinical variables could have time-varying effects on COVID-19 outcomes. That is to say, the feature importance of a variable in the predictive model varies at different disease stages.
Alleviate Exposure Bias in Sequence Prediction \\ with Recurrent Neural Networks
Mar 22, 2021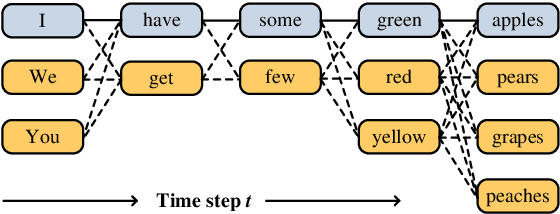
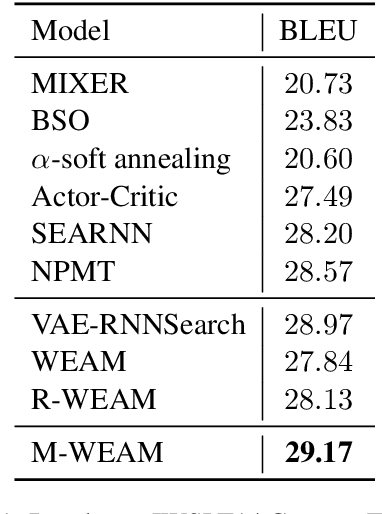
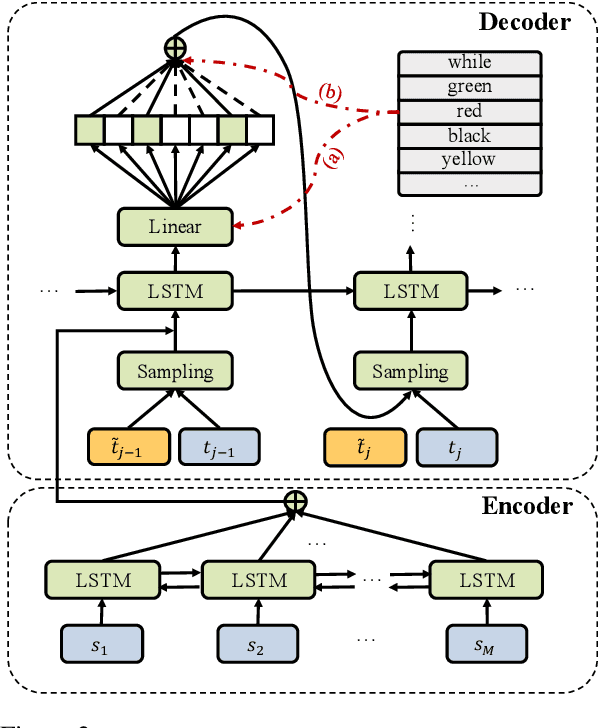
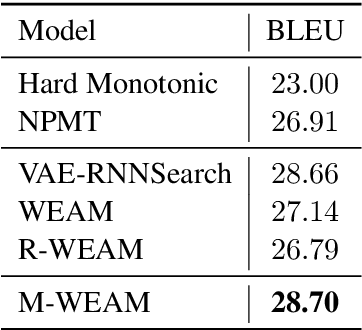
A popular strategy to train recurrent neural networks (RNNs), known as ``teacher forcing'' takes the ground truth as input at each time step and makes the later predictions partly conditioned on those inputs. Such training strategy impairs their ability to learn rich distributions over entire sequences because the chosen inputs hinders the gradients back-propagating to all previous states in an end-to-end manner. We propose a fully differentiable training algorithm for RNNs to better capture long-term dependencies by recovering the probability of the whole sequence. The key idea is that at each time step, the network takes as input a ``bundle'' of similar words predicted at the previous step instead of a single ground truth. The representations of these similar words forms a convex hull, which can be taken as a kind of regularization to the input. Smoothing the inputs by this way makes the whole process trainable and differentiable. This design makes it possible for the model to explore more feasible combinations (possibly unseen sequences), and can be interpreted as a computationally efficient approximation to the beam search. Experiments on multiple sequence generation tasks yield performance improvements, especially in sequence-level metrics, such as BLUE or ROUGE-2.
Satellite- and Cache-assisted UAV: A Joint Cache Placement, Resource Allocation, and Trajectory Optimization for 6G Aerial Networks
Jun 09, 2021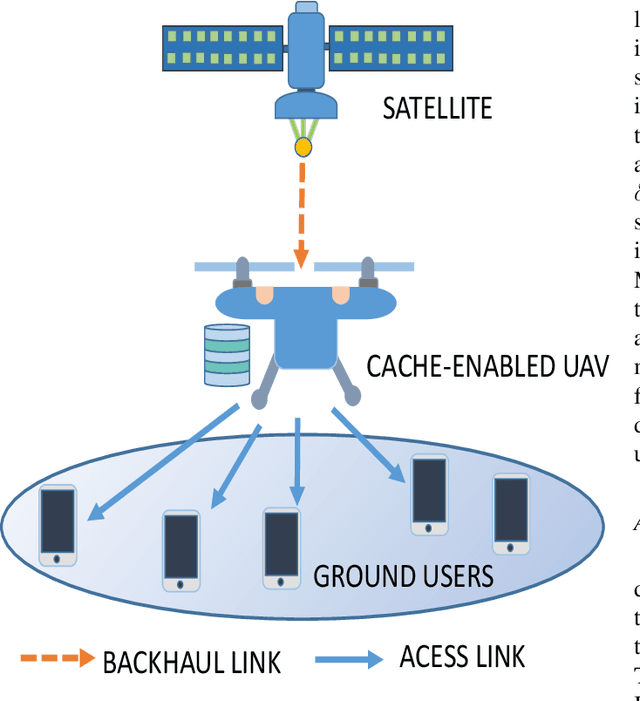
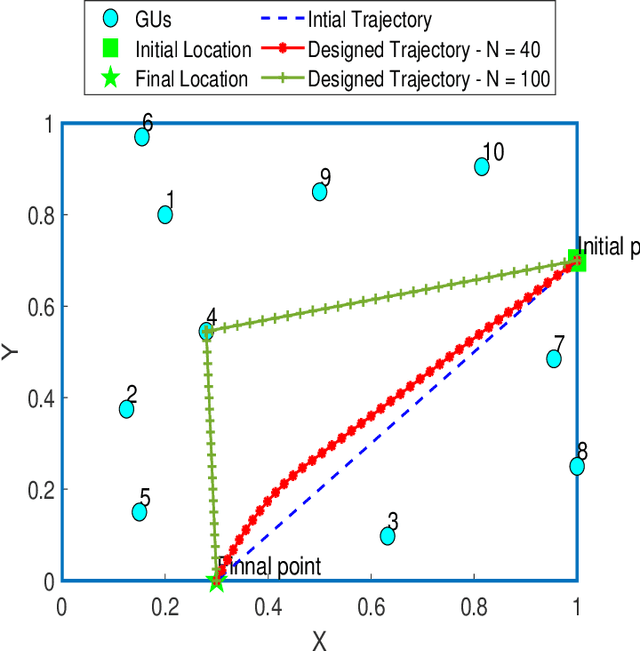
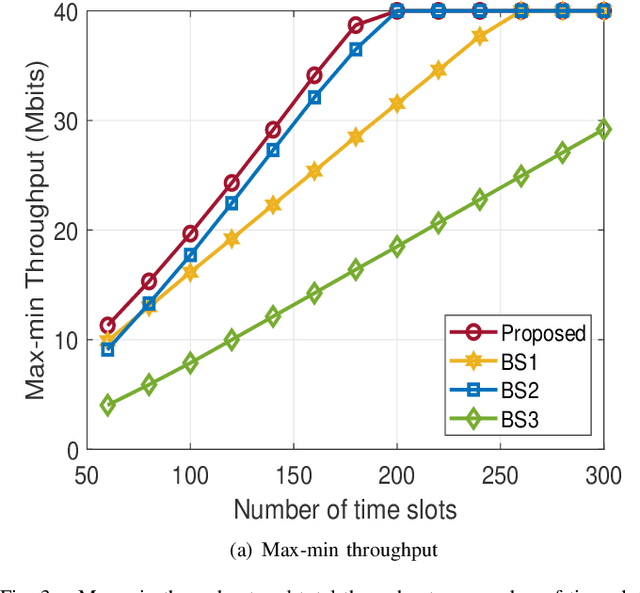
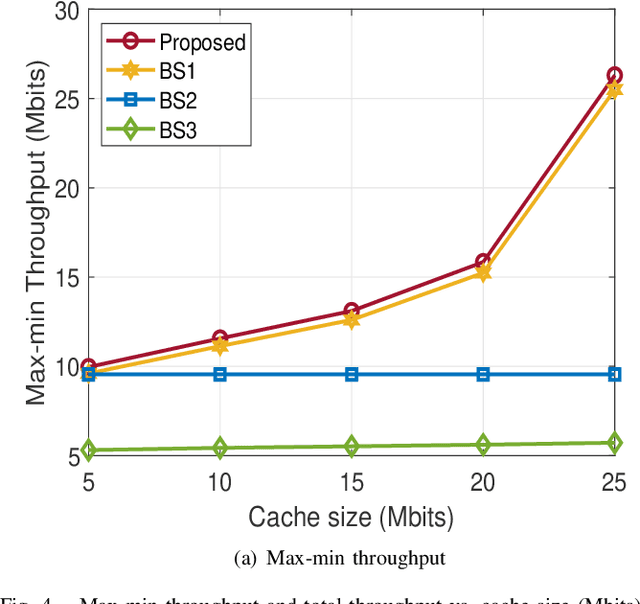
This paper considers LEO satellite- and cache-assisted UAV communications for content delivery in terrestrial networks, which shows great potential for next-generation systems to provide ubiquitous connectivity and high capacity. Specifically, caching is provided by the UAV to reduce backhaul congestion, and the LEO satellite supports the UAV's backhaul link. In this context, we aim to maximize the minimum achievable throughput per ground user (GU) by jointly optimizing cache placement, the UAV's resource allocation, and trajectory while cache capacity and flight time are limited. The formulated problem is challenging to solve directly due to its non-convexity and combinatorial nature. To find a solution, the problem is decomposed into three sub-problems: (1) cache placement optimization with fixed UAV resources and trajectory, followed by (2) the UAV resources optimization with fixed cache placement vector and trajectory, and finally, (3) we optimize the UAV trajectory with fixed cache placement and UAV resources. Based on the solutions of sub-problems, an efficient alternating algorithm is proposed utilizing the block coordinate descent (BCD) and successive convex approximation (SCA) methods. Simulation results show that the max-min throughput and total achievable throughput enhancement can be achieved by applying our proposed algorithm instead of other benchmark schemes.
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
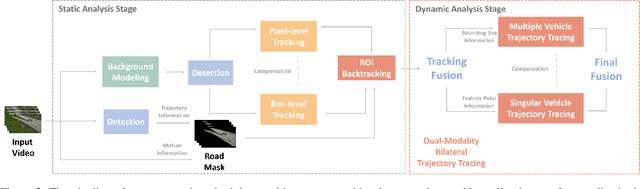
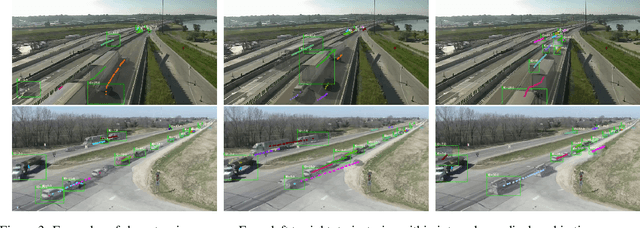
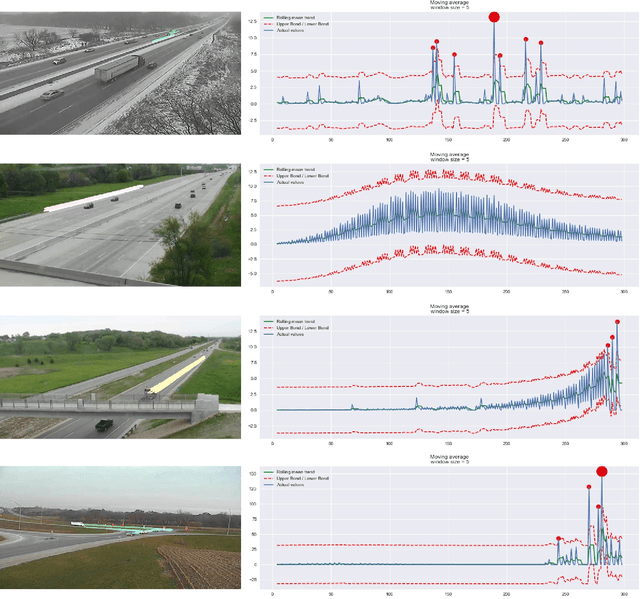
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.
Point-based Acoustic Scattering for Interactive Sound Propagation via Surface Encoding
May 17, 2021
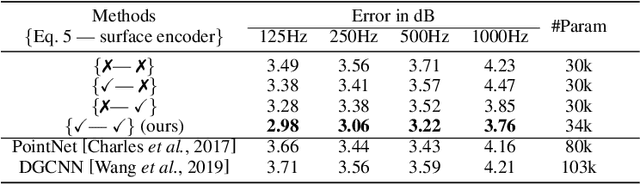
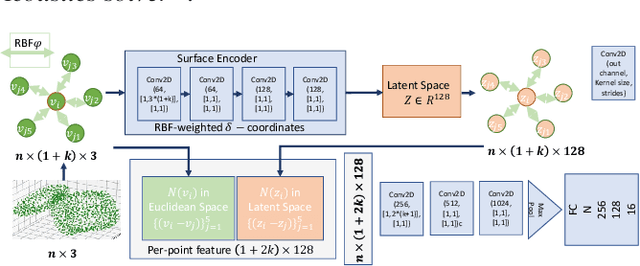
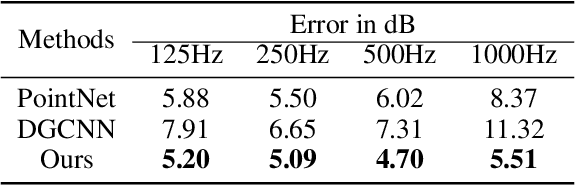
We present a novel geometric deep learning method to compute the acoustic scattering properties of geometric objects. Our learning algorithm uses a point cloud representation of objects to compute the scattering properties and integrates them with ray tracing for interactive sound propagation in dynamic scenes. We use discrete Laplacian-based surface encoders and approximate the neighborhood of each point using a shared multi-layer perceptron. We show that our formulation is permutation invariant and present a neural network that computes the scattering function using spherical harmonics. Our approach can handle objects with arbitrary topologies and deforming models, and takes less than 1ms per object on a commodity GPU. We have analyzed the accuracy and perform validation on thousands of unseen 3D objects and highlight the benefits over other point-based geometric deep learning methods. To the best of our knowledge, this is the first real-time learning algorithm that can approximate the acoustic scattering properties of arbitrary objects with high accuracy.
Information Avoidance and Overvaluation in Sequential Decision Making under Epistemic Constraints
Jun 09, 2021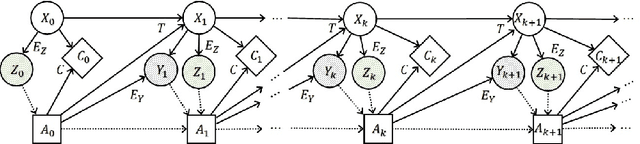
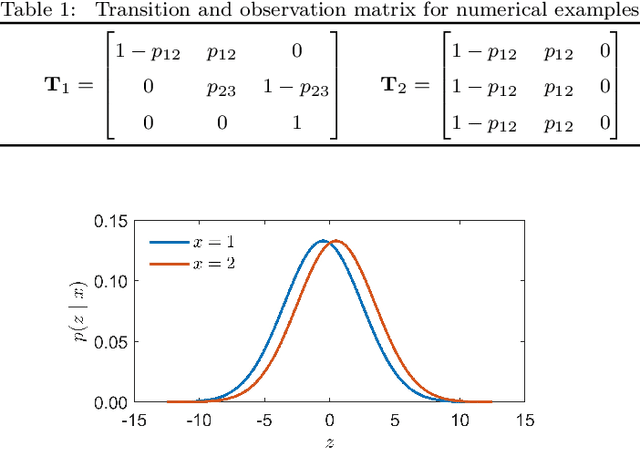
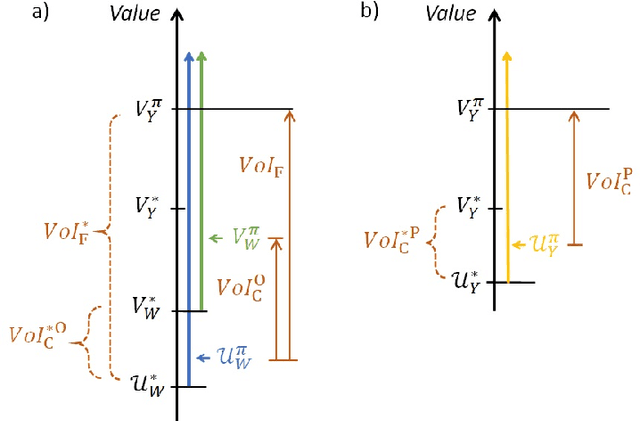
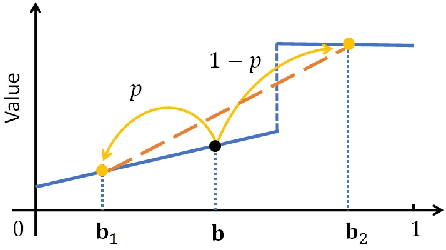
Decision makers involved in the management of civil assets and systems usually take actions under constraints imposed by societal regulations. Some of these constraints are related to epistemic quantities, as the probability of failure events and the corresponding risks. Sensors and inspectors can provide useful information supporting the control process (e.g. the maintenance process of an asset), and decisions about collecting this information should rely on an analysis of its cost and value. When societal regulations encode an economic perspective that is not aligned with that of the decision makers, the Value of Information (VoI) can be negative (i.e., information sometimes hurts), and almost irrelevant information can even have a significant value (either positive or negative), for agents acting under these epistemic constraints. We refer to these phenomena as Information Avoidance (IA) and Information OverValuation (IOV). In this paper, we illustrate how to assess VoI in sequential decision making under epistemic constraints (as those imposed by societal regulations), by modeling a Partially Observable Markov Decision Processes (POMDP) and evaluating non optimal policies via Finite State Controllers (FSCs). We focus on the value of collecting information at current time, and on that of collecting sequential information, we illustrate how these values are related and we discuss how IA and IOV can occur in those settings.
Time-causal and time-recursive spatio-temporal receptive fields
Dec 07, 2015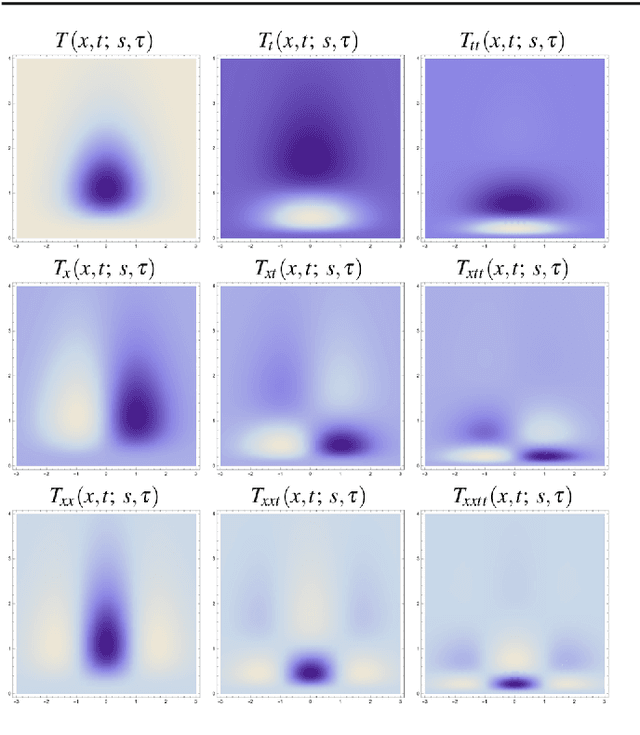

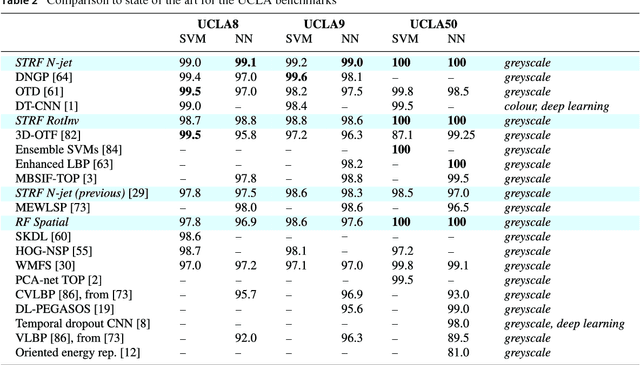
We present an improved model and theory for time-causal and time-recursive spatio-temporal receptive fields, based on a combination of Gaussian receptive fields over the spatial domain and first-order integrators or equivalently truncated exponential filters coupled in cascade over the temporal domain. Compared to previous spatio-temporal scale-space formulations in terms of non-enhancement of local extrema or scale invariance, these receptive fields are based on different scale-space axiomatics over time by ensuring non-creation of new local extrema or zero-crossings with increasing temporal scale. Specifically, extensions are presented about (i) parameterizing the intermediate temporal scale levels, (ii) analysing the resulting temporal dynamics, (iii) transferring the theory to a discrete implementation, (iv) computing scale-normalized spatio-temporal derivative expressions for spatio-temporal feature detection and (v) computational modelling of receptive fields in the lateral geniculate nucleus (LGN) and the primary visual cortex (V1) in biological vision. We show that by distributing the intermediate temporal scale levels according to a logarithmic distribution, we obtain much faster temporal response properties (shorter temporal delays) compared to a uniform distribution. Specifically, these kernels converge very rapidly to a limit kernel possessing true self-similar scale-invariant properties over temporal scales, thereby allowing for true scale invariance over variations in the temporal scale, although the underlying temporal scale-space representation is based on a discretized temporal scale parameter. We show how scale-normalized temporal derivatives can be defined for these time-causal scale-space kernels and how the composed theory can be used for computing basic types of scale-normalized spatio-temporal derivative expressions in a computationally efficient manner.
* 39 pages, 12 figures, 5 tables in Journal of Mathematical Imaging and Vision, published online Dec 2015
Learning a Dynamic Map of Visual Appearance
Dec 29, 2020
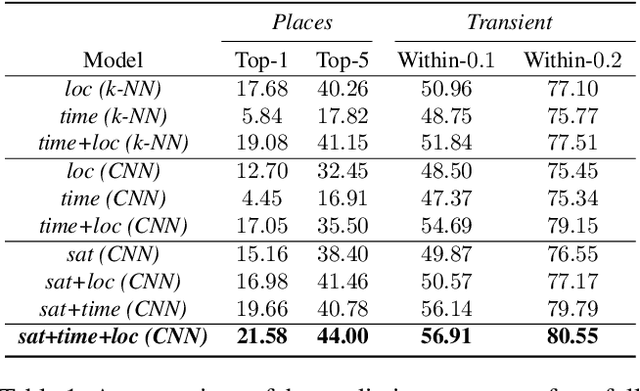

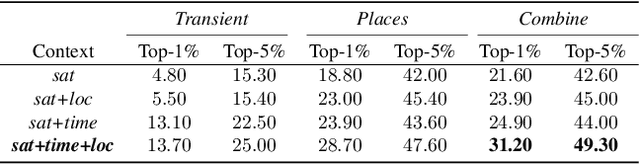
The appearance of the world varies dramatically not only from place to place but also from hour to hour and month to month. Every day billions of images capture this complex relationship, many of which are associated with precise time and location metadata. We propose to use these images to construct a global-scale, dynamic map of visual appearance attributes. Such a map enables fine-grained understanding of the expected appearance at any geographic location and time. Our approach integrates dense overhead imagery with location and time metadata into a general framework capable of mapping a wide variety of visual attributes. A key feature of our approach is that it requires no manual data annotation. We demonstrate how this approach can support various applications, including image-driven mapping, image geolocalization, and metadata verification.
Cardiac Functional Analysis with Cine MRI via Deep Learning Reconstruction
May 17, 2021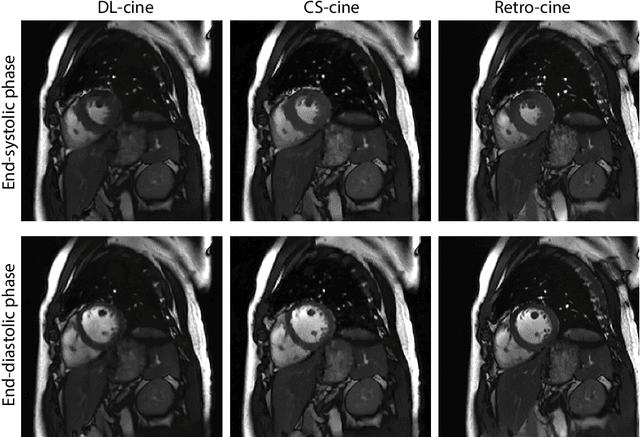
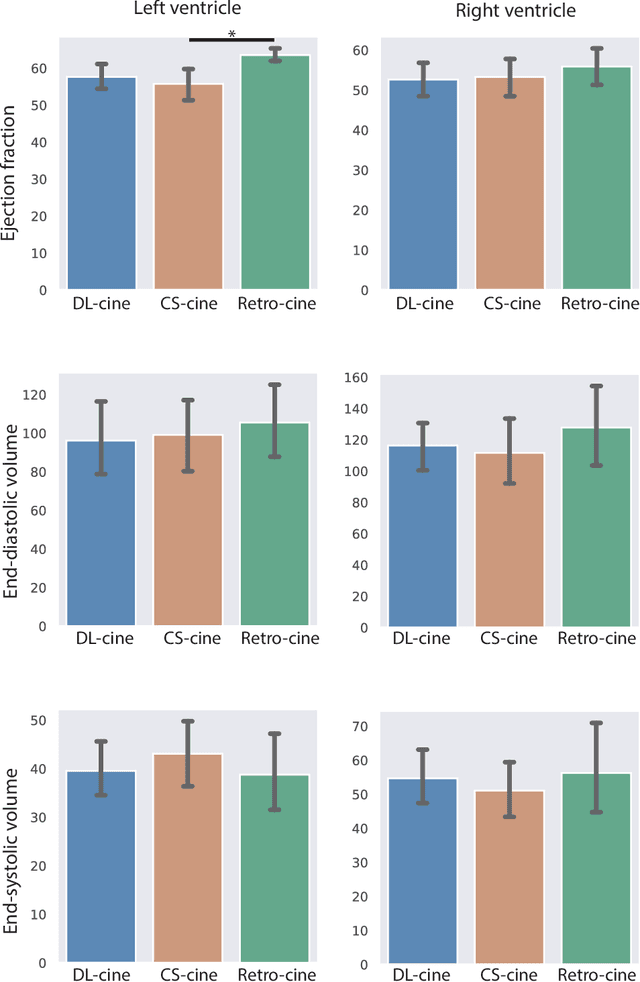
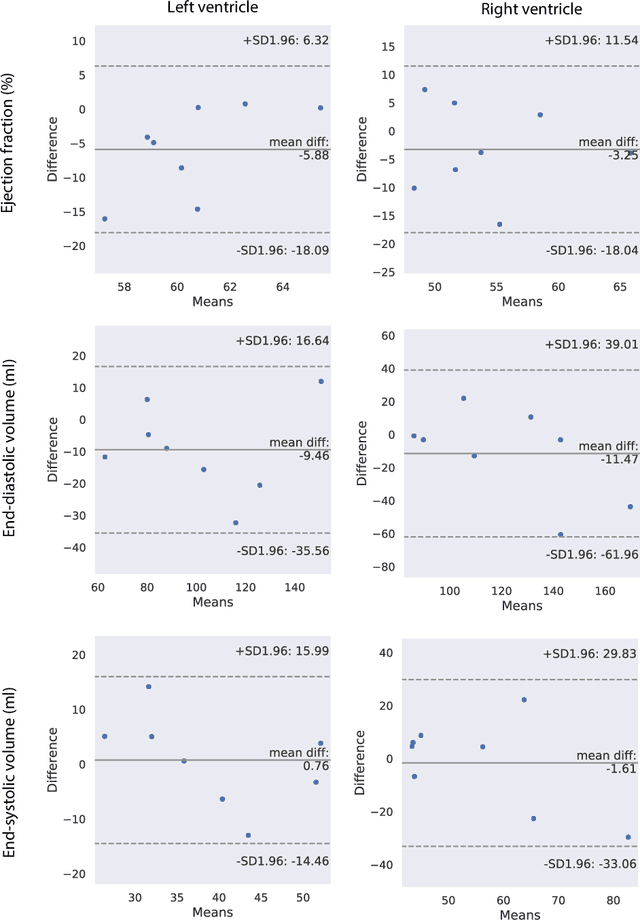
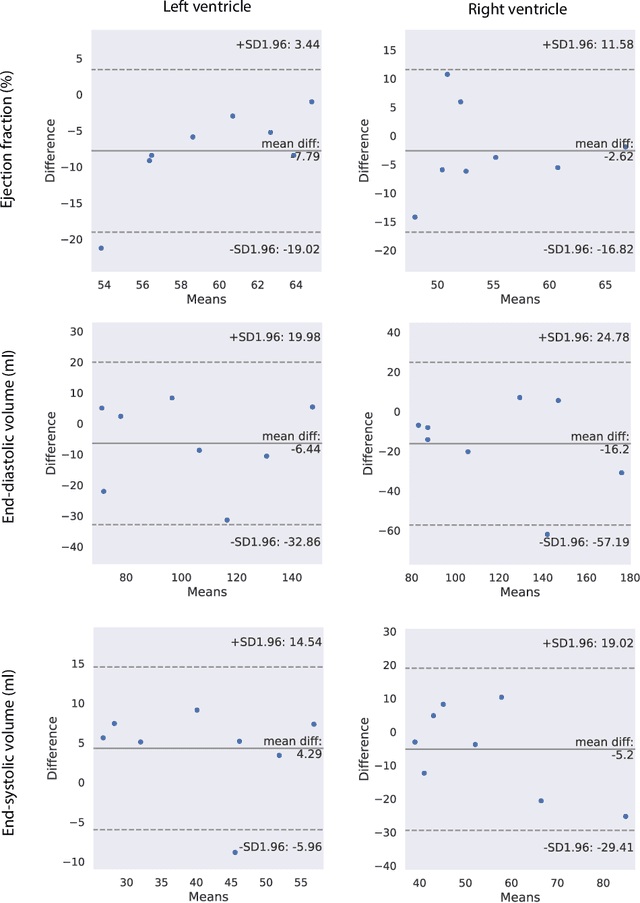
Retrospectively gated cine (retro-cine) MRI is the clinical standard for cardiac functional analysis. Deep learning (DL) based methods have been proposed for the reconstruction of highly undersampled MRI data and show superior image quality and magnitude faster reconstruction time than CS-based methods. Nevertheless, it remains unclear whether DL reconstruction is suitable for cardiac function analysis. To address this question, in this study we evaluate and compare the cardiac functional values (EDV, ESV and EF for LV and RV, respectively) obtained from highly accelerated MRI acquisition using DL based reconstruction algorithm (DL-cine) with values from CS-cine and conventional retro-cine. To the best of our knowledge, this is the first work to evaluate the cine MRI with deep learning reconstruction for cardiac function analysis and compare it with other conventional methods. The cardiac functional values obtained from cine MRI with deep learning reconstruction are consistent with values from clinical standard retro-cine MRI.